
- 1Merge和Rebase的区别_rebase和merge的区别
- 2Python中神奇的第三方库:Faker假数据生成器_python fake 省份
- 3llama3 微调教程之 llama factory 的 安装部署与模型微调过程,模型量化和gguf转换。_llama factory适配器路径
- 4目标检测算法常用评价指标_目标检测评价指标
- 5网络安全最全有效提高java编程安全性的12条黄金法则
- 6推荐上百个github上Python爬虫案例_github 爬虫代码
- 7Android framework系统默认设置修改_android framework 设备首次开机,亮度的调节流程
- 8vivado 建立多个仿真环境,active选择激活不同的仿真环境_vivado怎么同时仿真多个模块
- 9第14章 MySQL 数据字典_《mysql 8.0 参考手册》第 14 章 mysql 数据字典
- 10【python】pyltp的安装_[info] 2024-04-28 07:57:29 loaded 4 lexicon entrie
分布式任务调度平台XXL-JOB_xxl-job 服务关闭后线程未关闭
赞
踩
《分布式任务调度平台XXL-JOB》

![]()

![]()

![]()
一、简介
1.1 概述
XXL-JOB是一个轻量级分布式任务调度框架,其核心设计目标是开发迅速、学习简单、轻量级、易扩展。现已开放源代码并接入多家公司线上产品线,开箱即用。
1.2 特性
- 1、简单:支持通过Web页面对任务进行CRUD操作,操作简单,一分钟上手;
- 2、动态:支持动态修改任务状态、暂停/恢复任务,以及终止运行中任务,即时生效;
- 3、调度中心HA(中心式):调度采用中心式设计,“调度中心”基于集群Quartz实现并支持集群部署,可保证调度中心HA;
- 4、执行器HA(分布式):任务分布式执行,任务"执行器"支持集群部署,可保证任务执行HA;
- 5、注册中心: 执行器会周期性自动注册任务, 调度中心将会自动发现注册的任务并触发执行。同时,也支持手动录入执行器地址;
- 6、弹性扩容缩容:一旦有新执行器机器上线或者下线,下次调度时将会重新分配任务;
- 7、路由策略:执行器集群部署时提供丰富的路由策略,包括:第一个、最后一个、轮询、随机、一致性HASH、最不经常使用、最近最久未使用、故障转移、忙碌转移等;
- 8、故障转移:任务路由策略选择"故障转移"情况下,如果执行器集群中某一台机器故障,将会自动Failover切换到一台正常的执行器发送调度请求。
- 9、失败处理策略;调度失败时的处理策略,策略包括:失败告警(默认)、失败重试;
- 10、失败重试:调度中心调度失败且启用"失败重试"策略时,将会自动重试一次;执行器执行失败且回调失败重试状态时,也将会自动重试一次;
- 11、阻塞处理策略:调度过于密集执行器来不及处理时的处理策略,策略包括:单机串行(默认)、丢弃后续调度、覆盖之前调度;
- 12、分片广播任务:执行器集群部署时,任务路由策略选择"分片广播"情况下,一次任务调度将会广播触发集群中所有执行器执行一次任务,可根据分片参数开发分片任务;
- 13、动态分片:分片广播任务以执行器为维度进行分片,支持动态扩容执行器集群从而动态增加分片数量,协同进行业务处理;在进行大数据量业务操作时可显著提升任务处理能力和速度。
- 14、事件触发:除了"Cron方式"和"任务依赖方式"触发任务执行之外,支持基于事件的触发任务方式。调度中心提供触发任务单次执行的API服务,可根据业务事件灵活触发。
- 15、任务进度监控:支持实时监控任务进度;
- 16、Rolling实时日志:支持在线查看调度结果,并且支持以Rolling方式实时查看执行器输出的完整的执行日志;
- 17、GLUE:提供Web IDE,支持在线开发任务逻辑代码,动态发布,实时编译生效,省略部署上线的过程。支持30个版本的历史版本回溯。
- 18、脚本任务:支持以GLUE模式开发和运行脚本任务,包括Shell、Python、NodeJS等类型脚本;
- 19、任务依赖:支持配置子任务依赖,当父任务执行结束且执行成功后将会主动触发一次子任务的执行, 多个子任务用逗号分隔;
- 20、一致性:“调度中心”通过DB锁保证集群分布式调度的一致性, 一次任务调度只会触发一次执行;
- 21、自定义任务参数:支持在线配置调度任务入参,即时生效;
- 22、调度线程池:调度系统多线程触发调度运行,确保调度精确执行,不被堵塞;
- 23、数据加密:调度中心和执行器之间的通讯进行数据加密,提升调度信息安全性;
- 24、邮件报警:任务失败时支持邮件报警,支持配置多邮件地址群发报警邮件;
- 25、推送maven中央仓库: 将会把最新稳定版推送到maven中央仓库, 方便用户接入和使用;
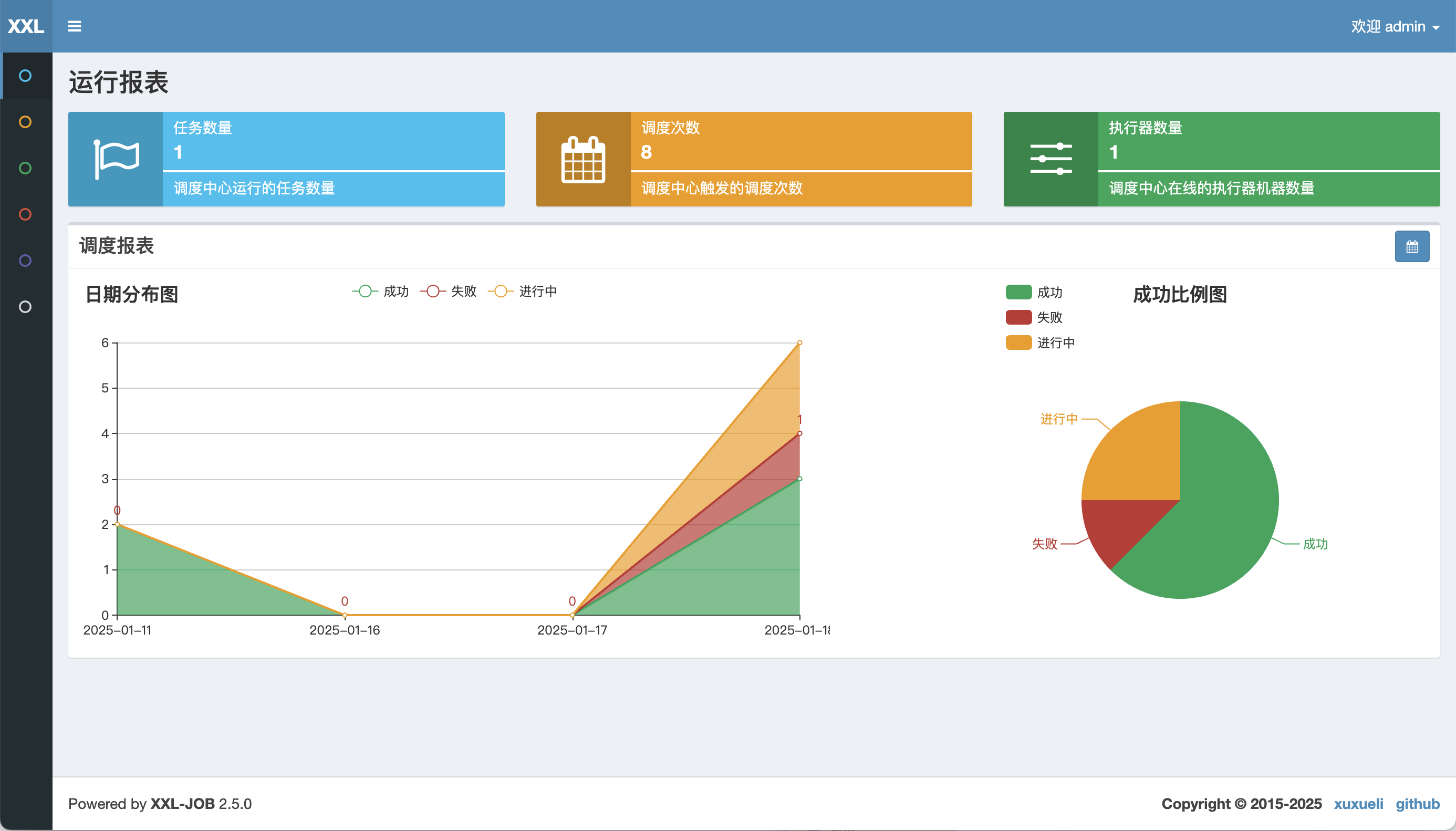
- 26、运行报表:支持实时查看运行数据,如任务数量、调度次数、执行器数量等;以及调度报表,如调度日期分布图,调度成功分布图等;
- 27、全异步:系统底层实现全部异步化,针对密集调度进行流量削峰,理论上支持任意时长任务的运行;
- 28、国际化:调度中心支持国际化设置,提供中文、英文两种可选语言,默认为中文;
1.3 发展
于2015年中,我在github上创建XXL-JOB项目仓库并提交第一个commit,随之进行系统结构设计,UI选型,交互设计……
于2015-11月,XXL-JOB终于RELEASE了第一个大版本V1.0, 随后我将之发布到OSCHINA,XXL-JOB在OSCHINA上获得了@红薯的热门推荐,同期分别达到了OSCHINA的“热门动弹”排行第一和git.oschina的开源软件月热度排行第一,在此特别感谢红薯,感谢大家的关注和支持。
于2015-12月,我将XXL-JOB发表到我司内部知识库,并且得到内部同事认可。
于2016-01月,我司展开XXL-JOB的内部接入和定制工作,在此感谢袁某和尹某两位同事的贡献,同时也感谢内部其他给与关注与支持的同事。
于2017-05-13,在上海举办的 "第62期开源中国源创会" 的 "放码过来" 环节,我登台对XXL-JOB做了演讲,台下五百位在场观众反响热烈(图文回顾 )。
于2017-10-22,又拍云 Open Talk 联合 Spring Cloud 中国社区举办的 "进击的微服务实战派上海站",我登台对XXL-JOB做了演讲,现场观众反响热烈并在会后与XXL-JOB用户热烈讨论交流
于2017-12-11,XXL-JOB有幸参会《InfoQ ArchSummit全球架构师峰会》,并被拍拍贷架构总监"杨波老师"在专题 "微服务原理、基础架构和开源实践" 中现场介绍。
于2017-12-18,XXL-JOB参与"2017年度最受欢迎中国开源软件"评比,在当时已录入的约九千个国产开源项目中角逐,最终进入了前30强。
于2018-01-15,XXL-JOB参与"2017码云最火开源项目"评比,在当时已录入的约六千五百个码云项目中角逐,最终进去了前20强。
我司大众点评目前已接入XXL-JOB,内部别名《Ferrari》(Ferrari基于XXL-JOB的V1.1版本定制而成,新接入应用推荐升级最新版本)。 据最新统计, 自2016-01-21接入至2017-12-01期间,该系统已调度约100万次,表现优异。新接入应用推荐使用最新版本,因为经过数个大版本的更新,系统的任务模型、UI交互模型以及底层调度通讯模型都有了较大的优化和提升,核心功能更加稳定高效。
至今,XXL-JOB已接入多家公司的线上产品线,接入场景如电商业务,O2O业务和大数据作业等,截止最新统计时间为止,XXL-JOB已接入的公司包括不限于:
- - 1、大众点评;
- - 2、山东学而网络科技有限公司;
- - 3、安徽慧通互联科技有限公司;
- - 4、人人聚财金服;
- - 5、上海棠棣信息科技股份有限公司
- - 6、运满满
- - 7、米其林 (中国区)
- - 8、妈妈联盟
- - 9、九樱天下(北京)信息技术有限公司
- - 10、万普拉斯科技有限公司(一加手机)
- - 11、上海亿保健康管理有限公司
- - 12、海尔馨厨 (海尔)
- - 13、河南大红包电子商务有限公司
- - 14、成都顺点科技有限公司
- - 15、深圳市怡亚通
- - 16、深圳麦亚信科技股份有限公司
- - 17、上海博莹科技信息技术有限公司
- - 18、中国平安科技有限公司
- - 19、杭州知时信息科技有限公司
- - 20、博莹科技(上海)有限公司
- - 21、成都依能股份有限责任公司
- - 22、湖南高阳通联信息技术有限公司
- - 23、深圳市邦德文化发展有限公司
- - 24、福建阿思可网络教育有限公司
- - 25、优信二手车
- - 26、上海悠游堂投资发展股份有限公司
- - 27、北京粉笔蓝天科技有限公司
- - 28、中秀科技(无锡)有限公司
- - 29、武汉空心科技有限公司
- - 30、北京蚂蚁风暴科技有限公司
- - 31、四川互宜达科技有限公司
- - 32、钱包行云(北京)科技有限公司
- - 33、重庆欣才集团
- - 34、咪咕互动娱乐有限公司(中国移动)
- - 35、北京诺亦腾科技有限公司
- - 36、增长引擎(北京)信息技术有限公司
- - 37、北京英贝思科技有限公司
- - 38、刚泰集团
- - 39、深圳泰久信息系统股份有限公司
- - 40、随行付支付有限公司
- - 41、广州瀚农网络科技有限公司
- - 42、享点科技有限公司
- - 43、杭州比智科技有限公司
- - 44、圳临界线网络科技有限公司
- - 45、广州知识圈网络科技有限公司
- - 46、国誉商业上海有限公司
- - 47、海尔消费金融有限公司,嗨付、够花 (海尔)
- - 48、广州巴图鲁信息科技有限公司
- - 49、深圳市鹏海运电子数据交换有限公司
- - 50、深圳市亚飞电子商务有限公司
- - 51、上海趣医网络有限公司
- - 52、聚金资本
- - 53、北京父母邦网络科技有限公司
- - 54、中山元赫软件科技有限公司
- - 55、中商惠民(北京)电子商务有限公司
- - 56、凯京集团
- - 57、华夏票联(北京)科技有限公司
- - 58、拍拍贷
- - 59、北京尚德机构在线教育有限公司
- - 60、任子行股份有限公司
- - 61、北京时态电子商务有限公司
- - 62、深圳卷皮网络科技有限公司
- - 63、北京安博通科技股份有限公司
- - 64、未来无线网
- - 65、厦门瓷禧网络有限公司
- - 66、北京递蓝科软件股份有限公司
- - 67、郑州创海软件科技公司
- - ……

更多接入的公司,欢迎在 登记地址 登记,登记仅仅为了产品推广。
欢迎大家的关注和使用,XXL-JOB也将拥抱变化,持续发展。
1.4 下载
文档地址
源码仓库地址
| 源码仓库地址 | Release Download |
|---|---|
| https://github.com/xuxueli/xxl-job | Download |
| http://gitee.com/xuxueli0323/xxl-job | Download |
中央仓库地址
- <!-- http://repo1.maven.org/maven2/com/xuxueli/xxl-job-core/ -->
- <dependency>
- <groupId>com.xuxueli</groupId>
- <artifactId>xxl-job-core</artifactId>
- <version>${最新稳定版本}</version>
- </dependency>
技术交流
1.5 环境
- JDK:1.7+
- Servlet/JSP Spec:3.1/2.3
- Tomcat:8.5.x/Jetty9.2.x
- Spring-boot:1.5.x/Spring4.x
- Mysql:5.6+
- Maven:3+
二、快速入门
2.1 初始化“调度数据库”
请下载项目源码并解压,获取 "调度数据库初始化SQL脚本" 并执行即可,正常情况下应该生成16张表。
"调度数据库初始化SQL脚本" 位置为:
/xxl-job/doc/db/tables_xxl_job.sql
调度中心支持集群部署,集群情况下各节点务必连接同一个mysql实例;
如果mysql做主从,调度中心集群节点务必强制走主库;
2.2 编译源码
解压源码,按照maven格式将源码导入IDE, 使用maven进行编译即可,源码结构如下:
- xxl-job-admin:调度中心
- xxl-job-core:公共依赖
- xxl-job-executor:执行器Sample示例(选择合适的版本执行器,可直接使用,也可以参考其并将现有项目改造成执行器)
- :xxl-job-executor-sample-spring:Spring版本,通过Spring容器管理执行器,比较通用,推荐这种方式;
- :xxl-job-executor-sample-springboot:Springboot版本,通过Springboot管理执行器;
- :xxl-job-executor-sample-jfinal:JFinal版本,通过JFinal管理执行器;
- :xxl-job-executor-sample-nutz:Nutz版本,通过Nutz管理执行器;
2.3 配置部署“调度中心”
- 调度中心项目:xxl-job-admin
- 作用:统一管理任务调度平台上调度任务,负责触发调度执行,并且提供任务管理平台。
步骤一:调度中心配置:
调度中心配置文件地址:
/xxl-job/xxl-job-admin/src/main/resources/xxl-job-admin.properties
调度中心配置内容说明:
- ### 调度中心JDBC链接:链接地址请保持和 2.1章节 所创建的调度数据库的地址一致
- xxl.job.db.driverClass=com.mysql.jdbc.Driver
- xxl.job.db.url=jdbc:mysql://localhost:3306/xxl-job?useUnicode=true&characterEncoding=UTF-8
- xxl.job.db.user=root
- xxl.job.db.password=root_pwd
-
- ### 报警邮箱
- xxl.job.mail.host=smtp.163.com
- xxl.job.mail.port=25
- xxl.job.mail.username=ovono802302@163.com
- xxl.job.mail.password=asdfzxcv
- xxl.job.mail.sendFrom=ovono802302@163.com
- xxl.job.mail.sendNick=《任务调度平台XXL-JOB》
-
- ### 登录账号
- xxl.job.login.username=admin
- xxl.job.login.password=123456
-
- ### 调度中心通讯TOKEN,非空时启用
- xxl.job.accessToken=
-
- ### 调度中心国际化设置,默认为中文版本,值设置为“en”时切换为英文版本
- xxl.job.i18n=
步骤二:部署项目:
如果已经正确进行上述配置,可将项目编译打war包并部署到tomcat中。 调度中心访问地址:http://localhost:8080/xxl-job-admin (该地址执行器将会使用到,作为回调地址),登录后运行界面如下图所示
至此“调度中心”项目已经部署成功。
步骤三:调度中心集群(可选):
调度中心支持集群部署,提升调度系统容灾和可用性。
调度中心集群部署时,几点要求和建议:
- DB配置保持一致;
- 登陆账号配置保持一致;
- 集群机器时钟保持一致(单机集群忽视);
- 建议:推荐通过nginx为调度中心集群做负载均衡,分配域名。调度中心访问、执行器回调配置、调用API服务等操作均通过该域名进行。
2.4 配置部署“执行器项目”
- “执行器”项目:xxl-job-executor-sample-spring (提供多种版本执行器供选择,现以Spring版本为例,可直接使用,也可以参考其并将现有项目改造成执行器)
- 作用:负责接收“调度中心”的调度并执行;可直接部署执行器,也可以将执行器集成到现有业务项目中。
步骤一:maven依赖
确认pom文件中引入了 "xxl-job-core" 的maven依赖;
步骤二:执行器配置
执行器配置,配置文件地址:
/xxl-job/xxl-job-executor-samples/xxl-job-executor-sample-spring/src/main/resources/xxl-job-executor.properties
执行器配置,配置内容说明:
- ### xxl-job admin address list:调度中心部署跟地址:如调度中心集群部署存在多个地址则用逗号分隔。执行器将会使用该地址进行"执行器心跳注册"和"任务结果回调"。
- xxl.job.admin.addresses=http://127.0.0.1:8080/xxl-job-admin
-
- ### xxl-job executor address:执行器"AppName"和地址信息配置:AppName执行器心跳注册分组依据;地址信息用于"调度中心请求并触发任务"和"执行器注册"。执行器默认端口为9999,执行器IP默认为空表示自动获取IP,多网卡时可手动设置指定IP,手动设置IP时将会绑定Host。单机部署多个执行器时,注意要配置不同执行器端口;
- xxl.job.executor.appname=xxl-job-executor-sample
- xxl.job.executor.ip=
- xxl.job.executor.port=9999
-
- ### xxl-job, access token:执行器通讯TOKEN,非空时启用
- xxl.job.accessToken=
-
- ### xxl-job log path:执行器运行日志文件存储的磁盘位置,需要对该路径拥有读写权限
- xxl.job.executor.logpath=/data/applogs/xxl-job/jobhandler/
-
- ### xxl-job log retention days:执行器Log文件定期清理功能,指定日志保存天数,日志文件过期自动删除。限制至少保持3天,否则功能不生效;
- xxl.job.executor.logretentiondays=-1
步骤三:执行器组件配置
执行器组件,配置文件地址:
/xxl-job/xxl-job-executor-samples/xxl-job-executor-sample-spring/src/main/resources/applicationcontext-xxl-job.xml
执行器组件,配置内容说明:
- <!-- 配置01、JobHandler 扫描路径:自动扫描容器中JobHandler -->
- <context:component-scan base-package="com.xxl.job.executor.service.jobhandler" />
-
- <!-- 配置02、执行器 -->
- <bean id="xxlJobExecutor" class="com.xxl.job.core.executor.XxlJobExecutor" init-method="start" destroy-method="destroy" >
- <!-- 执行器注册中心地址[选填],为空则关闭自动注册 -->
- <property name="adminAddresses" value="${xxl.job.admin.addresses}" />
- <!-- 执行器AppName[选填],为空则关闭自动注册 -->
- <property name="appName" value="${xxl.job.executor.appname}" />
- <!-- 执行器IP[选填],为空则自动获取 -->
- <property name="ip" value="${xxl.job.executor.ip}" />
- <!-- 执行器端口号[选填],为空则自动获取 -->
- <property name="port" value="${xxl.job.executor.port}" />
- <!-- 访问令牌[选填],非空则进行匹配校验 -->
- <property name="accessToken" value="${xxl.job.accessToken}" />
- <!-- 执行器日志路径[选填],为空则使用默认路径 -->
- <property name="logPath" value="${xxl.job.executor.logpath}" />
- <!-- 日志保存天数[选填],值大于3时生效 -->
- <property name="logRetentionDays" value="${xxl.job.executor.logretentiondays}" />
- </bean>
步骤四:部署执行器项目:
如果已经正确进行上述配置,可将执行器项目编译打部署,系统提供多种执行器Sample示例项目,选择其中一个即可,各自的部署方式如下。
- xxl-job-executor-sample-springboot:项目编译打包成springboot类型的可执行JAR包,命令启动即可;
- xxl-job-executor-sample-spring:项目编译打包成WAR包,并部署到tomcat中。
- xxl-job-executor-sample-jfinal:同上
- xxl-job-executor-sample-nutz:同上
至此“执行器”项目已经部署结束。
步骤五:执行器集群(可选):
执行器支持集群部署,提升调度系统可用性,同时提升任务处理能力。
执行器集群部署时,几点要求和建议:
- 执行器回调地址(xxl.job.admin.addresses)需要保持一致;执行器根据该配置进行执行器自动注册等操作。
- 同一个执行器集群内AppName(xxl.job.executor.appname)需要保持一致;调度中心根据该配置动态发现不同集群的在线执行器列表。
2.5 开发第一个任务“Hello World”
本示例以新建一个 “GLUE模式(Java)” 运行模式的任务为例。更多有关任务的详细配置,请查看“章节三:任务详解”。 ( “GLUE模式(Java)”的执行代码托管到调度中心在线维护,相比“Bean模式任务”需要在执行器项目开发部署上线,更加简便轻量)
前提:请确认“调度中心”和“执行器”项目已经成功部署并启动;
步骤一:新建任务:
登录调度中心,点击下图所示“新建任务”按钮,新建示例任务。然后,参考下面截图中任务的参数配置,点击保存。
步骤二:“GLUE模式(Java)” 任务开发:
请点击任务右侧 “GLUE” 按钮,进入 “GLUE编辑器开发界面” ,见下图。“GLUE模式(Java)” 运行模式的任务默认已经初始化了示例任务代码,即打印Hello World。 ( “GLUE模式(Java)” 运行模式的任务实际上是一段继承自IJobHandler的Java类代码,它在执行器项目中运行,可使用@Resource/@Autowire注入执行器里中的其他服务,详细介绍请查看第三章节)

步骤三:触发执行:
请点击任务右侧 “执行” 按钮,可手动触发一次任务执行(通常情况下,通过配置Cron表达式进行任务调度出发)。
步骤四:查看日志:
请点击任务右侧 “日志” 按钮,可前往任务日志界面查看任务日志。 在任务日志界面中,可查看该任务的历史调度记录以及每一次调度的任务调度信息、执行参数和执行信息。运行中的任务点击右侧的“执行日志”按钮,可进入日志控制台查看实时执行日志。
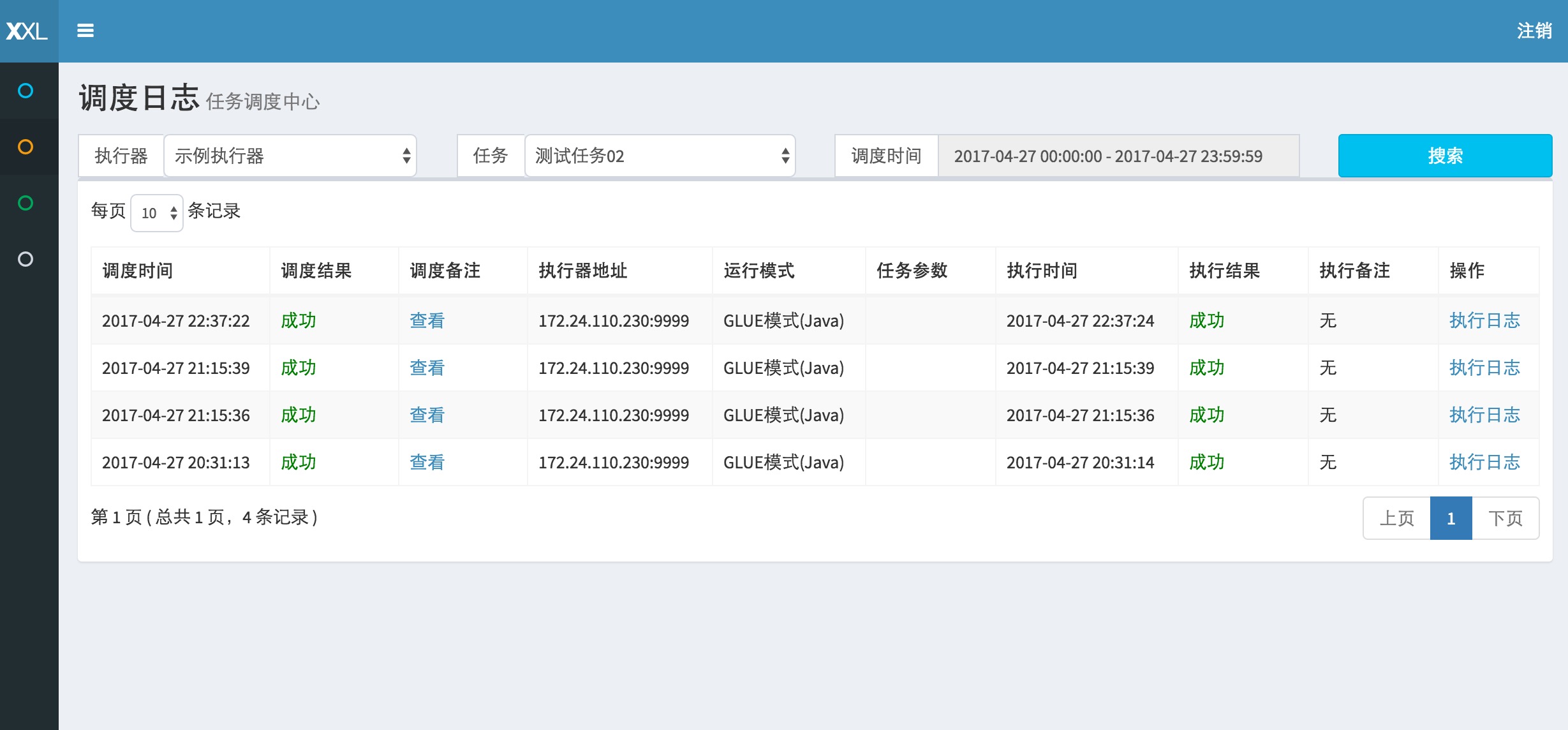
在日志控制台,可以Rolling方式实时查看任务在执行器一侧运行输出的日志信息,实时监控任务进度;
三、任务详解
配置属性详细说明:
- - 执行器:任务的绑定的执行器,任务触发调度时将会自动发现注册成功的执行器, 实现任务自动发现功能; 另一方面也可以方便的进行任务分组。每个任务必须绑定一个执行器, 可在 "执行器管理" 进行设置;
- - 描述:任务的描述信息,便于任务管理;
- - 路由策略:当执行器集群部署时,提供丰富的路由策略,包括;
- FIRST(第一个):固定选择第一个机器;
- LAST(最后一个):固定选择最后一个机器;
- ROUND(轮询):;
- RANDOM(随机):随机选择在线的机器;
- CONSISTENT_HASH(一致性HASH):每个任务按照Hash算法固定选择某一台机器,且所有任务均匀散列在不同机器上。
- LEAST_FREQUENTLY_USED(最不经常使用):使用频率最低的机器优先被选举;
- LEAST_RECENTLY_USED(最近最久未使用):最久为使用的机器优先被选举;
- FAILOVER(故障转移):按照顺序依次进行心跳检测,第一个心跳检测成功的机器选定为目标执行器并发起调度;
- BUSYOVER(忙碌转移):按照顺序依次进行空闲检测,第一个空闲检测成功的机器选定为目标执行器并发起调度;
- SHARDING_BROADCAST(分片广播):广播触发对应集群中所有机器执行一次任务,同时传递分片参数;可根据分片参数开发分片任务;
-
- - Cron:触发任务执行的Cron表达式;
- - 运行模式:
- BEAN模式:任务以JobHandler方式维护在执行器端;需要结合 "JobHandler" 属性匹配执行器中任务;
- GLUE模式(Java):任务以源码方式维护在调度中心;该模式的任务实际上是一段继承自IJobHandler的Java类代码并 "groovy" 源码方式维护,它在执行器项目中运行,可使用@Resource/@Autowire注入执行器里中的其他服务;
- GLUE模式(Shell):任务以源码方式维护在调度中心;该模式的任务实际上是一段 "shell" 脚本;
- GLUE模式(Python):任务以源码方式维护在调度中心;该模式的任务实际上是一段 "python" 脚本;
- GLUE模式(NodeJS):任务以源码方式维护在调度中心;该模式的任务实际上是一段 "nodejs" 脚本;
- - JobHandler:运行模式为 "BEAN模式" 时生效,对应执行器中新开发的JobHandler类“@JobHandler”注解自定义的value值;
- - 子任务:每个任务都拥有一个唯一的任务ID(任务ID可以从任务列表获取),当本任务执行结束并且执行成功时,将会触发子任务ID所对应的任务的一次主动调度。
- - 阻塞处理策略:调度过于密集执行器来不及处理时的处理策略;
- 单机串行(默认):调度请求进入单机执行器后,调度请求进入FIFO队列并以串行方式运行;
- 丢弃后续调度:调度请求进入单机执行器后,发现执行器存在运行的调度任务,本次请求将会被丢弃并标记为失败;
- 覆盖之前调度:调度请求进入单机执行器后,发现执行器存在运行的调度任务,将会终止运行中的调度任务并清空队列,然后运行本地调度任务;
- - 失败处理策略;调度失败时的处理策略;
- 失败告警(默认):调度失败和执行失败时,都将会触发失败报警,默认会发送报警邮件;
- 失败重试:调度失败时,除了进行失败告警之外,将会自动重试一次;注意在执行失败时不会重试,而是根据回调返回值判断是否重试;
- - 执行参数:任务执行所需的参数,多个参数时用逗号分隔,任务执行时将会把多个参数转换成数组传入;
- - 报警邮件:任务调度失败时邮件通知的邮箱地址,支持配置多邮箱地址,配置多个邮箱地址时用逗号分隔;
- - 负责人:任务的负责人;
3.1 BEAN模式
任务逻辑以JobHandler的形式存在于“执行器”所在项目中,开发流程如下:
步骤一:执行器项目中,开发JobHandler:
- - 1、继承"IJobHandler":“com.xxl.job.core.handler.IJobHandler”;
- - 2、注册到Spring容器:添加“@Component”注解,被Spring容器扫描为Bean实例;
- - 3、注册到执行器工厂:添加“@JobHandler(value="自定义jobhandler名称")”注解,注解value值对应的是调度中心新建任务的JobHandler属性的值。
- - 4、执行日志:需要通过 "XxlJobLogger.log" 打印执行日志;
- (可参考Sample示例执行器中的DemoJobHandler,见下图)

步骤二:调度中心,新建调度任务
参考上文“配置属性详细说明”对新建的任务进行参数配置,运行模式选中 "BEAN模式",JobHandler属性填写任务注解“@JobHandler”中定义的值;
3.2 GLUE模式(Java)
任务以源码方式维护在调度中心,支持通过Web IDE在线更新,实时编译和生效,因此不需要指定JobHandler。开发流程如下:
步骤一:调度中心,新建调度任务:
参考上文“配置属性详细说明”对新建的任务进行参数配置,运行模式选中 "GLUE模式(Java)";
步骤二:开发任务代码:
选中指定任务,点击该任务右侧“GLUE”按钮,将会前往GLUE任务的Web IDE界面,在该界面支持对任务代码进行开发(也可以在IDE中开发完成后,复制粘贴到编辑中)。
版本回溯功能(支持30个版本的版本回溯):在GLUE任务的Web IDE界面,选择右上角下拉框“版本回溯”,会列出该GLUE的更新历史,选择相应版本即可显示该版本代码,保存后GLUE代码即回退到对应的历史版本;
3.3 GLUE模式(Shell)
步骤一:调度中心,新建调度任务
参考上文“配置属性详细说明”对新建的任务进行参数配置,运行模式选中 "GLUE模式(Shell)";
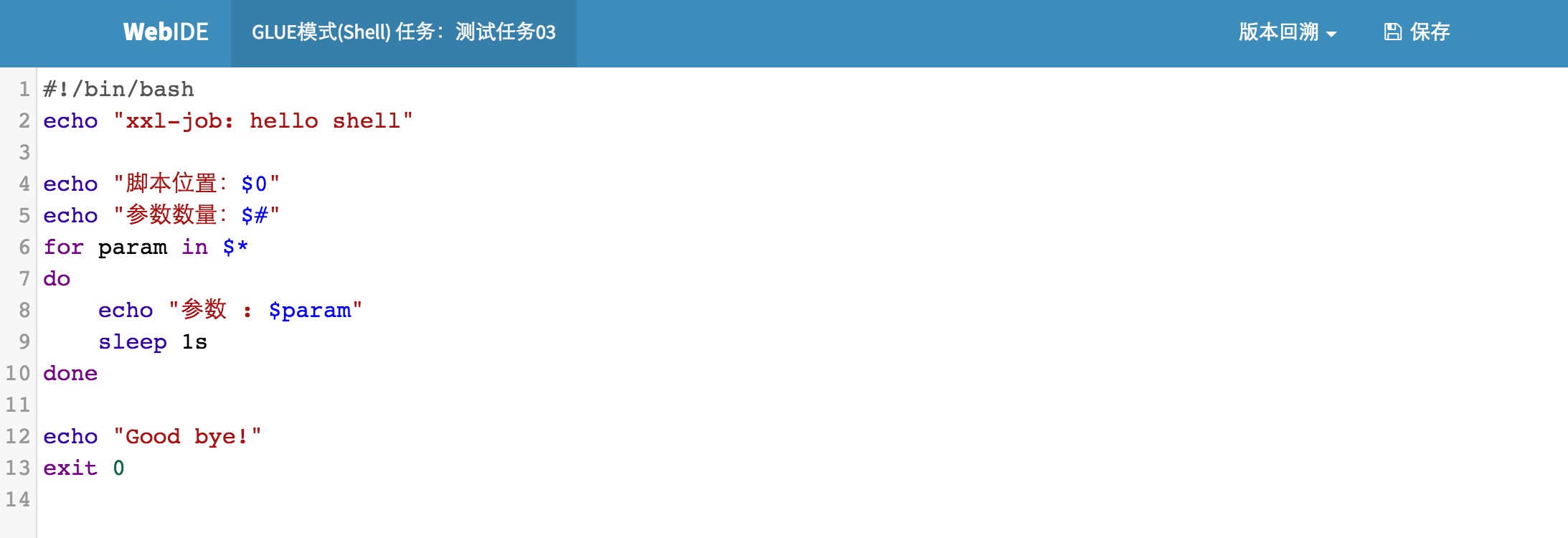
步骤二:开发任务代码:
选中指定任务,点击该任务右侧“GLUE”按钮,将会前往GLUE任务的Web IDE界面,在该界面支持对任务代码进行开发(也可以在IDE中开发完成后,复制粘贴到编辑中)。
该模式的任务实际上是一段 "shell" 脚本;
3.4 GLUE模式(Python)
步骤一:调度中心,新建调度任务
参考上文“配置属性详细说明”对新建的任务进行参数配置,运行模式选中 "GLUE模式(Python)";
步骤二:开发任务代码:
选中指定任务,点击该任务右侧“GLUE”按钮,将会前往GLUE任务的Web IDE界面,在该界面支持对任务代码进行开发(也可以在IDE中开发完成后,复制粘贴到编辑中)。
该模式的任务实际上是一段 "python" 脚本;
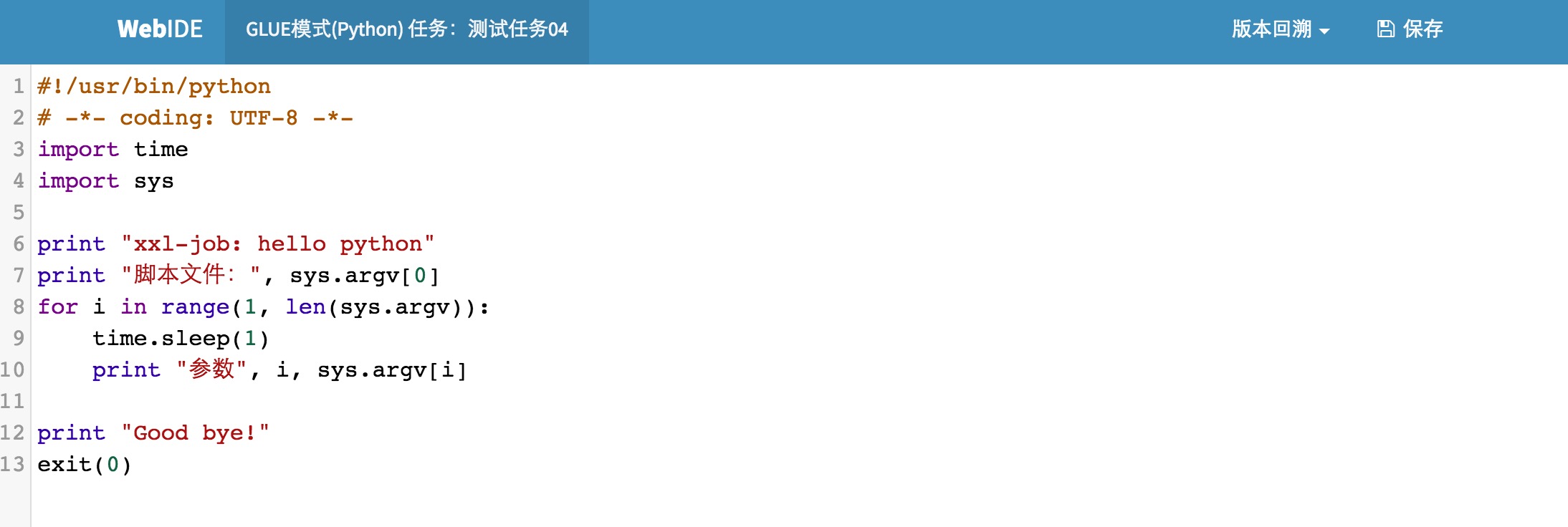
3.5 GLUE模式(NodeJS)
步骤一:调度中心,新建调度任务
参考上文“配置属性详细说明”对新建的任务进行参数配置,运行模式选中 "GLUE模式(NodeJS)";
步骤二:开发任务代码:
选中指定任务,点击该任务右侧“GLUE”按钮,将会前往GLUE任务的Web IDE界面,在该界面支持对任务代码进行开发(也可以在IDE中开发完成后,复制粘贴到编辑中)。
该模式的任务实际上是一段 "nodejS" 脚本;
四、任务管理
4.0 配置执行器
点击进入"执行器管理"界面, 如下图: 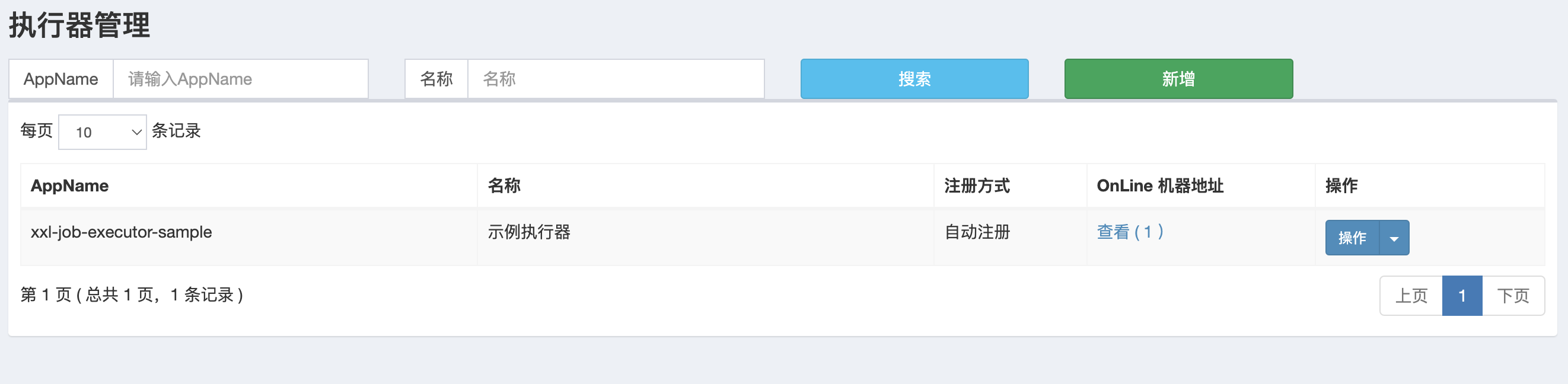
- 1、"调度中心OnLine:"右侧显示在线的"调度中心"列表, 任务执行结束后, 将会以failover的模式进行回调调度中心通知执行结果, 避免回调的单点风险;
- 2、"执行器列表" 中显示在线的执行器列表, 可通过"OnLine 机器"查看对应执行器的集群机器。
点击按钮 "+新增执行器" 弹框如下图, 可新增执行器配置:
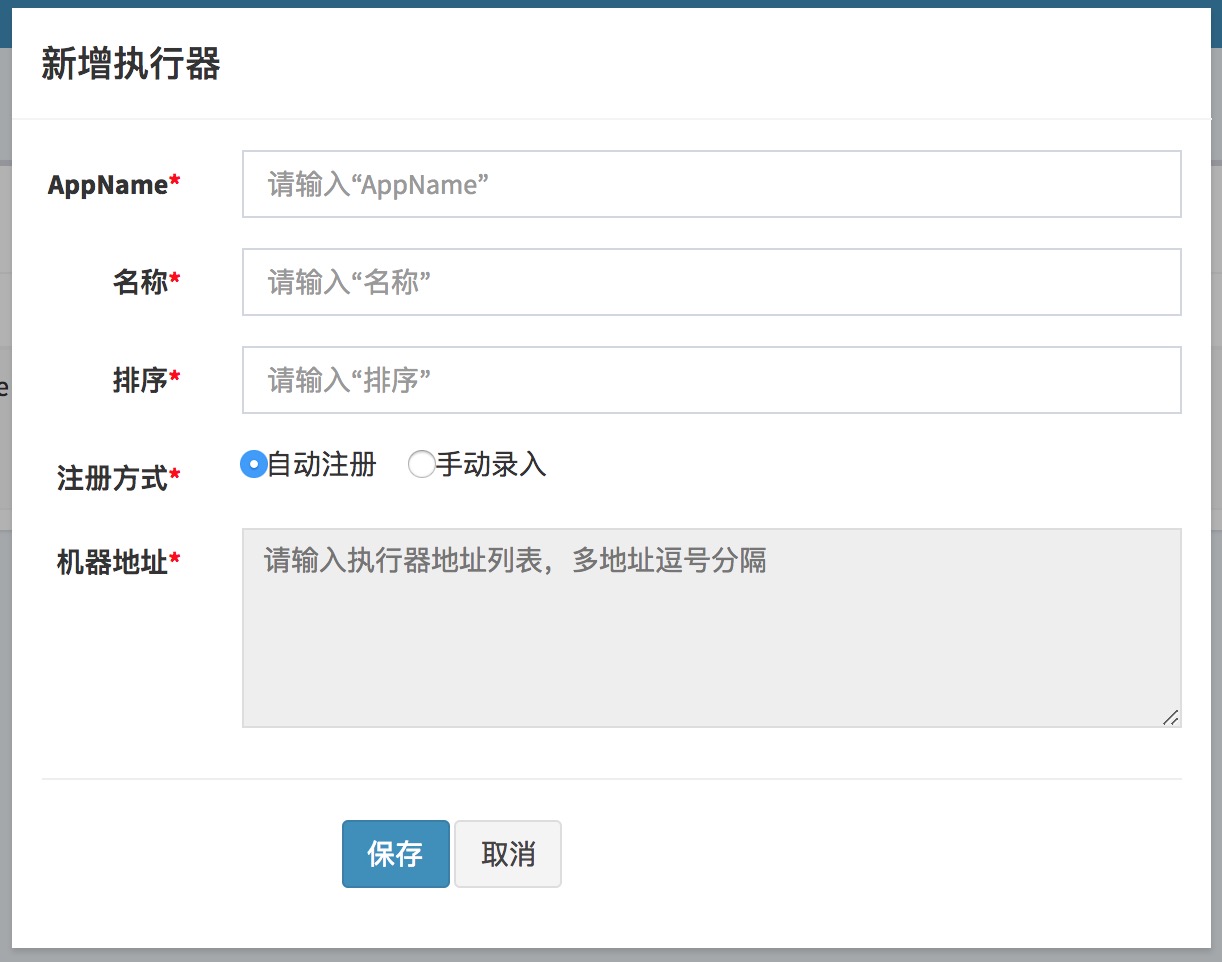
执行器属性说明
- AppName: 是每个执行器集群的唯一标示AppName, 执行器会周期性以AppName为对象进行自动注册。可通过该配置自动发现注册成功的执行器, 供任务调度时使用;
- 名称: 执行器的名称, 因为AppName限制字母数字等组成,可读性不强, 名称为了提高执行器的可读性;
- 排序: 执行器的排序, 系统中需要执行器的地方,如任务新增, 将会按照该排序读取可用的执行器列表;
- 注册方式:调度中心获取执行器地址的方式;
- 自动注册:执行器自动进行执行器注册,调度中心通过底层注册表可以动态发现执行器机器地址;
- 手动录入:人工手动录入执行器的地址信息,多地址逗号分隔,供调度中心使用;
- 机器地址:"注册方式"为"手动录入"时有效,支持人工维护执行器的地址信息;
4.1 新建任务
进入任务管理界面,点击“新增任务”按钮,在弹出的“新增任务”界面配置任务属性后保存即可。详情页参考章节 "三、任务详解"。
4.2 编辑任务
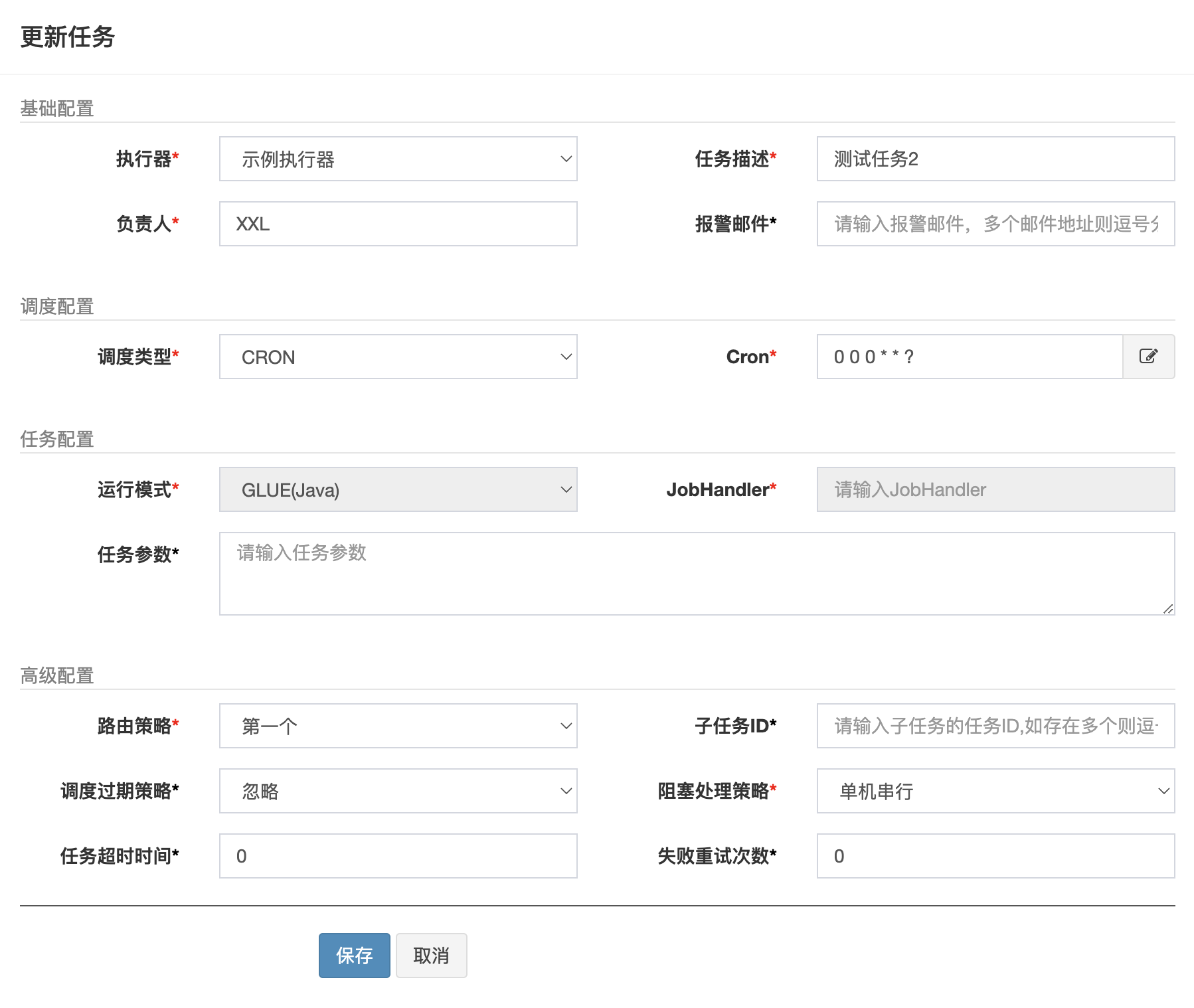
进入任务管理界面,选中指定任务。点击该任务右侧“编辑”按钮,在弹出的“编辑任务”界面更新任务属性后保存即可,可以修改设置的任务属性信息:
4.3 编辑GLUE代码
该操作仅针对GLUE任务。
选中指定任务,点击该任务右侧“GLUE”按钮,将会前往GLUE任务的Web IDE界面,在该界面支持对任务代码进行开发。可参考章节 "3.2 GLUE模式(Java)"。
4.4 暂停/恢复任务
可对任务进行“暂停”和“恢复”操作。 需要注意的是,此处的暂停/恢复仅针对任务的后续调度触发行为,不会影响到已经触发的调度任务,如需终止已经触发的调度任务,可查看“4.8 终止运行中的任务”

4.5 手动触发一次调度
点击“执行”按钮,可手动触发一次任务调度,不影响原有调度规则。

4.6 查看调度日志
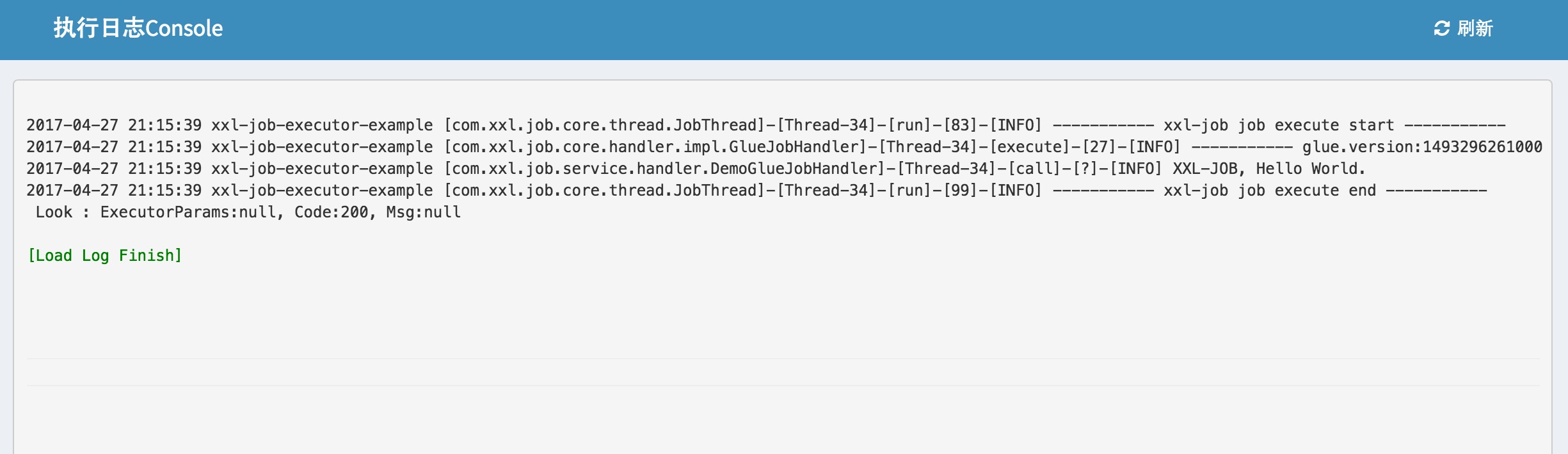
点击“日志”按钮,可以查看任务历史调度日志。在历史调入日志界面可查看每次任务调度的调度结果、执行结果等,点击“执行日志”按钮可查看执行器完整日志。

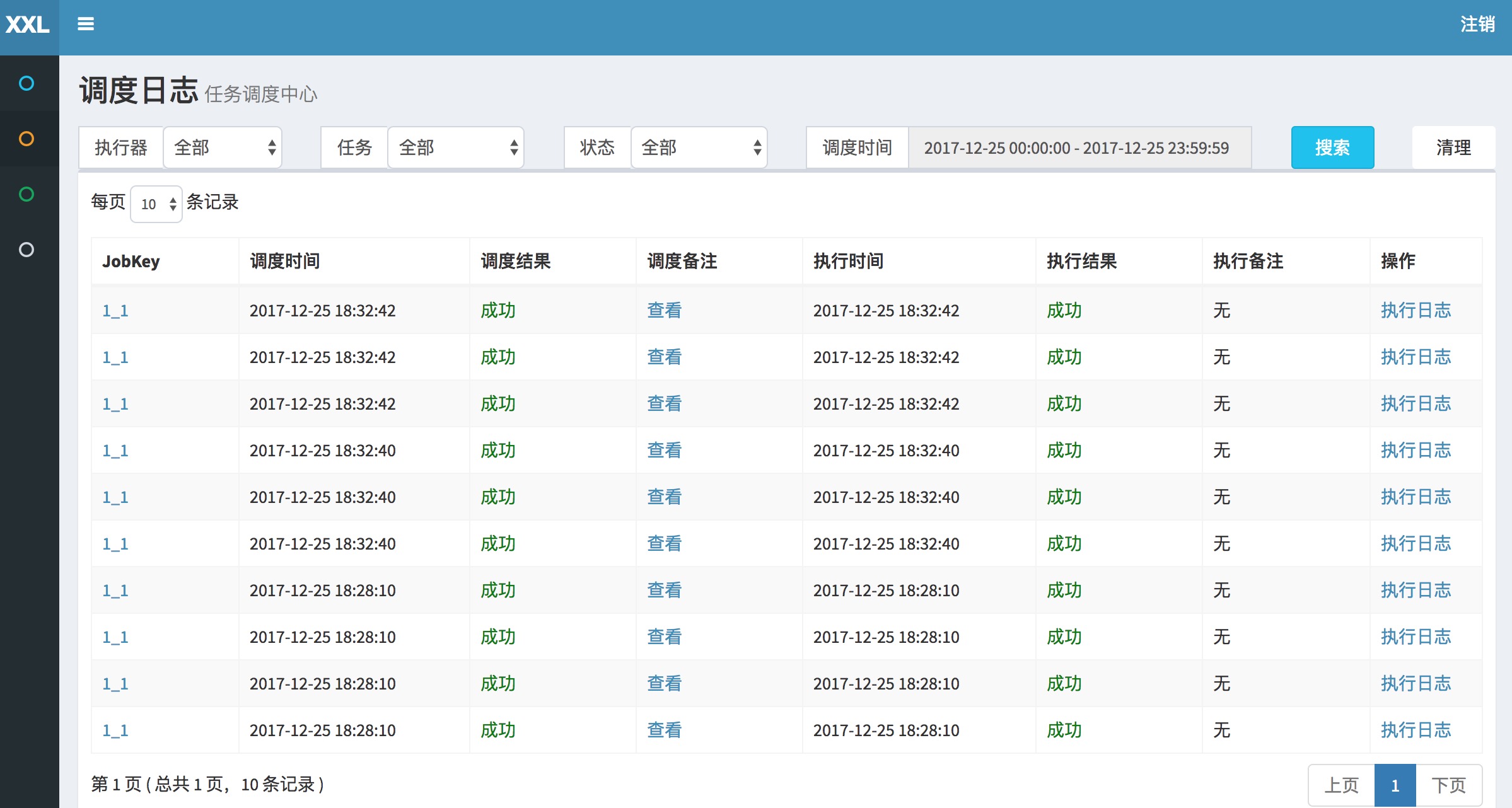
- 调度时间:"调度中心"触发本次调度并向"执行器"发送任务执行信号的时间;
- 调度结果:"调度中心"触发本次调度的结果,200表示成功,500或其他表示失败;
- 调度备注:"调度中心"触发本次调度的日志信息;
- 执行器地址:本次任务执行的机器地址
- 运行模式:触发调度时任务的运行模式,运行模式可参考章节 "三、任务详解";
- 任务参数:本地任务执行的入参
- 执行时间:"执行器"中本次任务执行结束后回调的时间;
- 执行结果:"执行器"中本次任务执行的结果,200表示成功,500或其他表示失败;
- 执行备注:"执行器"中本次任务执行的日志信息;
- 操作:
- "执行日志"按钮:点击可查看本地任务执行的详细日志信息;详见“4.7 查看执行日志”;
- "终止任务"按钮:点击可终止本地调度对应执行器上本任务的执行线程,包括未执行的阻塞任务一并被终止;
4.7 查看执行日志
点击执行日志右侧的 “执行日志” 按钮,可跳转至执行日志界面,可以查看业务代码中打印的完整日志,如下图;

4.8 终止运行中的任务
仅针对执行中的任务。 在任务日志界面,点击右侧的“终止任务”按钮,将会向本次任务对应的执行器发送任务终止请求,将会终止掉本次任务,同时会清空掉整个任务执行队列。

任务终止时通过 "interrupt" 执行线程的方式实现, 将会触发 "InterruptedException" 异常。因此如果JobHandler内部catch到了该异常并消化掉的话, 任务终止功能将不可用。
因此, 如果遇到上述任务终止不可用的情况, 需要在JobHandler中应该针对 "InterruptedException" 异常进行特殊处理 (向上抛出) , 正确逻辑如下:
- try{
- // TODO
- } catch (Exception e) {
- if (e instanceof InterruptedException) {
- throw e;
- }
- logger.warn("{}", e);
- }
而且,在JobHandler中开启子线程时,子线程也不可catch处理"InterruptedException",应该主动向上抛出。
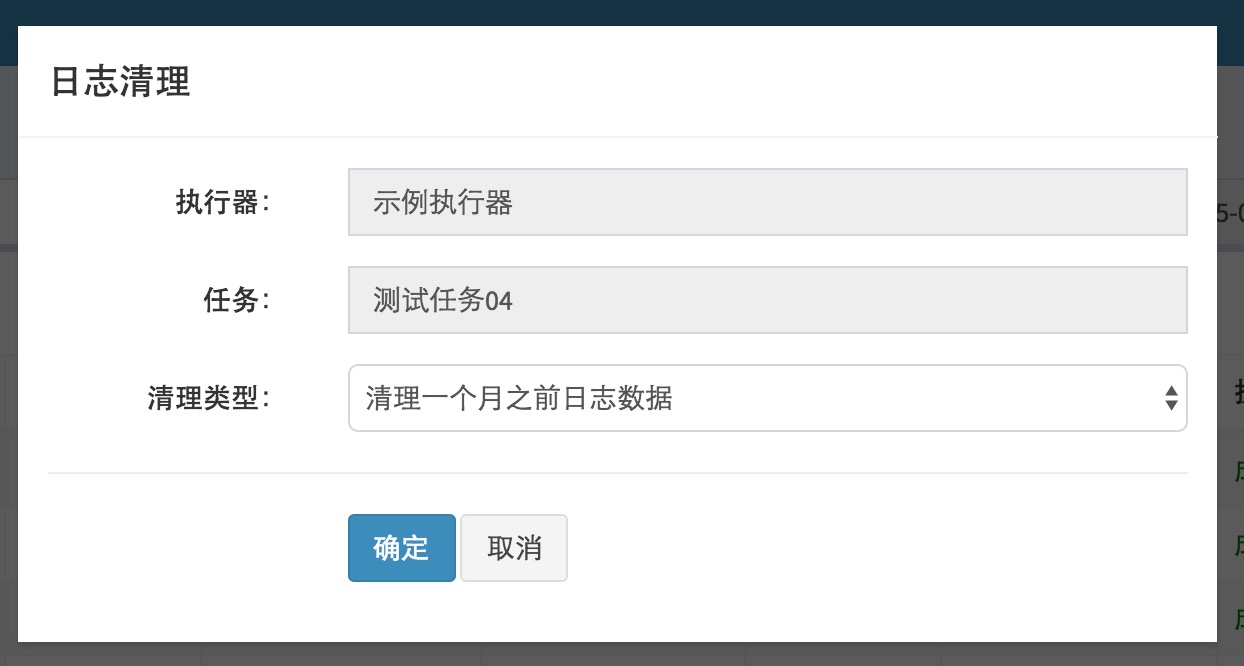
4.9 删除执行日志
在任务日志界面,选中执行器和任务之后,点击右侧的"删除"按钮将会出现"日志清理"弹框,弹框中支持选择不同类型的日志清理策略,选中后点击"确定"按钮即可进行日志清理操作; 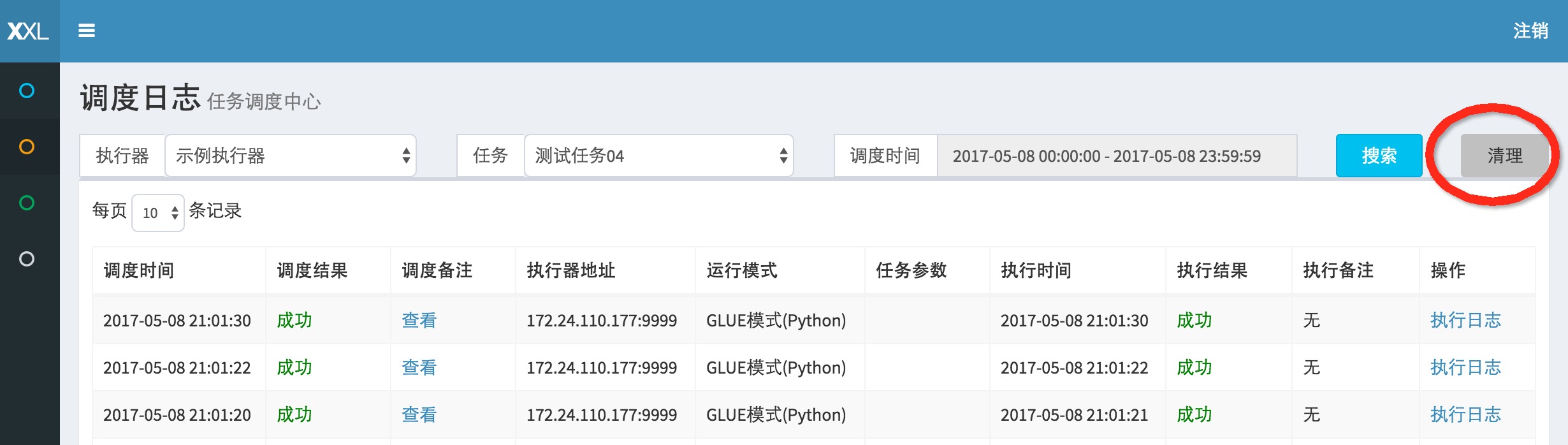
4.10 删除任务
点击删除按钮,可以删除对应任务。

五、总体设计
5.1 源码目录介绍
- - /doc :文档资料
- - /db :“调度数据库”建表脚本
- - /xxl-job-admin :调度中心,项目源码
- - /xxl-job-core :公共Jar依赖
- - /xxl-job-executor-samples :执行器,Sample示例项目(大家可以在该项目上进行开发,也可以将现有项目改造生成执行器项目)
5.2 “调度数据库”配置
XXL-JOB调度模块基于Quartz集群实现,其“调度数据库”是在Quartz的11张集群mysql表基础上扩展而成。
XXL-JOB首先定制了Quartz原生表结构前缀(XXL_JOB_QRTZ_)。

然后,在此基础上新增了几张张扩展表,如下: - XXL_JOB_QRTZ_TRIGGER_GROUP:执行器信息表,维护任务执行器信息; - XXL_JOB_QRTZ_TRIGGER_REGISTRY:执行器注册表,维护在线的执行器和调度中心机器地址信息; - XXL_JOB_QRTZ_TRIGGER_INFO:调度扩展信息表: 用于保存XXL-JOB调度任务的扩展信息,如任务分组、任务名、机器地址、执行器、执行入参和报警邮件等等; - XXL_JOB_QRTZ_TRIGGER_LOG:调度日志表: 用于保存XXL-JOB任务调度的历史信息,如调度结果、执行结果、调度入参、调度机器和执行器等等; - XXL_JOB_QRTZ_TRIGGER_LOGGLUE:任务GLUE日志:用于保存GLUE更新历史,用于支持GLUE的版本回溯功能;
因此,XXL-JOB调度数据库共计用于16张数据库表。
5.3 架构设计
5.3.1 设计思想
将调度行为抽象形成“调度中心”公共平台,而平台自身并不承担业务逻辑,“调度中心”负责发起调度请求。
将任务抽象成分散的JobHandler,交由“执行器”统一管理,“执行器”负责接收调度请求并执行对应的JobHandler中业务逻辑。
因此,“调度”和“任务”两部分可以相互解耦,提高系统整体稳定性和扩展性;
5.3.2 系统组成
- 调度模块(调度中心): 负责管理调度信息,按照调度配置发出调度请求,自身不承担业务代码。调度系统与任务解耦,提高了系统可用性和稳定性,同时调度系统性能不再受限于任务模块; 支持可视化、简单且动态的管理调度信息,包括任务新建,更新,删除,GLUE开发和任务报警等,所有上述操作都会实时生效,同时支持监控调度结果以及执行日志,支持执行器Failover。
- 执行模块(执行器): 负责接收调度请求并执行任务逻辑。任务模块专注于任务的执行等操作,开发和维护更加简单和高效; 接收“调度中心”的执行请求、终止请求和日志请求等。
5.3.3 架构图
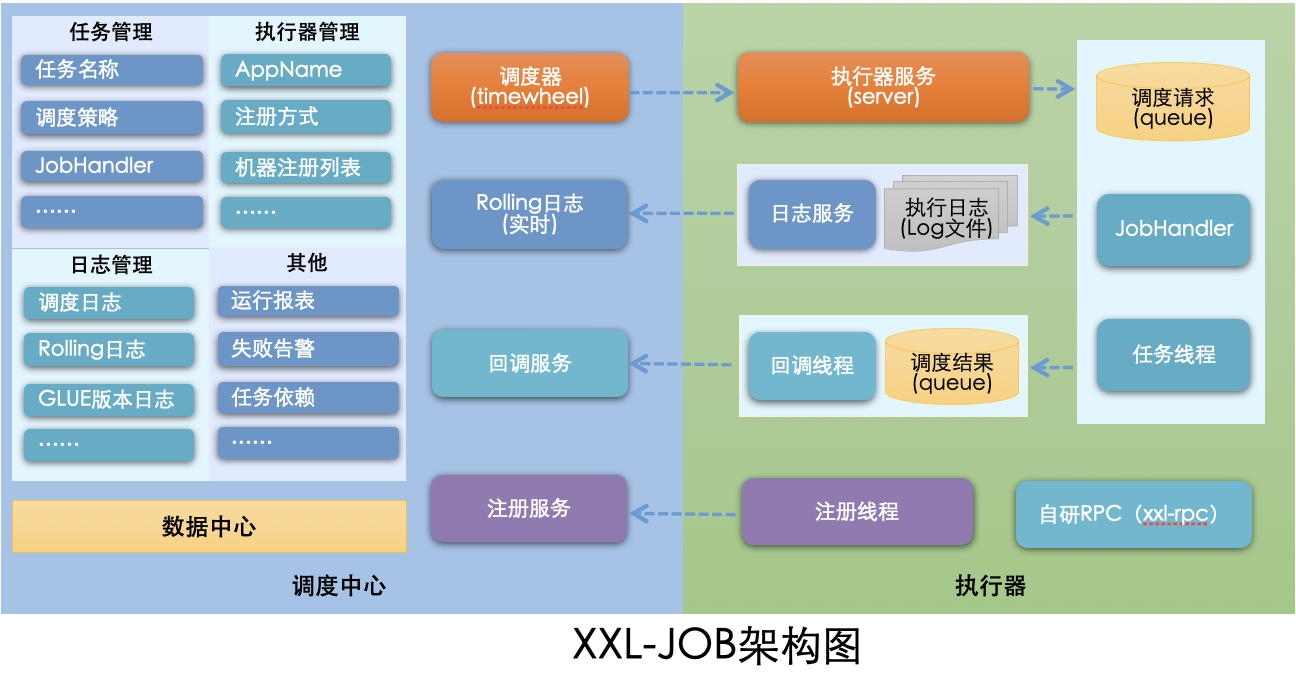
5.4 调度模块剖析
5.4.1 quartz的不足
Quartz作为开源作业调度中的佼佼者,是作业调度的首选。但是集群环境中Quartz采用API的方式对任务进行管理,从而可以避免上述问题,但是同样存在以下问题: - 问题一:调用API的的方式操作任务,不人性化; - 问题二:需要持久化业务QuartzJobBean到底层数据表中,系统侵入性相当严重。 - 问题三:调度逻辑和QuartzJobBean耦合在同一个项目中,这将导致一个问题,在调度任务数量逐渐增多,同时调度任务逻辑逐渐加重的情况加,此时调度系统的性能将大大受限于业务; XXL-JOB弥补了quartz的上述不足之处。
5.4.2 RemoteHttpJobBean
常规Quartz的开发,任务逻辑一般维护在QuartzJobBean中,耦合很严重。XXL-JOB中“调度模块”和“任务模块”完全解耦,调度模块中的所有调度任务使用同一个QuartzJobBean,即RemoteHttpJobBean。不同的调度任务将各自参数维护在各自扩展表数据中,当触发RemoteHttpJobBean执行时,将会解析不同的任务参数发起远程调用,调用各自的远程执行器服务。
这种调用模型类似RPC调用,RemoteHttpJobBean提供调用代理的功能,而执行器提供远程服务的功能。
5.4.3 调度中心HA(集群)
基于Quartz的集群方案,数据库选用Mysql;集群分布式并发环境中使用QUARTZ定时任务调度,会在各个节点会上报任务,存到数据库中,执行时会从数据库中取出触发器来执行,如果触发器的名称和执行时间相同,则只有一个节点去执行此任务。
- # for cluster
- org.quartz.jobStore.tablePrefix = XXL_JOB_QRTZ_
- org.quartz.scheduler.instanceId: AUTO
- org.quartz.jobStore.class: org.quartz.impl.jdbcjobstore.JobStoreTX
- org.quartz.jobStore.isClustered: true
- org.quartz.jobStore.clusterCheckinInterval: 1000
5.4.4 调度线程池
调度采用线程池方式实现,避免单线程因阻塞而引起任务调度延迟。
- org.quartz.threadPool.class: org.quartz.simpl.SimpleThreadPool
- org.quartz.threadPool.threadCount: 15
- org.quartz.threadPool.threadPriority: 5
- org.quartz.threadPool.threadsInheritContextClassLoaderOfInitializingThread: true
XXL-JOB系统中业务逻辑在远程执行器执行,全异步化设计,调度中心每次触发调度时仅发送一次调度请求,执行器会将请求存入执行队列并且立即响应调度中心,异步运行;相比直接在quartz的QuartzJobBean中执行业务逻辑,极大的降低了调度线程占用时间;
XXL-JOB调度中心中每个JOB逻辑非常 “轻”,单个JOB一次运行平均耗时基本在 "10ms" 之内(基本为一次请求的网络开销);因此,可以保证使用有限的线程支撑大量的JOB并发运行;
理论支撑任务量公式如下:
理论支撑任务量 = 线程数配置 / 平均调度频率(每秒) * 平均触发耗时(单位s)
理论上采用推荐机器配置 "4核4G内存" + "配置1s运行1次密集任务" + "调度中心与执行器ping延迟10ms(0.01s)" 的情况下,
- - 单线程支撑任务量 :1 / 1 * 0.01 = 100个任务
- - 15个线程支撑任务量:15 / 1 * 0.01 = 1500个任务
实际场景中,由于调度中心与执行器ping延迟不同、DB读写耗时不同、任务调度密集程度不同,会导致任务量上限会上下波动。
如若需要支撑更多的任务量,可以通过 "调大调度线程数" 、"降低调度中心与执行器ping延迟" 和 "提升机器配置" 几种方式实现。
5.4.5 @DisallowConcurrentExecution
XXL-JOB调度模块的“调度中心”默认不使用该注解,即默认开启并行机制,因为RemoteHttpJobBean为公共QuartzJobBean,这样在多线程调度的情况下,调度模块被阻塞的几率很低,大大提高了调度系统的承载量。
XXL-JOB的每个调度任务虽然在调度模块是并行调度执行的,但是任务调度传递到任务模块的“执行器”确实串行执行的,同时支持任务终止。
5.4.6 misfire
错过了触发时间,处理规则。 可能原因:服务重启;调度线程被QuartzJobBean阻塞,线程被耗尽;某个任务启用了@DisallowConcurrentExecution,上次调度持续阻塞,下次调度被错过;
quartz.properties中关于misfire的阀值配置如下,单位毫秒:
org.quartz.jobStore.misfireThreshold: 60000
Misfire规则: withMisfireHandlingInstructionDoNothing:不触发立即执行,等待下次调度; withMisfireHandlingInstructionIgnoreMisfires:以错过的第一个频率时间立刻开始执行; withMisfireHandlingInstructionFireAndProceed:以当前时间为触发频率立刻触发一次执行;
XXL-JOB默认misfire规则为:withMisfireHandlingInstructionDoNothing
- CronScheduleBuilder cronScheduleBuilder = CronScheduleBuilder.cronSchedule(jobInfo.getJobCron()).withMisfireHandlingInstructionDoNothing();
- CronTrigger cronTrigger = TriggerBuilder.newTrigger().withIdentity(triggerKey).withSchedule(cronScheduleBuilder).build();
5.4.7 日志回调服务
调度模块的“调度中心”作为Web服务部署时,一方面承担调度中心功能,另一方面也为执行器提供API服务。
调度中心提供的"日志回调服务API服务"代码位置如下:
xxl-job-admin#com.xxl.job.admin.controller.JobApiController.callback
“执行器”在接收到任务执行请求后,执行任务,在执行结束之后会将执行结果回调通知“调度中心”:
5.4.8 任务HA(Failover)
执行器如若集群部署,调度中心将会感知到在线的所有执行器,如“127.0.0.1:9997, 127.0.0.1:9998, 127.0.0.1:9999”。
当任务"路由策略"选择"故障转移(FAILOVER)"时,当调度中心每次发起调度请求时,会按照顺序对执行器发出心跳检测请求,第一个检测为存活状态的执行器将会被选定并发送调度请求。
调度成功后,可在日志监控界面查看“调度备注”,如下; 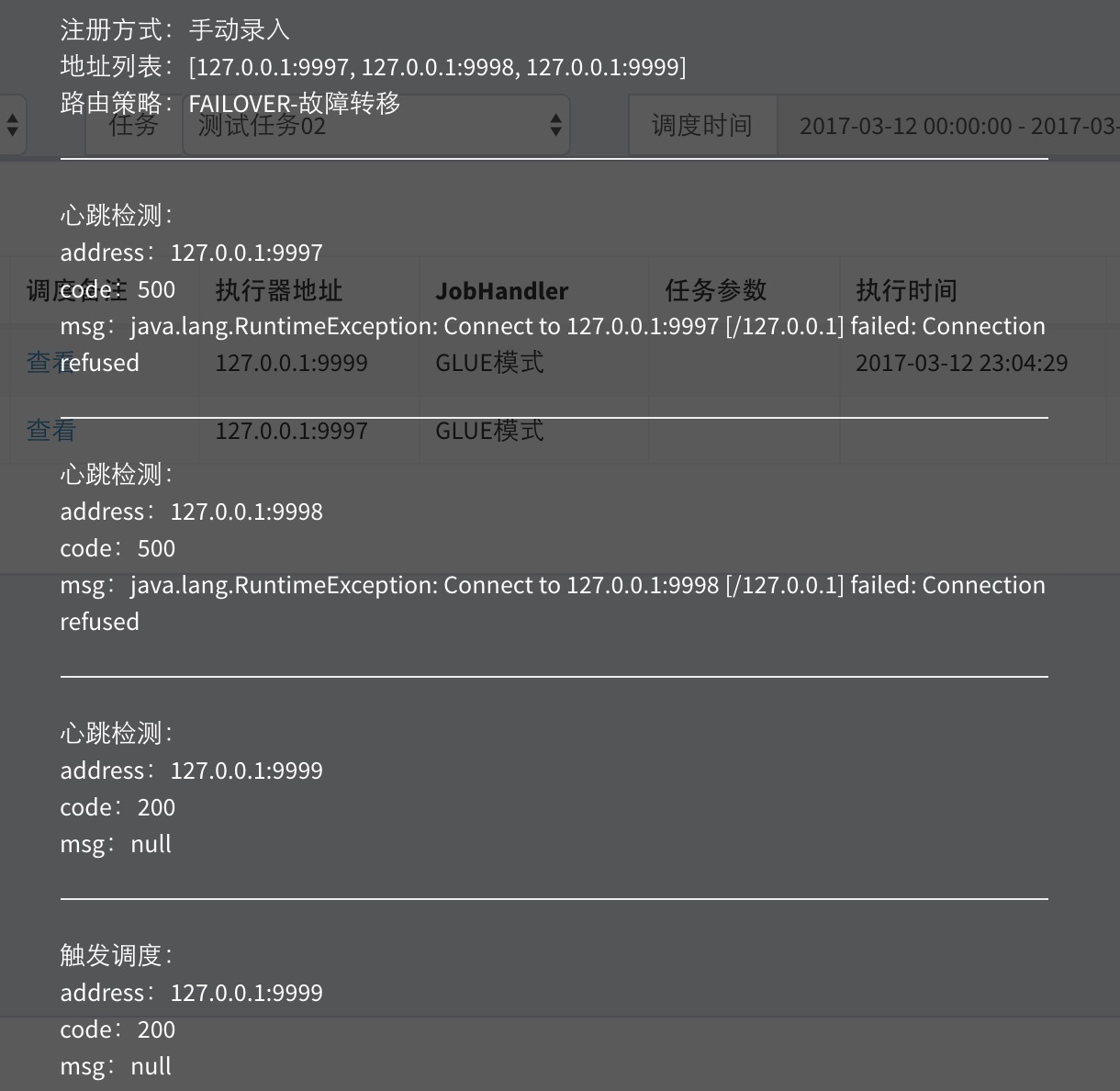
“调度备注”可以看出本地调度运行轨迹,执行器的"注册方式"、"地址列表"和任务的"路由策略"。"故障转移(FAILOVER)"路由策略下,调度中心首先对第一个地址进行心跳检测,心跳失败因此自动跳过,第二个依然心跳检测失败…… 直至心跳检测第三个地址“127.0.0.1:9999”成功,选定为“目标执行器”;然后对“目标执行器”发送调度请求,调度流程结束,等待执行器回调执行结果。
5.4.9 调度日志
调度中心每次进行任务调度,都会记录一条任务日志,任务日志主要包括以下三部分内容:
- 任务信息:包括“执行器地址”、“JobHandler”和“执行参数”等属性,点击任务ID按钮可查看,根据这些参数,可以精确的定位任务执行的具体机器和任务代码;
- 调度信息:包括“调度时间”、“调度结果”和“调度日志”等,根据这些参数,可以了解“调度中心”发起调度请求时具体情况。
- 执行信息:包括“执行时间”、“执行结果”和“执行日志”等,根据这些参数,可以了解在“执行器”端任务执行的具体情况;
调度日志,针对单次调度,属性说明如下:
- 执行器地址:任务执行的机器地址;
- JobHandler:Bean模式表示任务执行的JobHandler名称;
- 任务参数:任务执行的入参;
- 调度时间:调度中心,发起调度的时间;
- 调度结果:调度中心,发起调度的结果,SUCCESS或FAIL;
- 调度备注:调度中心,发起调度的备注信息,如地址心跳检测日志等;
- 执行时间:执行器,任务执行结束后回调的时间;
- 执行结果:执行器,任务执行的结果,SUCCESS或FAIL;
- 执行备注:执行器,任务执行的备注信息,如异常日志等;
- 执行日志:任务执行过程中,业务代码中打印的完整执行日志,见“4.7 查看执行日志”;
5.4.10 任务依赖
原理:XXL-JOB中每个任务都对应有一个任务ID,同时,每个任务支持设置属性“子任务ID”,因此,通过“任务ID”可以匹配任务依赖关系。
当父任务执行结束并且执行成功时,将会根据“子任务ID”匹配子任务依赖,如果匹配到子任务,将会主动触发一次子任务的执行。
在任务日志界面,点击任务的“执行备注”的“查看”按钮,可以看到匹配子任务以及触发子任务执行的日志信息,如无信息则表示未触发子任务执行,可参考下图。

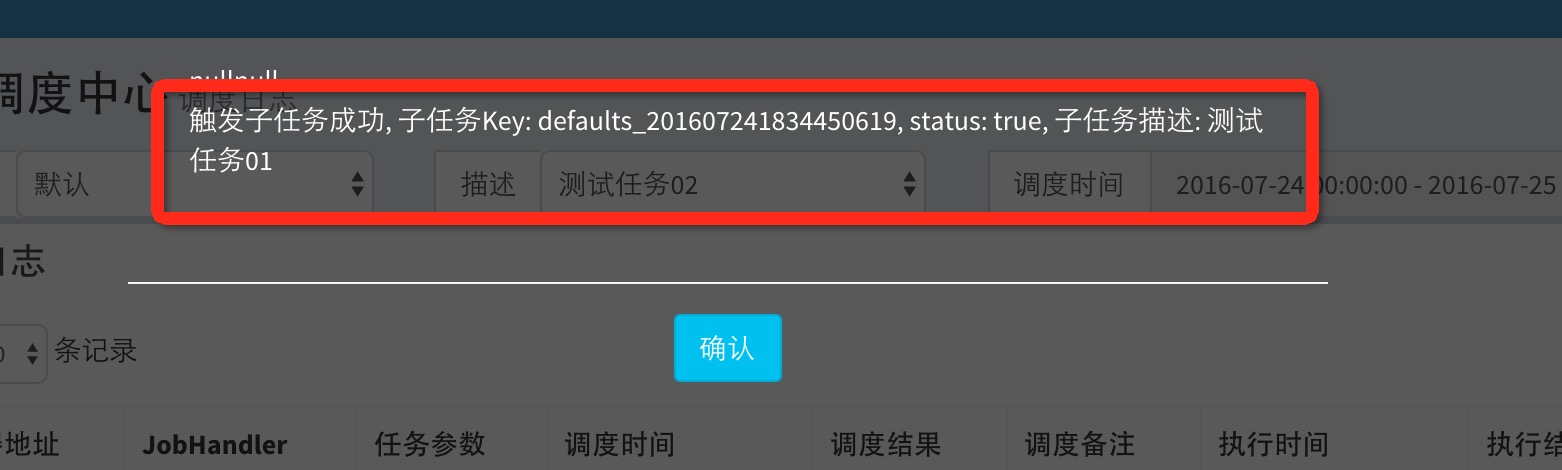
5.5 任务 "运行模式" 剖析
5.5.1 "Bean模式" 任务
开发步骤:可参考 "章节三" ; 原理:每个Bean模式任务都是一个Spring的Bean类实例,它被维护在“执行器”项目的Spring容器中。任务类需要加“@JobHandler(value="名称")”注解,因为“执行器”会根据该注解识别Spring容器中的任务。任务类需要继承统一接口“IJobHandler”,任务逻辑在execute方法中开发,因为“执行器”在接收到调度中心的调度请求时,将会调用“IJobHandler”的execute方法,执行任务逻辑。
5.5.2 "GLUE模式(Java)" 任务
开发步骤:可参考 "章节三" ; 原理:每个 "GLUE模式(Java)" 任务的代码,实际上是“一个继承自“IJobHandler”的实现类的类代码”,“执行器”接收到“调度中心”的调度请求时,会通过Groovy类加载器加载此代码,实例化成Java对象,同时注入此代码中声明的Spring服务(请确保Glue代码中的服务和类引用在“执行器”项目中存在),然后调用该对象的execute方法,执行任务逻辑。
5.5.3 GLUE模式(Shell) + GLUE模式(Python) + GLUE模式(NodeJS)
开发步骤:可参考 "章节三" ; 原理:脚本任务的源码托管在调度中心,脚本逻辑在执行器运行。当触发脚本任务时,执行器会加载脚本源码在执行器机器上生成一份脚本文件,然后通过Java代码调用该脚本;并且实时将脚本输出日志写到任务日志文件中,从而在调度中心可以实时监控脚本运行情况;脚本返回码为0时表示执行成功,其他标示执行失败。
目前支持的脚本类型如下:
- - shell脚本:任务运行模式选择为 "GLUE模式(Shell)"时支持 "shell" 脚本任务;
- - python脚本:任务运行模式选择为 "GLUE模式(Python)"时支持 "python" 脚本任务;
- - nodejs脚本:务运行模式选择为 "GLUE模式(NodeJS)"时支持 "nodejs" 脚本任务;
5.5.4 执行器
执行器实际上是一个内嵌的Jetty服务器,默认端口9999(配置项:xxl.job.executor.port)。
在项目启动时,执行器会通过“@JobHandler”识别Spring容器中“Bean模式任务”,以注解的value属性为key管理起来。
“执行器”接收到“调度中心”的调度请求时,如果任务类型为“Bean模式”,将会匹配Spring容器中的“Bean模式任务”,然后调用其execute方法,执行任务逻辑。如果任务类型为“GLUE模式”,将会加载GLue代码,实例化Java对象,注入依赖的Spring服务(注意:Glue代码中注入的Spring服务,必须存在与该“执行器”项目的Spring容器中),然后调用execute方法,执行任务逻辑。
5.5.5 任务日志
XXL-JOB会为每次调度请求生成一个单独的日志文件,需要通过 "XxlJobLogger.log" 打印执行日志,“调度中心”查看执行日志时将会加载对应的日志文件。
(历史版本通过重写LOG4J的Appender实现,存在依赖限制,该方式在新版本已经被抛弃)
日志文件存放的位置可在“执行器”配置文件进行自定义,默认目录格式为:/data/applogs/xxl-job/jobhandler/“格式化日期”/“数据库调度日志记录的主键ID.log”。
在JobHandler中开启子线程时,子线程将会将会把日志打印在父线程即JobHandler的执行日志中,方便日志追踪。
5.6 通讯模块剖析
5.6.1 一次完整的任务调度通讯流程
- - 1、“调度中心”向“执行器”发送http调度请求: “执行器”中接收请求的服务,实际上是一台内嵌jetty服务器,默认端口9999;
- - 2、“执行器”执行任务逻辑;
- - 3、“执行器”http回调“调度中心”调度结果: “调度中心”中接收回调的服务,是针对执行器开放一套API服务;
5.6.2 通讯数据加密
调度中心向执行器发送的调度请求时使用RequestModel和ResponseModel两个对象封装调度请求参数和响应数据, 在进行通讯之前底层会将上述两个对象对象序列化,并进行数据协议以及时间戳检验,从而达到数据加密的功能;
5.7 任务注册, 任务自动发现
自v1.5版本之后, 任务取消了"任务执行机器"属性, 改为通过任务注册和自动发现的方式, 动态获取远程执行器地址并执行。
- AppName: 每个执行器机器集群的唯一标示, 任务注册以 "执行器" 为最小粒度进行注册; 每个任务通过其绑定的执行器可感知对应的执行器机器列表;
- 注册表: 见"XXL_JOB_QRTZ_TRIGGER_REGISTRY"表, "执行器" 在进行任务注册时将会周期性维护一条注册记录,即机器地址和AppName的绑定关系; "调度中心" 从而可以动态感知每个AppName在线的机器列表;
- 执行器注册: 任务注册Beat周期默认30s; 执行器以一倍Beat进行执行器注册, 调度中心以一倍Beat进行动态任务发现; 注册信息的失效时间被三倍Beat;
- 执行器注册摘除:执行器销毁时,将会主动上报调度中心并摘除对应的执行器机器信息,提高心跳注册的实时性;
为保证系统"轻量级"并且降低学习部署成本,没有采用Zookeeper作为注册中心,采用DB方式进行任务注册发现;
5.8 任务执行结果
自v1.6.2之后,任务执行结果通过 "IJobHandler" 的返回值 "ReturnT" 进行判断; 当返回值符合 "ReturnT.code == ReturnT.SUCCESS_CODE" 时表示任务执行成功,否则表示任务执行失败,而且可以通过 "ReturnT.msg" 回调错误信息给调度中心; 从而,在任务逻辑中可以方便的控制任务执行结果;
5.9 分片广播 & 动态分片
执行器集群部署时,任务路由策略选择"分片广播"情况下,一次任务调度将会广播触发对应集群中所有执行器执行一次任务,同时传递分片参数;可根据分片参数开发分片任务;
"分片广播" 以执行器为维度进行分片,支持动态扩容执行器集群从而动态增加分片数量,协同进行业务处理;在进行大数据量业务操作时可显著提升任务处理能力和速度。
"分片广播" 和普通任务开发流程一致,不同之处在于可以可以获取分片参数,获取分片参数进行分片业务处理。
- Java语言任务获取分片参数方式:BEAN、GLUE模式(Java)
- // 可参考Sample示例执行器中的示例任务"ShardingJobHandler"了解试用
- ShardingUtil.ShardingVO shardingVO = ShardingUtil.getShardingVo();
- 脚本语言任务获取分片参数方式:GLUE模式(Shell)、GLUE模式(Python)、GLUE模式(Nodejs)
- // 脚本任务入参固定为三个,依次为:任务传参、分片序号、分片总数。以Shell模式任务为例,获取分片参数代码如下
- echo "分片序号 index = $2"
- echo "分片总数 total = $3"
分片参数属性说明:
- index:当前分片序号(从0开始),执行器集群列表中当前执行器的序号;
- total:总分片数,执行器集群的总机器数量;
该特性适用场景如:
- 1、分片任务场景:10个执行器的集群来处理10w条数据,每台机器只需要处理1w条数据,耗时降低10倍;
- 2、广播任务场景:广播执行器机器运行shell脚本、广播集群节点进行缓存更新等
5.10 访问令牌(AccessToken)
为提升系统安全性,调度中心和执行器进行安全性校验,双方AccessToken匹配才允许通讯;
调度中心和执行器,可通过配置项 "xxl.job.accessToken" 进行AccessToken的设置。
调度中心和执行器,如果需要正常通讯,只有两种设置;
- 设置一:调度中心和执行器,均不设置AccessToken;关闭安全性校验;
- 设置二:调度中心和执行器,设置了相同的AccessToken;
5.11 调度中心API服务
调度中心提供了API服务,供执行器和业务方选择使用,目前提供的API服务有:
- 1、任务结果回调服务;
- 2、执行器注册服务;
- 3、执行器注册摘除服务;
- 4、触发任务单次执行服务,支持任务根据业务事件触发;
调度中心API服务位置:com.xxl.job.core.biz.AdminBiz.java
调度中心API服务请求参考代码:com.xxl.job.adminbiz.AdminBizTest.java
5.12 执行器API服务
执行器提供了API服务,供调度中心选择使用,目前提供的API服务有:
- 1、心跳检测
- 2、忙碌检测
- 3、触发任务执行
- 4、获取Rolling Log
- 5、终止任务
执行器API服务位置:com.xxl.job.core.biz.ExecutorBiz
执行器API服务请求参考代码:com.xxl.executor.test.DemoJobHandlerTest
5.13 故障转移 & 失败重试
一次完整任务流程包括"调度(调度中心) + 执行(执行器)"两个阶段。
- "故障转移"发生在调度阶段,在执行器集群部署时,如果某一台执行器发生故障,该策略支持自动进行Failover切换到一台正常的执行器机器并且完成调度请求流程。
- "失败重试"发生在"调度 + 执行"两个阶段,如下:
- 调度中心调度失败时,任务失败处理策略选择"失败重试",将会自动重试一次;
- 执行器运行失败时,任务执行结果返回"失败重试(IJobHandler.FAIL_RETRY)"回调,将会自动重试一次;
六、版本更新日志
6.1 版本 V1.1.x,新特性[2015-12-05]
【于V1.1.x版本,XXL-JOB正式应用于我司,内部定制别名为 “Ferrari”,新接入应用推荐使用最新版本】
- 1、简单:支持通过Web页面对任务进行CRUD操作,操作简单,一分钟上手;
- 2、动态:支持动态修改任务状态,动态暂停/恢复任务,即时生效;
- 3、服务HA:任务信息持久化到mysql中,Job服务天然支持集群,保证服务HA;
- 4、任务HA:某台Job服务挂掉,任务会平滑分配给其他的某一台存活服务,即使所有服务挂掉,重启时或补偿执行丢失任务;
- 5、一个任务只会在其中一台服务器上执行;
- 6、任务串行执行;
- 7、支持自定义参数;
- 8、支持远程任务执行终止;
6.2 版本 V1.2.x,新特性[2016-01-17]
-
1、支持任务分组;
-
2、支持“本地任务”、“远程任务”;
-
3、底层通讯支持两种方式,Servlet方式 + JETTY方式;
-
4、支持“任务日志”;
-
5、支持“串行执行”,并行执行;
说明:V1.2版本将系统架构按功能拆分为:
- - 调度模块(调度中心):负责管理调度信息,按照调度配置发出调度请求;
- - 执行模块(执行器):负责接收调度请求并执行任务逻辑;
- - 通讯模块:负责调度模块和任务模块之间的信息通讯;
优点:
- - 解耦:任务模块提供任务接口,调度模块维护调度信息,业务相互独立;
- - 高扩展性;
- - 稳定性;
6.3 版本 V1.3.0,新特性[2016-05-19]
-
1、遗弃“本地任务”模式,推荐使用“远程任务”,易于系统解耦,任务对应的JobHandler统称为“执行器”;
-
2、遗弃“servlet”方式底层系统通讯,推荐使用JETTY方式,调度+回调双向通讯,重构通讯逻辑;
-
3、UI交互优化:左侧菜单展开状态优化,菜单项选中状态优化,任务列表打开表格有压缩优化;
-
4、【重要】“执行器”细分为:BEAN、GLUE两种开发模式,简介见下文:
“执行器” 模式简介: - BEAN模式执行器:每个执行器都是Spring的一个Bean实例,XXL-JOB通过注解@JobHandler识别和调度执行器; -GLUE模式执行器:每个执行器对应一段代码,在线Web编辑和维护,动态编译生效,执行器负责加载GLUE代码和执行;
6.4 版本 V1.3.1,新特性[2016-05-23]
- 1、更新项目目录结构:
- /xxl-job-admin -------------------- 【调度中心】:负责管理调度信息,按照调度配置发出调度请求;
- /xxl-job-core ----------------------- 公共依赖
- /xxl-job-executor-example ------ 【执行器】:负责接收调度请求并执行任务逻辑;
- /db ---------------------------------- 建表脚本
- /doc --------------------------------- 用户手册
- 2、在新的目录结构上,升级了用户手册;
- 3、优化了一些交互和UI;
6.5 版本 V1.3.2,新特性[2016-05-28]
- 1、调度逻辑进行事务包裹;
- 2、执行器异步回调执行日志;
- 3、【重要】在 “调度中心” 支持HA的基础上,扩展执行器的Failover支持,支持配置多执行期地址;
6.6 版本 V1.4.0 新特性[2016-07-24]
- 1、任务依赖: 通过事件触发方式实现, 任务执行成功并回调时会主动触发一次子任务的调度, 多个子任务用逗号分隔;
- 2、执行器底层实现代码进行重度重构, 优化底层建表脚本;
- 3、执行器中任务线程分组逻辑优化: 之前根据执行器JobHandler进行线程分组,当多个任务复用Jobhanlder会导致相互阻塞。现改为根据调度中心任务进行任务线程分组,任务与任务执行相互隔离;
- 4、执行器调度通讯方案优化, 通过Hex + HC实现建议RPC通讯协议, 优化了通讯参数的维护和解析流程;
- 5、调度中心, 新建/编辑任务, 界面属性调整:
- 5.1、任务新增/编辑界面中去除 "任务名JobName"属性 ,该属性改为系统自动生成: 该字段之前主要用于在 "调度中心" 唯一标示一个任务, 现实意义不大, 因此计划淡化掉该字段,改为系统生成UUID,从而简化任务新建的操作;
- 5.2、任务新增/编辑界面中去除 "GLUE模式" 复选框位置调整, 改为贴近"JobHandler"输入框右侧;
- 5.3、任务新增/编辑界面中去除 "报警阈值" 属性;
- 5.4、任务新增/编辑界面中去除 "子任务Key" 属性, 每个任务全局任务Key可以从任务列表获取, 当本任务执行结束且成功后, 将会根据子任务Key匹配子任务并主动触发一次子任务执行;
- 6、问题修复:
- 6.1、执行器jetty关闭优化,解决一处可能导致jetty无法关闭的问题;
- 6.2、执行器任务终止时,执行队列回调优化,解决一处导致任务无法回调的问题;
- 6.3、调度中心中列表分页参数优化,解决一处因服务器限制post长度而引起的问题;
- 6.4、执行器Jobhandler注解优化,解决一处因事务代理导致的容器无法加载JobHandler的问题;
- 6.5、远程调度优化,禁用retry策略,解决一处可能导致重复调用的问题;
Tips: 历史版本(V1.3.x)目前已经Release至稳定版本, 进入维护阶段, 地址见分支 V1.3 。新特性将会在master分支持续更新。
6.7 版本 V1.4.1 新特性[2016-09-06]
- 1、项目成功推送maven中央仓库, 中央仓库地址以及依赖如下:
- <!-- http://repo1.maven.org/maven2/com/xuxueli/xxl-job-core/ -->
- <dependency>
- <groupId>com.xuxueli</groupId>
- <artifactId>xxl-job-core</artifactId>
- <version>${最新稳定版}</version>
- </dependency>
- 2、为适配中央仓库规则, 项目groupId从com.xxl改为com.xuxueli。
- 3、系统版本不在维护在项目跟pom中,各个子模块单独配置版本配置,解决子模块无法单独编译的问题;
- 4、底层RPC通讯,传输数据的字节长度统计规则优化,可节省50%数据传输量;
- 5、IJobHandler取消任务返回值,原通过返回值判断执行状态,逻辑改为:默认任务执行成功,仅在捕获异常时认定任务执行失败。
- 6、系统公共弹框功能,插件化;
- 7、底层表结构,表明统一大写;
- 8、调度中心,异常处理器JSON响应的ContentType修改,修复浏览器不识别的问题;
6.8 版本 V1.4.2 新特性[2016-09-29]
- 1、推送新版本 V1.4.2 至中央仓库, 大版本 V1.4 进入维护阶段;
- 2、任务新增时,任务列表偏移问题修复;
- 3、修复一处因bootstrap不支持模态框重叠而导致的样式错乱的问题, 在任务编辑时会出现该问题;
- 4、调度超时和Handler匹配不到时,调度状态优化;
- 5、因catch异常,导致任务不可终止的问题,给出解决方案, 见文档;
6.9 版本 V1.5.0 特性[2016-11-13]
- 1、任务注册: 执行器会周期性自动注册任务, 调度中心将会自动发现注册的任务并触发执行。
- 2、"执行器" 新增参数 "AppName" : 是每个执行器集群的唯一标示AppName, 并周期性以AppName为对象进行自动注册。
- 3、调度中心新增栏目 "执行器管理" : 管理在线的执行器, 通过属性AppName自动发现注册的执行器。只有被管理的执行器才允许被使用;
- 4、"任务组"属性改为"执行器": 每个任务需要绑定指定的执行器, 调度地址通过绑定的执行器获取;
- 5、抛弃"任务机器"属性: 通过任务绑定的执行器, 自动发现注册的远程执行器地址并触发调度请求。
- 6、"公共依赖"中新增DBGlueLoader,基于原生jdbc实现GLUE源码的加载器,减少第三方依赖(mybatis,spring-orm等);精简和优化执行器测配置(针对GLUE任务),降低上手难度;
- 7、表结构调整,底层重构优化;
- 8、"调度中心"自动注册和发现,failover: 调度中心周期性自动注册, 任务回调时可以感知在线的所有调度中心地址, 通过failover的方式进行任务回调,避免回调单点风险。
6.10 版本 V1.5.1 特性[2016-11-13]
- 1、底层代码重构和逻辑优化,POM清理以及CleanCode;
- 2、Servlet/JSP Spec设定为3.0/2.2
- 3、Spring升级至3.2.17.RELEASE版本;
- 4、Jetty升级版本至8.2.0.v20160908;
- 5、已推送V1.5.0和V1.5.1至Maven中央仓库;
6.10 版本 V1.5.2 特性[2017-02-28]
- 1、IP工具类获取IP逻辑优化,IP静态缓存;
- 2、执行器、调度中心,均支持自定义注册IP地址;解决机器多网卡时错误网卡注册的情况;
- 3、任务跨天执行时生成多份日志文件的问题修复;
- 4、底层日志底层日志调整,非敏感日志level调整为debug;
- 5、升级数据库连接池c3p0版本;
- 6、执行器log4j配置优化,去除无效属性;
- 7、底层代码重构和逻辑优化以及CleanCode;
- 8、GLUE依赖注入逻辑优化,支持别名注入;
6.11 版本 V1.6.0 特性[2017-03-13]
- 1、通讯方案升级,原基于HEX的通讯模型调整为基于HTTP的B-RPC的通讯模型;
- 2、执行器支持手动设置执行地址列表,提供开关切换使用注册地址还是手动设置的地址;
- 3、执行器路由规则:第一个、最后一个、轮询、随机、一致性HASH、最不经常使用、最近最久未使用、故障转移;
- 4、规范线程模型统一,统一线程销毁方案(通过listener或stop方法,容器销毁时销毁线程;Daemon方式有时不太理想);
- 5、规范系统配置数据,通过配置文件统一管理;
- 6、CleanCode,清理无效的历史参数;
- 7、底层扩展数据结构以及相关表结构调整;
- 8、新建任务默认为非运行状态;
- 9、GLUE模式任务实例更新逻辑优化,原根据超时时间更新改为根据版本号更新,源码变动版本号加一;
6.12 版本 V1.6.1 特性[2017-03-25]
- 1、Rolling日志;
- 2、WebIDE交互重构;
- 3、通讯增强校验,有效过滤非正常请求;
- 4、权限增强校验,采用动态登录TOKEN(推荐接入内部SSO);
- 5、数据库配置优化,解决乱码问题;
6.13 版本 V1.6.2 特性[2017-04-25]
- 1、运行报表:支持实时查看运行数据,如任务数量、调度次数、执行器数量等;以及调度报表,如调度日期分布图,调度成功分布图等;
- 2、JobHandler支持设置任务返回值,在任务逻辑中可以方便的控制任务执行结果;
- 3、资源路径包含空格或中文时资源文件无法加载时,无法准确查看异常信息的问题处理。
- 4、路由策越优化:循环和LFU路由策略计数器自增无上限问题和首次路由压力集中在首台机器的问题修复;
6.14 版本 V1.7.0 特性[2017-05-02]
- 1、脚本任务:支持以GLUE模式开发和运行脚本任务,包括Shell、Python和Groovy等类型脚本;
- 2、新增spring-boot类型执行器example项目;
- 3、升级jetty版本至9.2;
- 4、任务运行日志移除log4j组件依赖,改为底层自主实现,从而取消了对日志组件的依赖限制;
- 5、执行器移除GlueLoader依赖,改为推送方式实现,从而GLUE源码加载不再依赖JDBC;
- 6、登录拦截Redirect时获取项目名,解决非根据目录发布时跳转404问题;
6.15 版本 V1.7.1 特性[2017-05-08]
- 1、运行日志读写编码统一为UTF-8,解决windows环境下日志乱码问题;
- 2、通讯超时时间限定为10s,避免异常情况下调度线程占用;
- 3、执行器,server启动、销毁和注册逻辑调整;
- 4、JettyServer关闭逻辑优化,修复执行器无法正常关闭导致端口占用和频繁打印c3p0日志的问题;
- 5、JobHandler中开启子线程时,支持子线程输出执行日志并通过Rolling查看。
- 6、任务日志清理功能;
- 7、弹框组件统一替换为layer;
- 8、升级quartz版本至2.3.0;
6.16 版本 V1.7.2 特性[2017-05-17]
- 1、阻塞处理策略:调度过于密集执行器来不及处理时的处理策略,策略包括:单机串行(默认)、丢弃后续调度、覆盖之前调度;
- 2、失败处理策略;调度失败时的处理策略,策略包括:失败告警(默认)、失败重试;
- 3、通讯时间戳超时时间调整为180s;
- 4、执行器与数据库彻底解耦,但是执行器需要配置调度中心集群地址。调度中心提供API供执行器回调和心跳注册服务,取消调度中心内部jetty,心跳周期调整为30s,心跳失效为三倍心跳;
- 5、执行参数编辑时丢失问题修复;
- 6、新增任务测试Demo,方便在开发时进行任务逻辑测试;
6.17 版本 V1.8.0 特性[2017-07-17]
- 1、任务Cron更新逻辑优化,改为rescheduleJob,同时防止cron重复设置;
- 2、API回调服务失败状态码优化,方便问题排查;
- 3、XxlJobLogger的日志多参数支持;
- 4、路由策略新增 "忙碌转移" 模式:按照顺序依次进行空闲检测,第一个空闲检测成功的机器选定为目标执行器并发起调度;
- 5、路由策略代码重构;
- 6、执行器重复注册问题修复;
- 7、任务线程轮空30次后自动销毁,降低低频任务的无效线程消耗。
- 8、执行器任务执行结果批量回调,降低回调频率提升执行器性能;
- 9、springboot版本执行器,取消XML配置,改为类配置方式;
- 10、执行日志,支持根据运行 "状态" 筛选日志;
- 11、调度中心任务注册检测逻辑优化;
6.18 版本 V1.8.1 特性[2017-07-30]
- 1、分片广播任务:执行器集群部署时,任务路由策略选择"分片广播"情况下,一次任务调度将会广播触发集群中所有执行器执行一次任务,可根据分片参数处理分片任务;
- 2、动态分片:分片广播任务以执行器为维度进行分片,支持动态扩容执行器集群从而动态增加分片数量,协同进行业务处理;在进行大数据量业务操作时可显著提升任务处理能力和速度。
- 3、执行器JobHandler禁止命名冲突;
- 4、执行器集群地址列表进行自然排序;
- 5、调度中心,DAO层代码精简优化并且新增测试用例覆盖;
- 6、调度中心API服务改为自研RPC形式,统一底层通讯模型;
- 7、新增调度中心API服务测试Demo,方便在调度中心API扩展和测试;
- 8、任务列表页交互优化,更换执行器分组时自动刷新任务列表,新建任务时默认定位在当前执行器位置;
- 9、访问令牌(accessToken):为提升系统安全性,调度中心和执行器进行安全性校验,双方AccessToken匹配才允许通讯;
- 10、springboot版本执行器,升级至1.5.6.RELEASE版本;
- 11、统一maven依赖版本管理;
6.19 版本 V1.8.2 特性[2017-09-04]
- 1、项目主页搭建:提供中英文文档:http://www.xuxueli.com/xxl-job
- 2、JFinal执行器Sample示例项目;
- 3、事件触发:除了"Cron方式"和"任务依赖方式"触发任务执行之外,支持基于事件的触发任务方式。调度中心提供触发任务单次执行的API服务,可根据业务事件灵活触发。
- 4、执行器摘除:执行器销毁时,主动通知调度中心并摘除对应执行器节点,提高执行器状态感知的时效性。
- 5、执行器手动设置IP时将会绑定Host;
- 6、规范项目目录,方便扩展多执行器;
- 7、解决执行器回调URL不支持配置HTTPS时问题;
- 8、执行器回调线程销毁前, 批量回调队列中数据,防止任务结果丢失;
- 9、调度中心任务监控线程销毁时,批量对失败任务告警,防止告警信息丢失;
- 10、任务日志文件路径时间戳格式化时SimpleDateFormat并发问题解决;
6.20 版本 V1.9.0 特性[2017-12-29]
- 1、新增Nutz执行器Sample示例项目;
- 2、新增任务运行模式 "GLUE模式(NodeJS) ",支持NodeJS脚本任务;
- 3、脚本任务Shell、Python和Nodejs等支持获取分片参数;
- 4、失败重试,完整支持:调度中心调度失败且启用"失败重试"策略时,将会自动重试一次;执行器执行失败且回调失败重试状态(新增失败重试状态返回值)时,也将会自动重试一次;
- 5、失败告警策略扩展:默认提供邮件失败告警,可扩展短信等,扩展代码位置为 "JobFailMonitorHelper.failAlarm";
- 6、执行器端口支持自动生成(小于等于0时),避免端口定义冲突;
- 7、调度报表优化,支持时间区间筛选;
- 8、Log组件支持输出异常栈信息,底层实现优化;
- 9、告警邮件样式优化,调整为表格形式,邮件组件调整为commons-email简化邮件操作;
- 10、项目依赖全量升级至较新稳定版本,如spring、jackson等等;
- 11、任务日志,记录发起调度的机器信息;
- 12、交互优化,如登陆注销;
- 13、任务Cron长度扩展支持至128位,支持负责类型Cron设置;
- 14、执行器地址录入交互优化,地址长度扩展支持至512位,支持大规模执行器集群配置;
- 15、任务参数“IJobHandler.execute”入参改为“String params”,增强入参通用性。
- 16、IJobHandler提供init/destroy方法,支持在相应任务线程初始化和销毁时进行附加操作;
- 17、任务注解调整为 “@JobHandler”,与任务抽象接口统一;
- 18、修复任务监控线程被耗时任务阻塞的问题;
- 19、修复任务监控线程无法监控任务触发和执行状态均未0的问题;
- 20、执行器动态代理对象,拦截非业务方法的执行;
- 21、修复JobThread捕获Error错误不更新JobLog的问题;
- 22、修复任务列表界面左侧菜单合并时样式错乱问题;
- 23、调度中心项目日志配置改为xml文件格式;
- 24、Log地址格式兼容,支持非"/"结尾路径配置;
- 25、底层系统日志级别规范调整,清理遗留代码;
- 26、建表SQL优化,支持同步创建制定编码的库和表;
- 27、系统安全性优化,登陆Token写Cookie时进行MD5加密,同时Cookie启用HttpOnly;
- 28、新增"任务ID"属性,移除"JobKey"属性,前者承担所有功能,方便后续增强任务依赖功能。
- 29、任务循环依赖问题修复,避免子任务与父任务重复导致的调度死循环;
- 30、任务列表新增筛选条件 "任务描述",快速检索任务;
- 31、执行器Log文件定期清理功能:执行器新增配置项("xxl.job.executor.logretentiondays")日志保存天数,日志文件过期自动删除。
6.21 版本 V1.9.1 特性[2018-02-22]
- 1、国际化:调度中心实现国际化,支持中文、英文两种语言,默认为中文。
- 2、调度报表新增"运行中"中状态项;
- 3、调度报表优化,报表SQL调优并且新增LocalCache缓存(缓存时间60s),提高大数据量下报表加载速度;
- 4、修复打包部署时资源文件乱码问题;
- 5、修复新版本chrome滚动到顶部失效问题;
- 6、调度中心配置加载优化,取消对配置文件名的强依赖,支持加载磁盘配置;
- 7、修复脚本任务Log文件未正常close的问题;
- 8、项目依赖全量升级至较新稳定版本,如spring、jackson等等;
6.22 版本 V1.9.2 特性[迭代中]
- 1、[迭代中]支持通过API服务操作任务信息;
- 2、[迭代中]任务告警逻辑调整:任务调度,以及任务回调失败时,均推送监控队列。后期考虑通过任务Log字段控制告警状态;
- 3、[迭代中]任务超时设置,超时任务主动终止;
- 4、任务属性枚举 "任务模式、阻塞策略" 国际化优化;
- 5、任务日志表状态字段类型优化;
TODO LIST
- 1、任务权限管理:执行器为粒度分配权限,核心操作校验权限;
- 2、任务分片路由:分片采用一致性Hash算法计算出尽量稳定的分片顺序,即使注册机器存在波动也不会引起分批分片顺序大的波动;目前采用IP自然排序,可以满足需求,待定;
- 3、任务单机多线程:提升任务单机并行处理能力;
- 4、回调失败丢包问题:执行器回调失败写文件,重启或周期性回调重试;调度中心周期性请求并同步未回调的执行结果;
- 5、任务依赖,流程图,子任务+会签任务,各节点日志;
- 6、调度任务优先级;
- 7、移除quartz依赖,重写调度模块:新增或恢复任务时将下次执行记录插入delayqueue,调度中心集群竞争分布式锁,成功节点批量加载到期delayqueue数据,批量执行。
- 8、springboot 和 docker镜像,并且推送docker镜像到中央仓库,更进一步实现产品开箱即用;
- 9、多数据库支持;
- 10、执行器Log清理功能:调度中心Log删除时同步删除执行器中的Log文件;
- 11、Bean模式任务,JobHandler自动从执行器中查询展示为下拉框,选择后自动填充任务名称等属性;
- 12、API事件触发类型任务(更类似MQ消息)支持"动态传参、延时消费";该类型任务不走Quartz,单独建立MQ消息表,调度中心竞争触发;
- 13、任务依赖增强,新增任务类型 "流程任务",流程节点可挂载普通类型任务,承担任务依赖功能。现有子任务模型取消;需要考虑任务依赖死循环问题;
- 14、分片任务某一分片失败,支持分片转移;
- 15、调度中心触发任务后,先推送触发队列,异步触发,然后立即返回。降低quartz线程占用时长。
- 16、新增API服务 "XxlJobService" ,支持通过API服务来维护管理任务信息;
- 17、新增任务默认运行状态,任务更新时运行状态保持不变;
- 18、告警邮件中展示失败告警信息;
- 19、提供多版本执行器:不依赖容器版本、不内嵌Jetty版本(通过配置executoraddress替换jetty通讯)等;
- 20、注册中心支持扩展,除默认基于DB之外,支持扩展接入第三方注册中心如zk、eureka等;
- 21、依赖Core内部国际化处理;
- 22、大数据量下任务日志分页优化,时间选择组件支持清空功能可提升速度;
- 23、故障转移、失败重试等策略,规范化合并归类;
- 24、流程任务,支持参数传递;

