
- 15年时间,从外包测试到自研,最后到阿里,这5年的经历只有自己能知道...._测试培训完去自研
- 2SpringBoot日志关系--及排除模块中的日志框架_jasypt-spring-boot-starter 排除日志模块
- 3使用Python实现深度学习模型:模型监控与性能优化
- 44年外包上岸,我只能说这类公司能不去就不去
- 5GrassRouter多链路聚合路由应用场景拓扑详解_多链路聚合路由器
- 6机器学习算法: 岭回归算法_岭回归c++算法实例
- 7H5--公众号页面如何唤起小程序_jweixin-1.6.0.js
- 8C++入门基础篇(下)
- 92024年前端最新最新的Vue面试题大全含源码级回答,吊打面试官系列,前端初级面试题_2024前端vue面试题
- 10Linux —— 进程间通信
聚类算法Clustering概述分析_k-modes clustering
赞
踩
k-means:仅适用数值Dataset;
1.确定聚类数目k;2.选取k个初始中心点;3.将Dataset中的每一个元素分别与k个中心点计算欧氏距离,归并到欧氏距离最近的类中;4.使用平均值法means更新k个中心点;迭代3.4步骤直到中心点无变化得到结果;
k-modes:适用非数值Dataset;
与k-means区别之处:
1.相关度D计算方法:D = 两组数据之间所有不同属性值的个数;
2.中心点更新方法:以每个类中每种属性的众数mode作为类的属性更新值;
k-prototype:适用混合数值Dataset;
相关性度量:D=P1+a*P2,其中P1采用k-means度量,P2采用k-modes度量,a是权重;
难点总结:1.k的确定;2.k个初始中心点的选取;3.k-prototype中权重a的确定;
mean-shift-clustering:无需提前预知聚类数目k
1.确定滑动窗口的半径,随机选择一系列中心点C;
2.每个滑动窗口向数据点密度更高的方向移动,并以区域内的均值更新中心点;
3.当向任意方向移动均无法提高区域密度时,结束滑动;
4.当产生的多个窗口有重叠时,仅保留密度最高的窗口,得到k个窗口;
5.根据产生的k个区域中心点,对整个数据集进行聚类;

Density-Based Spatial Clustering of Application with Noise:
DBSCAN将簇定义为密度相连的点的最大集合,可在有噪声的空间数据库中实现任意形状聚类;
优点:无需簇的数目k;
缺点:参数-半径r和minPoints对聚类结果影响较大,需要调参经验;
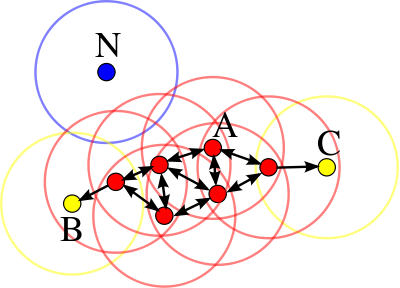
EM(Expectation-Maximization) Clustering with GMM(Gaussian Mixture Model):
当数据集中的点分布规律不能用中心均值(k-means)表示时,需要使用GMM方法
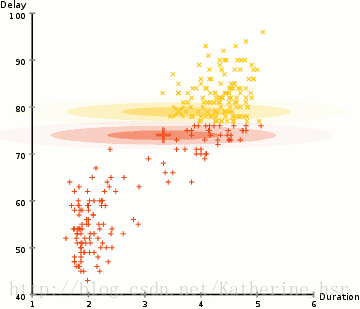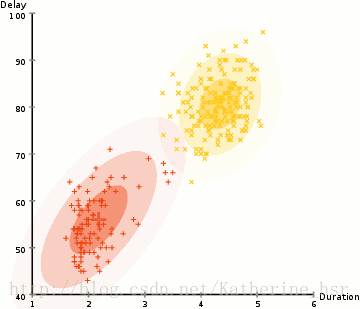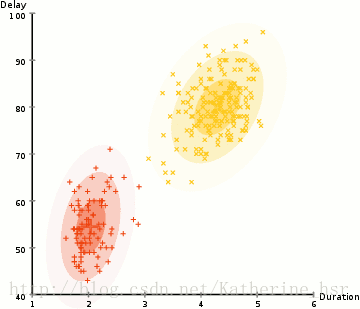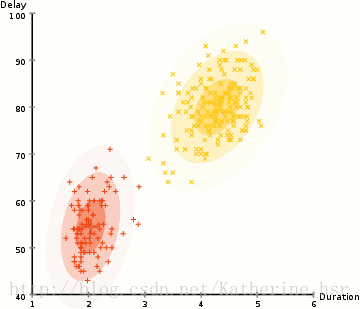
高斯混合模型(Gaussian Mixture Model):使用EM算法迭代求解
k-means根据每个类簇距离尺度来聚类,需要对数据进行归一化;高斯混合模型不需要归一化,因为它对每个类簇分别考虑了特征的协方差;
GMM引入了隐变量:均值和协方差

EM算法流程



