
- 1前端结合xlsx.js+xlsx-style.js源码实现自定义excel文件导出_xlsx.js库
- 2阿里云Linux (Centos 7) 指定目录安装mysql --ARM版系统安装失败_mysql 5.7.44 arm版本
- 3【问题解决】java.lang.IllegalStateException异常是什么问题?解决办法_java.lang.illegalstateexception: latitude is out o
- 448.请编写函数fun,其功能是:将两个两位数的正整数a、b合并形成一个整数放在c中。合并的方式是:将a数的十位和个位数依次放在c数的千位和十位上,b数的十位和个位数依次放在c数的百位和个位上。_将两个两位数的正整数a和b合并成一个整数放在c中。合并的方式为:将a的十位数和个
- 5解决WSL2/Linux ll command not found_wsl: command not found
- 6让 VIte+Vue3 打包的项目,在本地可以双击 index.html 打开运行_vue3 - 完美解决 vite 打包后在本地浏览器直接打开运行,build 打包后双击 index
- 7鸿蒙4.0开发笔记之DevEco Studio页面操作router的pushUrl页面跳转与back返回上一页(五)_huawei arkts router切换页面不能立即切换
- 8Android开发新手入门教程,华为大神花费5个月打造的这份714页学习笔记系列
- 9Linux下SSH服务的搭建_useprivilegeseparation
- 10-bash: export: Command not found_-bash: 鈥渆xport: command not found
京东广告算法架构体系建设--高性能计算方案最佳实践
赞
踩
1、前言
推荐领域算法模型的在线推理是一个对高并发、高实时有较强要求的场景。算法最初是基于Wide & Deep相对简单的网络结构进行建模,容易满足高实时、高并发的推理性能要求。但随着广告模型效果优化进入深水区,基于Transformer用户行为序列和Attention的建模逐渐成为主流,这个阶段模型的特点是参数的体量、网络结构复杂度呈指数级增长,算法建模的创新工作往往由于吞吐和耗时的性能算力问题,导致无法落地于在线推理获得效果收益。传统通过扩容资源的方式,其边际效应也在减弱,算力优化存在诸多挑战:
1、高算力需求下的资源成本边际效应问题:集群资源扩容是提升算力的一种传统方案,但算力需求的增加往往需要成倍数的资源增长才能抹平,带来了极强的边际递减效应。
2、复杂算法模型的在线推理算力扩展问题:推理引擎要求低延迟和高吞吐,而随着模型算法复杂度提升,突破计算资源算力上限(存储、计算),推理耗时显著增加,无法满足实时推荐系统的性能要求。
针对上述挑战和问题,广告算法架构在迭代演变的过程中,构建了一系列的优化体系,主要集中在两个方面:
1、架构层面:设计分布式分图异构计算框架,通过模型分图,分布式推理实现算力的向外扩展;CPU&GPU异构硬件差异化部署,算法结构与计算硬件资源相得益彰,最大化硬件适配性,实现算力的指数级增长。算力扩展的架构使得后续垂向优化成为可能,可以针对特定业务需求进行深度定制和调整。
2、高算力推理引擎层面:从底层架构出发,GPU算子调度和计算逻辑精细化优化,深入挖掘GPU专用计算设备的潜力,实现对推理性能的显著提升。
2、分布式分图异构计算框架
分布式分图异构计算框架是我们针对算力扩展问题提出的解决方案,通过模型结构化拆分,分布式分图计算,CPU&GPU异构硬件差异化部署,使算法结构与计算硬件资源高度适配,充分发挥各自优势。基于CPU计算集群构建大规模稀疏模型建模,利用内存资源易扩展等优势,支撑千亿规模参数的高性能推理。基于GPU计算集群构建稠密模型建模,利用高算力优势,支撑超长用户行为序列建模,为算法建模的创新提供了坚实的架构基础。我们基于该框架进一步研发并落地了京东零售首个Online Learning建模场景,使得模型可以感知人、货、场的实时变化。同时GPU服务集群作为独立于整体服务体系的组成部分,便于针对GPU推理引擎进行专项优化,从而便捷地进行性能提升措施的实施。
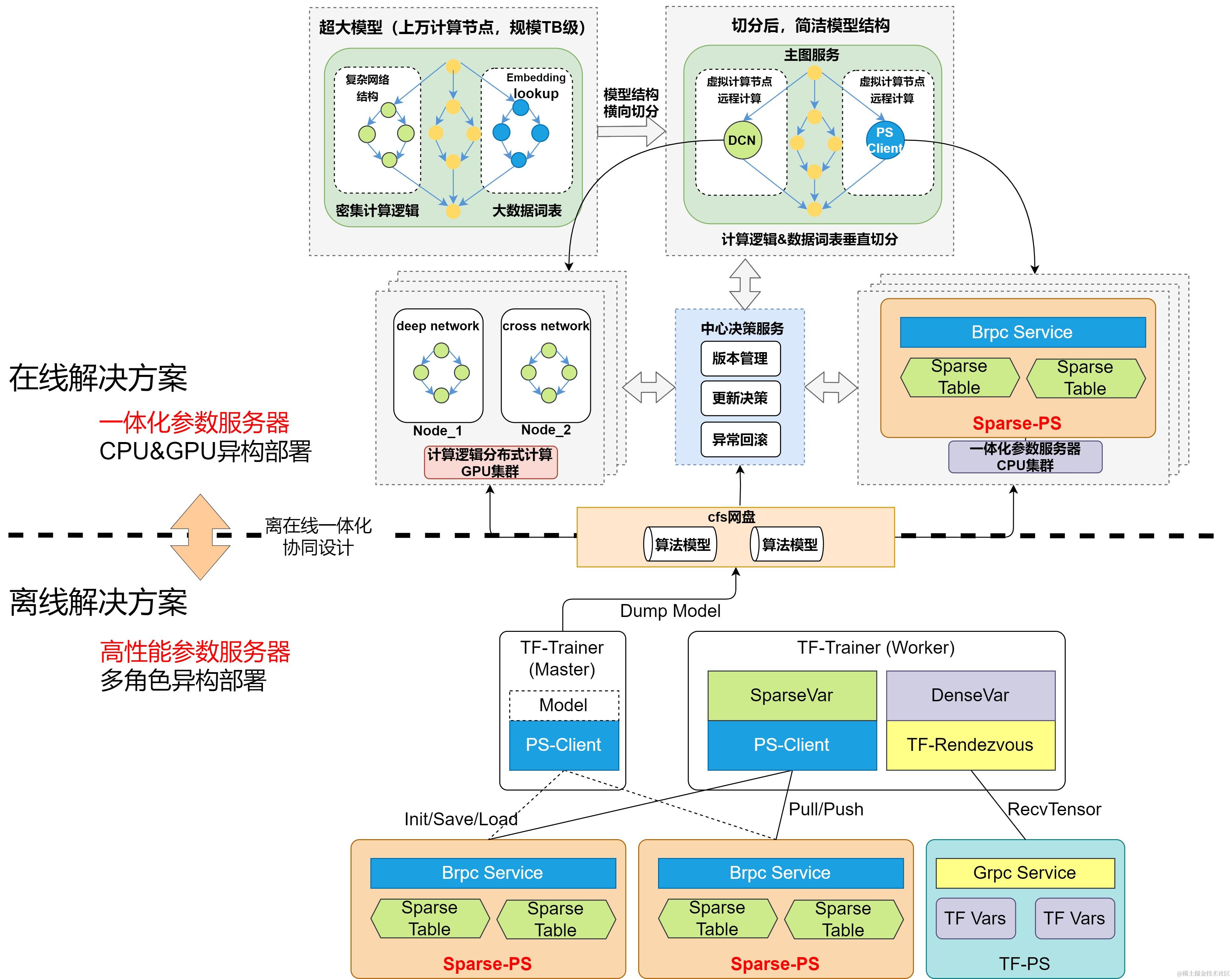
图1 分布式分图异构计算框架
3、高算力推理引擎
为了打造高算力推理引擎,开始深入调研基于GPU推理引擎优化推理性能的可行性,GPU作为一种高度并行的多核处理器,具备极强的并行计算能力,由于GPU高度并行化的结构,先天适合以稠密矩阵计算为主的NLP、CV领域。但直接应用于推荐领域会存在TP99耗时上涨,资源利用率不高等问题。这主要与推荐领域模型的自身特点相关:
1、建模过程复杂:为建模用户与商品关系,推荐领域模型建模不仅包含DNN等稠密计算部分,还存在大量针对稀疏特征的Embedding建模方式以及特征预处理等模块,集合了IO密集与计算密集两大特性,造成计算过程与GPU亲和性不高,难以充分发挥GPU的硬件优势。
2、模型规模大:推荐领域模型以稀疏参数为主,百G规模参数无法完全加载至GPU显存,稀疏参数交换导致带宽需求高,造成GPU无法充分利用。
3、模型结构复杂:用户行为序列建模成为模型建模的主流方法,而用户特征的多样性(浏览行为、购买行为、加购行为)需要单独建模以提升模型对用户的感知能力,因此造成模型分支结构多,结构复杂。TensorFlow推理框架虽然提供了算子级别的建模方案,通过堆叠细粒度算子完成各种复杂的模型建模,灵活的支撑了多种行为序列建模方式。但也因此造成了算子粒度过细,单算子计算量小,不易于GPU充分调度的问题,尤其是对于在线推理本身计算量就相对较小的场景问题更为致命。
得益于分布式分图异构计算框架,有效解决了上述1,2问题,并且可以让我们针对GPU算子调度和计算逻辑精细化优化,深入挖掘GPU专用计算设备的潜力,实现对推理性能的显著提升。具体工作体现在以下三个方面:a)TensorBatch:通过聚合计算请求提升GPU计算吞吐;b)深度学习编译器:通过自动化的算子融合、图优化等方式优化模型推理性能;c)多流计算:通过打造GPU多计算通道,构建真正的并行计算推理引擎。
3.1、TensorBatch
广告精排模型推理主要表现是单个请求耗时较短(毫秒级),同时每个请求中gpu kernel调用次数较多,每次gpu kernel的调度都会伴随相应的kernel launch,琐碎繁多的kernel launch会严重制约GPU模型的吞吐能力,同时会导致模型系统耗时较高,通过Nsight性能分析性能数据如下。
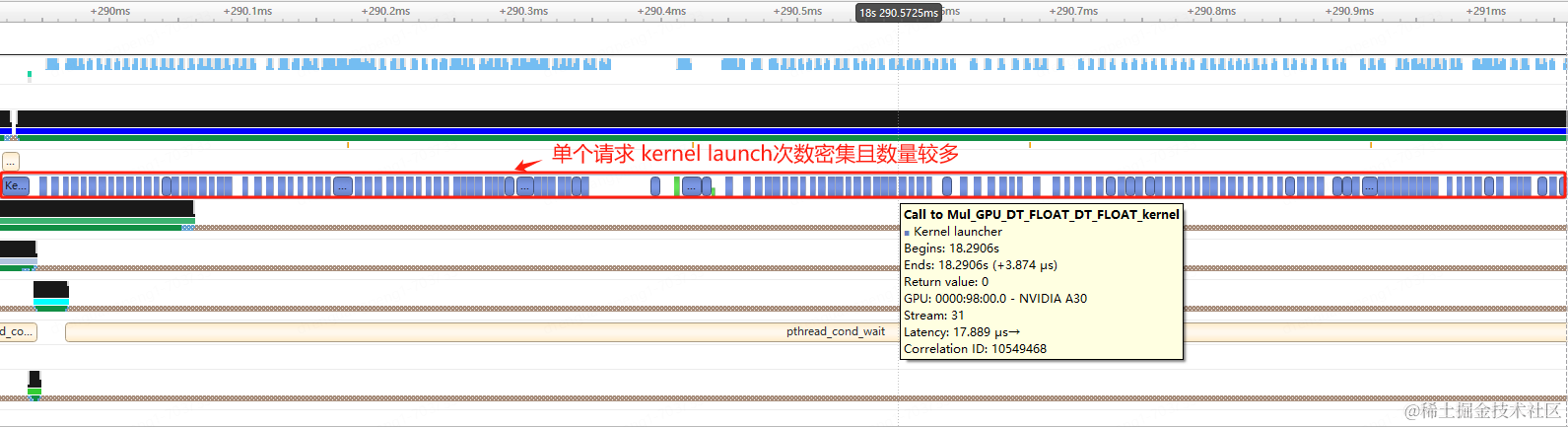
图2 大批量KernelLaunch操作
kernel launch 本质上是从host端核函数调用到GPU开始计算之间的这段时间,主要包括准备计算需要数据的传输和执行需要warp线程束的获取,无论是数据的传输还是选取执行所需要的warp线程束,多个请求之间是可以实现共享的,因此我们核心解决问题的思路是将多个模型推理请求合并成一个请求,完成模型推理后在对结果再进行合理的分割,减少请求级别 kernel launch 的数量,极大的提升kernel launch的效率,从而进一步提升GPU模型的吞吐能力,架构方案如 图3, 例如 1个模型请求经过tensorflow推理需要进行 1000 次 kernel launch,3个请求需要3000次kernel launch,如果将3个请求合并成1个请求,那么kernel launch数量会从3000 降至1000。
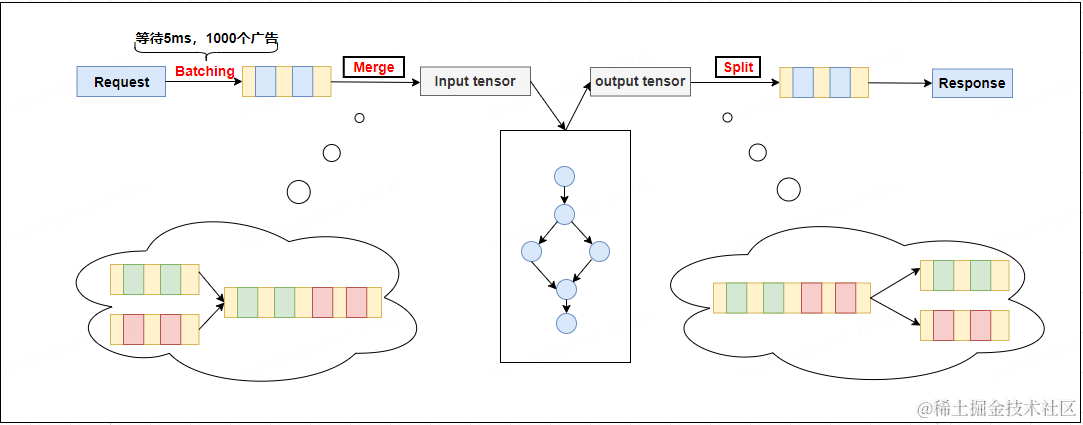
图3 Tensor Batch架构图
请求级别算子融合在广告精排模型进行全量上线,在GPU利用率不变的情况下,GPU模型吞吐能力提升2倍。请求级别融合本质是优化GPU kernel launch 效率,但是优化GPU kernel launch 效率方案不止一种,下面详细介绍一下基于"深度学习编译器"的算子融合。
3.2、深度学习编译器
KernelLaunch效率问题优化方面,我们首先采用了TensorBatch方案,在广告算法场景,调试聚合数量在5-8左右较为合适(聚合后广告数200-1000)。虽然对请求进行了聚合,但算子执行的TimeLine仍较稀疏,如图5所示,该现象解释了GPU无法得到充分利用的原因。针对这一现象,我们进一步研发了基于深度学习编译器的算子融合方案,通过算子融合n次 KernelLaunch至1次,大大降低整体KernelLaunch耗时,同时通过图优化等策略进一步提升模型的推理性能。

图4 GPU Kernel计算稀疏
3.2.1 深度学习编译器分桶预编译技术
XLA(Accelerated Linear Algebra)是google开源的深度学习编译器,将高级别的模型描述转换成高效的可执行代码,自动化的解决算子融合、内存管理、数据布局转换等问题。该框架已融合进Tensorflow开源框架中,并提供较友好的编程接口。但原生深度学习编译器在推荐领域模型应用方面存在一系列问题:
a)同一个XLA Graph针对不同的Tensor输入属性(数量、维度、类型)会触发不同的编译流程,形成多个XLA Runtime(编译结果),导致开源方案只适用于CV领域,定长输入(图像维度不变)的场景。推荐领域模型变长特征(用户行为序列)的存在使得在推理过程构建万级别数量的XLA Runtime(编译结果),在显存消耗上不可接受。
b)Tensorflow-XLA为运行时编译(JIT),编译过程缓慢,通常完成一个XLA Runtime的编译耗时长达1秒,且对CPU、GPU资源占用较大,在广告高实时场景下,耗时不可接受。
针对上述问题,我们研发了深度学习编译器分桶预编译技术。为避免不同特征维度导致的多次编译问题,首先对算法结构进行XLA子图划分,形成多个XLA子图。其次针对XLA子图的输入特征变长情况,实现分桶Padding能力,降低XLA Runtime编译数量,解决了编译中遇到的显存问题。最后通过模型XLA子图分桶标记算法,在模型加载阶段进行预编译,解决运行时编译耗时问题。
在深度学习编译器技术加持下,我们将广告推荐精排模型的算子调度次数从553次优化至190次,XLA子图模块的算子执行的TimeLine得到极大改善,单次推理耗时从14ms优化至9ms。
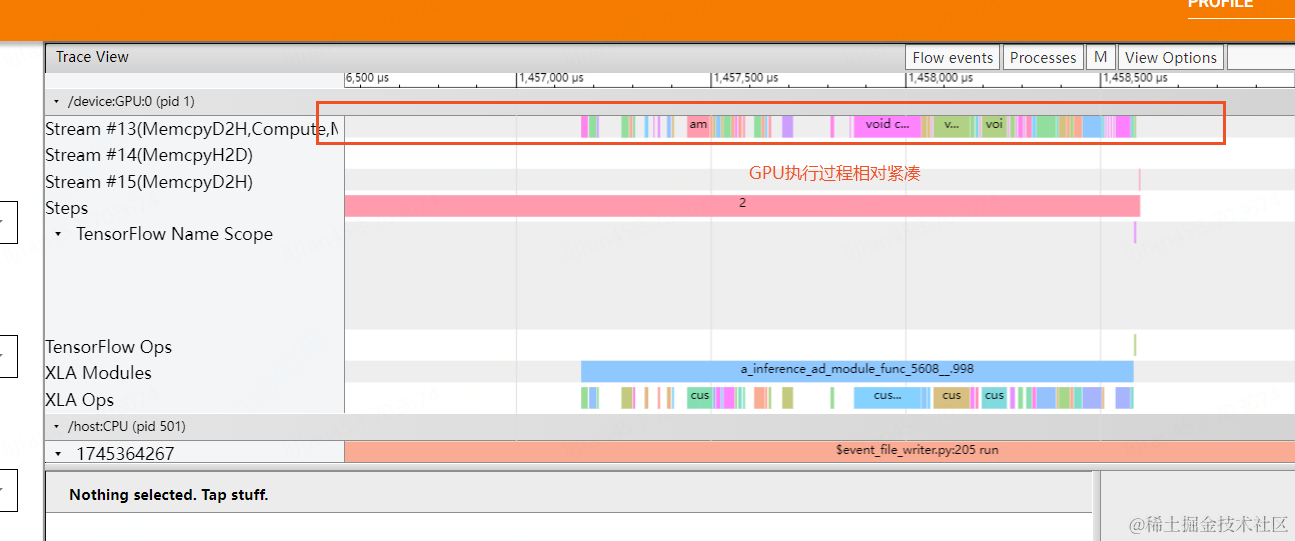
图5 XLA Runtime
3.2.2 深度学习编译器异步编译技术
通过深度学习编译器分桶预编译技术,我们解决了99.9%的问题,但仍有异常流量导致特征维度超出预设的分桶范围,导致触发运行时编译的可能。作为一个高稳定的在线系统,我们进一步实现了异步编译技术,解决异常流量带来的耗时问题:
a)模型构图方面,同时保留XLA子图与模型原图。
b)推理过程动态选择,命中分桶情况则选择XLA Runtime执行,未命中则选择原图执行,同时服务后台触发异步XLA编译,供下次请求使用。
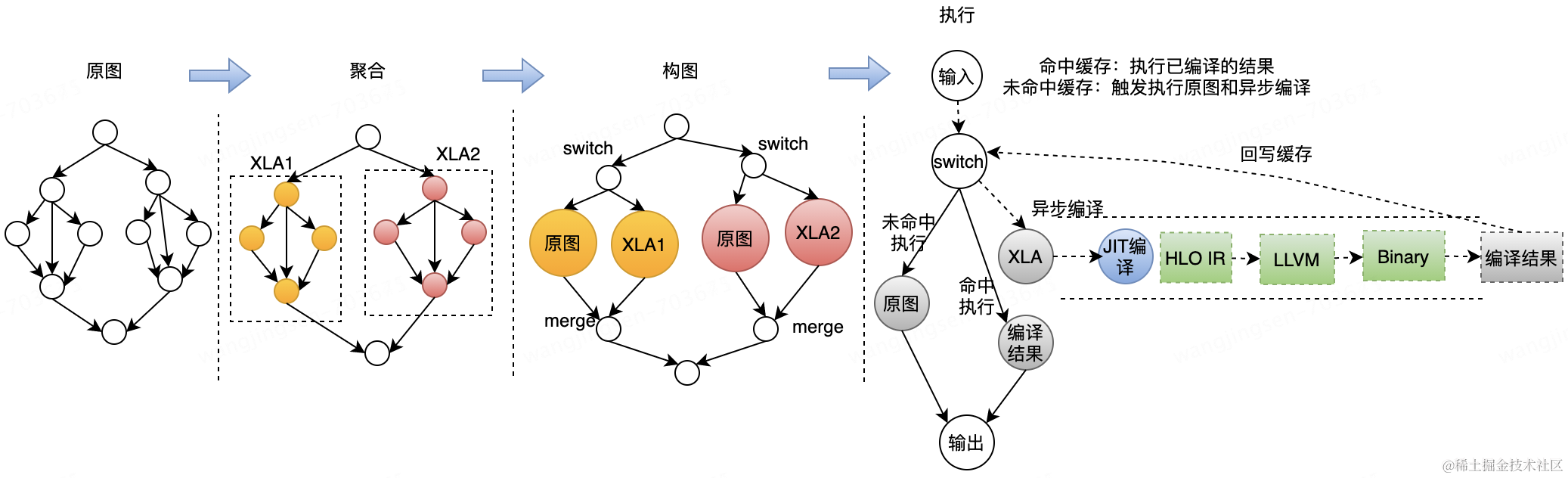
图6 深度学习编译器异步编译
3.3、多流计算

图7 GPU多流计算背景
Tensorflow深度学习框架虽然提供了GPU计算能力,但其CPU到GPU的交互通道仅为单通道模式。在线并发推理的场景下,存在算子调度互斥、算子计算阻塞排队等问题。针对上述痛点我们设计了GPU多通道模式-多流计算架构,真正实现了GPU的并发计算能力。
我们对Tensorflow框架中的底层GPU通道的创建和分配机制进行了深入的改造与升级,赋予了其在面对同一模型时,针对不同的在线请求,动态选择GPU通道进行运算的能力。每个GPU通道独立持有一份CUDA Stream和CUDA Context,既消除了算子并发调度导致的GPU资源争抢问题,也使得不同请求拥有独立的计算通道,提升GPU并行粒度。
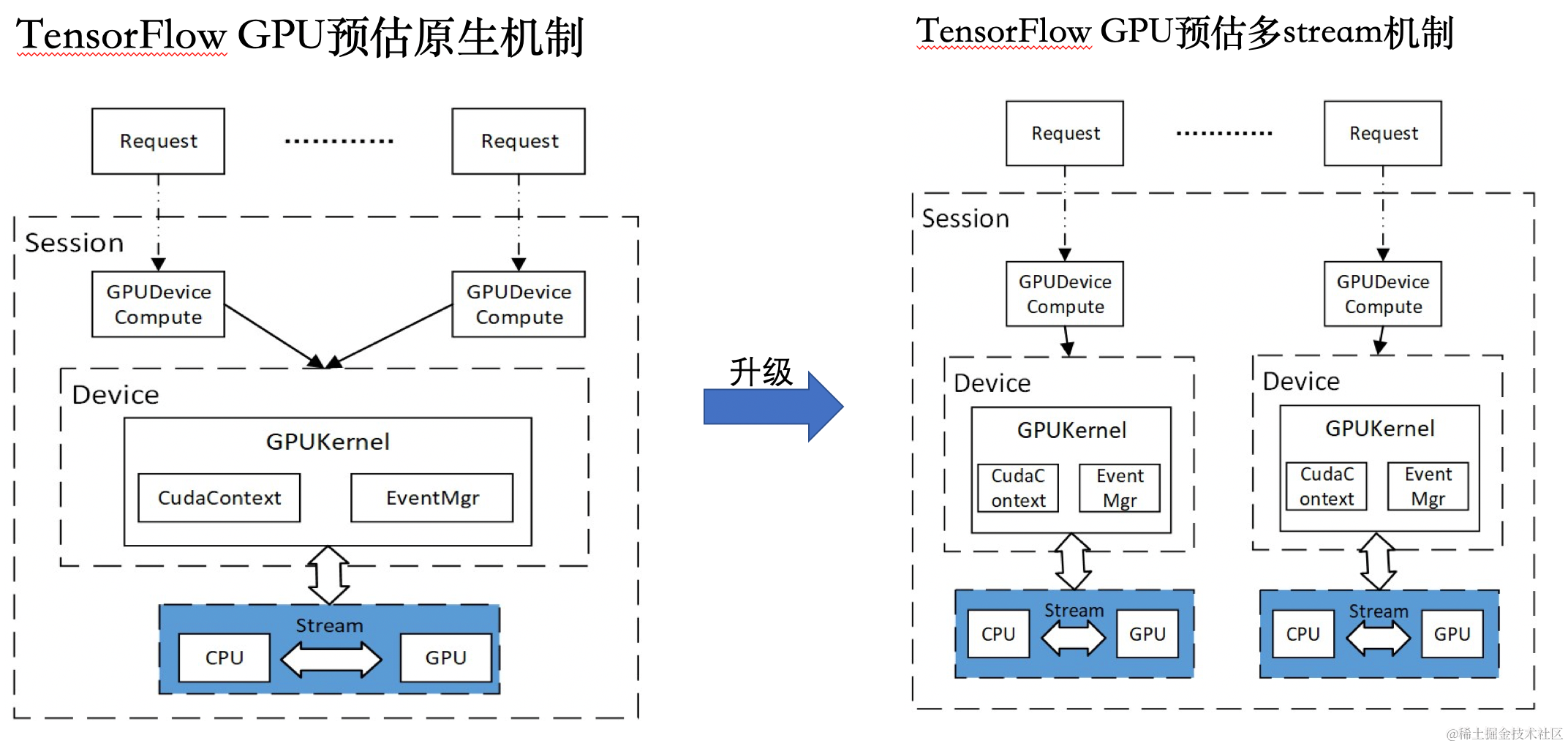
图8 多GPU通道
多GPU通道(多CudaStream + 多CudaContext)解决了KernelLaunch调度问题,算子调度可以并行执行,减少了执行的GAP。但在GPU硬件层面,CudaContext采用分时复用原则,即此某一时刻只有一个CudaContext被调度执行,没有完全达到算子计算间的并行。

图9 GPU Kernel交错计算
MPS + 多流计算框架实现真正意义的并行计算
MPS局限性:MPS(Multi-Process Service)是英伟达为充分利用GPU资源的一种解决方案。MPS多进程服务,每个进程有自己的上下文管理机制,MPS使用合并共享的并行模式,即将多个任务合并成一个上下文,因此可以同时跑多个任务,是真正意义上的并行。但MPS方案需要多进程服务的场景下才能生效,这种情况下单卡显存无法承载多进程任务,显存成为瓶颈,MPS机制失效,无法充分利用GPU算力。
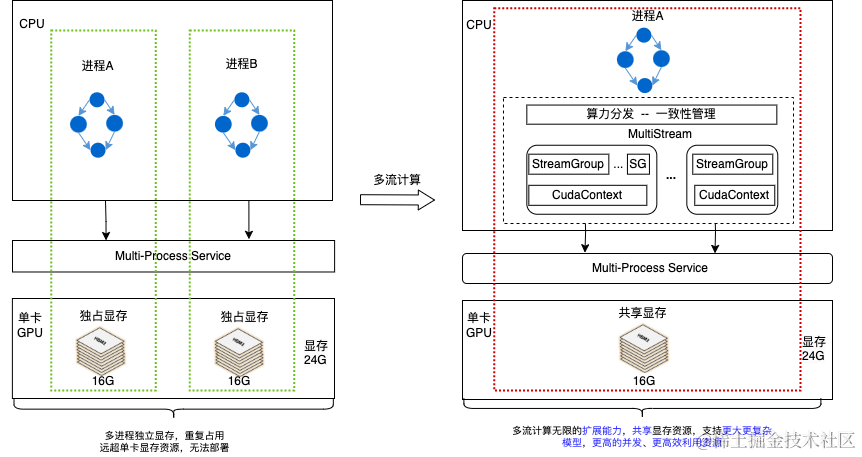
图10 Multi-Process Service局限性
因此,我们升级了多流计算架构,将MPS与自研的多CudaStream + 多CudaContext的多流计算架构相结合,解决了显存瓶颈的问题,最终通过单进程模型部署实现真正的并行计算。
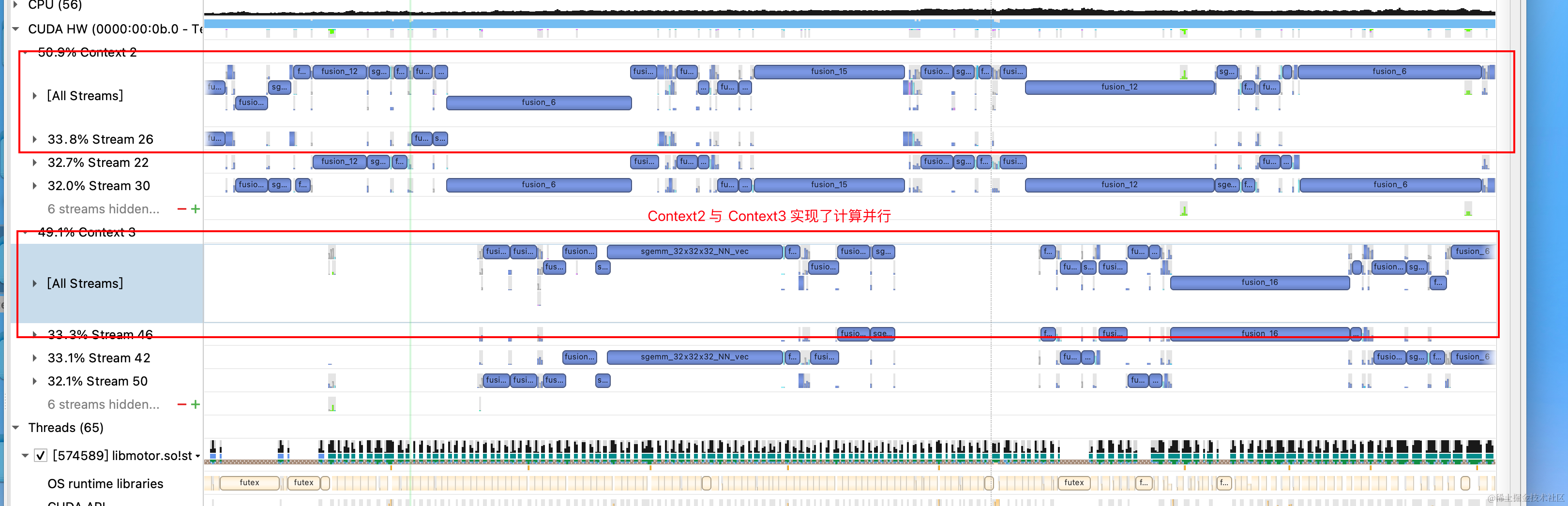
图11 GPU Kernel并行计算
综上,我们实现了完整的GPU多流计算框架:创建多组通信渠道打通软件和硬件通道,融合调度Context实现真正的计算并行化。
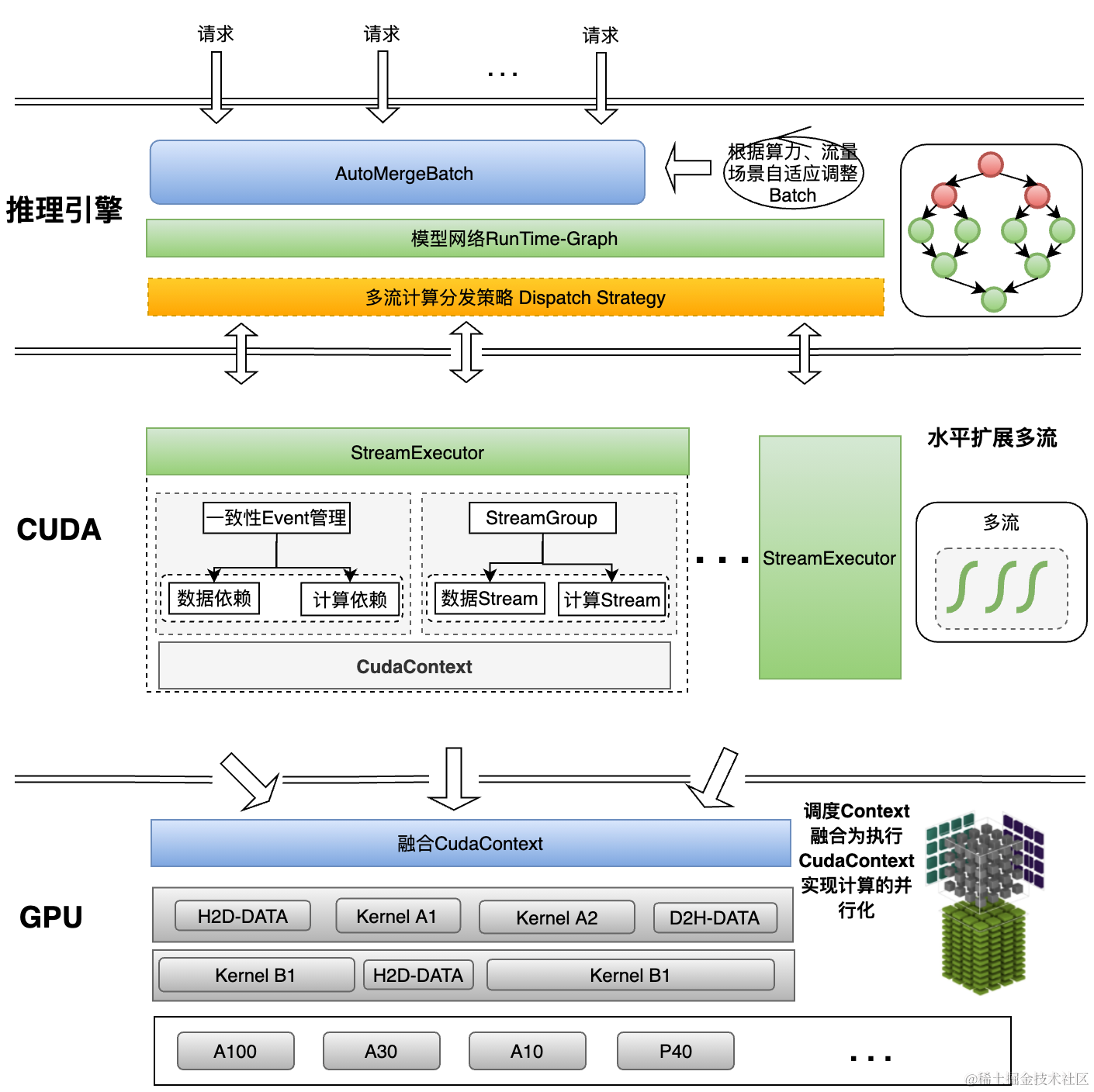
图12 GPU多流计算架构图
4、总结
综上,通过设计高性能的计算方案,打造新一代算法架构推理体系,在架构层面通过分布式分图异构方案很好的解决了高算力需求下的资源成本边际效应问题,在高算力推理引擎层面,通过一系列的专项优化,让GPU的算力得到充分的释放,实现复杂算法模型算力的扩展。目前新一代的高性能计算方案已经在广告多个业务线进行了落地实践,推荐首页CTR模型、推荐通用信息CTR模型、推荐商详CTR的规模扩展至千亿,助力推荐、搜索等核心业务取得显著的效果收益。
高性能算法推理系统是算法架构体系的重要组成部分,为算法建模的创新提供了算力基础,算力优化是一个极富挑战性的领域,它需要我们在技术层面上不断进行探索、学习和创新。目前,我们正在着手规划下一代推理算法架构体系,其最显著的特点将是算法、计算能力和架构的深度融合,以及在线和离线一体化的设计方案。
感谢广告架构师小组的架构师们和算法方向的专家们在算法架构体系建设方面提供的宝贵指导建议。同时我们诚挚地邀请对此领域感兴趣的同事们加入我们的讨论。相信通过大家的共同努力和协作,一定能够在这个前沿领域取得突破,为未来的推理算法架构体系开辟新的可能性和机遇。****


