
- 1人工智能AI:细粒度动物识别(8000种动物)
- 2TortoiseGit 版本回滚_tortoisegit回滚
- 3经典文献阅读之--SurroundOcc(自动驾驶的环视三维占据栅格预测)
- 4宝塔代理配置(Nginx)_阿里云服务宝塔部署如何配置nigix,如何配置代理的地址
- 5黑苹果-解决屏幕亮度无法调节问题_applebacklightfixup
- 6手把手用YOLO做目标检测
- 7VS编译器提示:C4996 ‘scanf‘: This function or variable may be unsafe. Consider using scanf_s instead.的解决方法
- 8百度千帆大模型初体验,接入30+大模型、100+提示词模版、插件最丰富,国内最强_大模型提示词模板
- 9Spring Framework和SpringBoot的区别_spring boot spring framework
- 10细数和Chatgpt相似的开源模型_chatgpt开源模型
视觉大模型--deter的深入理解
赞
踩
但对于transformer用于目标检测领域的开创性模型,该模型言简意赅,但是但从论文理解,有很多细节都不清楚,尤其是解码器的query和二分图匹配(Bipartite Matching)和匈牙利算法(Hungarian Algorithm)相关,本文将根据代码详细介绍这一部分
原理

 大家最常见的就是上面两幅图,这也是deter模型的整体架构,原理大家可以参考网络其他问题,有很多,我这里就不细讲了, 但是我会突出讲解,整个过程到底是什么样。
大家最常见的就是上面两幅图,这也是deter模型的整体架构,原理大家可以参考网络其他问题,有很多,我这里就不细讲了, 但是我会突出讲解,整个过程到底是什么样。
解码器的query
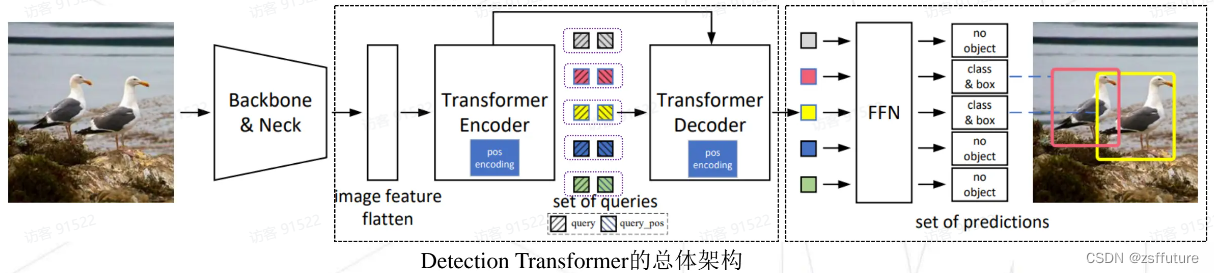
- Detection Transformer检测器是queries set(查询集合)到目标对象(object)的映射
- queries分为内容查询query和一一对应位置查询query_pos,每组queries对应一个预测结果(类别和框的位置)
- queries set的数量通常为100、300或900,远远少于之前密集预测(dense prediction)的工作
- queries set与经过Backbone、Neck和Encoder提取的图片特征在Decoder中交互,并经过FFN输出结果
- NMS-Free算法,输出结果(set prediction)无需NMS后处理。只有和label等量的queries会预测并直接输出目标的类别和框的位置,其余的gueries预测的结果为“没有目标”(no obiject)

解码器第一层:
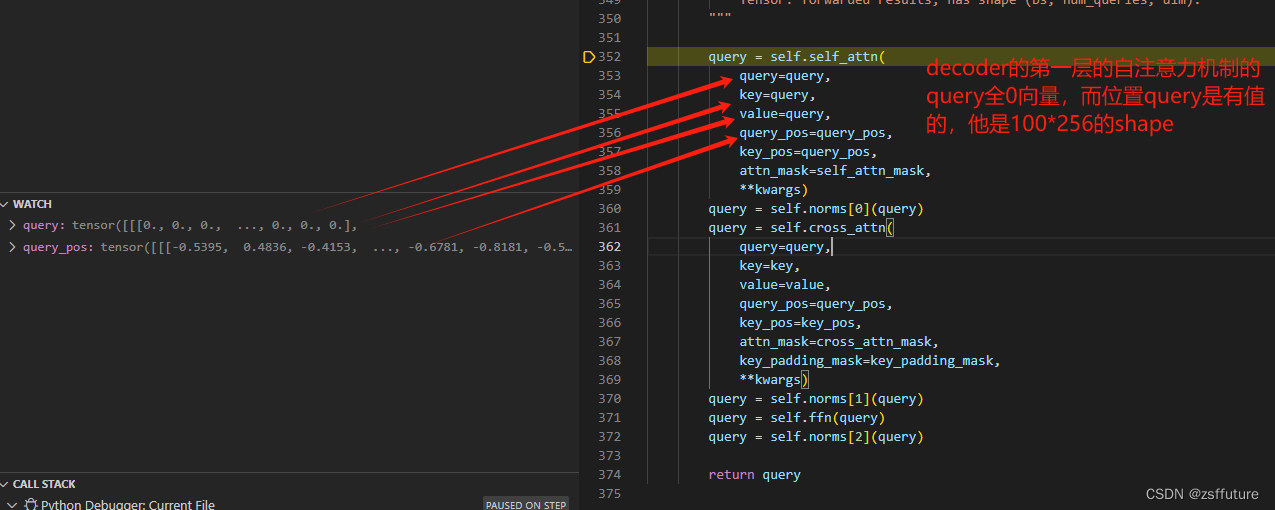
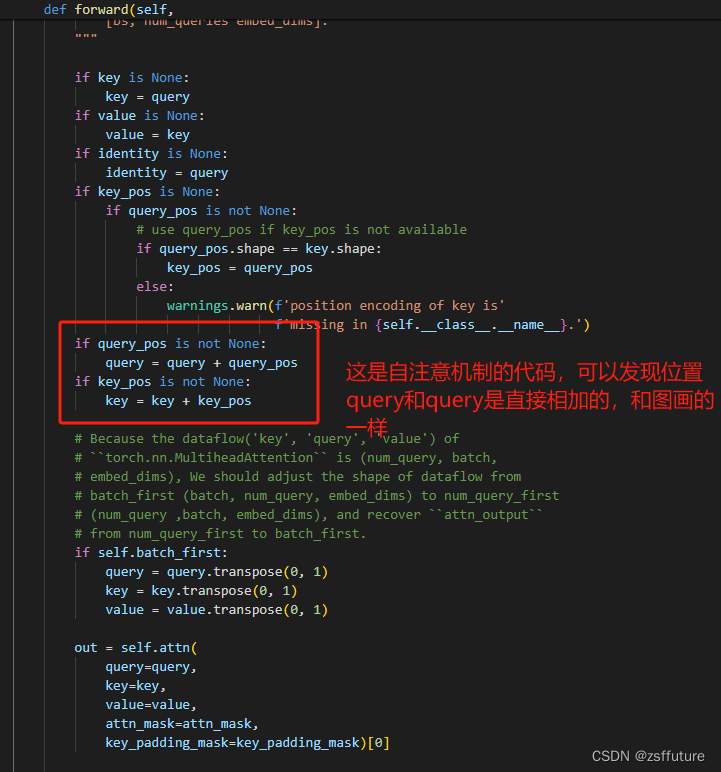
可以看到query进入self-Attention时全是0零向量且不具备学习权重,query_pos初始化为:
- # posequery初始化
- self.query_embedding = nn.Embedding(self.num_queries, self.embed_dims)
-
- # forward使用,每经过解码器的一层transformer层都会获取前一层的位置query的权重,这样位置随着每层训练都会进行更新,但是query在第一层为全0,在第一层结束后既不是全0向量了,他是前一层的输出
- query_pos = self.query_embedding.weight # 这个是可学习的,每次训练都会更新参数
- # (num_queries, dim) -> (bs, num_queries, dim)
- query_pos = query_pos.unsqueeze(0).repeat(batch_size, 1, 1)
- query = torch.zeros_like(query_pos) # 这个是不可学习,每次推理直接为0,相当于内容embeding
总结,从图中和代码可以发现,位置query即query_pos 是可学习的,除了第一batch训练的第一层的权重是随机初始化的,其他层的query_pose都是更新学习的,而内容query即query每次迭代训练输入都是全0开始,然后经过第一层后就不在是全0了,而是计算出了值即内容,然后将当前层输出的作为下一层输入的query。通俗来讲,deter的解码器的query由两部分组成,分别为query_pos和query_content(即图片的self.self_attn(query=query,...)),此时query_pos负责预测位置,query_content负责关注图片的内容,也就是为什么只对query_pos进行梯度更新,因为这是需要学习,才能对位置越来越准,而query_content是最终的计算结果集对内容特征的输出,这不需要更新,因为决定内容输出的不是query_content,而是key和value,因此只需要更新输入计算的权重即可,这就是本文的一大核心观点,后续很多都模型都是对这里进行修改。

loss计算和权重更新
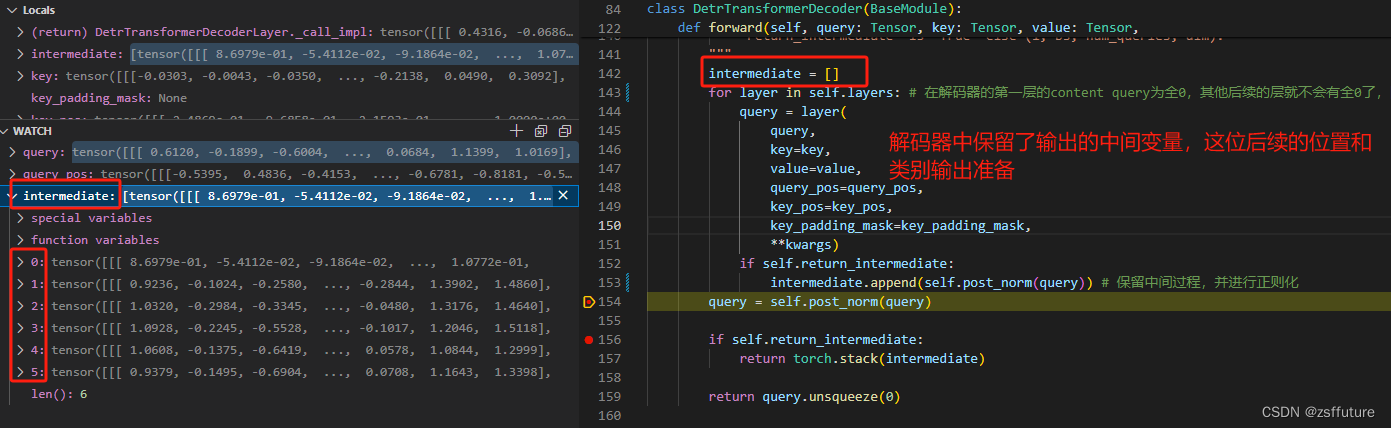
从上面我们可以看到,解码器的每层输出的query都保留了,这为后面预测类别和坐标做准备,因为每层都进行预测和计算loss
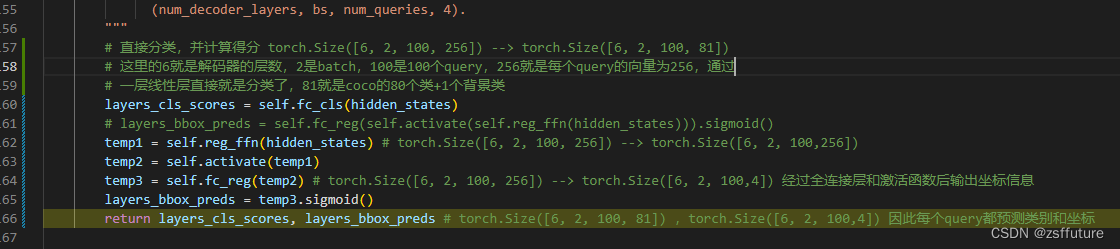
从上面代码可以发现,hidden_status就是记录的解码器的每层输出,同时每层的输出都是100个query,每个query是256维度的向量,然后每层每个query通过全连接层进行预测类别和坐标信息,而且每层的全连接层是相同的,即分别进行分类和回归坐标的全连接层是一样的。
后续拿到预测的分类数据和坐标数据后,先对坐标数据进行转换,因为上面的shape【6,2,100,4】中的4代表cx、cy、w、h,需要转为xyxy即左上角和右下角的点,同时把归一化坐标转为绝对坐标,这样才能通过计算预测结果和标签数据的1对1匹配。
分类代价:
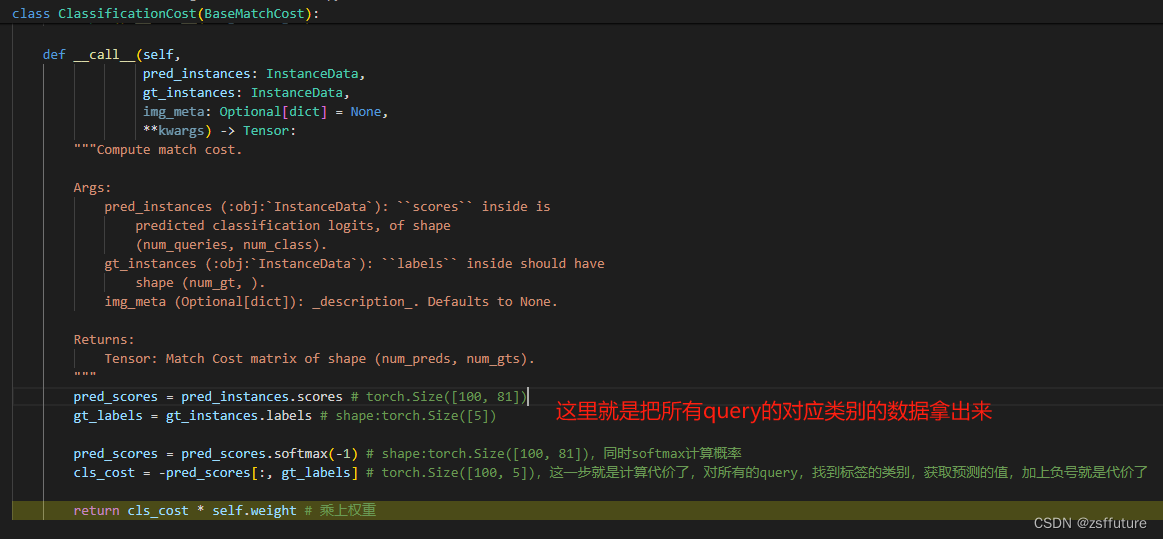
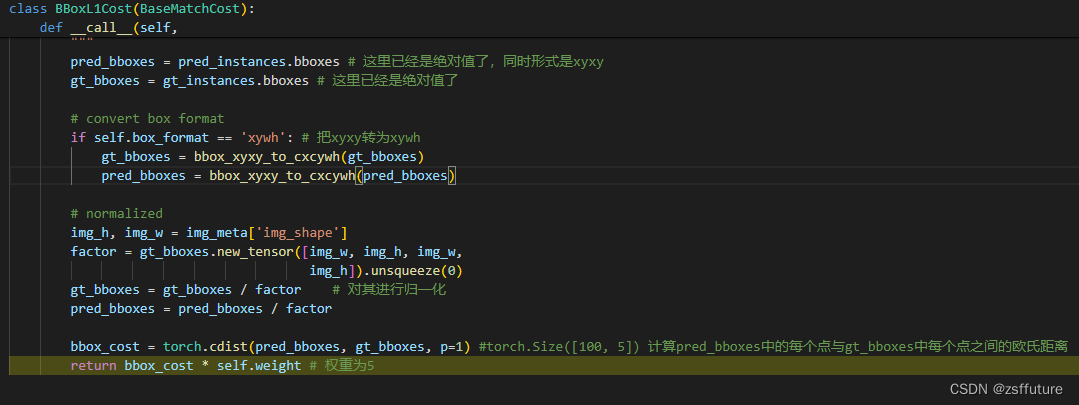
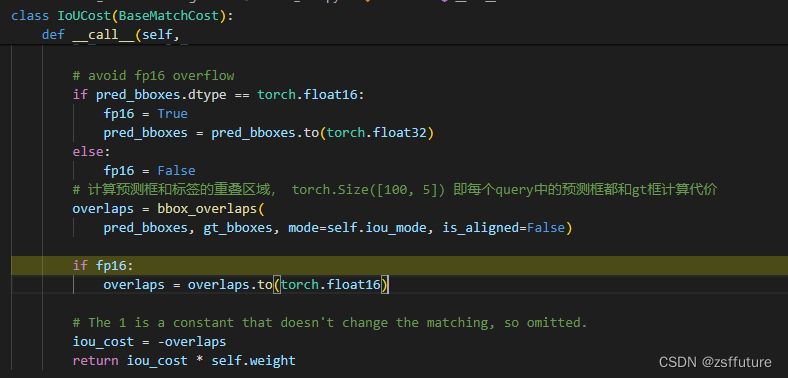
上面的三个代价计算结果都会存储到cost_list中,然后对该代价进行匈牙利配备后去最小的代价分配,进而确定使用哪个query进行预测前景,其他query预测背景
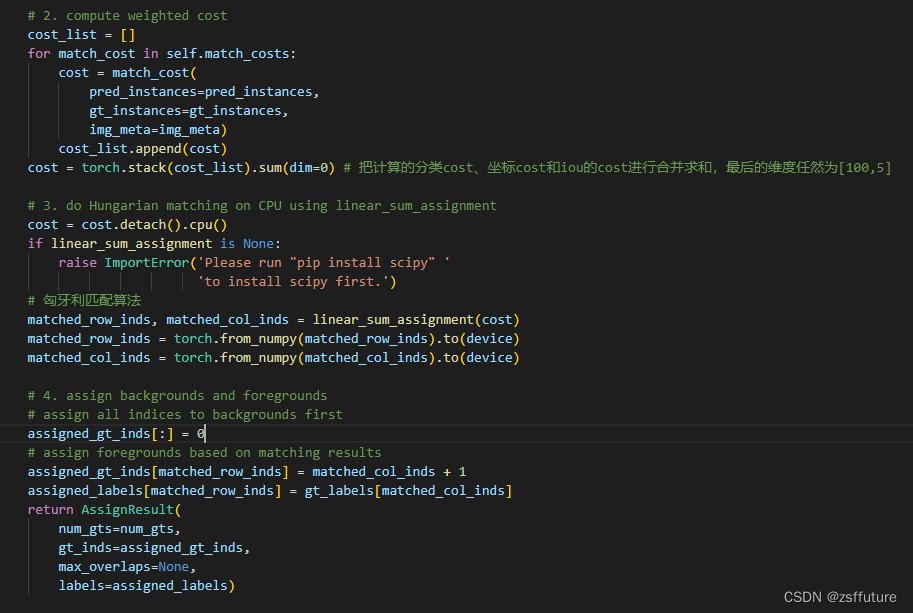
通过上面的匈牙利匹配我们找到了使用哪个query预测,后续就是使用这个query的分类预测结果和位置预测结果和对应的标签计算损失函数了:
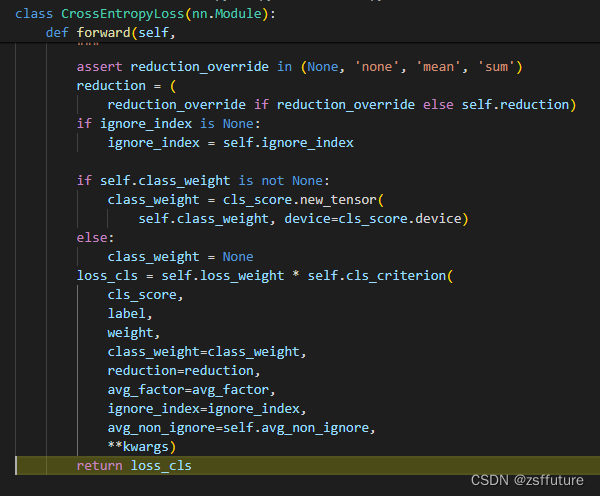
其他的损失例如位置损失和iou损失同样的进行计算即可:
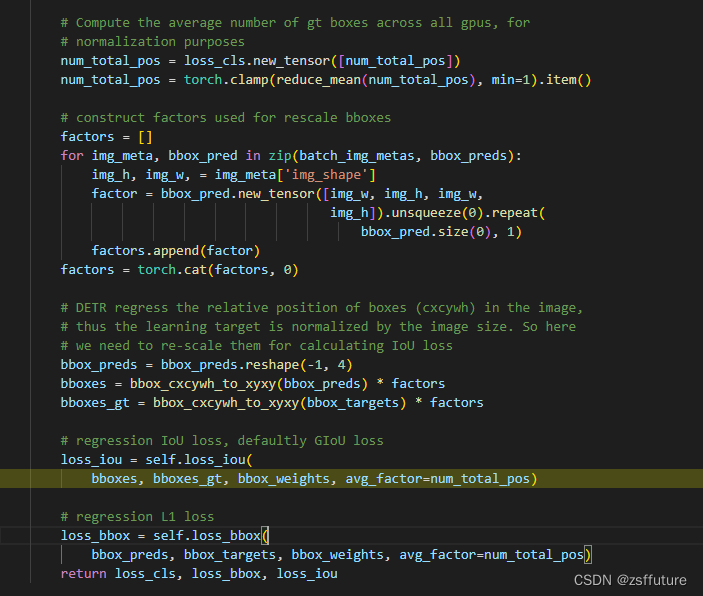 以上就是deter的主要内容。
以上就是deter的主要内容。

