
- 1如何使用C#与SQL Server数据库进行交互_c#程式和数据库沟通
- 2利用python绘制一个矩形_python画一个矩形
- 3区块链 | 最火的七大职业了解一下_区块链最吃香的岗位
- 4【AI大模型】Prompt Engineering_描述在ai大模型中,什么是“提示工程”(prompt engineering)
- 5Vue登录第1版_vue验证用户名和密码
- 6java做一个打地鼠小游戏_java打地鼠
- 7华为云受邀出席AICon2024 分享AI Agent在企业生产中的技术实践_aicon全球人工智能开发与应用大会2024 陈星亮
- 8python进行因子分析_python实现最大方差旋转法
- 9docker之win安装gitlab_gitlab安装包 windows
- 10Underscore.js 源码学习笔记(上)
MySQL数据结构_数据结构mysql
赞
踩
MySQL数据结构
前言
在日常工作中,MySQL无外乎是我们最熟悉的数据库了,理解MySQL的数据结构和索引特点,能够帮助我们写出查询效率更高,逻辑更为明确的SQL,也能给我们设计表结构时带来思路。
数据结构
索引
关于MySQL的优化我们第一想到的总是索引,那么,什么是索引呢?
索引是一种帮助MySQL高效获取数据的排好序的数据结构,如果是你,你会选用什么样的数据结构作为MySQL的底层存储?
如何选择数据结构
基于我们日常使用MySQl的情况,可以大致总结一下此数据结构的特点
- 查询效率高
- 支持数据量大,在千万级以上数据量时也要保持查询的稳定性
- 对范围查询友好
首先第一点:查询效率高,在众多的数据结构中,查询效率最高的必须是树了。
而支持查询的树有:
- 二叉搜索树
- 红黑树
- B树
- B+树
二叉搜索树
先不论它是否支持其他点,我们知道,平时我们的插入数据都是主键都是自增有序的,当二叉搜索树遇到这情况会发生什么?

此时,二叉搜索树退化成了链表。所以,该结构被我们pass掉了。
红黑树
简单来说红黑树是颗平衡树,当遇到某一边过长时将进行平衡,就像这样

所以它解决了退化为链表的问题,但是当数据量过大时,比如数据量达到1千万,他的树高为 2^n = 1千万,n大概是24。
也就是查询数据时,可能会有0~24次IO,时快时慢,所以这个数据结构,也不行。
B树
由上可知,树的高度决定了IO的次数,也就是查询效率。那么,该如何减少高度?
以上的树结构每个结点都只存了一个元素,如果我们能让一个结点存多个元素,是不是就能显著降低层高了?
这就是B树了
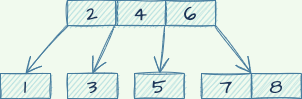
插入过程如图

和二叉树对比,树的高度确实会减小,每一个结点能够存放的元素越多,树的高度就减小的越多。
但它依旧有些别的缺点:
-
范围查询,显然,这棵树对范围查询确实不友好,比如从3到7,还是得一次一次的查出来。
-
在MySQL中,每行记录可不是只有1,2,3这种数字,还有很多其他的数据,一个结点的空间是有限的,每行记录越大,一个结点能存放的元素(记录)就越少,数据结构类似这样
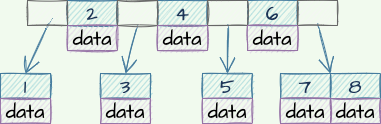
针对于以上两个问题,我们来看看B+树又是怎么解决的?
B+Tree
先来看看B+Tree的结构

B+tree相比于B-tree,有三个不同点:
-
叶子结点有互相指向的指针,便于进行范围查询,比如3-7,首先定位到3,然后从左往右遍历即可
-
叶子结点存放所有数据,其他非叶子节点冗余叶子结点的位置(用于定位),比如图中的
4 -
非叶子结点不存放数据,只存放索引,如此一个结点就存放更多的元素,就像这样

在MySQL中,一个结点的默认大小为16kb,指向其他结点的指针为6b,假设我们以主键(long类型)为索引,那么主键占用的空间为8b
如此,一个非叶子结点可以存放的元素个数为:16kb/(6b+8b)=1170
假设每行记录的大小为1kb,则一个叶子结点可以放16kb/1kb=16行记录
假设一颗3层的B+树,那么可以存放数据的行数为1170 * 1170 * 16 = 2.2千万
每行记录越小,则可以存放数据的行数越大,假设一行数据只有512b,则3层B+树可以存放4.4千万数据,这也是为什么垂直分表能够提高查询效率的原因之一。
综合以上情况,千万级数据量的表,查询数据也最多只要经历3次IO,而且根节点其实常驻在MySQL内存中。
Hash
Hash也是MySQL中的一种数据结构
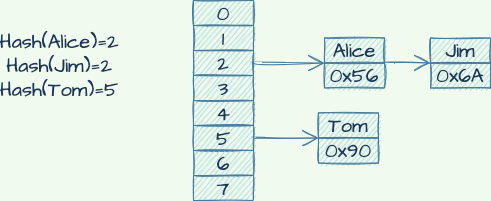
它的特点如下:
-
对索引的key进行一次hash计算就可以定位出数据
-
存储的位置仅能满足 “=”,“IN”
-
不支持范围查询Hash冲突
存储引擎
在日常工作中,常用的存储引擎有两种,InnodDB和MyISAM
InnoDB
聚集索引:叶子结点存储完整的数据,主键索引即数据文件
磁盘上以两个文件存储表信息
- table.frm: 表结构文件
- table.idb: 索引数据文件
比非聚集索引效率更高:减少了一次回表
MyISAM
非聚集索引:叶子结点存储的是指向数据的磁盘地址,索引和数据分离。
磁盘上以三个文件存储表信息
- table.frm: 表结构文件息
- table.MYI: 索引文件
- tbale.MYD: 数据文件
二级索引
在开发时,我们不仅会通过主键查询数据,也会通过其他字段查询数据,如username,此时也应该给username字段建立索引。
此类除主键索引之外的索引,称为二级索引或者辅助索引。
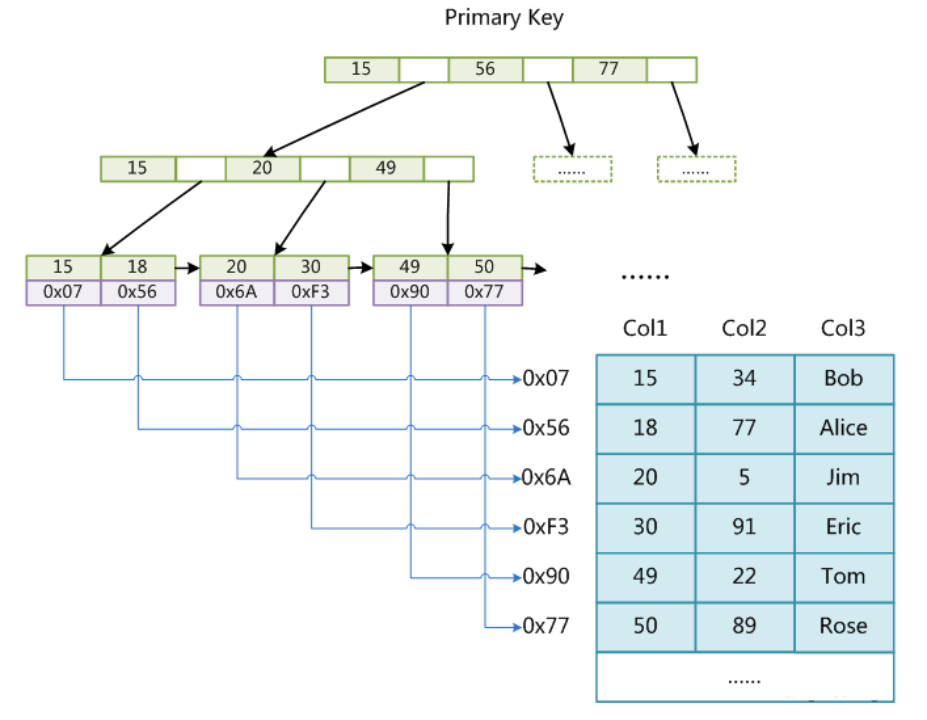
二级索引同样是颗B+树,与主键索引不同的是:二级索引的叶子节点并非存储完整的数据,而是存储主键。
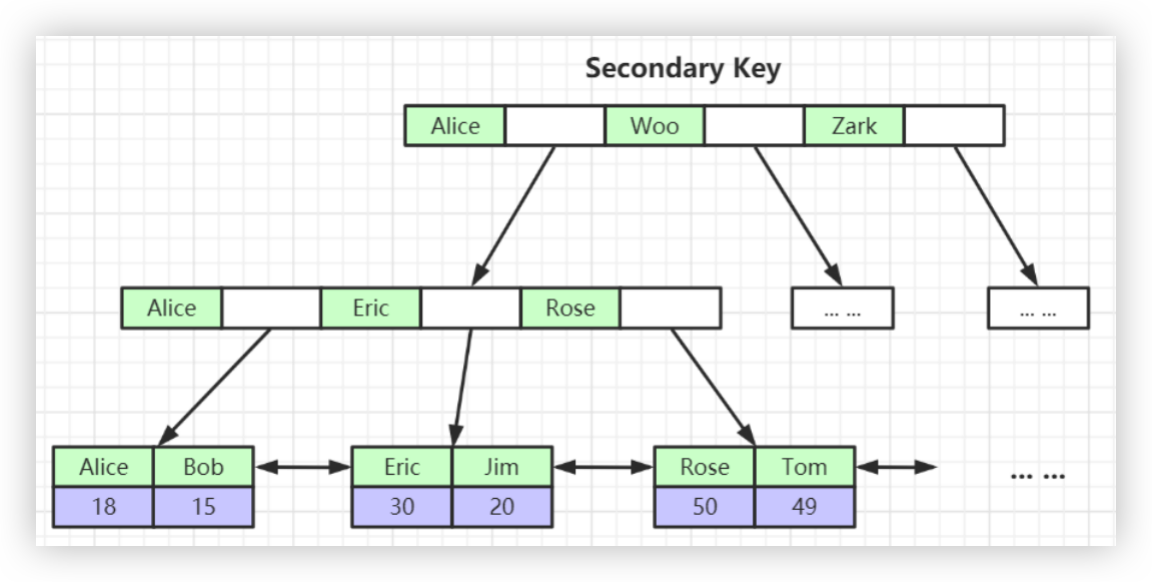
为什么二级索引存储的是主键而非完整数据?
- 一致性:如果二级索引也存储完整的数据,那么修改数据后就会很麻烦,需要修改主键索引又要修改二级索引。
- 节省磁盘空间
二级索引又分为普通索引和唯一索引。普通索引中比较特别的是联合索引,这也是平常开发打交道最多的索引。
联合索引
联合索引指由多个字段组成的索引,如name+age+positon构成这样一颗索引树,索引同样是从小到大排列,先排序第一个字段,第一个字段相同时排序第二个字段,以此类推。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-PE770WaA-1674891548799)(null)]
基本上,大部分的索引优化原则都是基于联合索引
建表时如果不设置主键会怎样?
上面说到,MySQL会以主键构成一颗索引树存储数据记录,反过来讲:数据的存储依赖于主键索引。那么,如果我们不设置主键会发生什么?
- 首先,MySQL会找表中是否有唯一索引,如果有,就以唯一索引作为主键。
- 如果没有唯一索引,那么将添加隐藏字段rowid作为主键。
查找算法
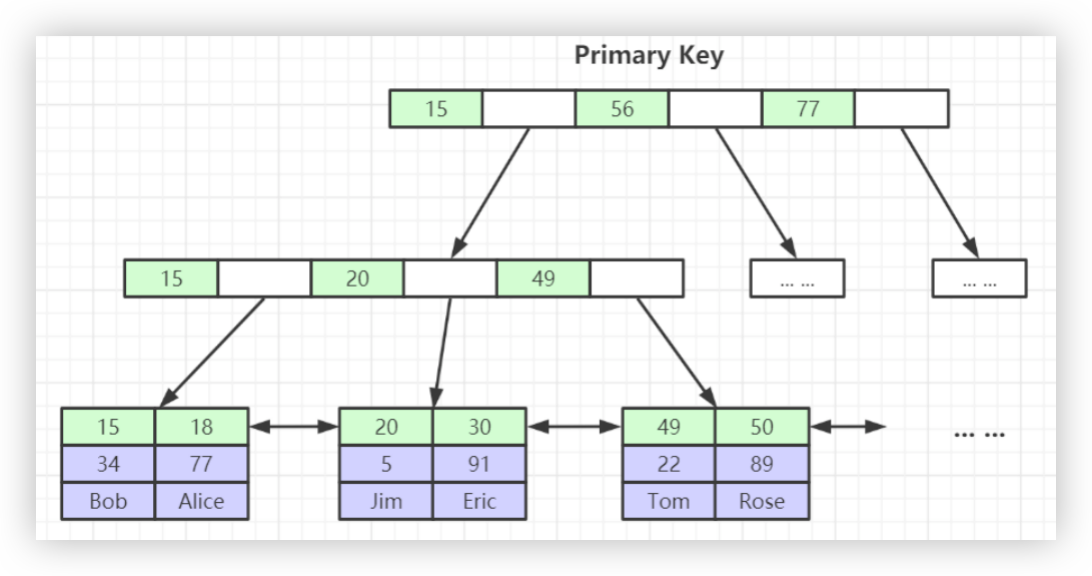
以下图索引树为例,查找id=30的行记录的过程是怎样的呢?
图中空白部分存储的为下个结点的磁盘地址,如根结点[15-56]之间的空白点存储的就是指向最左边子结点的磁盘地址。
1、首先,将根结点加载到内存中(后续根结点常驻内存)
2、二分查找id=30的位置,定位在15-56之间,读取下一个结点的磁盘地址
3、加载结点到内存,继续二分查找,定位在20-49之间,读取磁盘地址
4、加载叶子结点,找到id为30的记录
5、如果是通过二级索引查找,则继续使用主键回表查找主键索引
追更,想要了解更多精彩内容,欢迎关注公众号:程序员阿紫
个人博客网站:https://zijiancode.cn

