
热门标签
热门文章
- 1ElasticSearch常见用法,看这一篇就够了
- 2记录安装Nodejs和HBuilderX搭建、部署微信小程序开发环境(一)_如何配置和安装hbulder与微信小程序开发工具
- 3php textrank,textrank-jieba 算法复现
- 4项目打包上传到linux系统_项目打包后上传到linux服务器
- 5国行 lg g3 D858 刷 lg g3 D858hk 教程(备忘)
- 6什么是虚拟内存?_虚拟内存是指外存的一部分,可以解决内存不足的问题,它按照外存的管理方式进行管理
- 7java Flink(四十二)Flink的序列化以及TypeInformation介绍(源码分析)
- 8AI 数字人短视频变现及引流,轻松掌握流量密码_独特的ai数字人播报视频引流
- 9机器学习中的无监督学习是什么?
- 10representation learning 表示学习_张似衡
当前位置: article > 正文
改进YOLO系列:改进YOLOv8,教你YOLOv8如何添加20多种注意力机制,并实验不同位置。_yolov8添加注意力机制
作者:凡人多烦事01 | 2024-03-20 06:16:06
赞
踩
yolov8添加注意力机制
改进YOLOv8,YOLOv8添加20多种注意力机制
一、注意力机制介绍
注意力机制(Attention Mechanism)是深度学习中一种重要的技术,它可以帮助模型更好地关注输入数据中的关键信息,从而提高模型的性能。注意力机制最早在自然语言处理领域的序列到序列(seq2seq)模型中得到广泛应用,后来逐渐扩展到了计算机视觉、语音识别等多个领域。
注意力机制的基本思想是为输入数据的每个部分分配一个权重,这个权重表示该部分对于当前任务的重要程度。在自然语言处理任务中,这通常意味着对输入句子中的每个单词分配一个权重,而在计算机视觉任务中,这可能意味着为输入图像的每个像素或区域分配一个权重。
二.添加方法
1.GAM注意力
论文原文:https://arxiv.org/pdf/2112.05561v1.pdf
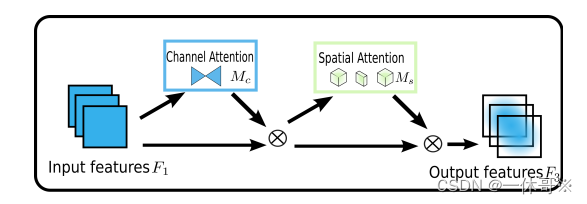
该论文提出了一种全局注意力机制(GAM),可以通过保留空间和通道信息之间的关联来提高模型的性能。GAM能够有效地捕捉不同通道之间的相关性,进而更好地区分不同的目标。
网络结构图:
import torch.nn as nn import torch class GAM_Attention(nn.Module): def __init__(self, in_channels,c2, rate=4): super(GAM_Attention, self).__init__() self.channel_attention = nn.Sequential( nn.Linear(in_channels, int(in_channels / rate)), nn.ReLU(inplace=True), nn.Linear(int(in_channels / rate), in_channels) ) self.spatial_attention = nn.Sequential( nn.Conv2d(in_channels, int(in_channels / rate), kernel_size=7, padding=3), nn.BatchNorm2d(int(in_channels / rate)), nn.ReLU(inplace=True), nn.Conv2d(int(in_channels / rate), in_channels, kernel_size=7, padding=3), nn.BatchNorm2d(in_channels) ) def forward(self, x): b, c, h, w = x.shape x_permute = x.permute(0, 2, 3, 1).view(b, -1, c) x_att_permute = self.channel_attention(x_permute).view(b, h, w, c) x_channel_att = x_att_permute.permute(0, 3, 1, 2).sigmoid() x = x * x_channel_att x_spatial_att = self.spatial_attention(x).sigmoid() out = x * x_spatial_att return out if __name__ == '__main__': x = torch.randn(1, 64, 20, 20) b, c, h, w = x.shape net = GAM_Attention(in_channels=c) y = net(x) print(y.size())

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
添加方法1
此方法适用于较早版本的yolov8代码,最新的yolov8代码加入方式看方法2
##将以上代码放到ultralytics/nn/modules.py里
在tasks.py里要加入from yltralytics.nn.modules import *
在ultralytics/nn/tasks.py处引用
注册以下代码:
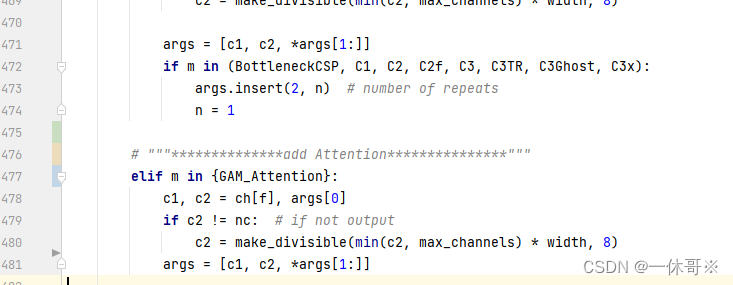
# """**************add Attention***************"""
elif m in {GAM_Attention}:
c1, c2 = ch[f], args[0]
if c2 != nc: # if not output
c2 = make_divisible(min(c2, max_channels) * width, 8)
args = [c1, c2, *args[1:]]
- 1
- 2
- 3
- 4
- 5
- 6
2.骨干中添加
新建yaml文件
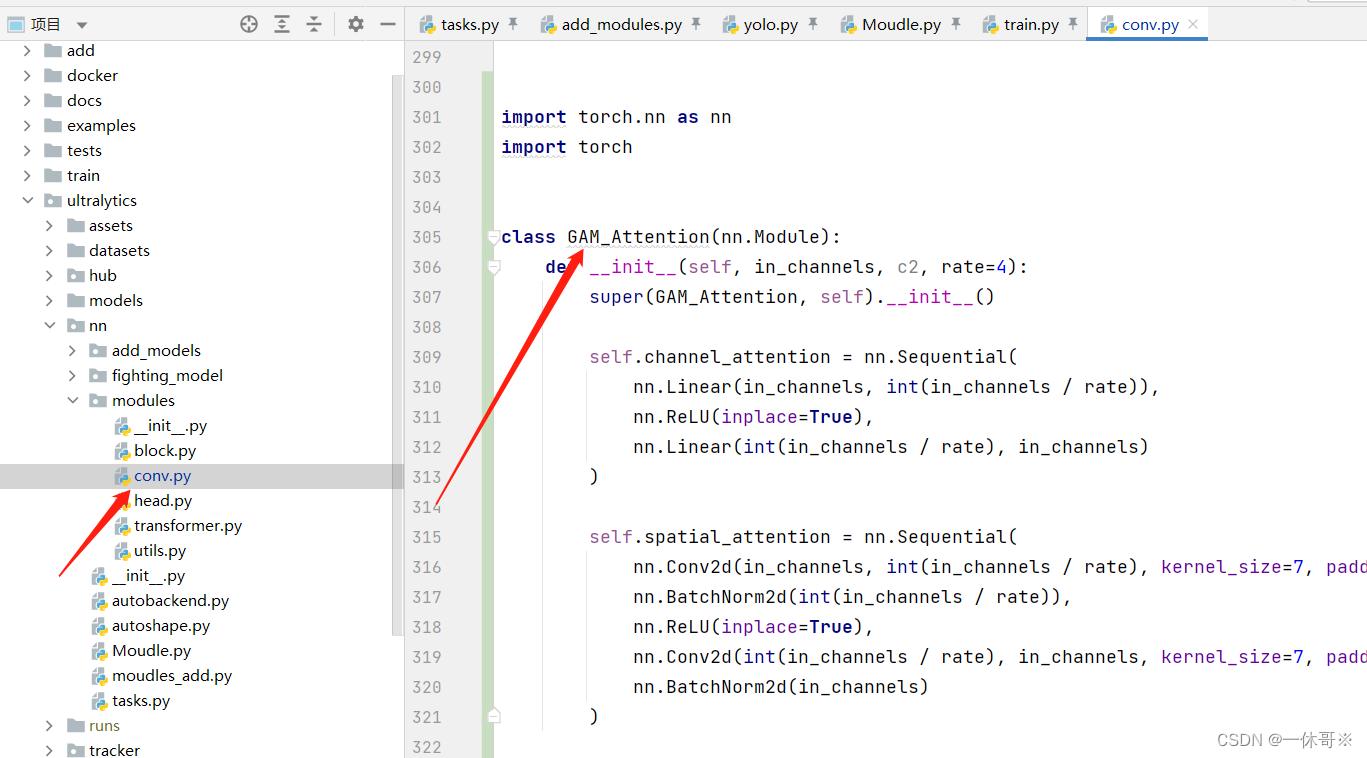
添加方法2
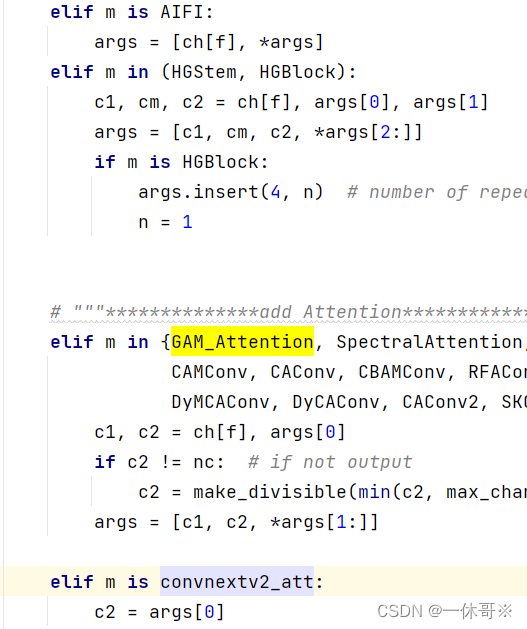
1.block代码中加入注意力代码
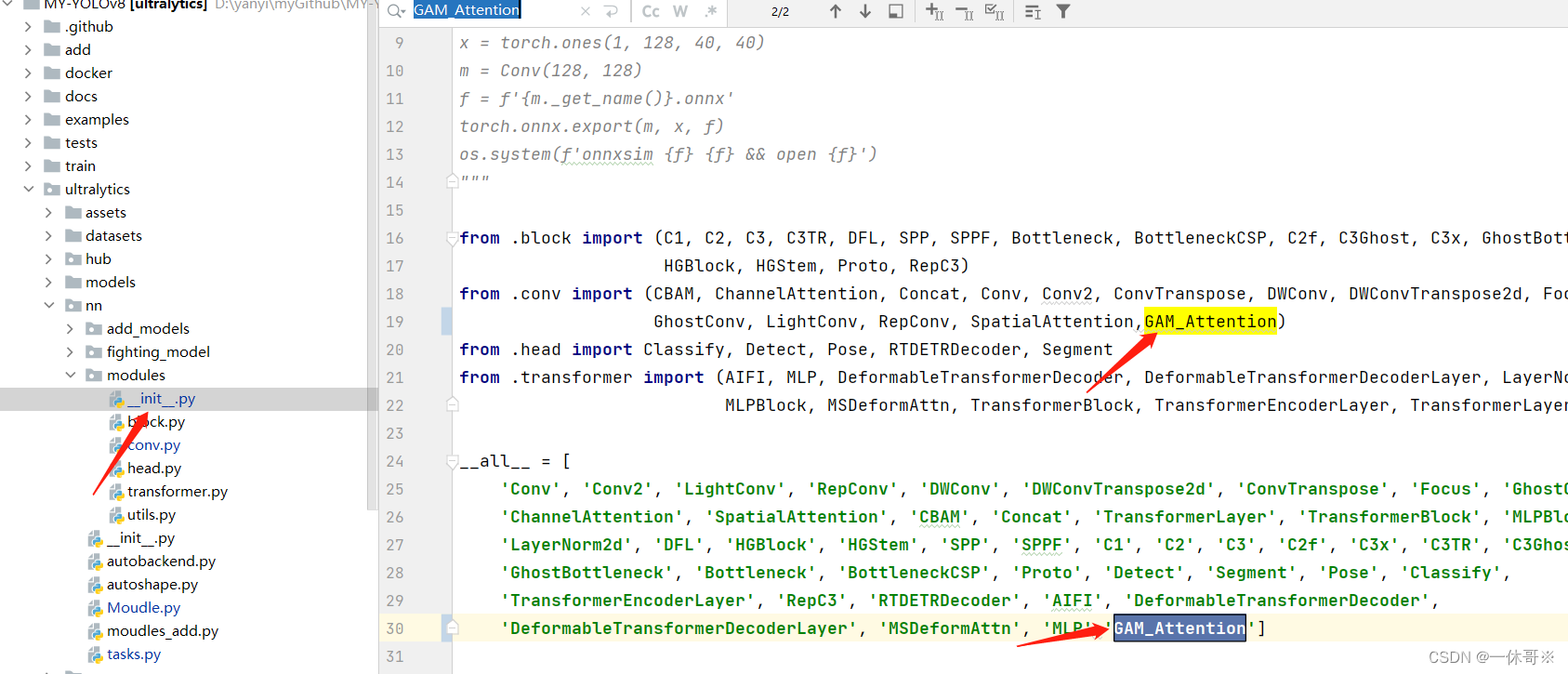
2.注册及引用GAM注意力代码
ultralytics/nn/modules/init.py文件中
ultralytics/nn/tasks.py文件中
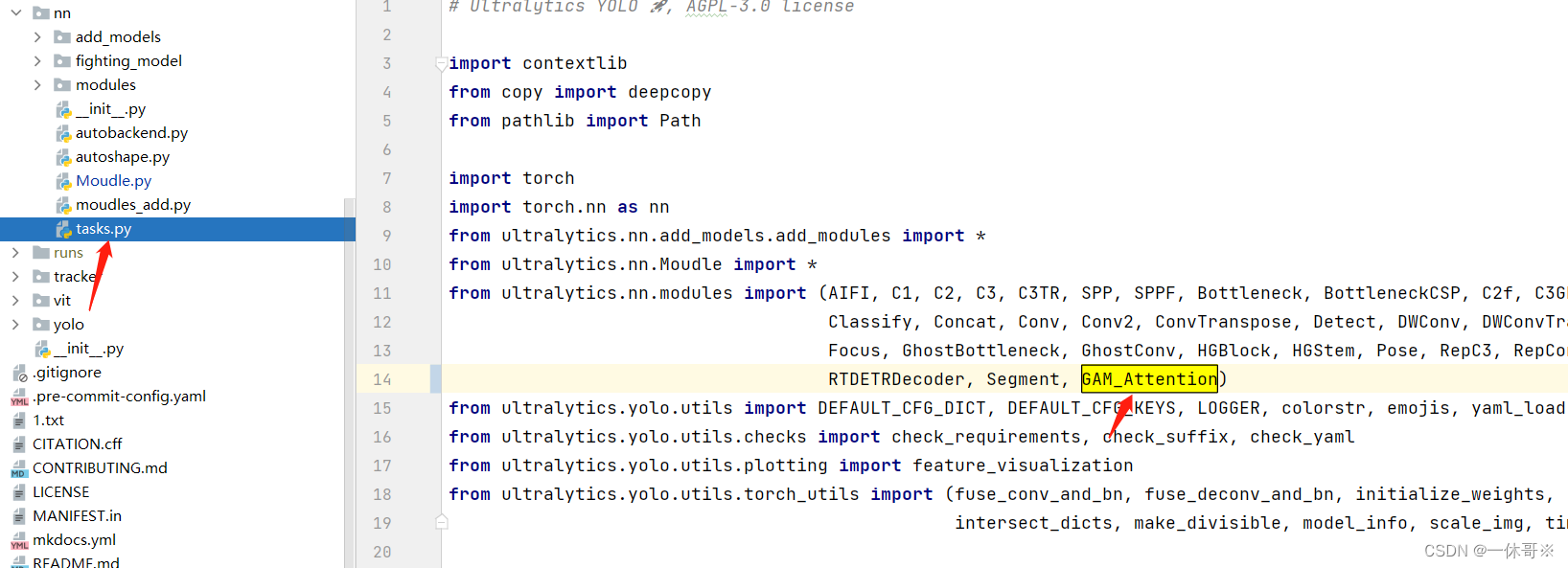
tasks里写入调用方式
# """**************add Attention***************"""
elif m in {GAM_Attention}:
c1, c2 = ch[f], args[0]
if c2 != nc: # if not output
c2 = make_divisible(min(c2, max_channels) * width, 8)
args = [c1, c2, *args[1:]]
- 1
- 2
- 3
- 4
- 5
- 6
示例
yaml文件
# Ultralytics YOLO 声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/凡人多烦事01/article/detail/271274推荐阅读
相关标签
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

