
- 1ubuntu服务器docker环境实现基于diffusers的stable diffusion部署_ubuntu docker stable diffusion
- 22_用keras训练一个神经网络及不同优化和初始化对性能的影响分析_neural nets with keras
- 3vue init webpack 卡在chromedriver上问题解决办法_chromedriver installation failed error with http(s
- 4解决uniapp下无法唤起微信公众号H5扫码问题_uniapp jweixin-module ios微信扫码没反应
- 5github-action+docker实现项目可持续自动化部署_github actions docker
- 6首个中文原生DiT架构!腾讯混元文生图大模型全面开源,免费商用
- 7OGG基本框架、安装、运维、报错处理、监控命令._oracle ogg源端数据库关闭了
- 8linux电容触摸屏驱动参数,基于FT5x06嵌入式Linux电容触摸屏驱动
- 9fpga烧写bin文件_FPGA烧写的方式和具体过程分析
- 101 vue.js - MVVM模式_说—下vue.js中的mvvm模式。
HiveSQL常用优化技巧_大数据hive sql优化
赞
踩
这次的目的很简单,就是利用各种技巧提升SQL执行效率
前言
好的,废话不多说,直接上干货
技巧一、去重一一用group by来替换distinct
小结:
1.使用场景仅限去重,不可以应用在去重计算count(distinct XX)
2.在极大的数据量(且很多重复值)时,可以先group by去重,再count()计数, 效率高于直接 count(distinct XX)
取出user_trade表中全部支付用户
##原有写法
SELECT distinct user_name
FROM user_trade
WHERE dt>'0';
##优化写法
SELECT user_name
FROM user_trade
WHERE dt>'O'
GROUP BY user_name;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
在2019年购买后又退款的用户
SELECT a.user_name
FROM
(SELECT distinct user_name
FROM user_trade
WHERE year(dt) =2019) a
JOIN
(SELECT distinct user_name
FROM user_refund
WHERE year(dt) =2019) b on a.user_name=b.user_name;
##优化写法:
SELECT a.user_name
FROM
(SELECT user_name
FROM user_trade
WHERE year(dt) =2019
GROUP BY user_name) a
JOIN
(SELECT user_name
FROM user_refund
WHERE year(dt) =2019
GROUP BY user_name ) b on a.user_name=b.user_name;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
技巧二、聚合- --利用窗口函数grouping sets、cube、 rollup
grouping sets
1.GROUPING SETS():在group by查询中,根据不同的维度组合进行聚合,等价于将不同维度的group by结果集进行union all。
2.聚合规则在括号中进行指定。
用户的性别分布、城市分布、等级分布
常规写法:(缺点:写三次SQL,执行三次,重复工作,且费时)
--性别分布
SELECT sex,
count(distinct user_id)
FROM user_info
GROUP BY sex;
--城市分布
SELECT city,
count(distinct user_id)
FROM user_info
GROUP BY city;
--等级分布
SELECT level,
count(distinct user_id)
FROM user_info
GROUP BY level;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
优化写法:
SELECT sex,
city,
level,
count(distinct user_id)
FROM user_info
GROUP BY sex,city,level
GROUPING SETS(sex,city, level);
- 1
- 2
- 3
- 4
- 5
- 6
- 7
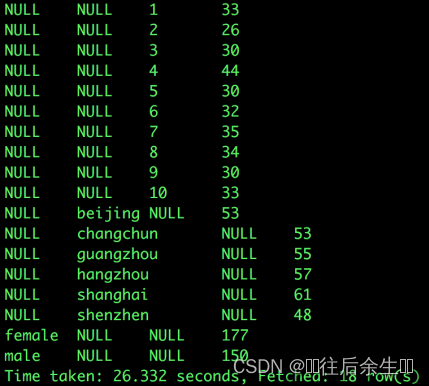
聚合结果均在同一列,分类字段用不同列来进行区分
举一反三:
用户的性别分布以及每个性别的城市分布
常规写法:
--性别分布
SELECT sex,
count(distinct user_id)
FROM user_info
GROUP BY sex;
--每个性别的城市分布
SELECT sex,
city,
count (distinct user_id)
FROM user_info
GROUP BY sex,
city;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
优化写法:
SELECT sex,
city,
count(distinct user_id)
FROM user_info
GROUP BY sex,city
GROUPING SETS(sex, (sex,city));
- 1
- 2
- 3
- 4
- 5
- 6
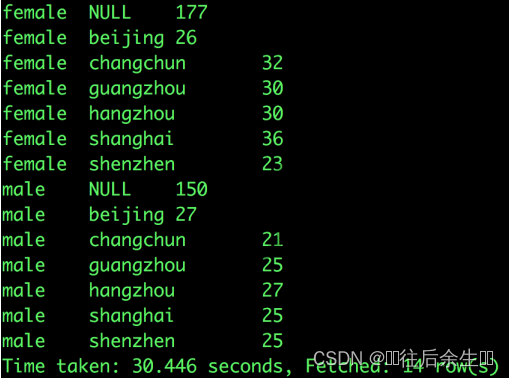
第二列为NULL的,即是性别的用户分布,其余有城市的均为每个性别的城市分布
cube
根据group by 维度的所有组合进行聚合
性别、城市、等级的各种组合的用户分布
SELECT sex,
city,
level,
count(distinct user_id)
FROM user_info
GROUP BY sex,city,level
GROUPING SETS(sex,city, level, (sex,city), (sex, level), (city, level), (sex,city, level));
##优化写法
--性别、城市、等级的各种组合的用户分布
SELECT sex,
city,
level,
count(distinct user_id)
FROM user_info
GROUP BY sex,city, level
with cube;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
跑完数据后,整理很关键!!
rollup
以最左侧的维度为主,进行层级聚合,是cube的子集
同时计算出,每个月的支付金额,以及每年的总支付金额
--每月的支付金额和每年的支付金额汇总
SELECT a.dt,
sum(a.year_amount),
sum(a.month_amount)
FROM
(SELECT substr(dt,1,4) as dt,
sum(pay_amount) year_amount,
0 as month_amount
FROM user_trade
WHERE dt>'O'
GROUP BY substr(dt,1,4)
UNION ALL
SELECT substr(dt,1,7) as dt,
0 as year_amount,
sum(pay_amount) as month_amount
FROM user_trade
WHERE dt>'0'
GROUP BY substr(dt,1,7)
) a
GROUP BY a.dt;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
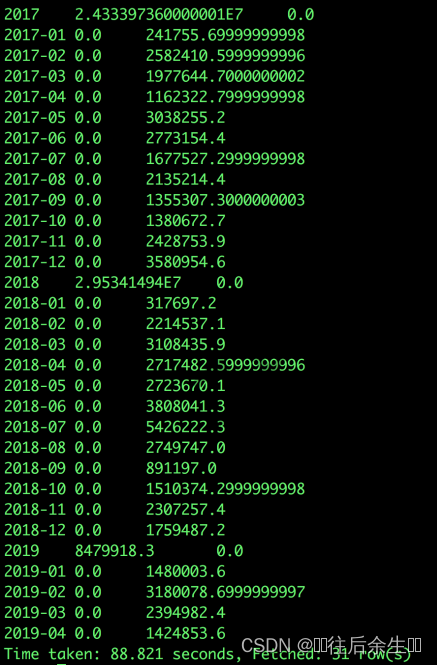
优化写法:
SELECT year(dt) as year,
month(dt) as month,
sum(pay_amount)
FROM user_trade
WHERE dt>'0'
GROUP BY year(dt),
month(dt)
with rollup;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
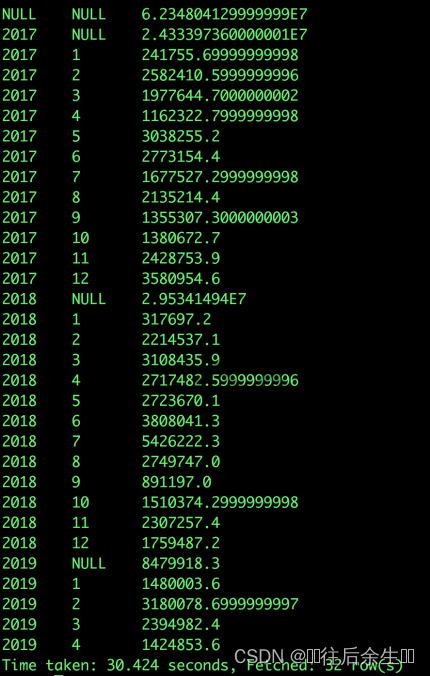
技巧三、换个思路解题
在2017年和2018年都购买的用户
SELECT a.user_name
FROM
(SELECT distinct user_name
FROM user_trade
WHERE year(dt) =2017) a
JOIN
(SELECT distinct user_name
FROM user_trade
WHERE year(dt) =2018) b on a.user_name=b.user_name;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
优化写法:
SELECT a.user_name
FROM
(SELECT user_name,
count(distinct year(dt)) as year_num
FROM user_trade
WHERE year(dt) in(2017, 2018)
GROUP BY user_name) a
WHERE a.year_num=2
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
技巧四、union all时可以开启并发执行
参数设置: set hive.exec.parallel=true
可以并行的任务较多时,开启并发执行,可以提高执行效率。
每个用户的支付和退款金额汇总
set hive.exec.parallel=true
SELECT a.user_name,
sum(a.pay_amount),
sum(a.refund_amount)
FROM
(
SELECT user_name,
sum(pay_amount) as pay_amount,
0 as refund_amount
FROM user_trade
WHERE dt>'0'
GROUP BY user_name
UNION ALL
SELECT user_name,
0 as pay_amount,
sum(refund_amount) as refund_amount
FROM user_refund
WHERE dt>'0'
GROUP BY user_name
) a
GROUP BY a.user_name;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
技巧五、利用lateral view进行行转列
split():字符串分割函数.
explode: 行转列函数
列转行函数: concat_ws(‘,’,collect_set(column))
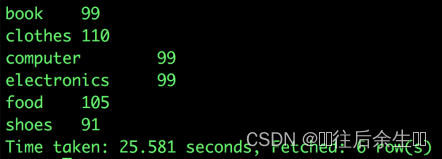
每个品类的购买用户数
SELECT b.category,
count(distinct a.user_name)
FROM user_goods_category a
lateral view explode(split(category_detail,',')) b as category
GROUP BY b.category;
- 1
- 2
- 3
- 4
- 5
技巧六、表连接优化
1.小表在前,大表在后
Hive假定查询中最后的一个表是大表,它会将其它表缓存起来,然后扫描最后那个表。.
2.使用相同的连接键
当对3个或者更多个表进行join连接时,如果每个on子句都使用相同的连接键的话,那么只会产生一个MapReduce job
3.尽早的过滤数据
减少每个阶段的数据量,对于分区表要加分区,同时只选择需要使用到的字段。
4.逻辑过于复杂时,引入中间表
技巧七、如何解决数据倾斜
数据倾斜的表现:
任务进度长时间维持在99%(或100%),查看任务监控页面,发现只有少量(1个或几个) reduce子任务未完成。因为其处理的数据量和其他reduce差异过大。
数据倾斜的原因与解决办法:
空值产生的数据倾斜
解决:如果两个表连接时,使用的连接条件有很多空值,建议在连接条件中增加过滤例如: on a.user_id=b.user_id and a.user_id is not null
大小表连接(其中一张表很大,另一张表非常小)
解决:将小表放到内存里,在map端做Join
SELECT /*+mapjoin(a)*/,
b.*
FROM a join b on a.**=b.**
- 1
- 2
- 3
两个表连接条件的字段数据类型不一致
解决:将连接条件的字段数据类型转换成一致的
如: on a.user_id=cast(b.user_id as string)
技巧八、如何计算按月累计去重
一般情况下用sum()、over()来计算按一定周期进行累计求和
其实还有更优的解法,去计算按月累计去重
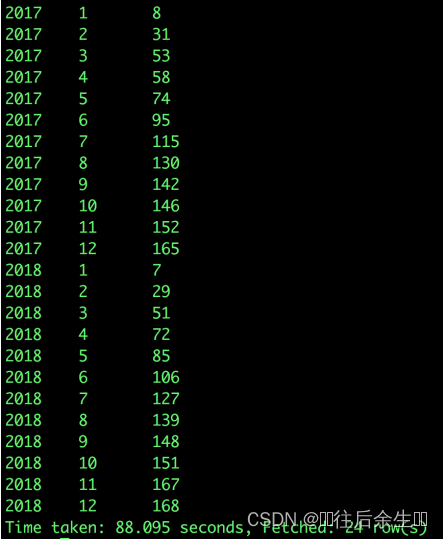
2017、2018年按月累计去重的购买用户数
SELECT b.year,
b.month,
sum(b.user_num) over(partition by b.year order by b.month)
FROM
( SELECT a.year,
a.month,
count(distinct a.user_name) user_num
FROM
(SELECT year(dt) as year,
user_name,
min(month(dt)) as month
FROM user_trade
WHERE year(dt) in(2017,2018)
GROUP BY year(dt),
user_name) a
GROUP BY a.year,
a.month) b
ORDER BY b.year,
b.month
limit 24;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
优化写法:
set hive.mapred.mode=nonstrict;
SELECT b.month,
count(distinct a.user_name)
FROM
(SELECT substr(dt, 1,7) as month,
user_name
FROM user_trade
WHERE year(dt) in(2017,2018)
GROUP BY substr(dt,1,7),
user_name) a
CROSS JOIN
(
SELECT month
FROM dim_month) b
WHERE b.month>=a.month
and substr(a.month, 1,4) =substr(b.month, 1,4)
GROUP BY b.month;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
总结
1.巧用group by
2.利用窗口函数提升聚合计算效率
3.必要时开启并发执行
4.行转列、列转行
5.小技巧提升表连接效率
6.多思路解题


