
- 1Docker入门(清晰认识)
- 2Spring Boot整合actuator实现监控管理
- 3Anaconda3安装VSCode提示Please make sure you are connected to the internet!
- 4论文阅读 基于机器学习文本处理的PHP和JSP Web shell检测系统(上海交大)_php word2vec
- 5电池的各类SOC估计方法存在的问题_开路电压soc的缺点
- 6ArcGIS Maps SDK for JavaScript:鼠标进入面要素时改变鼠标指针样式,离开时恢复
- 7【活动感想】筑梦之旅·AI共创工坊 workshop 会议回顾_共创活动workshop
- 8Java实现宿舍管理系统、基于java、JDBC、GUI、MySql、eclipse(含源文件/综合项目/数据库)
- 9个性化定制标注工具labelimg_labelimg软件
- 102024最新最全面的自动化测试学习步骤及路线(超详细)
如何定量分析 Llama 3,大模型系统工程师视角的 Transformer 架构
赞
踩
读完全文后,你将获得回答以下问题的能力(参考答案,请见最后一章节):
-
Llama 3 技术博客说 70B 模型、最长序列 8K、15T Tokens,训练了 640w GPU 时,这发挥了 H100 理论算力(989TFlops)的百分之多少?
-
Llama 2 7B 模型,这个 7B 是怎么算出来的? 这个模型训练和推理一个 Token 分别需要多少计算量?
-
Llama 2 70B 模型,使用 8 卡 A800 推理,16 个请求输入都是 4000 Tokens,要求首 Token 时延在 600-700ms 左右。这个需求合理么?
-
准备用 2 张 A800 跑 Llama 2 70B 模型推理(fp16 精度),如果输入输出最大长度是 4000 Tokens,那系统最大能跑多大并发?
今天的分享主要从工程师的视角来剖析 Transformer 的整体架构,主要分 4 个部分:
- 第 1 部分会介绍一些基础知识,帮助大家对后面讨论的内容做个铺垫。
- 第 2 部分是对 Transformer 架构的定量分析,也是今天分享的重点。在这个部分我会把 Transformer 架构打开,告诉大家它内部做了什么事情,并针对该模型做了一些定量分析,进而形成一些量化的结论。
- 第 3 部分我们会展示一些目前比较热门的 Transformer 架构变种,并从架构的视角来分析各个变种的效果和优化点。
- 第 4 部分是对一些实际案例进行分析,通过实战更好地让大家对大模型的性能和相关问题有更深入的理解。
1 基础知识回顾
在该部分我会介绍张量基础概念、张量和矩阵乘法以及 GPU 标称算力的基本原理。
1.1 张量是什么
张量这个概念可能大家平时听的比较多,但不太理解它具体是什么。其实张量就是多维数组。举个例子,如果数组是零维的,那其实它就是一个标量,即一个数字。如果是一维的,那么它就是一个向量,或者称之为一维数组。如果是二维的,那么它就是一个矩阵。如果数组的维度再高,比如说三维或者更高的维度,那么就给它起了个统一的名字,即张量。本次分享中,我们使用括号 [ ] 的形式来表示张量。
在大语言模型中,我们通常会在以下几种场景中使用到张量。
- 首先是权重 [hidden_size, hidden_size],我们一般使用二维的张量,即矩阵的形式来进行表示。在本次分享中,我们后续会用 [H, H] 来表示。
- 其次是激活值 [batch_size, seq_len, hidden_size],即输入输出值,我们一般使用三维的张量来进行表示。其中 batch_size 代表批的大小,seq_len 代表句子的长度 ,hidden_size 代表隐空间的大小。在本次分享中,我们后续会用 [B, S, H] 来表示。
- 第三是区分多头注意力的表示 [batch_size, seq_len, num_heads, head_size],我们一般用四维的张量来进行表示,在本次分享中,我们后续会用 [B, S, h, d] 来表示。

1.2 矩阵乘法与张量乘矩阵
接下来,我们来介绍一下矩阵乘法以及涉及到张量的矩阵乘法。
M*K 的矩阵 A 与一个 K*N 的矩阵 B 相乘后,就会得到一个 M*N 的矩阵。在后面,我们统一用@表示矩阵乘法,上面的例子我们也可以形式化表示为 [M, K]@[K, N]。
对于上述矩阵乘法,由于结果矩阵中的每一项我们都做了 K 次乘法和 K 次加法,所以对最终结果来说,总的计算量为 2*M*K*N(其中 2 表示一次乘法与一次加法计算)。相应的访存量我们也可以推导出来,包括 A 和 B 矩阵的读与结果矩阵的写,即(M*K + K*N + M*N)*sizeof(dtype),这也是下文我们统计计算量和访存量时会反复用到的工具。
那如果我们希望将上述简单的矩阵乘法应用到张量上,那应该如何来做呢?比如图中的 [B, S, H] 的张量与 [H, H] 的矩阵做乘法,我们可以将前一个张量理解为 S*H 的矩阵复制了 B 份,对于每个 S*H 的矩阵都和 H*H 的矩阵相乘。这样相乘后,我们其实就得到了一个 [B, S, H] 的结果。
所以从计算量的角度来说,对于 [A, M, K] 与 [K, N] 的矩阵乘法,最终的结果为 [A, M, N],总计算量相较于二维的矩阵乘法多了 A 次复制,所以总计算量为 2*A*M*K*N,访存量则为(A*M*K + K*N + A*M*N)*sizeof(dtype)。
以上就是张量乘法的一些基本过程,后面我们在推导实际计算过程时,会用到这些数学知识。

1.3 GPU 标称算力原理
接下来,我们来补充一些 GPU 算力相关的知识。
当提到 GPU, 比如说 A800 时,大家可能都会或多或少听说它的理论算力是 312 TFLOPS ,那这个数是怎么来的呢?
首先 312 TFLOPS 指的是 Tensor Core 的算力。Tensor Core 可以理解为硬件上的一个针对矩阵乘法专门优化过的硬件单元。以 A800 的 Tensor Core 为例,在它的一个时钟周期内可以计算一个 8*4*8 的小矩阵,由前文我们提到的矩阵计算量可知,在一个 GPU 的时钟周期内,一个 Tensor Core 进行了 2*(8*4*8) 次浮点数操作。A800 的主频为 1410 MHz,同时一张 A800 中有 108 个 SM,每个 SM 由 4 个 Tensor Core 组成。因此我们可以得到 A800 的算力为 2*(8*4*8)*4*108*1410 MHz,即 311.8 TFLOPS,约为 312 TFLOPS。这也是 A800 理论算力 312 TFLOPS 的由来。
上述的计算过程也给了我们一些启发,如果我们想要把 A800 312 TFLOPS 的算力完全发挥出来,其实有几个优化细节:
- 必须使用 Tensor Core。这也就意味着我们必须要做 8*4*8 的小矩阵乘法。如果我们要做非矩阵乘法操作,那肯定达不到最好的结果
- 任务要切的足够散。因为每张 A800 中有 432 个 Tensor Core(每个 A800 中有 108 个 SM,每个 SM 上有 4 个 Tensor Core),只有在每个 Tensor Core 上都有 8*4*8 的小矩阵,才能让我们的算力充分发挥起来。切分的矩阵过大或者过小都不利于算力的充分发挥。
除此之外,对于 GPU 来说,由于存在任务分配不均等问题,不同的芯片能发挥出来的极限效果也不太一样。对于 A800 来说,它最多只能发挥出 312 TFLPOS 的 80%,具体的芯片需要实测来进行具体的评估。

2 Transformer 架构定量分析
2.1 初代 Transformer 架构
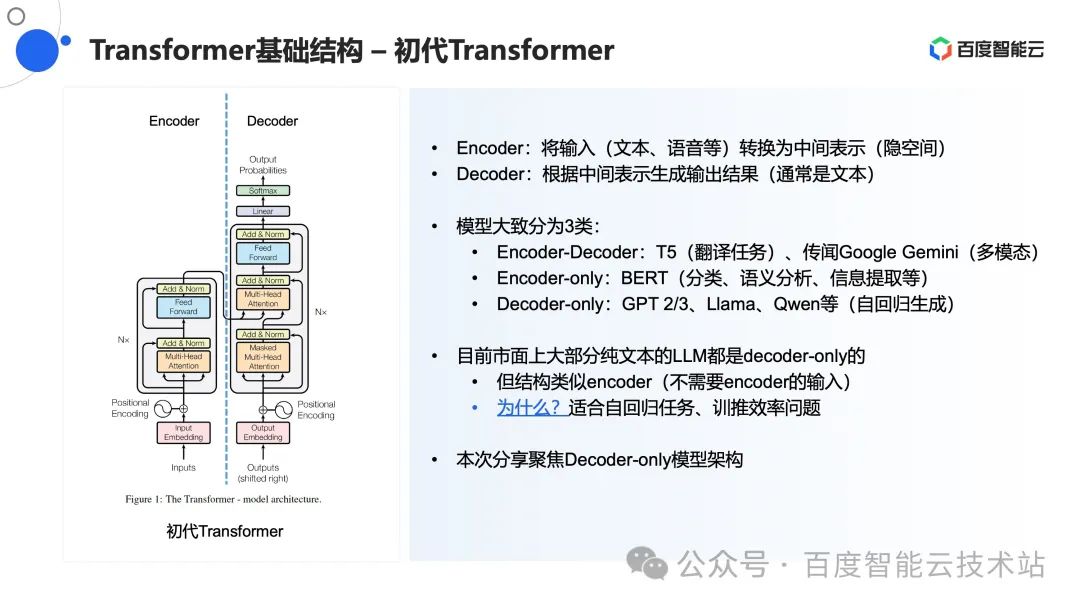
我们从初代 Transformer 开始着手。初代 Transformer 是 Google 在论文《Attention is all you need》中提出的。它包含两部分,一个是 Encoder 部分,它将输入(文本、语音等)转化为隐空间。另一个是 Decoder 部分,它根据隐空间生成对应的结果(通常为文本的形式)。
我们先讨论 Encoder 部分。它的输入是一段文本。Encoder 部分对文本进行编码之后,会重复经过两个结构。第一个是 Multi-Head Attention,第二个是 Feed Forward。在这两个结构之间,为了算法的稳定性和效果,会做一些残差的累加以及归一化的操作。
在 Encoder 架构中,它主要的工作就是将文本或者语音的输入信息转换为一个中间表示,也就是隐空间,即刚刚在前文提到的 hidden_size。有了这个隐空间之后,我们就可以在 Decoder 中结合隐空间的输入信息以及自身输出的信息,推断出下一个的输出结果。
接下来我们讨论 Decoder 部分。其实 Decoder 和 Encoder 的基本结构是相似的,但 Decoder 为了使用 Encoder 传过来的值,加了一个 Cross Attention 结构。通过这种方式,Decoder 重复 N 次就可以拿到最终的结果。以上就是 Transformer 的整体逻辑介绍。
一般来说,Transformer 一般分为三大类:
- 第一种是 Encoder-Decoder 类型。该类型完整遵循了原始 Transformer 结构,通常会用于翻译任务或者多模态的任务中。传闻 Google 的 Gemini 模型就采用了该架构。
- 第二种是 Encoder-Only 类型。只包括左边的 Encoder 部分。这也意味着无论输入什么信息,最终都会转化为隐空间的信息。该类型通常适用于分类、语音分析或者信息提取等相关的任务。最经典的就是前些年比较火的 BERT 类模型。
- 第三种是 Decoder-Only 类型。这也是最近比较火的生成式大模型所采用的主要架构。由于生成式大模型并不需要 Encoder 传入相关信息,所以本质上来说它的架构是没有中间 Cross Attention 的 Decoder 架构。比如 Llama、通义千问等模型。
接下来,我们的分享重点聚焦在 Decoder-Only 模型架构,
2.2 GPT 2 整体结构
我们接下来以 GPT 2 为例,了解大模型在推理和训练中的相关步骤。
我们先看推理的场景。我们都知道,在和大语言模型进行交互时,用户会先输入一些文本信息,这些文本信息会通过 Tokenizer 转换为 Token ID,然后不断进行 Decoder 操作最终生成一个隐空间的表示(即图中的 Hidden States)。隐空间本质上来说就是一堆向量,对于每一个词我们都有一个一定大小的向量来进行表示。然后这个值通过 embedding 计算,从词表中得到概率最大的词作为下一个预测词。上述就是推理的基本过程。
接下来我会分别介绍预处理、后处理以及最复杂的 Transformer 本身。

2.3 预处理
预处理过程其实就是大模型将用户的输入,比如中文、英文的相关内容,通过 Tokenizer 转换为对应的数字 ID。但这个 ID 能表达的信息很有限,我们要把它转为后续可以用到的隐空间表示。实际上,隐空间就是我们刚才提到的 [B, S, H] 的向量。那通过什么样的操作可以得到这样的向量呢?
举个例子,比如现在用户输入了一个句子,经过 Tokenizer 过程之后,会生成代表索引的 ID。这个 ID 其实就是这个词在词表范围内的索引位置,比如下面的例子中,some 这个词被转化为 121,即 121 就是 some 在词表中的索引位置。以此类推,我们就会得到一个 [B, S] 的矩阵。
然后我们会根据这些索引去查一个 [V, H] 的矩阵,也就是我们上述提到的词表WE。这个矩阵就是我们的模型经过训练后学习到的参数,其中 V 是词表的大小,H 是每一个单词学到的特征。这样把 [B, S] 矩阵中的数值作为索引 ID,我们就可以找到所有对应行的特征 H。例如如果 [B, S] 中的一个 id 是 121,那就会去 [V, H] 矩阵中查到第 122 行(假设 id 从 0 开始)的一个 [H] 向量,这个动作重复 B*S 次,最终得到一个 [B, S, H] 的张量。
从计算量的角度看,这是一个查表操作,也是纯访存的操作,因此计算量可以忽略不计。
以上就是预处理的过程。

2.4 后处理
当大模型拿到了这个 [B, S, H] 的矩阵之后,我们接下来希望计算出 [B, S, H] 矩阵中每一个词的概率,从而得到最后的输出。这里主要分为两个步骤:
- 通过转置词表 WE 得到 [H, V] 的矩阵,然后再和 [B, S, H] 进行计算得到一个 [B, S, V] 的张量
- 对得到的 [B, S, V] 的矩阵中的 V 这个维度进行 softmax 操作,得出对应词的概率。
通过上述的方式,我们就可以选择概率最大的索引位置,通过这个索引我就可以知道对应的 Token ID 以及该 Token ID 所对应的文本。
从计算量的角度看,根据上述讨论我们也可以计算出为 2*B*S*H*V。
以上就是后处理的过程。
2.5 多层 Decoder 处理
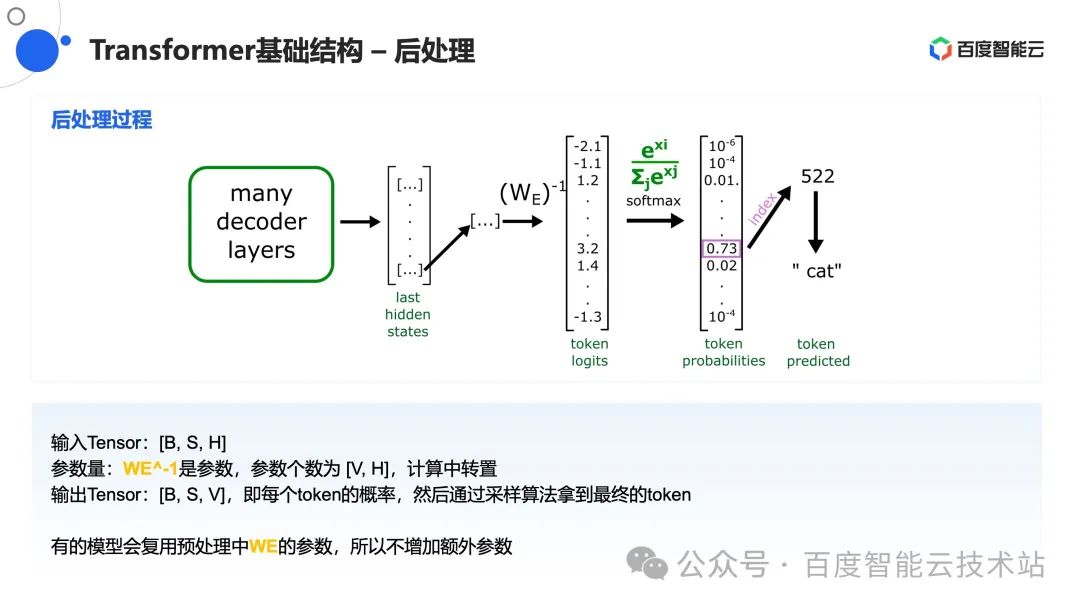
在之前的两个步骤中,我们讨论了文本转换为 Token,再通过 Token 转化为隐藏空间,并在 Transformer 中做了一系列「魔法」操作后,拿到了转换之后的 [B, S, H] 张量,再经过后处理计算又拿到了概率最大的 Token 值。那么在该部分,我们讨论下 Transformer 中的「魔法」操作。
Transformer 采用了多个 Decoder 层堆叠的架构。这些 Decoder 层的结构相同,实际参数不同。对于每个 Decoder 层来说,主要分为两部分操作:Self Attention 和 Feed Forward Neural Network。虽然对于多模态模型来说,还有 Cross Attention 操作,但本次分享我们聚焦于前两部分内容。
2.6 单头 Attention 和多头 Attention
首先是 Attention 部分。从数学视角看,Attention 其实是有明确定义的,如公式所示:
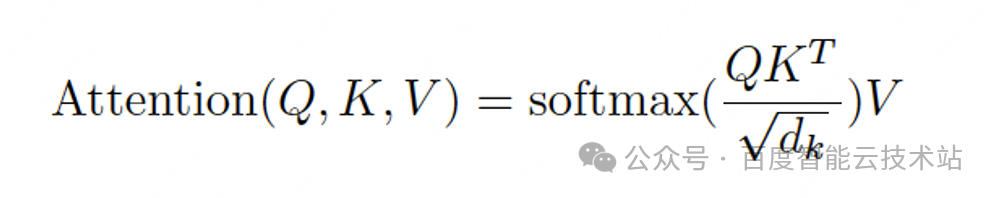
因此,我们需要先将输入张量 [B, S, H] 进行简单的扩展,获取到对应的 Q、K、V 参数,然后再进行后续的 Attention 计算,具体过程主要分为三个步骤:
- 对于输入的 [B, S, H] 张量,我们通过 MatMul 操作先乘上一个 [H, 3H] 矩阵,这样我们就获取到了一个 [B, S, 3H] 的张量。
- 对 [B, S, 3H] 切分为 Q、K、V 三份,此时对于 Q、K、V 来说均为 [B, S, H] 的张量,然后进行 Attention 计算 。其中,在多头 Attention 情况下,我们还会进行形变操作将其转化为 [B, h, S, d] 用于后续的计算,这个我们在后续进行详细介绍。
- 最终,我们再通过一次 MatMul 操作乘上一个 [H, H] 的矩阵,得到 Attention 部分的结果,并传给后续结构进行继续计算。
从计算量的视角看,两个 MatMul 操作我们分别进行了 2*B*S*H*3H 和 2*B*S*H*H 总计 8*B*S*H*H 次计算。接下来让我们继续深入到 Attention Block 部分,讨论该过程的细节和相关的计算量。
当我们获取到 Q、K、V 三个张量后,在推理过程中 K 和 V 对应的 S 可能会因为当前输入和历史处理过的文本长度产生变化,因此这里,张量 Q 我们用 [B, S, d ]表示,K 和 V 用 [B, S', d] 来表示。
备注:d 表示单头的 hidden_size。在单头注意力情况下,Q、K、V 中的 d 等于前述处理中的 H,在多头注意力情况下,可理解为将单头注意力复制为 h 份,那么则需要满足 d*h =H。
由 Attention 公式可知,在实际计算过程中分为如下三步:
- Q 先和 K 的转置进行计算,即 [B, S, d]@[B, d, S'] 得到张量 [B, S, S'](用 O 表示)。
- 对张量 O 进行 softmax 操作得到一个新的 [B, S, S'] ,用 O' 表示。
- 将 O' 和 V 进行计算,即 [B, S, S']@[B, S', d] 得到最终的 Attention 结果 [B, S, d]。
上述过程就是单头注意力情况下的 Attention 计算过程,整体计算量就是两个矩阵的乘法,即 2*B*S*d*S' + 2*B*S*S'*d。
接下来我们再讨论多头注意力的场景。
我们可以将多头注意力可理解为单头注意力复制为 h 份,那么则需要满足 d*h =H,此时,张量 Q 我们用 [B, h, S, d] 表示,张量 K、V 用 [B, h, S’, d] 表示。
相比于单头注意力场景,实际计算过程中依然分为三步:
- Q 先和 K 的转置进行计算,即 [B, h, S, d]@[B, h, d, S'] 得到张量 [B, h, S, S'](用 O 表示)。
- 对张量 O 进行 softmax 操作得到一个新的 [B, h, S, S'] ,用 O' 表示。
- 将 O' 和 V 进行计算,即 [B, h, S, S']@[B, h, S', d] 得到最终的 Attention 结果 [B, h, S, d]。
上述过程就是多头注意力 Attention 计算过程,整体计算量依然是两个矩阵的乘法,即 2*B*S*S'*h*d + 2*B*S*S'*h*d。
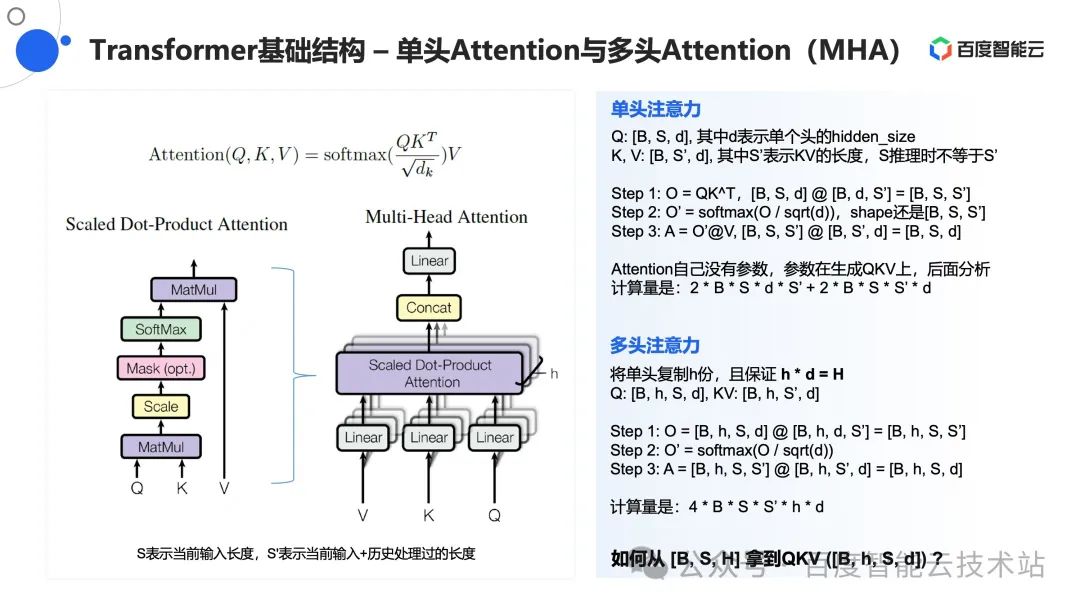
2.7 Attention 结构的参数量和计算量
现在,我们整体分析一下 Attention 结构带来的参数量和计算量。从工程视角看,它其实就是两个矩阵乘法加一个 Attention 操作,而 Attention 中主要的计算还是两个矩阵乘法。从参数的角度看,总计就是 4*H*H 个参数,从计算量角度看,总的计算量就是 8*B*S*H*H + 4*B*S*S'*H。
以上就是从工程视角对 Attention 的拆解。

2.8 FFN(MLP)结构的参数量和计算量
Feed Forward Neural Network(简称 FFN)是一个典型的标准多层网络机结构,因此大家一般也叫它 MLP。从数学的角度看,它本质上就是两个矩阵乘法加上一个激活函数,如下图所示。具体步骤分为三步:
- 将 Attention 结构中的输出结果 [B, S, H] 先做一次矩阵乘法,这里引入的矩阵为 [H, 4H],这样就得到了一个 [B, S, 4H] 的张量。
- 然后针对该 [B, S, 4H] 张量会做一次 ReLU 激活函数操作,对每个元素进行一次 max(x, 0) 计算,并得到一个新的 [B, S, 4H] 张量。
- 最终,我们再通过一次 MatMul 操作乘上一个 [H, H] 的矩阵,得到 FFN 部分的输出结果 [B, S, H] 并传递给下一层继续计算。
从参数量和计算量的视角看,FFN 的两次矩阵乘法和一次激活函数,带来了总计 8*H*H 的参数量,以及两次矩阵计算 2*B*S*H*4H + 2*B*S*H*4H 总计 16*B*S*H*H 次计算。

2.9 单层 Transformer 结构汇总
从工程视角看,忽略 rmsnorm、position embedding 等环节,Transformer 架构本质上就是多次的矩阵乘法:它的输入是一个 [B, S, H] 的张量,经过每个 Decoder 中一系列矩阵乘法后(比如 QKV 阶段的与矩阵 [H, 3H] 的乘法,Attention 阶段与转置矩阵的乘法、以及 FFN 过程中的两个矩阵乘法),再经过多次 Decoder 的重复操作,就得到了最终的结果。

2.10 参数量分析
接下来,我们对 Transformer 架构的模型进行一些定量分析,包括参数量、推理计算量、推理显存量、训练计算量、训练显存量、性能评估指标 MFU 等。
当模型训练完毕后,模型整体的参数就是固定的,这里介绍一种标准化的计算方式来进行评估(下方例子中采用 BLOOM 7B 模型为例)。
首先,对于单层 Transformer 来说,它包括 Attention 和 MLP 这两个结构,参数的符号化表示分别为 4*H*H 和 8*H*H,总计 12*H*H。
其次,结构中还存在一个词表(Word Embedding),BLOOM 模型中所使用的是一套可复用的词表,因此对应的参数符号化表示为 V*H。
因此,对于 BLOOM 模型来说,它的总参数量(后续用 N 来表示)的公式化表达为 N = L*12*H*H + V*H(L 是 Transformer 模型的层数)。
如果我们知道其中 L、H 以及 V 的值,那么就可以计算出这个大模型实际的参数量。实际上,在 HuggingFace 社区中,很多大模型都会提供对应的配置文件,告诉我们不同参数的具体值。比如下图中的配置文件,这里的 headsize 就是我们刚刚反复提到的 H,n_head 就是 h,n_layer 就是 L,vocab_size 就是 V。我们将具体数值带入,就可以计算出该 BLOOM 模型的参数。
如下图所示,我们计算出的结果参数和 7B 相差无几,中间的误差是因为我们在整个过程中忽略了 bias 这样一些不太重要的元素。大家未来看到不同的模型后,也可以根据上述的公式进行简单的计算和评估。

2.11 推理计算量分析
对于推理部分的计算量,我们也介绍一种标准化的方式来进行评估(同样采用 BLOOM 7B 模型为例)。
对于单层 Transformer 来说,推理过程主要的计算包括中间过程的矩阵乘法以及 Attention 、MLP 这两个结构,参数的符号化表示分别为2*B*S*4*H*H、 4*B*S*H*S' 、 2*B*S*8*H*H。考虑到 L 层计算,因此推理的总计算量为 L* 单层 Transformer = L*(2*B*S*4*H*H + 4*B*S*H*S' + 2*B*S*8*H*H)= B*S*[(2*N) + 4*L*H*S']。
而当序列比较小的时候,S' 远小于 H,此时计算量可以近似计算为 2*B*S*N。当 B = 1 且 S = 1 时,我们可以近似认为单 Token 的计算量为 2N。

2.12 推理显存量分析
除了参数量和显存量之外,还有一个关键的信息就是显存量。推理的显存由以下几部分组成:
- 模型参数的显存占用:比如当前的模型有 N 个参数,每个参数都需要进行存储,总的显存占用就是 N*sizeof(dtype),以 70B 的模型来说,如果用 fp16 的数据类型来存储(每个 fp16 约占据 2 个字节),对应的显存就是 2N,即 140GB。
- KV Cache:KV Cache 总的显存占用为 L*S'*h*d*2*sizeof(dtype),其中 S'*h*d 代表 K / V,2 代表 K 和 V 需要分别存储,L 代表 Transformer 的层数。
- 中间激活值:在计算过程中,也涉及到对中间状态的存储,因此也涉及到中间激活值。公式表示为 B*S*H*c,其中 c 是中间变量的个数,如果我们去仔细数其中每个操作,可以得到需要保存的中间变量的个数,但是本次分享为了简单考虑,忽略这个细节,用常量 c 表示。
经过上述分析,我们可以发现两个现象:一是参数量和请求长度无关,二是 KV 缓存值和序列的长度成正比。如下图所示,下图中蓝色代表模型参数占用的显存量,橙色代表 KV Cache 占用的显存量。
当缓存一条长度为 4000 Token 的请求时,模型参数消耗了大部分的显存。而当序列变长或者请求变多的时候,由于参数量和请求长度无关,蓝色区域的绝对值是不会发生变化的,KV Cache 则会随着序列长度的增加而线性增长。如下图所示,当缓存 100 条长度为 4000 Tokens 的请求时,KV Cache 的显存使用量就会远高于模型参数的显存量。通过这样的分析,我们也可以探索更多的优化方法。

2.13 从推理到训练
在忽略一些细节的情况下,我们可以看到,训练的过程包括数据的输入、前向计算、反向计算、梯度同步、参数更新这几个过程。推理过程其实和前向计算过程基本一致,因此训练的核心变化在于引入了反向计算、梯度同步和参数更新这三个过程。
从工程上来看,反向计算主要带来了一些额外的计算量和显存的需求,而梯度同步和参数更新(包括优化器的使用)则额外增加了一些显存的需求。下面我们来定量分析不同过程中计算和显存的变化。

2.14 训练计算量分析
对于矩阵的乘法来说,反向计算的过程大概是前向计算的两倍。我们可以看下下方左边的图,对于前向过程来说,只需要根据 X 和 W 的矩阵计算得到 Y 即可。但是在反向的过程中,则需要分别计算 X 和 W 的梯度。因此从训练的视角看,前向 + 反向的总计算量是推理的三倍。
在刚刚推理阶段我们计算出,在序列较短时推理的计算量约为 2N。因此在训练过程中,对应的计算量近似为 2N*3,即 6N。

2.15 训练显存量分析
接下来我们分析下训练过程消耗的显存量。
首先是优化器。这里我们以 Adam 优化器为例。训练过程中,优化器会带来大量的显存需求,我们需要保存权重和梯度,以及相关的优化器状态。同时为了保证训练的精度,我们可能会使用 fp16 和 fp32 各存一份。这样加起来总共大概有 20 个字节。而推理在这个过程中只需要 2 个字节,因此使用优化器对于每一个参数来说显存会有 10 倍的增加。
其次是中间状态存储。虽然训练过程相较于推理不需要 KV Cache,但是需要保留一些额外的激活值。比如下方的论文(https://arxiv.org/pdf/2205.05198)经过计算,总体来说会需要再乘一个和 Attention 相关的值再加上 34。如果感兴趣的同学可以看具体的论文,我们就不展开讲解了。

2.16 性能评估指标 MFU
在上面的介绍中,我们对训练、推理环节中的性能、计算量以及显存使用进行了拆解和讨论。当全部讨论完后,我们就会关心一个更重要的问题:该如何评估 Transformer 模型在实际的训练和推理过程中对算力的使用情况。
针对这个问题,业界有一个比较通用的性能指标 MFU。这个指标其实就是模型在实际生产过程中可以达到的实际吞吐量和理论计算到的理论值的比值,可以帮助我们评估当前模型对 GPU 算力的利用率。
实际吞吐量我们可以通过日志或者监控系统采集到,理论吞吐量我们可以使用目前系统的理论总算力和单 Token 在推理/训练过程中的理论计算量相除来得到。
我们以推理为例,刚刚我们分析了在推理过程中,单 Token 的计算量在序列较短时为 2N。如果我们有 M 张 GPU 卡,每张卡的算力为 312 TFLOPS,那么 312*M/2N 就是理论上 GPU 100% 发挥情况下,推理的总吞吐量。
但我们在第一章也讨论过,对 GPU 来说想把 312 TFLPOS 的算力完全发挥出来比较困难。所以对 MFU 来说,它的极限可能不是 100%,比如对 A800 来说,它的 MFU 极限就在 80% 左右。

2.17 从架构角度看并行策略的影响
在 GPU 加速的并行策略中,我们耳熟能详的如流水线并行、张量并行、数据并行等,接下来我将从公式的角度,来为大家解读不同的并行策略所影响的范围。
还是上述 Transformer 的输入 [B, S, H] 张量,B 其实就是我们的 batch,即样本。如果我们将 B 打散为 n 份,每一份大小是 B/n,这个打散过程其实就是数据并行的过程。S 代表序列长度,如果我们将 S 打散为 n 份,这个过程其实就是序列并行。
在 Transformer 中,我们重复经过 L 层进行了计算,如果我们将 L 层一分为二或者一分为四,这个过程其实就是流水并行。
此外,我们在层内还有一些大矩阵,比如上文中提到的[4H, H],我们将 4H 进行切分,那这个过程其实就是张量并行。
通过上述的分析,我们帮助大家对并行策略有了一个更理论化的理解,大家也可以在自己的日常实践中尝试以类似的视角来对并行策略有更深的理解。

3 Transformer 架构变种简介
上面我们介绍了原始版本的 Transformer 架构设计,接下来我们来讨论 Transformer 的几个变种,为大家简单分析下不同的变种分别在哪一层对进行了调整,每一次的调整改变了哪些维度,并评估下改变的量级。通过这样的方式,也帮助大家在后续分析 Transformer 的一些新论文或者新结构的时候自行进行分析。
3.1 Attention 优化
在原始的多头 Attention 结构中,对于每一个输入而言都有 h 个头。对于 L 层结构来说,单 Token 的显存占用为 L*h*d,这浪费了大量的显存空间。后来 Noam Shazeer 提出了一种改造,将原来的 h 份缩减到了 1 份,即 Multi-Query Attention(MQA) 结构。从工程上来说,这大大减少了 K&V 对显存的使用量。这种改造简单粗暴,对最终的效果也有一定影响。后来又提出了 Grouped-Query Attention(GQA)结构,将 MQA 中的 1 份变成可配置的 g 份(其中 g<h)。通过这样的方式,在减少显存使用的同时,相对 MQA 也提升了模型的效果。如下图中的例子,原始 MHA 的 h 为 32,GQA 中的 h 为 4,这样单层 KV Cache 节省了 32/4 =8 倍左右。

除了上述变种外,目前针对长序列,业内提出了 SlidingWindowAttention。这个方法核心就是对于一个 N*N 的矩阵而言,不需要再计算完整的矩阵,只需要将其捕捉到一个窗口的大小(比如将 S' 直接截取到 S_max)。这种方法比较适合长序列的场景,不会因为输入序列的无限长而导致大量的计算。
从公式的视角看,我们的计算量也从最开始的 4*B*S*S' 变成了 4*B*S*S_max,显存量也从 L*S'*H 减少到 L*S_max*H,计算量和显存量均降低了 S'/S_Max 倍。

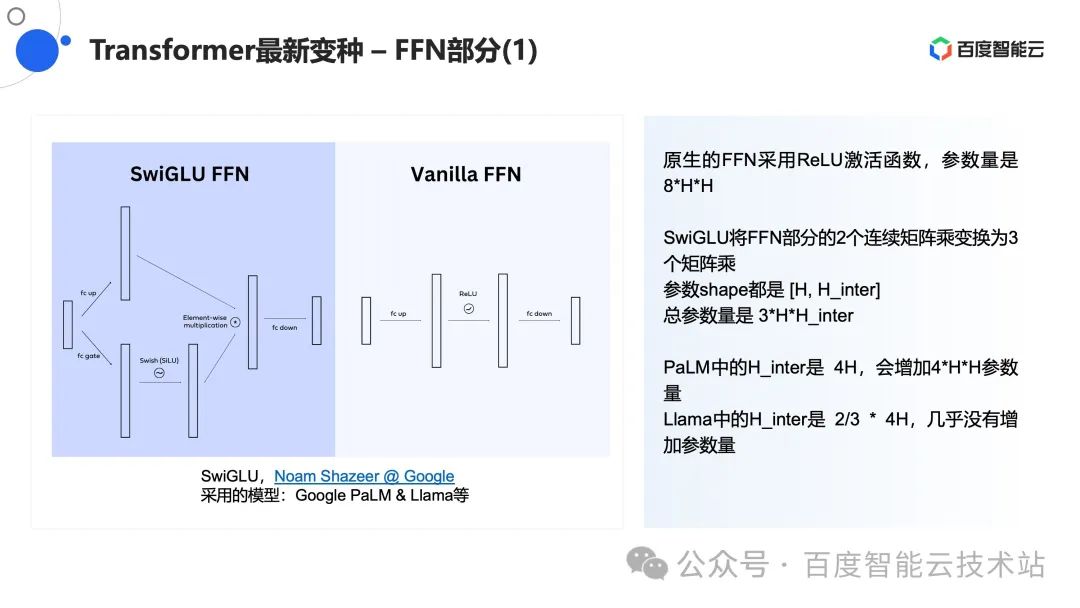
3.2 FFN 优化
针对 FFN 部分,其实大家也做了很多优化尝试,比如 Noam Shazeer 提出了一个变种:SwiGLU,重点优化了激活函数部分。
在原始的版本中,输入的 [B, S, H] 张量先做了一个 up 的矩阵乘法,然后进行 ReLU 计算,再做一个 down 的矩阵乘法。
而在 SwiGLU 中,除了做 up 乘法之外,还同时做了一个 gate 操作,然后再进行一次激活函数计算,最后结合两个矩阵做一个矩阵加法,最后再进行一次 down 的矩阵乘法。
如果站在定量分析的角度看,其实就是将原来的 FFN 中两个矩阵乘法变成了三个矩阵乘法,假设每个矩阵乘法的参数还保持原来的 [H, 4H],则参数量会增加4H*H,也就是增加 1/3。
在不同的论文中,大家会去优化 H_inter 的大小,比如 PaLM 模型中的 H_inter 为 4H,这反而会增加 4*H*H 参数量。而 Llama 中的 H_inter 为 2/3*4H,在没有增加参数量的情况下,改了一个新的激活函数。
对于 FFN 的优化其实还有其他方法,例如比较火的 MoE。从图中我们可以看出,这里将 FFN 切为 N 份,然后在 FFN 层新增了一个路由模型。这样就可以选择一个专家,然后做一份计算就可以了。通过这样的方式,我们就把 FFN 需要计算的参数量降低为 1/n,就可以在计算量不变的情况下增加我们的参数量,或者在参数量不变的情况下减少实际的计算量。

4 练习题
4.1 问题 1
Q: Llama 3 技术博客说 70B 模型、最长序列 8K、15T Tokens,训练了 640w GPU 时,这发挥了 H100 理论算力(989TFlops)的百分之多少?
A:我们可以使用 MFU 公式进行计算。
我们先计算理论上总的计算量,15T 的 Tokens 训练总量为 B*S* (6*N + 12*L*H*S) = 15*10^12 * (6*70*10^9 + 12*80*8192*8192) = 7.27 * 10^24 FLOPS。
接下来我们计算下如果发挥了全部的算力,即 989 TFLOPS, 所需要的时间为 7.27 * 10^24 / (989 * 10^12) = 204.2w GPU 时。而实际训练花费了 640w GPU 时,因此发挥了理论算力的 204.2w / 640w = 31.9%
4.2 问题 2
Q:Llama 2 7B 模型,这个 7B 是怎么算出来的? 这个模型训练和推理一个 Token 分别需要多少计算量?
A:首先是参数量的计算。根据我们之前推导的公式可知,Transformer 的总参数量 N = L * (Attention 参数量 + MLP 参数量) + word embedding * 2。
这里 word embedding 之所以会乘以 2,是因为 Llama 模型中并没有共享词表,它的配置项中的 tie_word_embedding 为 false。当然,这并不意味着所有的模型都有这个参数,具体的问题还是要具体分析。然后我们将具体的参数带入可以计算出:
总参数量 N = L * (4H*H + 3*H*H_inter) +2*V*H = 32 * (4 * 4096 * 4096 + 3 * 4096 * 11008) + 2 * 32000 * 4096 = 6738149376 ,约为 7B。
我们需要注意的是,在计算 FFN 的时候,参数量为 3*H*H_inter,这里的 H_inter 就是参数表中的 intermediate_size,即 11008。当然这里我们也忽略了一些其他的参数,这里的计算仅供参考。
其次是训练和推理的计算量,我们这里忽略 Attention,那么推理的计算量约为 2N,即 14 TFLOPS,训练的计算量约为 6N,即 42 TFLOPS。
4.3 问题 3
Q:Llama 2 70B 模型,使用 8 卡 A800 推理,16 个请求输入都是 4000 Tokens,要求首 Token 时延在 600-700ms 左右。这个需求合理么?
A:该问题其实我们在日常的沟通中也会经常遇到,我们也可以使用 MFU 的公式来进行分析。
在忽略 Attention 的情况下,16 个请求输入都是 4000 Tokens,那么计算的理论总计算量为 B*S*2*N = 16*4000*2*70*10^9 = 8.96*10^15。
对于 8 卡的 A800,其理论算力总和为:8*312*10^12 = 2.49*10^15。即使跑满 8 卡,至少也需要 8.96*10^15 / 2.49*10^15 = 3.59 s 才能完成,因此要求的 600-700ms 是理论不可达的。
当然我们有一些优化手段可以降低这个计算量,本次分享暂不讨论。
当然,在类似的时延上的一些定量需求,大家可以使用 MFU 的公式先去粗略估计一下可行性。
4.4 问题 4
Q:准备用 2 张 A800 跑 Llama 2 70B 模型推理(fp16 精度),如果输入输出最大长度是 4000 Tokens,那系统最大能跑多大并发?
A:由于这里不涉及到性能,所以我们从显存的角度来进行分析。2 卡 A800 总显存为 160 GB,我们假设其中可用 GPU 显存为 95%,即 152GB。对于 Llama 2 70B 模型(fp16 精度)来说,其显存使用量为 N*sizeof(fp16) = 140GB,还剩余12GB。
假设按 4000 Tokens 来估计,单个请求需要的 KV cache 显存为 L*S*g*d*2*sizeof(fp16) = 80*4000*8*128*4 = 1.2 GB。
假设 12G 中的 10G 用来存放 KV cache,则最大同时处理的并发数量为 8 左右。

