
- 1Hive初始化报错:org.apache.hadoop.hive.metastore.HiveMetaException: Failed to load driver
- 2【HIVE数据倾斜常见解决办法】_hive数据倾斜解决办法
- 3Linux上的Redis客户端软件G-dis3_g-dis3 使用
- 4(1)监听QQ消息自动回复-QQ自动化(.Net)_uianimations监控qq
- 5【附源码】基于flask框架基于微信小程序点餐系统的设计与实现 (python+mysql+论文)_基于微信小程序的点餐小程序的设计与实现
- 6【MongoDB】万字长文,命令与代码一一对应SpringBoot整合MongoDB之MongoTemplate
- 73种策略让微服务测试的ROI最大化_实现roi最大
- 8自动化脚本如何有效防检测、防风控?_脚本防止无障碍检测
- 9《Unity3D高级编程之进阶主程》第三章 数据表(二) - 数据表的制作方式
- 10Hadoop学习笔记(1)——单机版搭建_hadoop2.8单机部署
Spark编程基础
赞
踩
目录
一,Spark设计与运行原理
1,Spark简介
Spark 是一种基于内存的快速、通用、可扩展的大数据分析计算引擎
特点:运行速度快、容易使用、通用性、运行模式多样
2,Spark与Hadoop对比
Hadoop存在的缺点:
表达能力有限 ,磁盘IO开销大 ,延迟高
Spark优点:
编程模型更灵活,迭代运算效率更高,任务调度机制更优
二,Spark运行架构
1,RDD设计与运行原理
创建RDD
方法1.parallelize()
parallelizeO方法有两个输人参数,说明如下:
(1)要转化的集合:必须是 Seq集合。Seq 表示序列,指的是一类具有一定长度的、可迭代访问的对象,其中每个数据元素均带有一个从0开始的、固定的索引。
(2)分区数。若不设分区数,则RDD 的分区数默认为该程序分配到的资源的 CPU核心数。
通过 parallelizeO方法用一个数组的数据创建RDD,并设置分区数为4,创建后查看该 RDD 的分区数
方法2.makeRDD()
makeRDD0方法有两种使用方式,第一种使用方式与 parallelize0方法一致;第二种方式是通过接收一个 Seq[(T,Seq[String])]参数类型创建 RDD。第二种方式生成的RDD中保存的是T的值,Seq[String]部分的数据会按照 Seqf(T,Seq[String])的顺序存放到各个分区中,一个 Seq[Stringl对应存放至一个分区,并为数据提供位置信息,通过preferredLocations0方法可以根据位置信息查看每一个分区的值。调用 makeRDD0时不可以直接指定 RDD 的分区个数,分区的个数与 Seq[String]参数的个数是保持一致的,使用 makeRDD0方法创建 RDD,并根据位置信息查看每一个分区的值
方法3.通过HDFS文件创建 RDD
这种方式较为简单和常用,直接通过 textFile()方法读取 HDFS文件的位置即可。
在HDFS 的/user/toot 目录下有一个文件test.txt,读取该文件创建一个 RDD
方法4.通过 Linux 本地文件创建 RDD
本地文件的读取也是通过 sc.textFile("路径")的方法实现的,在路径前面加上“file://”表示从Linux 本地文件系统读取。在 IntelliJIDEA 开发环境中可以直接读取本地文件;但在 spark-shell 中,要求在所有节点的相同位置保存该文件才可以读取它,例如,在Linux的/opt 目录下创建一个文件 test.txt,任意输入4行数据并保存,将 test.txt 文件远程传输至所有节点的/opt 目录下,才可以读取文件 test.txt。读取 test.txt 文件,并且统计文件的数据行数
2,RDD方法归纳
1.使用map()方法转换数据
2.使用 sortBy()方法进行排序 
3.使用flatMap()方法转换数据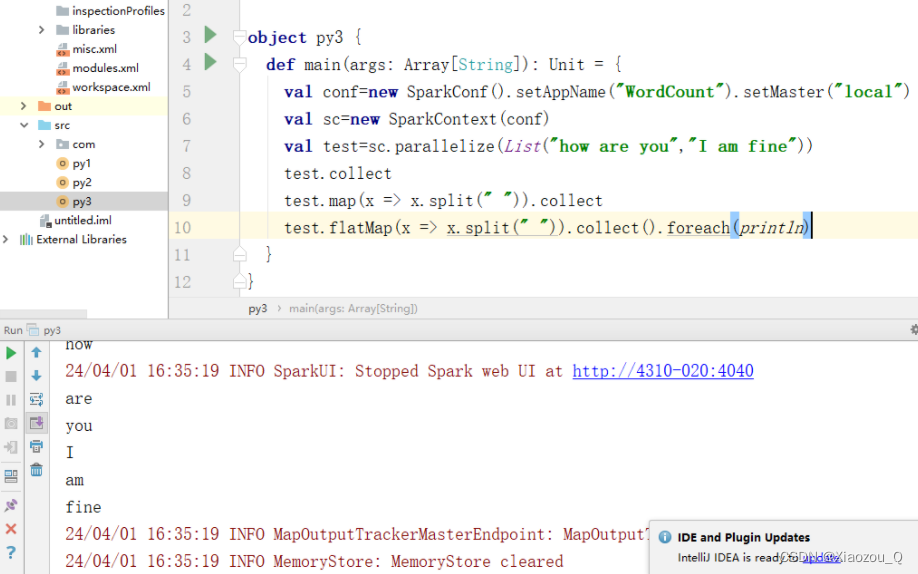
4.使用take()方法查询某几个值 
5.使用union()方法合并多个RDD
6.使用distinct()方法进行去重 
3, 使用简单的集合操作
(1)intersection()方法
(2)subtract()方法
(3)cartesian()方法 
任务实现:
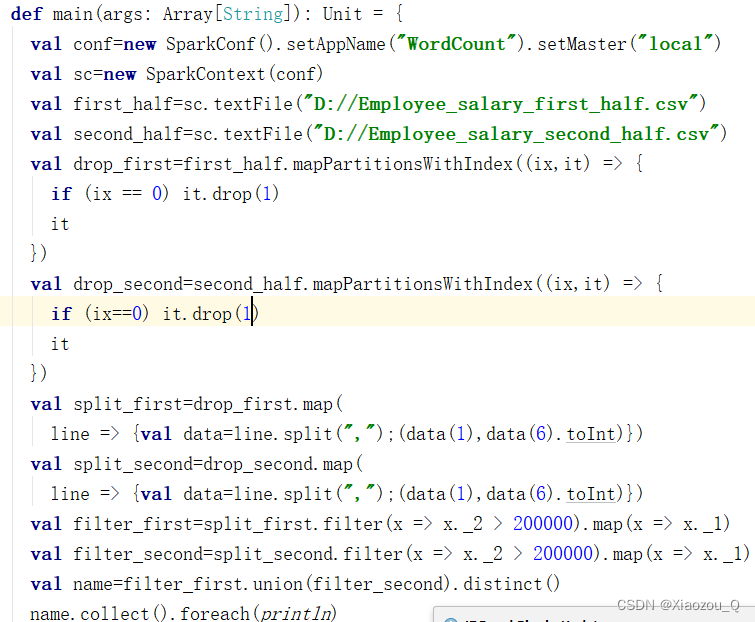
三,Spark快速上手
1,创建Maven项目
(1)增加Scala插件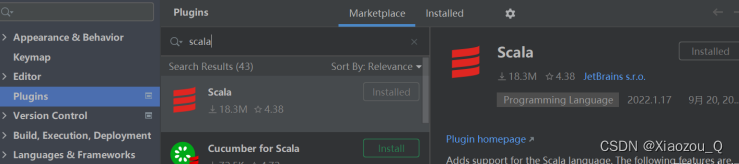
(2)增加依赖关系
修改Maven项目中的POM文件,增加Spark框架的依赖关系
- <dependencies>
-
- <!-- https://mvnrepository.com/artifact/org.apache.spark/spark-core -->
-
- <dependency>
-
- <groupId>org.apache.spark</groupId>
-
- <artifactId>spark-core_2.12</artifactId>
-
- <version>2.4.5</version>
-
- </dependency>
-
- </dependencies>
-
- <build>
-
- <plugins>
-
- <!-- 该插件用于将 Scala 代码编译成 class 文件 -->
-
- <plugin>
-
- <groupId>net.alchim31.maven</groupId>
-
- <artifactId>scala-maven-plugin</artifactId>
-
- <version>3.2.2</version>
-
- <executions>
-
- <execution>
-
- <!-- 声明绑定到 maven 的 compile 阶段 -->
-
- <goals>
-
- <goal>testCompile</goal>
-
- </goals>
-
- </execution>
-
- </executions>
-
- </plugin>
-
- <plugin>
-
- <groupId>org.apache.maven.plugins</groupId>
-
- <artifactId>maven-assembly-plugin</artifactId>
-
- <version>3.1.0</version>
-
- <configuration>
-
- <descriptorRefs>
-
- <descriptorRef>jar-with-dependencies</descriptorRef>
-
- </descriptorRefs>
-
- </configuration>
-
- <executions>
-
- <execution>
-
- <id>make-assembly</id>
-
- <phase>package</phase>
-
- <goals>
-
- <goal>single</goal>
-
- </goals>
-
- </execution>
-
- </executions>
-
- </plugin>
-
- </plugins>
-
- </build>

(3)WordCount
为了能直观地感受Spark框架的效果,接下来我们实现一个大数据学科中最常见的教学案例 WordCount
- /**
- * spark实现单词计数
- */
-
- object WordCountSpark {
-
- def main(args: Array[String]): Unit = {
-
- //创建spark运行配置对象
-
- val spark: SparkConf = new SparkConf()
-
- .setMaster("local[*]")
-
- .setAppName("WordCountSparkApps")
-
- //创建spark上下文对象
-
- val sc: SparkContext = new SparkContext(spark)
-
- //读文件数据
-
- val wordsRDD: RDD[String] = sc.textFile("data/word.txt")
-
- //讲文件中的数据进行分词
-
- val word: RDD[String] = wordsRDD.flatMap(_.split(","))
-
- //转换数据结构word ---->(word,1)
-
- val word2: RDD[(String, Int)] = word.map((_, 1))
-
- //将转换结构后的数据按照相同的单词进行分组聚合
-
- val word2CountRDD: RDD[(String, Int)] = word2.reduceByKey(_ + _)
-
- //将数据聚合结果采集到内存中
-
- val word2Count: Array[(String, Int)] = word2CountRDD.collect()
-
- //打印结果
-
- word2Count.foreach(println)
-
- //关闭spark连接
-
- sc.stop()
-
- }
-
- }
(4)异常处理
如果本机操作系统是Windows,在程序中使用了Hadoop相关的东西,比如写入文件到HDFS,则会遇到如下异常: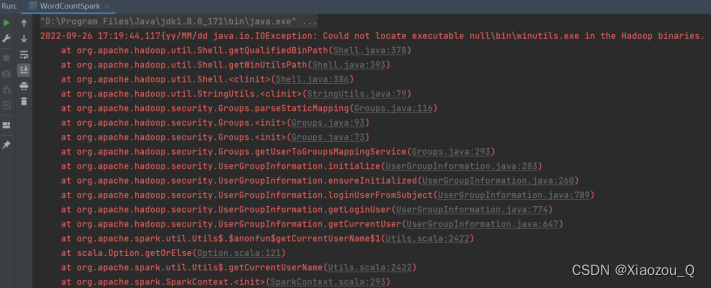
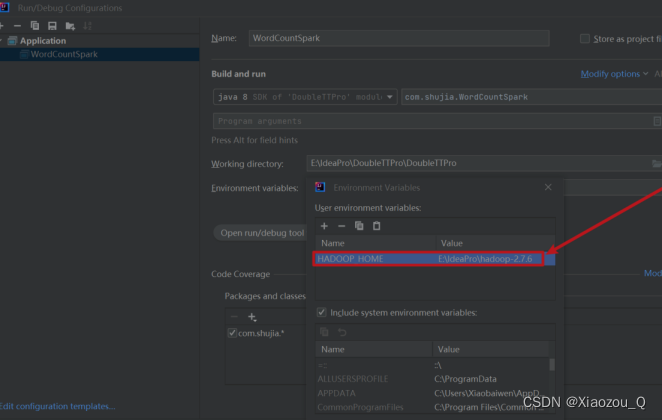
出现这个问题的原因,并不是程序的错误,而是windows系统用到了hadoop相关的服务,解决办法是通过配置关联到windows的系统依赖就可以了 
在IDEA中配置RunConfiguration,添加HADOOP_HOME变量或者在windows上配置环境变量:
四,Spark运行环境
1,Local模式
上传并解压缩文件
(1)上传文件至/usr/local/packages中
(2)解压缩到指定目录
[root@master local]# tar -zxvf spark-2.4.5-bin-hadoop2.6.tgz -C /usr/local/soft/
(3)重命名
[root@master soft]# mv spark-2.4.5-bin-hadoop2.6/ spark-local
启动local环境
(1)进入解压缩(spark-local)目录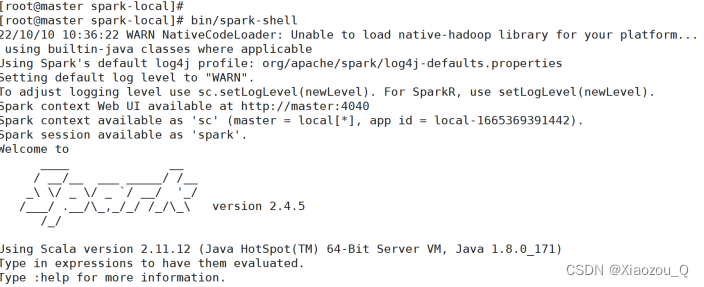
(2)启动成功后,可以输入网址进行Web UI监控页面访问 
命令行工具
sc.textFile("data/word.txt").flatMap(_.split(",")).map((_,1)).reduceByKey(_+_).collect
退出本地模式
scala> :quit
提交应用
bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master local[1] \
./examples/jars/spark-examples_2.11-2.4.5.jar \
10
五,Spark运行架构
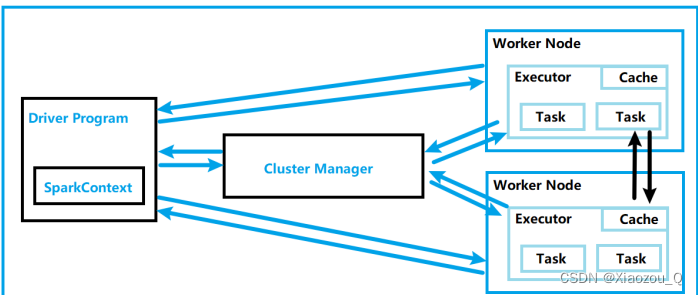
1,运行架构
Spark框架的核心是一个计算引擎,整体来说,它采用了标准master-slave的结构。如下图所示,它展示了一个 Spark 执行时的基本结构。图形中的Driver表示 master,负责管理整个集群中的作业任务调度。图形中的Executor则是 slave,负责实际执行任务。
2,核心概念
(1)Executor与Core


