
- 1解决Ubuntu虚拟机克隆后IP地址相同的问题_machine-id相同
- 2图-文多模态,大模型,预训练_多模态图文
- 3【FPGA入门】第二篇、ISE软件的使用
- 4鸿蒙所谓的软总线,套娃DLNA SOMEIP协议,QNX系统_分布式软总线
- 5如何在Linux下更新安装VMware Tools_linux vmware tool下载更新
- 6HarmonyOS应用开发者基础认证考试答案_ability系统调度应用的最小单元
- 73D机器视觉在新能源汽车动力电池行业的应用_动力电池检测相机需求数量
- 8Activity 的启动流程(Android 13)_activity启动流程
- 9Android-打包AAR步骤以及最为关键的注意事项
- 10前端媒体查询
TrOCR:基于Transformer的新一代光学字符识别_transfromer识别文字
赞
踩
很长一段时间以来,文本识别一直都是一个重要的关于文档数字化的研究课题。现有的文本识别方法通常采用 CNN 网络进行图像理解,采用 RNN 网络进行字符级别的文本生成。但是该方法需要额外附加语言模型来作为后处理步骤,以提高识别的准确率。
为此,微软亚洲研究院的研究员们展开了深入研究,提出了首个利用预训练模型的端到端基于 Transformer 的文本识别 OCR 模型:TrOCR。该模型简单有效,可以使用大规模合成数据进行预训练,并且能够在人工标注的数据上进行微调。实验证明,TrOCR 在打印数据和手写数据上均超过了当前最先进的模型。训练代码和模型现已开源。希望感兴趣的读者可以阅读全文,了解 TrOCR 的优势所在!
光学字符识别(OCR)是将手写或印刷文本的图像转换成机器编码的文本,可应用于扫描文档、照片或叠加在图像上的字幕文本。一般的光学字符识别包含两个部分:文本检测和文本识别。
-
文本检测用于在文本图像中定位文本块,粒度可以是单词级别或是文本行级别。目前的解决方案大多是将该任务视为物体检测问题,并采用了如 YoLOv5 和 DBNet 的传统物体检测模型。
-
文本识别致力于理解文本图像并将视觉信号转换为自然语言符号。该任务通常使用编码器-解码器架构,现有方法采用了基于 CNN 网络的编码器进行图像理解,以及基于 RNN 网络的解码器进行文本生成。
在文本识别领域中,Transformer 模型被频繁采用,其结构的优势带来了显著的效率提升。然而,现有方法仍主要采用 CNN 网络作为主干网络,并在此基础上配合自注意力机制来理解文本图像;另外,现有方法还依旧采用 CTC 作为解码器,配合额外的字符级别的语言模型来提高整体的准确率。这种混合模型虽然取得了巨大的成功,但仍然有很大的提升空间:
1. 现有模型的参数是在合成或人工标注的数据上从零开始训练的,没有探索大规模预训练模型的应用。
2. 图像 Transformer 模型变得愈发流行,特别是最近提出的自监督图像预训练。现在应当开始探索预训练的图像 Transformer 是否可以替代 CNN 主干网络,以及预训练的图像 Transformer 是否可以在单一网络中配合预训练文本 Transformer 进行文本识别任务。
因此,微软亚洲研究院的研究员们聚焦文本识别任务展开了多项研究,并提出了首个利用预训练模型的端到端基于 Transformer 的文本识别 OCR 模型:TrOCR,模型结构如图1。
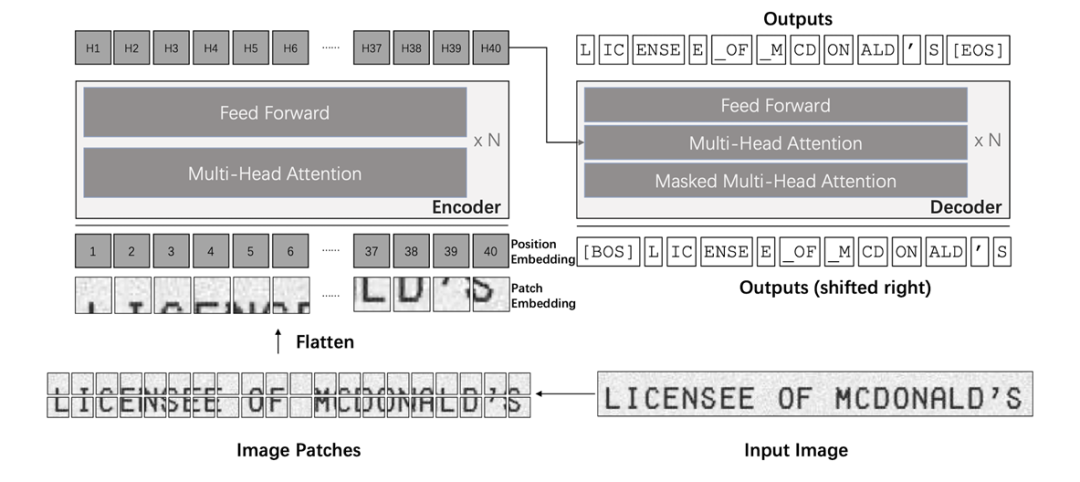
图1:TrOCR 模型结构示意图
与现有方法不同,TrOCR 简单、高效,没有将 CNN 作为主干网络,而是把输入的文本图像切分成图像切片,然后输入到图像 Transformer 中。TrOCR 的编码器和解码器则均使用了标准的 Transformer 结构以及自注意力机制,解码器生成 wordpiece 作为输入图像的识别文本。为了更有效的训练 TrOCR 模型,研究员们使用了 ViT 模式的预训练模型和BERT模式的预训练模型,来分别初始化编码器和解码器。

论文:https://arxiv.org/abs/2109.10282
代码/模型:https://aka.ms/trocr
TrOCR 的优势有三个方面:
1. TrOCR 使用预训练的图像和文本模型,利用大规模无标注数据的优势来进行图像理解和建模语言模型,不需要额外的语言模型介入。
2. TrOCR 不需要任何复杂的卷积网络来作为主干网络,更加易于实现和维护。实验证明,TrOCR 在打印体和手写体文本识别任务的基准数据集上均超越了当前最先进的方法,不需要任何复杂的预/后处理步骤。
3. TrOCR 可以很容易地扩展为多语言模型,只需要在解码器端使用多语种预训练模型即可。此外,通过简单调整预训练模型的参数量配置,使云/端部署变得极为简便。
实现方法
模型结构
TrOCR 采用了 Transformer 结构,包括图像 Transformer 和文本 Transformer,分别用于提取视觉特征和建模语言模型,并且采用了标准的 Transformer 编码器-解码器模式。编码器用于获取图像切片的特征;解码器用于生成 wordpiece 序列,同时关注编码器的输出和之前生成的 wordpiece。
对于编码器,TrOCR 采用了 ViT 模式的模型结构,即改变输入图像的尺寸,并切片成固定大小的正方形图像块,以形成模型的输入序列。模型保留预训练模型中的特殊标记“[CLS]”代表整张图片的特征,对于 DeiT 的预训练模型,同样保留了对应的蒸馏token,代表来自于教师模型的蒸馏知识。而对于解码器,则采用原始的 Transformer 解码器结构。
模型初始化
编码器和解码器均应用在经过大规模标注/无标注数据预训练过的公开模型上,从而进行初始化。编码器采用 DeiT 和 BEiT 模型进行初始化,而解码器采用 RoBERTa 模型进行初始化。由于 RoBERTa 的模型结构和标准的 Transformer 解码器不完全匹配,例如缺乏编码器-解码器注意力层,因此研究员们将随机初始化这些在 RoBERTa 模型中不存在的层。
任务流程
TrOCR 的文本识别任务过程是:给定待检测的文本行图像,模型提取其视觉特征,并且给予图像以及已经生成的上文来预测对应的 wordpiece。真实文本以“[EOS]”符号结尾,代表句子的结束。在训练过程中,研究员们向后旋转真实文本的 wordpiece 序列,并把“[EOS]”符号挪到首位,输入到解码器中,并使用交叉熵损失函数来监督解码器的输出。在推断时,解码器从“[EOS]”符号开始迭代预测之后的 wordpiece,并把预测出的 wordpiece 作为下一次的输入。
预训练
研究员们使用文本识别任务作为预训练任务,因为它可以使模型同时学习到视觉特征提取和语言模型两者的知识。预训练过程分为两个阶段:第一个阶段,研究员们合成了一个包含上亿张打印体文本行的图像以及对应文本标注的数据集,并在其上预训练 TrOCR 模型;第二个阶段,研究员们构建了两个相对较小的数据集,分别对应打印体文本识别任务和手写体文本识别任务,均包含上百万的文本行图像,并在打印体数据和手写体数据上预训练了两个独立的模型,且都由第一阶段的预训练模型初始化。
微调
研究员们在打印体文本识别任务和手写体文本识别任务上微调了预训练的 TrOCR 模型。模型的输出基于 BPE(字节对编码)并且不依赖于任何任务相关的词典。
数据增强
为了增加预训练数据和微调数据的变化,研究员们使用了数据增强技术,合计七种图像转换方法(包括保持原有输入图像不变)。对于每个样例,研究员们在随机旋转、高斯模糊、图像膨胀、图像腐蚀、下采样、添加下划线、保持原样中会机会均等地随机选取一个方法对图像进行变换。
预训练数据
为了构建一个大规模高质量的数据集,研究员们从互联网上公开的 PDF 文档中随机选取了两百万张文档页面。由于这些 PDF 是数字生成的,因此通过把 PDF 文档转换为页面图像,然后提取文本行和裁切图像就可以得到高质量的打印体文本行图像。第一阶段的预训练数据一共包含6亿8千万文本行数据。
对于预训练的第二阶段,研究员们使用5427个手写字体和 TRDG 开源文本识别数据生成工具,合成了大量的手写文本行图像,并随机从维基百科的页面中选取文本。该阶段预训练的手写数据集包含合成数据和 IIIT-HWS 数据集,共计1800万的文本行。此外,研究员们还收集了现实世界中的5万3千张收据照片,并通过商业 OCR 引擎识别了上面的文本,对照片进行了修正和裁剪。同样,研究员们也使用 TRDG 合成了100万打印体的文本行图像,并使用了两种收据字体和其内置的打印体字体。第二阶段预训练的打印体数据集包含330万的文本行。表1统计了合成数据的规模。
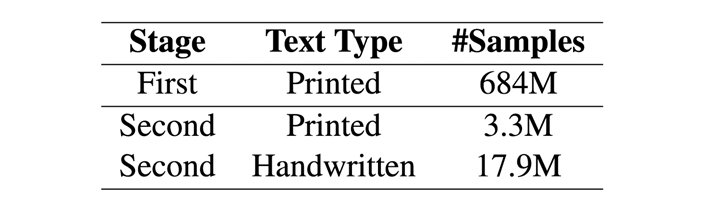
表1:两阶段预训练的合成数据规模
预训练结果
首先,研究员们比较了不同编码器和解码器的组合,来寻找最佳的模型设定。研究员们比较了 DeiT,BEiT 和 ResNet50 网络作为编码器的选项。在比较中,DeiT 和 BEiT 均使用了论文中 base 的模型设定。对于解码器而言,研究员们则比较使用了 RoBERTa-base 初始化的 base 解码器和使用 RoBERTa-large 初始化的 large 解码器。作为对照,研究员们对随机初始化的模型、CRNN 基线模型以及 Tesseract 开源 OCR 引擎也进行了实验。
表2给出了组合得到的模型结果。BEiT 编码器和 RoBERTa-large 解码器表现出了最好的结果。与此同时,结果表明预训练模型确实提高了文本识别模型的性能,纯 Transformer 模型的性能要优于 CRNN 模型和 Tesseract。根据这个结果,研究员们选取了后续实验的两个模型设定:TrOCR-base,包含 334M 个参数,由 BEiT-base 编码器和 RoBERTa-large 解码器组成;TrOCR-large,包含558M个参数,由 BEiT-large 编码器和 RoBERTa-large 解码器组成。
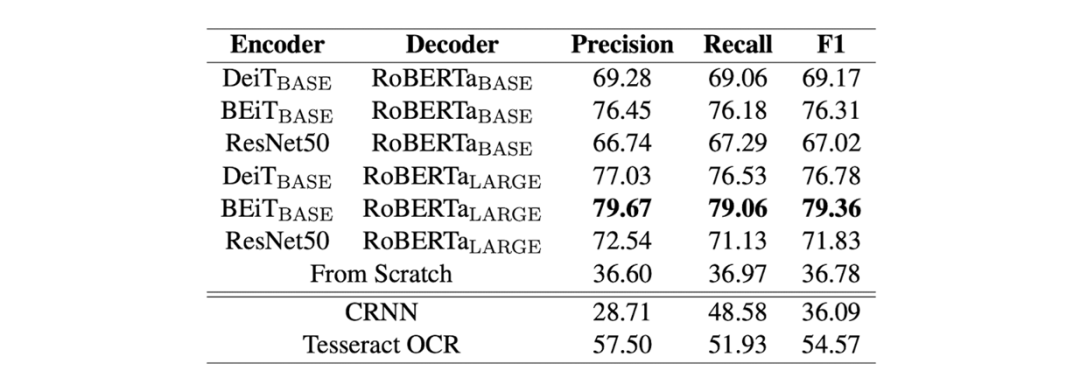
表2:在 SROIE 数据集上进行的消融实验结果
表3给出了 TrOCR 模型和 SROIE 数据集排行榜上当前最先进模型的结果。可以看出,TrOCR 模型凭借纯 Transformer 模型超过了当前最先进模型的性能,同时也证实了其不需要任何复杂的预/后处理步骤。基于 Transformer 的文本识别模型在视觉特征提取上可以与基于 CNN 的模型有近似性能,在语言模型上可与 RNN 相媲美。
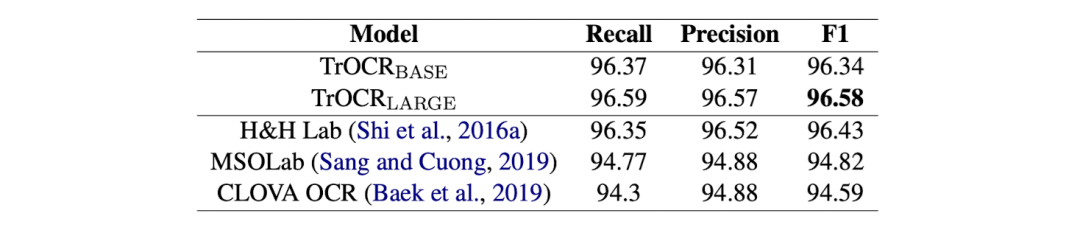
表3: 大规模预训练的 TrOCR 模型在 SROIE 印刷体数据集的实验结果
表4给出了 TrOCR 模型和 IAM 数据集上现有方法的结果。结果显示现有方法中 CTC 解码器和额外的语言模型可以带来显著的效果提升。通过与(Bluche and Messina, 2017)比较,TrOCR-large 有着更好的结果,这说明 Transformer 解码器相比于 CTC 解码器在文本识别任务中更具竞争力,同时已经具有足够的建模语言模型的能力,而不需要依赖于额外的语言模型。
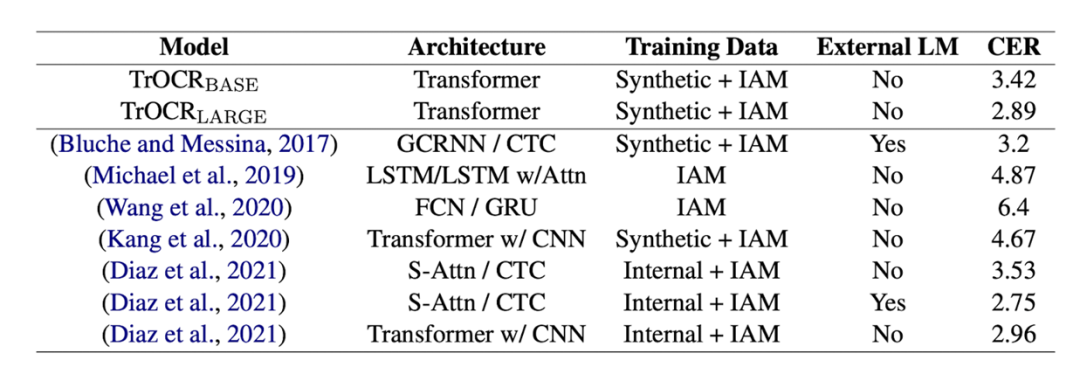
表4: 大规模预训练的 TrOCR 模型在 IAM 手写体数据集的实验结果
TrOCR 使用了来自于图像切片的信息,获得了与 CNN 网络相似甚至更好的结果,说明经过预训练的 Transformer 结构可以胜任提取视觉特征的任务。从结果来看TrOCR 模型使用纯 Transformer 结构超过了所有仅使用合成+IAM 数据的方法,同时在没有使用额外人工标注数据的情况下,取得了和使用人工标注数据的方法相近的结果。
总结
在本文中,研究员们提出了首个利用预训练模型的端到端基于 Transformer 的文本识别 OCR 模型:TrOCR。不同于现有方法,TrOCR 不依赖于传统的 CNN 模型进行图像理解,而是利用了图像 Transformer 作为视觉编码器,利用文本 Transformer 作为文本编码器。此外,与基于字符的方法不同,研究员们使用 wordpiece 作为识别输出的基本单元,节省了在额外的语言模型中额外的计算开销。实验证明,在没有任何后处理步骤,且仅使用一个简单的编码器-解码器模型的情况下,TrOCR 在打印文本和手写文本识别中均取得了目前最先进的准确率。

