
- 1Android APP全屏显示(去掉顶部状态栏和底部虚拟导航栏)以及使用AndroidAutoSize实现自适应_android 设置全屏无状态栏
- 2华为hicar支持车型列表_华为Hicar来了!与车企合作,RS3车主或将成首批体验用户...
- 3Android制作AAR包并混淆后加载调用_android aar混淆
- 4Transformer的前世今生 day11(Transformer的流程)
- 5python开源聊天机器人ChatterBot——聊天机器人搭建、流程分析、源码分析
- 6OpenHarmony图片转Base64编码开发流程
- 7动态存储分配 | malloc realloc calloc的使用_malloc和realloc的用法
- 8计算机毕业设计PHP基于微信小程序的教学效果测评系统(源码+程序+uni+lw+部署)_计算机毕业设计php教学质量评价系统小程序(源码+程序+uni+lw+部署)
- 9sh脚本报错“eval: line 1: syntax error: unterminated quoted string”
- 10C 语言程序设计——统计给定区间内素数的个数并求和_统计给定区间内的素数个数并求和(双重循环)
【好用的AI工具Kimi Chat】帮助提高面试效率_kimi ai如何帮助测试行业
赞
踩
一、背景
- 年前裁员潮,不少人离职找工作,以及年后金三银四,也是求职高峰期。
- 如何更高效的复习技术知识,以及特别是横纵向比对有总结性的问题。
- 本文以面试【测试开发】的岗位为例,对面试题进行拓展,让AI帮助我们更快速地提高复习效率。
二、使用AI工具 Kimi Chat来帮助我们做归纳和参考,提高复习效率
2.1 问题1:PO设计模式
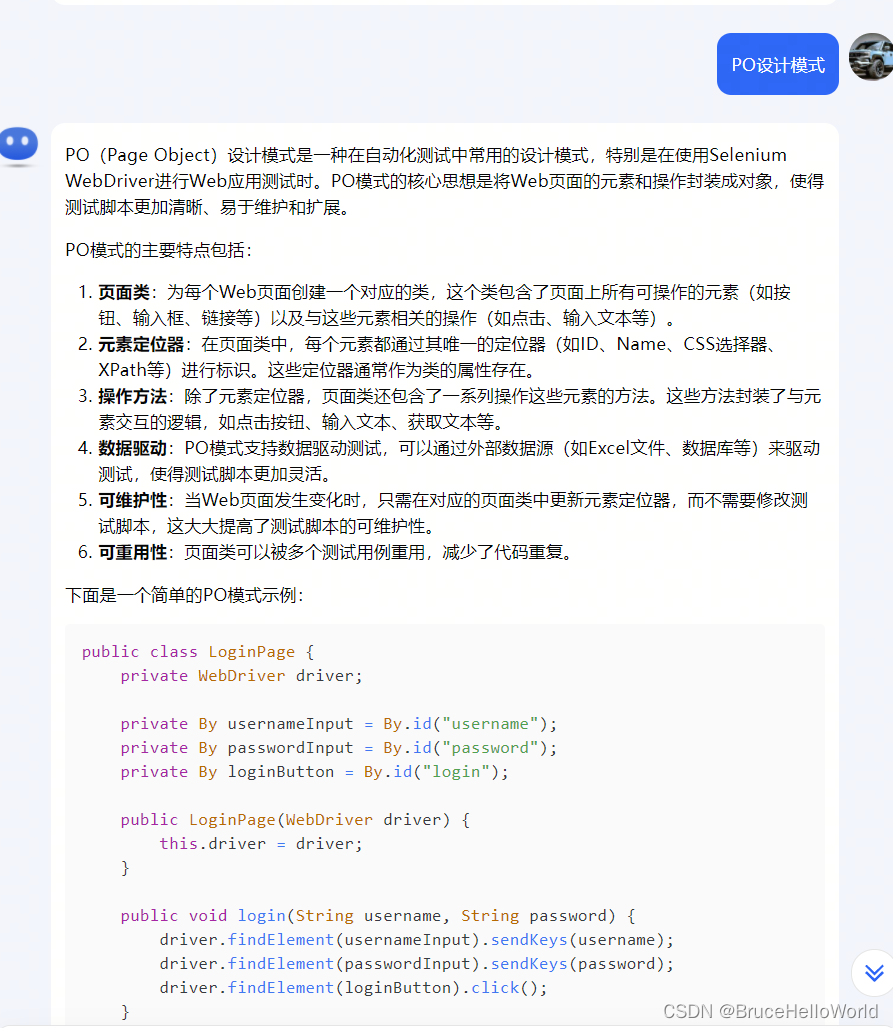
PO(Page Object)设计模式是一种在自动化测试中常用的设计模式,特别是在使用Selenium WebDriver进行Web应用测试时。PO模式的核心思想是将Web页面的元素和操作封装成对象,使得测试脚本更加清晰、易于维护和扩展。
PO模式的主要特点包括:
-
页面类:为每个Web页面创建一个对应的类,这个类包含了页面上所有可操作的元素(如按钮、输入框、链接等)以及与这些元素相关的操作(如点击、输入文本等)。
-
元素定位器:在页面类中,每个元素都通过其唯一的定位器(如ID、Name、CSS选择器、XPath等)进行标识。这些定位器通常作为类的属性存在。
-
操作方法:除了元素定位器,页面类还包含了一系列操作这些元素的方法。这些方法封装了与元素交互的逻辑,如点击按钮、输入文本、获取文本等。
-
数据驱动:PO模式支持数据驱动测试,可以通过外部数据源(如Excel文件、数据库等)来驱动测试,使得测试脚本更加灵活。
-
可维护性:当Web页面发生变化时,只需在对应的页面类中更新元素定位器,而不需要修改测试脚本,这大大提高了测试脚本的可维护性。
-
可重用性:页面类可以被多个测试用例重用,减少了代码重复。
下面是一个简单的PO模式示例:
- public class LoginPage {
- private WebDriver driver;
-
- private By usernameInput = By.id("username");
- private By passwordInput = By.id("password");
- private By loginButton = By.id("login");
-
- public LoginPage(WebDriver driver) {
- this.driver = driver;
- }
-
- public void login(String username, String password) {
- driver.findElement(usernameInput).sendKeys(username);
- driver.findElement(passwordInput).sendKeys(password);
- driver.findElement(loginButton).click();
- }
-
- // 其他操作方法...
- }

在这个例子中,LoginPage类代表了登录页面,包含了用户名和密码输入框以及登录按钮的定位器。login方法封装了登录操作的逻辑。
使用PO模式的好处是,当Web页面的布局或元素发生变化时,只需要更新页面类中的元素定位器,而测试脚本本身不需要做任何修改。这使得自动化测试更加健壮,减少了维护成本。
2.2 问题2 :自动化测试中明等待和暗等待的区别

在自动化测试中,等待机制是确保测试脚本能够正确执行的关键部分,尤其是在处理异步操作或动态加载内容时。Selenium WebDriver提供了两种主要的等待机制:显式等待(Explicit Wait)和隐式等待(Implicit Wait)。
- 正在尝试为您在互联网搜索相关资料...
- 开始获取资料...
- 找到了第 1 篇资料:[Selenium]11.定位方式优先级 - 知乎
- 找到了第 2 篇资料:selenium自动化测试:4.webdriver八种定位方式 - 知乎
- 找到了第 3 篇资料:Web自动化测试:webdriver所有定位方式详解 - 知乎
- 找到了第 4 篇资料:WebDriver--定位元素的8种方式 - 丶荧惑守芯 - 博客园
- 找到了第 5 篇资料:Selenium的八大定位方法与WebDriver API元素定位中的 ...
- 一共找到 5 篇资料,正在阅读...
- 找到了 5 篇资料作为参考:
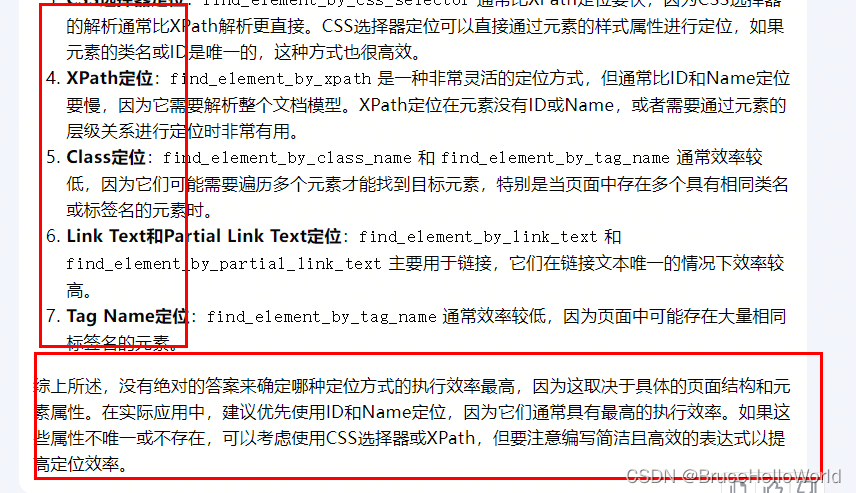
- 在Selenium WebDriver中,定位元素的效率通常受到多种因素的影响,包括元素的唯一性、页面结构的复杂性以及定位策略的复杂度。以下是几种常见的定位方式及其执行效率的一般评价:
-
- ID定位:find_element_by_id 是最直接且效率最高的定位方式。ID属性在HTML中是唯一的,因此使用ID定位可以快速准确地找到元素。如果元素有唯一的ID,这是首选的定位方式。
-
- Name定位:find_element_by_name 次之,虽然Name属性在某些情况下可能不是唯一的,但如果元素的Name属性是唯一的,它也是一个有效的定位方式。
-
- CSS选择器定位:find_element_by_css_selector 通常比XPath定位要快,因为CSS选择器的解析通常比XPath解析更直接。CSS选择器定位可以直接通过元素的样式属性进行定位,如果元素的类名或ID是唯一的,这种方式也很高效。
-
- XPath定位:find_element_by_xpath 是一种非常灵活的定位方式,但通常比ID和Name定位要慢,因为它需要解析整个文档模型。XPath定位在元素没有ID或Name,或者需要通过元素的层级关系进行定位时非常有用。
-
- Class定位:find_element_by_class_name 和 find_element_by_tag_name 通常效率较低,因为它们可能需要遍历多个元素才能找到目标元素,特别是当页面中存在多个具有相同类名或标签名的元素时。
-
- Link Text和Partial Link Text定位:find_element_by_link_text 和 find_element_by_partial_link_text 主要用于链接,它们在链接文本唯一的情况下效率较高。
-
- Tag Name定位:find_element_by_tag_name 通常效率较低,因为页面中可能存在大量相同标签名的元素。
-
- 综上所述,没有绝对的答案来确定哪种定位方式的执行效率最高,因为这取决于具体的页面结构和元素属性。在实际应用中,建议优先使用ID和Name定位,因为它们通常具有最高的执行效率。如果这些属性不唯一或不存在,可以考虑使用CSS选择器或XPath,但要注意编写简洁且高效的表达式以提高定位效率。
在实际应用中,显式等待通常被认为是更好的实践,因为它提供了更好的控制和可预测性。隐式等待应该谨慎使用,并且通常在测试脚本中只设置一次,以避免不必要的等待。
2.3 问题3:WebDriver中定位方式执行效率最高的是哪个

三、总结
3.1 优势
能依据输入的内容,快速地去分析相关的链接,然后给出答案,其中包含论点和论据,以及结论性总结,相对更加全面,省时省力。

3.2 劣势
需要针对行业和个人工作习惯进行训练,需要时间,如编写自动化脚本,需要依据语言和框架,以及个人的风格进行训练。
-
显式等待(Explicit Wait):
- 显式等待是在测试脚本中明确指定等待条件的机制。开发者需要设置一个等待时间,并定义一个期望条件(例如,元素可见、元素存在等)。
- 当条件满足时,等待立即结束,如果条件在指定时间内没有满足,会抛出一个异常。
- 显式等待通常使用
WebDriverWait类来实现,它提供了until方法来指定等待条件。
示例代码:
- driver.implicitly_wait(10) # 设置隐式等待时间为10秒
- element = driver.find_element_by_id("myElement") # 在查找元素时会自动等待10秒
区别:
- 作用范围:显式等待是局部的,只对特定的元素查找操作有效;隐式等待是全局的,影响整个WebDriver实例。
- 等待时机:显式等待是在元素查找操作时触发;隐式等待是在每次查找元素时自动触发。
- 灵活性:显式等待提供了更多的灵活性,可以针对不同的元素和条件设置不同的等待时间;隐式等待则对所有元素查找操作应用相同的等待时间。
- 代码复杂性:显式等待需要显式地设置等待条件,代码可能更复杂;隐式等待则简化了代码,但可能需要更频繁地调整等待时间。

