
- 1【HarmonyOS】鸿蒙开发之文件操作与网络请求-HTTP网络请求——第5.1章_harmonyos http code 0
- 2langchain新版本学习指南_langchain版本
- 3Vmware虚拟机安装MacOS13-Ventura详细教程_macos13镜像iso
- 4几款好用的内网穿透工具
- 5使用Syncthing搭建自己的私人网盘_syncthing远程穿透
- 6无人驾驶与人工驾驶的对比,人工驾驶的优缺点
- 7python摔倒检测,跌倒检测openpose站立行为检测_python pose库
- 8截取列表前面100行_python列表
- 9mysql:mysql的优势_mysql优势
- 10非华为电脑如何与matepad pro进行多屏协同,以及如何处理连接失败等问题_平板多屏协作提示修改显卡设置
深度学习——深度学习发展历程
赞
踩
1 基本概念
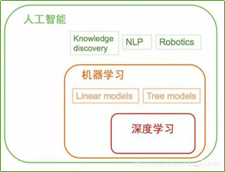
人工智能(Artificial Intelligence),英文缩写为AI。它是研究、开发用于模拟、延伸和扩展人的智能的理论、方法、技术及应用系统的一门新的技术科学,是计算机科学的一个分支。人工智能就是研究如何使计算机去做过去只有人才能做的智能工作。研究如何让计算机去完成以往需要人的智力才能胜任的工作,也就是研究如何应用计算机的软硬件来模拟人类某些智能行为的基本理论、方法和技术。该领域的研究包括语音识别、图像识别、机器人、自然语言处理、智能搜索和专家系统等。人工智能可以对人的意识、思维的信息过程的模拟。人工智能不是人的智能,但能像人那样思考、也有可能超过人的智能。
机器学习是一门多学科交叉专业,涵盖概率论知识,统计学知识,近似理论知识和复杂算法知识,使用计算机作为工具并致力于真实实时的模拟人类学习方式,并将现有内容进行知识结构划分来有效提高学习效率。是研究怎样使用计算机模拟或实现人类学习活动的科学,是人工智能中最具智能特征,最前沿的研究领域之一。
深度学习是机器学习的一种,而机器学习是实现人工智能的必经路径。深度学习的概念源于人工神经网络的研究,含多个隐藏层的多层感知器就是一种深度学习结构。深度学习通过组合低层特征形成更加抽象的高层表示属性类别或特征,以发现数据的分布式特征表示。研究深度学习的动机在于建立模拟人脑进行分析学习的神经网络,它模仿人脑的机制来解释数据,例如图像,声音和文本等。ANN本质上是一种运算模型, 由大量的神经元节点相互连接构成。每个节点可以当做是一个神经元, 节点中包含激励函数, 根据其输入判断其输出。深度学习本质上是一种新兴的机器学习算法, 其基本模型框架是基于ANN的, 如含有多隐层的感知器。深度学习概念由Hinton于2006年在《Science》上发表的论文《Deep Learning》提出。(刘俊一.基于人工神经网络的深度学习算法综述[J].中国新通信,2018,20(06):193-194.)
(1)严格意义上说,人工智能和机器学习没有直接关系,只不过目前机器学习的方法被大量的应用于解决人工智能的问题而已。目前机器学习是人工智能的一种实现方式,也是最重要的实现方式。早期的机器学习实际上是属于统计学,而非计算机科学的;而二十世纪九十年代之前的经典人工智能跟机器学习也没有关系。
(2)深度学习是机器学习研究中的一个新的领域,是机器学习现在比较火的一个方向,其本身是神经网络算法的衍生,在图像、语音等富媒体的分类和识别上取得了非常好的效果。其动机在于建立、模拟人脑进行分析学习的神经网络,它模仿人脑的机制来解释数据,例如图像,声音和文本。
2人工智能发展和内容
2.1 AI目标
(1)逻辑推理。使计算机能够完成人类能够完成的复杂心理任务。例如下棋和解代数问题。
(2)知识表达。使计算机能够描述对象,人员和语言。例如能使用面向对象的编程语言 Smalltalk。
(3)规划和导航。使计算机从A点到B点。例如,第一台自动驾驶机器人建于20世纪60年代初。
(4)自然语言处理。使计算机能够理解和处理语言。例如把英语翻译成俄语,或者把俄语翻译成英语。
(5)感知。让电脑通过视觉,听觉,触觉和嗅觉与世界交流。
(6)紧急智能。也就是说,智能没有被明确地编程,而是从其他AI特征中明确体现。这个设想的目的是让机器展示情商,道德推理等等。
2.2 AI领域
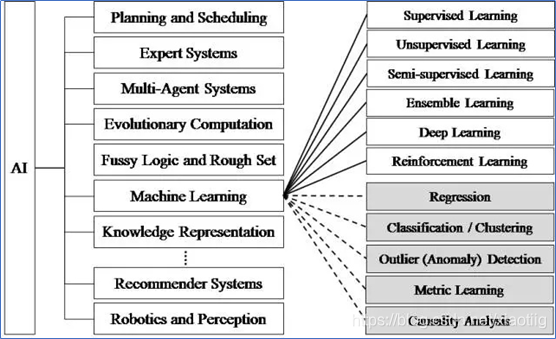
(1)机器学习是人工智能领域,使计算机不用明确编程就能学习。
(2)搜索和优化算法,如梯度下降迭代搜索局部最大值或最小值。
(3)约束满足是找到一组约束的解决方案的过程,这些约束施加变量必须满足的条件。
(4)逻辑推理。人工智能中逻辑推理的例子是模拟人类专家决策能力的专家计算机系统。
(5)概率推理是将概率论的能力去处理不确定性和演绎逻辑的能力来利用形式论证的结构结合起来。其结果是一个更丰富和更具表现力的形式主义与更广泛应用领域。
(6)控制理论是一种正式的方法来找到具有可证性的控制器。这通常涉及描述像机器人或飞机这样的物理系统的微分方程组。
3 机器学习发展内容
3.1 发展阶段
1950年(艾伦.图灵提议建立一个学习机器),从20世纪50年代研究机器学习以来,不同时期的研究途径和目标并不相同,可以划分为四个阶段。
第一阶段是20世纪50年代中叶到60年代中叶,这个时期主要研究“有无知识的学习”。
第二阶段从20世纪60年代中叶到70年代中叶,这个时期主要研究将各个领域的知识植入到系统里,在本阶段的目的是通过机器模拟人类学习的过程。比如专家系统。
第三阶段从20世纪70年代中叶到80年代中叶,称为复兴时期。在此期间,人们从学习单个概念扩展到学习多个概念,探索不同的学习策略和学习方法,且在本阶段已开始把学习系统与各种应用结合起来,并取得很大的成功。
第四阶段20世纪80年代中叶,是机器学习的最新阶段。机器学习已成为新的学科,它综合应用了心理学、生物学、神经生理学、数学、自动化和计算机科学等形成了机器学习理论基础。
3.2 任务
机器学习的研究主要分为两类研究方向:第一类是传统机器学习的研究,该类研究主要是研究学习机制,注重探索模拟人的学习机制;第二类是大数据环境下机器学习的研究,该类研究主要是研究如何有效利用信息,注重从巨量数据中获取隐藏的、有效的、可理解的知识。
根据训练数据是否拥有标记信息,学习任务可大致划分为两大类"监督学习" (supervised learning) 和"无监督学习" (unsupervised learning),亦称“有导师学习“和 “无导师学习”确切地说,是"未见示例" (unseen instance)。分类和回归是前者的代表,而聚类则是后者的代表。
3.3目标
机器学习的目标是使学得的模型能很好地适用于"新样本", 而不是仅仅在训练样本上工作得很好; 学得模型适用于新样本的能力,称为"泛化" (generalization)能力.具有强泛化能力的模型能很好地适用于整个样本空间.于是,尽管训练集通常只是样本需间的一个很小的采样,我们仍希望它能很好地反映出样本空间的特性,否则就很难期望在训练集上学得的模型能在整个样本空间上都工作得很好。
3.4算法
机器学习的经典算法主要有五种类型,分别为:
(1)聚类算法,采用各种距离度量技术将一系列的数据点划分到K类中,划分后的聚类结构具有类内相似、类间差距最大的特点。
(2)分类算法,事先按照一定的标准给一组对象集合进行分类,并赋予类标签,训练出学习模型,利用该模型对未知对象进行分类。
(3)回归算法,综合考虑整个数据集中因变量和自变量之间的关系进行建模, 进而利用模型对给定的自变量进行计算得到预测值。
(4)关联规则算法,在整个事务型数据中分析同时出现次数较多的频繁项集,并将出现次数满足一定阈值的频繁项集作为关联项集。
(5)降维算法,在机器学习过程中由于对象属性较多,为了降低计算复杂度利用各种度量技术将高维空间中的数据转换成低维空间中的数据。(摘自:并行机器学习算法基础体系前沿进展综述)
(1)人工智能的常用十种算法_人工智能_fanyun的博客-CSDN博客 https://blog.csdn.net/fanyun_01/article/details/83505856
(2)(5条消息)人工智能常见算法简介_人工智能_nfzhlk的专栏-CSDN博客 https://blog.csdn.net/nfzhlk/article/details/82725769?utm_medium=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-1.nonecase&depth_1-utm_source=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-1.nonecase
(3)周志华老师的西瓜书很不错。
3.5 学习方式
机器学习按照学习方法分类可分为:监督学习、无监督学习、半监督学习和强化学习、若监督学习。
(1)监督学习(Supervised learning),监督学习指的是用打好标签的数据训练预测新数据的类型或值。
(2)无监督学习(Unsupervised learning),无监督学习是在数据没有标签的情况下做数据挖掘, 无监督学习主要体现在聚类。简单来说是将数据根据不同的特征在没有标签的情况下进行分类。无监督学习的典型方法有k-聚类及主成分分析等。
(3)半监督学习(Semi-Supervised learning),半监督学习根据字面意思可以理解为监督学习和无监督学习的混合使用。事实上是学习过程中有标签数据和无标签数据相互混合使用。一般情况下无标签数据比有标签数据量要多得多。
(4)强化学习(Reinforcement learning),强化学习是通过与环境的交互获得奖励, 并通过奖励的高低来判断动作的好坏进而训练模型的方法,可以得到一个延迟的反馈,并且只有提示你是离答案越来越近还是越来越远。
(5)弱监督学习,弱监督通常分为三种类型:不完全监督(半监督学习)、不确切监督、不准确监督。不确切监督:训练的数据有一个弱标签,希望通过深度学习,得到一个强标签。比如说,知道一张图片是一只猫,通过训练知道猫在那里,将猫和背景分离开来。不准确监督:有些标签是错误的,不准确的。
4深度学习发展内容
4.1 深度学习的发展历程
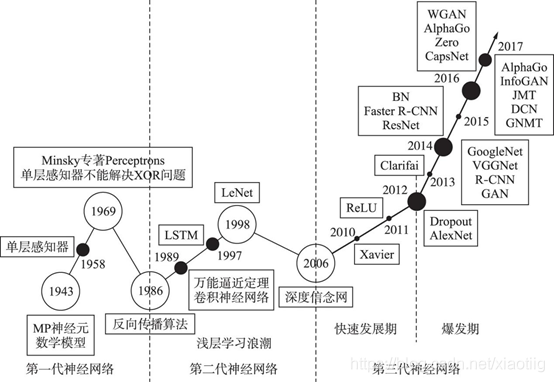
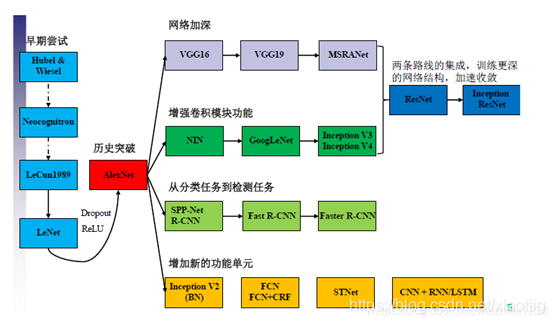
(1)1943年, 心理学家McCulloch和数理逻辑学家Pitts提出了神经元的第1个数学模型———MP模型(以他们两的名字命名)[1]. 它大致模拟了人类神经元的工作原理, 但需要手动设置权重, 十分不便。MP模型具有开创意义, 为后来的研究工作提供了依据.
(2)1958年, Rosenblatt[2]教授提出了感知机模型 (perceptron) , Rosenblatt在MP模型的基础之上增加了学习功能, 提出了单层感知器模型, 第一次把神经网络的研究付诸实践[2, 3]. 尽管相比MP模型, 该模型能更自动合理地设置权重, 但同样存在较大的局限, 难以展开更多的研究。
(3)Minsky教授于和Paper教授于1969年证明了感知机模型只能解决线性可分问题, 不能够处理线性不可分问题,并且否定了多层神经网络训练的可能性, 甚至提出了“基于感知机的研究终会失败”的观点, 此后十多年的时间内, 神经网络领域的研究基本处于停滞状态。
(4)20世纪80年代, 计算机飞速发展, 计算能力相较以前也有了质的飞跃。直至1986年, Rumelhart等人[4] 在Nature上发表文章,提出了一种按误差逆传播算法训练的多层前馈网络—反向传播网络 (Back PropagationNetwork, BP网络) , 解决了原来一些单层感知器所不能解决的问题. BP算法的提出不仅有力地回击了Minsky教授等人的观点, 更引领了神经网络研究的第二次高潮。随后, 玻尔兹曼机、卷积神经网络、循环神经网络等神经网络结构模型均在这一时期得到了较好的发展。
(5)由于在20世纪90年代, 各种浅层机器学习模型相继被提出, 较经典的如支持向量机[5], 而且当增加神经网络的层数时传统的BP网络会遇到局部最优、过拟合及梯度扩散等问题, 这些使得深度模型的研究被搁置.
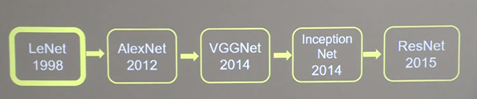
(6)1990 年, LeCun等[4]提出了现代 CNN 框架的原始版本, 之后又对其进行了改进, 于1998年提出了基于梯度学习的CNN模型——LeNet-5[5], 并将其成功应用于手写数字字符的识别中, 1998年的LeNet.最早提出了卷积神经网络,并用于手写数字识别.只是由于当时缺乏大规模的训练数据, 计算机的计算能力也有限, 所以LeNet在解决复杂问题 (例如大规模的图像和视频分类问题) 时, 效果并不好(陈超,齐峰.卷积神经网络的发展及其在计算机视觉领域中的应用综述[J].计算机科学,2019,46(03):63-73.)这篇paper写的很好。
(7)2006年, 机器学习领域泰斗Hinton[5]及其团队在Science上发表了关于神经网络理念突破性的文章, 首次提出了深度学习的概念, 并指明可以通过逐层初始化来解决深度神经网络在训练上的难题。该理论的提出再次激起了神经网络领域研究的浪潮。Hinton教授解决了BP神经网络算法梯度消失的问题, 深度学习的思想再次回到了大众的视野之中, 也正因为如此, 2006年被称为是深度学习发展的元年。
前6个发展历史的参考文献(付文博,孙涛,梁藉,闫宝伟,范福新.深度学习原理及应用综述[J].计算机科学,2018,45(S1):11-15+40.)(周飞燕,金林鹏,董军.卷积神经网络研究综述[J].计算机学报,2017,40(06):1229-1251.)
(8)2011年, 吴恩达领导Google科学家们用16000台电脑成功模拟了一个人脑神经网络;
(9)2012年, Hinton教授带领团队参加ImageNet图像识别比赛。在比赛中, Hinton团队所使用的深度学习算法一举夺魁, 其性能达到了碾压第二名SVM算法的效果, 自此深度学习的算法思想受到了业界研究者的广泛关注。深度学习的算法也渐渐在许多领域代替了传统的统计学机器学习方法, 成为人工智能中最热门的研究领域(周晟颐.深度学习技术综述[J].科技传播,2018,10(20):116-118.DOI:10.16607/j.cnki.1674-6708.2018.20.058)
(10)2013年, 欧洲委员会发起模仿人脑的超级计算机项目, 同年1月, 百度宣布成立深度学习研究院。
(11)2014年, 2014 年出现了两个很有影响力的卷积神经网络模型——依旧致力于加深模型层数的 VGGNet 和在模型结构上进行优化的 Inception Net深度学习模型Top-5在ImageNet 2014计算机识别竞赛上拔得头筹, 同年, 腾讯和京东也分别成立了自己的深度学习研究室。
(12)2014年, 生成对抗网络[6]的提出是深度学习的又一突破性进展, 将生成模型和判别模型紧密联系起来。(乔风娟,郭红利,李伟,李彬.基于SVM的深度学习分类研究综述[J].齐鲁工业大学学报,2018,32(05):39-44.DOI:10.16442/j.cnki.qlgydxxb.2018.05.008)
(13)2016年, AlphaGo击败围棋世界冠军李在石, 同年9月, 中国科学院计算技术研究所发布“寒武纪1A”深度神经元网络处理器。这一切都显著地表明了一个事实:深度学习正在有条不紊地发展着, 其影响力不断扩大。(付文博,孙涛,梁藉,闫宝伟,范福新.深度学习原理及应用综述[J].计算机科学,2018,45(S1):11-15+40.)
这篇文章写的很详细(张荣,李伟平,莫同.深度学习研究综述[J].信息与控制,2018,47(04):385-397+410.DOI:10.13976/j.cnki.xk.2018.8091)
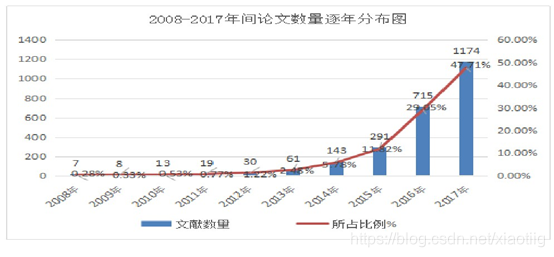
2008年到2017年知网上深度学习相关论文发表数量和比例趋势图
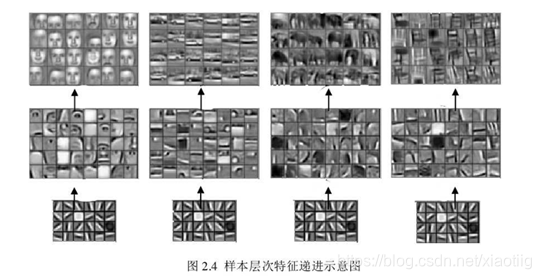
对一幅图像来说,像素级的特征是没有意义的复杂的图像都是由一些基本的图像构成。


4.2深度学习算法
4.2.1 神经网络的本质:
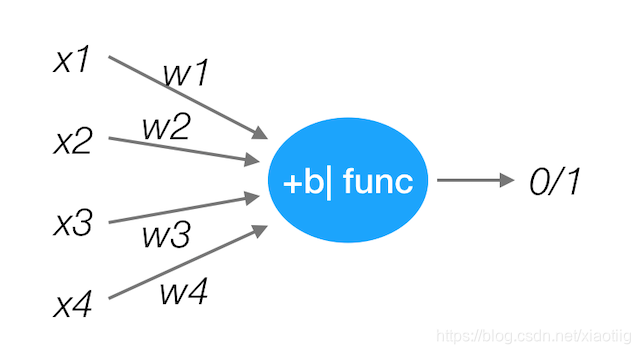

理解具有全连接层的神经网络的一个方式是:可以认为它们定义了一个由一系列函数组成的函数族,网络的权重就是每个函数的参数。
神经网络可以近似任何连续函数。
基于深度学习的算法有分类和回归两类。回归问题指预测出一个连续值的输出, 例如可以通过房价数据的分析, 根据样本的数据输入进行拟合, 进而得到一条连续的曲线用来预测房价。分类问题指预测一个离散值的输出, 例如根据一系列的特征判断当前照片是狗还是猫, 输出值就是1或者0。
深度学习是一类模式分析方法的统称,就具体研究内容而言,主要涉及6类方法:
(1)基于卷积运算的神经网络系统,即卷积神经网络(CNN)。
(2)基于多层神经元的自编码神经网络,包括自编码( Auto encoder)以及近年来受到广泛关注的稀疏编码两类( Sparse Coding)。
(3)以多层自编码神经网络的方式进行预训练,进而结合鉴别信息进一步优化神经网络权值的深度置信网络(DBN)。
(4)限制玻尔兹曼机(RestrictedBoltzmann Machine,RBM)
(5)循环神经网络(Recurrent Neural Network,RNN)
(6)生成对抗网络 (GAN)
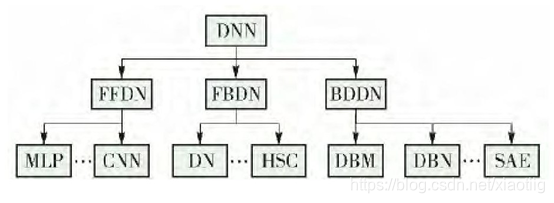
深度神经网络分为以下3类( 如下图所示) .
- 前馈深度网络 ( feed-forward deep networks, FFDN) ,由多个编码器层叠加而成,如多层感知机 ( multi-layer perceptrons,MLP)[31-32]、卷积神经网络 (convolutional neural networks,CNN)[33-34]等.
- 反馈深度网络 ( feed-back deep networks, FBDN) ,由多个解码器层叠加而成,如反卷积网络 ( deconvolutional networks,DN)[30]、层次稀疏编码网络(hierarchical sparse coding,HSC)[35]等.
- 双向深度网络( bi-directional deep networks, BDDN) ,通过叠加多个编码器层和解码器层构成 ( 每层可能是单独的编码过程或解码过程,也可能既包含编码过程也包含解码过程) ,如深度玻尔兹曼机( deep Boltzmann machines,DBM)[36-37]、深度信念网络( deep belief networks,DBN)[26]、栈式自编码器( stackedauto-encoders,SAE)[38]等. (尹宝才,王文通,王立春.深度学习研究综述[J].北京工业大学学报,2015,41(01):48-59.)
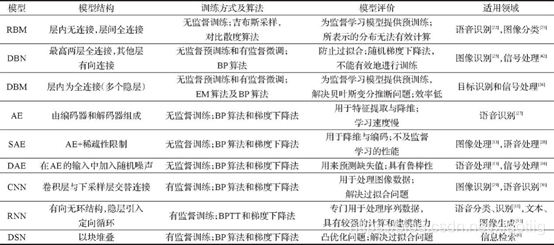
深度学习发展非常迅速, 涌现出诸多模型。深度置信网络、自编码器[9]、卷积神经网络[10]和循环神经网络[11]构成了早期的深度学习模型, 随后由这些模型演变出许多其他模型, 主要包括稀疏自编码器[12]、降噪自编码器[13]、堆叠降噪自编码器[14]、深度玻尔兹曼机[15]、深度堆叠网络[16]、深度对抗网络[17]和卷积深度置信网络[18]等([1]史加荣,马媛媛.深度学习的研究进展与发展[J].计算机工程与应用,2018,54(10):1-10.)
4.3 深度学习特点
深度网络[12-13]包含多层非线性映射, 具有多个隐藏层, 每一层提取出相应的特征, 经过多层次的提取和结合, 得到更有利于分类的高级特征。其特点可以概括为: 1) 深层次,2) 非线性,3) 逐层特征提取,深度学习模型有支持向量机无法比拟的非线性函数逼近能力, 能够很好地提取并表达数据的特征, 深度学习模型的本质是特征学习器[30]。(乔风娟,郭红利,李伟,李彬.基于SVM的深度学习分类研究综述[J].齐鲁工业大学学报,2018,32(05):39-44.DOI:10.16442/j.cnki.qlgydxxb.2018.05.008)
DNN 的两个非常重要的特征是多层和非线性.DNN 的两个非常重要的特征是多层和非线性[30],多[30],多层是为了符合分布式知识表达(1.1 节)的要求,非线性是为了解决更加复杂的问题(张政馗,庞为光,谢文静,吕鸣松,王义.面向实时应用的深度学习研究综述[J].软件学报,1-25.DOI:10.13328/j.cnki.jos.005946)。
4.4 最新研究,很重要
AutoML(Automated Machine Learning)[82]和神经架构搜索(Neural Architecture Search,NAS)的发展促进了深度学习模型的自动化设计.AutoML 是模型选择、特征抽取和超参数调优等一系列自动化方法,可以实现自 动训练有价值的模型.机器学习最耗费人力的部分主要是数据清洗和模型调参,而这部分过程如果采用自动化 方式实现将会加快网络模型的开发过程. (张政馗,庞为光,谢文静,吕鸣松,王义.面向实时应用的深度学习研究综述[J].软件学报,1-25.DOI:10.13328/j.cnki.jos.005946)
另外可以将深度学习与svm结合,深度学习中全连接层将输出转化为一维向量,将得到的一维向量作为SVM的输入, 进行训练, 并在测试集上进行验证。(乔风娟,郭红利,李伟,李彬.基于SVM的深度学习分类研究综述[J].齐鲁工业大学学报,2018,32(05):39-44.DOI:10.16442/j.cnki.qlgydxxb.2018.05.008)
随着人类社会的飞速发展,在越来越多复杂的现实场景任务中,需要利用 DL来自动学习大规模输入数据的抽象表征,并以此表征为依据进行自我激励的 RL,优化解决问 题 的 策 略.决问 题 的 策 略.由 此,谷 歌 的 人 工 智 能 研 究 团 队DeepMind创新性地将具有感知能力的 DL 和具有决策能力的 RL 相结合,形成了人工智能领域新的研究 热 点,即 深 度 强 化 学 习 (Deep ReinforcementLearning,DRL).(刘全,翟建伟,章宗长,钟珊,周倩,章鹏,徐进.深度强化学习综述[J].计算机学报,2018,41(01):1-27.)。
(张昱航.基于端到端的深度网络优化算法[D].中国科学院大学(中国科学院深圳先进技术研究院),2020.这篇文章介绍的很详细
5卷积神经网络发展内容
5.1卷积神经网络介绍
卷积神经网络具有局部感知、共享权重和池化降采样三大特点,被广泛应用于图像处理中(吴雨茜,王俊丽,杨丽,余淼淼.代价敏感深度学习方法研究综述[J].计算机科学,2019,46(05):1-12.)。广泛应用于图像分类和物体识别等场景.CNN 网络的架构可以用公式[3]来[3]来表示:输入层→(卷积层+→池化层?)+→全连接层+,其中“卷积层+”表示一层或多层卷积层(CONV),“池化层?”表示没有或一层池化层(POOL).卷积层的全连接层+,其中“卷积层+”表示一层或多层卷积层(CONV),“池化层?”表示没有或一层池化层(POOL).卷积层的以极大减少训练阶段需要优化的总参数量.池化层可以非常有效地缩减矩阵的尺寸(主要用于减小矩阵的长和宽),从而减少最后全连接层中的参数,并有防止过拟合的作用。
卷积、非线性变换(激活函数)和下采样3个阶段构成的单层卷积神经网络如下图所示.。(尹宝才,王文通,王立春.深度学习研究综述[J].北京工业大学学报,2015,41(01):48-59.)

多层卷积神经网络深度学习算法具有可移植性。(肖堃.多层卷积神经网络深度学习算法可移植性分析[J/OL].哈尔滨工程大学学报:1-6[2020-05-07 14:46].)


5.2卷积神经网络处理计算机视觉的原理

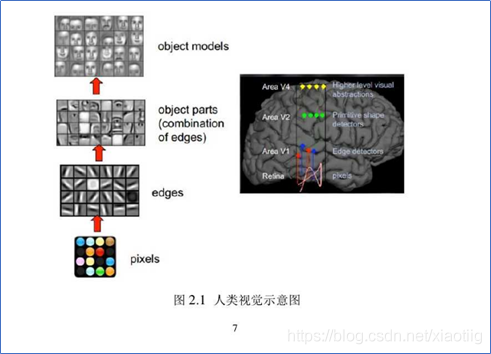
**对一幅图像来说,像素级的特征是没有意义的复杂的图像都是由一些基本的图像构成。**浅层卷积层可以得到物体的边缘信息,深层卷积层可以得到物体更抽象更细节的信息。


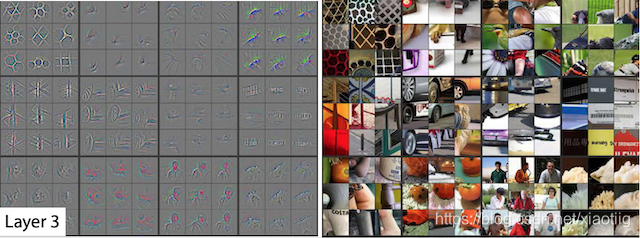

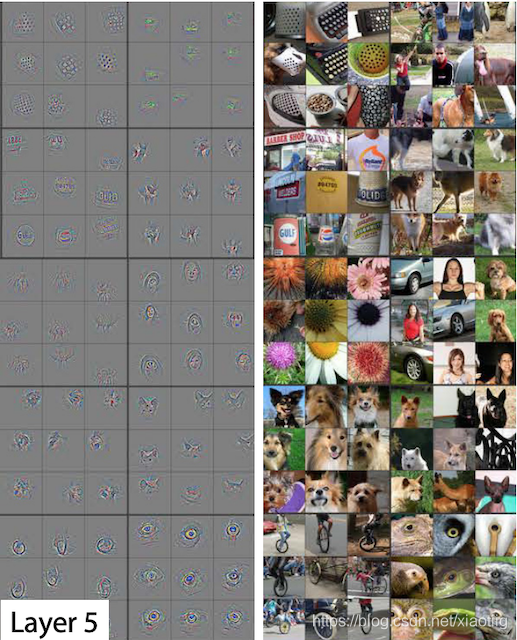

另外一个计算原理就是:本质上就是一个个线性方程,比如y=ax+b,进行曲线的拟合。使得交叉熵或其它损失函数指最小。
神经元模型是从神经元上受到了启发,但是在计算机视觉图片和卷积神经网络中是受大脑皮层的启发。

致谢
对本文中所用到的资料的作者表示最崇高的感谢!

