
- 1Unity Bound_unity中的bound
- 2基于ssm的宠物医院管理系统的设计与实现_宠物医院管理软件设计
- 3Android EditText关于imeOptions的设置和响应_android:imeoptions
- 4RTTHREAD 软件包目录(实时更新)_rtthread env 软件包目录
- 5从高考到程序员的成长之路_cui 程序员
- 6LeetCode-48. 旋转图像【数组 数学 矩阵】
- 7图文介绍HTTP/2(特性、解决的问题、实现方法)_http2 实现
- 8我,程序员,32岁失业后干啥都赔钱,月薪2万的好日子一去不返_失业的程序员在干什么
- 9开源 | 30余套STM32单片机、嵌入式Linux、物联网、人工智能项目(开发板+教程+视频)_单片机开源项目
- 10如何阅读“计算机界三大神书”之一 ——SICP
数字人解决方案——阿里EMO音频驱动肖像生成能说话能唱歌的逼真视频
赞
踩
前言
数字可以分为3D数字人和2D数字人。3D数字人以虚幻引擎的MetaHuman为代表,而2D数字人则现有的图像或者视频做为输入,然后生成对口型的数字人,比如有SadTalker和Wav2Lip。
-
SadTalker:SadTalker是一种2D数字人算法,其输入为图片+音频。这一类算法不仅生成新的口型,还生成头部运动,具有较高的复杂度。SadTalker的主要功能是将静态图像中的人物头部进行运动生成,使其似乎在说话。这种技术对于视频制作、虚拟人物等领域具有广泛的应用。
-
Wav2Lip:Wav2Lip也是一种2D数字人算法,其输入为视频+音频。与SadTalker不同,Wav2Lip的主要功能是根据音频内容生成视频中人物的口型,使其与音频同步。这种技术在视频配音、语音合成等应用中非常有用。
而最近,阿里发布了一款名为EMO的新音频驱动人物头像说话视频生成模型。EMO具有更高的生成能力和自然度。只需提供一张照片和一段音频,EMO即可生成长达1分30秒的AI视频,其中人物头部能够表现丰富的变化,包括表情、五官、姿势等,呈现出更加自然的效果。
阿里EMO音频驱动图像生成能说话能唱歌的逼真视频
EMO增强说话头像视频生成的方法,旨在提高其真实感和表现力。通过直接将音频转换为视频,而不是依赖中间的3D模型或面部标记,从而绕过了一些传统方法中可能存在的缺陷,如视频帧之间的过渡不连续或身份保护的不一致性。EMO的实验结果表明,它能够生成令人信服的说话视频和唱歌视频,并且在表现力和逼真度方面明显优于现有的方法。
通过这种直接从音频到视频的转换,EMO能够在生成的视频中保持更加连续和一致的动作,同时确保了身份保护的准确性。这使得生成的视频更加自然和真实,增强了用户的观感体验。

如果对该数字人项目感兴趣或者的企鹅群:787501969,大家一起探讨。
算法简介
本文旨在建立一种创新的说话头框架,旨在捕捉广泛的真实面部表情,包括微妙的微表情,并促进自然的头部运动,从而赋予生成的头部视频无与伦比的表现力。为了实现这一目标,提出了一种利用扩散模型的生成能力的方法,能够直接从给定的图像和音频剪辑合成角色头部视频。为了解决音频与面部表情之间的映射模糊性问题,模型中加入了稳定的控制机制,即速度控制器和面部区域控制器,以增强生成过程中的稳定性。此外,为了确保生成的视频中的角色与输入参考图像保持一致,采用了ReferenceNet的方法,并设计了一个类似的模块,FrameEncoding,旨在在整个视频中保持角色的身份。
EMO能够生成高度自然和表现力强的说话和唱歌视频。为了训练模型,作者构建了一个包含250小时的音视频数据集,涵盖了演讲、电影、电视剧和唱歌表演等多种内容和多种语言。作者在HDTF数据集上进行了广泛的实验和比较,结果表明EMO方法在多个指标上均超过了当前最先进的方法。此外,作者还进行了用户研究和定性评估,证明EMO方法可以生成高度自然和表现力强的说话和唱歌视频,是迄今为止最好的方法之一。
算法原理
音频驱动的说话人生成方法可以分为基于视频和基于单张图片的两种方法。基于视频的方法直接编辑输入视频片段,但存在头部动作固定和只生成口部动作的限制。基于单张图片的方法利用参考照片生成与照片外观相似的视频,但存在3D网格表达能力有限和生成结果表现力不足的问题。相对于其他方法,Dreamtalk进行了改进,但仍然无法实现高度自然的面部视频生成。
EMO基于单张角色肖像图即可生成视频,可以根据输入的语音音频剪辑生成与之同步的视频,保留自然的头部运动和生动的表情,同时与提供的语音音频的音调变化协调一致。该模型可以创建无缝级联的视频序列,生成具有一致身份和连贯动作的长时间说话肖像视频,对于实现逼真的应用非常重要。
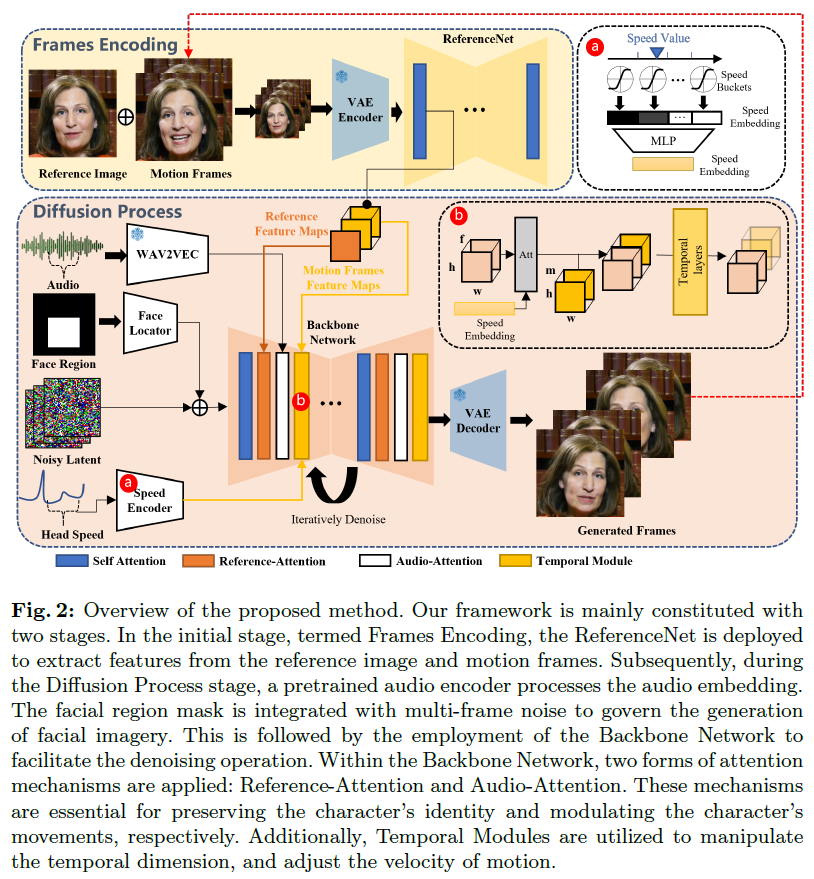
EMO的方法概述如图2所示。骨干网络获取多帧噪声潜在输入,并尝试在每个时间步内对连续的视频帧进行去噪,骨干网络具有与原始SD 1.5相似的UNet结构配置。1)与之前的工作类似,为保证生成帧之间的连续性,骨干网络中嵌入了时序模块。2)为了保持生成的框架中肖像的ID一致性,部署了一个平行于主干的UNet结构ReferenceNet,它输入参考图像以获取参考特征。3)使用音频层对语音特征进行编码,以驱动角色说话动作。4)利用人脸定位器和速度层提供弱条件,使说话人运动可控、稳定。
骨干网络:
骨干网络获取多帧噪声潜在输入,并尝试在每个时间步内对连续的视频帧进行去噪。骨干网络具有与原始SD 1.5相似的UNet结构配置。为保证生成帧之间的连续性,在骨干网络中嵌入了时序模块。为了保持生成的框架中肖像的ID一致性,部署了一个平行于主干的UNet结构ReferenceNet,它输入参考图像以获取参考特征。
音频层:
通过预训练wav2vec的各个块从输入音频序列中提取的特征被连接起来,以产生第f帧的音频表示嵌入A (f)。然而,动作可能会受到未来/过去音频片段的影响,为解决这个问题,本文通过连接附近帧的特征来定义每个生成帧的语音特征。为了将语音特征注入到生成过程中,在骨干网络的每个ref-attention层之后,在潜代码和gen之间添加音频-注意力层,执行交叉注意力机制。
ReferenceNet:
ReferenceNet具有与骨干网络相同的结构,用于从输入图像中提取详细特征。参考网络和骨干网络都继承了原始SD UNet的权重。目标字符的图像输入到ReferenceNet中,以提取自注意力层输出的参考特征图。在主干去噪过程中,对应层的特征与提取的特征图一起经过参考注意力层。
时间模块:
在AnimateDiff的架构概念的指导下,将自注意力时间层应用于帧内的特征。将自注意力引导到时间维度f上,以有效捕捉视频的动态内容。时序层插入到骨干网的每个分辨率层。本方法纳入了之前生成的片段的最后n帧,称为"运动帧",以增强跨片段的一致性。将这n个运动帧输入到ReferenceNet以预提取多分辨率运动特征图。在主干网络的去噪过程中,将时序层输入与预先提取的匹配分辨率的运动特征沿帧维度进行融合。
面部定位器和速度层:
时间模块可以保证生成帧的连续性和视频片段之间的无缝过渡,但由于生成过程的独立性,时间模块不足以保证生成角色在各个片段之间运动的一致性和稳定性。选择“弱”控制信号方法,利用掩膜M作为人脸区域,其中包含视频剪辑的面部边界框区域。采用了人脸定位器,它由轻量级的卷积层组成,旨在编码边界框掩膜。然后将得到的编码掩码添加到噪声潜表示中,然后将其输入到主干中。通过这种方式,可以使用掩模来控制应该生成字符人脸的位置。
然而,由于在单独的生成过程中头部运动频率的变化,在片段之间创建一致和平滑的运动是具有挑战性的。为解决这个问题,将目标头部运动速度纳入到生成中。通过这样做并指定目标速度,可以在不同剪辑中同步生成角色头部的旋转速度和频率。结合面部定位器提供的面部位置控制,输出结果既稳定又可控。
训练方法
训练过程分为三个阶段:
-
第一阶段:图像预训练,包括对骨干网络、ReferenceNet和Face Locator的训练。在此阶段,主要对骨干网络的结构进行预训练,以及对辅助网络(ReferenceNet)和人脸定位器进行训练。
-
第二阶段:视频训练,引入了时间模块和音频层。在这个阶段,除了利用图像预训练的模型外,还引入了时间模块和音频层,以更好地处理视频数据的动态特性和语音信息。
-
第三阶段:集成速度层,只训练时间模块和速度层,而不训练音频层。这一阶段的目标是通过加入速度层来进一步提高模型的性能,但不再训练音频层,因为同时训练速度和音频层可能会削弱音频对角色动作的驱动能力。
实验与测试
实现细节:
-
数据集和训练时长:
- 使用了250小时的讲话视频和HDTF、VFHQ数据集进行训练。
- HDTF数据集被分为训练集和测试集,其中测试集占10%,训练集占90%。
-
人脸检测和姿态提取:
- 使用MediaPipe人脸检测框架获取面部边界框区域。
- 使用面部标志提取6DoF头部姿态,计算相邻帧之间的旋转度数。
-
训练过程:
- 采用了三个阶段的训练,使用了批量大小为48和4的不同参数。
- 第一阶段对骨干网络、ReferenceNet和Face Locator进行图像预训练。
- 第二阶段引入了时间模块和音频层,进行视频训练。
- 第三阶段集成速度层,只训练时间模块和速度层,不训练音频层。
-
推理过程:
- 使用DDIM的采样算法生成视频剪辑。
- 每批次的时间消耗为15秒。
-
实验设置和评估指标:
- 使用Diffused Heads方法生成的结果进行了定性比较。
- 比较了与Wav2Lip、SadTalker和DreamTalk等方法的性能。
- 使用DreamTalk的说话风格参数。
- 使用Fréchet Inception Distance (FID)评估生成帧的质量。
- 使用面部相似度(FSIM)评估生成帧与参考图像之间的身份保持程度。
- 使用Fréchet Video Distance (FVD)评估视频的质量。
- 使用SyncNet评估唇部同步质量。
- 使用Expression-FID评估生成视频中面部表情的表达能力。
结果比对


相比于Wav2Lip和DreamTalk,EMO的方法具有以下优势:首先,Wav2Lip合成的嘴部区域模糊,而EMO方法能够生成更清晰的嘴部图像。其次,DreamTalk的样式剪辑可能扭曲原始面部,限制了面部表情和头部动作的动态性,而EMO的方法能够生成更多样的头部动作和更动态的面部表情。值得注意的是,EMO的方法不使用直接信号来控制角色运动,而是直接由音频驱动,这使得在生成过程中能够更好地保持角色的一致性和流畅性。
进一步地,EMO探索了不同肖像风格的说话头像视频的生成。尽管模型只在逼真的视频上进行了训练,但它展示了在各种肖像类型上生成说话头像视频的能力。EMO的方法能够在处理具有明显音调特征的音频时生成更丰富的面部表情和动作。此外,通过利用运动帧,EMO可以延长生成的视频,从而根据输入音频的长度生成持续时间更长的视频。值得一提的是,EMO的方法在大幅运动中仍然能够保持角色的身份,这是生成视频时的一个重要考量因素。


项目主页:https://humanaigc.github.io/emote-portrait-alive/
论文地址:https://arxiv.org/pdf/2402.17485.pdf
Github地址:https://github.com/HumanAIGC/EMO

