
- 1mysql系列之-根据月份查询数据_mysql按月份查询并汇总
- 2Ubuntu22.04与深度学习配置(已搭建三台服务器)_深度学习是用ubantu20好还是用ubantu22比较好
- 3vscode 远程开发golang_vscode ssh 远程开发怎么启动golang项目
- 4网络安全CTF夺旗赛入门到入狱-入门介绍篇_ctf夺旗赛找flag
- 5nvm安装步骤及使用方法_nvm使用教程
- 6linux 完全卸载docker_linux完全卸载docker
- 7基于hadoop或docker环境下,Kafka+flink+mysql+datav的实时数据大屏展示_flink 实时大屏
- 8springboot--跨域_springboot什么是跨域问题
- 9常见算法在实际项目中的应用_算法在实际开发中有用么
- 10MySQL 10几种索引类型,你都清楚吗?_mysql索引分类
zero shot classification提取主题词_zero-shot-event-classification-for-newsfeeds
赞
踩
基于 NLI 的零镜头文本分类。zero shot classification提出了一种使用预训练的 NLI 模型作为现成的零样本序列分类器的方法。该方法的工作原理是将要分类的序列设置为 NLI 前提,并从每个候选标签构建一个假设。例如,如果我们想评估一个序列是否属于“政治”类,我们可以构建一个“本文是关于政治”的假设。然后将蕴涵和矛盾的概率转换为标签概率。
这种方法在许多情况下都非常有效,尤其是与 BART 和 Roberta 等大型预训练模型一起使用时。有关此方法和其他零样本方法的更广泛介绍,请参阅此博客文章,并查看下面的代码片段,以获取使用此模型进行零样本分类的示例,包括 Hugging Face 的内置管道和本机 Transformers/PyTorch 代码。
使用零样本分类管道
该模型可以加载零样本分类管道,如下所示:
- from transformers import pipeline
- classifier = pipeline("zero-shot-classification",
- model="facebook/bart-large-mnli")
-
- # You can then use this pipeline to classify sequences into any of the class names you specify.
- sequence_to_classify = "one day I will see the world"
- candidate_labels = ['travel', 'cooking', 'dancing']
- classifier(sequence_to_classify, candidate_labels)
- #{'labels': ['travel', 'dancing', 'cooking'],
- # 'scores': [0.9938651323318481, 0.0032737774308770895, 0.002861034357920289],
- # 'sequence': 'one day I will see the world'}
- #If more than one candidate label can be correct, pass multi_class=True to calculate each class independently:
- candidate_labels = ['travel', 'cooking', 'dancing', 'exploration']
- classifier(sequence_to_classify, candidate_labels, multi_class=True)
- #{'labels': ['travel', 'exploration', 'dancing', 'cooking'],
- # 'scores': [0.9945111274719238,
- # 0.9383890628814697,
- # 0.0057061901316046715,
- # 0.0018193122232332826],
- # 'sequence': 'one day I will see the world'}

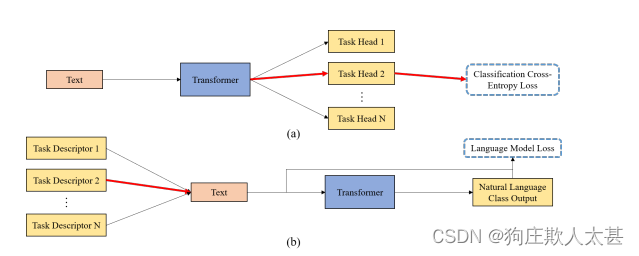
(a) 多任务分类器让模型对文本进行特征化,并将其发送到 N 个任务头之一。
(b)在我们的方法中,N个任务之一描述符附加在文本前面,模型以自然语言生成答案
在这项工作中,我们提出了一种新的零镜头语言分类预训练方法生成语言模型分类器。通过自然语言生成分类该模型消除了对多个特定于任务的分类头的需要,使该模型更加简单通用性和灵活性。增加模型和数据规模进一步表明最近的transformer语言模型足以提取有意义的特征表示让我们更好地概括和适应新任务。这些结果突出了天然气的潜力语言作为未来应用中的学习和适应信号。
目前,这项工作用于分类。未来的扩展应该进行调查.基于梯度的元学习适应任务描述符的能力,无论是通过基于K-shot支持的学习,还是通过对任务描述符本身采取梯度步骤
此外,未来的工作可以将文本分类任务扩展到其他语言问题,如作为问题答案或指示。在其他设置中应用此技术需要:解决其在可控性、可用数据和任务多样性方面的当前限制。
参考文献:Zero-shot Text Classification With Generative Language Models

