
- 1介绍一款idea神级插件【Bito-ChatGPT】而且免费!_bito-chatgpt插件
- 2L2-4 哲哲打游戏 (25 分)_l2-034 口罩发放 分数 25 作者 dai, longao 单位 杭州百腾教育科技有限公司 为
- 3【微信小程序开发】小程序前后端交互--发送网络请求实战解析
- 4python用pd.read_csv()方法来读取csv文件_pd 读csv
- 5FPGA基本概念及资源整理——FPGA学习笔记<0>_野火fpga资料
- 6Vue 组件的生命周期钩子有哪些用途是什么
- 7文献阅读:Mistral 7B_mistral 本地知识库
- 8已解决selenium.common.exceptions.SessionNotCreatedException: Message: session not created异常的正确解决方法,亲测有效
- 9计算机专业研究生平均月薪,研究生刚毕业工资一般多少
- 10ZYNQ AXI4总线访问DDR3实现图像数据乒乓存储与显示_axi 访问ps ddr
机器学习之协同过滤算法_协同过滤算法模型怎么训练
赞
踩
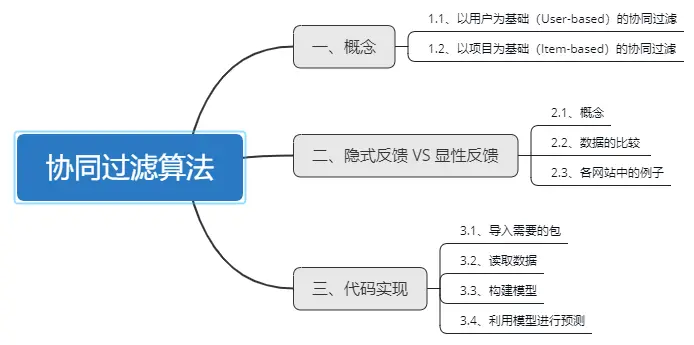
一、概念
协同过滤算法主要分为基于用户的协同过滤算法和基于项目的协同过滤算法。
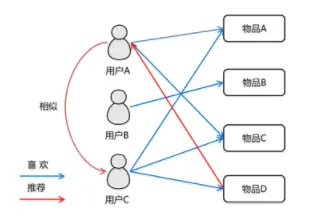
1.1、以用户为基础(User-based)的协同过滤
用相似统计的方法得到具有相似爱好或者兴趣的相邻用户,所以称之为以用户为基础(User-based)的协同过滤或基于邻居的协同过滤(Neighbor-based Collaborative Filtering)。
具体步骤为:
1.收集用户信息
收集可以代表用户兴趣的信息。一般的网站系统使用评分的方式或是给予评价,这种方式被称为“主动评分”。另外一种是“被动评分”,是根据用户的行为模式由系统代替用户完成评价,不需要用户直接打分或输入评价数据。电子商务网站在被动评分的数据获取上有其优势,用户购买的商品记录是相当有用的数据。
2.最近邻搜索(Nearest neighbor search, NNS)
以用户为基础(User-based)的协同过滤的出发点是与用户兴趣爱好相同的另一组用户,就是计算两个用户的相似度。例如:查找n个和A有相似兴趣用户,把他们对M的评分作为A对M的评分预测。一般会根据数据的不同选择不同的算法,较多使用的相似度算法有Pearson Correlation Coefficient、Cosine-based Similarity、Adjusted Cosine Similarity。
3.产生推荐结果
有了最近邻集合,就可以对目标用户的兴趣进行预测,产生推荐结果。依据推荐目的的不同进行不同形式的推荐,较常见的推荐结果有Top-N 推荐和关系推荐。Top-N 推荐是针对个体用户产生,对每个人产生不一样的结果,例如:通过对A用户的最近邻用户进行统计,选择出现频率高且在A用户的评分项目中不存在的,作为推荐结果。关系推荐是对最近邻用户的记录进行关系规则(association rules)挖掘。
1.2、以项目为基础(Item-based)的协同过滤
以用户为基础的协同推荐算法随着用户数量的增多,计算的时间就会变长,所以在2001年Sarwar提出了基于项目的协同过滤推荐算法(Item-based Collaborative Filtering Algorithms)。以项目为基础的协同过滤方法有一个基本的假设“能够引起用户兴趣的项目,必定与其之前评分高的项目相似”,通过计算项目之间的相似性来代替用户之间的相似性。
具体步骤为:
1.收集用户信息
同以用户为基础(User-based)的协同过滤。
2.针对项目的最近邻搜索
先计算已评价项目和待预测项目的相似度,并以相似度作为权重,加权各已评价项目的分数,得到待预测项目的预测值。例如:要对项目 A 和项目 B 进行相似性计算,要先找出同时对 A 和 B 打过分的组合,对这些组合进行相似度计算,常用的算法同以用户为基础(User-based)的协同过滤。
3.产生推荐结果
以项目为基础的协同过滤不用考虑用户间的差别,所以精度比较差。但是却不需要用户的历史数据,或是进行用户识别。对于项目来讲,它们之间的相似性要稳定很多,因此可以离线完成工作量最大的相似性计算步骤,从而降低了在线计算量,提高推荐效率,尤其是在用户多于项目的情形下尤为显著。
二、隐式反馈 VS 显性反馈
2.1、概念
隐性反馈行为:不能明确反映用户喜好的行为。
显性反馈行为:用户明确表示对物品喜好的行为。
显性反馈行为包括用户明确表示对物品喜好的行为,隐性反馈行为指的是那些不能明确反应用户喜好的行为。在许多的现实生活中的很多场景中,我们常常只能接触到隐性的反馈,例如页面游览,点击,购买,喜欢,分享等等。
基于矩阵分解的协同过滤的标准方法,一般将用户商品矩阵中的元素作为用户对商品的显性偏好。在 MLlib 中所用到的处理这种数据的方法来源于文献: Collaborative Filtering for Implicit Feedback Datasets 。 本质上,这个方法将数据作为二元偏好值和偏好强度的一个结合,而不是对评分矩阵直接进行建模。因此,评价就不是与用户对商品的显性评分,而是与所观察到的用户偏好强度关联起来。然后,这个模型将尝试找到隐语义因子来预估一个用户对一个商品的偏好。
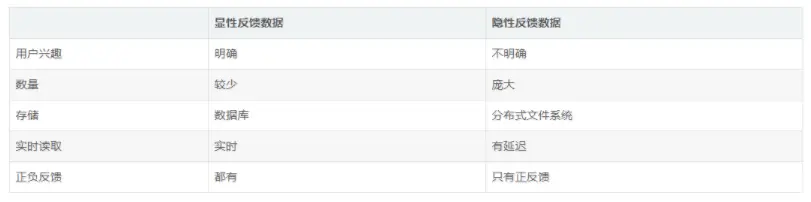
2.2、显性反馈数据和隐形反馈数据的比较
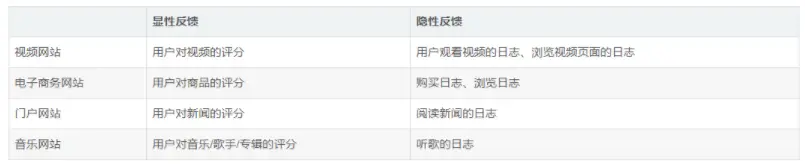
2.3、各代表网站中显性反馈数据和隐性反馈数据的例子
三、代码实现
下面代码读取spark的示例文件,文件中每一行包括一个用户id、商品id和评分。我们使用默认的ALS.train() 方法来构建推荐模型并评估模型的均方差。
3.1、导入需要的包:
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.mllib.recommendation.ALS;
import org.apache.spark.mllib.recommendation.MatrixFactorizationModel;
import org.apache.spark.mllib.recommendation.Rating;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
3.2、读取数据:
首先,读取文本文件,把数据转化成rating类型,即[Int, Int, Double]的RDD;
/** * 1、获取spark */ SparkConf conf = new SparkConf().setAppName("CollaborativeModel").setMaster("local"); JavaSparkContext sc = new JavaSparkContext(conf); /** * 2、读取文本文件,把数据转化成rating类型,即[Int, Int, Double]的RDD */ JavaRDD<String> source = sc.textFile("data/mllib/collaborative.data"); JavaRDD<Rating> ratings = source.map(line->{ String[] parts = line.split(","); return new Rating(Integer.parseInt(parts[0]), Integer.parseInt(parts[1]), Double.parseDouble(parts[2])); }); ratings.foreach(x->{ System.out.println(x); }); /** *控制台输出结果: *Rating中的第一个int是user编号,第二个int是item编号,最后的double是user对item的评分。 ---------------- Rating(1,1,5.0) Rating(3,2,5.0) Rating(1,2,1.0) Rating(3,3,1.0) Rating(1,3,5.0) Rating(3,4,5.0) Rating(1,4,1.0) Rating(4,1,1.0) Rating(2,1,5.0) Rating(4,2,5.0) Rating(2,2,1.0) Rating(4,3,1.0) Rating(2,3,5.0) Rating(4,4,5.0) Rating(2,4,1.0) Rating(3,1,1.0) ---------------- **/

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
3.3、构建模型
划分训练集和测试集,比例分别是0.8和0.2。
JavaRDD<Rating>[] splits = ratings.randomSplit(new double[] {0.8,0.2});
JavaRDD<Rating> training = splits[0];
JavaRDD<Rating> test = splits[1];
- 1
- 2
- 3
指定参数值,然后使用ALS训练数据建立推荐模型:
int rank = 10;
int numIterations = 10;
/**
* 可以调整这些参数,不断优化结果,使均方差变小。比如:iterations越多,lambda较小,均方差会较小,推荐结果较优
*/
MatrixFactorizationModel model = ALS.train(training.rdd(),rank,numIterations,0.01);
- 1
- 2
- 3
- 4
- 5
- 6
在 MLlib 中的实现有如下的参数:
numBlocks 是用于并行化计算的分块个数 (设置为-1,为自动配置)。
rank 是模型中隐语义因子的个数。
iterations 是迭代的次数。
lambda 是ALS的正则化参数。
implicitPrefs 决定了是用显性反馈ALS的版本还是用适用隐性反馈数据集的版本。
alpha 是一个针对于隐性反馈 ALS 版本的参数,这个参数决定了偏好行为强度的基准。
可以调整这些参数,不断优化结果,使均方差变小。比如:iterations越多,lambda较小,均方差会较小,推荐结果较优。上面的例子中调用了 ALS.train(ratings, rank, numIterations, 0.01) ,我们还可以设置其他参数,调用方式如下:
MatrixFactorizationModel model2 = new ALS().setRank(10)
.setIterations(2000)
.setLambda(0.01)
.setImplicitPrefs(true)
.setUserBlocks(10)
.setProductBlocks(10)
.run(training);
- 1
- 2
- 3
- 4
- 5
- 6
- 7
3.4、 利用模型进行预测
从 test训练集中获得只包含用户和商品的数据集 :
JavaRDD<Tuple2<Object, Object>> testUsersProducts = test.map(line->{
return new Tuple2<>(line.user(),line.product());
});
- 1
- 2
- 3
使用训练好的推荐模型对用户商品进行预测评分,得到预测评分的数据集:
JavaPairRDD<Tuple2<Integer, Integer>, Double> predictions =JavaPairRDD.fromJavaRDD(
model.predict(testUsersProducts.rdd()).toJavaRDD().map(r->
new Tuple2<>(new Tuple2<>(r.user(),r.product()),r.rating())));
- 1
- 2
- 3
将真实评分数据集与预测评分数据集进行合并。这里,Join操作类似于SQL的inner join操作,返回结果是前面和后面集合中配对成功的,过滤掉关联不上的。
JavaPairRDD<Tuple2<Integer, Integer>, Double> predictions = JavaPairRDD.fromJavaRDD( model.predict(testUsersProducts.rdd()).toJavaRDD().map(r-> new Tuple2<>(new Tuple2<>(r.user(),r.product()),r.rating()))); System.out.println(predictions); predictions.foreach(x->{ System.out.println(x); }); /** *控制台输出结果: *Rating中的第一个int是user编号,第二个int是item编号,最后的double是user对item的评分。 ---------------------------- ((4,2),0.010526887751696495) ((1,1),3.6826782499237716) ((1,2),0.7464017268228036) ((3,2),0.010526887751696495) ---------------------------- **/
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
我们把结果输出,对比一下真实结果与预测结果:
JavaPairRDD<Tuple2<Integer, Integer>, Tuple2<Double, Double>> ratesAndPreds = JavaPairRDD.fromJavaRDD(test.map(x->new Tuple2<>( new Tuple2<>(x.user(),x.product()),x.rating()))).join(predictions); System.out.println("------------------------------------------"); ratesAndPreds.foreach(x->{ System.out.println(x); }); /** *控制台输出结果: *比如,第二条结果记录((4,2),(5.0,0.010526887751696495))中,(4,2)分别表示4号用户和2号商品,而5.0是实际的估计分值, *0.010526887751696495是经过推荐的预测分值。 ----------------------------------- ((1,1),(5.0,3.6826782499237716)) ((4,2),(5.0,0.010526887751696495)) ((1,2),(1.0,0.7464017268228036)) ((3,2),(5.0,0.010526887751696495)) ----------------------------------- **/
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
比如,第二条结果记录((4,2),(5.0,0.010526887751696495))中,(4,2)分别表示4号用户和2号商品,而5.0是实际的估计分值,0.010526887751696495是经过推荐的预测分值。
然后计算均方差,这里的r1就是真实结果,r2就是预测结果:
double MSE = ratesAndPreds.values().mapToDouble(x->{
double err = x._1() - x._2();
return err * err;
}).mean();
System.out.println("Mean Squared Error = "+MSE);
/**
*控制台输出结果:
-----------------------------------
Mean Squared Error = 2.8413113799948704
-----------------------------------
**/
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
我们可以看到打分的均方差值为1.09左右。由于本例的数据量很少,预测的结果和实际相比有一定的差距。上面的例子只是对测试集进行了评分,我们还可以进一步的通过调用model.recommendProducts给特定的用户推荐商品以及model.recommendUsers来给特定商品推荐潜在用户。
参考资料:http://spark.apache.org/docs/latest/mllib-collaborative-filtering.html

