
- 1【物联网工程导论期末复习完整知识点】第四章物联网智能硬件与嵌入式
- 2DNS安全浅议、域名A记录(ANAME),MX记录,CNAME记录 专题
- 3你怎么对待婚姻,婚姻就怎么对待你!_你怎么对婚姻 婚姻就怎么对你
- 4清华发布新版计算机学科推荐学术会议和期刊列表,IJCAI降级_《清华大学计算机学科推荐学术会议和期刊列表》
- 5关于Can‘t find model ‘en_core_web_sm‘. 错误解决
- 6云上战场:ToDesk云电脑、青椒云、顺网云全面对决_青椒云包月计时和包月的区别
- 7【Android Studio使用教程1】Android Studio导入项目的几种方法
- 8基于FPGA的IIC读写EEPROM_eeprom fpga
- 9【重点EI会议推荐】机器学习主题方向论文征稿:2021计算机、物联网与控制工程国际学术会议(CITCE 2021)...
- 10亚马逊云科技AIGC全家桶Bedrock炸裂登场,开放定制隐私拉满
震撼来袭,GPT-4全解读_gpt4的多模态原理,小孩子也能看懂的通俗原理
赞
踩
今年3月,OpenAI团队正式宣布:GPT-4 来了!
微信搜索关注《Python学研大本营》,加入读者群,分享更多精彩
OpenAI发布的GPT-4是深度学习方面的最新里程碑。GPT-4是一个大型的多模态模型(可接收图像和文本输入,发出文本输出),虽然在许多现实世界的场景中能力不如人类,但在各种专业和学术基准上匹敌人类水平的表现。例如,它通过了模拟的律师考试,分数在应试者的前10%左右;相比之下,GPT-3.5的分数则在后10%左右。OpenAI花了6个月的时间,利用对抗性测试项目以及ChatGPT的经验,反复调整GPT-4,结果在事实性、可引导性等方面取得了有史以来最好的结果。

在过去的两年里,OpenAI重建了整个深度学习的技术栈,并且微软Azure专门为OpenAI设计了一台超级计算机。一年前,OpenAI训练了GPT-3.5作为系统的第一次 "试运行"。此次发现并修复了一些错误,并改进了理论基础。因此,GPT-4训练运行空前稳定。
GPT-4的“考试”能力
在机器对话中,GPT-3.5和GPT-4之间的区别并不大。但当任务的复杂性达到一定阈值时,区别就体现出来了,GPT-4比GPT-3.5更可靠,更有创造性,能够处理更细微的指令。
为了了解这两种模型之间的差异,OpenAI在各种基准上进行了测试,包括参加考试。OpenAI并没有为这些考试做专门的训练,考试中的少数问题是模型在训练中看到的。

GPT-4在GRE语文上取得了169的高分(满分170)!

OpenAI还在为机器学习模型设计的传统基准上评估了GPT-4。GPT-4的性能大大超过了现有的大型语言模型,与大多数最先进的(SOTA)模型并驾齐驱。

因为许多现有的ML基准是基于英语,为了初步了解其他语言的能力,OpenAI使用微软的Azure Translate将MMLU基准(一套涵盖57个主题的14000个多选题)翻译成了其他语言。在测试的26种语言中的24种语言中,GPT-4的表现优于GPT-3.5和其他LLM(Chinchilla,PaLM)的英语表现,包括一些小众语言,如拉脱维亚语、威尔士语和斯瓦希里语。

玩图也一流
GPT-4可以接收文本和图像输入,用户可指定任何视觉或语言任务。具体来说,它可以生成文本输出(自然语言、代码等),给定的输入包括穿插的文本和图像。在一系列的领域中,包括带有文字和照片的文件、图表或屏幕截图,GPT-4表现出与纯文本输入类似的能力。
GPT-4可以看懂搞笑图中的梗!
用户:这幅图有什么不寻常之处?
GPT-4:这张图片的不寻常之处在于,一名男子正在连接在一辆行驶中的出租车车顶的熨衣板上熨烫衣服。

用户:你能解释一下这个帖子吗?
GPT-4:这个备忘录是一个笑话,它结合了两个不相关的东西:从太空看地球的图片和鸡块。该备忘录的文字表明,下面的图片是从太空拍摄的地球的照片。然而,该图片实际上是鸡块的排列,摆放地像一张世界地图。这个备忘录的幽默感来自于文字和图片的意外并置。文字让人期待地球的雄伟形象,但图像实际上是平凡而愚蠢的东西。

用户:这幅画有什么有趣的地方?逐一描述一下。
GPT-4:图片显示的是一个“Lightning Cable”适配器的包装,有三张图。图1:一部智能手机,其充电端口插着一个VGA接口。图2:“Lightning Cable”适配器的包装上有一张VGA接口的图片。图3:VGA连接器的特写,末端是一个小的Lightning连接器(用于为iPhone和其他苹果设备充电)。这张图片的幽默感来自于将一个大的、过时的VGA连接器插入一个小的、现代的智能手机充电端口的荒谬性。

GPT-4还能对表格数据进行总结。
用户:格鲁吉亚和西亚的日均肉类消费之和是多少?在提供你的答案之前,请提供一步步的推理。
GPT-4:为了找到格鲁吉亚和西亚的日均肉类消费总和,我们将遵循以下步骤。
确定格鲁吉亚的日均肉类消费。
确定西亚的日均肉类消费。
将步骤1和2的数值相加。
第1步:从提供的图表中,我们看到格鲁吉亚的日均肉类消费量为每人每天79.84克。第2步:从图表中,我们看到西亚的平均每日肉类消费是每人每天69.62克。第3步:将第1步和第2步的数值相加。79.84克(格鲁吉亚)+69.62克(西亚)=149.46克
因此,格鲁吉亚和西亚的日均肉类消费之和为每人每天149.46克。

GPT-4还会做法国高考试题。
用户:回答问题I.1.a. 逐步解答。
GPT-4:为了回答问题I.1.a,我们需要表达导电条上每一点的温度T(x),其特征是标点x。
在静止状态下,棒材中的一维热传导的热方程为。d²T/dx² = 0
通过一次积分,我们可以得到 dT/dx = C₁
第二次积分。T(x) = C₁x + C₂
为了确定常数C₁和C₂,我们使用边界条件。T(0)=T0,从而得出C₂=T0 T(L)=Tb,因此C₁ = (Tb - T0) / L
最后,T(x)的表达式为。T(x) = (Tb - T0) * (x / L) + T0 这代表了沿着导电条的线性温度曲线,其斜率为(Tb - T0) / L。

将InstuctGPT论文发给GPT-4,它就能总结出论文的要点来。
用户:面是InstuctGPT论文的一部分。你能给我总结一下吗?
GPT-4:InstructGPT论文的重点是训练大型语言模型在人类反馈下遵循指令。作者指出,让语言模型变得更大并不能从本质上使它们更好地遵循用户的意图。大型模型可能会产生不真实的、有毒的或根本没有帮助的输出。
为了解决这个问题,作者在广泛的任务中使用人类反馈对语言模型进行了微调。他们从一组标签员写的提示和回应开始,然后收集标签员对所需模型行为的演示数据集。他们使用监督学习对GPT-3进行微调,然后使用来自人类反馈的强化学习来进一步微调该模型。由此产生的模型,称为InstructGPT,显示了真实性的改善和有毒输出生成的减少,同时在公共NLP数据集上的性能回归最小。
作者总结说,利用人类反馈进行微调是使语言模型与人类意图相一致的一个有希望的方向。

GPT-4变得更听话了
OpenAI一直在努力实现可引导性,让GPT可以更“听话”。与经典的ChatGPT个性的固定言语、语气和风格不同,开发者现在可以通过在“系统”消息中描述这些方向来规定他们的AI的风格和任务。系统消息允许API用户在一定范围内大幅定制他们的用户体验。

局限性
尽管有这样的能力,GPT-4也有与早期GPT模型类似的局限性。最重要的是,它仍然不是完全可靠的。在使用语言模型的输出时,特别是在高风险的情况下,应该非常小心,要让准确的协议与特定的使用案例的需求相匹配。
虽然仍然是一个真实的问题,但相对于以前的模型(这些模型本身也在不断改进),GPT-4大大减少了失误。在内部对抗性事实性评估中,GPT-4的得分比最新的GPT-3.5高40%。
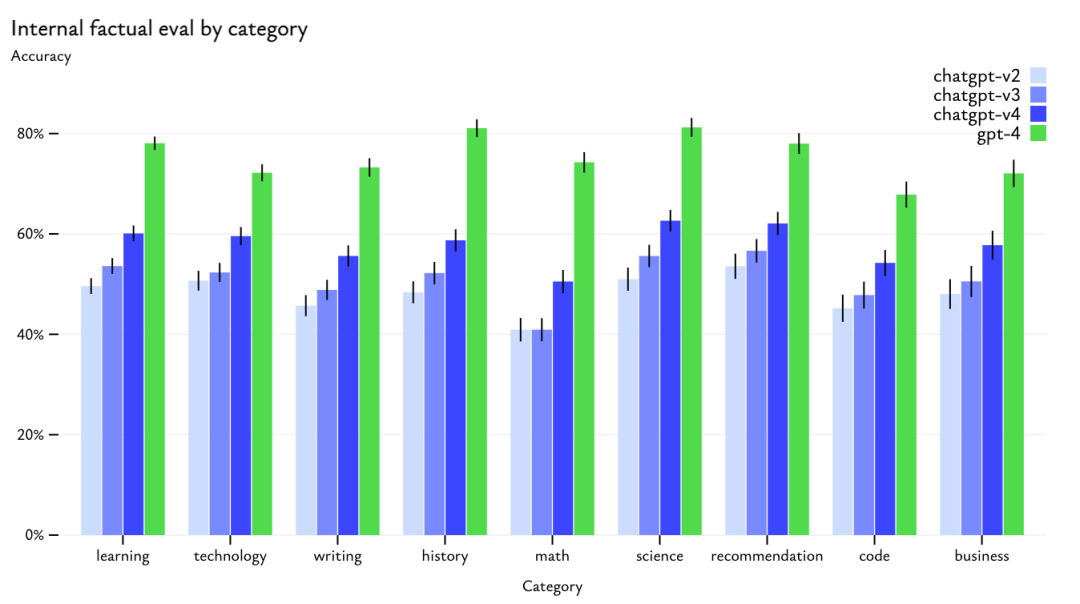
在九类内部对抗性设计的事实评估中,GPT-4(绿色)与前三个ChatGPT版本进行了比较。在所有题目中都有明显的进步。准确度为1.0意味着模型的答案被判断为与评估中所有问题的人类理想答案一致。
GPT-4在TruthfulQA等外部基准上取得了进展,该基准测试了模型从对抗性选择的不正确陈述中分离事实的能力。这些问题与在统计学上具有吸引力的事实错误的答案相搭配。

GPT-4基础模型在这项任务上只比GPT-3.5略胜一筹;然而,在经过RLHF的后期训练后(应用OpenAI在GPT-3.5上使用的相同过程),却有很大提升。

更加安全的GPT-4
OpenAI一直在对GPT-4进行迭代,使其从培训开始就更加安全和一致,努力的方向包括选择和过滤预培训数据、评估和专家参与、模型安全改进以及监测和执行。
GPT-4与以前的模型有类似的风险,如产生有害的建议、错误的代码或不准确的信息。然而,GPT-4的额外能力导致了新的风险面。为了了解这些风险的程度,OpenAI聘请了50多位来自人工智能对接风险、网络安全、生物风险、信任和安全以及国际安全等领域的专家对该模型进行对抗性测试。来自这些专家的反馈和数据为OpenAI缓解和改进模型提供了依据;OpenAI已经收集了额外的数据,以提高GPT-4拒绝有关如何合成危险化学品的请求的能力。
GPT-4在RLHF训练中加入了一个额外的安全奖励信号,通过训练模型来拒绝对此类内容的请求,从而减少有害产出。奖励是由GPT-4的零点分类器提供的,它判断安全边界和安全相关提示的完成方式。为了防止模型拒绝有效的请求,OpenAI从不同的来源(例如,标记的生产数据、人类的红队、模型生成的提示)收集多样化的数据集,并在允许和不允许的类别上应用安全奖励信号(有一个正值或负值)。
与GPT-3.5相比,OpenAI的缓解措施大大改善了GPT-4的许多安全性能。与GPT-3.5相比,OpenAI将模型对不允许内容的请求的响应倾向降低了82%,而GPT-4对敏感请求(如医疗建议和自我伤害)的响应符合政策的频率提高了29%。


训练过程
和以前的GPT模型一样,GPT-4基础模型的训练是为了预测文档中的下一个词,并使用公开的数据(如互联网数据)以及OpenAI授权的数据进行训练。这些数据是一个网络规模的语料库,包括对数学问题的正确和错误的解决方案,薄弱和强大的推理,自相矛盾和一致的声明,并代表了大量的意识形态和想法。
因此,当被提示有问题时,基础模型可以做出各种各样的反应,可能与用户的意图相去甚远。为了使其与用户的意图保持一致,OpenAI使用人类反馈的强化学习(RLHF)对模型的行为进行了微调。
GPT-4可扩展性大大提高
GPT-4项目的一大重点是建立了可扩展的深度学习栈。主要原因是,对于像GPT-4这样的大型训练运行,进行广泛的特定模型调整是不可行的。OpenAI开发了基础设施和优化,在多种规模下都有非常可预测的行为。为了验证这种可扩展性,OpenAI提前准确地预测了GPT-4在内部代码库(不属于训练集)上的最终损失,方法是通过使用相同的方法训练的模型进行推断,但使用的计算量要少10000倍。

现在,OpenAI可以准确地预测在训练过程中优化的指标(损失),OpenAI开发了多种方法来预测更多可解释的指标。例如,成功地预测HumanEval数据集的一个子集的通过率,从计算量少1000倍的模型中推断出来。

开源OpenAI Evals评估框架
OpenAI开源了OpenAI Evals,这是一个软件框架,用于创建和运行评估GPT-4等模型的基准,同时逐个样本检查其性能。OpenAI使用Evals来指导模型的开发(包括识别缺点和防止退步),用户可以应用它来跟踪不同模型版本(现在将定期推出)和不断发展的产品集成的性能。例如,Stripe使用Evals来补充他们的人工评估,以衡量其GPT驱动的文档工具的准确性。
因为代码都是开源的,Evals支持编写新的类来实现自定义的评估逻辑。希望Evals成为一个分享和众包基准的工具,最大限度地代表广泛的故障模式和困难任务。
推荐书单
《Python从入门到精通(第2版)》
《Python从入门到精通(第2版)》从初学者角度出发,通过通俗易懂的语言、丰富多彩的实例,详细介绍了使用Python进行程序开发应该掌握的各方面技术。全书共分23章,包括初识Python、Python语言基础、运算符与表达式、流程控制语句、列表和元组、字典和集合、字符串、Python中使用正则表达式、函数、面向对象程序设计、模块、异常处理及程序调试、文件及目录操作、操作数据库、GUI界面编程、Pygame游戏编程、网络爬虫开发、使用进程和线程、网络编程、Web编程、Flask框架、e起去旅行网站、AI图像识别工具等内容。所有知识都结合具体实例进行介绍,涉及的程序代码都给出了详细的注释,读者可轻松领会Python程序开发的精髓,快速提升开发技能。除此之外,该书还附配了243集高清教学微视频及PPT电子教案。

精彩回顾
微信搜索关注《Python学研大本营》
访问【IT今日热榜】,发现每日技术热点

