
- 13台虚拟机HA高可用配置详解_三台主机配置 keepalive 高可用
- 2SQL常见函数以及使用_sql函数的使用方法及实例大全
- 3小波包能量 matlab,小波包提取能量特征的3种方法
- 4如何使用群晖虚拟机部署本地网页文件实现公网远程访问?_如何让别人访问我部署在虚拟机上的网页
- 5Android 小白菜鸟从入门到精通教程
- 6mysql utf8mb4 java_Mysql数据库字符集utf8mb4使用问题
- 7用python画简单的风车,python绘制六边形风车_python画风车的代码
- 8web前端新手总结(一):前、后端是如何进行数据交互的?_购物网站前后端如何链到一起
- 9分布式存储Ceph的部署及应用(创建MDS、RBD、RGW 接口)_ceph rados接口
- 10Datawhale AI 夏令营(NLP方向)2024 2期 笔记2
手把手带你搭建一个语音对话机器人,5分钟定制个人AI小助手(新手入门篇)_如何实现对话机器人
赞
踩
写在前面
如果你的身边有一个随时待命、聪明绝顶的AI小助手,能够听懂你的话,理解你的需求,用温暖的声音回应你,会是一种什么体验?
今天,带大家从0到1搭建一个语音对话机器人,分分钟拥有一个专属的个人AI小助手。
本文面向技术小白,以最通俗易懂的语言,最贴心的步骤指导,确保你能够轻松上手,快速掌握。
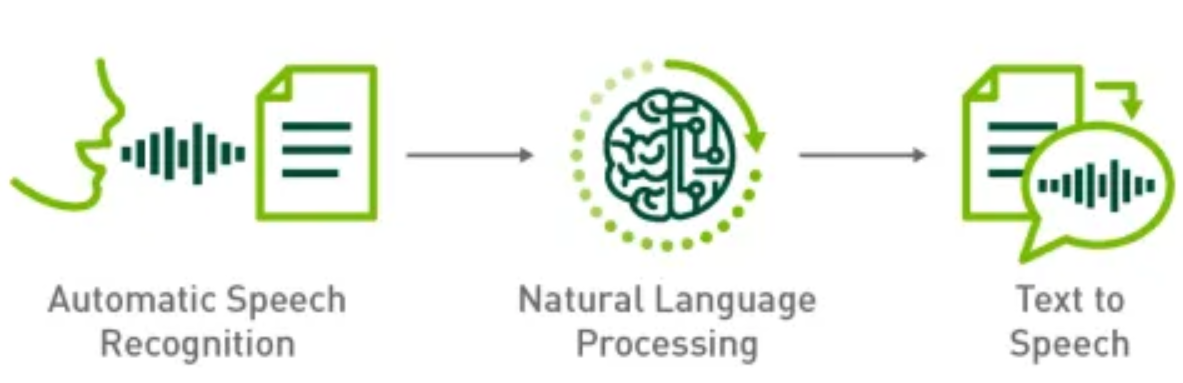
语音对话系统的基本组成有哪些?
一个可以实现语音对话的机器人,通常需要由硬件和软件构成,硬件可以理解为机器人的躯体。
本篇主要来聊聊语音对话机器人的软件部分。
说到软件部分,通常又可以抽象为三个部分:
- 自动语音识别(Automatic Speech Recognition, 简称 ASR),相当于 机器人的耳朵,用于把我们的语音识别成文字;
- 自然语言处理(Natural Language Processing, 简称 NLP),相当于 机器人的大脑,理解上一步得到的文字信息,并进行答复,当前主流的解决方案是大语言模型LLM;
- 文本到语音合成(Text to Speech,简称 TTS),相当于 机器人的嘴巴,把上一步的答复用语音回答出来
如何快速搭建语音对话系统?
为了帮助大家从0到1快速完成一个系统的搭建,本文将完全采用开源方案来实现。具体而言:
-
ASR 采用 FunASR,相比 OpenAI 开源的 Whisper,中文识别效果更好;
-
NLP 采用大语言模型(LLM)方案,比如我们这里可以采用 LLaMA3-8B,采用本地的 GPU 部署和运行,如果没有本地 GPU 资源,也可以调用云端 API 实现这一步;
-
TTS 采用 最新开源的 ChatTTS,它是专门为对话场景设计的文本转语音模型,支持英文和中文两种语言,效果非常惊艳。
1 语音识别 ASR
ASR 采用阿里开源的 FunASR,相比 OpenAI 开源的 Whisper,中文识别效果更好。
GitHub地址:https://github.com/modelscope/FunASR
模型调用参考:https://modelscope.cn/studios/iic/funasr_app_clipvideo/summary
通过如下代码,我们简单测试一下返回结果和模型效果:
from funasr import AutoModel
# asr model
funasr_model = AutoModel(model="iic/speech_seaco_paraformer_large_asr_nat-zh-cn-16k-common-vocab8404-pytorch",
vad_model="damo/speech_fsmn_vad_zh-cn-16k-common-pytorch",
punc_model="damo/punc_ct-transformer_zh-cn-common-vocab272727-pytorch",
spk_model="damo/speech_campplus_sv_zh-cn_16k-common",
)
rec_result = funasr_model.generate("test.wav", return_raw_text=False, is_final=True)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
接下来我们需要将其封装成一个 API ,方便后续调用。最简单的我们可以采用 FastAPI 来实现封装,示例代码如下:
# 定义asr数据模型,用于接收POST请求中的数据 class ASRItem(BaseModel): wav : str # 输入音频,base64编码 time_stamp : int = 0 # 时间戳,可选,默认为0 app = FastAPI() @app.post("/asr") async def asr(item: ASRItem): time_stamp = int(item.time_stamp) try: data = base64.b64decode(item.wav) rec_result = funasr_model.generate(data, return_raw_text=False, is_final=True) res = rec_result[0]['sentence_info'] if time_stamp else rec_result[0]['text'] result_dict = {"code": 0, "msg": "ok", "res": res} except Exception as e: result_dict = {"code": 1, "msg": str(e)} return result_dict if __name__ == '__main__': uvicorn.run(app, host='0.0.0.0', port=2002)

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
2 大语言模型(LLM)
为了实现对话功能,我们可以采用当前的大语言模型(LLM),对上一步识别出来的文字进行理解,并给出答复。
本文的 LLM 采用 LLaMA3-8B,开源社区已经实现了对 LLaMA3-8B 的中文指令微调,为此中文效果会比原始版本效果更好。
GitHub地址:https://github.com/ymcui/Chinese-LLaMA-Alpaca-3
模型地址:https://modelscope.cn/models/ChineseAlpacaGroup/llama-3-chinese-8b-instruct/summary
在上述的 GitHub 仓库中,给出了一键部署的脚本,非常方便。四步走搞定它:
- 下载代码
- 下载模型
- 安装必要的包
- 服务启动
step 1 下载代码:
git clone https://github.com/ymcui/Chinese-LLaMA-Alpaca-3
- 1
step 2 下载模型:
git clone https://www.modelscope.cn/ChineseAlpacaGroup/llama-3-chinese-8b-instruct.git
- 1
step 3 安装必要的包:
pip install fastapi uvicorn shortuuid sse_starlette peft bitsandbytes
pip install flash-attn --no-build-isolation # 如果要使用flash-attention的话
- 1
- 2
step 4 服务启动:
服务启动的代码如下,--base_model 替换为自己的模型路径,--load_in_4bit 指定了采用 4bit 量化。
注意:如果采用不量化的方案,显存占用12G,回复非常慢,有请求过来显存占用最高近14G,而采用4bit 量化,显存只占用 6G。
python scripts/oai_api_demo/openai_api_server.py \
--base_model /path/to/models/llama-3-chinese-8b-instruct/ \
--gpus 2 \
--port 2001 \
--load_in_4bit \
--use_flash_attention_2 \
> log.txt 2>&1 &
- 1
- 2
- 3
- 4
- 5
- 6
- 7
step 5 服务调用:
为了实现 LLM 的个性化回答,当然需要给它设定一个特定的人设啦 ~ ,这一步可以通过人设提示词来轻松搞定。下面给一个示例:
from openai import OpenAI # 枚举所有可用的模型服务 model_dict = { 'llama3-8b': { 'api_key': 'sk-xxx', 'base_url': 'http://10.18.32.170:2001/v1', }, } # 设置人设提示词,根据需要进行修改 prompt_dict = { 'llama3-8b': [ {"role": "system", "content": "你是猴哥的全能小助手,上知天文,下知地理,可解决生活中的一切困扰。"}, ], } class LLM_API: def __init__(self, api_key, base_url, model): self.client = OpenAI( api_key=api_key, base_url=base_url, ) self.model = model def __call__(self, messages, temperature=0.7): completion = self.client.chat.completions.create( model=self.model, messages=messages, temperature=temperature, ) return completion.choices[-1].message.content if __name__ == '__main__': model = 'llama3-8b' llm = LLM_API(model_dict[model]['api_key'], model_dict[model]['base_url'], model) user_question = "你是谁" messages = prompt_dict[model] + [{"role": "user", "content": user_question},] print(llm(messages))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
如果本地没有 GPU 资源部署 大语言模型,也可以选择调用云端 API 来实现这一步,猴哥下一篇就来梳理一下:
我们都可以调用哪些免费的 LLM API?
欢迎追更!
3 语音生成(TTS)
为了将大模型输出的文字生成语音返回,这里我们采用 2024.5 刚开源的项目 - ChatTTS,生成效果非常惊艳。关于 ChatTTS 的具体使用,猴哥会单独出一篇教程,否则本文的篇幅就太长了。
同样还是采用 FastAPI 来实现封装,和部署 ASR 模型类似,在此不再赘述。
(PS:需要源码的可到文末自取~)
4 前端交互实现(Gradio)
Gradio是一个用于快速创建机器学习模型的交互式演示的开源库。它允许开发者通过简单的Python代码快速构建一个用户界面。
为了快速搭建应用,我们还是要请出我们的老朋友 - Gradio,交互界面如图所示:
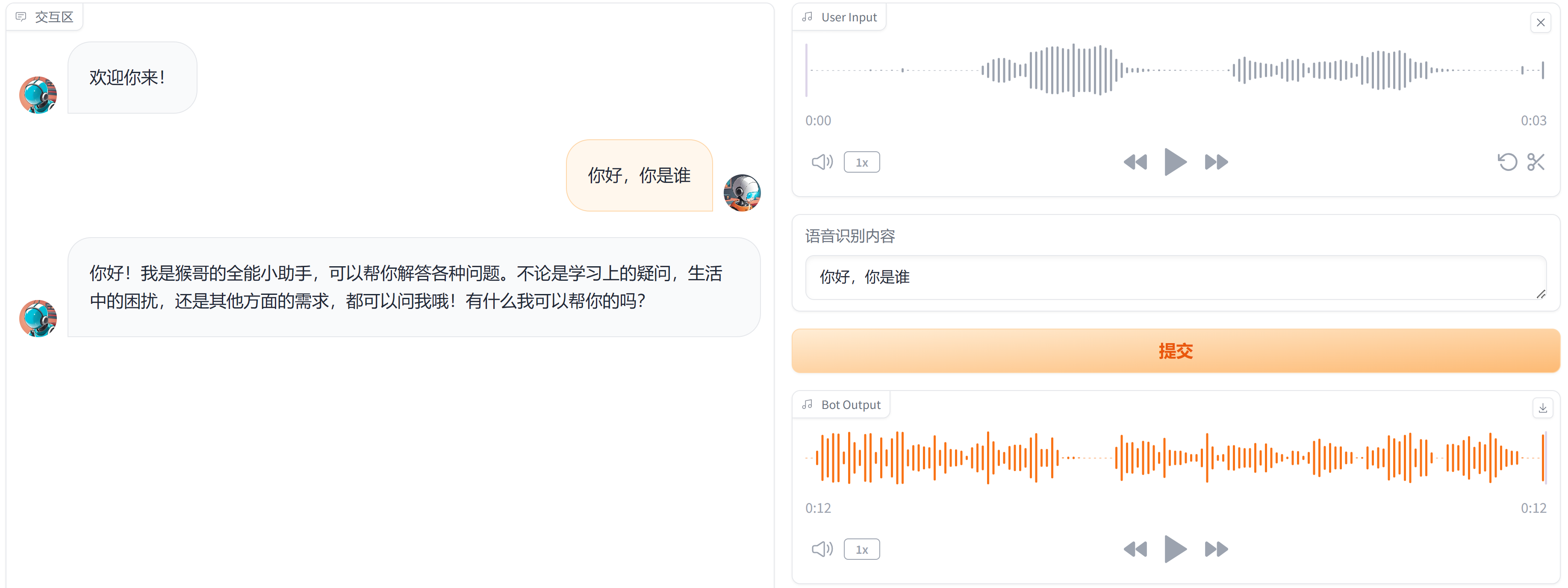
WebUI 代码奉上:
import gradio as gr from speech_client import asr_damo_api, tts_chat_api from llm_client import LLM_API, prompt_dict, model_dict host_avatar = 'assets/host_image.png' user_avatar = 'assets/user_image.png' model = 'llama3-8b' # model = 'gpt-4' llm = LLM_API(model_dict[model]['api_key'], model_dict[model]['base_url'], model) with gr.Blocks(theme=gr.themes.ThemeClass) as demo: state = gr.State({'messages': []}) with gr.Row(): with gr.Column(scale=1): user_chatbot = gr.Chatbot( value=[[None, '欢迎你来!']], elem_classes="app-chatbot", avatar_images=[host_avatar, user_avatar], label="交互区", show_label=True, bubble_full_width=False, height=800) with gr.Column(scale=1): audio_user = gr.Audio(label="User Input", sources=['microphone'], type='filepath') user_text = gr.Textbox(label="语音识别内容") user_submit = gr.Button("提交", variant="primary") audio_bot = gr.Audio(label="Bot Output", autoplay=True, type='filepath') def process_audio(audio): print('Processing audio:', audio) text = asr_damo_api(audio, time_stamp=0, srt=False) print(text) return text def user_submit_handler(user_text, state, chatbot): chatbot.append((user_text, None)) yield (chatbot, None) messages = state['messages'] if len(messages) == 0: messages = prompt_dict[model] + [{"role": "user", "content": user_text}] else: messages.append({"role": "user", "content": user_text}) print(messages) response = llm(messages) chatbot.append((None, response)) messages.append({"role": "assistant", "content": response}) print(messages) state['messages'] = messages audio = tts_chat_api(response) print(audio) yield (chatbot, audio) audio_user.stop_recording(process_audio, inputs=audio_user, outputs=user_text) user_submit.click(user_submit_handler, inputs=[user_text, state, user_chatbot], outputs=[user_chatbot, audio_bot]) demo.launch(server_name='0.0.0.0', server_port=7861)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
最后我们来看下效果:
语音对话机器人-个人AI小助手
未完待续
至此,一个语音对话交互系统就搭建好了,当然目前只是为了演示基本功能,界面还比较简陋,在此基础上 ,还可以增加更多功能:
- ASR : 目前采用的 FunASR 模型,在有噪声情况下识别效果还有待增强,需要找到更有效的平替;
- LLM:模型本地部署对很多小伙伴还是有一定门槛,需要找到平价 or 免费的云端 API
- TTS:ChatTTS的效果非常不错,后续可以增加说话人身份,实现更丰富的输出;支持流式对话,像 GPT-4o 那样自然打断。
如果本文对你有帮助,欢迎点赞收藏备用!
猴哥一直在做 AI 领域的研发和探索,会陆续跟大家分享路上的思考和心得。
最近开始运营一个公众号,旨在分享关于AI效率工具、自媒体副业的一切。用心做内容,不辜负每一份关注。
如需要获取本项目的源码,可关注后台发送 “机器人” 获取

Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

