
- 1【禅与计算机程序设计艺术】7 大程序设计原则_程序代码设计原则
- 2【社区图书馆】《uni-app跨平台开发与应用》读书笔记_uniapp跨平台开发与应用从入门到实践的详细目录
- 331.HarmonyOS App(JAVA)鸿蒙系统app Service服务的用法
- 4Stable diffusion 三大基础脚本 提示词矩阵,载入提示词,XYZ图表讲解_prompts from file or textbox
- 5开发第一个 VisionOS 应用程序的初学者指南_如何在xcode中开发vision app
- 6基于springBoot的社区信息管理系统_社区管理系统
- 7修改Echarts提示框(tooltip)的位置和宽高背景色等_echarts tooltip大小
- 8SAP MB52改为ALV显示格式_sap mb52 alv
- 9OpenHarmony2.0 一站式编译烧录Hi3516标准系统
- 10c++语言与c语言相互调用 踩的坑 否则报函数未定义 一文读懂extern “C“_c代码中引用c++代码有时候会报错为什么
基于转换器的生成式预训练模型(英語:,GPT)是一种大型语言模型(LLM),也是生成式人工智慧的重要框架。_gpt是llm模型嘛
赞
踩
基于转换器的生成式预训练模型(英語:,GPT)是一种大型语言模型(LLM),也是生成式人工智慧的重要框架。首个GPT由OpenAI于2018年推出。GPT模型是基于Transformer模型的人工神经网络,在大型未标记文本数据集上进行预训练,并能够生成类似于人类自然语言的文本。截至2023年,大多数LLM都具备这些特征,并广泛被称为GPT。
| 机器学习与 |
|---|
 |
| 范式
|
| 问题 |
| 监督学习 |
| 聚类分析
|
| 降维
|
| 结构预测
|
| 异常检测
|
| 强化学习
|
| 与人类学习
|
| 模型诊断
|
| 数学基础
|
| 大会与出版物
|
| 相关条目
|
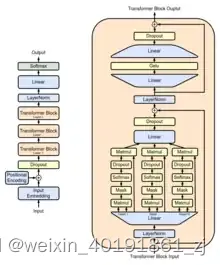
原始的GPT模型
OpenAI发布了具有极大影响力的GPT基础模型,它们按顺序编号,构成了“GPT-n”系列。由于其规模(可训练参数数量)和训练程度的提升,每个模型相较于前一个都显著增强。其中最新的模型是GPT-4,于2023年3月发布。这些模型为更具任务特定性的GPT系统奠定了基础,包括经过微调以适应特定指令的模型——而这些又反过来为ChatGPT聊天机器人服务提供了支持 。
术语“GPT”还用于命名和描述其他开发者所开发的模型。例如,其他GPT基础模型包括EleutherAI开发的一系列模型,以及Cerebras开发的七个模型。此外,不同行业的公司还在其各自领域开发了执行特定任务的GPT,例如赛富时的“EinsteinGPT”(用于客户关系管理)和彭博的“BloombergGPT”(用于金融领域)。
历史
初步发展
生成式预训练(,简称GP)是机器学习应用中一个历史悠久的概念,但直到2017年,Google的员工发明了Transformer模型,这才使得大型语言模型如BERT(2018年)和XLNet(2019年)成为可能,这些模型是预训练的转换器(,简称PT),但未被设计为生成式,而是“仅编码器”()。2018年,OpenAI发表了题为《通过生成式预训练提高语言理解能力》()的文章,在其中首次介绍了基于转换器的生成式预训练模型(GPT)系统(“GPT-1”)。
在基于转换器的架构出现之前,表现最优秀的神经自然语言处理(NLP)模型通常通过大量手动标记的数据进行监督学习。这种依赖于监督学习的开发途径限制了在未经充分标记的数据集上的应用,并且使得训练极大型语言模型相当耗时且开支非常昂贵。
OpenAI采用半监督学习方法来构建大规模生成式系统,同时也是首个使用Transformer模型的方法。该方法包括两个阶段:无监督的生成式“预训练”阶段,使用目标函数来设置初始参数;以及有监督的判别式“微调”阶段,将这些参数在目标任务上进行微调。
后续发展
OpenAI于2020年7月发布了GPT-3的首个版本。其中包括三个模型,参数数量分别为10亿、67亿和1750亿,分别被命名为巴贝奇()、居里()和达芬奇(),分别以B、C和D作为简称。
2021年7月,OpenAI发布了Codex,是专门用于编程应用的特定任务GPT模型。该模型使用GitHub上的代码对GPT-3的12亿参数版本(与之前的GPT-3模型不同)进行代码微调而开发。
2022年3月,OpenAI发布了两个针对指令跟随进行微调(即“指令微调”())的GPT-3版本,分别命名为davinci-instruct-beta(1750亿参数)和text-davinci-001,随后开始测试code-davinci-002。text-davinci-002是通过code-davinci-002进行指令微调得到的。text-davinci-003和ChatGPT于2022年11月发布,两者都是在text-davinci-002的基础上通过基于人类反馈的强化学习方案(RLHF)得到的。text-davinci-003用于遵循指令(与其前身相似),而ChatGPT则经过进一步训练,可与人类用户进行对话交互 。
OpenAI最新的GPT基础模型是GPT-4,于2023年3月14日发布。用户可以通过ChatGPT的高级版本直接访问它,而开发者则可通过OpenAI的API将其纳入其他产品和服务中。其他GPT基础模型的开发者包括EleutherAI(从2021年3月开始推出一系列模型)和Cerebras(于2023年3月发布七个模型)。
基础模型
更多:OpenAI
基础模型是指在广泛的数据上进行大规模训练的AI模型,以便能够适用于各种下游任务 。
迄今为止,最著名的GPT基础模型来自OpenAI的GPT-n系列。其中最新的是GPT-4,OpenAI选择不公开该模型的规模或训练细节,理由是“大规模模型的竞争环境和安全影响”。
| 模型 | 架构 | 参数数量 | 训练数据 | 发布日期 | 训练成本 |
|---|---|---|---|---|---|
| GPT-1 | 12层,12头的Transformer解码器(没有编码器),后跟线性softmax层 | 1.17 亿 | BookCorpus:一个包含7000本未出版书籍的语料库,总大小为4.5 GB。这些书籍涵盖了各种不同的文学流派和主题。 | 2018年6月11日 | “使用8个GPU训练1个月”,或等价于1.7e19次浮点运算(FLOP) |
| GPT-2 | 基于GPT-1架构,但使用修改后的归一化方法 | 15亿 | WebText:一个包含八百万个文档的语料库,总大小为40 GB。这些文本是从Reddit上投票最高的4,500万个网页中收集的,包括各种主题和来源,例如新闻、论坛、博客、维基百科和社交媒体等。 | 2019年2月14日(初始/有限版)和2019年11月5日(完整版) | “数十PetaFlop/s-day”,或等价于1.5e21次浮点运算 |
| GPT-3 | 基于GPT-2架构,但修改以支持更大规模的训练 | 1750亿 | 一个总大小为570 GB的大规模文本语料库,其中包含约4990亿个标记。这些数据主要来自于Common Crawl、WebText、英文维基百科和两个书籍语料库(Books1和Books2)。 | 2020年5月28日 | 3640 petaflop/s-day(Table D.1 ), 或等价于3.1e23次浮点运算 |
| GPT-3.5 | 未公开 | 1750亿 | 未公开 | 2020年3月15日 | 未公开 |
| GPT-4 | 使用文本预测和基于人类反馈的强化学习方案(RLHF)进行训练,并可以接受文本和图像输入。进一步的细节尚未公开 | 未公开 | 未公开 | 2023年3月14日 | 未公开。估计约为2.1e25次浮点运算 |
其他类似的模型包括Google的PaLM,与2023年3月通过API向开发者提供。另外还有Together的GPT-JT,据报道是与GPT-3性能最接近的开源替代方案(源自早期的开源GPT模型)。Meta AI(前身为Facebook)还拥有一个基于转换器的生成式基础大型语言模型(),称为LLaMA。
基础GPT模型还可以采用文本以外的模态进行输入和/或输出。GPT-4是一个多模态LLM,能够处理文本和图像输入(尽管其输出仅限于文本)。多模态输出方面,一些基于转换器的生成式模型被用于文本到图像技术,如扩散和并行解码。此类模型可作为视觉基础模型(visual foundation models,简称VFMs),用于开发能够处理图像的下游系统。
特定任务模型
基础GPT模型可以进一步适应特定任务和/或主题领域,形成更具针对性的系统。这种适应的方法可以包括额外的微调(超出基础模型的微调),以及某种形式的提示工程 。
一个重要的例子是将模型微调以遵循指令,这当然是一个相当广泛的任务,但比基础模型更具针对性。2022年1月,OpenAI推出了“InstructGPT”系列模型,这些模型在GPT-3语言模型的基础上使用监督训练和基于人类反馈的强化学习方案(RLHF)进行微调,以遵循指令。与纯粹的基础模型相比,其优点包括更高的准确性、更少的负面情感,以及更好地符合用户需求。因此,OpenAI开始将它用作其API服务提供的基础。其他开发者也发布了不同的经过指令微调的模型,其中还有完全开源的模型。
另一种(相关的)任务特定模型是聊天机器人,它可以进行类似人类对话的交流。2022年11月,OpenAI推出了ChatGPT。ChatGPT是一个在线聊天界面,由经过指令微调的语言模型提供支持,该模型的训练方式类似于InstructGPT。OpenAI使用RLHF训练该模型,通过让人工智能训练员进行对话,扮演用户和AI的角色,并将这些新的对话数据集与InstructGPT数据集混合,形成了适合聊天机器人的对话格式。其他主要的聊天机器人还包括微软的Bing Chat,它使用OpenAI的GPT-4(作为OpenAI和微软之间更广泛合作的一部分),以及竞争对手Google的Bard聊天机器人(最初基于他们的LaMDA系列对话训练语言模型,计划转换为PaLM)。
GPT还可以用于另一种元任务,即生成它自己的指令,如为“自己”开发一系列提示(),以实现人类用户给定的更一般目标。这被称为AI智能体,具体而言是递归性的,因为它利用前一次的自我指令结果来帮助形成后续的提示;这方面的一个重要例子是Auto-GPT(使用OpenAI的GPT模型),此外还有其他类似的模型被开发出来 。
多模态性
基于转换器的生成式系统还可以针对涉及文本以外的其他模态的任务进行定制。
例如,微软的“Visual ChatGPT”结合了ChatGPT与视觉基础模型(VFMs),使其能够处理包含图像和文本的输入或输出。此外,由于文本转语音技术的进步,当该技术与基础GPT语言模型结合使用时,可为音频内容的创作提供强大的工具。
领域特异性
GPT系统可以针对特定领域或行业。以下是一些报道中涉及的此类模型和应用示例:
- EinsteinGPT - 用于销售和营销领域,辅助客户关系管理(使用GPT-3.5)。
- BloombergGPT - 用于金融领域,帮助处理金融新闻和信息(使用“免费可用”的AI方法,结合其专有数据)。
- Khanmigo – 被描述为在教育领域中用于辅导的GPT版本,通过引导学生的学习过程而不是直接提供答案,来帮助他们在可汗學院上学习(由GPT-4提供支持)。
- SlackGPT - 用于Slack即时通讯服务,帮助导航和概括讨论内容(使用OpenAI的API)
- BioGPT – 由微软开发的,用于生物医学领域,帮助进行生物医学文献的文本生成和挖掘
- ProtGPT2 – 用于蛋白质研究
有时,领域特异性可以通过软件插件或附加组件实现。例如,几家公司已经开发了与OpenAI的ChatGPT接口直接交互的特定插件,Google Workspace也提供了可用的附加组件,如“GPT for Sheets and Docs”。据报道,该组件有助于Google試算表中電子試算表功能的使用。
品牌问题
OpenAI曾宣称“GPT”应该被视为OpenAI的品牌。在2023年4月,OpenAI在其服务条款中修改了品牌指南,指示其他企业在使用其API运行其人工智能(AI)服务时,将不再能够在名称或品牌中包含“GPT”。在2023年5月,OpenAI聘请了一个品牌管理服务,通知其API客户有关此政策的信息,尽管这些通知并未明确提出法律要求(比如指控商标侵权或要求停止并终止)。
此外,OpenAI已向美国专利及商标局(USPTO)申请在AI领域对“GPT”一词进行国内商标注册。OpenAI试图让其申请被加速处理,但专利及商标局于2023年4月拒绝了该请求。要获得商标批准,OpenAI需要证明该术语实际上在其特定产品中具有“显著性”,而不仅仅被广泛理解为描述类似技术的广泛技术术语。一些媒体报道暗示OpenAI或可间接基于其ChatGPT的知名度来实现这一点,对于ChatGPT,OpenAI已经单独寻求商标保护(并试图更严格地执行) 。其他报道表明,“GPT”一词似乎不太可能被授予独占权,因为它经常用于简单地指代涉及生成预训练转换器的AI系统。即使这种情况发生,商标上的描述性合理使用原则仍可能保留一些空间,使其能继续进行与品牌无关的使用。
部分出版物
以下为OpenAI和微软关于其GPT模型的主要官方出版物:
GPT-1:报告,GitHub发布
GPT-2:博客公告,关于“分阶段发布”决策的报告,GitHub发布
GPT-3:报告。此后没有GitHub或任何其他形式的代码发布
webGPT: 博客公告、报告
InstructGPT:博客公告、报告
ChatGPT:博客公告(无报告)
GPT-4:博客公告、报告、model card
參考資料
- ^ 冯志伟. . 中国科技术语. [2023-02-27]. (原始内容存档于2023-02-27) –微信公众平台.
- ^ Haddad, Mohammed. . www.aljazeera.com. [2023-07-20]. (原始内容存档于2023-07-05).
- ^ . World Economic Forum. [2023-07-20]. (原始内容存档于2023-04-25).
- ^ . Time. 2023-04-13.
- ^ Hu, Luhui. . Medium. 2022-11-15 [2023-07-20]. (原始内容存档于2023-06-05).
- ^ . www.computer.org. [2023-07-20]. (原始内容存档于2023-04-28).
- ^ . openai.com. 2018-06-11 [2023-03-18]. (原始内容存档于2023-03-18) (美国英语).
- ^ Toews, Rob. . Forbes. [2023-07-20]. (原始内容存档于2023-04-14).
- ^ Toews, Rob. . Forbes. [2023-07-20]. (原始内容存档于2023-04-14).
- ^ Mckendrick, Joe. . Forbes. 2023-03-13 [2023-07-20]. (原始内容存档于2023-04-16).
- ^ . MUO. 2023-04-11 [2023-07-20]. (原始内容存档于2023-04-15).
- ^ Alford, Anthony. . InfoQ. 2021-07-13 [2023-07-20]. (原始内容存档于2023-02-10).
- ^ (新闻稿).
- ^ Morrison, Ryan. . Tech Monitor. 2023-03-07 [2023-07-20]. (原始内容存档于2023-04-15).
- ^ . Forbes. [2023-07-20]. (原始内容存档于2023-04-06).
- ^ Hinton (et-al), Geoffrey. (PDF). IEEE Signal Processing Magazine. 2012-10-15,. Digital Object Identifier 10.1109/MSP.2012.2205597 [2023-07-22]. S2CID 206485943. doi:10.1109/MSP.2012.2205597. (原始内容存档 (PDF)于2023-03-18).
- ^ Deng, Li. . Apsipa Transactions on Signal and Information Processing (Cambridge.org). 2014-01-22, 3: e2 [2023-05-21]. S2CID 9928823. doi:10.1017/atsip.2013.9. (原始内容存档于2023-04-27).
- ^ Vaswani, Ashish; Shazeer, Noam; Parmar, Niki; Uszkoreit, Jakob; Jones, Llion; Gomez, Aidan N.; Kaiser, Lukasz; Polosukhin, Illia. . 2017-12-05. arXiv:1706.03762
 .
. - ^ Devlin, Jacob; Chang, Ming-Wei; Lee, Kenton; Toutanova, Kristina. . 2019-05-24. arXiv:1810.04805v2
 .
. - ^ Yang (et-al), Zhilin. (PDF). Proceedings from NeurIPS 2019. 2019 [2023-07-22]. (原始内容存档 (PDF)于2023-05-24).
- ^ Naik, Amit Raja. . Analytics India Magazine. 2021-09-23 [2023-07-22]. (原始内容存档于2023-06-10).
- ^ Radford, Alec; Narasimhan, Karthik; Salimans, Tim; Sutskever, Ilya. (PDF). OpenAI: 12. 2018-06-11 [2021-01-23]. (原始内容存档 (PDF)于2021-01-26).
- ^ Chen, Mark; Tworek, Jerry; Jun, Heewoo; Yuan, Qiming; Ponde de Oliveira Pinto, Henrique; Kaplan, Jared; Edwards, Harri; Burda, Yuri; Joseph, Nicholas; Brockman, Greg; Ray, Alex; Puri, Raul; Krueger, Gretchen; Petrov, Michael; Khlaaf, Heidy. . 2021-07-01 [2023-07-22]. arXiv:2107.03374
 . (原始内容存档于2023-06-24).
. (原始内容存档于2023-06-24). - ^ Ouyang, Long; Wu, Jeffrey; Jiang, Xu; Almeida, Diogo; Wainwright, Carroll; Mishkin, Pamela; Zhang, Chong; Agarwal, Sandhini; Slama, Katarina; Ray, Alex; Schulman, John; Hilton, Jacob; Kelton, Fraser; Miller, Luke; Simens, Maddie. . Advances in Neural Information Processing Systems. 2022-12-06, 35: 27730–27744 [2023-07-22]. arXiv:2203.02155
 . (原始内容存档于2023-06-28) (英语).
. (原始内容存档于2023-06-28) (英语). - ^ . openai.com. [2023-06-24]. (原始内容存档于2023-06-29) (美国英语).
- ^ Fu, Yao; Peng, Hao; Khot, Tushar. . Yao Fu's Notion. 2022 [2023-07-22]. (原始内容存档于2023-04-19).
- ^ . OpenAI API. [2023-06-23]. (原始内容存档于2023-06-23) (英语).
- ^ . Stanford HAI. [2023-07-22]. (原始内容存档于2023-06-04).
- ^ OpenAI. (PDF). 2023 [2023-03-16]. (原始内容存档 (PDF)于2023-03-14).
- ^ Zhu, Yukun; Kiros, Ryan; Zemel, Rich; Salakhutdinov, Ruslan; Urtasun, Raquel; Torralba, Antonio; Fidler, Sanja. . IEEE International Conference on Computer Vision (ICCV) 2015: 19–27. 2015 [2023-02-07]. arXiv:1506.06724
 . (原始内容存档于2023-02-05).
. (原始内容存档于2023-02-05). - ^ . Epoch. [2023-05-02]. (原始内容存档于2023-07-16) (英语).
- ^ Vincent, James. . The Verge. 2019-11-07 [2023-07-22]. (原始内容存档于2020-06-11).
- ^ Brown, Tom B.; Mann, Benjamin; Ryder, Nick; Subbiah, Melanie; Kaplan, Jared; Dhariwal, Prafulla; Neelakantan, Arvind; Shyam, Pranav; Sastry, Girish; Askell, Amanda; Agarwal, Sandhini; Herbert-Voss, Ariel; Krueger, Gretchen; Henighan, Tom; Child, Rewon; Ramesh, Aditya; Ziegler, Daniel M.; Wu, Jeffrey; Winter, Clemens; Hesse, Christopher; Chen, Mark; Sigler, Eric; Litwin, Mateusz; Gray, Scott; Chess, Benjamin; Clark, Jack; Berner, Christopher; McCandlish, Sam; Radford, Alec; Sutskever, Ilya; Amodei, Dario. . 2020-05-28. arXiv:2005.14165v4
 .
. - ^ Ver Meer, Dave. . NamePepper. 2023-06-01 [2023-06-09]. (原始内容存档于2023-06-05) (英语).
- ^ Vincent, James. . The Verge. 2023-03-14 [2023-07-22]. (原始内容存档于2023-03-14).
- ^ . [2023-07-22]. (原始内容存档于2023-05-31).
- ^ Iyer, Aparna. . Analytics India Magazine. 2022-11-30 [2023-07-22]. (原始内容存档于2023-06-02).
- ^ . PCMAG. [2023-07-22]. (原始内容存档于2023-07-19).
- ^ Islam, Arham. . 2023-03-27 [2023-07-22]. (原始内容存档于2023-05-15).
- ^ Islam, Arham. . 2022-11-14 [2023-07-22]. (原始内容存档于2023-07-18).
- ^ Saha, Shritama. . Analytics India Magazine. 2023-01-04 [2023-07-22]. (原始内容存档于2023-05-15).
- ^ Wu (et-al), Chenfei. . 2023-03-08. arXiv:2303.04671
 [cs.CV].
[cs.CV]. - ^ Bommasani (et-al), Rishi. . 2022-07-12. arXiv:2108.07258
 [cs.LG].
[cs.LG]. - ^ . crfm.stanford.edu. [2023-07-22]. (原始内容存档于2023-04-06).
- ^ . Databricks. 2023-04-12 [2023-07-22]. (原始内容存档于2023-07-14).
- ^ . openai.com. [2023-03-16]. (原始内容存档于2023-03-16) (美国英语).
- ^ . CNET. [2023-07-22]. (原始内容存档于2023-07-24).
- ^ . Mashable. 2023-04-19 [2023-07-22]. (原始内容存档于2023-07-22).
- ^ Marr, Bernard. . Forbes. [2023-07-22]. (原始内容存档于2023-05-21).
- ^ . InfoQ. [2023-07-22]. (原始内容存档于2023-06-03).
- ^ Edwards, Benj. . Ars Technica. 2023-01-09 [2023-07-22]. (原始内容存档于2023-07-18).
- ^ Morrison, Ryan. . 2023-03-07 [2023-07-20]. (原始内容存档于2023-04-15).
- ^ Leswing, Kif. . CNBC. 2023-04-13 [2023-07-22]. (原始内容存档于2023-05-19).
- ^ . Fast Company. 2023-05-04 [2023-05-22]. (原始内容存档于2023-05-11).
- ^ . THE Journal. [2023-07-22]. (原始内容存档于2023-05-07).
- ^ Hachman, Mark. . PCWorld. 2023-05-04 [2023-07-22]. (原始内容存档于2023-06-09).
- ^ Matthias Bastian. . The Decoder. 2023-01-29 [2023-02-27]. (原始内容存档于2023-02-07).
- ^ Luo R, Sun L, Xia Y, Qin T, Zhang S, Poon H; et al. . Brief Bioinform. 2022, 23 (6) [2023-02-27]. PMID 36156661. doi:10.1093/bib/bbac409. (原始内容存档于2023-07-27).
- ^ Ferruz, N., Schmidt, S. & Höcker, B.; et al. . Nature Communications volume. 2022, 13 [2023-02-27]. doi:10.1038/s41467-022-32007-7. (原始内容存档于2023-02-08).
- ^ . 2023-05-05 [2023-07-22]. (原始内容存档于2023-05-09).
- ^ . openai.com. [2023-07-22]. (原始内容存档于2023-03-23).
- ^ . MUO. 2023-03-12 [2023-07-22]. (原始内容存档于2023-06-19).
- ^ Asay, Matt. . InfoWorld. 2023-02-27 [2023-07-22]. (原始内容存档于2023-06-02).
- ^ Hicks, William. . The Business Journals. 2023-05-10 [2023-05-21]. (原始内容存档于2023-06-28).
- ^ OpenAI. . 2023-04-24 [2023-05-21]. (原始内容存档于2023-07-18).
- ^ Heah, Alexa. . DesignTAXI. 2023-04-26 [2023-05-21]. (原始内容存档于2023-04-26).
- ^ 25 April 2023, 08:04 am. . Tech Times. 2023-04-25 [2023-05-21]. (原始内容存档于2023-04-25).
- ^ . [2023-05-21]. (原始内容存档于2023-06-05) (美国英语).
- ^ Demcak, Tramatm-Igor. . Lexology. 2023-04-26 [2023-05-22]. (原始内容存档于2023-05-05) (英语).
- ^ Lawton, George. . Enterprise AI. 2023-04-20 [2023-05-21]. (原始内容存档于2023-05-09) (英语).
- ^ Robb, Drew. . eWEEK. 2023-04-12 [2023-05-21]. (原始内容存档于2023-07-27) (美国英语).
- ^ Rheintgen, Husch Blackwell LLP-Kathleen A. . Lexology. 2013-08-16 [2023-05-21]. (原始内容存档于2023-05-21) (英语).
- ^ . OpenAI. 2018-06-11 [2023-05-01]. (原始内容存档于2023-05-19).
- ^ . openai.com. [2023-05-01]. (原始内容存档于2023-03-31) (美国英语).
- ^ Solaiman, Irene; Brundage, Miles; Clark, Jack; Askell, Amanda; Herbert-Voss, Ariel; Wu, Jeff; Radford, Alec; Krueger, Gretchen; Kim, Jong Wook; Kreps, Sarah; McCain, Miles; Newhouse, Alex; Blazakis, Jason; McGuffie, Kris; Wang, Jasmine. . 2019-11-12. arXiv:1908.09203
 [cs.CL].
[cs.CL]. - ^ . OpenAI. 2023-05-01 [2023-05-01]. (原始内容存档于2023-03-11).
- ^ . openai.com. [2023-07-02]. (原始内容存档于2023-06-21) (美国英语).
- ^ Nakano, Reiichiro; Hilton, Jacob; Balaji, Suchir; Wu, Jeff; Ouyang, Long; Kim, Christina; Hesse, Christopher; Jain, Shantanu; Kosaraju, Vineet; Saunders, William; Jiang, Xu; Cobbe, Karl; Eloundou, Tyna; Krueger, Gretchen; Button, Kevin. . 2021-12-01 [2023-07-22]. (原始内容存档于2023-07-02).
- ^ . openai.com. [2023-03-23]. (原始内容存档于2023-03-23).
- ^ Ouyang, Long; Wu, Jeff; Jiang, Xu; et al. . 2022-03-04. arXiv:2203.02155
 .
. - ^ . openai.com. [2023-05-01]. (原始内容存档于2023-03-14) (美国英语).
- ^ OpenAI. . 2023-03-27. arXiv:2303.08774
 [cs.CL].
[cs.CL]. - ^ Bubeck, Sébastien; Chandrasekaran, Varun; Eldan, Ronen; Gehrke, Johannes; Horvitz, Eric; Kamar, Ece; Lee, Peter; Lee, Yin Tat; Li, Yuanzhi; Lundberg, Scott; Nori, Harsha; Palangi, Hamid; Ribeiro, Marco Tulio; Zhang, Yi. . 2023-04-13. arXiv:2303.12712
 [cs.CL].
[cs.CL]. - ^ (PDF). OpenAI. 2023-03-23 [2023-05-22]. (原始内容存档 (PDF)于2023-04-07) (美国英语).
This article is issued from Wikipedia. The text is licensed under Creative Commons - Attribution - Sharealike. Additional terms may apply for the media files.
- ///
/// 文件转换成文件流/// /// [详细] -->赞
踩

