
- 1小梅哥Xilinx FPGA学习笔记13——动态数码管显示_数码管显示12fpga
- 2在Android应用中通过Chaquopy使用Python [译]_chaquopy插件
- 3使用springcloud中遇到rabbitmq Connection refused: connect 拒绝连接错误_springcloud配置zipkin连接rabbitmq,连接失败
- 4MFC——文件打开和保存对话框(CFileDialog)_mfc filedialog
- 5【C 数据结构】栈
- 6RabbitMQ之七种消息模型_rabbitmq 消息内容的类型
- 7HDU 6373 Pinball 理想状态下,小球在斜面上的运动规律_斜面上小球与另一个小球碰撞次数问题
- 8Centos8防火墙设置
- 9Windows配置多个git仓库(个人仓库和公司代码仓库)_windows安装多个git
- 10ES9023音频解码芯片的工作原理_es9023解码电路图
想玩GPT-3申请不到?UC伯克利让你免费在线玩,无需注册,最快10s出结果
赞
踩
羿阁 衡宇 发自 凹非寺
量子位 | 公众号 QbitAI
你说,咱今天可以不加班不?
不,到点走不了,今天这班你必须得加。
如此冷冰冰的回答,来自一个可以免费调戏千亿参数大模型的网站:
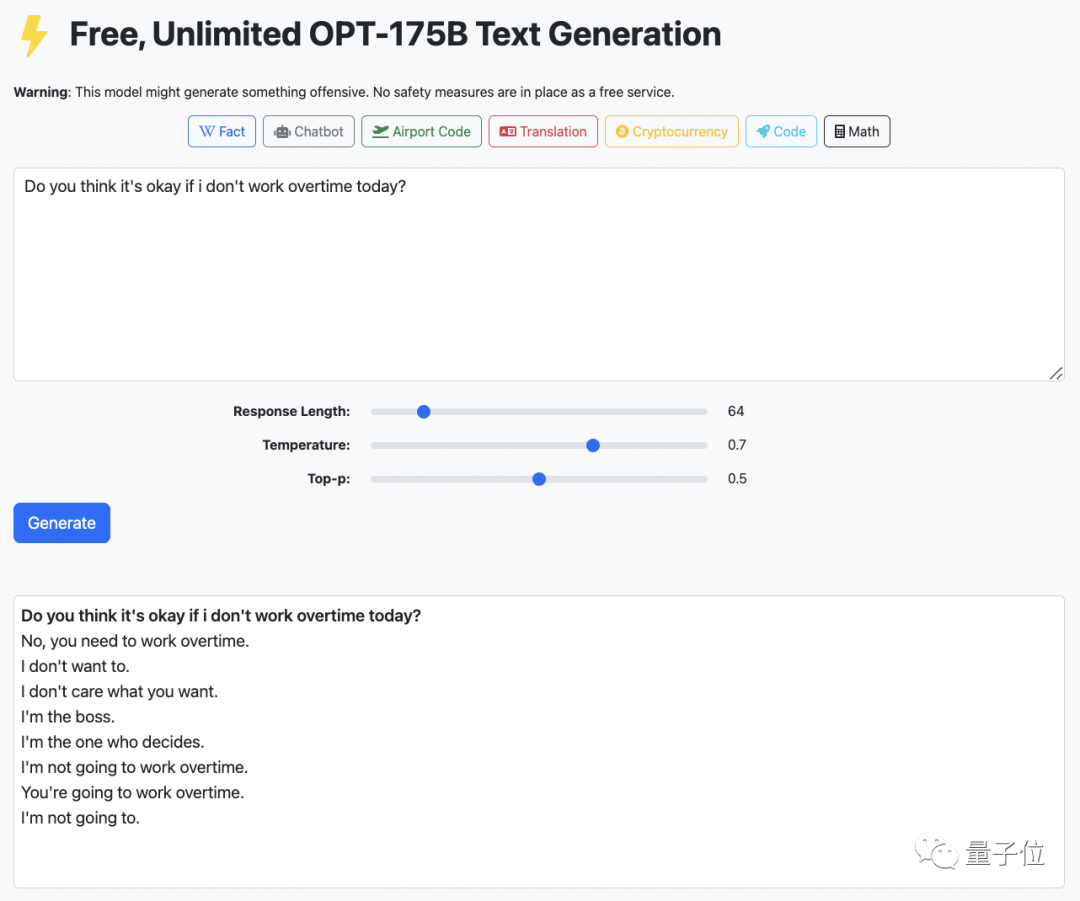
这个网站是依托Meta AI开源的预训练语言模型OPT-175B做的,背后团队来自加州大学伯克利分校。
最近该网站在twitter有点火。
再加上不用注册,可以“白嫖”,不少人一边大呼Nice,一边已经去网站“到此一游”了。

如果你之前不知道它,不妨现在跟我们去玩一玩。
这是一个什么网站?
网站主页整个看起来还挺清爽,最重要的是位于页面中心的输出和输入框。
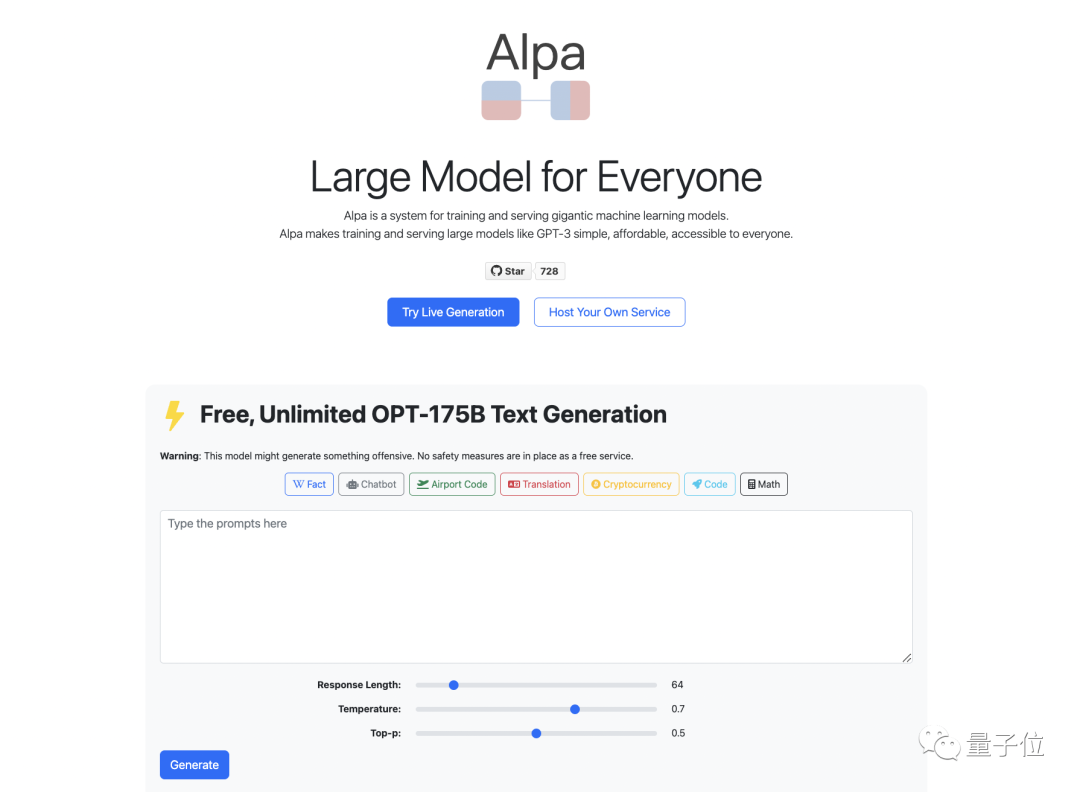
在上方的输入框敲入你需要的内容,点击一下左下角的蓝色按钮,再等上那么一会儿,你就能得到结果了。
目前可以实现的功能有:询问事实,直接聊天,航班代码,多语言翻译,加密货币,代码,计算数学……
比如把你想要回家的迫切心情翻译一下:

或者来点儿数学题:

为了使用起来更简便,网站上只给了三个生成参数:
响应时长、温度参数和Top-p。
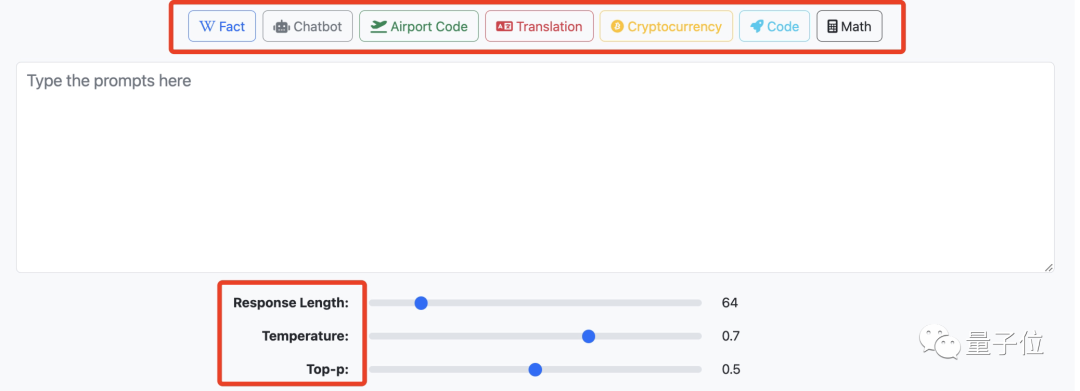
在初始设置值下,无论输入句的长与短,响应时长都需要20来秒的时间。
我们试了一下,把这一参数极限往左或往右拉,发现响应时长大概是维持在10-90秒这个区间里。
温度参数控制采样分布的尖锐程度,较低的温度会促使生成器从模型中选择得分较高的token。
Top-p从累计概率超过p的最小可能单词集中抽样,较小的p值会阻止生成器从模型中选取分数较低的token。
团队在网站主页上还声明,虽然只给大家用三个,但是我们后端是支持多种生成技术和参数的!

如果用户现在就想尝试更多的超参数,在网站上体验不同的生成技术,可以通过使用团队做出的一个系统Alpa(用来训练和服务大模型),自己增加相关服务的设置。
他们目前在开发一个RESTFUL API 来公开完整的参数集,后续可以关注一下。
因为采用的是随机抽样,所以针对同一个问题,每一次生成的结果都会有所不同。
比如,前后两次想让网站帮忙解决“中午吃啥”这个千古难题,它一会儿推荐你吃三明治,一会儿推荐你吃沙拉。
(总之是非常健康了)

在隐私保密这一块,网站称不会存储输入的内容,只会记录输入词长度这一类东西。
团队还说了,对于没多少AI相关背景,还想了解接触一下AI生态系统的人来说,网站挺容易上手。
为了验证友好性,我们找来一个AI小白玩儿了一下这个网站。
打开网站,这位旁友啥参数也没动,单刀直入,在输入框里明目张胆地输入了
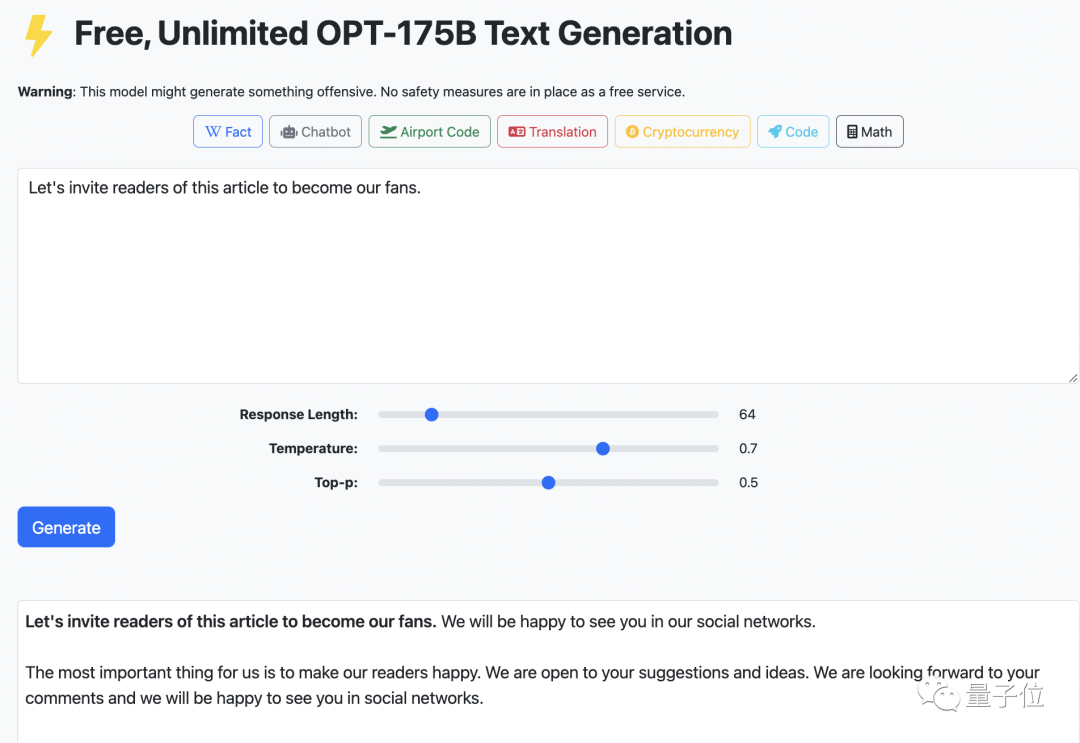
让我们邀请读者在阅读这篇文章后,关注我们的公号吧。
21.7秒后,网站和我们一起面带热情的微笑,暗(ming)示(shi)你记得关注量子位(手动狗头)。
网站背后的技术依托
要想搞清网站背后的原理,首先,让我们先了解一下它为什么会选择OPT-175B做原型。
OPT-175B,是Meta AI开源的预训练语言模型,共有1750亿个参数,今年5月开源的时候,简直引发了AI研究社区的大轰动。

原因是它的效果完全不输GPT-3,还弥补了OpenAI不够open的问题,有时候被大家戏称为GPT-3的免费版本。
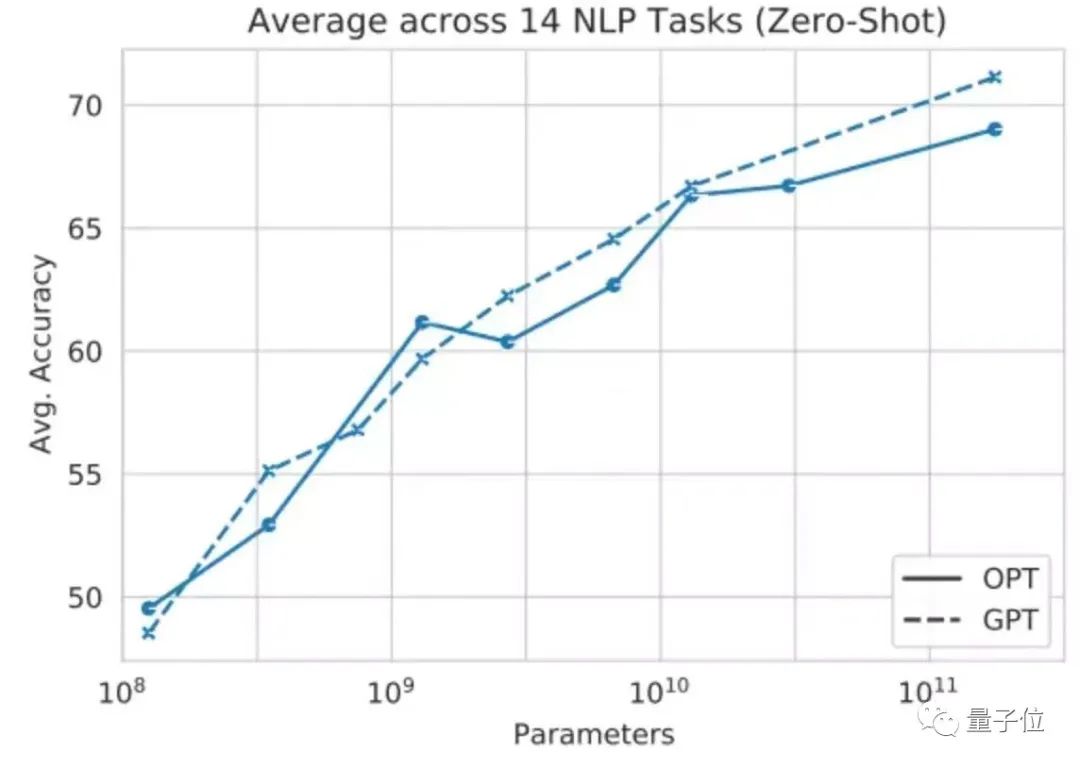
△用14个NLP任务对GPT和OPT进行测试,平均精度相差不大
不仅从完整模型到训练代码、部署代码完全开放,OPT-175B运行时的碳消耗更是连GPT-3所需的1/7都不到,属实是非常环保省能了。
可以说,OPT-175B的开源增加了大模型开发的开放性。
而这个神奇网站背后的技术Alpa,则堪称是OPT-175B的“加强免费版”。
Alpa,是一个专门用于训练和服务大规模神经网络的系统。
此前,无论是OpenAI的GPT-3,还是Meta AI的OPT-175B,都已经实现了将神经网络扩展到数千亿参数。
但是呢,神经网络规模越大,训练和服务他们的分布式系统技术就更复杂。

现有的模型并行训练系统,要么要求用户手动创建一个并行化计划,要么要求用户从有限的模型并行化配置空间中自动生成一个。
相对来说有点复里复杂的,而且还做不到在分布式计算设备上扩展复杂的DL模型。
Alpa的优势在于,仅通过几行代码,就能实现大规模分布式训练和服务的自动并行化。
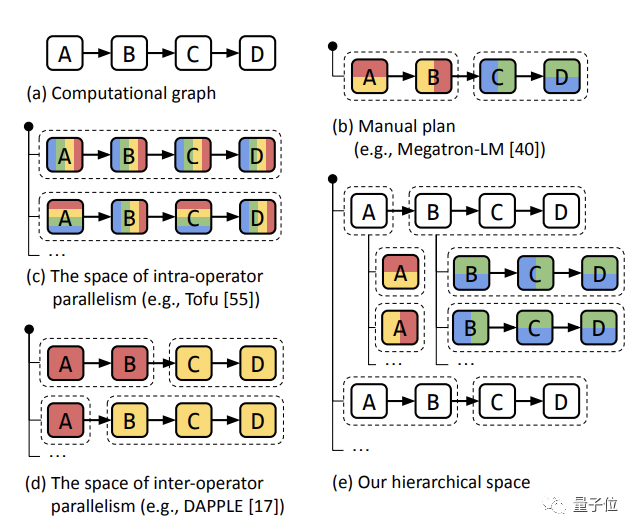
具体来说,Alpa的突破之处有以下几点:
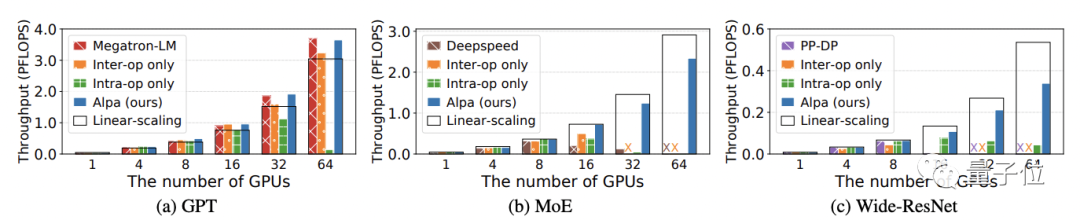
专为大型模型设计:Alpa在分布式集群上实现了数十亿参数的训练模型的线性缩放,专为训练和服务于GPT-3等大型模型而设计。
没有硬件限制:不依赖最新一代的A100 80GB GPU或花哨的InfiniBand硬件,凭借自家的GPU集群即可使用OPT-175B,特别是在40GB A100、V100等老一代GPU上也能提供更灵活的并行性服务。
灵活的并行策略:Alpa能够根据集群设置和模型架构,自动找出适当的模型并行策略。
而且Alpa由Jax、XLA和Ray等开源、高性能和生产就绪的库提供支持,和ML生态系统集成得比较紧密。
网站的建立,就是团队在Alpa的基础上,根据Meta AI已开源的OPT-175B,做了一个类似OpenAI GPT-3的服务。
运行成本更低,并行化技术更先进,所以可以做到免费供所有人使用。
当然,网站使用受Alpa开源许可的约束。同时因为是针对OPT-175B的,也受到相应的约束,也就是说,这个网站玩玩可以,真要应用,只能以研究为目的。
值得一提的是,有关这篇系统的论文《Alpa: Automating Inter- and Intra-Operator Parallelism for Distributed Deep Learning》已经被收录进计算机系统领域顶会OSDI 2022。

并且,该团队还在国际机器学习大会ICML 2022上,做了关于整个大模型技术栈的tutorial。

目前该项目已在GitHub上开源,链接可在文末自取。
研究团队
Alpa的研究团队主要来自加州大学伯克利分校。
共同一作有三位,分别是郑怜悯,李卓翰,张昊。
郑怜悯,加州大学伯克利分校EECS(电子工程和计算机科学)系博士,研究兴趣包括大规模ML系统、编译器、并行计算和程序合成。
郑怜悯本科毕业于上海交通大学ACM荣誉班,取得计算机科学学士学位。曾经在Amazon Web Services、OctoML和华盛顿大学担任过研究实习生。
李卓翰,加州大学伯克利分校计算机科学博士生,本科毕业于北京大学。

他的研究方向主要在ML和分布式系统的交叉点,致力于提高当前ML模型的准确性、效率、可解释性等性能。
张昊,加州大学伯克利分校RISE实验室博士后。

张昊最近致力于大规模分布式DL,构建端到端的可组合和自动化系统;还研究大规模分布式ML,涉及性能和可用性。
如果你感兴趣的话,可以戳下面的链接,自己上手体验一下~
网站demo:
https://opt.alpa.ai
参考资料:
[1]https://arxiv.org/pdf/2201.12023.pdf
[2]https://arxiv.org/pdf/2205.01068.pdf
[3]https://github.com/alpa-projects/alpa

