
- 1spark groupByKey().mapValues
- 2低代码平台:IVX 重新定义编程_ivx前端导出react代码
- 3dvwa靶场Brute Force(暴力破解)全难度教程(附代码分析)_dvwa靶机使用指南下载
- 4Apache Kafka - 构建数据管道 Kafka Connect
- 5瑞吉外卖(部署维护篇)_瑞吉外卖的sh脚本如何修改
- 6【MySQL】数据的导入导出及.sql文件执行_导出数据库脚本的命令
- 7蚁群算法路径规划
- 8WebRTC源码研究(23)WebRTC网络传输基本知识_esp32 webrtc
- 92020微信支付v3版本java对接详细流程_platformcertpath
- 10Android 子线程与主线程间的通信_android 主线程传数据给子线程
机器学习在信贷风控建模中的优势和挑战
赞
踩
今天,你AI了没?
关注:决策智能与机器学习,学点AI干货
在国内国外金融风控领域大致分为两个流派,其中一派为具有统计学背景的人,分布在银行、金融消费公司等传统的金融领域,偏好评分卡进行建模。另外一派则是具有互联网背景的新兴探索者,将机器学习、深度学习等方法运用于金融风控领域。融360是 ToB 的金融风控企业,不仅跟传统的金融公司有合作,还和京东、百度金融、滴滴等互联网背景的公司有交集。本次演讲内容为这两种流派优劣势对比及机器学习、深度学习在金融风控领域的实践应用。
一、信用评分卡模型
评分卡模型虽然是一个简单的权重线性加和的回归模型,但在传统金融风控领域使用了上百年。

1、评分卡模型中的特征筛选、参数求解
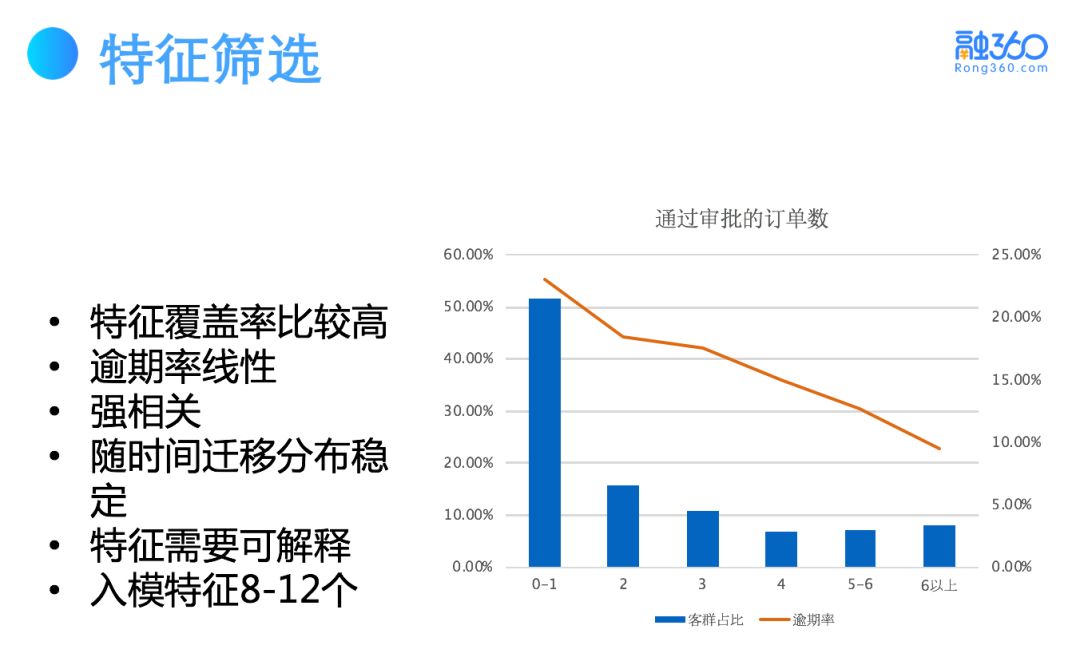
评分卡模型对特征筛选有以下偏好:
1)特征覆盖率高,通常达到70%以上;
2)特征与逾期率为线性强相关;
3)特征随着时间迁移,其分布保持稳定;
4)特征变量与风险趋势的相关性有明显的可解释性,并且入模变量少,通常为8-12个。
以上特征筛选的偏好是为了保证入模的特征变量的稳定性、有效性,比如会有黑名单、负债、资产等特征变量。总的来说,在少样本量及强特征的情况下,使用评分卡这种简单的模型能够很好的保证稳定性和有效性。
关于参数求解,在机器学习中通常设定损失函数,将其转化为凸问题,再进行求解。但是在评分卡模型中,若行业样本非常稀缺,对参数训练收敛有一定的困难。若当前样本量为0,可根据专家的历史经验进行权重设定。若当前样本为几百个,可根据单特征区分能力比如 KS / IV 值等进行权重设定。
2、评分卡模型的非线性 / 交叉特征处理
线性回归模型有一定的劣势,比如不能解决非线性相关特征及交叉特征的问题。
2.1 非线性特征处理 — woe / 分桶
对于非线性特征线性化有 woe 处理和分桶两种方式。
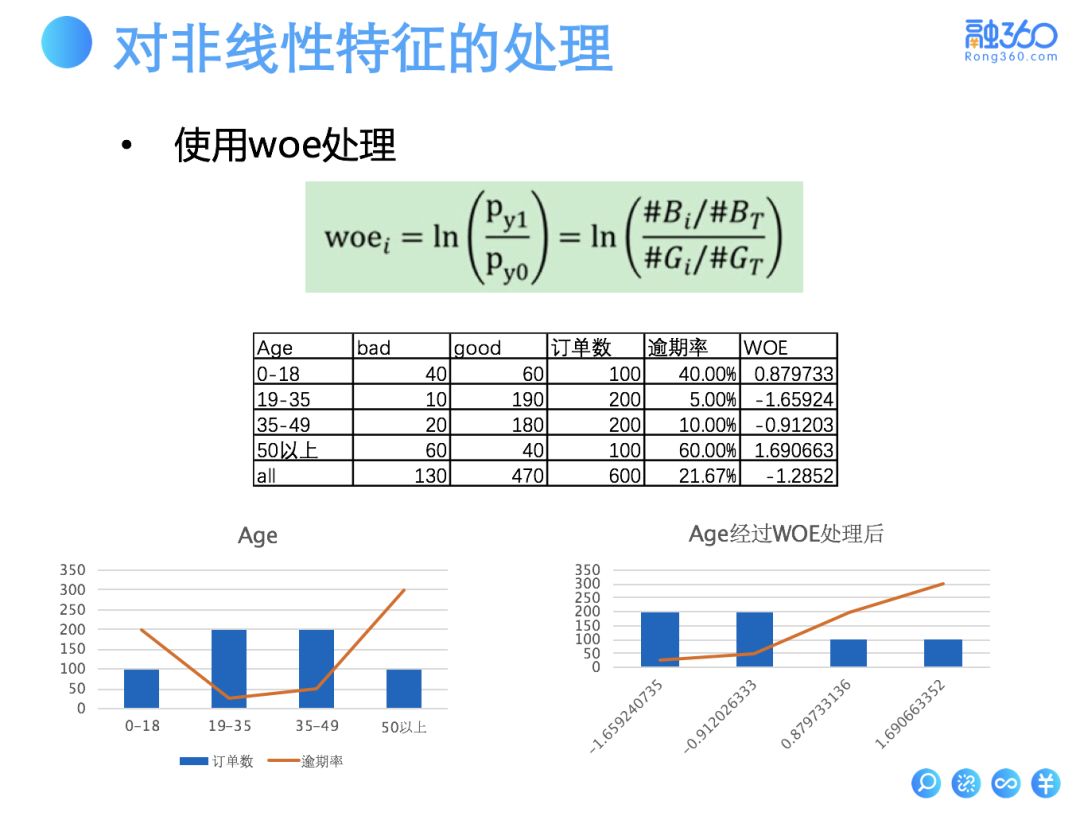
1)左图中年龄与逾期率呈非线性相关性,对年龄特征做 woe 特征变换后,在右图中年龄与逾期率呈现了一定的线性相关性。再将变换后的年龄特征带入线性回归模型,就能比较好地体现和刻画年龄特征的价值。
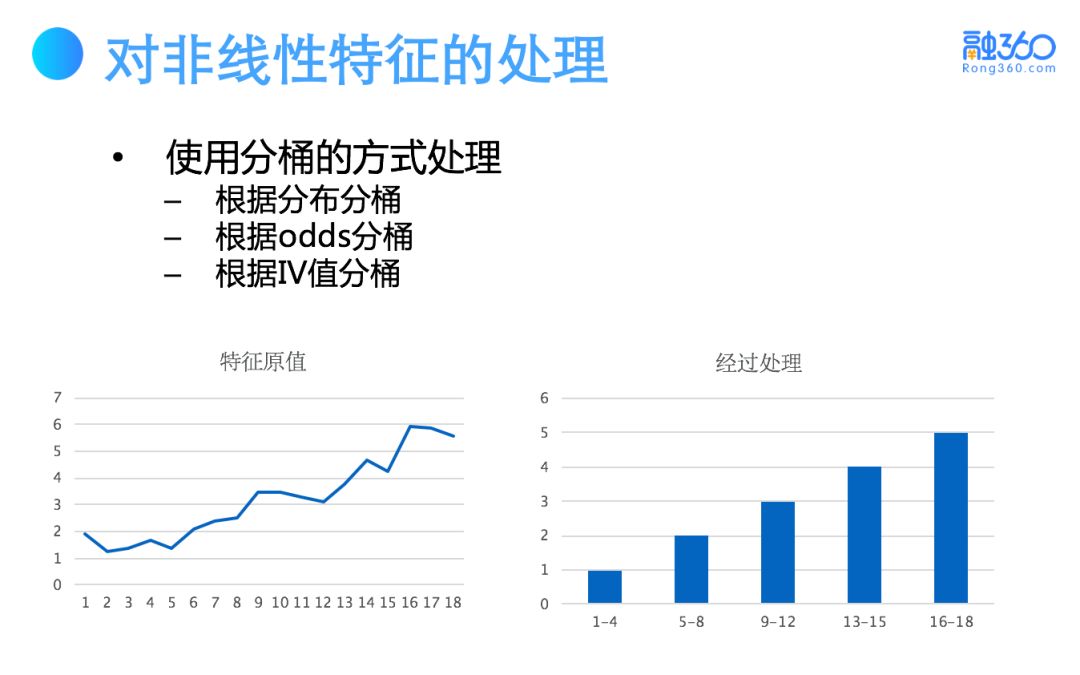
2)对有一定跳变的连续值特征进行分桶,其优势在于弱线性特征转化为强线性特征,并且可以增加模型的鲁棒性。
2.2 交叉特征处理 — 分群
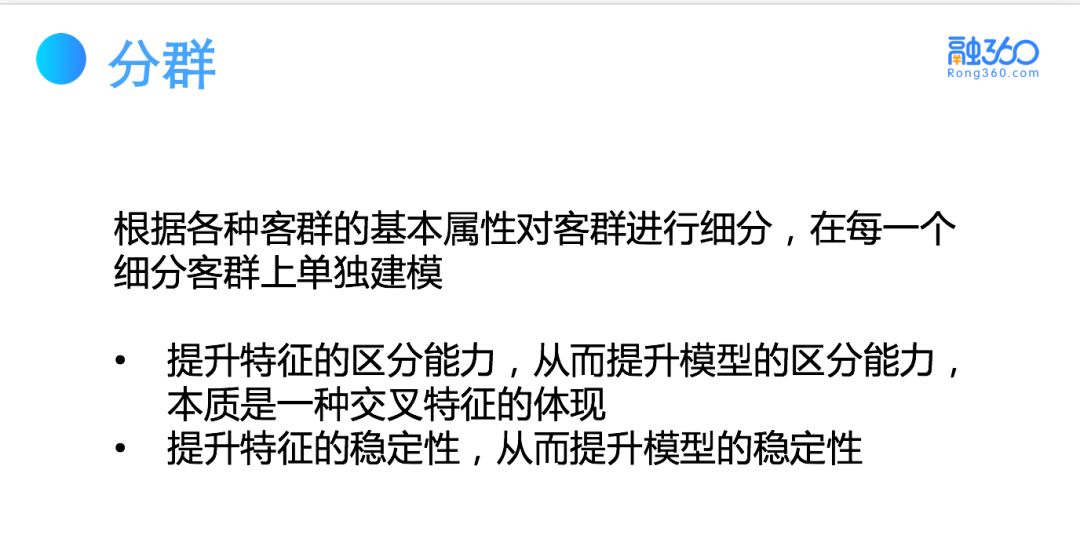
对于交叉特征的问题,可使用客户分群的方式。根据基本客群的基本属性划分,比如是否有征信,是否为 VIP 等基本属性划分,再对细分客群进行单独建模,拟合风险。以上在一定程度上相当于做了交叉特征,该过程类似于决策树的建立,根据经验和业务指标建立决策树,将人群的划分作为不同的叶子节点。
最后,结合以上特征处理的技巧,在小样本量上进行线性回归就可以得到稳定且区分度高的模型。
3、总结

评分卡模型的优势有稳定、高可解释性、可实现冷启动以及快速适应市场变化。其中冷启动优势的表现在于不论初始样本量的多少就能快速建模。其劣势为特征要求强相关,且非常依赖建模的个人经验,挖掘的信息价值相对有限。
二、机器学习的出现
随着机器学习的出现,传统金融逐渐向互联网金融转变。
1、传统金融和互联网金融的差异及新要求

传统金融的订单数少、订单金额高、贷款期限长、客群资质好、风控预算高。互联网金融订单数多、订单金额低、贷款期限短、客群资质差、风控预算低。风控的预算高低主要体现在订单金额的高低和期限的长短,其共同决定了贷款利率的高低。每一笔订单金额越高、期限越长,每一笔收获的利息越高,即风控预算越高。
针对互联网金融独有的特性,对风控提出了新的要求。
1)目前具有央行征信的个体覆盖占全国的50%左右,对于剩下50%客群资质较差的个体,央行征信的风控系统无法进行覆盖。互联网金融的服务客群就是这剩下的50%。所以要使得互联网金融信贷用户下沉,就得要求风控模型覆盖的人群更广,准确地说覆盖大量传统风控不能评估的个体。
2)互联网金融借贷的期限短,模型要求有较短预测有效期。
3)互联网金融风控成本低,要求风控数据价格低。
2、金融风控数据
基于以上风控的新要求,对风控数据进行如下整体分析。
数据是根本,建模方法要根据数据进行不断地调整。将风控数据分为四部分,资质数据、信贷数据、消费数据、行为数据。其与逾期率的相关性从前往后逐渐减弱。
1)资质类数据包括该个体是否有房车、教育程度、工资水平等个人属性相关的数据;
2)信贷类数据包括历史的借贷额度、借贷次数、还款情况、是否逾期等借贷相关的数据;
3)消费数据包括在电商平台的消费记录等流水相关的数据;
4)行为数据包括个体之间的联系、手机 App 的使用列表、手机型号、浏览内容类别等个人行为数据。
互联网金融中资质较差的客群基本没有资质数据以及合规的信贷数据,虽然有一定的消费数据但是该类数据大多掌握在巨头电商平台手中,所以所能获取到的就是开放度高的互联网行为类数据。行为类数据的优势为覆盖广、成本低,缺陷为相关性弱、变化快。

3、机器学习的优势及问题
互联网金融的数据特征相关性弱,那么要求模型的挖掘能力要强,所以机器学习的重要性就显现出来了。
机器学习有以下优势:

1)特征的拟合能力更强,对非线性和交叉特征有更好的能力;
2)能够基于不同的基础模型融合得到拟合更强和更稳的模型,比如 rf / gbdt / xgboost / lightGBM 。本质上,提高了模型的复杂度,模型对固定 pattern 的识别能力增强。总的来说,机器学习能从海量的、贫瘠的数据中挖掘出数据的价值。
机器学习在商业上应用比较成功的领域有广告、推荐等,但是与信贷领域有较大的差异:

1)样本量级不同,广告推荐亿级近期样本,信贷风控只有百万级历史样本;
2)预测时间不同,广告推荐实时预测,信贷风控是未来长周期的预测;
3)模型更迭周期不同,广告推荐能短时间内进行模型更迭,能捕获到短时间内的样本特征回馈。信贷风控模型具有滞后性,样本回馈需要较长的周期,建模的训练数据与预测数据存在着较大的时间跨度;
4)泛化能力不同,广告推荐面向的客群比较特定,信贷风控模型需要适用于广泛的客群和场景。
想要在信贷风控的场景成功地利用机器学习,必须要做一些迁移和适应。
三、机器学习技术的突围
在信贷风控领域关于机器学习技术的探索主要分为三个方向。
第一个方向,既然构造复杂模型存在着不稳定的风险,最稳妥的方式为使用机器学习 / 人工智能增加新特征,再使用评分卡模型。
第二个方向为传统风控为体,机器学习为用。即特征筛选的标准和规则仍不变,仅替换评分卡模型为复杂模型比如 xgboost 等。
第三个方向为大规模样本结合机器学习,保证模型的稳定和泛化。

1、使用机器学习 / 人工智能加工特征、风控为体-机器学习为用
关于机器学习 / 人工智能加工特征,做了以下的实践尝试。
1.1 社交关系图 / 知识图谱
将用户看为一个点,用户之间的联系为边。基于图结构构造特征,比如图的出 / 入度 ,度中黑名单的个数,黑用户 randomwalk 将度权重传导至相邻的边等衍生特征。
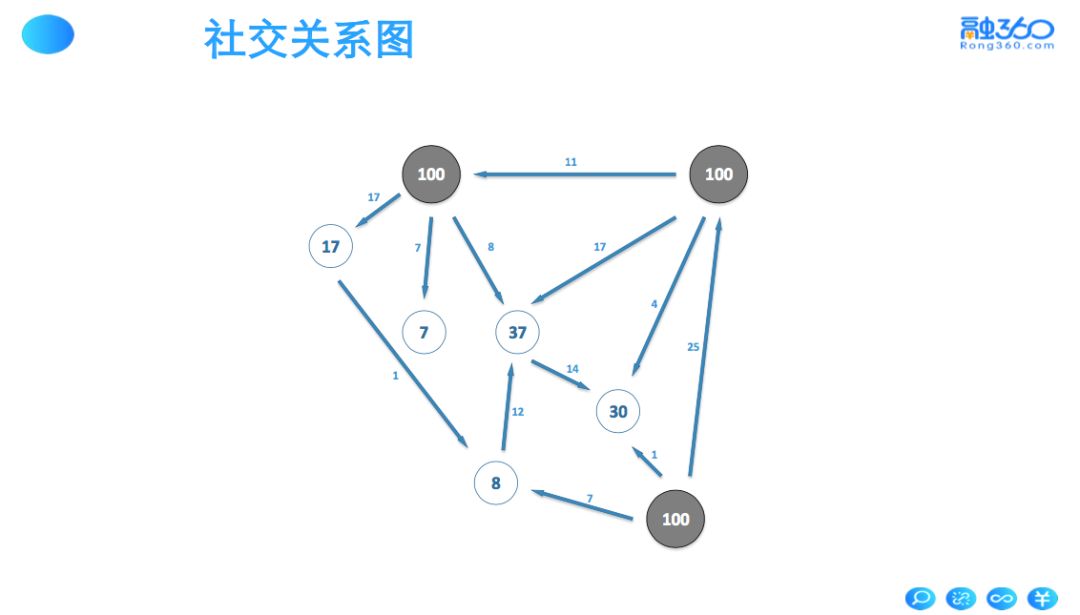
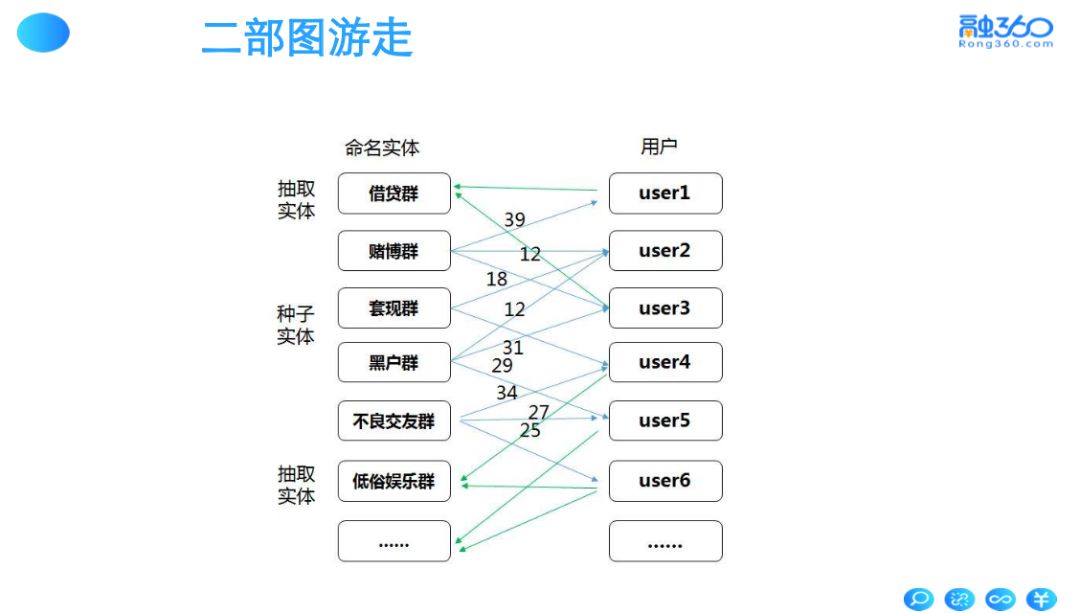
1.2 二部图游走
以下为通过二部图来衍生特征,首先建立用户与实体的二部图,实体可以为 QQ 群,App ,浏览链接等等。用户与实体特性相关则连接一条权重边,将有反面特性的实体作为种子实体,向用户侧游走,用户侧又向实体侧游走,直到游走平衡进入稳态可以得到稳定的权重。将稳定的权重作为特征,来标识反面特性的程度。
1.3 word2vec
word2vec 主要应用于 NLP 领域,在风控领域中的运用鲜少。目前该方法应用于页面埋点动作的特征提取,将点击和浏览动作看作词,用户完整周期内的所有动作行为组成了段落和文章,再使用 word2vec 方法,将用户的点击浏览行为隐含表征为一定维度的向量,再将向量作为用户的特征输入 xgboost 进行建模,单个特征有1-2个 ks 点的提升,效果还是不错的。
1.4 订单序列模型
用时序的模型如 LSTM 处理用户某一个订单的相关特征,如期限、金额、时间、到期账单等,其中一个订单表示一个时序事件,用户生命周期所有订单构成完整的时序链。将历史用户周期内的订单特征灌入 LSTM 得到 ( 1 , N ) 维特征,再将这些特征输入 LR 模型进行训练。该模型对于跨时间不是太稳定,但是相较之前还是有较大的提升,后续还需要持续优化。
2、模型和数据的减压、模型监控
以传统的风控为体,机器学习为用的方式,虽然使用了机器学习方法但还是向传统靠拢。该方式强化了人工干预和信息抽象,弱化模型的复杂度和数据,以此来提升模型特征的信息含量和稳定。比如以高要求 ( 高 IV 低 PSI ) 筛选入模特征,或者 LDA 文本主题词浓缩大量文本信息等方式来给模型减压。

为了保证模型的稳定性,可加强对模型的监控即加强数据和特征的分布及中间结果的监控。同时可加快模型的更新效率,建设模型自动重训练机制。

以传统风控为体,机器学习为用的方式能够使得模型构建过程更加透明,特征构建更加灵活。也就是机器学习技术仅仅用于新特征的挖掘,最终仍以高要求筛选特征,入模评分卡。

3、大规模机器学习
在去年9月份开始尝试大规模机器学习模型 — XGB-LR / deepFM / Deep&wide ,大规模机器学习有以下要求:
1)百万级别的样本。对样本的一致性要求不是很高,可将时间跨度大的订单样本作为输入。
2)数万维的特征,数十万参数的模型。大容量模型意味着多参数,多特征。其中输入特征为所有特征,即不经过高要求 ( 高 IV 低 PSI ) 筛选入模。其主要风险点为线下线上模型效果差异大,即线下建模效果佳,完全拟合了线下分布,但是上线后可能由于过拟合等原因导致效果不佳。所以到目前为止,该模型一直处于线下陪跑测试阶段,监控其稳定性。
传统风控为体-机器学习为用方式建模的模型效果,对比大规模机器学习的模型效果,大部分时间内,其效果要优于传统风控为体-机器学习为用方式,并且有一定的稳定性。
4、总结

在个人技术成长的角度有以下总结:
1)机器学习技术在信贷风控领域远不如广告推荐、语音图像、自然语言等领域成熟,成长期大概在5-6年,还有非常多的机器学习的点值得探索。
2)在引入新技术同时需要参考应用场景,比如新技术在广告领域 auc 达到了0.99等,但是在风控领域其实不然。所以需要充分考虑风控领域的特性,将机器学习的优势迁移过来。
3)机器学习技术在信贷风控领域还有广阔的发展空间和前景。
嘉宾介绍:

罗灿,融360天机业务风控模型部负责人。北京大学计算机系硕士研究生,曾服务于百度网盟广告模型部、微软亚洲研究院计算广告组,在机器学习技术和应用上积累丰富。2016年加入融360天机负责风控模型搭建,一直致力于将机器学习技术应用于风控建模,颇有心得。
文章推荐
干货 | 深度强化学习国际顶会ICML-2019最新进展速览—论文PDF打包下载
最新 | 用深度强化学习打造不亏钱的交易机器人(附代码)
博弈论的经典入门课程和资料
德州扑克AI核心算法CFR在量化交易中的探索应用
干货 | 深度学习在美团配送ETA预估中的探索与实践
深度强化学习领域盘点系列 | 大神篇
深度强化学习领域盘点系列 | 大厂机构
干货 |VALSE 2019总结 --PPT 打包下载
深度强化学习领域盘点系列 | 大厂机构篇
量化投资之宏观篇 | 达里欧谈美国社会的矛盾及如何改良
NLP for Quant:使用NLP和深度学习预测股价(附代码)
自动驾驶中轨迹规划的探索和挑战
计算机进行通用学习的原理、方法和工程模型
深度强化学习 | 用TensorFlow构建你的第一个游戏AI
干货| 聊天机器人对知识图谱有哪些特殊的需求?

