
- 1VPCFormer:一个基于transformer的多视角指静脉识别模型和一个新基准
- 2MathType2024MAC苹果电脑版本下载安装图文教程_mathtype mac
- 3MySQL 8.0 修改密码的那些折腾事_update user set plugin='caching_sha2_password' whe
- 4IBM SPSS Statistics:提升数据处理效率的利器
- 5Android Notification通知使用(从基本到高级)
- 6数理统计————思维导图(上岸必备)_数理统计思维导图
- 7Android获取手机内部存储路径-包含SD卡(通过挂载点)_android获取挂载设备名称
- 8微软牵手OpenAI劲敌!Mistral最新顶级大模型不再开源_mistral ai le chat猫
- 9批量梯度下降 | 随机梯度下降 | 小批度梯度下降_参数分批次下降
- 10IDEA系列:如何在Idea中去配置Gradle_idea配置gradle
UIE Slim满足工业应用场景,解决推理部署耗时问题,提升效能_we are using
赞
踩
UIE Slim满足工业应用场景,解决推理部署耗时问题,提升效能
在UIE强大的抽取能力背后,同样需要较大的算力支持计算。在一些工业应用场景中对性能的要求较高,若不能有效压缩则无法实际应用。因此,基于数据蒸馏技术构建了UIE Slim数据蒸馏系统。其原理是通过数据作为桥梁,将UIE模型的知识迁移到封闭域信息抽取小模型,以达到精度损失较小的情况下却能达到大幅度预测速度提升的效果。
FasterTokenizer是一款简单易用、功能强大的跨平台高性能文本预处理库,集成业界多个常用的Tokenizer实现,支持不同NLP场景下的文本预处理功能,如文本分类、阅读理解,序列标注等。结合PaddleNLP Tokenizer模块,为用户在训练、推理阶段提供高效通用的文本预处理能力。use_faster: 使用C++实现的高性能分词算子FasterTokenizer进行文本预处理加速
UIE数据蒸馏三步
-
Step 1: 使用UIE模型对标注数据进行finetune,得到Teacher Model。
-
Step 2: 用户提供大规模无标注数据,需与标注数据同源。使用Taskflow UIE对无监督数据进行预测。
-
Step 3: 使用标注数据以及步骤2得到的合成数据训练出封闭域Student Model。
效果展示:
测试硬件情况:
1点算力卡对应的:
V100 32GB
GPUTesla V100
Video Mem32GB
CPU4 Cores
RAM32GB
Disk100GB
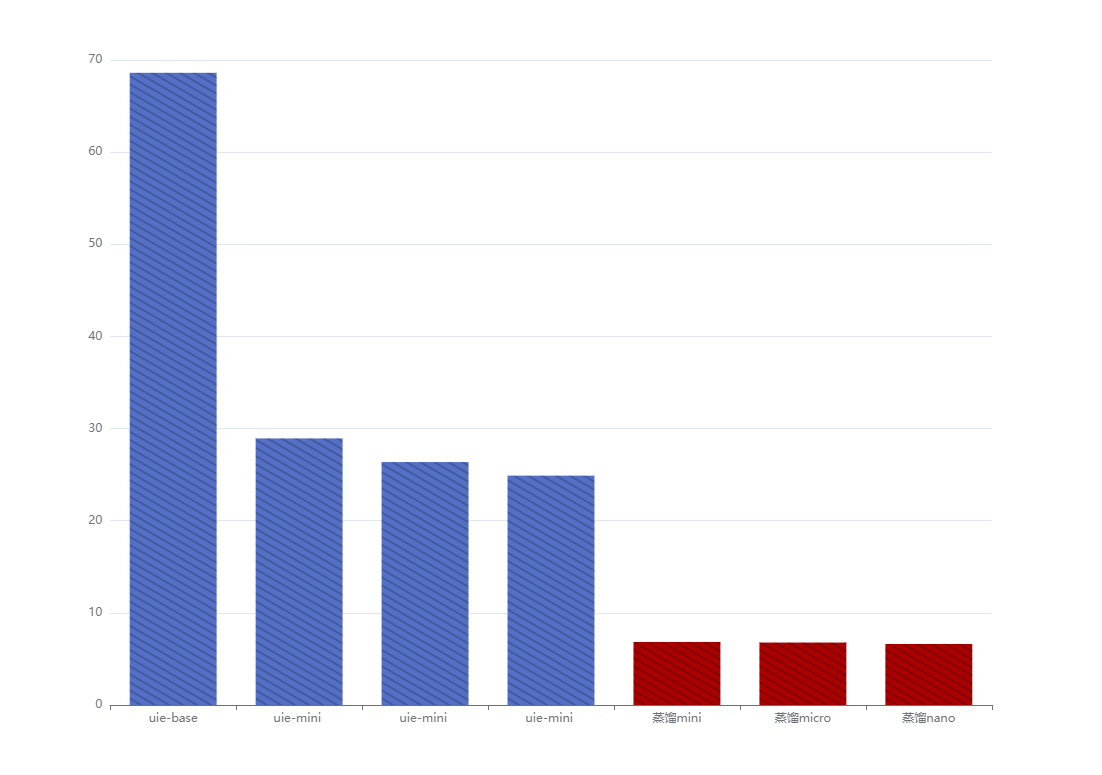
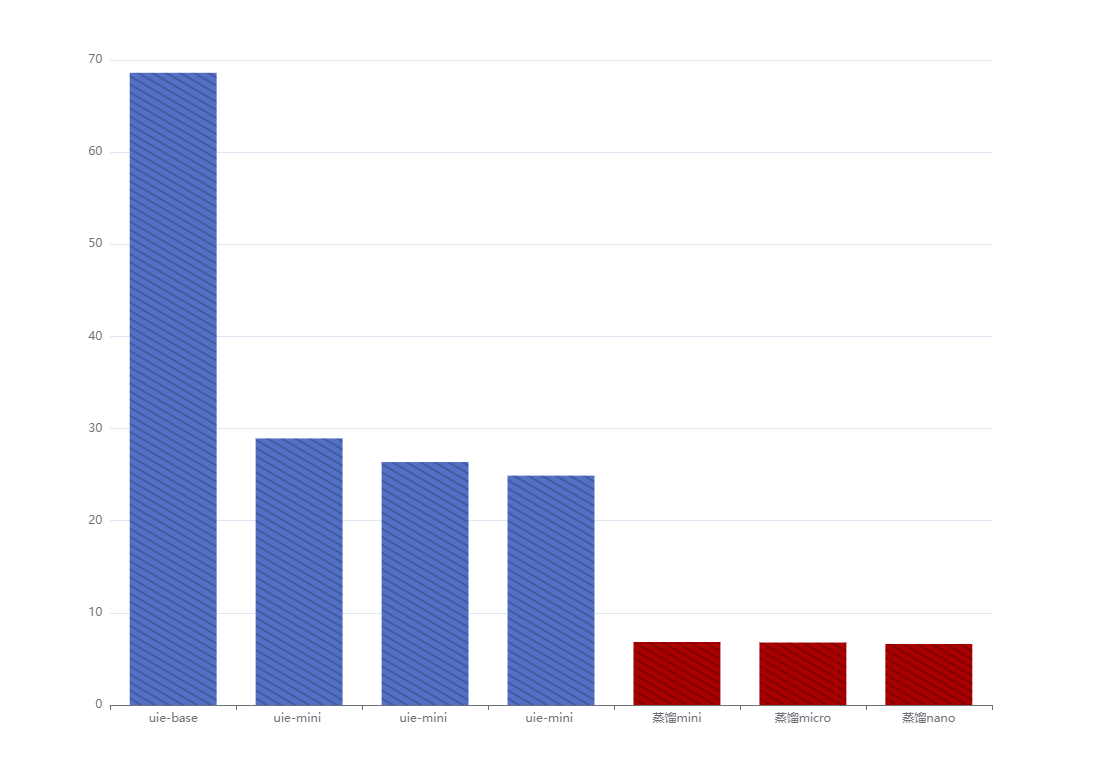
| 模型 | 模型计算运行时间 | precision | recall | F1 |
|---|---|---|---|---|
| uie-base | 68.61049008s | 0.69277 | 0.72327 | 0.70769 |
| uie-mini | 28.932519437s | 0.74138 | 0.54088 | 0.62545 |
| uie-micro | 26.36701917 | 0.74757 | 0.48428 | 0.58779 |
| uie-nano | 24.8937761 | 0.74286 | 0.49057 | 0.59091 |
| 蒸馏mini | 6.839258904s | 0.7732 | 0.75 | 0.76142 |
| 蒸馏micro | 6.776990s | 0.78261 | 0.72 | 0.75 |
| 蒸馏nano | 6.6231770s | 0.7957 | 0.74 | 0.76684 |
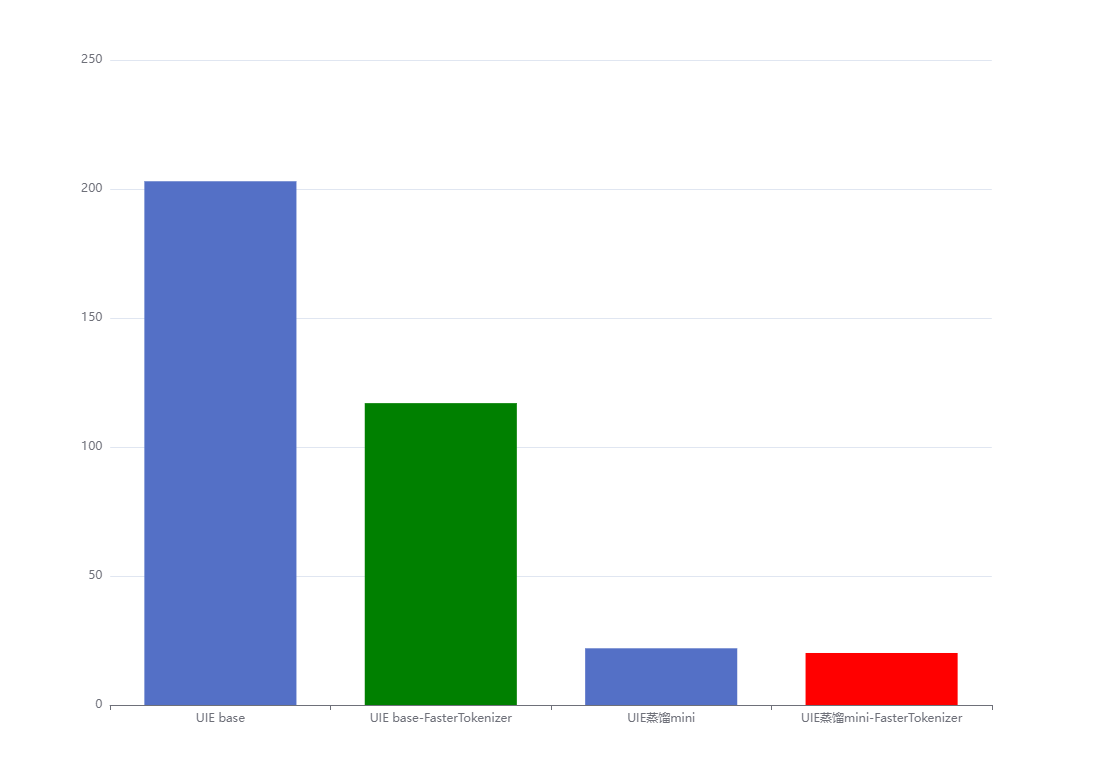
模型计算运行时间:
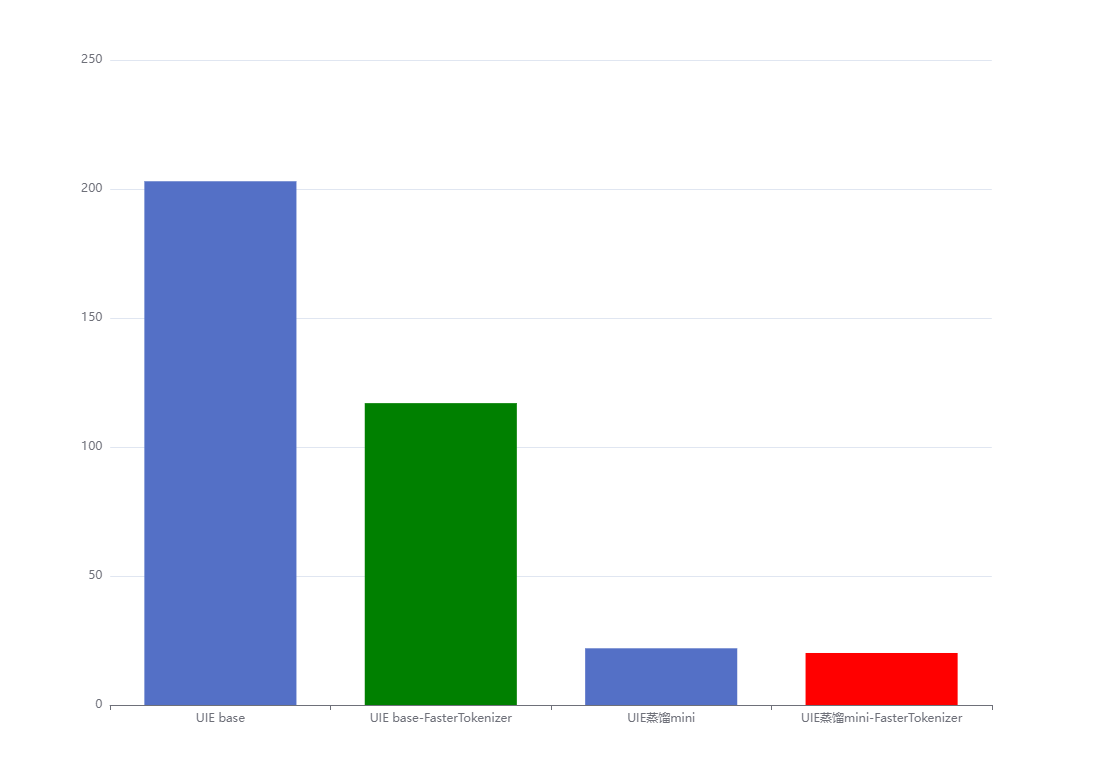
| 模型 | 模型计算运行时间 | 提速x倍 |
|---|---|---|
| UIE base | 203.95947s | 1 |
| UIE base + FasterTokenizer | 177.1798s | 1.15 |
| UIE蒸馏mini | 21.97979s | 9.28 |
| UIE蒸馏mini + FasterTokenizer | 20.1557s | 10.12 |
0.安装环境&数据准备
# !pip install --upgrade paddlenlp --user
!pip install --upgrade paddlenlp
# !unzip PaddleNLP-model_zoo-uie.zip
# !pip install paddlenlp==2.3.4 -i https://mirror.baidu.com/pypi/simple --user
#根据信息安装
- 1
- 2
- 3
- 4
- 5
警告不用管忽略
Installing collected packages: paddlenlp
Attempting uninstall: paddlenlp
Found existing installation: paddlenlp 2.4.0
Uninstalling paddlenlp-2.4.0:
Successfully uninstalled paddlenlp-2.4.0
Successfully installed paddlenlp-2.3.4
#本项目中从CMeIE数据集中采样少量数据展示了UIE数据蒸馏流程,示例数据下载,解压后放在./data目录下
# !wget https://bj.bcebos.com/paddlenlp/datasets/uie/data_distill/data.zip && unzip -d ./ data.zip
!cp /home/aistudio/数据集/* ./data/ #移动已经下载好的数据到data
- 1
- 2
- 3
# %cd ..
- 1
/home/aistudio
- 1
Archive: data.zip
- inflating: ./data/unlabeled_data.txt
- inflating: ./data/doccano_ext.json
示例数据包含以下两部分:
| 名称 | 数量 |
|---|---|
| doccano格式标注数据(doccano_ext.json) | 200 |
| 无标注数据(unlabeled_data.txt) | 1277 |
1. 进行预训练微调,得到Teacher Model
具体参数以及doccano标注细节参考文档:
Paddlenlp之UIE模型实战实体抽取任务【打车数据、快递单】
PaddleNLP之UIE信息抽取小样本进阶(二)[含doccano详解]
Paddlenlp之UIE分类模型【以情感倾向分析新闻分类为例】含智能标注方案)
!python doccano.py \
--doccano_file ./data/doccano_ext.json \
--task_type ext \
--save_dir ./data \
--splits 0.8 0.2 0
- 1
- 2
- 3
- 4
- 5
[32m[2022-09-09 20:54:13,944] [ INFO][0m - Converting doccano data...[0m 100%|███████████████████████████████████████| 160/160 [00:00<00:00, 8505.34it/s] [32m[2022-09-09 20:54:13,965] [ INFO][0m - Adding negative samples for first stage prompt...[0m 100%|█████████████████████████████████████| 160/160 [00:00<00:00, 275149.09it/s] [32m[2022-09-09 20:54:13,966] [ INFO][0m - Adding negative samples for second stage prompt...[0m 100%|████████████████████████████████████████| 160/160 [00:00<00:00, 914.34it/s] [32m[2022-09-09 20:54:14,142] [ INFO][0m - Converting doccano data...[0m 100%|████████████████████████████████████████| 40/40 [00:00<00:00, 46281.98it/s] [32m[2022-09-09 20:54:14,143] [ INFO][0m - Adding negative samples for first stage prompt...[0m 100%|███████████████████████████████████████| 40/40 [00:00<00:00, 211034.16it/s] [32m[2022-09-09 20:54:14,144] [ INFO][0m - Adding negative samples for second stage prompt...[0m 100%|███████████████████████████████████████| 40/40 [00:00<00:00, 401368.80it/s] [32m[2022-09-09 20:54:14,155] [ INFO][0m - Converting doccano data...[0m 0it [00:00, ?it/s] [32m[2022-09-09 20:54:14,156] [ INFO][0m - Adding negative samples for first stage prompt...[0m 0it [00:00, ?it/s] [32m[2022-09-09 20:54:14,178] [ INFO][0m - Save 480 examples to ./data/train.txt.[0m [32m[2022-09-09 20:54:14,196] [ INFO][0m - Save 246 examples to ./data/dev.txt.[0m [32m[2022-09-09 20:54:14,198] [ INFO][0m - Save 0 examples to ./data/test.txt.[0m [32m[2022-09-09 20:54:14,198] [ INFO][0m - Finished! It takes 0.26 seconds[0m [0m

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
处理后部分数据展示:
{"content": "缺血性卒中@对于因占位效应导致恶化的大面积大脑半球卒中,应考虑去骨瓣减压术。", "result_list": [{"text": "大面积大脑半球卒中", "start": 18, "end": 27}], "prompt": "疾病"}
{"content": "缺血性卒中@对于因占位效应导致恶化的大面积大脑半球卒中,应考虑去骨瓣减压术。", "result_list": [{"text": "去骨瓣减压术", "start": 31, "end": 37}], "prompt": "手术治疗"}
{"content": "妊娠胆汁淤积@## 检查 ### 首要检查 ### 查看全部 ### 胆汁酸 检查 结果 检查 对任何患有瘙痒合并没有因可识别的皮疹导致的皮肤抓痕的孕妇的医嘱。", "result_list": [{"text": "妊娠胆汁淤积", "start": 1, "end": 7}], "prompt": "疾病"}
{"content": "妊娠胆汁淤积@## 检查 ### 首要检查 ### 查看全部 ### 胆汁酸 检查 结果 检查 对任何患有瘙痒合并没有因可识别的皮疹导致的皮肤抓痕的孕妇的医嘱。", "result_list": [{"text": "胆汁酸", "start": 40, "end": 43}], "prompt": "检查"}
- 1
- 2
- 3
- 4
UIE:模型
| 模型 | 结构 | 语言 | 大小 |
|---|---|---|---|
| uie-base (默认) | 12-layers, 768-hidden, 12-heads | 中文 | 118M |
| uie-base-en | 12-layers, 768-hidden, 12-heads | 英文 | 118M |
| uie-medical-base | 12-layers, 768-hidden, 12-heads | 中文 | |
| uie-medium | 6-layers, 768-hidden, 12-heads | 中文 | 75M |
| uie-mini | 6-layers, 384-hidden, 12-heads | 中文 | 27M |
| uie-micro | 4-layers, 384-hidden, 12-heads | 中文 | 23M |
| uie-nano | 4-layers, 312-hidden, 12-heads | 中文 | 18M |
| uie-m-large | 24-layers, 1024-hidden, 16-heads | 中、英文 | 实际大小2G |
| uie-m-base | 12-layers, 768-hidden, 12-heads | 中、英文 | 实际大小1G |
实际模型大小解释:
base模型118M parameters是指base模型的参数个数,因为同一个模型可以被不同的精度来表示,例如float16,float32,下载下来是450M左右(存储空间大小),是因为下载的模型是float32,118M * 4 大概是存储空间的量级。
!python finetune.py \
--train_path "./data/train.txt" \
--dev_path "./data/dev.txt" \
--save_dir "./checkpoint" \
--learning_rate 5e-6 \
--batch_size 16 \
--max_seq_len 512 \
--num_epochs 10 \
--model "uie-base" \
--seed 1000 \
--logging_steps 10 \
--valid_steps 50 \
--device "gpu"
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
base模型部分结果展示:
[2022-09-08 17:26:55,701] [ INFO] - Evaluation precision: 0.69375, recall: 0.69811, F1: 0.69592
[2022-09-08 17:27:01,145] [ INFO] - global step 260, epoch: 9, loss: 0.00172, speed: 1.84 step/s
[2022-09-08 17:27:06,448] [ INFO] - global step 270, epoch: 9, loss: 0.00168, speed: 1.89 step/s
[2022-09-08 17:27:12,102] [ INFO] - global step 280, epoch: 10, loss: 0.00165, speed: 1.77 step/s
[2022-09-08 17:27:17,607] [ INFO] - global step 290, epoch: 10, loss: 0.00162, speed: 1.82 step/s
[2022-09-08 17:27:22,899] [ INFO] - global step 300, epoch: 10, loss: 0.00159, speed: 1.89 step/s
[2022-09-08 17:27:26,577] [ INFO] - Evaluation precision: 0.69277, recall: 0.72327, F1: 0.70769
[2022-09-08 17:27:26,577] [ INFO] - best F1 performence has been updated: 0.69841 --> 0.70769
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
2.离线蒸馏
2.1 通过训练好的UIE定制模型预测无监督数据的标签
用户提供大规模无标注数据,需与标注数据同源。使用Taskflow UIE对无监督数据进行预测。
References:
GlobalPointer:用统一的方式处理嵌套和非嵌套NER:
GPLinker:基于GlobalPointer的实体关系联合抽取
%cd /home/aistudio/data_distill
!python data_distill.py \
--data_path /home/aistudio/data \
--save_dir student_data \
--task_type relation_extraction \
--synthetic_ratio 10 \
--model_path /home/aistudio/checkpoint/model_best
- 1
- 2
- 3
- 4
- 5
- 6
- 7
/home/aistudio/data_distill
[32m[2022-09-09 13:03:05,841] [ INFO][0m - We are using <class 'paddlenlp.transformers.ernie.tokenizer.ErnieTokenizer'> to load '/home/aistudio/checkpoint/model_best'.[0m
W0909 13:03:05.868649 1201 gpu_resources.cc:61] Please NOTE: device: 0, GPU Compute Capability: 7.0, Driver API Version: 11.2, Runtime API Version: 11.2
W0909 13:03:05.872092 1201 gpu_resources.cc:91] device: 0, cuDNN Version: 8.2.
[32m[2022-09-09 13:03:08,028] [ INFO][0m - Converting to the inference model cost a little time.[0m
[32m[2022-09-09 13:03:16,407] [ INFO][0m - The inference model save in the path:/home/aistudio/checkpoint/model_best/static/inference[0m
[32m[2022-09-09 13:04:47,551] [ INFO][0m - Save 1437 examples to student_data/train_data.json.[0m
[32m[2022-09-09 13:04:47,552] [ INFO][0m - Save 40 examples to student_data/dev_data.json.[0m
[32m[2022-09-09 13:04:47,552] [ INFO][0m - Save 0 examples to student_data/test_data.json.[0m
[0m
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
可配置参数说明:
-
data_path: 标注数据(doccano_ext.json)及无监督文本(unlabeled_data.txt)路径。
-
model_path: 训练好的UIE定制模型路径。
-
save_dir: 学生模型训练数据保存路径。
-
synthetic_ratio: 控制合成数据的比例。最大合成数据数量=synthetic_ratio*标注数据数量。
-
task_type: 选择任务类型,可选有entity_extraction,relation_extraction,event_extraction和opinion_extraction。因为是封闭域信息抽取,需指定任务类型。
-
seed: 随机种子,默认为1000。
parser.add_argument("--data_path", default="../data", type=str, help="The directory for labeled data with doccano format and the large scale unlabeled data.")
parser.add_argument("--model_path", type=str, default="../checkpoint/model_best", help="The path of saved model that you want to load.")
parser.add_argument("--save_dir", default="./distill_task", type=str, help="The path of data that you wanna save.")
parser.add_argument("--synthetic_ratio", default=10, type=int, help="The ratio of labeled and synthetic samples.")
parser.add_argument("--task_type", choices=['relation_extraction', 'event_extraction', 'entity_extraction', 'opinion_extraction'], default="entity_extraction", type=str, help="Select the training task type.")
parser.add_argument("--seed", type=int, default=1000, help="Random seed for initialization")
- 1
- 2
- 3
- 4
- 5
- 6
2.2老师模型评估
UIE微调阶段针对UIE训练格式数据评估模型效果(该评估方式非端到端评估,不适合关系、事件等任务),可通过以下评估脚本针对原始标注格式数据评估模型效果
%cd /home/aistudio/data_distill
!python evaluate_teacher.py \
--task_type relation_extraction \
--test_path ./student_data/dev_data.json \
--label_maps_path ./student_data/label_maps.json \
--model_path /home/aistudio/checkpoint/model_best
- 1
- 2
- 3
- 4
- 5
- 6
对原始标注格式数据评估模型效果:
Evaluation precision: {‘entity_f1’: 0.75532, ‘entity_precision’: 0.80682, ‘entity_recall’: 0.71, ‘relation_f1’: 0.52459, ‘relation_precision’: 0.50794, ‘relation_recall’: 0.54237}
可配置参数说明:
-
model_path: 训练好的UIE定制模型路径。
-
test_path: 测试数据集路径。
-
label_maps_path: 学生模型标签字典。
-
batch_size: 批处理大小,默认为8。
-
max_seq_len: 最大文本长度,默认为256。
-
task_type: 选择任务类型,可选有entity_extraction,relation_extraction,event_extraction和opinion_extraction。因为是封闭域信息抽取的评估,需指定任务类型。
parser.add_argument("--model_path", type=str, default=None, help="The path of saved model that you want to load.")
parser.add_argument("--test_path", type=str, default=None, help="The path of test set.")
parser.add_argument("--encoder", default="ernie-3.0-base-zh", type=str, help="Select the pretrained encoder model for GP.")
parser.add_argument("--label_maps_path", default="./ner_data/label_maps.json", type=str, help="The file path of the labels dictionary.")
parser.add_argument("--batch_size", type=int, default=16, help="Batch size per GPU/CPU for training.")
parser.add_argument("--max_seq_len", type=int, default=128, help="The maximum total input sequence length after tokenization.")
parser.add_argument("--task_type", choices=['relation_extraction', 'event_extraction', 'entity_extraction', 'opinion_extraction'], default="entity_extraction",
- 1
- 2
- 3
- 4
- 5
- 6
- 7
2.3学生模型训练
底座模型可以参考下面进行替换!
!python train.py \
--task_type relation_extraction \
--train_path student_data/train_data.json \
--dev_path student_data/dev_data.json \
--label_maps_path student_data/label_maps.json \
--num_epochs 200 \
--encoder ernie-3.0-mini-zh
- 1
- 2
- 3
- 4
- 5
- 6
- 7
# %cd /home/aistudio/data_distill
!python train.py \
--task_type relation_extraction \
--train_path student_data/train_data.json \
--dev_path student_data/dev_data.json \
--label_maps_path student_data/label_maps.json \
--num_epochs 100 \
--encoder ernie-3.0-mini-zh\
--device "gpu"\
--valid_steps 100\
--logging_steps 10\
--save_dir './checkpoint2'\
--batch_size 16
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
蒸馏后学生模型输出结果
[2022-09-09 13:18:31,253] [ INFO] - global step 3000, epoch: 34, loss: 0.74747, speed: 9.28 step/s
[2022-09-09 13:18:31,439] [ INFO] - Evaluation precision: {'entity_f1': 0.76142, 'entity_precision': 0.7732, 'entity_recall': 0.75, 'relation_f1': 0.56061, 'relation_precision': 0.50685, 'relation_recall': 0.62712}
[2022-09-09 13:18:31,439] [ INFO] - best F1 performence has been updated: 0.55556 --> 0.56061
best_model已保存
- 1
- 2
- 3
- 4
可配置参数说明:
-
train_path: 训练集文件路径。
-
dev_path: 验证集文件路径。
-
batch_size: 批处理大小,默认为16。
-
learning_rate: 学习率,默认为3e-5。
-
save_dir: 模型存储路径,默认为./checkpoint。
-
max_seq_len: 最大文本长度,默认为256。
-
weight_decay: 表示AdamW优化器中使用的 weight_decay 的系数。
-
warmup_proportion: 学习率warmup策略的比例,如果0.1,则学习率会在前10%训练step的过程中从0慢慢增长到learning_rate, 而后再缓慢衰减,默认为0.0。
-
num_epochs: 训练轮数,默认为100。
-
seed: 随机种子,默认为1000。
-
encoder: 选择学生模型的模型底座,默认为ernie-3.0-mini-zh。
-
task_type: 选择任务类型,可选有entity_extraction,relation_extraction,event_extraction和opinion_extraction。因为是封闭域信息抽取,需指定任务类型。
-
logging_steps: 日志打印的间隔steps数,默认10。
-
valid_steps: evaluate的间隔steps数,默认200。
-
device: 选用什么设备进行训练,可选cpu或gpu。
-
init_from_ckpt: 可选,模型参数路径,热启动模型训练;默认为None。
3.Taskflow部署学生模型以及性能测试
通过Taskflow一键部署封闭域信息抽取模型,task_path为学生模型路径。
demo测试
from pprint import pprint
from paddlenlp import Taskflow
ie = Taskflow("information_extraction", model="uie-data-distill-gp", task_path="checkpoint2/model_best/") # Schema 在闭域信息抽取中是固定的
pprint(ie("登革热@结果 升高 ### 血清白蛋白水平 检查 结果 检查 在资源匮乏地区和富足地区,对有症状患者均应早期检测。"))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
[2022-09-09 14:25:47,884] [ INFO] - We are using <class 'paddlenlp.transformers.ernie.tokenizer.ErnieTokenizer'> to load 'checkpoint2/model_best/'. [{'疾病': [{'end': 3, 'probability': 0.9995957, 'relations': {'实验室检查': [{'end': 21, 'probability': 0.99892455, 'relations': {}, 'start': 14, 'text': '血清白蛋白水平'}], '影像学检查': [{'end': 21, 'probability': 0.99832386, 'relations': {}, 'start': 14, 'text': '血清白蛋白水平'}]}, 'start': 0, 'text': '登革热'}]}]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
from pprint import pprint import json from paddlenlp.taskflow import Taskflow import pandas as pd #运行时间 import time def openreadtxt(file_name): data = [] file = open(file_name,'r',encoding='UTF-8') #打开文件 file_data = file.readlines() #读取所有行 for row in file_data: data.append(row) #将每行数据插入data中 return data # 时间1 old_time = time.time() data_input=openreadtxt('/home/aistudio/数据集/unlabeled_data.txt') few_ie = Taskflow("information_extraction", model="uie-data-distill-gp", task_path="/home/aistudio/data_distill/checkpoint2/model_best",batch_size=32) # Schema 在闭域信息抽取中是固定的 # 时间1 current_time = time.time() print("数据模型载入运行时间为" + str(current_time - old_time) + "s") #时间2 old_time1 = time.time() results=few_ie(data_input) current_time1 = time.time() print("模型计算运行时间为" + str(current_time1 - old_time1) + "s") #时间2 #时间三 old_time3 = time.time() test = pd.DataFrame(data=results) test.to_csv('/home/aistudio/output/reslut.txt', sep='\t', index=False,header=False) #本地 # with open("/home/aistudio/output/reslut.txt", "w+",encoding='UTF-8') as f: #a : 写入文件,若文件不存在则会先创建再写入,但不会覆盖原文件,而是追加在文件末尾 # for result in results: # line = json.dumps(result, ensure_ascii=False) #对中文默认使用的ascii编码.想输出真正的中文需要指定ensure_ascii=False # f.write(line + "\n") current_time3 = time.time() print("数据导出运行时间为" + str(current_time3 - old_time3) + "s") # for idx, text in enumerate(data): # print('Data: {} \t Lable: {}'.format(text[0], results[idx])) print("数据结果已导出")
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
mini运行时间:
数据模型载入运行时间为0.8430757522583008s
模型计算运行时间为6.839258909225464s
数据导出运行时间为0.008304595947265625s
nano运行时间:
数据模型载入运行时间为0.5164840221405029s
模型计算运行时间为6.6231770515441895s
数据导出运行时间为0.023623943328857422s
micro运行时间:
数据模型载入运行时间为0.5323500633239746s
模型计算运行时间为6.77699007987976s
数据导出运行时间为0.04320549964904785s
4 进行预训练模型UIE-mini并测试推理时间
封闭域UIE的schema是固定的,可以在label_maps.json查看
0:"手术治疗"
1:"实验室检查"
2:"影像学检查"
- 1
- 2
- 3
%cd .. #返回到上一层
!python finetune.py \
--train_path "./data/train.txt" \
--dev_path "./data/dev.txt" \
--save_dir "./checkpoint_mini" \
--learning_rate 5e-6 \
--batch_size 16 \
--max_seq_len 512 \
--num_epochs 10 \
--model "uie-mini" \
--seed 1000 \
--logging_steps 10 \
--valid_steps 50 \
--device "gpu"
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
训练结果部分展示:
[2022-09-09 15:48:48,164] [ INFO] - global step 270, epoch: 9, loss: 0.00197, speed: 8.73 step/s
[2022-09-09 15:48:49,732] [ INFO] - global step 280, epoch: 10, loss: 0.00194, speed: 6.38 step/s
[2022-09-09 15:48:51,132] [ INFO] - global step 290, epoch: 10, loss: 0.00192, speed: 7.15 step/s
[2022-09-09 15:48:52,292] [ INFO] - global step 300, epoch: 10, loss: 0.00189, speed: 8.62 step/s
[2022-09-09 15:48:53,951] [ INFO] - Evaluation precision: 0.74138, recall: 0.54088, F1: 0.62545
- 1
- 2
- 3
- 4
- 5
!python finetune.py \
--train_path "./data/train.txt" \
--dev_path "./data/dev.txt" \
--save_dir "./checkpoint_micro" \
--learning_rate 5e-6 \
--batch_size 16 \
--max_seq_len 512 \
--num_epochs 10 \
--model "uie-micro" \
--seed 1000 \
--logging_steps 10 \
--valid_steps 50 \
--device "gpu"
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
micro
[2022-09-09 21:00:02,337] [ INFO] - global step 300, epoch: 10, loss: 0.00239, speed: 11.91 step/s
[2022-09-09 21:00:03,837] [ INFO] - Evaluation precision: 0.74757, recall: 0.48428, F1: 0.58779
[2022-09-09 21:00:03,837] [ INFO] - best F1 performence has been updated: 0.57937 --> 0.58779
- 1
- 2
- 3
!python finetune.py \
--train_path "./data/train.txt" \
--dev_path "./data/dev.txt" \
--save_dir "./checkpoint_nano" \
--learning_rate 5e-6 \
--batch_size 16 \
--max_seq_len 512 \
--num_epochs 10 \
--model "uie-nano" \
--seed 1000 \
--logging_steps 10 \
--valid_steps 50 \
--device "gpu"
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
uie-nano
[2022-09-09 21:00:56,083] [ INFO] - Evaluation precision: 0.74286, recall: 0.49057, F1: 0.59091
[2022-09-09 21:00:56,083] [ INFO] - best F1 performence has been updated: 0.58015 --> 0.59091
- 1
- 2
%cd /home/aistudio/data_distill
!python train.py \
--task_type relation_extraction \
--train_path student_data/train_data.json \
--dev_path student_data/dev_data.json \
--label_maps_path student_data/label_maps.json \
--num_epochs 100 \
--encoder ernie-3.0-micro-zh\
--device "gpu"\
--valid_steps 100\
--logging_steps 10\
--save_dir './checkpoint_micro'\
--batch_size 16
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
ernie-3.0-micro-zh
[2022-09-09 21:10:23,593] [ INFO] - Evaluation precision: {'entity_f1': 0.75, 'entity_precision': 0.78261, 'entity_recall': 0.72, 'relation_f1': 0.52991, 'relation_precision': 0.53448, 'relation_recall': 0.52542}
[2022-09-09 21:10:23,593] [ INFO] - best F1 performence has been updated: 0.52713 --> 0.52991
best_model已保存
- 1
- 2
- 3
# %cd /home/aistudio/data_distill
!python train.py \
--task_type relation_extraction \
--train_path student_data/train_data.json \
--dev_path student_data/dev_data.json \
--label_maps_path student_data/label_maps.json \
--num_epochs 100 \
--encoder ernie-3.0-nano-zh\
--device "gpu"\
--valid_steps 100\
--logging_steps 10\
--save_dir './checkpoint_nano'\
--batch_size 16
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
from pprint import pprint import json from paddlenlp import Taskflow import pandas as pd #运行时间 import time def openreadtxt(file_name): data = [] file = open(file_name,'r',encoding='UTF-8') #打开文件 file_data = file.readlines() #读取所有行 for row in file_data: data.append(row) #将每行数据插入data中 return data # 时间1 old_time = time.time() data_input=openreadtxt('/home/aistudio/数据集/unlabeled_data.txt') schema = {'疾病': ['手术治疗', '实验室检查', '影像学检查']} # few_ie = Taskflow('information_extraction', schema=schema, batch_size=32,task_path='/home/aistudio/checkpoint_mini/model_best') #自行切换 few_ie = Taskflow('information_extraction', schema=schema, batch_size=32,task_path='/home/aistudio/checkpoint_micro/model_best') # 时间1 current_time = time.time() print("数据模型载入运行时间为" + str(current_time - old_time) + "s") #时间2 old_time1 = time.time() results=few_ie(data_input) current_time1 = time.time() print("模型计算运行时间为" + str(current_time1 - old_time1) + "s") #时间2 #时间三 old_time3 = time.time() test = pd.DataFrame(data=results) test.to_csv('/home/aistudio/output/reslut.txt', sep='\t', index=False,header=False) #本地 # with open("/home/aistudio/output/reslut.txt", "w+",encoding='UTF-8') as f: #a : 写入文件,若文件不存在则会先创建再写入,但不会覆盖原文件,而是追加在文件末尾 # for result in results: # line = json.dumps(result, ensure_ascii=False) #对中文默认使用的ascii编码.想输出真正的中文需要指定ensure_ascii=False # f.write(line + "\n") current_time3 = time.time() print("数据导出运行时间为" + str(current_time3 - old_time3) + "s") # for idx, text in enumerate(data): # print('Data: {} \t Lable: {}'.format(text[0], results[idx])) print("数据结果已导出")
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
[2022-09-09 21:34:09,863] [ INFO] - We are using <class 'paddlenlp.transformers.ernie.tokenizer.ErnieTokenizer'> to load '/home/aistudio/checkpoint_micro/model_best'.
数据模型载入运行时间为0.39632749557495117s
模型计算运行时间为26.367019176483154s
数据导出运行时间为0.012260198593139648s
数据结果已导出
- 1
- 2
- 3
- 4
- 5
- 6
- 7
通过上述程序自行切换:加载对应模型
记录推理时间:
uie-nano
数据模型载入运行时间为0.3770780563354492s
模型计算运行时间为24.893776178359985s
数据导出运行时间为0.01157689094543457s
uie-micro
数据模型载入运行时间为0.39632749557495117s
模型计算运行时间为26.367019176483154s
数据导出运行时间为0.012260198593139648s
uie-mini
数据模型载入运行时间为0.5642790794372559s
模型计算运行时间为28.93251943588257s
数据导出运行时间为0.01435089111328125s
uie-base
数据模型载入运行时间为1.4756040573120117s
模型计算运行时间为68.61049008369446s
数据导出运行时间为0.02205801010131836s
5.提前尝鲜UIE FasterTokenizer加速,提升推理性能
FasterTokenizer是一款简单易用、功能强大的跨平台高性能文本预处理库,集成业界多个常用的Tokenizer实现,支持不同NLP场景下的文本预处理功能,如文本分类、阅读理解,序列标注等。结合PaddleNLP Tokenizer模块,为用户在训练、推理阶段提供高效通用的文本预处理能力。
use_faster: 使用C++实现的高性能分词算子FasterTokenizer进行文本预处理加速。需要通过pip install faster_tokenizer安装FasterTokenizer库后方可使用。默认为False。更多使用说明可参考[FasterTokenizer文档]
https://github.com/PaddlePaddle/PaddleNLP/blob/develop/faster_tokenizer/README.md
特性
-
高性能。由于底层采用C++实现,所以其性能远高于目前常规Python实现的Tokenizer。在文本分类任务上,FasterTokenizer对比Python版本Tokenizer加速比最高可达20倍。
-
跨平台。FasterTokenizer可在不同的系统平台上使用,目前已支持Windows x64,Linux x64以及MacOS 10.14+平台上使用。
-
多编程语言支持。FasterTokenizer提供在C++、Python语言上开发的能力。
-
灵活性强。用户可以通过指定不同的FasterTokenizer组件定制满足需求的Tokenizer。
FAQ
Q:我在AutoTokenizer.from_pretrained接口上已经打开use_faster=True开关,为什么文本预处理阶段性能上好像没有任何变化?
A:在有三种情况下,打开use_faster=True开关可能无法提升性能:
-
没有安装faster_tokenizer。若在没有安装faster_tokenizer库的情况下打开use_faster开关,PaddleNLP会给出以下warning:"Can’t find the faster_tokenizer package, please ensure install faster_tokenizer correctly. "。
-
加载的Tokenizer类型暂不支持Faster版本。目前支持4种Tokenizer的Faster版本,分别是BERT、ERNIE、TinyBERT以及ERNIE-M Tokenizer。若加载不支持Faster版本的Tokenizer情况下打开use_faster开关,PaddleNLP会给出以下warning:“The tokenizer XXX doesn’t have the faster version. Please check the map paddlenlp.transformers.auto.tokenizer.FASTER_TOKENIZER_MAPPING_NAMES to see which faster tokenizers are currently supported.”
-
待切词文本长度过短(如文本平均长度小于5)。这种情况下切词开销可能不是整个文本预处理的性能瓶颈,导致在使用FasterTokenizer后仍无法提升整体性能。
5.1 方案一
把paddlenlp直接装到指定路径然后修改对应文件;
详情参考这个PR:
Add use_faster flag for uie of taskflow.
# 如果需要进行持久化安装, 需要使用持久化路径, 如下方代码示例:
# !mkdir paddlenlp
!pip install --upgrade paddlenlp -t /home/aistudio/paddlenlp
- 1
- 2
- 3
# 同时添加如下代码, 这样每次环境(kernel)启动的时候只要运行下方代码即可:
import sys
import os
sys.path.append('/home/aistudio/paddlenlp')
sys.path.append('/home/aistudio/paddlenlp/paddlenlp/taskflow')
- 1
- 2
- 3
- 4
- 5
5.2方案二
直接找到pr修改后的版本,从giuhub拉去过来:链接参考
https://github.com/joey12300/PaddleNLP/tree/add_ft_requirements
!unzip -d PaddleNLP PaddleNLP-add_ft_requirements.zip
- 1
#这里采用先装老库再覆盖的方案,确保依赖都安装时,不然直接解压执行setup.py会卡主
!pip install --upgrade paddlenlp
- 1
- 2
%cd /home/aistudio/PaddleNLP/PaddleNLP-add_ft_requirements
!python setup.py install --user
%cd ../../
- 1
- 2
- 3
#安装UIE FasterTokenizer
!pip install faster_tokenizer
- 1
- 2
from pprint import pprint import json from paddlenlp.taskflow import Taskflow import pandas as pd #运行时间 import time def openreadtxt(file_name): data = [] file = open(file_name,'r',encoding='UTF-8') #打开文件 file_data = file.readlines() #读取所有行 for row in file_data: data.append(row) #将每行数据插入data中 return data # 时间1 old_time = time.time() data_input=openreadtxt('/home/aistudio/数据集/unlabeled_data-Copy1.txt') few_ie = Taskflow("information_extraction", model="uie-data-distill-gp", task_path="/home/aistudio/data_distill/checkpoint2/model_best",use_faster=True,batch_size=32) # Schema 在闭域信息抽取中是固定的 # few_ie = Taskflow("information_extraction", model="uie-data-distill-gp", task_path="/home/aistudio/data_distill/checkpoint2/model_best",batch_size=32) # Schema 在闭域信息抽取中是固定的 # schema = {'疾病': ['手术治疗', '实验室检查', '影像学检查']} # few_ie = Taskflow('information_extraction', schema=schema, batch_size=32,use_faster=True,task_path='/home/aistudio/checkpoint/model_best') # few_ie = Taskflow('information_extraction', schema=schema, batch_size=32,task_path='/home/aistudio/checkpoint/model_best') # 时间1 current_time = time.time() print("数据模型载入运行时间为" + str(current_time - old_time) + "s") #时间2 old_time1 = time.time() results=few_ie(data_input) current_time1 = time.time() print("模型计算运行时间为" + str(current_time1 - old_time1) + "s") #时间2 #时间三 old_time3 = time.time() test = pd.DataFrame(data=results) test.to_csv('/home/aistudio/output/reslut.txt', sep='\t', index=False,header=False) #本地 # with open("/home/aistudio/output/reslut.txt", "w+",encoding='UTF-8') as f: #a : 写入文件,若文件不存在则会先创建再写入,但不会覆盖原文件,而是追加在文件末尾 # for result in results: # line = json.dumps(result, ensure_ascii=False) #对中文默认使用的ascii编码.想输出真正的中文需要指定ensure_ascii=False # f.write(line + "\n") current_time3 = time.time() print("数据导出运行时间为" + str(current_time3 - old_time3) + "s") # for idx, text in enumerate(data): # print('Data: {} \t Lable: {}'.format(text[0], results[idx])) print("数据结果已导出")
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
[2022-09-11 22:53:07,314] [ INFO] - We are using <class 'paddlenlp.transformers.ernie.tokenizer.ErnieTokenizer'> to load '/home/aistudio/data_distill/checkpoint2/model_best'.
数据模型载入运行时间为0.7269768714904785s
模型计算运行时间为20.155770540237427s
数据导出运行时间为0.012202978134155273s
数据结果已导出
- 1
- 2
- 3
- 4
- 5
- 6
- 7
5.3UIE FasterTokenizer加速,提升推理性能
数据样本增大为原来的三倍:unlabeled_data-Copy1.txt
UIE base
数据模型载入运行时间为1.6006419658660889s
模型计算运行时间为203.95947885513306s
数据导出运行时间为0.07103896141052246s
UIE base + FasterTokenizer
数据模型载入运行时间为1.6196515560150146s
模型计算运行时间为177.17986011505127s
数据导出运行时间为0.07898902893066406s
UIE蒸馏mini
数据模型载入运行时间为0.8441095352172852s
模型计算运行时间为21.979790925979614s
数据导出运行时间为0.02339339256286621s
UIE蒸馏mini + FasterTokenizer
数据模型载入运行时间为0.7269768714904785s
模型计算运行时间为20.155770540237427s
数据导出运行时间为0.012202978134155273s
6.总结
测试硬件情况:
1点算力卡对应的:
V100 32GB
GPUTesla V100
Video Mem32GB
CPU4 Cores
RAM32GB
Disk100GB
| 模型 | 模型计算运行时间 | precision | recall | F1 |
|---|---|---|---|---|
| uie-base | 68.61049008s | 0.69277 | 0.72327 | 0.70769 |
| uie-mini | 28.932519437s | 0.74138 | 0.54088 | 0.62545 |
| uie-micro | 26.36701917 | 0.74757 | 0.48428 | 0.58779 |
| uie-nano | 24.8937761 | 0.74286 | 0.49057 | 0.59091 |
| 蒸馏mini | 6.839258904s | 0.7732 | 0.75 | 0.76142 |
| 蒸馏micro | 6.776990s | 0.78261 | 0.72 | 0.75 |
| 蒸馏nano | 6.6231770s | 0.7957 | 0.74 | 0.76684 |
模型计算运行时间:
| 模型 | 模型计算运行时间 | 提速x倍 |
|---|---|---|
| UIE base | 203.95947s | 1 |
| UIE base + FasterTokenizer | 177.1798s | 1.15 |
| UIE蒸馏mini | 21.97979s | 9.28 |
| UIE蒸馏mini + FasterTokenizer | 20.1557s | 10.12 |
1.可以看出UIE蒸馏在小网络下,性能差不多可以按需选择。可能会在更大任务性能会更好点
2.这里uie-base等只简单运行了10个epoch,可以多训练会提升性能
3.一般学生模型会选择参数量比较小的,UIE蒸馏版是schema并行推理的,速度会比UIE快很多,特别是schema比较多以及关系抽取等需要多阶段推理的情况
1.FasterTokenizer加速,paddlenlp2.4.0版本目前还不支持,只要参考PR改下源码
2.封闭域UIE的话schema是固定的,可以在label_maps.json查看,目前支持实体抽取、关系抽取、观点抽取和事件抽取,句子级情感分类目前蒸馏还不支持
3.想要更快的推理换下学生模型的backbone就行
感谢
感谢paddlenlp工作人员@linjieccc的支持,接受了issue并创建了pull request:fix data distill for UIE #3231 https://github.com/PaddlePaddle/PaddleNLP/pull/3231
Add use_faster flag for uie of taskflow. #3194
展望:
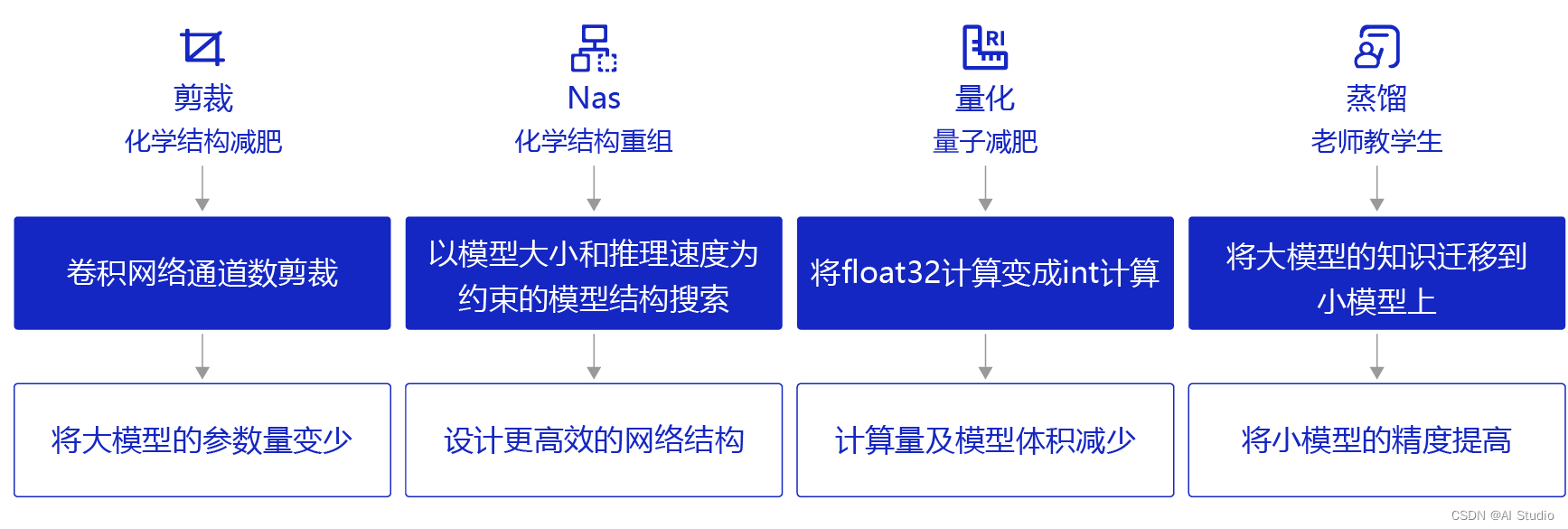
后续对FasterTokenizer进行补充;以及研究一下UIE模型的量化、剪枝、NAS
此文章为搬运
原项目链接

