
- 1基于阿里云 OpenAPI 插件,让 Grafana 轻松实现云上数据可视化
- 2微信小程序上线流程
- 3用Python实现童年的21款小游戏,有你玩过的吗?(不要错过哦)_python开发儿童游戏_python小游戏代码
- 4解决Vue 报错error:0308010C:digital envelope routines::unsupported问题_报错digital envelope routines unsupported
- 5学习笔记Label自右向左滚动和父容器内左右移动方法(含代码)_lvgl文本从右到左滚动
- 6Vue项目如何引入echarts_vue项目引入echarts
- 7solidworks批量图号分离_SolidWorks如何利用宏来快速的实现 “图号名称”分离 呢?...
- 8使用 Python 中的美丽汤进行网络数据解析的完整指南_用靓汤库解析网页源代码
- 9【MIT-6.1810】Lab: Xv6 and Unix utilities_xargs (moderate)
- 10python帅气又简单的代码,python比较炫酷的代码_python炫酷代码
如何在虚拟机上安装和配置Spark开发环境_最后我们需要校验是否安装配置成功了; 现在我们启动spark并且运行spark自带的demo
赞
踩
如何
在虚拟机上安装和配置Spark开发环境
背景:
Apache Spark是专为大规模数据处理而设计的快速通用的计算引擎。Spark是UC Berkeley AMP lab(加州大学伯克利分校的AMP实验室)所开源的类Hadoop MapReduce的通用并行框架,Spark拥有Hadoop MapReduce所具有的优点;但不同于MapReduce的是——Job中间输出结果可以保存在内存中,从而不再需要读写HDFS,因此Spark能更好地适用于数据挖掘与机器学习等需要迭代的MapReduce的算法。
下载解压安装包
我们从官网下载好安装包,
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-aF8JGJ2V-1609661845784)(https://data.educoder.net/api/attachments/224760)] 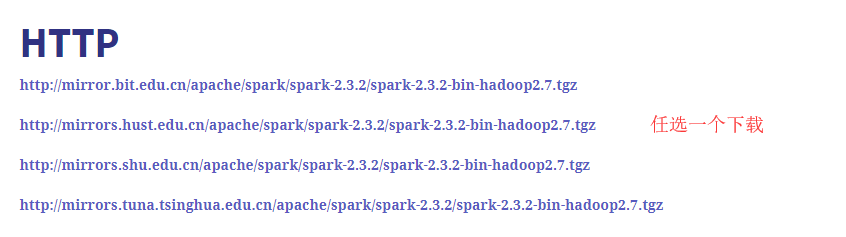
自己在虚拟机创建一个opt目录,如果你的虚拟机是6.0以上,7.0一下的版本的化你要注意,虚拟机上有opt目录的,如果是7.0以上的版本要自己创建一个opt目录,用来存储下好的Spark包:
创建存储文件:
mkdir /opt
在创建一个/app用来放解压后的文件的文件目录
mkdir /app
- 1
- 2
- 3
- 4
解压:
tar -zxvf spark-2.2.2-bin-hadoop2.7.tgz -C /app
- 1
配置环境变量:
vim /etc/profile
- 1
添加如下内容:
#set spark enviroment
$PARK_HOME=/app/spark-2.2.2-bin-hadoop2.7
export PATH=$PATH:$SPARK_HOME/bin
- 1
- 2
- 3
- 4
修改Spark配置文件
切换到conf目录下:
cd /app/spark-2.2.2-bin-hadoop2.7/conf
- 1
在这里我们需要配置的是spark-env.sh文件,但是查看目录下文件只发现一个spark-env.sh.template文件,我们使用命令复制该文件并重命名为spark-env.sh即可;
cp spark-env.sh.template spark-env.sh
- 1
接下来编辑spark-env.sh,在文件末尾添加如下配置:
export JAVA_HOME=/usr/lib/jvm/jdk1.8.0_111export SCALA_HOME=/app/scala-2.12.7export HADOOP_HOME=/usr/local/hadoop/export HADOOP_CONF_DIR=/usr/local/hadoop/etc/hadoopexport SPARK_MASTER_IP=machine_name # machine_name 根据自己的主机确定export SPARK_LOCAL_IP=machine_name # machine_name 根据自己的主机确定
- 1
参数解释:
| 参数 | 解释 |
|---|---|
| JAVA_HOME | Java的安装路径 |
| SCALA_HOME | Scala的安装路径 |
| HADOOP_HOME | Hadoop的安装路径 |
| HADOOP_CONF_DIR | Hadoop配置文件的路径 |
| SPARK_MASTER_IP | Spark主节点的IP或机器名 |
| SPARK_LOCAL_IP | Spark本地的IP或主机名 |
如何查看机器名/主机名呢?
很简单,在命令行输入:hostname即可。
如图:

校验
最后我们需要校验是否安装配置成功了; 现在我们启动spark并且运行spark自带的demo:
首先我们在spark根目录下启动spark: 在spark的根目录下输入命令./sbin/start-all.sh即可启动,使用jps命令查看是否启动成功,有woker和master节点代表启动成功。
如图:

接下来运行demo:
-
在
Spark根目录使用命令./bin/run-example SparkPi > SparkOutput.txt` 运行示例程序- 1
- 2
- 3
-
在运行的时候我们可以发现打印了很多日志,最后我们使用
cat SparkOutput.txt- 1
可以查看计算结果(计算是有误差的所以每次结果会不一样):

