
- 1深度学习进化编年大事记
- 2python绘制相关系数热力图_python相关性热力图
- 3FPGA自学4—— Modelsim仿真软件使用_fpga仿真软件有哪些
- 4Linux CentOS 本地yum配置
- 5【Linux】文件系统中inode与软硬链接以及读写权限问题_linux 链接文件的权限
- 6核心框架:spring boot、vue.js_springboot vue.js
- 7票据ticket实现方式java代码_CAS工程用redis集群存储票据ticket Spring整合
- 8一个让阿里面试官都说好软件测试简历模板_对阿里云产品测试应该怎么写简历
- 9一阶差分序列garch建模_时间序列模型stata 基本命令汇总
- 10Oracle 全局数据库名 数据库实例名 数据库服务名_oracle全局数据库名是什么
决策树算法及python实现_决策树python
赞
踩
下文只是对决策树的一个简要介绍,详细介绍:经典机器学习系列之【决策树详解】
1.什么是决策树 / 判定树(Decision Tree)?
决策树是一个类似于流程图的树结构:其中,每个内部结点表示在一个属性上的测试,每个分支代表一个属性输出,而每个树叶结点代表类或类分布。树的最顶端是跟结点。
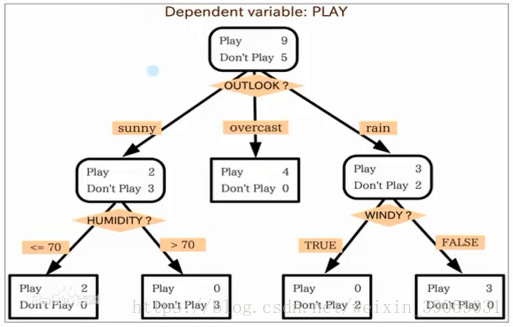
举个例子:我们用决策树来计算一下小明是否会去游泳,如上图所示,我们首先需要去窗外看一下今天什么天气吖?我们假设有三种结果:晴天、阴天、雨天,我们就可以得到上图从根结点出来的三种输出,假设是晴天,之后我们又要看湿度是多少:小于等于70,大于70两种。如果构建出来了这样的决策树的话我们就可以判断了。在方框中显示的是小明以往游泳的实例。
再举个实例说明:
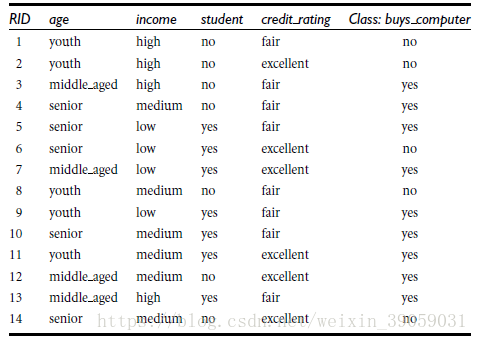
假设我们有一个用户购买电脑的数据集如上图所示。有客户的一些基本信息,还有最终是否购买电脑。这个时候我们用这些信息来构建一个决策树。构建决策树的目的就是为了判断,当一个新人进到店里面的时候,我们能够通过决策树判断 / 预测他是否会购买电脑。
那么我们如何来创建一个这样的决策树呢?
在创建决策树之前,我们需要先来了解一个概念,熵(entropy),也叫做信息熵。
我们知道信息是一个非常抽象的概念,所以我们如何来度量信息呢?由此呢,在1948年,香农提出了‘信息熵(entropy)’的概念。什么意思呢?就是一条信息的信息量大小和它的不确定性有直接关系,如果我们要搞清楚一件非常不确定的事情,或则是我们一无所知的事情,需要了解大量信息==>信息量的度量就等于不确定性的多少啦。举个例子来说,假如说我们猜世界杯冠军,加入我们一无所知,我们需要猜多少次?我们都知道世界杯有32支球队,给每只球队都编号,每次提问只能得到是或否的答案。比如第一次问冠军是不是在1-16之间,得到答案:是的,第二次问是不是在9-16之间,得到答案:不是,那我们知道答案肯定在1-8之间。这样我们一次一次往下找,就可以找出答案,2的5次方是32。这样我们最多猜五次就可以猜出来了。如果每只球队获奖的概率都是一样的话,用下面这个公式求解,我们可以得出数字5,其中p1表示第一支球队是冠军的概率,p32是第32支球队是冠军的概率。但实际上每个队夺冠的概率都是不等的,也就是我们实际上用不了五次就可以猜出冠军是哪支球队。
由此我们给出信息熵的公式:
总体表达的意思就是,变量的不确定性越大,熵就越大。
我们接下来来看一下决策树归纳算法中的几个代表:
ID3算法:
1970-1980年由J.Ross. Quinlan提出,首先我们如何判断属性结点,如上面小明游泳的例子,我们为什么要把判断天气作为跟结点?在选择结点的时候我们有很多度量标准,其中有一种叫信息获取量(Information Gain): Gain(A) = Info(D) - Infor_A(D)通过A来作为结点分类获取了多少信息。什么意思呢?就是假设我们有一个属性A,他的信息获取量等于没有它的时候的信息熵减去加上他之后的信息熵,他两之间熵的差值作为他的信息获取量。我们接下来结合上面买电脑的实例来计算一下:
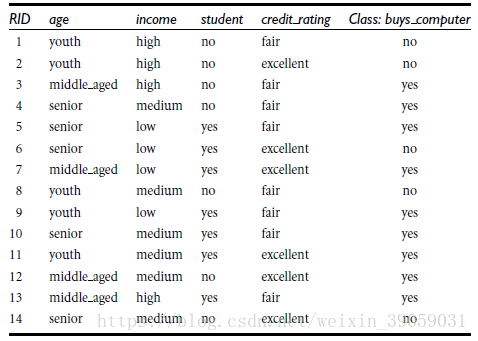
我们假设A是年龄,假设没有A的时候,本身的目标函数按是否买电脑来分,总共有14个实例,有9个买了电脑,5个没买电脑。下面这个公式就是根据没有任何属性来分类,本身这个数据集目标类属性的信息熵。
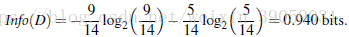
我们现在以年龄来分的话:年轻人占5/14,在这其中又有两个人买了,三个人没买,同理我们需要加上中年人,以及老年人的信息熵。

所以我们知道了没有用年龄区分的时候的信息熵为0.94,用了年龄区分的时候信息熵为0.694,他们两者之间的差值即为信息获取量:
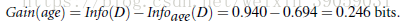
同理可以算出其他的标签的信息获取量分别是多少,所以我们选择一个信息获取量大的作为当前的根结点,也就得到了下图:
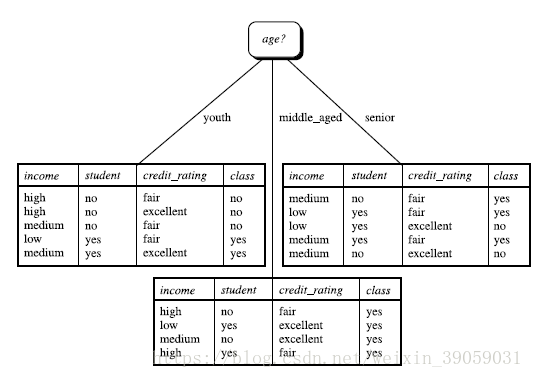
依次往下计算即可将决策树构建完成。
其他的一些算法:
C4.5算法;Classification and Regression Trees (CART)算法。
共同点:都是贪心算法,自上而下(Top-down approach)。
区别:属性选择度量方法不同:C4.5(gain ratio), CART(gain index)。
Python实例:
基于的教程:1.10. Decision Trees — scikit-learn 1.4.1 documentation
首先需要安装一些包,代码如下:
- from sklearn.datasets import load_iris
- from sklearn import tree
- import graphviz
- iris = load_iris()
- clf = tree.DecisionTreeClassifier()
- clf = clf.fit(iris.data, iris.target)
- dot_data = tree.export_graphviz(clf, out_file=None)
- graph = graphviz.Source(dot_data)
- graph.render("iris")
输出结果如下:
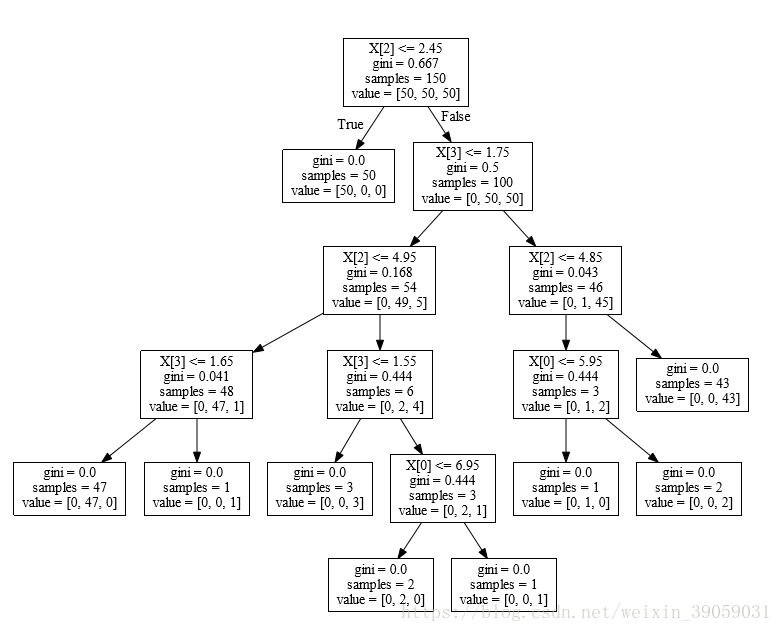
我的微信公众号名称:小小何先生
公众号介绍:主要研究强化学习、计算机视觉、深度学习、机器学习等相关内容,分享学习过程中的学习笔记和心得!期待您的关注,欢迎一起学习交流进步!


