
- 1日内跌幅超20%,Arkham团队套现砸盘还是另有隐情?
- 2特征降维与自然语言处理:从文本摘要到情感分析
- 3【占坑】Pre-train 与 Fine-tuning_pre-train和fine tuning
- 4Hoppscotch:开源 API 开发工具,快捷实用 | 开源日报 No.77_hoppscotch公共
- 5FPGA——MOS管_fpga mos管怎么控
- 6hotmail 邮件怎么在foxmail里面挂_这样发简历邮件,HR根本不会点开
- 7不出网上线CS的各种姿势_reduh上线cs
- 8深度学习第一弹: PyCharm和Anconda的安装与配置_pycharm和anaconda实现深度学习
- 9操作系统真象还原:保护模式入门
- 10机器学习-09-图像处理02-PIL+numpy+OpenCV实践_noisy-rectangle
⑦ MySQL物理存储索引结构&Innodb存储结构_mysql 物理存储
赞
踩
索引是存储引擎中用于快速高效获取数据的 数据结构;可以理解为排好序的快速查找数据结构;
索引的优缺点:
优点:
1.提高数据检索的效率,降低磁盘的IO;
2.加速表与表之间的连接;
3.在使用分组或者排序的时候,显著减少查询中分组与排序的时间;
缺点:
1.创建与维护索引需要消耗时间;
2.索引数据需要占磁盘空间;
3.索引提示查询速度的同时,降低了更新表的速度;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
1 索引的数据结构
MySQL数据按照数据页进行存储,每条记录通过链式连接存储,数据页与数据页之间也通过双向链表连接存储;
1.1 设计索引
一条记录通过行格式实际存储数据:
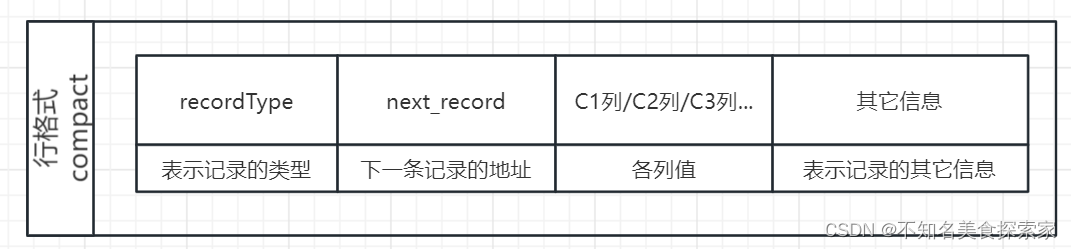
recordType = 2 最小的记录
recordType = 0 普通数据的记录
recordType = 3 最大的记录
recordType=1 数据目录页的记录
记录通过链表连接;
数据库底层按照数据页来存储数据:
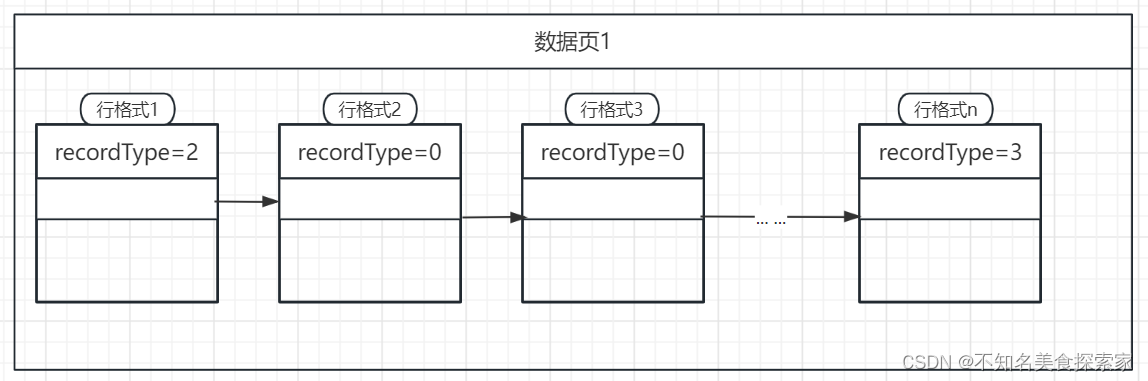
数据页与数据页之前通过双向链表连接;
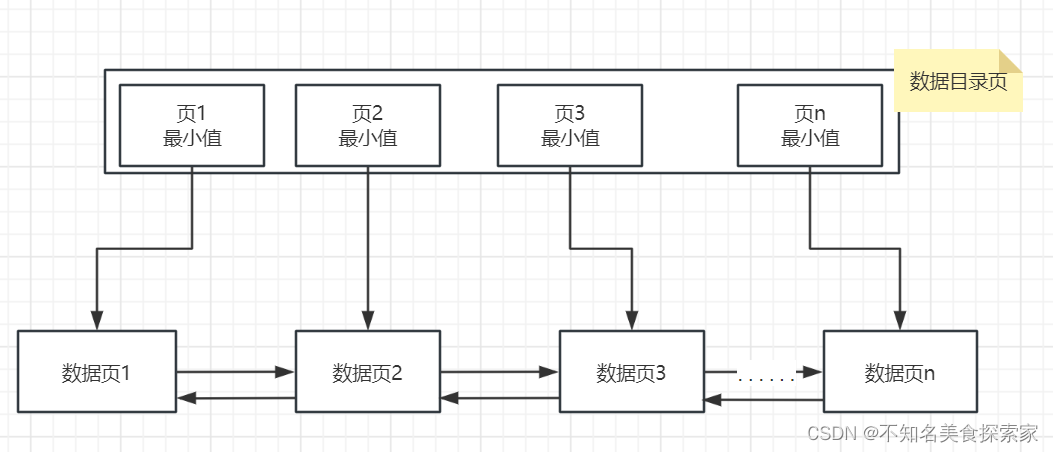
为了方便快速查找,通过类似普通数据页的方式组织数据页相关的信息构成目录数据页:
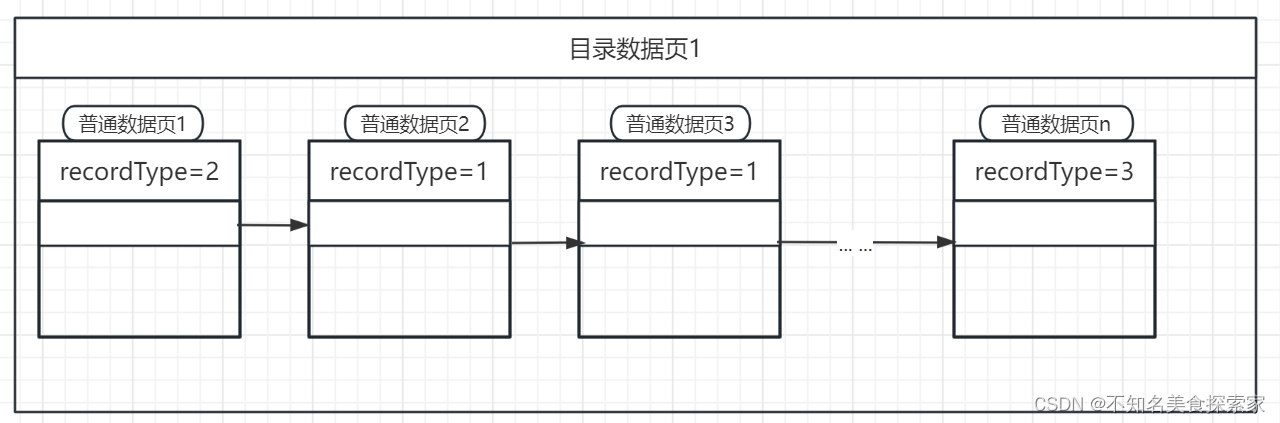
为更加快速的查找目录数据页,就会再生成更上层的目录数据页来记录:
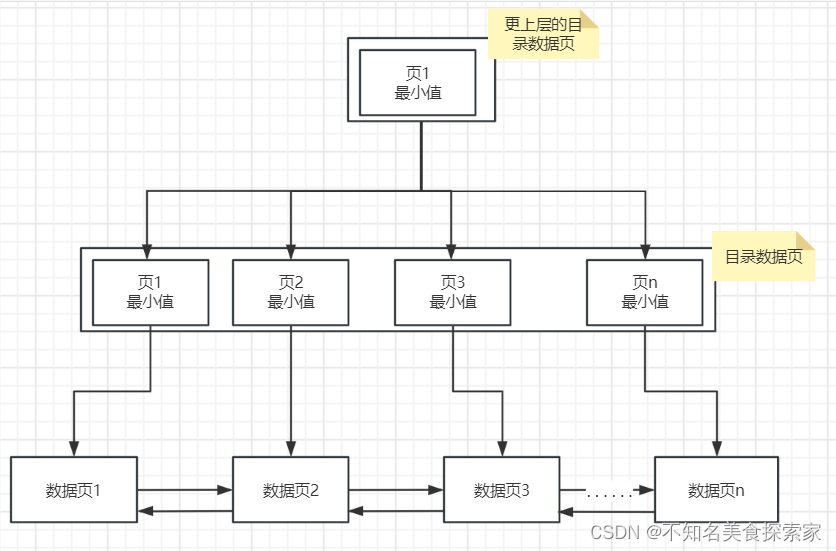
这样的数据结构名称就成为B+树
这种结构特性成为聚簇索引,InnoDB存储引擎会自动创建聚簇索引;
1.2 常见的索引概念
索引按照物理实现方式分为:聚簇索引与非聚簇索引
聚簇索引不是索引类型,而是一种数据存储的方式;
聚簇表示实际的数据行和相邻的键值聚簇的存储在一起;
聚集索引的优点:
1.数据访问速度快,因为聚集索引的索引与实际数据存在于同一个B+树;
2.聚集索引对于主键的排序和范围查找速度非常快;
3.聚集索引减少了大量的IO操作;
聚集索引的缺点:
1.插入速度依赖顺序,可能发生页裂变,严重影响性能,所以一般聚集索引采用主键自增的方式去维护
限制:
1.mysql表中只能有一个聚集索引,一般情况为表的主键;
2.只有InnoDB支持聚集索引,myISAM不支持聚集索引;
3.如果没有定义主键,InnoDB会自动取一个非空唯一索引作为聚集索引,如果再没有,则数据表隐藏维护一个主键作为聚集索引;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
非聚集索引比如非主键字段维护的B+树索引结构;
非聚集索引的查找:先查找非聚集索引B+树,然后回表查找聚集索引的B+树,最后找到查询结果;
联合索引:多个字段一起作为主键创建聚集索引;
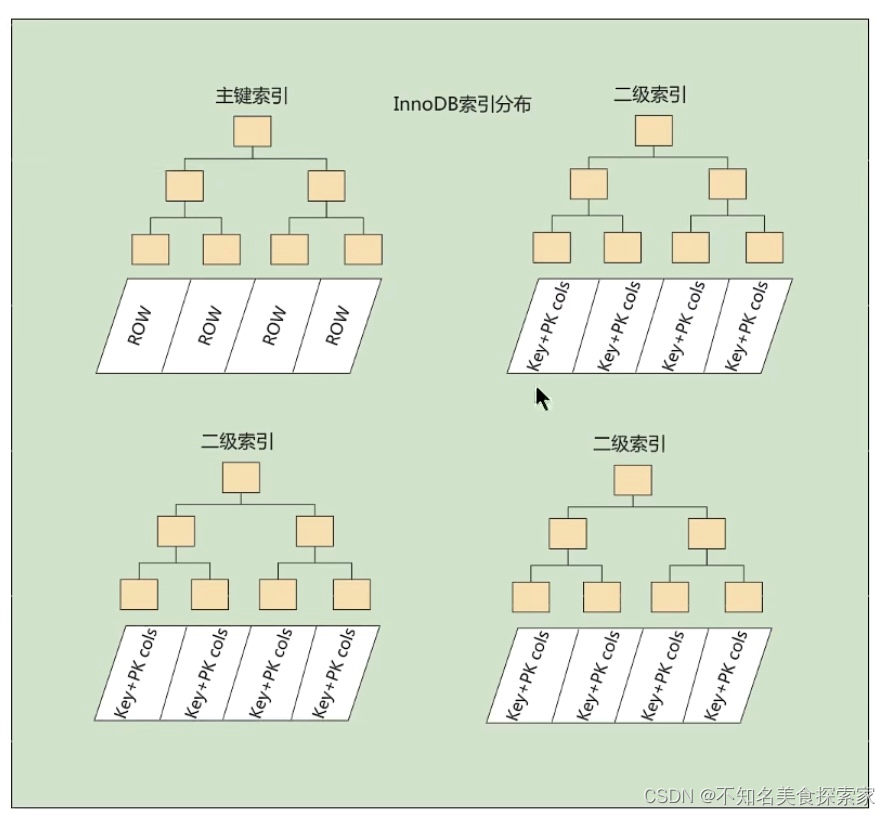
聚集索引与非聚集索引的区别:
1.聚集索引的叶子节点存储的是实际的数据记录,非聚集索引叶子结点存储的是数据位置,非聚集索引不会影响物理表的存储顺序;
2.一个表只能有一个聚集索引,但是可以有多个非聚集索引;
3.使用聚集索引的时候数据的查询效率高,对数据进行写操作时,非聚集索引效率更高。
- 1
- 2
- 3
1.3 InnoDB中B+树索引
B+树实际根节点不会动
(1)B+树实际是先创建根节点,用户的数据实际先存储在根节点中,等到根节点数据页空间用完时,再插入数据的时候,根节点会将数据复制到新的页1,再进行页裂变,页2存储这个新的数据;
(2)页1和页2就会组织成聚簇索引叶子节点的数据页格式,对应存储 主键-实际数据数据 ,并主键排序;
(3)根节点边升级为记录目录项的目录数据页;
(4)当根节点记录目录项存储空间用完后,新增一个目录记录时,根节点会复制当前的数据页作为子节点,然后页列表生产另一个子节点记录新的目录。根节点则会升级为目录页上层的目录记录数据页;
- 1
- 2
- 3
- 4
MyISAM通过B树来进行数据存储实现
(1)MyISAM只支持非聚簇索引,myISAM索引和数据分开存储的;
(2)底层文件中myISAM存储引擎的索引和实际表数据在不同的两个文件;
(3)myISAM的B树的叶子节点存储的是:主键 + 数据记录的地址;
(4)MyISAM存储引擎的B树叶子节点存储的是主键值 + 数据记录的地址;myISAM的主键索引和二级索引没有太大的区别,只是myISAM要求的主键是唯一的,二级索引可以重复;
- 1
- 2
- 3
- 4
myISAM与InnoDB的对比
1.在InnoDB中会有一个聚簇索引,在myISAM中都是非聚簇索引,根据主键查找数据,InnoDB会根据主键直接找到数据并返回,myISAM会在B数中找到数据地址回表查找到数据再返回;
2.从底层数据存储来说,InnoDB主键索引与数据存储在一起的,myISAM的主键索引与实际数据存在两个不同的文件中;
3.非主键索引的情况下,myISAM通过地址回表会比InnoDB对聚簇索引回表找数据快;
4.InnoDB必须有主见,myISAM可以没有;
- 1
- 2
- 3
- 4
索引的代价
1.每建立一个索引就会建立一个B+树,一个B数的一个节点就是一个数据页,数据页默认占16KB的空间,因此需要一定存储空间来维护索引,数据量越大,存储空间就会越大;
2.当出现增删改操作的时候,因为B+数的节点数据页内都是按照大小顺序排列的,无论是内节点还是实际数据页,都可能发生页裂变,或者页回收,来重新维持B+树的数据规则,需要浪费一定的时间;
- 1
- 2
2 InnoDB数据存储结构
2.1 页结构
1.数据行及索引数据都是存在数据页中,数据页是内存与磁盘交互的基本单位,数据页的默认大小是:16kb;
2.记录是按照行来存储的,行存储方式称为行格式,行格式存储在数据页中;
3.数据页与数据页之间通过双向链表连接,数据页中的数据通过主键大小顺序连接,数据页会为存储在页内的记录生成页目录,能够通过二分法快速定位到指定记录;
- 1
- 2
- 3
查看数据页大小:SHOW VARIABLES LIKE '%innodb_page_size%'
B+树如何进行记录检索的:
1.从根节点开始逐步遍历,然后进行逐层检索,直到找到叶子节点
2.找到叶子节点后,将数据页加载到内存中,通过页目录进行二分查找,找到粗略的分组
3.在通过分组进行链表遍历找到需要查询的记录行
2.2 行格式
1.行格式是数据行记录的单位,行格式之间通过单链表连接;
2.当行溢出时,数据会存储到其它数据页中去;
- 1
- 2

