
- 1播放dlna服务器上文件,群晖使用教程:DLNA/UPnP协议和Kodi在多设备上播放媒体文件...
- 2【R语言技巧】apply家族篇 sumNotes_eqtl-a-ensg的gwasid
- 3集成google+1组件,提示There was a temporary problem with your +1 Please try again later_there was a probloem coummunicating with google se
- 4windows配置pm2开机自启动_windows重启后,如何自动启动pm2
- 5G0第25章:Go Web进阶项目实战_gin框架项目实战
- 6Python 人工智能实战:智能交通_python智能公交系统 csdn
- 7C++学习网站收藏_hackingcpp网站
- 8Android——发送和接收广播
- 9【安卓学习笔记】Android Studio第9课——进度条ProgressBar、SeekBar和RatingBar_android中进度条用法
- 10专升本常考的C语言编程代码_c语言程序大全
设计原则之【迪米特法则】,非礼勿近
赞
踩
全网最全最细的【设计模式】总目录,收藏起来慢慢啃,看完不懂砍我
一、什么是迪米特法则
迪米特原则(Law of Demeter LoD)是指一个对象应该对其他对象保持最少的了解,又叫最少知道原则(Least Knowledge Principle,LKP),尽量降低类与类之间的耦合。迪米特原则主要强调只和朋友交流,不和陌生人说话。出现在成员变量、方法的输入、输出参数中的类都可以称之为成员朋友类,而出现在方法体内部的类不属于朋友类。
其含义是:如果两个软件实体无须直接通信,那么就不应当发生直接的相互调用,可以通过第三方转发该调用。其目的是降低类之间的耦合度,提高模块的相对独立性。
迪米特法则中的“朋友”是指:当前对象本身、当前对象的成员对象、当前对象所创建的对象、当前对象的方法参数等,这些对象同当前对象存在关联、聚合或组合关系,可以直接访问这些对象的方法。
1、理解迪米特法则
不该有直接依赖关系的类之间,不要有依赖;有依赖关系的类之间,尽量只依赖必要的接口。迪米特法则是希望减少类之间的耦合,让类越独立越好。每个类都应该少了解系统的其他部分。一旦发生变化,需要了解这一变化的类就会比较少。
2、如何理解“高内聚、松耦合”?
“高内聚、松耦合”是一个非常重要的设计思想,能够有效提高代码的可读性和可维护性,缩小功能改动导致的代码改动范围。“高内聚”用来指导类本身的设计,“松耦合”用来指导类与类之间依赖关系的设计。
所谓高内聚,就是指相近的功能应该放到同一个类中,不相近的功能不要放到同一类中。相近的功能往往会被同时修改,放到同一个类中,修改会比较集中。所谓松耦合指的是,在代码中,类与类之间的依赖关系简单清晰。即使两个类有依赖关系,一个类的代码改动也不会或者很少导致依赖类的代码改动。
二、实例
1、实例1
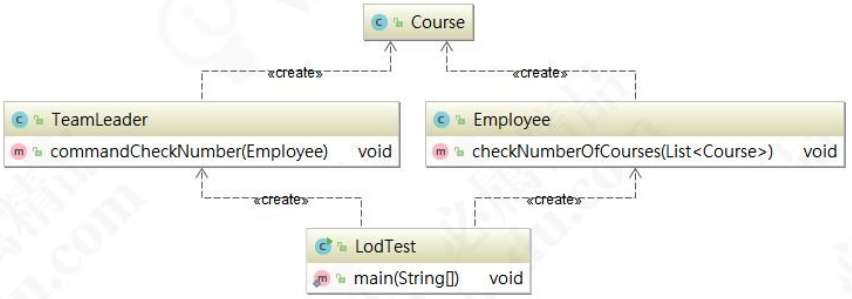
现在来设计一个权限系统,TeamLeader需要查看目前发布到线上的课程数量。这时候,TeamLeader要找到员工 Employee 去进行统计,Employee 再把统计结果告诉 TeamLeader。接下来我们还是来看代码:
public class Course { } public class Employee{ public void checkNumberOfCourses(List<Course> courseList){ System.out.println("目前已发布的课程数量是:" + courseList.size()); } } public class TeamLeader{ public void commandCheckNumber(Employee employee){ List<Course> courseList = new ArrayList<Course>(); for (int i= 0; i < 20 ;i ++){ courseList.add(new Course()); } employee.checkNumberOfCourses(courseList); } } public static void main(String[] args) { TeamLeader teamLeader = new TeamLeader(); Employee employee = new Employee(); teamLeader.commandCheckNumber(employee); }

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
写到这里,其实功能已经都已经实现,代码看上去也没什么问题。根据迪米特原则,TeamLeader只想要结果,不需要跟 Course 产生直接的交流。而 Employee 统计需要引用 Course 对象。TeamLeader和 Course 并不是朋友,从下面的类图就可以看出来:
下面来对代码进行改造:
public class Employee {
public void checkNumberOfCourses(){
List<Course> courseList = new ArrayList<Course>();
for (int i= 0; i < 20 ;i ++){
courseList.add(new Course());
}
System.out.println("目前已发布的课程数量是:"+courseList.size());
}
}
public class TeamLeader {
public void commandCheckNumber(Employee employee){
employee.checkNumberOfCourses();
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
再来看下面的类图,Course 和 TeamLeader 已经没有关联了。
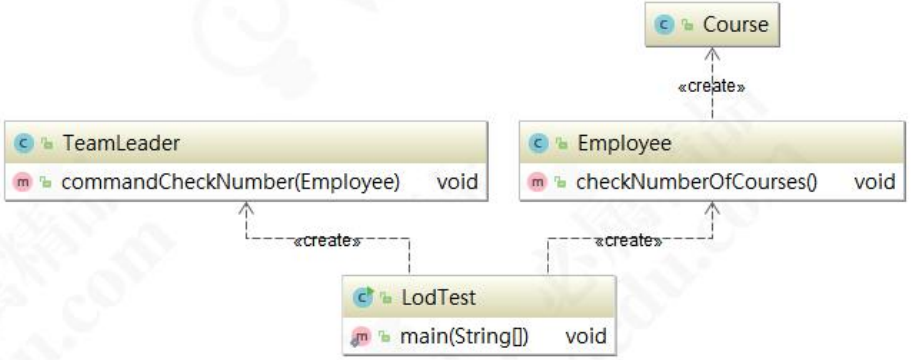
迪米特法则的核心是降低类之间的耦合。
但是要注意:由于每个类都减少了不必要的依赖,因此迪米特法则只是要求降低类间(对象间)耦合关系,并不是要求完全没有依赖关系。
2、实例2
我们实现一个简化版的搜索引擎爬取网页的功能。代码中包含三个主要的类。其中,NetUtil 类负责底层网络通信,根据请求获取数据;HtmlDownloader 类用来通过 URL 获取网页;Document 表示网页文档,后续的网页内容抽取、分词、索引都是以此为处理对象。
public class NetUtil{ // 省略属性和其他方法... public Byte[] send(HtmlRequest htmlRequest) { //... } } public class HtmlDownloader { private NetUtil netUtil;//通过构造函数或IOC注入 public Html downloadHtml(String url) { Byte[] rawHtml = netUtil.send(new HtmlRequest(url)); return new Html(rawHtml); } } public class Document { private Html html; private String url; public Document(String url) { this.url = url; HtmlDownloader downloader = new HtmlDownloader(); this.html = downloader.downloadHtml(url); } //... }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
我们分析一下这三个类,虽然看起来没什么问题,但是仍有优化的空间。
首先看NetUtil类,作为一个工具类,应该尽可能的“通用”,send方法不应该依赖HtmlRequest 。
public class NetUtil {
// 省略属性和其他方法...
public Byte[] send(String address, Byte[] data) {
//...
}
}
- 1
- 2
- 3
- 4
- 5
- 6
我们修改了NetUtil 类,那么HtmlDownloader 也应该同步修改:
public class HtmlDownloader {
private NetUtil netUtil;//通过构造函数或IOC注入
public Html downloadHtml(String url) {
HtmlRequest htmlRequest = new HtmlRequest(url);
Byte[] rawHtml = netUtil.send(htmlRequest.getAddress(), htmlRequest.getContent().getBytes());
return new Html(rawHtml);
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
Document类构造方法中downloadHtml耗时较长,不应该放在构造方法中,影响代码的可测试性;
HtmlDownloader 对象在构造函数中通过 new 来创建,违反了基于接口而非实现编程的设计思想,也会影响到代码的可测试性;
从业务含义上来讲,Document 网页文档没必要依赖 HtmlDownloader 类,违背了迪米特法则。
ublic class Document { private Html html; private String url; public Document(String url, Html html) { this.html = html; this.url = url; } //... } // 通过一个工厂方法来创建Document public class DocumentFactory { private HtmlDownloader downloader; public DocumentFactory(HtmlDownloader downloader) { this.downloader = downloader; } public Document createDocument(String url) { Html html = downloader.downloadHtml(url); return new Document(url, html); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23


