
- 1【喂饭级AI教程】手把手教你在本机安装Stable Diffusion秋包【附带全套资源】_秋叶stable diffusion安装包
- 2spring boot破解xjar.go加密后的jar包
- 3hbase中创建表、插入数据,更新数据,删除数据_编程实现在hbase下的建表,插入数据,浏览数据,关闭
- 4253.【华为OD机试】田忌赛马(贪心算法-Java&Python&C++&JS实现)_田忌赛马 od
- 5谈谈工业通信协议的采集和转换-如modbus opc profinet ethernetIP 61850等_opc协议转换映射
- 6张一鸣辞职,没那么简单
- 7【华为OD】C卷真题:100分:小朋友至少有几个 C语言代码实现【思路+代码】_计算幼儿园小朋友至少有几个 c语言
- 8《机器学习by周志华》学习笔记-线性模型-02
- 9几大主流的前端框架(UI/JS)框架
- 10API 接口应该如何设计?如何保证安全?如何签名?如何防重?_api接口设置
鹅厂程序员亲测AI写真通用版,女友直呼“真妙呀”!
赞
踩
 # 关注并星标腾讯云开发者
# 关注并星标腾讯云开发者
# 每周4 | 鹅厂一线程序员,为你“试毒”新技术
# 第4期 | 腾讯霍然:鹅厂大牛手把手教学,让自己实现数字分身?

时下流行的 AI 写真工具,为用户提供了用现成的照片遨游于广袤素材与想象中的可能性,也启发 AI 从业者对于大众消费产品的构想。对于个人来说,是否可以上手 AI 技术,做出自己的“数字分身”呢?本文将介绍一种高效率、易上手、低成本、高安全的“数字分身”制作方式。看完本文,你也会用一张图片“穿越古今”,做出自己的 N 个“数字分身”。

图1,作者使用 Stable Diffusion 制作的美女“数字分身”集
随着网络某相机小程序的火爆,关于 AIGC 智能应用的讨论又一次点燃移动互联网。9.9 元即可制作不同背景、造型下的“数字分身”照片,出图效果几可比拟专业照相馆,引发了受众的追捧。
而质疑者,认为 9.9 元的体验成本过高,也觉得产品高峰期的数十小时的等待时长过于熬人。苦恼于无法对生产的照片任意加工,更为 AI 应用的数据安全性忧心忡忡。
这些想法也反映了广大用户对于 AI 应用的需求和渴望。对于 AI 工具,用户希望既可以降低使用成本,又可以保证生产效果。如果还能简化生产流程、缩短生产时长、提供便于交互的服务,同时保证数据安全性,当然更佳。
那么,所谓的 AI“数字分身”领域,或是“AI 写真”领域为例,是否有一个满足以上所有要求的方案呢?
制作个人的 LoRA 模型是一种生成“数字分身”的方式,也被一些用户猜测为“AI 写真小程序”的技术方案。
这种方法可以生成较为稳定的、多角度的人像,但是其需要输入的照片较多,技术实现的步骤也稍复杂,对于新手的使用门槛较高,文中不做介绍。
本文将由浅入深地介绍一种小白可以轻松上手的简易“数字分身”制作方式,基本满足用户对 AI 应用的要求。
本文介绍的“数字分身”制作方法可以通过 AI 技术随意更换照片中人物的服装、造型、背景,用一张人像照片“穿越古今”。读者可以拿 9.9 元买一杯蜜雪冰城,在家里“一键出图”。
整个产图流程可以在个人计算机的服务器完成,不需要把照片上传到外部服务器,极大地保障数据的安全性。同时,千变万化的服装、背景、造型更是令人眼花缭乱,AI 的创意指数拉满,令人拍案叫绝。

图2,作者使用 Stable Diffusion 制作风格各异的美女“数字分身”
制作“数字分身”的过程需要解决 3 个问题:
画什么?用什么?参考什么?
针对这 3 个问题,产生了 3 个步骤:
画什么:填写描述词;
用什么:上传图片并选择重绘区域;
参考什么:提供参考的人物姿态。
下面将按照这 3 点依次介绍。下文用到的工具为 Stable Diffusion WebUI,以及 ControlNet 插件。为了简化内容,本文介绍便捷有效的实操步骤,Stable Diffusion 的安装和精细化调参技能点请读者自行学习,文末附有参考材料。

图3,文章核心步骤的示意图
“画什么”的问题在用文字形式模拟用户脑海中的想象。
小时候,男生幻想自己穿着侠客的青衫,仗剑走天涯;女生幻想自己穿着飘逸的襦裙,沐浴唐风汉韵。如今的 AI 技术可以借助语言描述,让我们在风格各异的场景中塑造个人形象。建立这一形象,首先需要用语言描述人物的服装、发型、背景,描述语言称为提示词。
提示词分为正向提示词(希望画面出现的内容)和负向提示词(不希望画面出现的内容)。绘图用的 Stable Diffusion 为国际化工具,提示词要用英语。
比如生成一个穿着古装汉服的女孩,女孩佩戴精美发簪,以传统的中式宫殿为背景;同时,希望图片高质量、高清晰,不要出现模糊、丑陋、动画等元素。将正向提示词写为“1girl, wearing song hanfu, wearing delicate traditional chinese hairpins, chinese palace background, materpiece, best quality, ultra-detailed”。负向提示词写为“blurry, ugly, bad quality, cartoon, anime, NSFW, nude”。
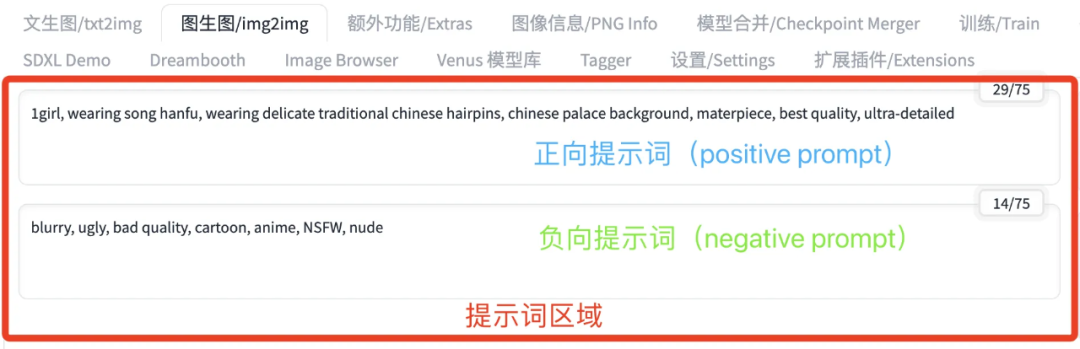
图4,Stable Diffusion WebUI 的提示词输入界面
“用什么”在追问图片生产过程中的主要原料是什么。
本文介绍简易的“数字分身”制作过程,用现成的照片换掉照片中的造型、服饰、背景,达到“一键穿越”的效果。 在此过程中,用到的原料是现有的照片,应用的技术为 Stable Diffusion 的图生图局部重绘(img2img inpaint)功能。涉及到的操作为上传图片并手动选择重绘区域。选择照片时,建议选择上半身,面部轮廓清晰的正面照。比如,以一张年轻女性的正面半身照作为输入。

图5,上传的照片示例
上传图片后,我们把“换造型,换服装”的需求转换为技术语言“重绘除了脸部之外的所有区域”。那么,AI 工具如何知道照片中哪里是面部区域呢?在使用时,先上传图片,再用黑色的笔刷手动涂抹面部区域,就能精准地标识面部区域,如图 6 所示。
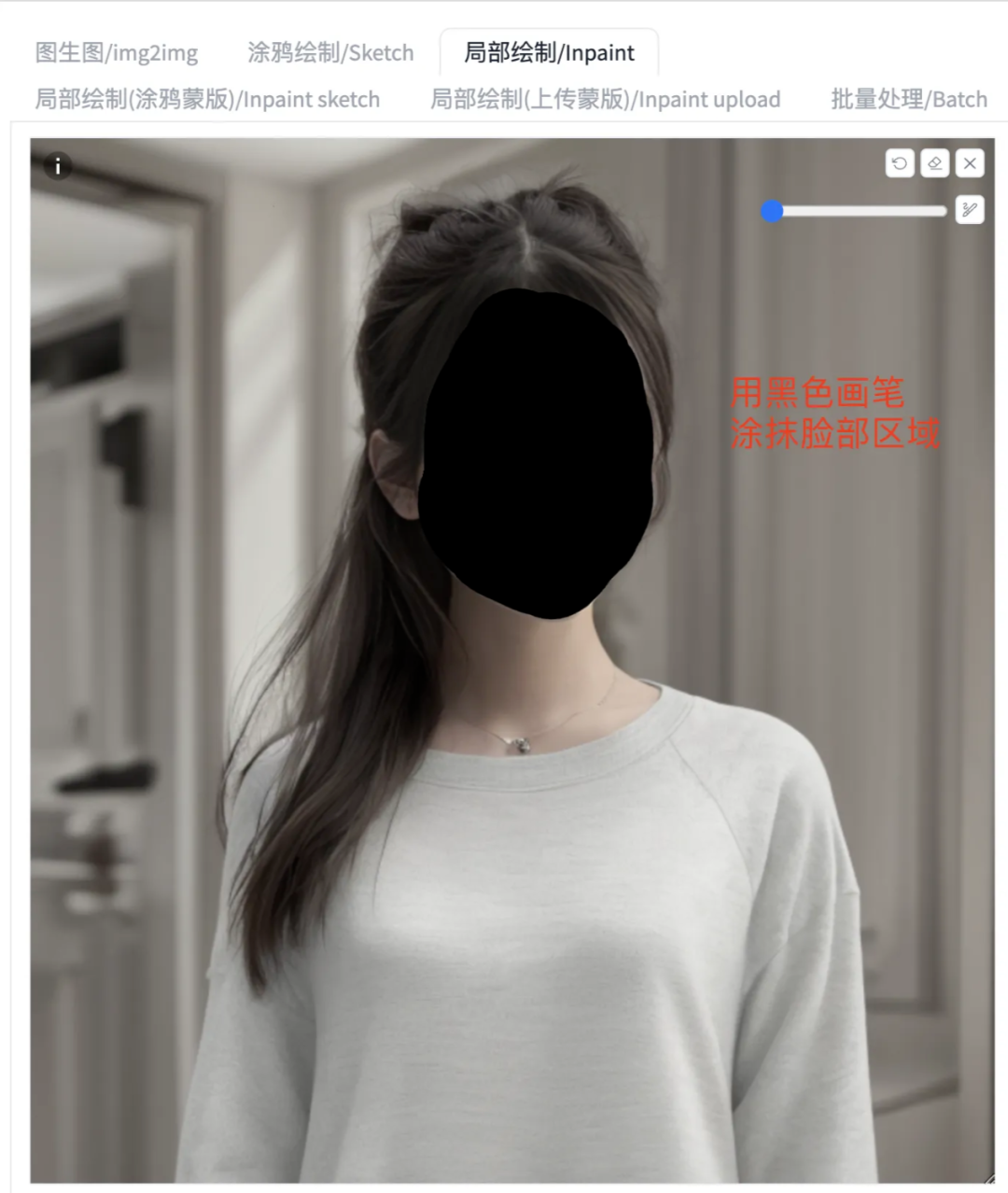
图6,涂抹上传照片的功能示例
此外,还需要选择对非涂抹区域进行重绘的选项(inpaint not masked),也就是对于除面部外的区域进行新的创作,如图 7 所示。

图7,选择“绘制非蒙版内容”操作示例
“参考什么”则是结合什么辅助信息,让图片生产的效果更稳定。
既然是参考,则非必需,但是有利于提升图片生产的质量。上面的两个步骤为 AI 描绘了绘图内容,也提供了人像的脸部特征。此时若是让 AI 工具“信马由缰”地发挥,容易出现人体比例失调,动作不自然等问题。为 AI 工具提供“参考答案”虽然会减少创意空间,但是能让 AI 工具学习原照片的动作姿态,生成更加自然的图片。如何学习人物姿态呢?学习人物姿态需要用到 ControlNet 插件,一款对图片进行预加工的工具,把预加工的结果像积木块一样拼插到生成图片的流程中。
输入和上一步相同的正面半身照,用 ControlNet 插件中的 openpose 预处理器学习图中人物姿态,比如头和身体位置关系,手臂的动作。按照图 8 的方式选择启用 ControlNet 插件,并选择 openpose 预处理模式和模型。
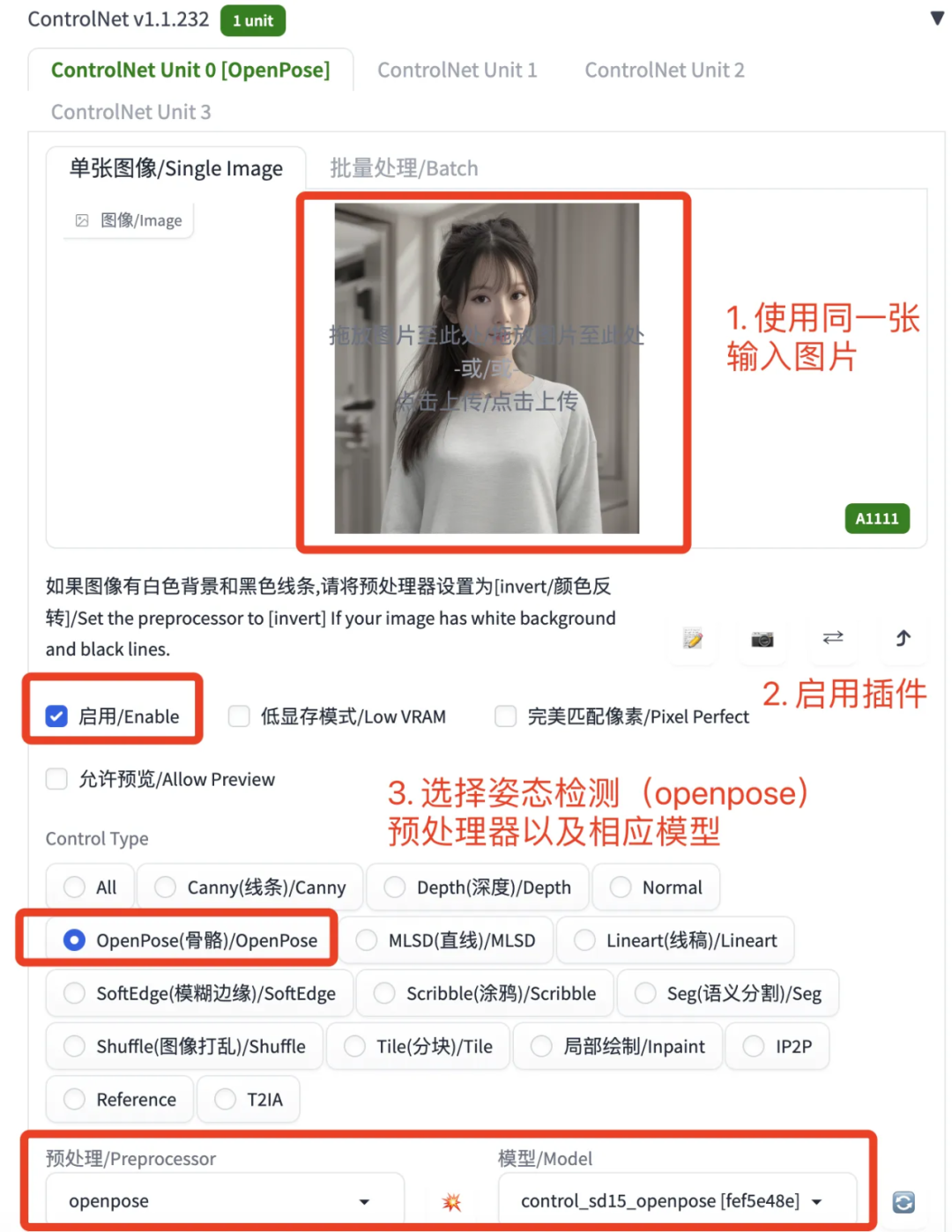
图8, ControlNet 插件的使用示例
进行上述操作后,就可以得到图 9 的多款古装美女“数字分身”。

图9,通过 Stable Diffusion WebUI 制作的古装美女“数字分身”
那么如果想制作更多的分身,读者应该修改前文介绍的哪些步骤呢?
读者可以回顾,思考一下本文介绍的方法。前面介绍的 3 个步骤中,“画什么”的步骤决定图片内容,“用什么”的步骤决定核心素材,“参考什么”的步骤决定额外的素材。
回顾后发现,当我们想对画面元素做修改时,只需要修改“画什么”步骤中的提示词。比如想要生成现代装校园风图片,只需要重写正向提示词中涉及服装,造型,背景的提示词,将正向提示词改写为“1girl, wearing school uniform, ponytail, campus background, materpiece, best quality, ultra-detailed”。负向提示词仍然写为“blurry, ugly, bad quality, cartoon, anime, NSFW, nude”,如图 10 所示。
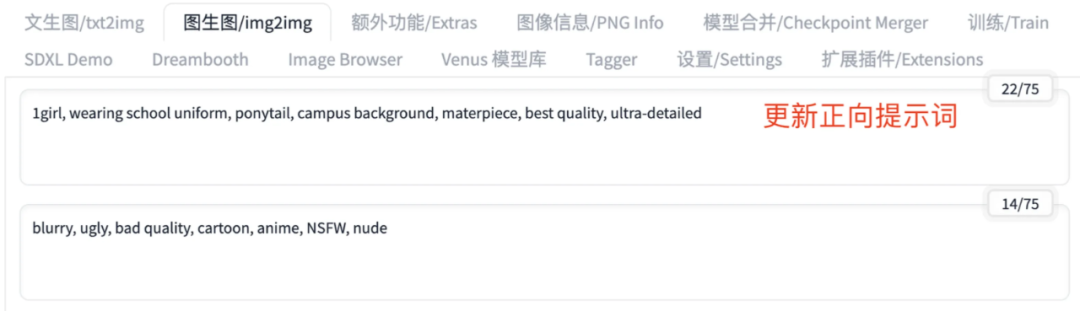
图10,更新 Stable Diffusion WebUI 的提示词示例
除了修改正向提示词外,其他步骤均保持不变。点击“生成”按钮,就能得到图 11 的“校园女孩分身”。
得到“数字分身”后,如果读者希望进一步修改图片细节,比如重新生成背景中的建筑物,可以用局部重绘功能涂抹待修改的细节,仿照上面的指引,用提示词来牵引重绘方向,具体操作交给读者探索。

图11,通过 Stable Diffusion WebUI 制作的校园美女“数字分身”
按照这种方式不断解锁校园风、古代风、未来感、中式旗袍、日常风的造型,就得到了文章开头异彩纷呈的“数字分身集”。

图12,作者使用 Stable Diffusion 制作的美女“数字分身”集
写到最后,对比一下本文通过 Stable Diffusion WebUI 制作“数字分身”的方案和 AI 写真小程序在用户体验方面的异同。
两种方法的相同点为:以人像照片为输入,通过技术手段获得不同场景、造型的人像写真图。
除此之外,两者在使用体验方面有较大的差异。在成本方面,AI 写真小程序需要更多“有形投资”,比如更多的照片数量,更高的费用;而本文的方法有更多的“无形投资”,比如部署和使用 Stable Diffusion 的能力。
在收益方面,AI 写真小程序在生成图片的角度和颜值上有优势,画面自然感更高;而本文的方法在生成图片的造型、背景丰富度以及再加工能力上更胜一筹。
期待大家可以用 AI 技术拓展生活的疆域。
如果读者朋友们想进一步学习如何部署 Stable Diffusion 以及如何精细化调参,可以参考腾讯云开发者的这篇文章《给想玩AI的新手|Stable Diffusion 保姆级入门手册》。
有了自制的 AI 写真工具,你最想生成哪些照片?或者想在工具里面加入哪些功能?欢迎留言。我们将挑选一则最有趣的答案,为其留言者送出腾讯定制T恤。8月31日中午12点开奖。

Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

