
- 1Linux功耗管理(18)_Linux cpuidle framework(1)_概述和软件架构_linux cpuidle wfi
- 2android安卓记事本课设_安卓记事本app课程设计
- 3如何保护您的SpringBoot项目:防止源代码泄露,确保更安全的部署_spring 泄露
- 4Hadoop单机环境搭建_hadoop单机版访问hdfs
- 5数据资产管理的艺术:构建智能化、精细化的数据资产管理体系,从数据整合、分析到决策支持,为企业提供一站式的数据资产解决方案,助力企业把握数字时代的新机遇
- 6论文《Learning the quantum algorithm for state overlap 》阅读笔记
- 7智能信息检索——期末复习题库_在 10,000 篇文档构成的文档集中,某个查询的相关文档总数为 10,下面给出了某系 统
- 8Lianwei 安全周报|2024.07.01
- 9华为OD 技术综合面,手撕代码真题整理(七):字符串的不重复子串 | 二叉树的最大路径和_华为od面试手撕代码python
- 10ELK笔记
【实战案例】python爬取百度图片
赞
踩
网络爬虫的本质就是模拟客户端发送请求,一个爬虫的基本开发流程包含五步:
1、明确目标数据
2、分析数据的请求流程
3、模拟发送请求
4、解析数据
5、数据持久化
一、明确目标数据
我们要下载的是百度图片首页中的图片
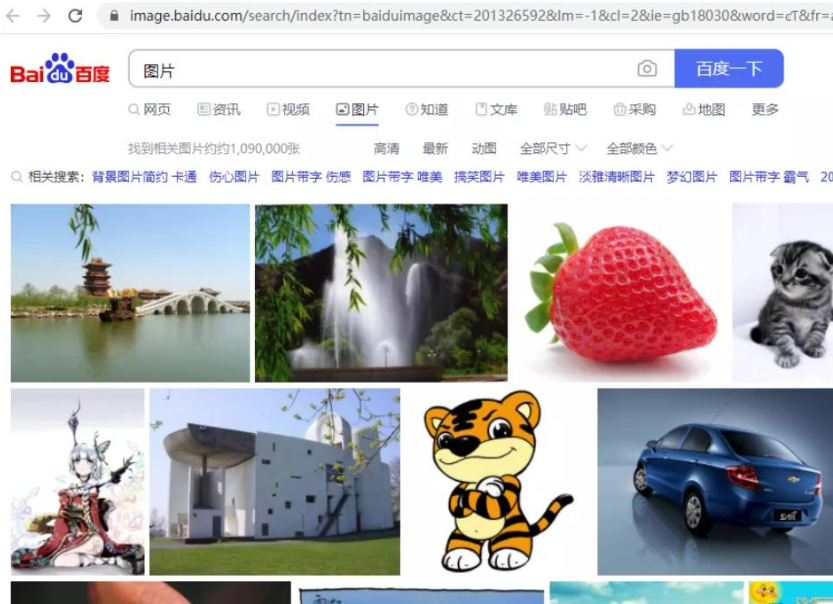
网页中的图片是浏览器通过 http 请求下载回来的。
浏览器会先下载图片的 url,再通过 url 下载图片。
所以我们只要找到图片 url 的 http 请求即可。
一般情况下,页面中的图片 url 就包含在页面的 HTML 文档中,使用谷歌浏览器开发者调试工具获取图片的 url
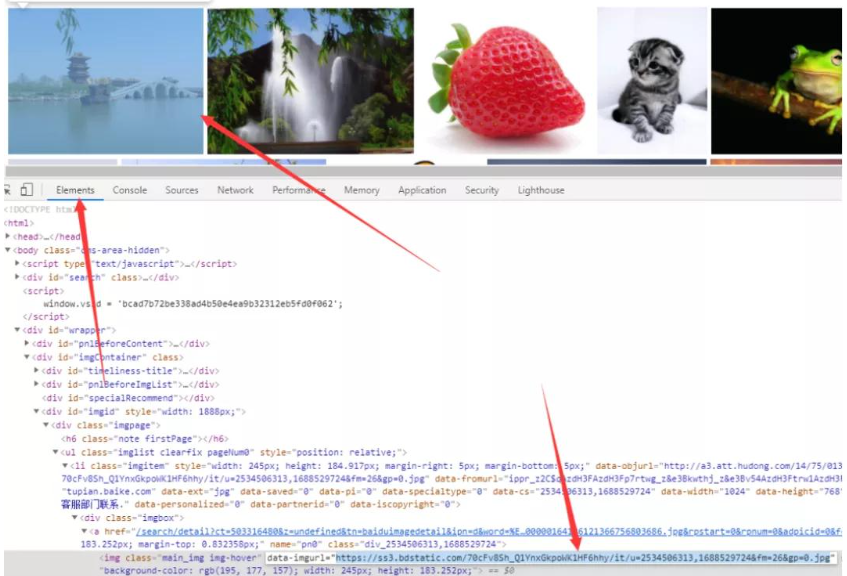
然后右键查看网页源文件可以查看当前页面的 HTML 文档
ctrl+f 调出搜索框,把前面找到的图片的 url 粘贴进来,果然发现了 url 就在 HTML 中
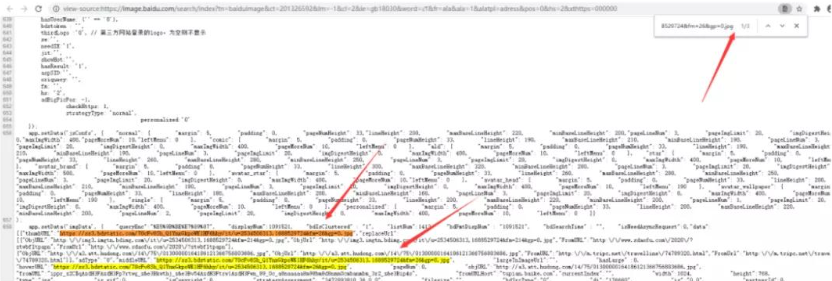
为了稳妥可以多找几张图片的 url 测试。发现页面中的前 30 张图片的 url 都在 HTML 文档中。
二、分析数据请求流程
在 HTTP 协议中信息以二进制的形式进行传输的,我们需要借助工具来分析 HTTP 请求。常用工具有,谷歌浏览器和 fiddler。
fiddler 的使用和安装相对复杂,谷歌浏览器可以满足大部分的请求流程分析,这里主要介绍谷歌浏览器。
谷歌浏览器提供了开发者调试工具,能够对浏览器的 HTTP 请求进行监控,按功能键 F12 即可打开工具界面,功能窗口如下:
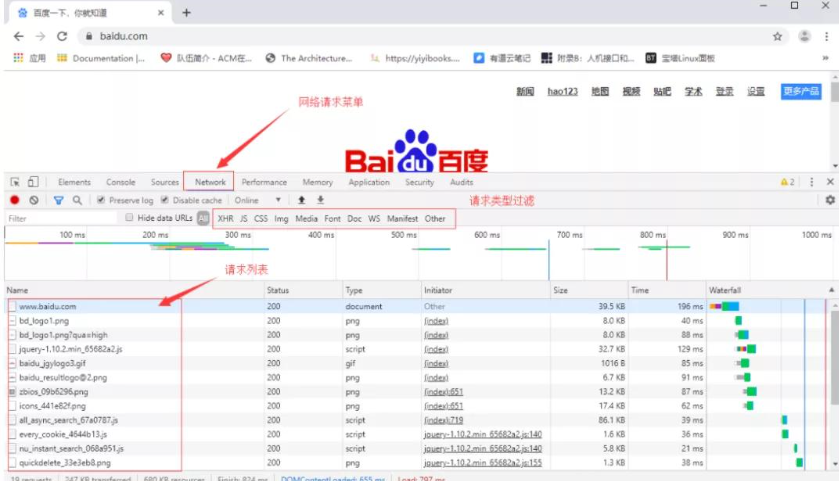
点击某个具体的请求后
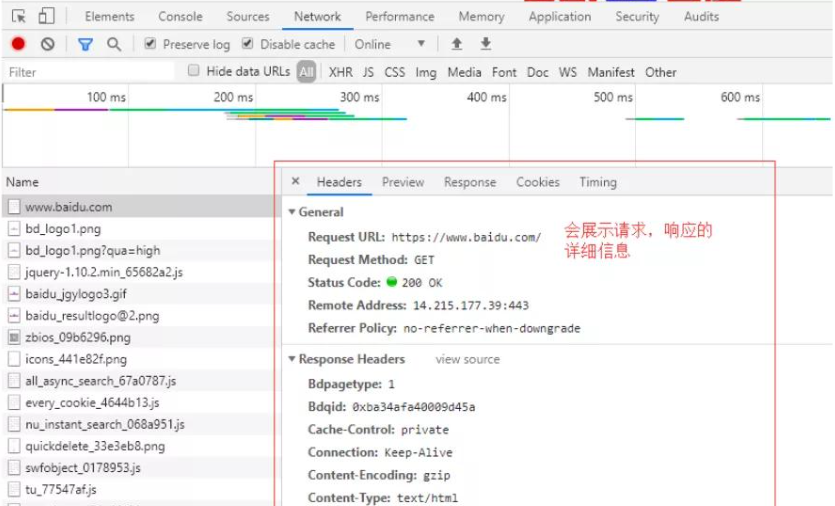
我们这个案例中的请求就是网页的请求
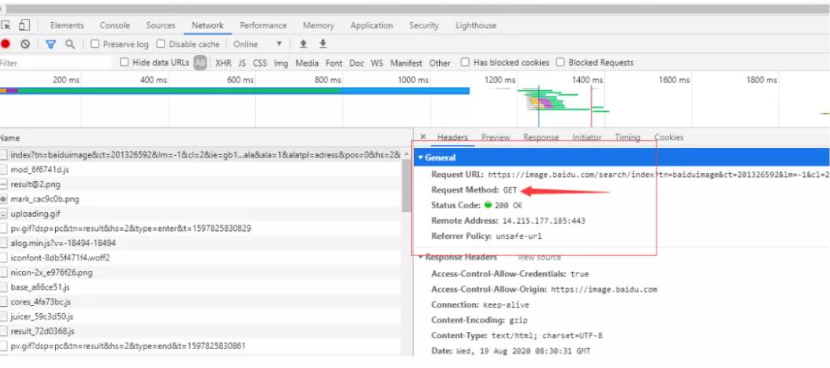
分析请求流程的目的找到目标资源的 http 请求,根据前面学习的 HTTP 协议知识,分析请求流程的具体信息是:
1、请求方法:get
2、url:
https://image.baidu.com/search/index?tn=baiduimage&ct=201326592&lm=-1&cl=2&ie=gb18030&word=%CD%BC%C6%AC&fr=ala&ala=1&alatpl=adress&pos=0&hs=2&xthttps=000000
3、请求头:当前可以忽略
4、请求数据:无
三、 发送请求
分析清楚目标资源的请求过程后,就需要通过代码模拟发送请求。
通过 socket 发送 HTTP 请求

工具库
上面我们通过使用 socket 实现了一个非常简单的请求的发送,可以看到代码比较复杂,如果需要传递更多信息,处理起来会更繁琐,费时费力。
python 提供了很多的库,将发送 HTTP 请求的细节进行了封装,只需要进行简单的调用就可以实现各种 http 请求的发送,常用的库有:
- urllib urllib 是一个用来处理网络请求的 python 标准库
- urllib3 urllib3 是一个基于 python3 的功能强大,友好的 http 客户端。越来越多的 python 应用开始采用 urllib3.它提供了很多 python 标准库里没有的重要功能。
- requests 牛逼
使用 requests 发送请求

四.解析数据
响应正文及响应数据一般分为两大类,文本数据和二进制数据。
其中文本数据又分为 HTML 和 JSON(注:主要指爬虫目标数据,js,CSS 等也属于文本数据)。
二进制数据主要指各种音频,视频,其他文件等。
对于二进制数据一般不需要特殊处理。
HTML 解析
今天的案例数据包含在 HTML 文档中,所以需要解析 HTML
解析 HTML 的常用方法有两种:
1、正则表达式
2、HTML 解析库
五、数据持久化
爬虫爬取到的数据需要存储起来,对于少量的数据,生成相应的文件,例如 Excel,cvs 等。
对于图片,视频等二进制文件也是以文件的形式保存。
如果要保存大量的文本信息,例如商品信息,订单信息等,就需要存储到数据库中。
代码

最后
如果有想学习爬虫的小伙伴,这里给大家分享一份Python爬虫学习资料和公开课,里面的内容都是适合零基础小白的笔记和资料,超多实战案例,不懂编程也能听懂、看懂。需要的话扫描下方二维码免费获得,让我们一起学习!
学习资源推荐
除了上述分享,如果你也喜欢编程,想通过学习Python获取更高薪资,这里给大家分享一份Python学习资料。
这里给大家展示一下我进的兼职群和最近接单的截图

Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

