- 1ERROR 1524 (HY000): Plugin ‘mysql_native_passsword‘ is not loaded_error 1524(hy000) :plugin 'mysgl navtive password'
- 2el-upload文件上传后端实现_el-upload上传文件给后端
- 3SD好复杂,是不是很糊,一文搞懂Stable Diffusion的各种模型及用户操作界面_sd模型网站
- 4mongoDB教程(十):导入、导出_mongodb导出、导入数据
- 5Kafka 消息发送和消费流程_kafka能直接消费另一个kafka么
- 6获得桌面图标所在窗口--兼容Win7_delphi workerw
- 7centos7下mysql8.0.29的安装以及开启ssl访问_mysql8.0.29启动centos
- 8自然语言处理系列九》中文分词》规则分词》逆向最大匹配法_逆向最大匹配算法
- 9AI提示词:打造爆款标题生成器
- 10Web前端最全PHP异世界云商系统开源源码(2),2024年最新Web前端面试题集2024版_2024 php开源商城源码
论文阅读——DINOv
赞
踩
首先是关于给了提示然后做分割的一些方法的总结:
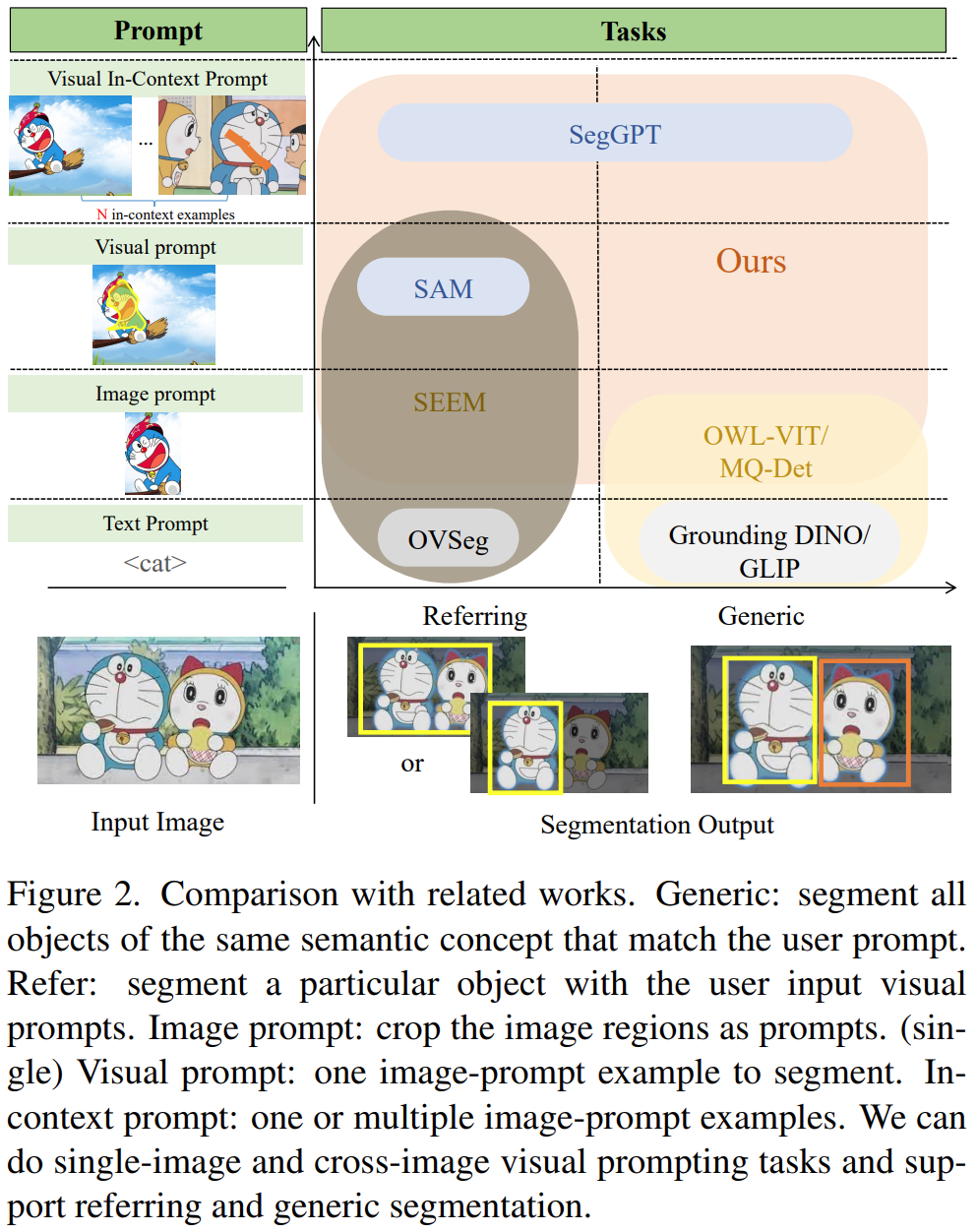
左边一列是prompt类型,右边一列是使用各个类型的prompt的模型。这些模型有分为两大类:Generic和Refer,通用分割和参考分割。Generic seg 是分割和提示语义概念一样的所有的物体,也就是提示是狮子,就把图片中所有狮子分割出来;Refer seg 是根据用户提示分割特定的物体,也就是提示是狗狗的一只耳朵,分割出来的也是狗狗的耳朵。可以看到,本文DINOv填补了视觉提示(Visual prompt)方法的空白。
DINOv可以做Generic和Refer。
Generic和Refer的例子:

这篇文章不是简单的prompt,而是in-context learning.
输入是一组图片-提示对(a set of reference image (Q) - visual prompt (A) pairs)输入的提示可以是mask、涂鸦(scribble)、框等,输出目标图片的mask。
DINOv的框架:

给一些参考图片:![]()
相应的视觉提示:![]()
要预测的图片,即目标图片:![]()
视觉提示可以是masks, boxes, scribbles, points, etc.
参考图片可以和目标图片一样,这时退化为单图片视觉提示分割问题
DINOv主要由Enc、PromptEncoder、Decoder组成
Enc:vision encoder,提取图片特征
PromptEncoder:prompt encoder,结合图片特征和用户提供的提示特征来提取提示特征。
Decoder:基于分割查询和视觉提示特征产生mask和视觉概念。
输入参考图片和视觉提示,Enc提取图片特征Z,然后将Z和视觉提示输入到PromptEncoder提取参考视觉提示F(reference visual prompt F),也就是这一步是为了生成和图片特征相关的prompt。然后从F中采样出查询视觉提示特征Qp(sample the query visual prompt features Qp.)。公式表示如下:
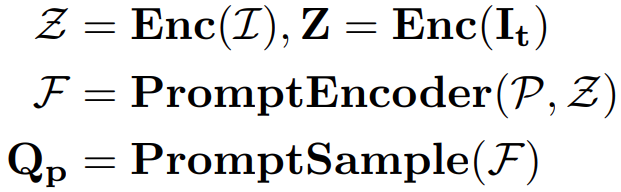
除了觉提示特征Qp,还引入了分割查询Qs(segmentation queries Qs)作为候选提取(proposal extraction)。然后用共享解码器解码Qp和Qs,解码过程中和目标图片特征Z做了交叉注意力。公式表示:

Os是解码的分割查询特征(segmentation query features),Op是解码的目标视觉查询特征(target visual prompt features),M、B是预测的mask和box,Cg 和 Cr 是预测的通用分割和参考分割的匹配分数,这两个分数通过PromptClassifier计算Os和Op的相似性得到。
PromptClassifier:
通用分割任务的目标是将Os分类到不同的类别,当采用视觉提示的时候,差别在于Op作为类别embeddings的使用。
![]()
Np 和 Ns 分别是视觉提示和物体特征的数量。g是线性映射。相当于,得到的Cg矩阵,每一列代表一个物体特征,每一行代表一个类别,每一列都被分类到了某一行代表的那个类别。
对于参考分割任务,目标和通用分割任务不一样。参考分割任务中视觉提示用于识别目标图像中最匹配的实例,可以看做一个分类问题。(训练中目标图片和参考图片一样)
![]()
h是线性映射。
上面两个式子在实现中,对于通用分割任务是为每一个mask proposal 找到最适合的视觉提示,而参考分割任务相反,是给定一个视觉提示来匹配特定的mask proposal。也就是说,一个是给了mask proposal,然后从一堆视觉提示里找最合适的,另一个是给了视觉提示,然后从一堆mask proposal里面匹配特定,相应的。如上面DINOv框架图右边b、c图所示。
Visual Prompt Formulation:
DINOv的核心部分是视觉提示机制。
它提取与各种形式的视觉提示所指示的位置相对应的视觉特征,为了捕捉到细粒度视觉特征,使用了三层mask交叉注意力层(Mask Cross Attention Layer)。每层使用的是Enc提取的不同尺度的特征,使用视觉输入作为掩码,使用可学习的查询向量处理相应位置的特征得到视觉提示特征。

我理解的是,这应该是用的参考图片提取的不同尺度的特征提供更新prompt的特征,然后输入的prompt那个图片提供mask,再加一个可学习的提示查询通过从特征里面查询得到最终的提示。有时间再看代码查证。
Prompt Sampling
得到prompt之后做了一个采样,分别对通用分割和参考分割采用两种采样策略。
对参考分割,用“自参考”’的方法(“self-referring” approach),参考图像和目标图像相同,从一个实例中采样一个提示,并训练模型引用(生成的mask指向的)是同一个实例。好处是这种方法使我们能够利用大量的分割数据,如SA-1B,来有效地训练我们的模型。虽然训练时用的同一个实例,但是模型推理时可以泛化到使用不同目标图片,即cross-image referring。
对通用分割,训练阶段和推理阶段不太一样。训练阶段采样正负提示样本。所有图片同语义一类别的F归到一组,对每一组,随机的采样变量个数范围[1,N]的样本,然后使用一个聚合过程产生Qp。这个Qp会直接送入decoder,然后和目标图片交互融合计算一下得到最终的目标视觉提示Qp。采样的时候采用个数不确定是因为给定的一批图像可能不包括数据集中存在的所有语义类别,从而导致在训练过程中语义类别的数量可变。
上面通用分割训练过程采样伪代码如下:

对于通用分割的推理阶段采样策略,在推理阶段,以COCO数据集为例,基于训练阶段建立的所有语义类别的掩码提示,预提取相应的视觉提示特征。然后采用随机选择方法,为每个语义类别选择N(默认为16)个特征。这些选定的特征作为每个类别的代表性视觉提示功能。
简单来说应该是从训练集里面选出每个类别的视觉提示特征,然后从里面每个类别采样16个样本。
Decoder Query Formulation
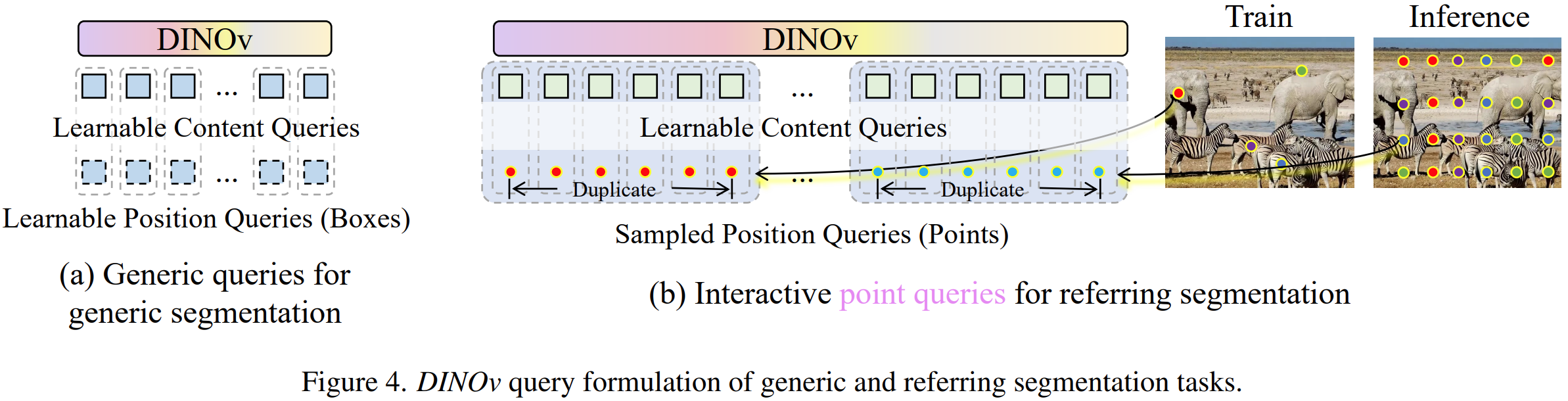
分割查询也是两种类型。对于通用分割,是类似MaskDINO的可学习查询。
对于参考分割,使用和Semantic-SAM一样的交互式点查询。与Semantic-SAM类似,视觉提示(点或框)都被转换为锚框格式,然后每个视觉提示的位置将被编码为位置查询。每个位置查询都是重复的,然后与不同粒度的内容查询组合作为最终的分割查询。对于SA-1B上的训练,为了避免模型上过多的计算开销,我们选择性地将该视觉概念中包含的点的子集采样为正点查询。同时,我们从剩余区域中随机抽取一个子集作为负点。在推理阶段,我们在20×20均匀分布网格上对初始点位置查询进行采样,作为单个帧的初始点位置。
实验部分: