
- 1一文详解Docker镜像
- 2CROSSFORMER: A VERSATILE VISION TRANSFORMER BASED ON CROSS-SCALE ATTENTION 论文阅读笔记
- 3HTML 表单控件_html表单控件
- 4【机器学习系列】之ID3、C4.5、CART决策树构建代码_c4.5二分类决策树代码
- 5十八、神奇算法之句法分析树的生成_句法依赖树怎么生成
- 6大数据挖掘工具_apache systemml和sickict learn
- 7Vite项目插件_vite-plugin-monkey
- 8Txt文本编码格式说明
- 9触摸识别,智能分拣……看AI如何为垃圾分类赋能
- 10表单标签:属性文本框和密码框、单选按钮和复选框_表单的文本框
怎么在div中调整图片位置_基本原理 | 图片中的绝对位置信息,CNN能搞定吗?
赞
踩
点击上方“AI算法修炼营”,选择加星标或“置顶”
标题以下,全是干货
0 1论文概述论文题目:《How much Position Information Do Convolutional Neural Networks Encode? 》
论文地址:https://openreview.net/forum?id=rJeB36NKvB
这个文章解释了CNN是怎么学到图片内的绝对位置信息的。文章来自于加拿大学者,收录在ICLR2020。论文中主要说明了两件事:
卷积神经网络能够引入绝对位置信息,且不同的网络引入的程度不同。
- 绝对位置信息是通过zero-padding引入的,并且在深层的表征效果更好。
02
什么是图像中的绝对位置?之前,CNN和绝对位置,这两个概念很少被一起讨论。
我觉得有两个原因:一是,大家普遍认为:CNN是平移不变的(对分类任务),或者说平移等变的(对分割和检测任务);二是,没有具体任务上的需求。比如对计算机视觉的三大物体感知任务,分类,分割和检测。物体分类跟位置没关系;语义分割作为像素级语义分类,也不依赖于位置;最有可能和绝对位置有关系的物体检测任务,被主流方法解耦了绝对位置,变成相对于锚框或者锚点进行局部相对位置的回归。这样,网络本身不需要知道物体的绝对位置,位置信息作为人为先验被用在前后处理进行坐标换算。但是在很多任务上绝对位置信息很有价值,比如实例分割等问题中,对象+绝对位置就能唯一确定实例了。
一个很显而易见的观察是,人的视觉系统是可以轻松知道绝对位置的,比如:“左上角有一只鸟,它又飞到右边了”。并且,对图像里的物体来说,本质上是通过位置和形状来区分不同实例的。
0 3CNN怎么学到绝对位置?这篇文章先做了假设:
首先,我们知道,卷积网络学习到的原图特征可用CAM进行显著性区域可视化。文中进行了一个简单的试验,对一张图片进行裁剪,测试裁剪前后的显著性区域的变化。
理论上,裁剪前后图片中,因为特征都相同,共同对象的显著性区域应该是不变的,但实际中发现裁剪后显著性区域也发生了偏移,这用卷积神经网络的平移不变性难以解释,怀疑是位置信息导致的。
于是,作者通过试验来进行分析是否卷积神经网络能够学习到位置信息。
实验具体网络设计:
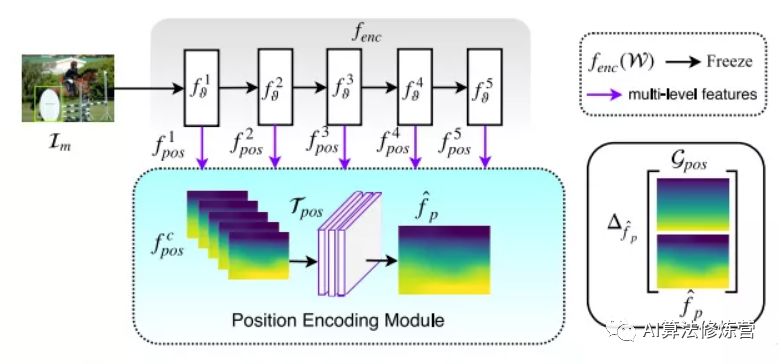
可以看到,网络分为两部分:
Encoder:是经过预训练的ResNet或者VGG等的backbone,参数不参与训练,只作为一个前馈网络提取特征;
Position Encoding Module:由卷积组成,参数可训练,实验中只用了一个卷积。
输入任意图片(图像是有内容的),训练网络输出位置相关的图片。比如,输入噪声图片,希望网络输出水平坐标图(位置信息)。同时将图像归一化的梯度结果设置了5个目标mask:
H:水平方向 V:竖直方向上 G:高斯分布
HS:水平方向上的重复 VS:垂直方向上的重复
上述的标签可以认为是一个随机标签,因为与图像的内容没有相关性,只和一些像素在图像中的位置有关系。
评估指标:SPC:spearman相关系数,衡量两个变量依赖性的非参数指标,用于评价两个统计变量的相关性。MAE:预测位置图和真实梯度位置图之间的平均像素差异。
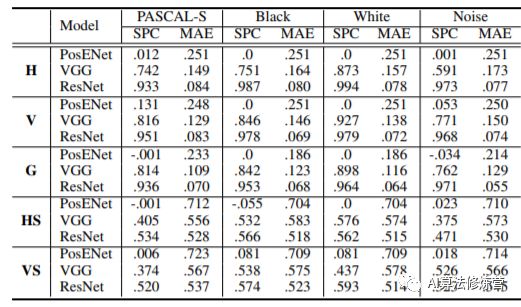
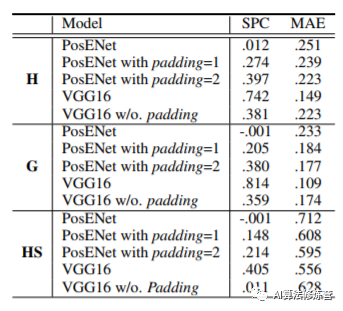
其中VGG/ResNet表示利用预训练的权重提取特征图作为Position Encoding Module的输入。而PosENet的输入直接是原图。
从实验结果表格中可以看出,通过两者的对比发现,从原图中提取位置信息是非常困难的。但是经过神经网络的编码,提取到了一致的位置信息。而测试集结果的高性能表达,表明了模型并非是盲目地拟合噪声,而是提取了真实的位置信息。
具体来说,在有zero-padding的情况下,基于VGG和ResNet的模型都可以预测比较合理的位置相关的输出,比如横坐标或者纵坐标。
在没有padding的情况下,输出只会直接响应在输入的内容上,不能预测和内容无关的位置信息。
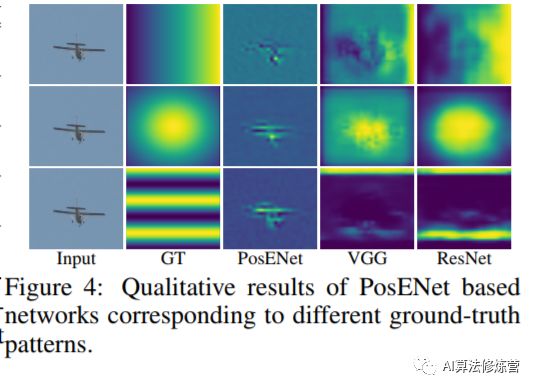
上图对结果进行了可视化,对应着ground truth,可以看到预测位置图与真实位置图之间的相关性,进一步揭示了这些网络中位置信息的存在。位置信息在分类的卷积神经网络结构中都隐式编码,无需进行任何明确的监督。
0 4哪些因素影响绝对位置信息?前面的实验验证实了卷积神经网络在分类任务中的预训练权重,能够编码绝对位置信息,然而这些编码受哪些因素影响呢?
因为绝对位置信息是通过Encoder模块得到的特征图,经过Position Encoding Module提取位置,而在提取过程中只有卷积操作。因此考虑卷积操作和特征图。
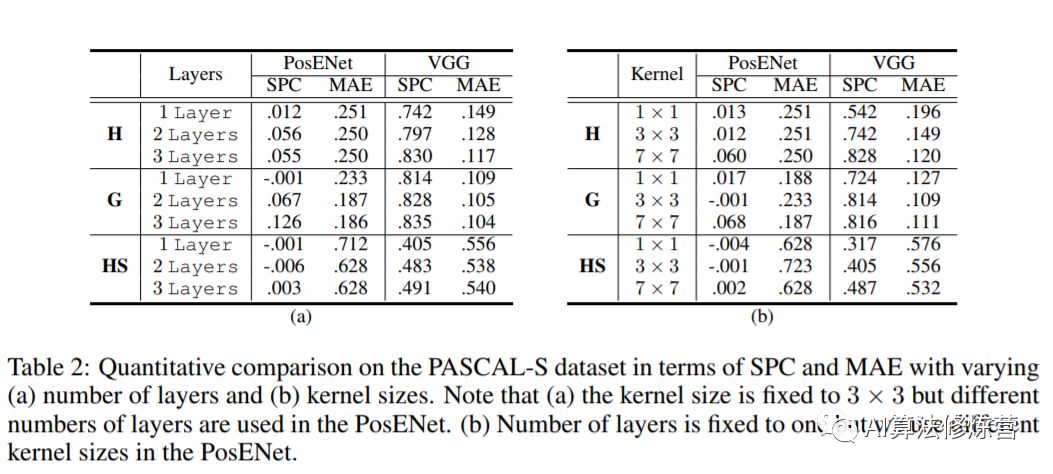
卷积核堆叠层数:如上面(a)结果所示,堆叠多层卷积可以提高网络的位置信息读取。原因可能是多个卷积层堆叠,增加了感受野。
扩大卷积核尺寸:从结果(b)可知更大的核尺寸可能会捕获更多的位置信息,这也和上面堆叠卷积层数相呼应,都是增加了感受野。
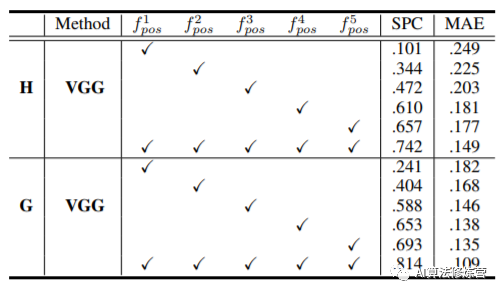
特征层的影响:与浅层的特征相比,深层的特征可获得更高的性能。但这里还有一个变量是各个层的空间通道数不一样,因此控制变量,使得具有相同的特征来对比明确了位置信息在网络深层有更强的编码。
从前面两个实验了解到卷积神经网络具有编码位置信息的能力,且原图不具有引入位置信息。那么这个位置信息不是来自于原图,那么是来自于哪里呢?答案是Zero-Padding。
作者通过实验分析,对Position Encoding Module网络中的padding数进行控制变量测试,发现padding增加,位置信息更加显著。同时,利用VGG网络的试验也更加证实了padding引入位置信息。

从上图中可视化也可以看出padding引入位置信息的效果,特别是最后VGG,有无padding影响非常的大。
同样的,对于物体检测和语义分割任务,实验发现去除了padding操作之后性能下降很多。
0 6总结文中是通过实验的方式说明是zero-padding的作用,但是zero-padding具体如何引入位置信息的,其作用原理的原理可能还可以未来继续研究来解释。
虽然目前的CNN模型可以隐式的学到一定程度的位置信息,但是显然是不充分的。怎样更充分的利用绝对位置信息,非常值得进一步挖掘,CoordConv和semi-conv是很好的探索。
最直接的做法当然就是把每个像素的坐标concat到输入或者中间特征上,这种简单直接做法可以在SOLO的实例分割结果上带来3.6 AP的提升。
总体来讲,对位置信息的理解,或者说对zero-padding的理解,未来可以更好的设计一些网络和任务。比如需要位置信息的实例分割,对象检测等多引入zero-padding,而对于比如图像风格化中的style分支,由于不需要位置信息,减少使用可能会带来一些效果。


目标检测系列
秘籍一:模型加速之轻量化网络
秘籍二:非极大值抑制及回归损失优化
秘籍三:多尺度检测
秘籍四:数据增强
秘籍五:解决样本不均衡问题
秘籍六:Anchor-Free
语义分割系列
一篇看完就懂的语义分割综述
最新实例分割综述:从Mask RCNN 到 BlendMask
面试求职系列
决战春招!算法工程师面试问题及资料超详细合集
一起学C++系列
内存分区模型、引用、函数重载
竞赛与工程项目分享系列
如何让笨重的深度学习模型在移动设备上跑起来
基于Pytorch的YOLO目标检测项目工程大合集
点云配准领域全面资料、课程、数据集合集分享
10万奖金天文数据挖掘竞赛!0.95高分Baseline分享
目标检测应用竞赛:铝型材表面瑕疵检测
SLAM系列
视觉SLAM前端:视觉里程计和回环检测
视觉SLAM后端:后端优化和建图模块
视觉SLAM中特征点法开源算法:PTAM、ORB-SLAM
视觉SLAM中直接法开源算法:LSD-SLAM、DSO
视觉注意力机制系列
Non-local模块与Self-attention之间的关系与区别?
视觉注意力机制用于分类网络:SENet、CBAM、SKNet
Non-local模块与SENet、CBAM的融合:GCNet、DANet
Non-local模块如何改进?来看CCNet、ANN



