
- 1Transformer 理解Tokenizer_transformer tokenizer
- 2Python学习笔记(五):数据类型之 String_python rstring
- 3人工智能和python之间有什么联系?为何用python?
- 4ChatGPT:如何运用强大的自然语言处理技术撰写高质量论文
- 5Python自然语言处理 NLTK 库用法入门教程【经典】_python nltk combine函数的用法
- 6a-upload——实现上传功能——基础积累_a-upload 上传
- 7基于T5的模型微调以及对应的数据介绍_t5模型微调
- 8MySql概述及其性能说明_大量使用mysql,性能能否支撑后续发展,文档如何解释
- 9pytorch初学笔记(六):DataLoader的使用_pytorch dataloader
- 10剪辑师和小白都能用的AI解说神器,一键把短剧变解说视频-手把手教程-2024_ai解说短剧自动剪辑
深度学习之全面了解网络架构
赞
踩
在这篇文章中,我们将和大家探讨“深度学习中的网络架构”这个主题,解释相关背景知识,并就一些问题进行解答。
我选择的问题反映的是常见用法,而不是学术用例。我将概括介绍该主题,然后探讨以下四个问题:
1. 要进行图像分类,我应该使用哪种架构?
2. 在时序应用中,我能否重用基于图像数据训练的架构?
3. 对于时序回归,我该如何选择合适的方法?
4. 对于小型数据集,我应该使用哪种网络架构?
◆ ◆ ◆ ◆
引言
网络架构定义了深度学习模型的构建方式,更重要的是定义了它的功能。架构会决定:
-
模型准确度(网络架构是影响准确度的众多因素之一)
-
模型能预测什么
-
模型期望的输入和输出
-
层的组合以及数据如何流经这些层
大部分人会利用已有的成果,从现成的层组合入手开始训练。毕竟初次尝试某件事的话,借鉴前人的工作不失为一个好办法。
相当一段时间以来,深度学习研究人员都在探索不同的网络架构和层组合。得益于他们的工作,我们有了 GoogLeNet、ResNet、SqueezeNet 等各种网络,这些架构都取得了很好的效果。
刚起步时,您可以选择一个解决类似问题的已有架构,在它的基础上进行构建,而无需从头开始。
在选择网络架构之前,务必了解您的用例类型以及可用的常见网络。
◆ ◆ ◆ ◆
开始接触深度学习时,您可能会遇到以下常见架构:
-
卷积神经网络 (CNN):
CNN 通常用来处理图像输入数据,但也可以用于其他输入数据,我将在问题 1 中详细说明。
-
循环神经网络 (RNN):
RNN 包含连接,可跟踪先前信息以进行未来预测。CNN 假定每个输入是独立事件,而 RNN 则可以处理可能相互影响的数据序列。例如在自然语言处理中,前面的单词会影响后续单词出现的可能性。
-
长短期记忆 (LSTM) 网络:
LSTM 网络是针对序列和信号数据的常用 RNN。我将在问题 3 中进行详细介绍。
-
生成式对抗网络 (GAN):
尽管下面的问题不会涉及这类网络,但是 GAN 最近越来越火了。GAN 可以基于现有数据生成新数据(想像一下并非现实真人的人像)。我觉得这挺有意思,而且有点未来感;
那么,接下来就开始回答问题!
◆ ◆ ◆ ◆
Q1
我需要一个图像分类模型。我应该使用哪种架构?
很好的问题。先说结论,您或许可以使用 CNN 进行图像分类。
原因如下。
我们首先谈谈 CNN 和 LSTM 网络分别是什么,以及它们的常见用途。
1) CNN
当谈到卷积神经网络时,有些人会说“ConvNet”,但我总觉得我自己这样说会显得有点装。
CNN 由许多层组成,但形式上遵循一种“卷积 | ReLU | 池化”的模式,这会一再重复、反反复复。
这类网络通常很适合处理图像分类问题,因为它们非常擅长局部空间模式匹配,而且在图像特征提取方面通常也优于其他方法。
别忘了,CNN 的核心是卷积。使用一系列过滤器对输入图像进行卷积可以突出图像中的特征,而不会丢失相邻像素之间的空间关系。
CNN 有很多变体,一些常见配置如下:
串联网络

Alexnet 示例。串联层排列成一直线。
DAG 网络
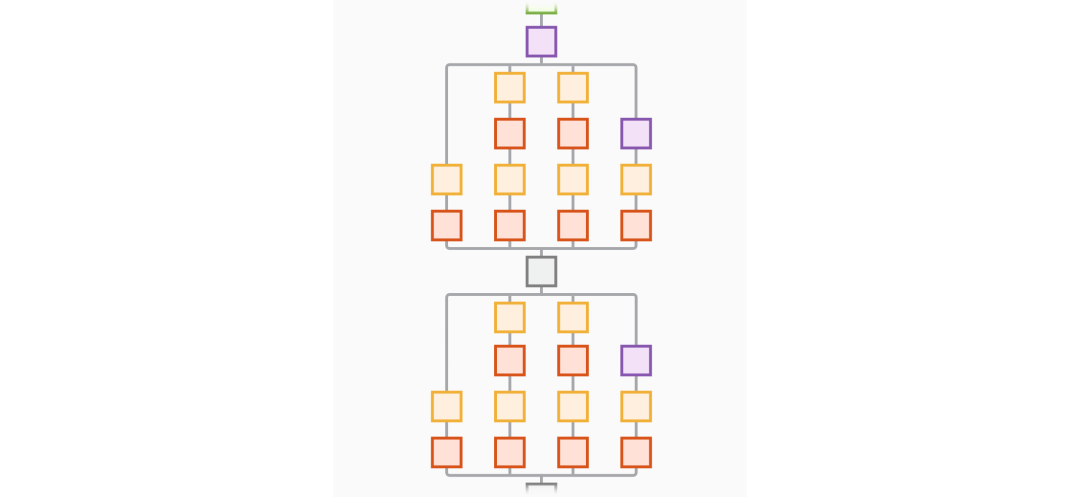
GoogLeNet 示例。多线多连接是 DAG 的典型特征。
2) LSTM
长短期记忆网络主要用于时序和序列数据。LSTM 网络会记住决策之前的部分数据,从而利用数据的上下文更好地作出关联。
根据经验,时序数据通常最适合用 LSTM 网络处理,而图像数据适合用 CNN。信号数据则是一个与经验部分吻合的例外。CNN 和 LSTM 网络都可以用来处理信号数据。我写过一篇关于深度学习非图像应用的文章,其中一个示例就是使用 CNN 进行语音识别。
下图是一个用于分类的简单 LSTM 网络架构:
![]()
下图是一个用于回归的简单 LSTM 网络架构:
![]()
Q2
在时序应用中,我能否重用基于图像数据训练的架构?
可以!
您需要将输出层从 classificationOutputLayer 更改为 regressionOutputLayer,可以跟随这个简单的文档示例进行操作:将分类网络转换为回归网络
Q3
实现时序回归的选择太多!我该如何选择合适的架构?
我的第一反应肯定是建议您采用 LSTM 网络!
但是,其他方法的存在必然有其意义,事实上,某些方法在特定场景下表现会更好。
如果没有更多背景信息,我就很难具体回答这个问题,因此让我们逐一分析几种可能的场景。
1) 时序回归场景 #1:
我的输入是低复杂度的时序数据。我想使用一系列数据点来预测未来的事件。
这种情况最好使用机器学习。
2) 时序回归场景 #2:
我想使用来自多个传感器的数据预测机器剩余使用寿命(即机器在不得不维修或更换之前可以使用的时间)。
这个问题来自我们在工业自动化领域的客户,他们需要赶在问题变得危险或处理代价高昂之前先找出问题。
对于这个场景,最好选择 LSTM 网络而不是机器学习回归。这种方法不要求手动识别特征,毕竟在多传感器的情况下,手动识别特征会是相当艰巨的任务。
3) 时序回归场景 #3:
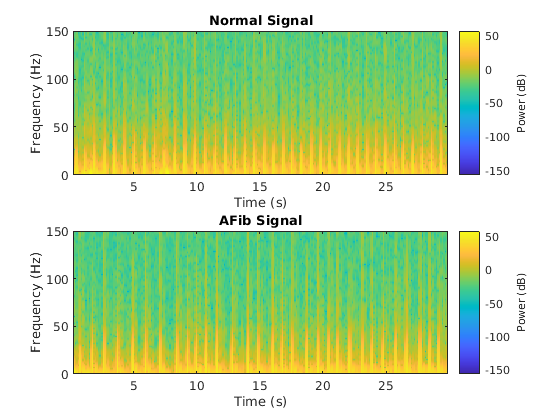
我想要对音频数据进行去噪。
这里可以使用 CNN。这种方法的重点在于,在将信号传送到网络之前,先要将信号转换成图像。也就是说,您需要通过傅里叶变换或其他时频操作,将信号转换为图像表示。
借助图像,您可以看到原始信号中难以可视化的特征。这里可以使用为图像任务设计的预训练网络,因为傅里叶变换本质上是图像。
这个示例演示了如何使用 CNN 对语音进行去噪。对于场景 3,我还要补充一点:如果要从时序数据中提取信息并将其用作 CNN 输入,小波也是一种比较主流的方法。

Q4
我想构建一个用来识别图像的分类器,但是我的数据集有限。有没有一种网络架构可以更好地处理小型数据集?
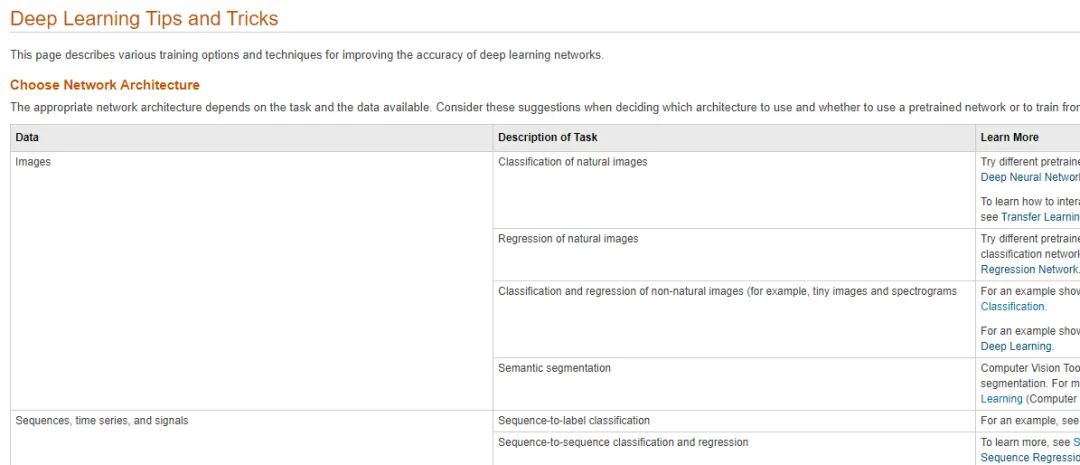
网络架构和预训练网络是密切相关的。预训练模型是经过训练的神经网络。网络的权重和偏置会根据输入数据进行调整,因此面对新任务时,可以较快地重新训练网络。此过程称为迁移学习,有时所需的图像会比较少,适用于小型数据集。另一个可以考虑的方法是通过模拟或数据增强“创造”更多数据。
为帮助您进一步了解各种网络架构的适用场景,我们汇总了一些提示和窍门,其中还包括有关预训练网络的信息。
对于这个问题,我认为无论数据集大小如何,您都可以使用任何您认为合适的网络,但可以考虑使用预训练网络来减少所需的输入数据量,或考虑采用一些方法来增强数据集。

