- 1成功的四大天敌(一)_真正用功都是润物无声
- 2Data truncation: Out of range value for column ‘id‘ at row 1_data truncation: out of range value for column 'id
- 3MPU6050的数据获取、分析与处理_加速度计的x轴分量寄存器是什么
- 4python贪吃蛇设计思路_Python制作AI贪吃蛇,很多很多细节、思路都写下来了!
- 5【随笔】Git 高级篇 -- 不带 source 参数的命令 git fetch & git push(三十九)_git fetch可以不填参数吗
- 6数据归一化处理_2、在第1题的处理的基础上,对其中的speed和height数据进行归一化处理,并绘制这两
- 7C++比较运算符解释_c++a=b(a,c)
- 8ORB-SLAM3的CMake与ROS编译以及测试(亲自总结,亲测可用)_基于ros2实现orb-slam3
- 9linux入门到精通-第十九章-libevent(开源高性能事件通知库)
- 10【资源】TrollStore 巨魔商店安装教程(最新)
Linux_开发工具_yum_vim_gcc/g++_gdb_make/makefile_进度条_git_vs code_2
赞
踩
文章目录
一、Linux软件包管理器yum
1. centos7 中安装软件方式
1、源码安装
2、rpm包安装
3、yum安装: 不用编译源码,不用解决软件的依赖关系
2.安装,卸载,查看
安装sl:
sudo yum install sl
- 1
运行sl:
卸载sl:
sudo yum remove sl
- 1
如果我要知道我要安装什么软件,用yum可以很简单!
我们要安装别人的软件:
1.需要别人先把代码给我编译成为可执行程序
2.需要有人将编好的软件,放在用户能下载的地方(官网,应用软件市场)
yum类似于手机上的应用市场app
列出可以安装的软件,并筛选出包含sl
yum list |grep sl
- 1
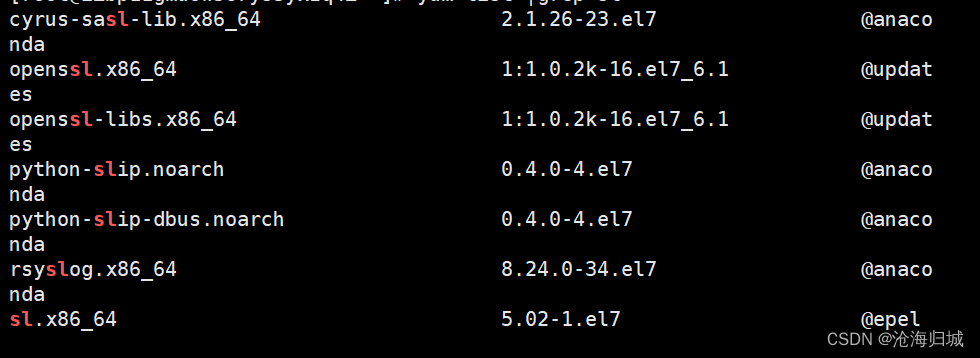
el7即为centos7
3.yum源
yum会去 /etc/yum.repos.d 这个路径下的的配置文件,配置文件里面写着的网址。
1、不是所有人的linux上yum源是国内的链接
2、如果你不是国内的,或者安装软件特别慢,建议更新yum源,在网上搜centos 7国内yum源
4.安装lrzsz
作用:Windows的文件传到Linux,可以直接拖拽到xShell里,或者rz上传。
yum install lrzsz
- 1
上传:
rz
- 1
5.安装扩展源
准官方的服务器列表
yum install -y epel-release
- 1
二、Linux编辑器-vim
1.安装vim
安装:
yum install vim
- 1
vim是什么?
是一个编辑器
1、只能用来写代码
2、功能强大(多模式的编辑器)
为什么要学vim?
有时候,需要我们在生成环境下,需要你快速的定位问题,甚至需要你快速修改代码!
2.vim的三种模式
用vim 打开普通文件:
vim 文件名
- 1
vim三种模式:
1、命令行模式(进去就是的,默认模式)
2、底行模式(退出保存的)
3、插入模式(代码编写的)
三种模式切换(重要):
命令行模式->底行模式 :shirt + :
命令行模式->插入模式 : i
插入模式->命令行模式 :Esc键
底行模式->命令行模式 :Esc键
没有直接从底行模式进入插入模式,和插入进入底行模式,可以间接,先回退到命令行模式,再往下切。
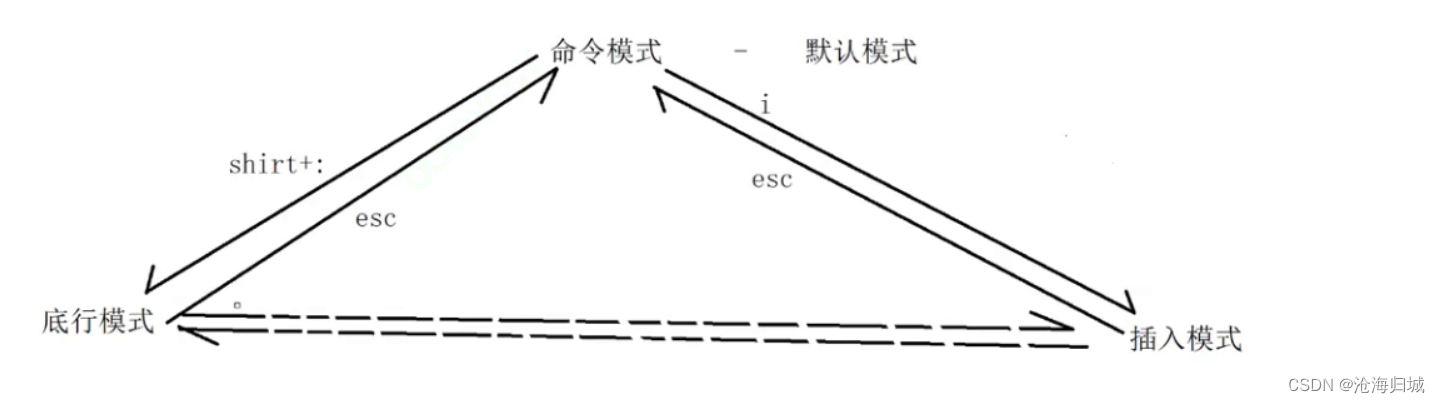
任何模式想回到命令模式无脑Esc
3.命令模式-文本批量化操作
yy:复制当前行 ,nyy (n为数字,是多行复制)
p:粘贴当前行的后面,np
dd:剪切(删除)当前行,ndd
u :撤销
Ctrl+r:针对u操作,再次进行撤销
shitf+g:G光标快速定位到文本末尾
gg:快速的将光标定位到文本的最开始
n+shift+g:光标快速定位到文本的任意一行
shift+4:$光标快速定位到文本行的末尾
shift+6: ^光标快速定位到文本行的开始
把$和^称为锚点。
w , b:向后,向前在一行以单词为单位进行光标移动
h , j ,k ,l:左,下,上,右,移动。
shift+ ` (Esc下面的键):~大小写快速切换
r:替换光标所在的字符,nr
shift +rR,批量化替换
x:删除光标所在字符,nx
拓展:
用vim打开两个文件,即分屏用vim:
先打开一个文件,在底行模式,vim 文件名
光标在两屏切:ctrl+w
批量化注释:
默认模式按Ctrl+v
选中要注释区域:
下:j
上:k
左:h
右:l
选中之后,输入切大写,输入i,输入//,再按ESC键。
批量化取消注释:
默认模式按Ctrl+v
选中要取消注释区域:
下:j
上:k
左:h
右:l
选中之后,输入d
将内容1替换成内容2
底行模式下:
a. %s/内容1/内容2/g
b. 回车
4.vim配置
在 shell 中执行指令(想在哪个用户下让vim配置生效, 就在哪个用户下执行这个指令. 强烈 “不推荐” 直接在 root 下执行):
curl -sLf https://gitee.com/HGtz2222/VimForCpp/raw/master/install.sh -o ./install.sh && bash ./install.sh
- 1
只支持centos7
三、Linux编译器-gcc/g++使用
1.安装
sudo yum install -y gcc-c++
- 1
不行切root安装!!!
2.gcc如何完成
程序(文本)->机器语言(二进制)
过程为:预处理,编译,汇编,链接
计算机为什么只认识二进制?
组成计算机的各种组件,只能认识二进制!
1、 预处理
a.宏替换b.头文件展开c.去注释d.条件编译
gcc -E test.c -o test.i
- 1
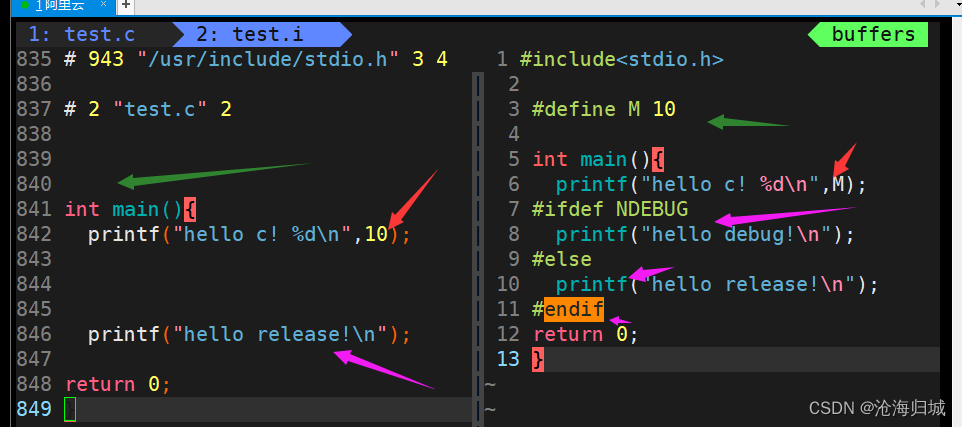
-E:从现在开始给我进行程序的翻译,当预处理完成,就停下来。
头文件既然能被写到程序,就必须在系统中能被找到,要找到头文件,就必须知道头文件所在路径,一般在Linux安装的库都在 /usr/included
编译器内部都必须通过一定的方式,知道你包含的头文件所在路径
预处理之后还是c语言吗?
是,是一份干净的c语言
2、 编译
将C语言翻译成汇编语言
gcc -S test.i -o test.s
- 1
-S :从现在开始进行程序的翻译,当编译完成之后,就停下来。
3、 汇编
将汇编语言翻译成为可重定位二进制文件 .o/.obj
gcc -c test.s -o test.o
- 1
-c:从现在开始进行程序的翻译,当汇编结束之后,就停下来!
为什么此时不能运行,编译谁的代码?
只编译了自己的代码
代码中需要的printf在哪?
C标准库,C标准库在 /lib64
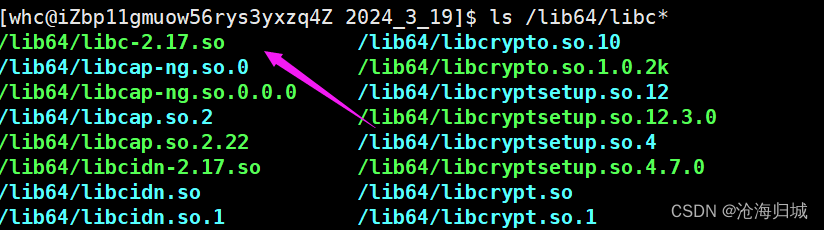
如何和目标printf的实现产生关联?
链接
4、 链接(一般使用gcc/g++ 用这一步就行)
gcc test.o -o mytest
- 1
-o:隐含的就是链接我们自己的程序和库,形成可执行程序
查看可执行程序依赖的库:
ldd mytest
- 1


5、快速记忆上面的 ESc,iso
3.动静态库(感性认识)
头文件:给我们提供了可以使用的方法,所有的开发环境,具有语法提示,本质是通过头文件帮 我们搜索的!
库文件:给我们提供了可以使用的方法的实现,以供链接,形成我们自己的可执行程序。
动态库:Linux(.so) windows(.dll) 动态链接
优点:大家共享一个库,可以节省资源
缺点:一旦库缺失,会导致几乎所有程序失效
静态库:Linux(.a) windows(.lib) 静态链接
将库中的相关代码,直接拷贝到自己的可执行程序中!
优点:不依赖任何库,程序可以独立执行
缺点:浪费资源
gcc中如何体现?

默认情况下,形成的可执行程序就是动态链接
默认一般而言,都没有自带静态库
安装C静态库:
sudo yum install -y glibc-static
- 1
安装C++静态库:
sudo yum install -y libstdc++-static
- 1
如果不行用root装!
如果想用静态链接:
gcc test.c -o mytest2 -static
- 1

会发现用静态库会占用很大空间。
4.扩展
-g :以debug形式软件发布(下面gdb调试前铺垫)
-fPIC:产生位置无关码——生成.o时添加的选项,关于形成动态库的。
-shared:在链接的时候生成动态库.so,的必要选项。
-l :要用的库,后面跟的是库名,假设用的库是libmymath.a
gcc test.c -lmymath
- 1
-I(大写的 i ):指明头文件搜索路径
-L:指明库文件搜索路径
-D:定义宏
gcc -D ARRAY_SIZE=10 程序.c
- 1
四、Linux调试器-gdb使用
1.安装
yum install -y gdb
- 1
2.调试前铺垫
编写一个hello.c:
#include<stdio.h> int AddToTop(int top) { int res = 0; int i; for( i= 1;i<=top;i++) { res+=i; } return res; } int main() { int result = 0; int top =100; result = AddToTop(top); printf ("result: %d\n",result); return 0; }

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
C程序发布有两种:
1、debug
2、release
Linux默认形成的可执行程序无法调试,因为形成的程序是release
编译生产可执行程序:
gcc hello.c -o hello_g -g
- 1
-g :以debug形式软件发布
3.调试
开始调试:
gdb 调试的程序
gdb hello_g
- 1
下面行为是在gdb里:
显示代码:
l
- 1
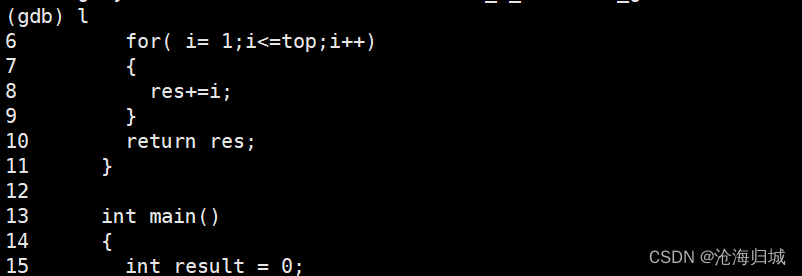
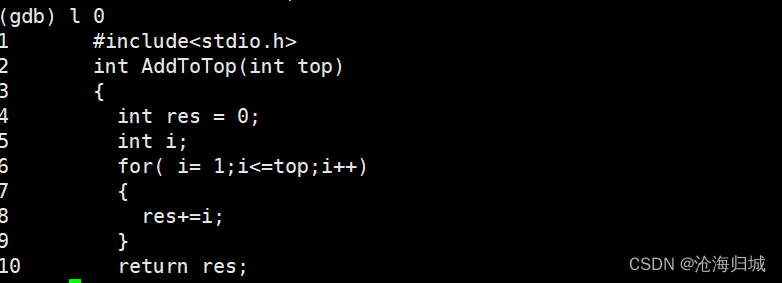
从第0行显示代码:
l 0
- 1
打断点:
b 要打断点的行号
- 1

查看断点:
info b
- 1

取消断点:
d 断点编号
- 1
上面查看断点的Num就是编号
跑:
r
- 1
查看变量:
p 变量
- 1
看地址:
p &变量
- 1
长显示变量:
display 变量
- 1
取消长显变量:
undisplay 编号
- 1
逐语句(会进入函数):
s
- 1
逐过程:
n
- 1
跳转:
untile 行数
- 1
查看调用堆栈:
bt
- 1
总结加拓展:
b 行号:打断点
d 断点编号:取消断点
l 行号 :显示代码
s : step 逐语句(可以进入函数)
n :next 逐过程
display && undisplay:长显示或者取消长显示
until 行号:跳转到指定行
r :运行程序
c :从一个断点,之间运行到另一个断点
finish:执行完一个函数就停下来
五、Linux项目自动化构建工具-make/Makefile
1.什么是make/makefile
make是一个命令。
makefile是一个文件。
2.makefile
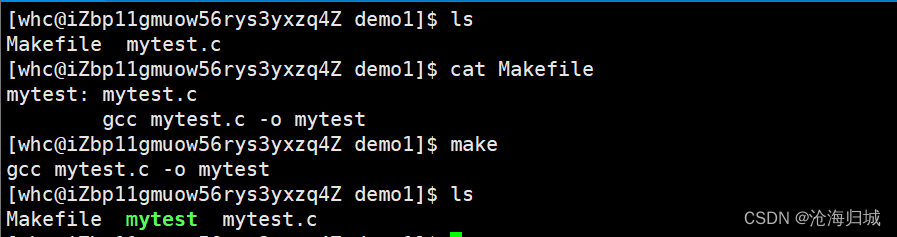
需要在代码路径下创建Makefile(首字母大写小写都可以)
Makefile:
- 依赖关系 mytest -> mytest.c
- 依赖方法 gcc mytest.c -o mytest
目标为mytset依赖的是mytest.c
Makfile内容:
写法1:
mytest:mytest.c
gcc mytest.c -o mytest
- 1
- 2
: 左侧目标文件,右侧依赖文件列表
注意:依赖关系前必须是Tab
写法2:
test:test.c
gcc -o $@ $^
- 1
- 2
$@:代表是就是目标文件
$^:依赖文件列表
命令行敲:
make
- 1
清理项目:
在Makefile添加内容:
mytest:mytest.c
gcc mytest.c -o mytest
.PHONY:clean
clean:
rm -f mytest
- 1
- 2
- 3
- 4
- 5
- 6
运行清理:
make clean
- 1

为什么生产可执行文件,只需要make,而清除需要make clean?
因为生产可执行文的依赖关系在前,make默认只会形成第一个目标文件,执行该依赖关系的依赖方法。
.PHONY是Makefile语法格式中的一个关键字,后面的跟着的就是伪目标,clean被.PHONY修饰时,表明总是被执行的。
什么是总是被执行的?
当我们make了之后再次make就会出现:

会告诉我们mytest是最新的可执行的程序,不能再生成,就是不能总是被执行了!
所以总是被执行的:无论目标文件是是否新旧,照样直接执行依赖关系!
Makefile是如何识别我的程序是新的还是旧的?
stat 文件名 :显示文件的状态信息
一般情况下Linux下文件会有三种时间:
Access为访问时间。
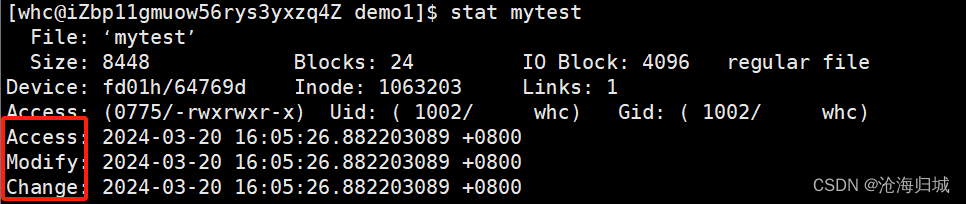
Modify vs Change
文件 = 内容 + 属性
Modify代表内容修改的最后时间,Change代表属性修改的最后时间
修改属性后查询:
chmod u-x mytest :去掉拥有者的可执行权限,也就是修改了文件属性
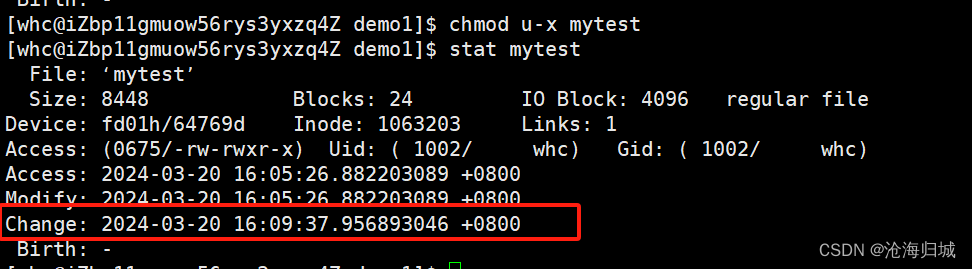
发现只有Change时间改变了
修改内容后查询:
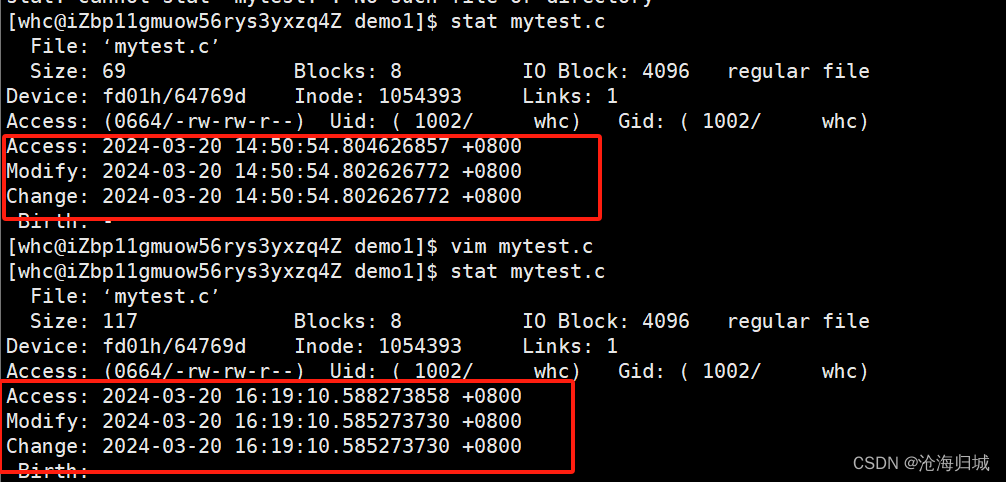
修改内容可能会引起change time的变化。
根据对比源文件和可执行程序的最近内容修改时间,评估要不要重新生成,也就说.PHONY后的目标文件是忽略对比时间
3.多文件的makefile
创建 test.c , test.h ,main.c:
touch test.c test.h main.c
- 1
test.h:
#pragma once
#include<stdio.h>
extern void show();
- 1
- 2
- 3
- 4
test.c:
#include"test.h"
void show()
{
printf("you can see me!\n");
printf("you can see me!\n");
printf("you can see me!\n");
printf("you can see me!\n");
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
main.c:
#include"test.h"
int main()
{
show();
return 0;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
多个源文件,倾向于,把test.c和main.c形成.o文件最后链接生成可执行程序。
makefile:
hello:main.o test.o
gcc -o hello main.o test.o
main.o:main.c
gcc -c main.c
test.o:test.c
gcc -c test.c -o test.o
.PHONY:clean
clean:
rm -f *.o hello
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
*是通配符,*.o表示以.o结尾的文件
六、Linux第一个小程序-进度条
1.铺垫-缓冲区的理解-回车vs换行-编写倒计时
#include<stdio.h>
#include<unistd.h>
int main()
{
printf("hello world!");
sleep(3);
return 0;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
执行程序后的现象:
开始什么也没有,直到sleep3秒后才出现hello world!
为什么没有在sleep之前打印,但最后打印了,在sleep3秒里hello world!在哪里?
1、在缓冲区里,缓冲区的理解就是一段内存空间
对于缓冲区有一种策略,立马将内存中的空间显示出来————行刷新
不想用\n,就想让数据立马刷新,如何做?
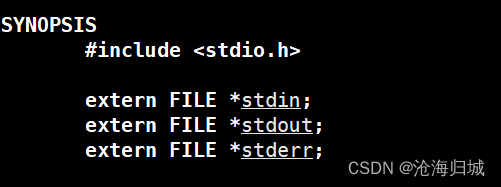
一般程序启动会打开三个输入输出流,如果想要打印出来,就要刷新stdout,就用到 fflush, 将数据立马刷新。
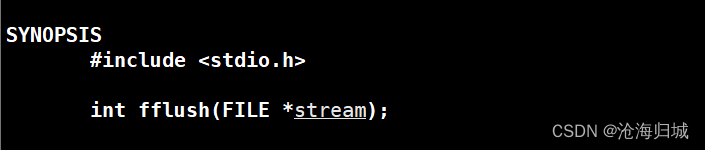
#include<stdio.h>
#include<unistd.h>
int main()
{
printf("hello world!");
fflush(stdout);
sleep(3);
return 0;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
执行程序的现象:
先打印出hello world!再sleep3秒
回车 vs 换行
回车:将光标回到当前行的最开始
换行:新起一行
\n = 回车+换行
\r = 回车
编写倒计时,让在一行的开头不断减小数字,不是另起一行:
#include<stdio.h>
#include<unistd.h>
int main()
{
int cnt = 9;
while(cnt)
{
printf("%d\r",cnt--);
fflush(stdout);
sleep(1);
}
return 0;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14


2.进度条
#include<stdio.h> #include<string.h> #include<unistd.h> #define NUM 101 void process() { char bar[NUM]; memset(bar,'\0',sizeof(bar)); int cnt = 0; const char* lable = "|/-\\"; while(cnt<=100) { printf("[%-100s][%d%%]%c\r",bar,cnt,lable[cnt%4]); fflush(stdout); bar[cnt++] = '='; //sleep(1); usleep(30000); } printf("\n"); } int main() { process(); return 0; }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26

七、git
1.git是什么?
git是版本控制器。
2.如何使用
1.登陆注册
略过
2.新建仓库
3.将仓库克隆到本地
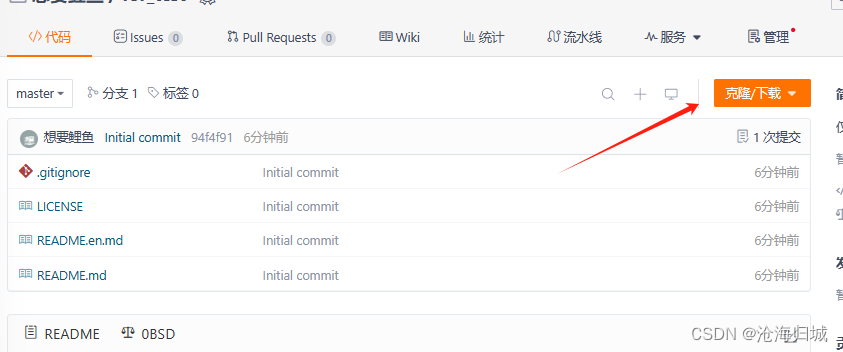
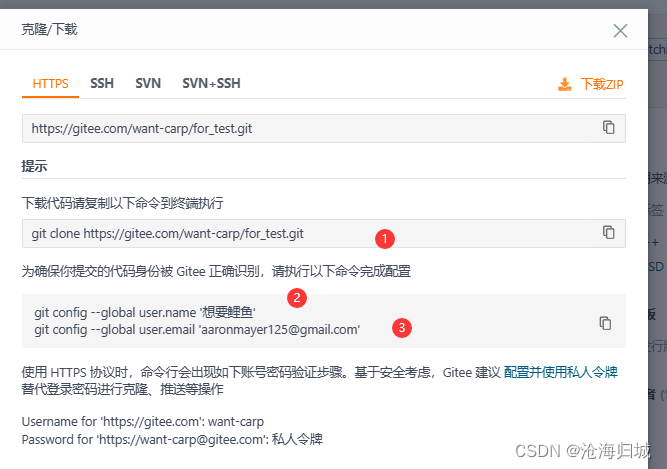
上图的1,2,3依次在Linux上输入即可:
注意:如果没有执行2,3或者2,3添加不对,可能会导致上传没有小绿点或者上传失败。
下面是解释每一步在做什么
库克隆:
git clone https:xxxx(你的仓库网址)
- 1
如何查看:
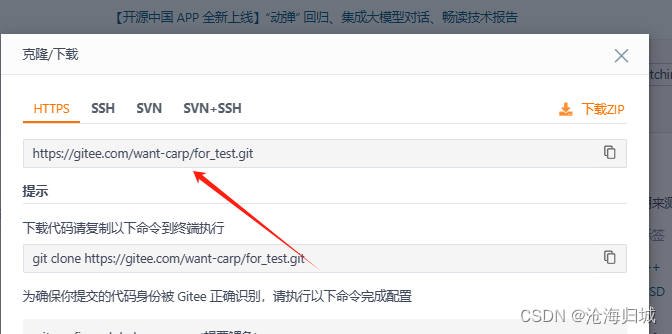
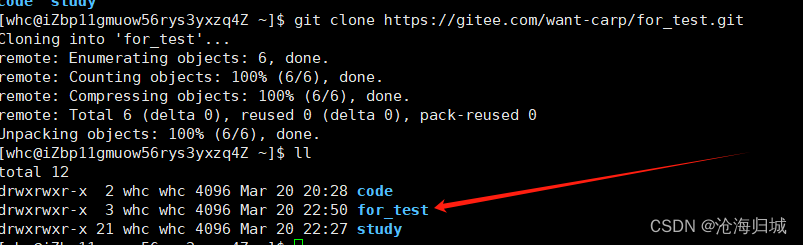
此时就已经把你克隆下来到本地。
配置本地git用户名:
git config --global user.name '你的用户名'
- 1
配置本地git提交邮箱:
git config --global user.email '你gitee的主邮箱'
- 1
4.如何使用-三板斧add,commit,push
如果要你输入账号和密码,是你gitee的账户和密码,不是linux的!!!
进入仓库目录里,创建你要提交的代码或目录:
下面演示要提交的代码为test.c
第一步:
git add test.c
- 1
查看本地仓库和远端仓库的关系-gti status:
git status
- 1
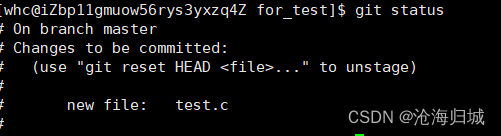
第二步:
git commit -m "写的是提交日志,不能瞎写"
- 1
第三步:
git push
- 1
之后就要输入你gitee的账号和密码
下面是提交成功的:
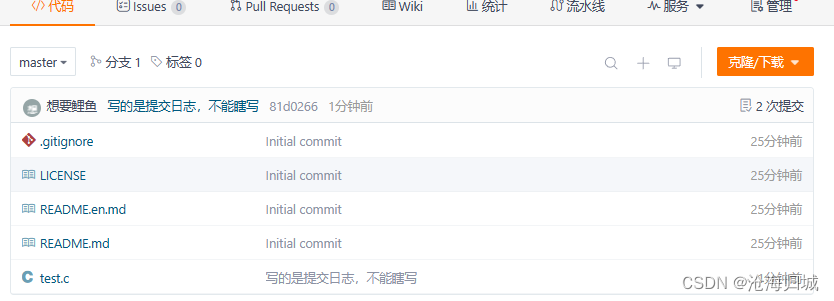
5.拉取-git pull
上面的提交之前,必须是你本地和远端一样,才能提交,如果不一样,你就得从远端拉取下来。
从远端拉取:
git pull
- 1
接的就可以正常提交了。
6.查看日志 -git log
查看日志:
git log
- 1
7.总结
- 建立仓库
- git clone
- git add
- git commit -m " 写好你的日志"
- git push
a. sudo yum install -y git
b.第一次使用git的时候,可能会让你配置一下你的用户名和邮箱
c. .gitignore 黑名单,在文件里的有的后缀,不会提交gitee
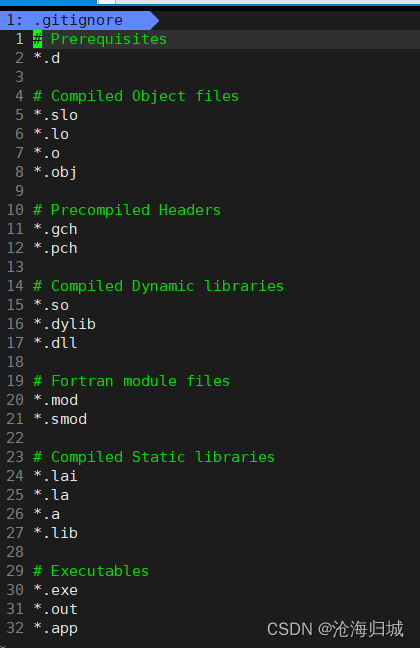
提交修改后的代码:
git init----> git add—>git commit -m ‘xxxxxx’—>git push
八、vscode
1.vscode是什么
vscode是一个编辑器,我们用的更多是一个编写代码的功能。
2.插件推荐
1.remote
远程连接云服务器。
a.安装
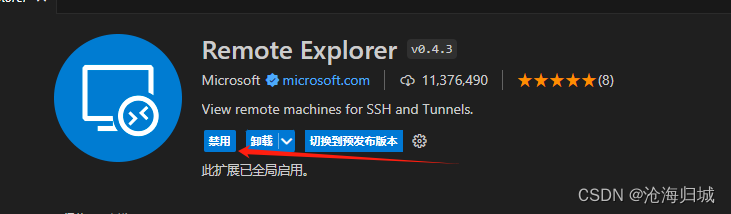
b.添加主机
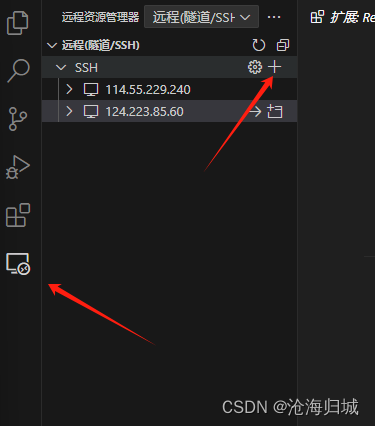
c.输入配置信息

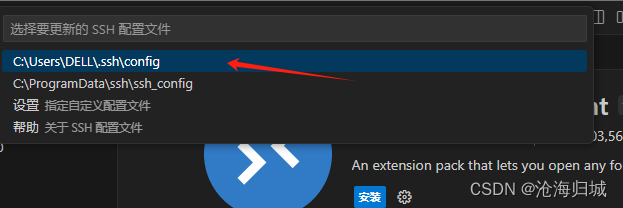
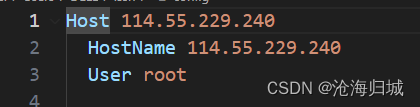
调出命令行:
Ctrl+~

2.Chinese(Simplified)
3.C/C++
4.include Autocomplete
5.GBKtoUTF8
6.vscode-icons
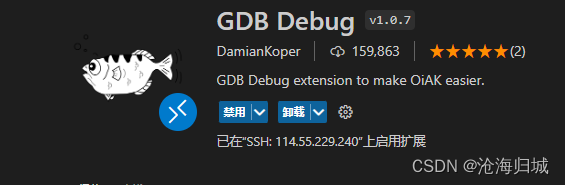
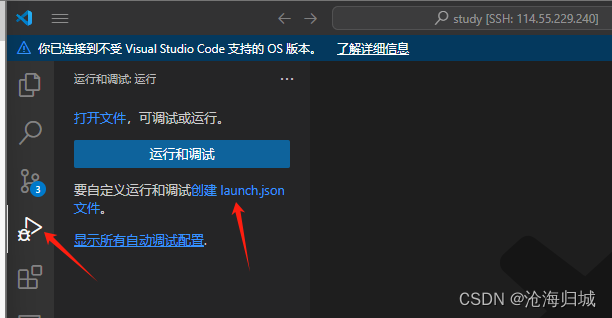
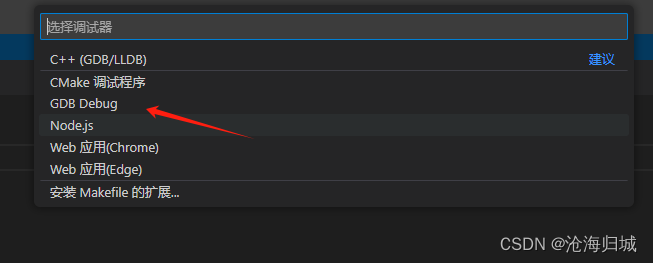
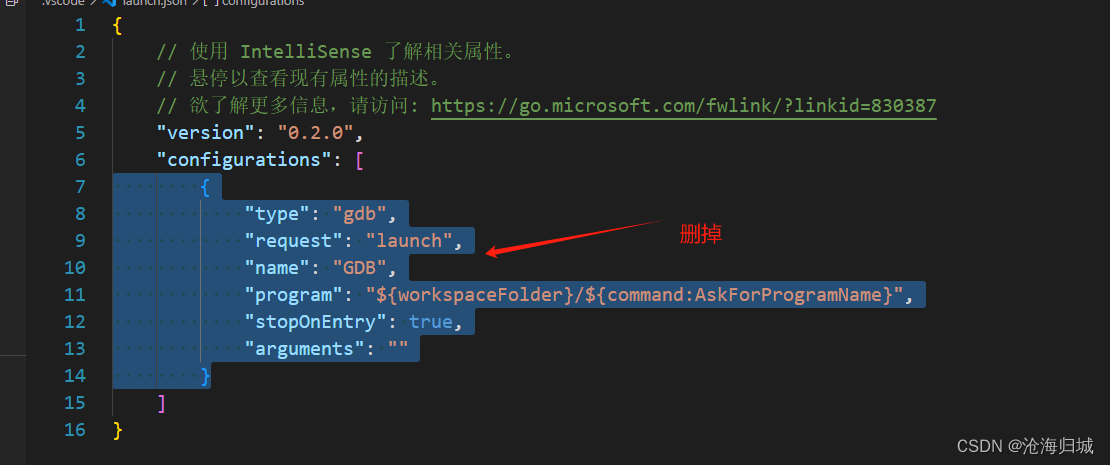
7.gdb debug