
- 1Gitea 的简单介绍
- 2面向对象设计原则详解:迪米特法则_迪米特原则 菜鸟
- 3flask服务中如何request获取请求的headers信息
- 4云计算时代改变了什么?_大数据、云计算改变了什么的结果
- 5Q-learning算法理论及应用_q-learning算法中的状态值是怎么表达的
- 6android genymotion模拟器怎么使用以及和google提供的模拟器性能对比
- 7深入了解PyTorch的文本摘要和文本生成技术
- 8字节跳动面试分享,android内存优化面试题
- 9git分支回滚之后,无法合并的问题及解决方式_git回退版本以后重新合并
- 10稀疏卷积Submanifold Sparse Convolutional Networks
LLM漫谈(二)| QAnything支持任意格式文件或数据库的本地知识库问答系统_qanything 格式解析
赞
踩

一、QAnything介绍
QAnything (Question and Answer based on Anything) 是致力于支持任意格式文件或数据库的本地知识库问答系统,可断网安装使用。
您的任何格式的本地文件都可以往里扔,即可获得准确、快速、靠谱的问答体验。
目前已支持格式: PDF,Word(doc/docx),PPT,Markdown,Eml,TXT,图片(jpg,png等),网页链接,更多格式,敬请期待...
二、特点
-
数据安全,支持全程拔网线安装使用。
-
支持跨语种问答,中英文问答随意切换,无所谓文件是什么语种。
-
支持海量数据问答,两阶段向量排序,解决了大规模数据检索退化的问题,数据越多,效果越好。
-
高性能生产级系统,可直接部署企业应用。
-
易用性,无需繁琐的配置,一键安装部署,拿来就用。
-
支持选择多知识库问答。
三、架构

3.1 为什么是两阶段检索?
知识库数据量大的场景下两阶段优势非常明显,如果只用一阶段embedding检索,随着数据量增大会出现检索退化的问题,如下图中绿线所示,二阶段rerank重排后能实现准确率稳定增长,即数据越多,效果越好。
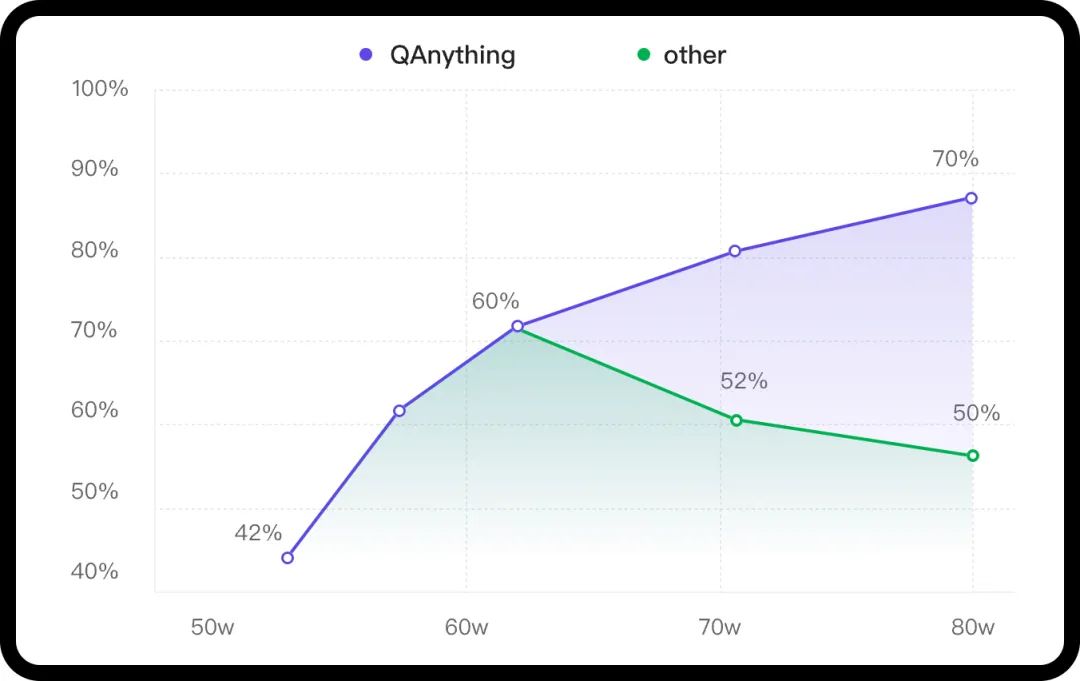
QAnything使用的检索组件BCEmbedding(https://github.com/netease-youdao/BCEmbedding)有非常强悍的双语和跨语种能力,能消除语义检索里面的中英语言之间的差异,从而实现:
-
强大的双语和跨语种语义表征能力【基于MTEB的语义表征评测指标】。
-
基于LlamaIndex的RAG评测,表现SOTA【基于LlamaIndex的RAG评测指标】。
一阶段检索(embedding)
| 模型名称 | Retrieval | STS | PairClassification | Classification | Reranking | Clustering | 平均 |
|---|---|---|---|---|---|---|---|
| bge-base-en-v1.5 | 37.14 | 55.06 | 75.45 | 59.73 | 43.05 | 37.74 | 47.20 |
| bge-base-zh-v1.5 | 47.60 | 63.72 | 77.40 | 63.38 | 54.85 | 32.56 | 53.60 |
| bge-large-en-v1.5 | 37.15 | 54.09 | 75.00 | 59.24 | 42.68 | 37.32 | 46.82 |
| bge-large-zh-v1.5 | 47.54 | 64.73 | 79.14 | 64.19 | 55.88 | 33.26 | 54.21 |
| jina-embeddings-v2-base-en | 31.58 | 54.28 | 74.84 | 58.42 | 41.16 | 34.67 | 44.29 |
| m3e-base | 46.29 | 63.93 | 71.84 | 64.08 | 52.38 | 37.84 | 53.54 |
| m3e-large | 34.85 | 59.74 | 67.69 | 60.07 | 48.99 | 31.62 | 46.78 |
| bce-embedding-base_v1 | 57.60 | 65.73 | 74.96 | 69.00 | 57.29 | 38.95 | 59.43 |
-
更详细的评测结果详见Embedding模型指标汇总(https://github.com/netease-youdao/BCEmbedding/blob/master/Docs/EvaluationSummary/embedding_eval_summary.md)。
二阶段检索(rerank)
| 模型名称 | Reranking | 平均 |
|---|---|---|
| bge-reranker-base | 57.78 | 57.78 |
| bge-reranker-large | 59.69 | 59.69 |
| bce-reranker-base_v1 | 60.06 | 60.06 |
-
更详细的评测结果详见Reranker模型指标汇总(https://github.com/netease-youdao/BCEmbedding/blob/master/Docs/EvaluationSummary/reranker_eval_summary.md)
3.2 基于LlamaIndex的RAG评测(embedding and rerank)
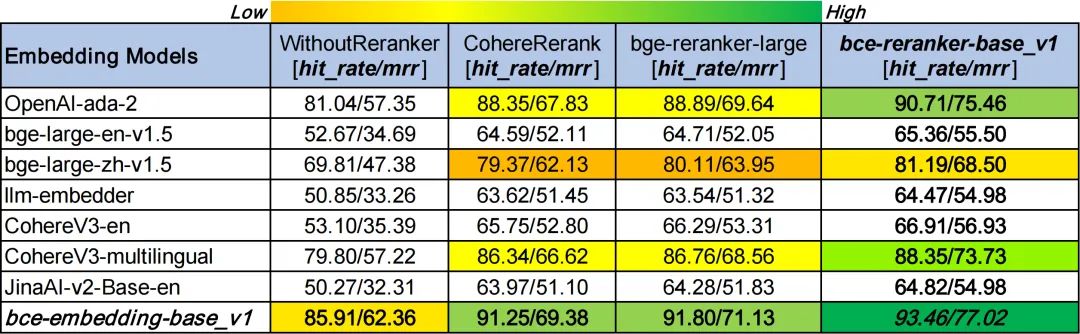
NOTE:
-
在WithoutReranker列中,我们的bce-embedding-base_v1模型优于所有其他embedding模型。
-
在固定embedding模型的情况下,我们的bce-reranker-base_v1模型达到了最佳表现。
-
bce-embedding-base_v1和bce-reranker-base_v1的组合是SOTA。
-
如果想单独使用embedding和rerank请参阅:BCEmbedding
3.3 LLM
开源版本QAnything的大模型基于通义千问,并在大量专业问答数据集上进行微调;在千问的基础上大大加强了问答的能力。如果需要商用请遵循千问的license,具体请参阅:通义千问(https://github.com/QwenLM/Qwen)
四、开始
- ```html
[详细] -->赞
踩
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

