
- 1adb 全屏沉浸命令_settings put global
- 2IDEA tomcat热部署
- 3爬虫(一)网络爬虫/相关工具与知识_uipath设计网络爬虫机器人的工具是
- 4移远RM500U-CN模块直连嵌入式ubuntu实现拨号上网
- 5Python 使用pyplot画图_python pyplot
- 6MySQL各存储引擎区别与特点_mysql ndb 优点
- 7面试题_x times - software engineer
- 8《机器学习》------实验三(决策树)_南航研究生机器学习决策树算法实验报告作业
- 9华为设备基础配置命令总结(持续更新。。。。。。)_local-user caikong ftp-directory flash:翻译
- 10java水浒传血战梁山泊,仿写题(共4分)读《三国演义》,我们可以领略到诸葛亮舌战群儒的风采;读《水浒传》,我们可以感受到众英雄梁山泊聚义的豪情;,。-七年级语文-魔方格...
tfidf和word2vec构建文本词向量并做文本聚类_tfidf向量
赞
踩
一、相关方法原理
1、tfidf
tfidf算法是一种用于文本挖掘、特征词提取等领域的因子加权技术,其原理是某一词语的重要性随着该词在文件中出现的频率增加,同时随着该词在语料库中出现的频率成反比下降,即可以根据字词的在文本中出现的次数和在整个语料中出现的文档频率,来计算一个字词在整个语料中的重要程度,并过滤掉一些常见的却无关紧要本的词语,同时保留影响整个文本的重要字词。
TF (Term Frequency,TF) 是指词频,表示词语在文本中出现的频率。设
t
f
i
j
tf_{ij}
tfij为词语
t
i
t_i
ti在文件
d
j
d_j
dj中出现的频率,
TF 计算公式如下:
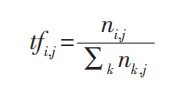
其中,
n
i
j
n_{ij}
nij为该词在文 档
d
j
d_j
dj中出现的次数。
IDF (Inverse Document Frequency,IDF) 是指逆向文档频率,用于衡量某一词语的普遍重要性。IDF 越大包含该词条的文档数越少,则表明该词条具有很好的类别区分能力。计算公式如下:
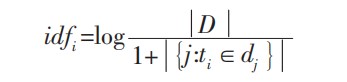
其中, D 是语料库中文档总数,| {
j
:
t
i
∈
d
j
j:t_i∈d_j
j:ti∈dj }|表示包含词语
t
i
t_i
ti的文档数目 (即
n
i
,
j
≠
0
n_i,j≠0
ni,j=0 的文件数目)。如果该词语不在语料库中,会导致分母为零,因此一般情况下使用 |{
1
+
j
:
t
i
∈
d
j
1+ j:t_i∈d_j
1+j:ti∈dj}| 。
TF-IDF 是基于无监督学习算法的关键词提取。如果某个词语的 TF-IDF 值越大,则该词语越能体现出该文档的特点,这样就可以找出文档中的重要关键词,从而针对这些关键词做进一步的分析挖掘。TF-IDF 计算公式如下:

2、word2vec
word2vec,即词向量,就是一个词语用一个向量来表示,由Google在2013年提出的。word2vec主要包含两个模型:跳字模型(skip-gram)和连续词袋模型(continuous bag of words,简称CBOW),以及两种高效训练的方法:负采样(negative sampling)和层序softmax(hierarchical softmax)。word2vec词向量可以较好地表达不同词之间的相似和类比关系。详细公式推导网上资料较多,由于文章篇幅受限,这里不再介绍word2vec的公式推导。
3、文本聚类
文本聚类就是把相似的文档聚在一起,至于聚成几个类可以根据轮廓系数等判断,也可以根据实际需求把文档聚成自己想要的类别。文本聚类依赖每个文档的句向量,而句向量由词向量构成,所以可以使用tfidf或者word2vec得出词向量,再按照一定的规则构建句向量,本文直接使用求和得出句向量,从而得出每个文档的词向量总和,进而可以做文档聚类。
4、轮廓系数
轮廓系数(Silhouette Coefficient),是聚类效果好坏的一种评价方式,轮廓系数计算公式为:
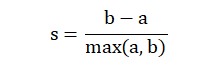
其中,s表示轮廓系数,a表示样本点与同一簇中所有其他点的平均距离,即样本点与同一簇中其他点的相似度;b表示样本点与下一个最近簇中所有点的平均距离,即样本点与下一个最近簇中其他点的相似度。轮廓系数s的取值范围是(-1, 1),当s越接近与1,聚类效果越好,越接近与-1,则聚类效果越差。笔者选取聚类簇数区间为[2, 10],分别计算每个簇数的轮廓系数。
二、文本聚类案例
本文依然使用笔者在招聘网站采集到的电商岗位数据做文本聚类分析。
1、导入所需的包
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from gensim import corpora
from gensim.models import TfidfModel, Word2Vec
from sklearn.cluster import KMeans
from sklearn.manifold import TSNE
from sklearn.metrics import silhouette_score
from warnings import filterwarnings
filterwarnings('ignore')
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
其中filterwarnings(‘ignore’)是忽视文件相关的警告。gensim下的的TfidfModel, Word2Vec模块可以分别实现tfidf和word2vec词向量,KMeans即kmeans聚类算法,TSNE是一种流形降维算法,可以把高维向量映射成二维或三维特征向量后进行可视化展示,silhouette_score就是计算轮廓系数。
2、读入招聘要求分词文件并截取分词
df = pd.read_csv('电商岗位数据(分词后).csv')
content = df['分词']
content
- 1
- 2
- 3

共136699条数据,这里可以把每条分词列表看成一个文档。
3、构建分词字典与语料库
cut_word_list = np.array([cont.split() for cont in content.tolist()])
dictionary = corpora.Dictionary(cut_word_list)
corpus = [dictionary.doc2bow(text) for text in cut_word_list]
- 1
- 2
- 3
cut_word_list即分词后的文档数组,dictionary为gensim能识别的字典,corpus是语料库。
4、word2vec训练词向量
# word2vec训练词向量
def word2vec_model():
model = Word2Vec(cut_word_list, vector_size=200, window=5, min_count=1, seed=1, workers=4)
model.save('word2vec.model')
word2vec_model()
# 加载模型得出词向量
model = Word2Vec.load('word2vec.model')
model.train(cut_word_list, total_examples=model.corpus_count, epochs=10)
wv = model.wv # 所有分词对应词向量
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
本文把词向量的维度设置为200维,保留的最少分词出现次数为1,即使用所有分词训练文本向量。
5、word2vec词向量
# word2vec构建文档向量 def get_word2vec_vec(content=None): text_vec = np.zeros((content.shape[0], 200)) for ind, text in enumerate(content): wlen = len(text) vec = np.zeros((1, 200)) for w in text: try: vec += wv[w] except: pass text_vec[ind] = vec/wlen word2vec = pd.DataFrame(data=text_vec) word2vec.to_csv('word2vec.csv', index=False) return text_vec word2vec = get_word2vec_vec(cut_word_list)

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
6、word2vec结合tfidf权重构建文档向量
word_id = dictionary.token2id tfidf_model = TfidfModel(corpus, normalize=False) corpus_tfidf = [tfidf_model[doc] for doc in corpus] corpus_id_tfidf = list(map(dict, corpus_tfidf)) def get_tfidf_vec(content=None): text_vec = np.zeros((content.shape[0], 200)) for ind, text in enumerate(content): wlen = len(text) vec = np.zeros((1, 200)) for w in text: try: if word_id.get(w, False): vec += (wv[w] * corpus_id_tfidf[ind][word_id[w]]) else: vec += wv[w] except: pass text_vec[ind] = vec/wlen tfidf = pd.DataFrame(data=text_vec) tfidf.to_csv('tfidf_vec.csv', index=False) return text_vec tfidf = get_tfidf_vec(cut_word_list)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
7、轮廓系数确定最优簇数
# 轮廓系数确定簇数 -> 最佳值为1,最差值为-1。接近0的值表示重叠的群集 def silhouette_score_show(data_vec=None, name=None): k = range(2, 10) score_list = [] for i in k: model = KMeans(n_clusters=i).fit(data_vec) y_pre = model.labels_ score = round(silhouette_score(data_vec, y_pre), 2) score_list.append(score) plt.figure(figsize=(12, 8)) plt.plot(list(k), score_list) plt.xticks(fontsize=12) plt.yticks(fontsize=12) plt.xlabel('簇数', fontsize=15) plt.ylabel('系数', fontsize=15) plt.savefig(f'{name}轮廓系数.jpg') plt.show()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
(1)word2vec向量下的轮廓系数
silhouette_score_show(word2vec, 'word2vec')
- 1

(2)word2vec结合tfidf向量下的轮廓系数
silhouette_score_show(tfidf, 'tfidf')
- 1
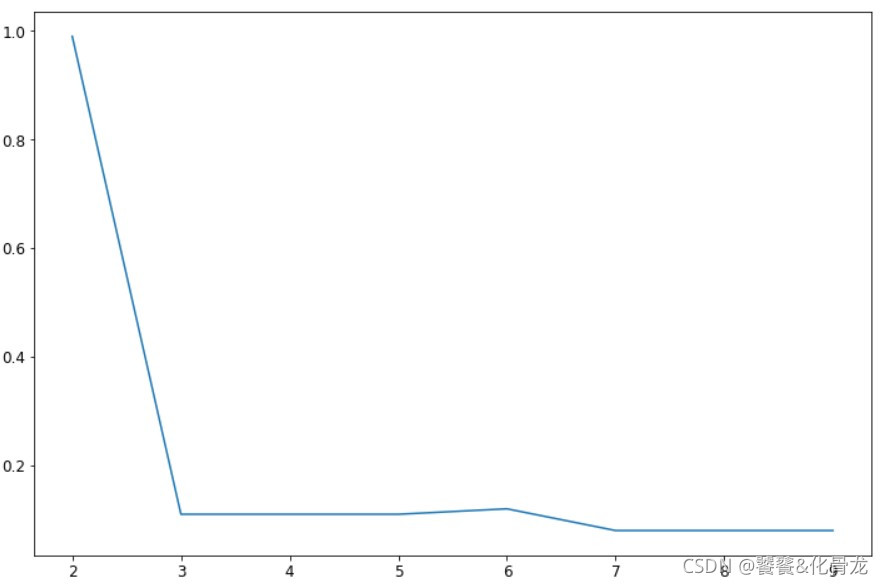
通过对比两张图可知,word2vec结合tfidf向量下的聚成2类轮廓系数最高,几乎接近1了,但这就说明聚成2类就是最好的吗?我们先聚成2类观察一下聚类情况。
kmeans = KMeans(n_clusters=2).fit(tfidf)
y_pre = kmeans.labels_
labels = pd.DataFrame(y_pre)
labels.value_counts()
- 1
- 2
- 3
- 4
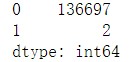
可以发现,第二类居然只有2个文档,聚类效果明显不太好。我们继续使用TSNE流行降维方法把文档向量降维并绘图,直观查看聚类效果。
data = pd.DataFrame(tfidf)
data_label = pd.concat([data, labels], axis=1)
data_label.columns = [f'vec{i}' for i in range(1, tfidf.shape[1]+1)] + ['label']
data_label.head()
- 1
- 2
- 3
- 4
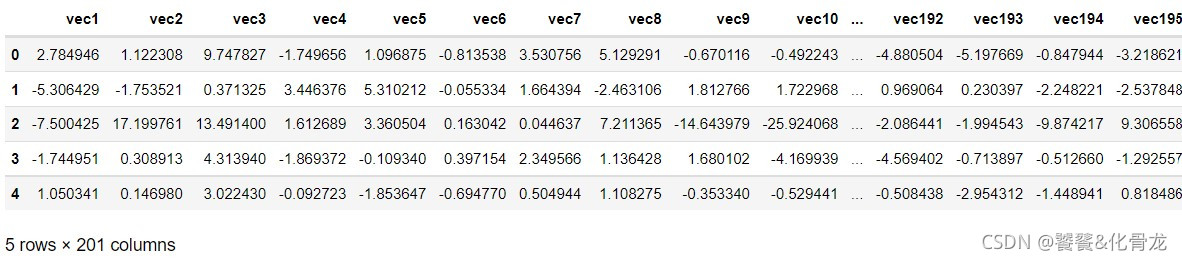
tsne = TSNE()
tsne.fit_transform(data_label) # 进行数据降维
tsne = pd.DataFrame(tsne.embedding_,index=data_label.index) # 转换数据格式
plt.figure(figsize=(10, 6))
plt.xticks(fontsize=12)
plt.yticks(fontsize=12)
d = tsne[data_label['label'] == 0]
plt.plot(d[0],d[1],'rD')
d = tsne[data_label['label'] == 1]
plt.plot(d[0],d[1],'go')
plt.xticks([])
plt.yticks([])
plt.legend(['第一类', '第二类'], fontsize=12)
plt.savefig('文本聚类效果图.jpg')
plt.show()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15

从图中明显可以看出,第二类的两个文档已经包含在第一类中,并且文档向量并没有很好的区分度,基本是连在一起的。这说明源文档的描述内容非常相近。但我们通过阅读源文档发现,其实不同岗位的招聘要求是存在较大差异的,所以,关于该文档的文本聚类分析,还需要从词向量和聚类算法上进行优化。

