
- 1【NLP Tool -- JieBa】Jieba实现TF-IDF和TextRank文本关键字提取(附代码)_python 使用jieba,将下列一段文字分别利用tf-idf和textrank算法提取关键词,并
- 2在 WordPress 中使用 AI 改善 SEO 的 10 种方法
- 3Eclipse的CDT插件配置_eclipse cdt
- 4新兴技术成熟度曲线
- 5Java动态导出excel列_java导出excel动态列
- 6明翰全日制英国硕士学术写作V0.1(持续更新)_假设和倾向(assumptions and biases)怎么写
- 7PyTorch-----torch.flatten()函数
- 8Bert 结构详解_bert的结构组成
- 9【CSS】css转换、css过渡、css动画_09_css变换和过渡
- 10论文中的实验环境配置_论文运行环境
手把手教你:基于LSTM的股票预测系统
赞
踩
系列文章
一、项目简介
本文主要介绍如何使用python搭建:一个基于长短期记忆网络(LSTM:Long Short-Term Memory, 简称 LSTM)的股票、大宗商品预测系统。
项目只是用股票预测作为抛砖引玉,其中包含了使用LSTM进行时序预测的相关代码。主要功能如下:
- 数据预处理。
- 模型构建及训练,使用tensorflow构建LSTM网络。
- 预测股票时序走向并进行模型评估。
如各位童鞋需要更换训练数据,完全可以根据源码将图像和标注文件更换即可直接运行。
博主也参考过网上图像分类的文章,但大多是理论大于方法。很多同学肯定对原理不需要过多了解,只需要搭建出一个预测系统即可。
本文只会告诉你如何快速搭建一个基于LSTM的股票预测系统并运行,原理的东西可以参考其他博主。
也正是因为我发现网上大多的帖子只是针对原理进行介绍,功能实现的相对很少。
如果您有以上想法,那就找对地方了!
不多废话,直接进入正题!
二、数据集介绍
首先我们这次工作主要是针对,大宗商品指数的一个预测,分别为:化工、贵金属、有色。
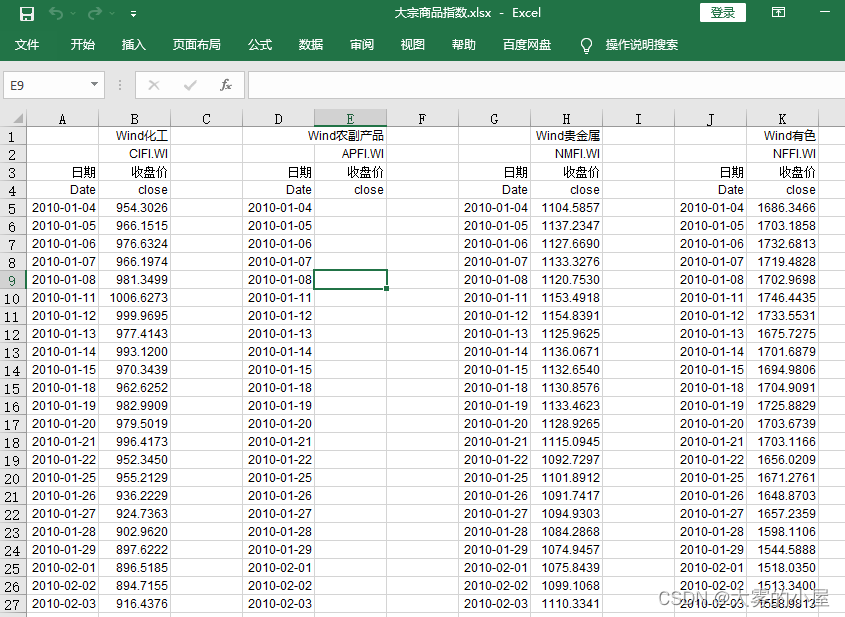
-
接下来是模型预测的结果,这里我用:化工商品,来观测模型预测的时序结果:

-
可以看到其中红色曲线为化工商品的时序情况、绿色曲线为预测情况。
三、环境安装
1.环境要求
本项目开发IDE使用的是:Pycharm,大家可以直接csdn搜索安装指南非常多,这里就不再赘述。
因为本项目基于TensorFlow因此需要以下环境:
- tensorflow >= 2.0
- pandas
- scikit-learn
- numpy
- matplotlib
- joblib
四、重要代码介绍
环境安装好后就可以打开pycharm开始愉快的执行代码了。由于代码众多,博客中就不放入最终代码了,有需要的童鞋可以在博客最下方找到下载地址。
1.数据预处理
- 首先我们需要将时序问题转换为监督学习,才能进行训练。下方代码将输入的时序的收盘价转化为每日收益率并将收益率中滞后一天(默认为一天)的观测值作为监督学习值。
def series_to_supervised(data, n_in=1, n_out=1, dropnan=True): """ 将时间序列转换为监督学习问题 Arguments: data: 输入数据需要是列表或二维的NumPy数组的观察序列。 n_in: 输入的滞后观察数(X)。值可以在[1..len(data)]之间,可选的。默认为1。 n_out: 输出的观察数(y)。值可以在[0..len(data)-1]之间,可选的。默认为1。 dropnan: Bool值,是否删除具有NaN值的行,可选的。默认为True。 Returns: 用于监督学习的Pandas DataFrame。 """ # 定义series_to_supervised()函数 # 将时间序列转换为监督学习问题 n_vars = 1 if type(data) is list else data.shape[1] df = DataFrame(data) cols, names = list(), list() # input sequence (t-n, ... t-1) for i in range(n_in, 0, -1): cols.append(df.shift(i)) names += [('var%d(t-%d)' % (j + 1, i)) for j in range(n_vars)] # forecast sequence (t, t+1, ... t+n) for i in range(0, n_out): cols.append(df.shift(-i)) if i == 0: names += [('var%d(t)' % (j + 1)) for j in range(n_vars)] else: names += [('var%d(t+%d)' % (j + 1, i)) for j in range(n_vars)] # put it all together agg = concat(cols, axis=1) agg.columns = names # drop rows with NaN values if dropnan: agg.dropna(inplace=True) # 删除多余列 agg.drop(agg.columns[[6, 8, 10]], axis=1, inplace=True) print("*" * 20) print("完成监督学习转换:") print(agg.head()) return agg

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 其二就是在数据构建完成后,以一定比率将训练数据和测试数据分离。
2.预测模型构建
- 因为使用的是LSTM做回归预测,因此模型输出应该不是分类的类别,而是回归值。模型构建代码如下:
def model_create(train_X):
"""
搭建LSTM模型
:param train_X:
:return:
"""
model = Sequential()
model.add(LSTM(64, input_shape=(train_X.shape[1], train_X.shape[2])))
model.add(Dropout(0.5))
model.add(Dense(1, activation='relu'))
model.compile(loss='mae', optimizer='adam', metrics=['mse'])
return model
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
3.模型训练
3.1 训练参数定义
- 设置批处理batch_size:100,博主总共跑了100个epoch。
# 定义callbacks参数
callbacks = [
TensorBoard(log_dir=my_log_dir)
]
# 贵金属模型训练
history1 = lstm_gjs.fit(train_x_gjs, train_y_gjs, epochs=100, batch_size=100,
validation_data=(test_x_gjs, test_y_gjs), callbacks=callbacks,
verbose=2, shuffle=False)
# 保存最终模型
lstm_gjs.save_weights('models/' + 'model_lstm_gjs.tf')
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
3.2 训练loss及MSE
-
训练和测试集的loss,可以看到训练至30个epoch左右,loss已经收敛,同时MSE也较低。
-
贵金属训练曲线:

-
有色金属训练曲线:

- 化工商品训练曲线:

五、完整代码地址
由于项目代码量和数据集较大,感兴趣的同学可以下载完整代码,使用过程中如遇到任何问题可以在评论区进行评论,我都会一一解答。
完整代码下载:
【代码分享】手把手教你:基于LSTM的股票预测系统

