
- 1李景山php,[李景山php]每天laravel-20160927|Factory.php
- 2Istio流量管理实践之(2): 通过Istio管理应用的灰度发布
- 3Vue图片点击放大预览_vue图片点击放大预览代码
- 4使用pytorch构建GAN模型的评估
- 5navicat premium 12 最新版破解方法
- 6IP地址定位:揭秘精准定位的技术与应用
- 7大数据方面核心技术有哪些?_大数据智能分析需要哪些技术
- 8网络安全自学入门:(超详细)从入门到精通学习路线&规划,学完即可就业
- 9C#设计模式之17-中介者模式_c# 中介模式 修改和删除接口怎么写
- 10关于Python中install edge_tts记录
自动机器学习AutoML
赞
踩
AutoML
模型的选择和超参数的调节等等任务对于机器学习算法的开发者来说是一件繁琐的工作,为了使得机器可以自动地设计模型并调优,自动机器学习AutoML便应运而生。
自动化机器学习也称为自动化 ML 或 AutoML,是将机器学习模型开发过程中耗时的反复性任务自动化的过程。 它的主要作用是降低构建和部署机器学习模型的门槛,通过自动执行一系列任务,例如特征选择、模型选择、超参数调优等等,AutoML能够有效地减少人工干预的需求,并提高模型的性能。
AutoML主要是基于神经网络结构搜索(Neural Architecture Search,NAS),通过该算法实现模型的自动生成,其中主要涉及到搜索空间和搜索策略,然后对生成模型的性能进行自动评估。目前NAS在图像分类、目标检测、语音识别、自然语言处理的各种模型中被广泛使用。
- 搜索空间定义: NAS首先定义一个搜索空间,该空间包含了所有可能的神经网络结构。这可以包括不同类型的层、层之间的连接方式、每一层的宽度和深度等。
- 搜索策略: NAS使用搜索算法,通常是基于启发式或优化方法,来在搜索空间中寻找最优的网络结构。这些算法可以是基于遗传算法、强化学习、进化算法、贝叶斯优化等。
- 评估和更新: 对于每个搜索到的网络结构,需要评估其性能。通常采用训练神经网络并在验证集上进行评估的方式。性能评估后,根据评估结果更新搜索算法的权重,以优化下一轮搜索。
- 加速搜索: 由于NAS的搜索空间很大,搜索过程可能非常昂贵。因此,研究者们提出了一些方法来加速搜索,例如通过共享参数、采用模型缩放、使用代理模型等。
使用AutoML通常包括以下步骤:
- 数据准备: 准备好用于训练和评估的数据集。
- 选择AutoML工具: 选择适合你任务的AutoML工具或平台。一些常见的AutoML工具包括Auto-Sklearn、AutoKeras、AutoGluon、Google AutoML、Azure和Auto-PyTorch等。
- 配置搜索空间: 定义模型和超参数的搜索空间。这可能涉及到选择合适的模型类型、设置超参数的范围等。
- 运行AutoML: 启动AutoML工具,让其在定义的搜索空间中自动搜索最佳模型和超参数组合。
- 模型评估: 对AutoML得到的模型进行评估,了解其性能。这通常涉及使用验证集或交叉验证来检查模型的泛化能力。
- 部署模型: 一旦满意,将AutoML生成的模型部署到生产环境中,以便进行实际预测。
下面对Auto-Sklearn、AutoKeras、AutoGluon、Google AutoML和Azure自动机器学习共五种AutoML工具进行介绍。
Auto-Sklearn
Auto-Sklearn是一个流行的AutoML工具,它建立在Scikit-Learn库之上,提供了自动化模型选择和调优的功能。在实际使用中,可能需要根据数据的特征进行更详细的配置,例如选择不同的度量标准、调整模型的搜索空间等。Auto-Sklearn提供了许多配置选项,允许用户更灵活地定制自动化过程。此外,还可以通过Auto-Sklearn的API访问模型的详细信息,以便更好地了解所选择的最佳模型。更多详细内容可以参考官方Github网站。

Python代码示例:使用Auto-Sklearn对手写数字数据集(Digits)进行分类,可以根据你的任务替换为自己的数据集。请注意,time_left_for_this_task和per_run_time_limit参数用于限制Auto-Sklearn的运行时间。
# 安装Auto-Sklearn
!pip install auto-sklearn
# 导入必要的库
import autosklearn.classification
from sklearn.model_selection import train_test_split
from sklearn import datasets
# 加载示例数据集(如果没有,可以替换为自己的数据集)
X, y = datasets.load_digits(return_X_y=True)
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=42)
# 创建并训练Auto-Sklearn分类器
automl_classifier = autosklearn.classification.AutoSklearnClassifier(time_left_for_this_task=120, per_run_time_limit=30)
automl_classifier.fit(X_train, y_train)
# 在测试集上评估模型性能
accuracy = automl_classifier.score(X_test, y_test)
print(f"Accuracy: {accuracy}")
# 获取Auto-Sklearn所选用的模型信息
print(automl_classifier.show_models())
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
AutoKeras
AutoKeras是一个基于Keras的开源AutoML框架,由Texas A&M大学开发,上手简单,可以尝试各种结构的神经网络结构。更多详细内容可以参考官方Github网站。
Python代码的一个简单示例:
# 安装autokeras
pip install autokeras
# 导入autokeras库
import autokeras as ak
# 创建模型
clf = ak.ImageClassifier()
# 模型训练
clf.fit(x_train, y_train)
# 模型测试
results = clf.predict(x_test)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
AutoGluon
AutoGluon是另一个开源的AutoML框架,由Apache MXNet社区(亚马逊)开发,上手非常简单,且功能强大。它旨在简化机器学习模型的训练和部署过程,使用户能够轻松构建高性能的模型,而无需深度专业知识。它与更多关注模型和超参数选择的其他AutoML框架不同,AutoGluon可以通过集成多个模型并使它们堆叠在多个层中而获得更优异的表现。更多详细内容可以参考官方Github网站。
Python代码示例:假设你有一个用于二分类的表格数据集,其中class列是目标标签。AutoGluon会自动选择合适的模型并优化超参数,然后返回在测试集上的性能指标和预测结果。
# 安装AutoGluon
!pip install autogluon
# 导入AutoGluon相关模块
from autogluon import TabularPrediction as task
# 加载示例数据集(如果没有,可以替换为自己的数据集)
train_data = task.Dataset('https://autogluon.s3.amazonaws.com/datasets/Inc/train.csv')
test_data = task.Dataset('https://autogluon.s3.amazonaws.com/datasets/Inc/test.csv')
# 定义任务类型为二分类
predictor = task.fit(train_data=train_data, label='class', problem_type='binary')
# 在测试集上评估模型性能
performance = predictor.evaluate(test_data)
# 打印性能指标
print(performance)
# 进行预测
predictions = predictor.predict(test_data)
print(predictions)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
Google AutoML
Google Cloud AutoML是Google Cloud平台上的一项服务,它提供了强大的自动机器学习功能。请注意,使用Google AutoML需要Google Cloud账户,并且可能涉及费用。以下是开发步骤:
- 创建Google Cloud项目: 确保你在Google Cloud上创建了一个项目,并启用了AutoML API。
- 上传数据: 在Google Cloud Console中,导航到AutoML Vision页面,上传包含图像和标签的数据集。按照指导上传和标记图像。
- 训练模型: 在上传完数据后,选择模型配置和超参数,然后开始训练模型。
- 等待模型训练完成: 根据数据集的大小,模型训练可能需要一些时间。你可以在Google Cloud Console上跟踪训练进度。
- 评估模型: 训练完成后,你可以在AutoML Vision页面上评估模型的性能,查看混淆矩阵、精确度等指标。
- 使用模型进行预测: 一旦满意,你可以使用训练好的模型进行预测。在Google Cloud Console上提供一个在线API,或者你可以下载模型并在本地部署。
以下是一个简化的Python示例:演示如何使用Google AutoML Vision进行图像分类任务。
from google.cloud import automl_v1beta1
from google.cloud.automl_v1beta1.proto import service_pb2
# 替换为你的项目ID、模型ID和文件路径
project_id = "your-project-id"
model_id = "your-model-id"
file_path = "path/to/your/image.jpg"
# 创建AutoML客户端
client = automl_v1beta1.AutoMlClient()
# 构建模型路径
model_full_id = f"projects/{project_id}/locations/us-central1/models/{model_id}"
# 读取图像文件
with open(file_path, "rb") as content_file:
content = content_file.read()
# 构建图像内容
image = automl_v1beta1.Image(image_bytes=content)
# 构建预测请求
payload = service_pb2.PredictRequest.Params()
payload.image.image_bytes = content
payload = {"image": payload}
request = automl_v1beta1.PredictRequest(name=model_full_id, payload=payload)
# 发送预测请求
response = client.predict(request=request)
# 解析预测结果
for result in response.payload:
print(f"Predicted class: {result.display_name}")
print(f"Confidence: {result.classification.score}")
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
Azure自动机器学习
Azure自动机器学习是微软开发的AutoML框架。如图所示,在训练期间,Azure 自动机器学习会创建多个尝试不同算法和参数的并行管道。 该服务将迭代与特征选择配对的 ML 算法,每次迭代都会生成带有训练评分的模型。 要优化的指标的分数越好,模型就越被视为“适合”数据。 一旦达到试验中定义的退出条件,机器学习就会停止。
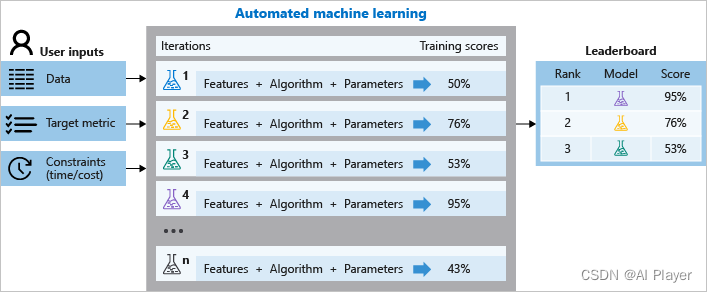
Azure自动机器学习框架可以适用于分类、回归、时序预测、计算机视觉和自然语言处理。其中:
- 分类模型的主要目标是根据从其训练数据中获得的经验,预测新数据将属于哪些类别。 常见分类示例包括欺诈检测、手写识别和对象检测。
- 回归模型基于独立的预测器预测数字输出值。 在回归中,目标是通过估计一个变量对其他变量的影响,帮助建立这些独立预测因子变量之间的关系。 例如,基于每英里耗油量、安全评级等特征预测汽车价格。
- 时序预测被视为多元回归问题。 将“透视”过去的时序值,使其成为回归量与其他预测指标的附加维度。 与传统时序方法不同,这种方法的优点是,在训练过程中自然包含多个上下文变量及其相互关系。 自动化 ML 会针对数据集和预测时间范围内的所有项目,习得通常有内部分支的单个模型。 这样就可以使用更多的数据来估计模型参数,使得未知系列的泛化成为可能。高级预测配置包括:
(1)假日检测和特征化
(2)时序和 DNN 教学器(Auto-ARIMA、Prophet、ForecastTCN)
(3)通过分组实现的多模型支持
(4)滚动原点交叉验证
(5)可配置滞后
(6)滚动窗口聚合特征 - 计算机视觉可支持多类图像分类、多标签图像分类、目标检测和实例分割任务。并可大规模运作,利用 Azure 机器学习 MLOps 和 ML 管道功能。
- 自然语言处理的自动化ML,让你能够轻松地生成针对文本数据训练的模型,用于文本分类和命名实体识别场景。它提供 104 种语言的多语言支持,支持 Horovod 进行分布式训练。
自动化机器学习支持默认已启用的系综模型。 系综学习通过组合多个模型而不是使用单个模型,来改善机器学习结果和预测性能。 系综迭代显示为作为的最后一个迭代。 自动化机器学习使用投票和堆叠系综方法来组合模型:
- 投票:根据预测类概率(对于分类任务)或预测回归目标(对于回归任务)的加权平均值进行预测。
- 堆叠:堆叠方法组合异构的模型,并根据各个模型的输出训练元模型。 当前的默认元模型是 LogisticRegression(对于分类任务)和 ElasticNet(对于回归/预测任务)。
此外, 在 Azure 自动机器学习中,应用缩放和规范化技术来简化特征工程(特征工程是使用数据领域知识创建有助于优化机器学习算法学习效果的特征的过程)。
上述关于Azure自动机器学习的内容参考官方网站,在此仅介绍了它的相关原理和功能,前往官方网站查看更多详细内容,例如,如何安装Azure、数据预处理、模型训练与测试、模型部署、可视化以及监视模型等等,并提供了详细的代码示例。
- [详细] -->
赞
踩

