
- 1java MD5算法返回数字型字串_java md5加密并将结果用十进制表示
- 2C++初识--------带你从不同的角度理解引用的巧妙之处
- 3【送书福利-第三十期】《Java面试八股文:高频面试题与求职攻略一本通》_java面试八股文高频面试题与求职攻略电子书
- 4Windows中redis怎么设置密码_windows redis设置密码
- 5Vue中组件生命周期过程详解_vue 子组件生命周期
- 6树莓派安装python3.9以及pip换源_树莓派安装pip
- 7python无人机路径规划算法_无人机集群——航迹规划你不知道的各种算法优缺点...
- 8卓越体验的秘密武器:评测ToDesk云电脑、青椒云、天翼云的稳定性和流畅度_青椒云评价
- 9Mybatis 注解实现基本 CRUD_mybatis mapper 注解方式编程:针对模型类设计基本的 crud 功
- 10数据结构-----二叉排序树
吴恩达深度学习笔记:深度学习的 实践层面 (Practical aspects of Deep Learning)1.1-1.3
赞
踩
第二门课: 改善深层神经网络:超参数调试、正 则 化 以 及 优 化 (Improving Deep Neural Networks:Hyperparameter tuning, Regularization and Optimization)
第一周:深度学习的 实践层面 (Practical aspects of Deep Learning)
1.1 训练,验证,测试集(Train / Dev / Test sets)
本月,我们将继续学习如何有效运作神经网络,内容涉及超参数调优,如何构建数据,以及如何确保优化算法快速运行,从而使学习算法在合理时间内完成自我学习。
第一周,我们首先说说神经网络机器学习中的问题,然后是随机神经网络,还会学习一些确保神经网络正确运行的技巧,带着这些问题,我们开始今天的课程。
在配置训练、验证和测试数据集的过程中做出正确决策会在很大程度上帮助大家创建高效的神经网络。训练神经网络时,我们需要做出很多决策,例如:神经网络分多少层;每层含有多少个隐藏单元;学习速率是多少;各层采用哪些激活函数。

创建新应用的过程中,我们不可能从一开始就准确预测出这些信息和其他超级参数。实际上,应用型机器学习是一个高度迭代的过程,通常在项目启动时,我们会先有一个初步想法,比如构建一个含有特定层数,隐藏单元数量或数据集个数等等的神经网络,然后编码,并尝试运行这些代码,通过运行和测试得到该神经网络或这些配置信息的运行结果,你可能会根据输出结果重新完善自己的想法,改变策略,或者为了找到更好的神经网络不断迭代更新自己的方案。
目前为止,我觉得,对于很多应用系统,即使是经验丰富的深度学习行家也不太可能一开始就预设出最匹配的超级参数,所以说,应用深度学习是一个典型的迭代过程,需要多次循环往复,才能为应用程序找到一个称心的神经网络,因此循环该过程的效率是决定项目进展速度的一个关键因素,而创建高质量的训练数据集,验证集和测试集也有助于提高循环效率。
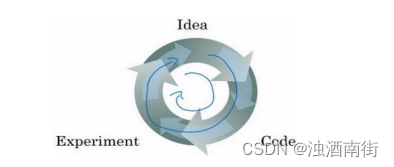
假设这是训练数据,我用一个长方形表示,我们通常会将这些数据划分成几部分,一部分作为训练集,一部分作为简单交叉验证集,有时也称之为验证集,方便起见,我就叫它验证集(dev set),其实都是同一个概念,最后一部分则作为测试集。
接下来,我们开始对训练执行算法,通过验证集或简单交叉验证集选择最好的模型,经过充分验证,我们选定了最终模型,然后就可以在测试集上进行评估了,为了无偏评估算法的运行状况。
在机器学习发展的小数据量时代,常见做法是将所有数据三七分,就是人们常说的 70%验证集,30%测试集,如果没有明确设置验证集,也可以按照 60%训练,20%验证和 20%测试集来划分。这是前几年机器学习领域普遍认可的最好的实践方法。如果只有 100 条,1000 条或者 1 万条数据,那么上述比例划分是非常合理的。
但是在大数据时代,我们现在的数据量可能是百万级别,那么验证集和测试集占数据总量的比例会趋向于变得更小。因为验证集的目的就是验证不同的算法,检验哪种算法更有效,因此,验证集要足够大才能评估,比如 2 个甚至 10 个不同算法,并迅速判断出哪种算法更有效。我们可能不需要拿出 20%的数据作为验证集。
比如我们有 100 万条数据,那么取 1 万条数据便足以进行评估,找出其中表现最好的 1-2 种算法。同样地,根据最终选择的分类器,测试集的主要目的是正确评估分类器的性能,所以,如果拥有百万数据,我们只需要 1000 条数据,便足以评估单个分类器,并且准确评估该分类器的性能。假设我们有 100 万条数据,其中 1 万条作为验证集,1 万条作为测试集,100 万里取 1 万,比例是 1%,即:训练集占 98%,验证集和测试集各占 1%。对于数据量过百万的应用,训练集可以占到 99.5%,验证和测试集各占 0.25%,或者验证集占 0.4%,测试集占 0.1%。
总结一下,在机器学习中,我们通常将样本分成训练集,验证集和测试集三部分,数据集规模相对较小,适用传统的划分比例,数据集规模较大的,验证集和测试集要小于数据总量的 20%或 10%。后面我会给出如何划分验证集和测试集的具体指导。
现代深度学习的另一个趋势是越来越多的人在训练和测试集分布不匹配的情况下进行训练,假设你要构建一个用户可以上传大量图片的应用程序,目的是找出并呈现所有猫咪图片,可能你的用户都是爱猫人士,训练集可能是从网上下载的猫咪图片,而验证集和测试集是用户在这个应用上上传的猫的图片,就是说,训练集可能是从网络上抓下来的图片。而验证集和测试集是用户上传的图片。结果许多网页上的猫咪图片分辨率很高,很专业,后期制作精良,而用户上传的照片可能是用手机随意拍摄的,像素低,比较模糊,这两类数据有所不同,针对这种情况,根据经验,我建议大家要确保验证集和测试集的数据来自同一分布,关于这个问题我也会多讲一些。因为你们要用验证集来评估不同的模型,尽可能地优化性能。如果验证集和测试集来自同一个分布就会很好。

但由于深度学习算法需要大量的训练数据,为了获取更大规模的训练数据集,我们可以采用当前流行的各种创意策略,例如,网页抓取,代价就是训练集数据与验证集和测试集数据有可能不是来自同一分布。但只要遵循这个经验法则,你就会发现机器学习算法会变得更快。我会在后面的课程中更加详细地解释这条经验法则。
最后一点,就算没有测试集也不要紧,测试集的目的是对最终所选定的神经网络系统做出无偏估计,如果不需要无偏估计,也可以不设置测试集。所以如果只有验证集,没有测试集,我们要做的就是,在训练集上训练,尝试不同的模型框架,在验证集上评估这些模型,然后迭代并选出适用的模型。因为验证集中已经涵盖测试集数据,其不再提供无偏性能评估。当然,如果你不需要无偏估计,那就再好不过了。
在机器学习中,如果只有一个训练集和一个验证集,而没有独立的测试集,遇到这种情况,训练集还被人们称为训练集,而验证集则被称为测试集,不过在实际应用中,人们只是把测试集当成简单交叉验证集使用,并没有完全实现该术语的功能,因为他们把验证集数据过度拟合到了测试集中。如果某团队跟你说他们只设置了一个训练集和一个测试集,我会很谨慎,心想他们是不是真的有训练验证集,因为他们把验证集数据过度拟合到了测试集中,让这些团队改变叫法,改称其为“训练验证集”,而不是“训练测试集”,可能不太容易。即便我认为“训练验证集“在专业用词上更准确。实际上,如果你不需要无偏评估算法性能,那么这样是可以的。
所以说,搭建训练验证集和测试集能够加速神经网络的集成,也可以更有效地衡量算法地偏差和方差,从而帮助我们更高效地选择合适方法来优化算法。
1.2 偏差,方差(Bias /Variance)
关于深度学习的误差问题,一个趋势是对偏差和方差的权衡研究甚浅,你可能听说过这两个概念,但深度学习的误差很少权衡二者,我们总是分别考虑偏差和方差,却很少谈及偏差和方差的权衡问题,下面我们来一探究竟。
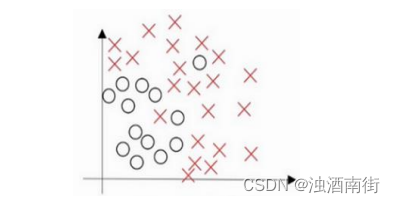
假设这就是数据集,如果给这个数据集拟合一条直线,可能得到一个逻辑回归拟合,但它并不能很好地拟合该数据,这是高偏差(high bias)的情况,我们称为“欠拟合(” underfitting)。
相反的如果我们拟合一个非常复杂的分类器,比如深度神经网络或含有隐藏单元的神经网络,可能就非常适用于这个数据集,但是这看起来也不是一种很好的拟合方式分类器方差较高(high variance),数据过度拟合(overfitting)。
在两者之间,可能还有一些像图中这样的,复杂程度适中,数据拟合适度的分类器,这个数据拟合看起来更加合理,我们称之为“适度拟合”(just right)是介于过度拟合和欠拟合中间的一类。
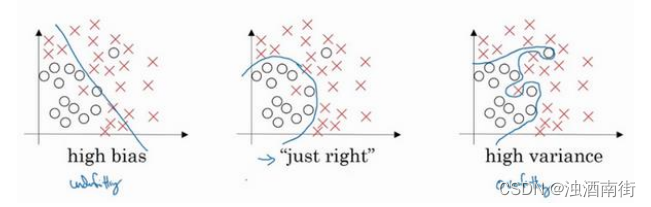
在这样一个只有
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

