
- 1自学网络安全,毕业月薪1.6万,方法分享_自学网络安全怎么赚钱
- 2ESP32或K210如何上传图片到Mixio物联网平台显示_esp32cam米思齐教程
- 3【python之文件读写】_python文件读写
- 4LeetCode刷题 - 链表小结_链表刷题总结
- 5线性表——C语言顺序表的基本操作(静态分配)_c语言对线性表的顺序存储结构进行基本操作
- 6Gitlab安装使用及汉化配置_postgresql-9.6.10-1.nfs.x86_64.rpm
- 7[Linux]Kali安装Deepin-wine-WeChat_kali linux 企业威信
- 8忘了是出自雪中还是剑来或者就是癞蛤蟆?反正应该是烽火大太监的句子吧。还掺杂了许多别家的,记不清谁写的了,或许有西藏的佛陀_如秋蝉在最高枝头,对天地放声
- 9推荐一款可私有部署的企业知识分享与团队协同软件_私有化部署 团队协同
- 10[HarmonyOS]主题课:使用DevEco Studio高效开发_arkts stage模型,关于其工程目录结构说法正确的是
Generative AI 新世界 | 扩散模型原理的代码实践之采样篇_在哪里diffusion_utilities
赞
踩
在上一期的文章中,探讨了在 Amazon SageMaker Studio 上使用 QLoRA 等量化技术微调 Falcon 40B 大语言模型。而从本期开始,我们将一起尝试在更深的知识维度,继续探究生成式 AI 这一火热的新知识领域。
亚马逊云科技开发者社区为开发者们提供全球的开发技术资源。这里有技术文档、开发案例、技术专栏、培训视频、活动与竞赛等。帮助中国开发者对接世界最前沿技术,观点,和项目,并将中国优秀开发者或技术推荐给全球云社区。如果你还没有关注/收藏,看到这里请一定不要匆匆划过,点这里让它成为你的技术宝库!
目前计划有三个大方向:
- 代码深度实践方向。例如用代码完整诠释 Diffusion 模型的工作原理,或者 Transformer 的完整架构等;
- 模型部署和训练优化方向。例如尝试解读 LMI、DeepSpeed、Accelerate、FlashAttention 等不同模型优化方向的最新进展;
- 模型量化实践方向。例如 GPTQ、bitsandbtyes 等前沿模型量化原理和实践等。
在我们之前已经连载的十二期文章中,除了通过论文介绍生成式 AI 和大语言模型(LLMs)的主要原理之外,在代码实践环节主要还是局限于是引入预训练模型、在预训练模型基础上做微调、使用 API 等等。很多资深研究者通过多种渠道和我们沟通,觉得还不过瘾,希望内容可以更加深入。
因此,本期做为代码深度实践方向的第一个系列:“扩散模型原理”代码实践系列,将尝试用代码完整从底层开始洞悉扩散模型(Diffusion Models)的工作原理。而不再仅仅止步于引入预训练模型或使用 API 完成工作。
扩散模型系列内容概述
基于扩散模型(Diffusion Models)的大模型,例如:Stable Diffusion、Midjourney、DALL-E 等能够仅通过提示词(Prompt)就能够生成图像。我们希望通过编写这个“扩散模型原理”代码实践系列,使用代码来探究和诠释这些应用背后算法的原理。
这个由四篇文章组成的“扩散模型原理” 代码实践系列中,我们将:
- 探索基于扩散的生成人工智能的前沿世界,并从头开始创建自己的扩散模型
- 深入了解扩散过程和驱动扩散过程的模型,而不仅仅是预先构建的模型和 API
- 通过进行采样、训练扩散模型、构建用于噪声预测的神经网络以及为个性化图像生成添加背景信息,获得实用的编码技能
- 在整个系列的最后,我们将有一个模型,可以作为我们继续探索应用扩散模型的起点
我将会用四集的篇幅,逐行代码来构建扩散模型(Diffusion Model)。这四部分分别是:
- 噪声采样(Sampling)
- 训练扩散模型(Training)
- 添加上下文(Embedding & Adding Context)
- 噪声快速采样(Fast Sampling)
这四部分的完整代码可参考我的个人 GitHub ,网址如下:
https://github.com/hanyun2019/difussion-model-code-implementation?trk=cndc-detail
本文是第一部分:噪声采样(Sampling)。
扩散模型的目标
中国有句古语:起心动念。因此,既然我们要开始从底层揭开扩散模型(Diffusion Model)的面纱,首先是否应该要想清楚一个问题:使用扩散模型的目标是什么?
本章将讨论扩散模型的目标,以及如何利用各种游戏角色图像(例如:精灵图像)训练数据来增强模型的能力,然后让扩散模型自己去生成更多的游戏角色图像(例如:生成某种风格的精灵图像等)。
假设下面是你已经有的精灵图像数据集(来自 ElvGames 的 FrootsnVeggies 和 kyrise 精灵图像集),你想要更多的在这些数据集中没有的大量精灵图像,你该如何实现这个现在看起来不可能完成的任务?
-
《kyrise》

Source: Sprites by ElvGames
面对这个看上去不可能完成的任务,扩散模型(Diffusion Model)就能帮上忙了。你有很多训练数据,比如你在这里看到的游戏中精灵角色的图像,这是你的训练数据集。而你想要更多训练数据集中没有的精灵图像。你可以使用神经网络,按照扩散模型过程为你生成更多这样的精灵。扩散模型能够生成这样的精灵图像。这就是我们这个系列要讨论的有趣话题。
以这个精灵图像数据集为例,扩散模型能够学习到精灵角色的通用特征,例如某种精灵的身体轮廓、头发颜色甚至腰带配饰细节等。
神经网络学习生成精灵图像的概念是什么呢?它可能是一些精致的细节,比如精灵的头发颜色、腰带配饰等;也可能是一些大致的轮廓,比如头部轮廓、身体轮廓、或者介于两者之间的其它轮廓等。而做到这一点的一种方法,即通过获取数据并能够专注更精细的细节或轮廓的方法,实际上是添加不同级别的噪声(noise)。因此,这只是在图像中添加噪声,它被称为 “噪声过程”(noising process)。
这个思路其实是受到了物理学的启发,场景很类似一滴墨水滴到一杯清水里的全过程。最初我们确切地知道墨水滴落在那里;但是随着时间的推移,我们会看到墨水扩散到清水中直到它完全消失(或者说完全和清水融为一体)。
如下图所示,我们从最左边的图像“Bob the Sprite”开始,当添加噪音时,它会消失,直到我们辨别不出它到底是哪个精灵。

Source: How Diffusion Models Work,https://learn.deeplearning.ai/diffusion-models/lesson/2/intuition?trk=cndc-detail ,by DeepLearning.AI
以这个 Bob 精灵图像为例,以下详细描述通过添加不同阶段噪声,到精灵训练数据集的全过程。
在最左边图像“Bob the Sprite!”的时候,我们想让神经网络知道:“这就是 Bob ,它是一个精灵”。
到了“Probably Bob”的时候,我们想让神经网络知道:“你知道,这里有一些噪声”,不过通过一些细节它看起来像“Bob the Sprite!”。
到了“Well, Bob or Fred”这个图像时,变得只能看到精灵的模糊轮廓了。那么在这里我们感觉到这可能是精灵,但可能是精灵 Bob 、精灵 Fred ,或者是精灵 Nance ,这时我们可能想让神经网络为这些精灵图像推荐更通用的细节,比如:在此基础上为 Bob 建议一些细节,或者你会为 Fred 建议一些细节等。
到了最后“No Idea”这个图像时,虽然已经无法辨认图像的特征,我们仍然希望它看起来更像精灵。这时,我们仍然想让神经网络知道:“我希望你通过这张完全嘈杂的图像,通过提炼出精灵可能样子的轮廓,来把它变成更像精灵的图像”。
这就是整个“噪声过程”(noising process,即随着时间的推移逐渐增加噪声的过程,如同把一滴墨水完全扩散到一杯清水之中。我们需要训练的那个神经网络,就是希望它能够把不同的嘈杂图像变成美丽精灵。这就是我们的目标,即扩散模型的目标。
要让神经网络做到这一点,就是要让它学会去除添加的噪声。从“No Idea”这个图像开始(这时只是纯粹的噪声),到开始看起来像里面可能有精灵,再到长得像精灵 Bob ,到最后就是精灵 Bob。
这里要强调的是:“No Idea”这个图像的噪声非常重要,因为它是正态分布(normal distribution)的。换句话说,也就是这个图像的像素每一个都是从正态分布(又称 “高斯分布”)中采样的。
因此,当你希望神经网络生成一个新的精灵时,比如精灵 Fred ,你可以从该正态分布中采样噪声,然后你可以使用神经网络逐渐去除噪声来获得一个全新的精灵!除了你训练过的所有精灵之外,你还可以获得更多的精灵。

Source:How Diffusion Models Work, https://learn.deeplearning.ai/diffusion-models/lesson/2/intuition?trk=cndc-detail ,by DeepLearning.AI
恭喜你,你已经找到了生成大量的全新美丽精灵的理论方法!接下来就是代码实践了。
在下一章里,我们将用代码展示为了实现正态分布噪声采样,而主动在迭代阶段添加噪声的方法;和没有添加噪声方法的模型输出结果对比测试。这将是一次很有趣和难忘的扩散模型工作原理奇妙体验。
Sampling 噪声采样的代码实践
首先我们将讨论采样。我们将详细介绍采样的细节以及它在多个不同的迭代中是如何工作的。
1. 创建 Amazon SageMaker Notebook 实例
篇幅所限,本文不再赘述如何创建 Amazon SageMaker Notebook 实例。
如需详细了解,可参考以下官方文档:
https://docs.aws.amazon.com/zh_cn/sagemaker/latest/dg/gs-setup-working-env.html?trk=cndc-detail
2. 代码说明
本实验的完整示例代码可参考:
示例代码的 notebook 在 Amazon SageMaker Notebook 测试通过,内核为 conda_pytorch_p310 ,实例为一台 ml.g5.2xlarge 实例,如下图所示。
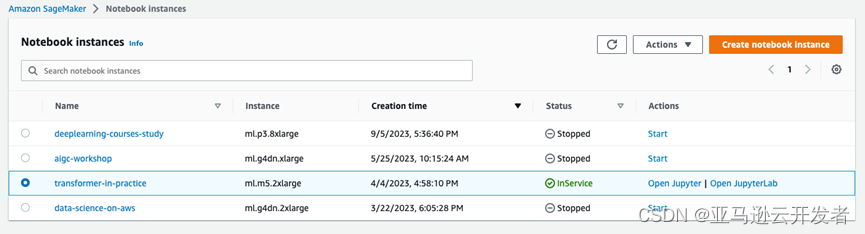
3. 采样过程说明
首先假设你有一个噪声样本(noise sample),你把这个噪声样本输入到一个已经训练好的神经网络中。这个神经网络已经知道精灵图像的样子,它接下来的主要工作是预测噪声。请注意:这个神经网络预测的是噪声而不是精灵图像,然后我们从噪声样本中减去预测的噪声,来得到更像精灵图像的输出结果。
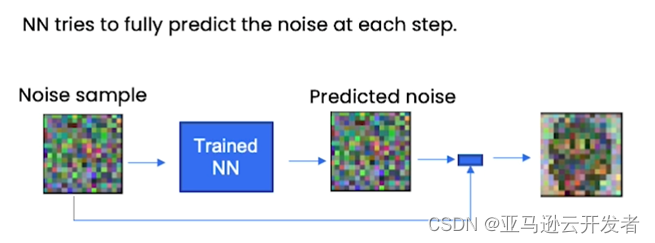
Source: How Diffusion Models Work, https://learn.deeplearning.ai/diffusion-models/lesson/2/intuition?trk=cndc-detail ,by DeepLearning.AI
由于只是对噪声的预测,它并不能完全消除所有噪声,因此需要多个步骤才能获得高质量的样本。比如我们希望在 500 次这样的迭代之后,能够得到看起来非常像精灵图像的输出结果。
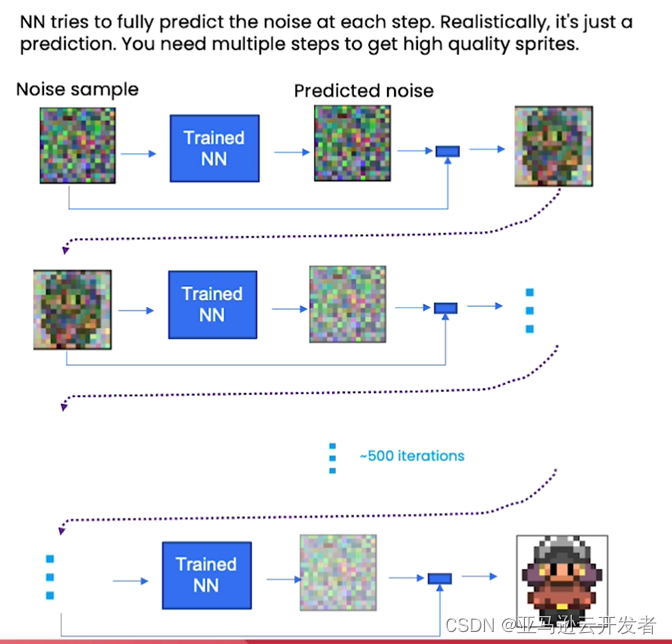
Source: How Diffusion Models Work,https://learn.deeplearning.ai/diffusion-models/lesson/2/intuition?trk=cndc-detail ,by DeepLearning.AI
我们先看一段伪代码,从算法实现上高屋建瓴地看下整个逻辑结构:

Source: How Diffusion Models Work, https://learn.deeplearning.ai/diffusion-models/lesson/2/intuition?trk=cndc-detail ,by DeepLearning.AI
首先我们以随机采样噪声样本(random noise sample)的方式,开始这段旅程。
如果你看过一些关于穿越时间旅行的电影,这整个过程很像是一段时间旅行。想像一下你有一杯墨汁,我们实际上是在用时光倒退(step backwards)的方式;它最初是完全扩散的漆黑墨汁,然后我们会一直追溯到有第一滴墨汁滴入一杯清水的那个最初时分。
然后,我们将采样一些额外噪声(extra noise)。为什么我们需要添加一些额外噪声,这其实是一个很有趣的话题,我们会在本文的后面部分详细探讨这个话题。
这是你实际将原始噪声、那个样本传递回神经网络的地方,然后你会得到一些预测的噪声。而这种预测噪声是经过训练的神经网络想要从原始噪声中减去的噪声,以在最后得到看起来更像精灵图像的输出结果。
最后我们还会用到一种名为 “DDPM” 的采样算法,它代表降噪扩散概率模型。
4. 导入所需的库文件
现在我们进入通过代码解读扩散模型的部分。首先,我们需要导入 PyTorch 和一些 PyTorch 相关的实用库,以及导入帮助我们设计神经网络的一些辅助函数(helper functions)。
- from typing import Dict, Tuple
- from tqdm import tqdm
- import torch
- import torch.nn as nn
- import torch.nn.functional as F
- from torch.utils.data import DataLoader
- from torchvision import models, transforms
- from torchvision.utils import save_image, make_grid
- import matplotlib.pyplot as plt
- from matplotlib.animation import FuncAnimation, PillowWriter
- import numpy as np
- from IPython.display import HTML
- from diffusion_utilities import *
5. 神经网络架构设计
现在我们来设置神经网络,我们要用它来采样。
-
- class ContextUnet(nn.Module):
- def __init__(self, in_channels, n_feat=256, n_cfeat=10, height=28): # cfeat - context features
- super(ContextUnet, self).__init__()
-
- # number of input channels, number of intermediate feature maps and number of classes
- self.in_channels = in_channels
- self.n_feat = n_feat
- self.n_cfeat = n_cfeat
- self.h = height #assume h == w. must be divisible by 4, so 28,24,20,16...
-
- # Initialize the initial convolutional layer
- self.init_conv = ResidualConvBlock(in_channels, n_feat, is_res=True)
- # Initialize the down-sampling path of the U-Net with two levels
- self.down1 = UnetDown(n_feat, n_feat) # down1 #[10, 256, 8, 8]
- self.down2 = UnetDown(n_feat, 2 * n_feat) # down2 #[10, 256, 4, 4]
-
- # original: self.to_vec = nn.Sequential(nn.AvgPool2d(7), nn.GELU())
- self.to_vec = nn.Sequential(nn.AvgPool2d((4)), nn.GELU())
-
- # Embed the timestep and context labels with a one-layer fully connected neural network
- self.timeembed1 = EmbedFC(1, 2*n_feat)
- self.timeembed2 = EmbedFC(1, 1*n_feat)
- self.contextembed1 = EmbedFC(n_cfeat, 2*n_feat)
- self.contextembed2 = EmbedFC(n_cfeat, 1*n_feat)
-
- # Initialize the up-sampling path of the U-Net with three levels
- self.up0 = nn.Sequential(
- nn.ConvTranspose2d(2 * n_feat, 2 * n_feat, self.h//4, self.h//4), # up-sample
- nn.GroupNorm(8, 2 * n_feat), # normalize
- nn.ReLU(),
- )
- self.up1 = UnetUp(4 * n_feat, n_feat)
- self.up2 = UnetUp(2 * n_feat, n_feat)
-
- # Initialize the final convolutional layers to map to the same number of channels as the input image
- self.out = nn.Sequential(
- nn.Conv2d(2 * n_feat, n_feat, 3, 1, 1), # reduce number of feature maps #in_channels, out_channels, kernel_size, stride=1, padding=0
- nn.GroupNorm(8, n_feat), # normalize
- nn.ReLU(),
- nn.Conv2d(n_feat, self.in_channels, 3, 1, 1), # map to same number of channels as input
- )
-
- def forward(self, x, t, c=None):
- """
- x : (batch, n_feat, h, w) : input image
- t : (batch, n_cfeat) : time step
- c : (batch, n_classes) : context label
- """
- # x is the input image, c is the context label, t is the timestep, context_mask says which samples to block the context on
-
- # pass the input image through the initial convolutional layer
- x = self.init_conv(x)
- # pass the result through the down-sampling path
- down1 = self.down1(x) #[10, 256, 8, 8]
- down2 = self.down2(down1) #[10, 256, 4, 4]
-
- # convert the feature maps to a vector and apply an activation
- hiddenvec = self.to_vec(down2)
-
- # mask out context if context_mask == 1
- if c is None:
- c = torch.zeros(x.shape[0], self.n_cfeat).to(x)
-
- # embed context and timestep
- cemb1 = self.contextembed1(c).view(-1, self.n_feat * 2, 1, 1) # (batch, 2*n_feat, 1,1)
- temb1 = self.timeembed1(t).view(-1, self.n_feat * 2, 1, 1)
- cemb2 = self.contextembed2(c).view(-1, self.n_feat, 1, 1)
- temb2 = self.timeembed2(t).view(-1, self.n_feat, 1, 1)
- #print(f"uunet forward: cemb1 {cemb1.shape}. temb1 {temb1.shape}, cemb2 {cemb2.shape}. temb2 {temb2.shape}")
-
- up1 = self.up0(hiddenvec)
- up2 = self.up1(cemb1*up1 + temb1, down2) # add and multiply embeddings
- up3 = self.up2(cemb2*up2 + temb2, down1)
- out = self.out(torch.cat((up3, x), 1))
- return out

6. 设置模型训练的超参数
接下来,我们将设置模型训练需要的一些超参数,包括:时间步长、图像尺寸等。
如果对照 DDPM 的论文,其中定义了一个 noise schedule 的概念, noise schedule 决定了在特定时间里步长对图像施加的噪点水平。因此,这部分只是构造一些你记得的缩放因子的 DDPM 算法参数。那些缩放值 S1、S2、S3 ,这些缩放值是在 noise schedule 中计算的。它之所以被称为 “Schedule”,是因为它取决于时间步长。

Source: How Diffusion Models Work, https://learn.deeplearning.ai/diffusion-models/lesson/2/intuition?trk=cndc-detail ,by DeepLearning.AI
超参数介绍:
- beta1:DDPM 算法的超参数
- beta2:DDPM 算法的超参数
- height:图像的长度和高度
- noise schedule(噪声调度):确定在某个时间步长应用于图像的噪声级别;
- S1,S2,S3:缩放因子的值
如下面代码所示,我们在这里设置的时间步长(timesteps)是 500 ;图像尺寸参数 height 设置为 16 ,表示这是 16 乘 16 的正方形图像;DDPM 的超参数 beta1 和 beta2 等等。
- # hyperparameters
-
- # diffusion hyperparameters
- timesteps = 500
- beta1 = 1e-4
- beta2 = 0.02
-
- # network hyperparameters
- device = torch.device("cuda:0" if torch.cuda.is_available() else torch.device('cpu'))
- n_feat = 64 # 64 hidden dimension feature
- n_cfeat = 5 # context vector is of size 5
- height = 16 # 16x16 image
- save_dir = './weights/'
请记住,你正在浏览 500 次的步骤,因为你正在经历你在这里看到的缓慢去除噪音的 500 次迭代。
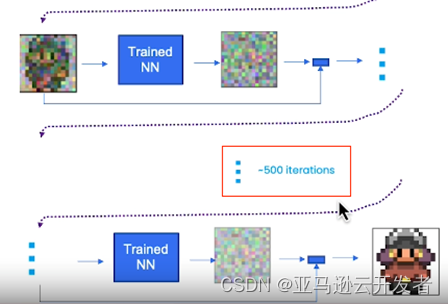
Source: How Diffusion Models Work, https://learn.deeplearning.ai/diffusion-models/lesson/2/intuition?trk=cndc-detail ,by DeepLearning.AI
以下代码块将构建 DDPM 论文中定义的时间步长(noise schedule):
- # construct DDPM noise schedule
- b_t = (beta2 - beta1) * torch.linspace(0, 1, timesteps + 1, device=device) + beta1
- a_t = 1 - b_t
- ab_t = torch.cumsum(a_t.log(), dim=0).exp()
- ab_t[0] = 1
接下来实例化模型:
- # construct model
- nn_model = ContextUnet(in_channels=3, n_feat=n_feat, n_cfeat=n_cfeat, height=height).to(device)
7. 添加额外噪声的输出测试
首先测试的是添加额外噪声的输出测试。可以重点关注下变量 z 。
在每次迭代之后,我们通过设置“z = torch.randn_like(x)”来添加额外的采样噪声,以让噪声输入符合正态分布:
- # helper function; removes the predicted noise (but adds some noise back in to avoid collapse)
- def denoise_add_noise(x, t, pred_noise, z=None):
- if z is None:
- z = torch.randn_like(x)
- noise = b_t.sqrt()[t] * z
- mean = (x - pred_noise * ((1 - a_t[t]) / (1 - ab_t[t]).sqrt())) / a_t[t].sqrt()
接下来加载该模型:
- # load in model weights and set to eval mode
- nn_model.load_state_dict(torch.load(f"{save_dir}/model_trained.pth", map_location=device))
- nn_model.eval()
- print("Loaded in Model")
以下代码段实现了前面介绍过的 DDPM 采样算法:
- # sample using standard algorithm
- @torch.no_grad()
- def sample_ddpm(n_sample, save_rate=20):
- # x_T ~ N(0, 1), sample initial noise
- samples = torch.randn(n_sample, 3, height, height).to(device)
-
- # array to keep track of generated steps for plotting
- intermediate = []
- for i in range(timesteps, 0, -1):
- print(f'sampling timestep {i:3d}', end='\r')
-
- # reshape time tensor
- t = torch.tensor([i / timesteps])[:, None, None, None].to(device)
-
- # sample some random noise to inject back in. For i = 1, don't add back in noise
- z = torch.randn_like(samples) if i > 1 else 0
- eps = nn_model(samples, t) # predict noise e_(x_t,t)
- samples = denoise_add_noise(samples, i, eps, z)
- if i % save_rate ==0 or i==timesteps or i<8:
- intermediate.append(samples.detach().cpu().numpy())
- intermediate = np.stack(intermediate)
- return samples, intermediate
运行模型以获得预测的噪声:
eps = nn_model(samples, t) # predict noise e_(x_t,t)最后降噪:
samples = denoise_add_noise(samples, i, eps, z)现在,让我们来可视化采样随时间推移的样子。这可能需要几分钟,具体取决于你在哪种硬件上运行。在本系列的第四集中,我们还将介绍一种快速采样(Fast Sampling)技术,这个在第四集中我们在详细讨论。
点击开始按钮来查看不同时间线上,模型生成的精灵图像,动图显示如下所示。
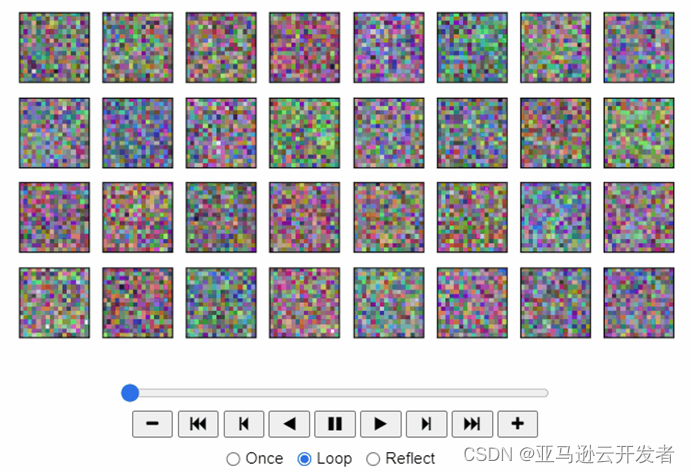
Source: Model output with Amazon SageMaker notebook instance
如果以上动图无法在手机上正常显示,可以参考下面这三张,我在不同时间线上分别做了截图。

Source: Model output with Amazon SageMaker notebook instance

Source: Model output with Amazon SageMaker notebook instance

Source: Model output with Amazon SageMaker notebook instance
8. 未添加额外噪声的输出测试
对于我们不添加噪音的输出测试,代码方面其实实现很简单,就是是将变量 z 设置为零,然后将其传入。代码如下所示。
- # incorrectly sample without adding in noise
- @torch.no_grad()
- def sample_ddpm_incorrect(n_sample):
- # x_T ~ N(0, 1), sample initial noise
- samples = torch.randn(n_sample, 3, height, height).to(device)
-
- # array to keep track of generated steps for plotting
- intermediate = []
- for i in range(timesteps, 0, -1):
- print(f'sampling timestep {i:3d}', end='\r')
-
- # reshape time tensor
- t = torch.tensor([i / timesteps])[:, None, None, None].to(device)
-
- # don't add back in noise
- z = 0
-
- eps = nn_model(samples, t) # predict noise e_(x_t,t)
- samples = denoise_add_noise(samples, i, eps, z)
- if i%20==0 or i==timesteps or i<8:
- intermediate.append(samples.detach().cpu().numpy())
-
- intermediate = np.stack(intermediate)
- return samples, intermediate
让我们来看看不添加噪音方式的输出结果,如下图所示:输出变形了!

Source: Model output with Amazon SageMaker notebook instance
这显然不是我们想要的结果。可见,在这个神经网络的架构设计中,在每个迭代阶段添加额外噪声,来保持输入噪声符合正态分布是很关键的一个步骤。
总结
作为 “扩散模型工作原理”代码实践系列的第一篇,本文通过两段不同代码块的实现,来对比了两种扩散模型的采样方法:
- 添加额外噪声的方法
- 不添加额外噪声的方法
总结来说,就是扩散模型的神经网络输入应该是符合正态分布的噪声样本。由于在迭代过程中,噪声样本减去模型预测的噪声之后得到的样本已经不符合正态分布了,所以容易导致输出变形。因此,在每次迭代之后,我们需要根据其所处的时间步长来添加额外的采样噪声,以让输入符合正态分布。这可以保证模型训练的稳定性,以避免模型的预测结果由于接近数据集的均值,而导致的输出结果变形。
这个系列之后的文章,我们将继续深入了解扩散过程和执行该过程的模型,帮助大家在更深层次的理解扩散模型;并且通过自己动手从头构建扩散模型,而不是仅仅引用预训练好的模型或使用模型的 API ,来对扩散模型底层实现原理的理解更加深刻。下一篇文章我们将用代码来实践扩散模型的训练,敬请期待。
参考资料
-
Sprites by ElvGames, FrootsnVeggies and kyrise
-
DDPM & DDIM papers
-
Diffusion model is based on Denoising Diffusion Probabilistic Models and Denoising Diffusion Implicit Models

作者 黄浩文
亚马逊云科技资深开发者布道师,专注于 AI/ML、Data Science 等。拥有 20 多年电信、移动互联网以及云计算等行业架构设计、技术及创业管理等丰富经验,曾就职于 Microsoft、Sun Microsystems、中国电信等企业,专注为游戏、电商、媒体和广告等企业客户提供 AI/ML、数据分析和企业数字化转型等解决方案咨询服务。


