
- 1iOS-YHChat仿微信聊天(老司机带你入门即时通讯)_masonry微信聊天
- 2JVM,堆,栈,方法区之间的关系_堆和栈在jvm里面吗
- 3VALSE 2024 计算机视觉与机器学习 | 文档解析与向量化技术加速多模态大模型训练与应用_ai解析切片 向量化
- 4翻译: 使用 GPT-4 将您的 Streamlit 应用程序提升到一个新的水平一_chatgpt 生成streamlit 应用
- 5用LLama-Factory训练和微调 LLama3,打造你的专属 AI 模型!
- 6【技巧】matlab批量读取nc文件并转为tif
- 7我要爬爬虫(14)Android下charles抓包_charles抓包安卓14
- 8labelme的json文件转换为yolo标签格式_labelme json 转换为yolov8格式
- 9hbase的安装和配置_hbase 十亿
- 10postgresql 15疑难进阶手册(1)- 安装(以freebsd为例)_freebsd系统上安装postgres数据库教程
糖尿病预测模型-Pima印第安人数据集-论文_企业科研_pima indians diabetes database写的论文
赞
踩
糖尿病概述
糖尿病有一型和二型,是由于胰腺分泌胰岛素紊乱或人体无法有效利用其产生的胰岛素而发生的一种慢性疾病,是21世纪人类面临的健康问题之一.糖尿病伴有弥漫性并发症,其包括心血管病变、肾脏疾病、高血压、中风等、眼部疾病、下肢截肢上百种,由此增加了过早死亡的风险.因此,糖尿病防治形势十分严峻.
下右图为糖尿病视网膜病变

2019年估算中国糖尿病患病率排名世界第二

中国糖尿病患者数量位居世界第一。中国是糖尿病最大药物研发市场。越来越多年轻人也加入糖尿病市场,成为药企摇钱树。

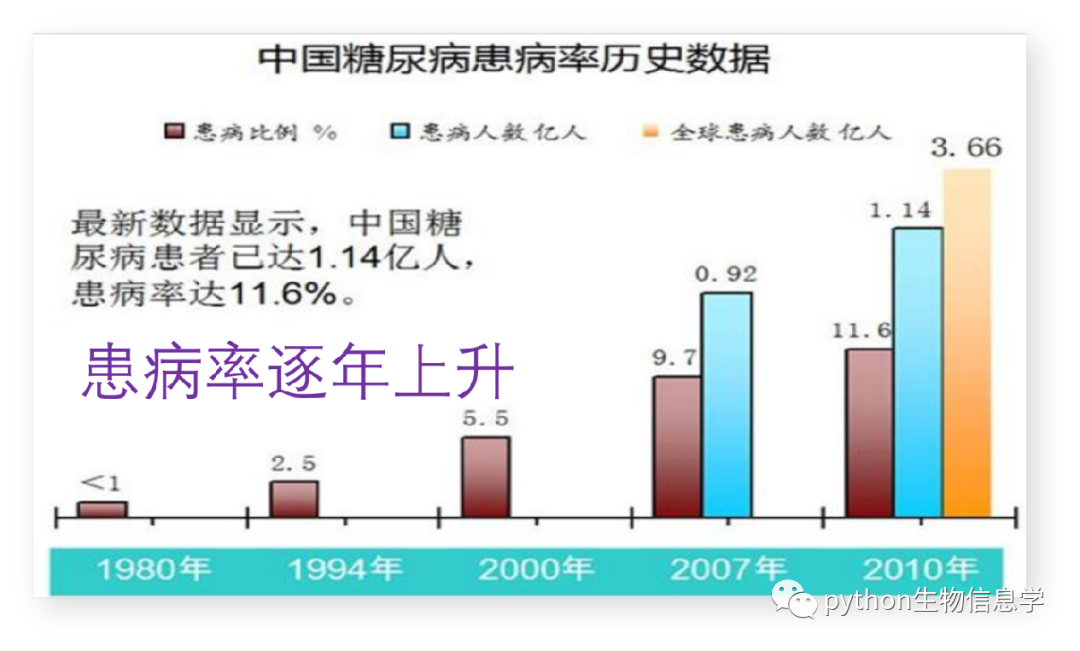
下图为中国糖尿病患病率历史数据
糖尿病给经济带来巨大负担
糖尿病也给经济带来了巨大的负担,每年诊断出的糖尿病成本约为 3270 亿美元,而未确诊的糖尿病和前驱糖尿病的总成本接近 4000 亿美元。

糖尿病可预防
虽然糖尿病无法治愈,但减肥、健康饮食、积极运动和接受药物治疗等策略可以减轻这种疾病对许多患者的危害。早期诊断可以改变生活方式和更有效的治疗,使糖尿病风险预测模型成为公共和公共卫生官员的重要工具。
糖尿病致病因子多样化
虽然有不同类型的糖尿病,但 II 型糖尿病是最常见的形式,其患病率因年龄、教育程度、收入、地点、种族和其他健康的社会决定因素而异。这种疾病的大部分负担也落在社会经济地位较低的人身上。
本实验就是通过建立人工智能机器学习模型,预测糖尿病概率和挖掘糖尿病重要致病因子。
糖尿病建模数据集介绍
糖尿病数据集来源Pima印第安人糖尿病数据集。数据集包含769条数据,9个变量。变量如下:妊娠, 血糖,血压,皮肤厚度,胰岛素,BMI,糖尿病系统功能,年龄,是否为糖尿病患者。
本研究的实验数据来自 UniversityofCalifornia,UGI机器学习数据库中的 PimaIndianDiabetes数据集,其研究对象是亚利桑那州凤凰城附近的皮马印第安人.该数据集共有768条数据项,包含8个医学预测变量和1个结果变量,其具体属性包括:怀孕次数(Pregnancies)、血糖浓度(Glucose)、年龄(Age)、血压(BloodPressure)、肱三头肌皮脂厚度(SkinThickness)、胰岛素含量(Insulin)、身体质量指数(BMI)、糖尿病遗传系数(DiabetesPedigreeFunction)和 结 果(Outcome,1代 表 患 糖 尿 病,0代 表 未 患 糖 尿 病).在PimaIndianDiabetes数据集中,Outcome为1的有268例,即为糖尿病患者人数;Outcome为0的有500例,即为未患有糖尿病的人数.

模型价值和意义
通过我们建立的人工智能机器学习预测模型,可实现以下一些研究问题:
1.模型能准确预测个人是否患有糖尿病。
2.模型能挖掘哪些风险因素最能预测糖尿病风险。
3.我们能使用风险因素的一个子集来准确预测一个人是否患有糖尿病。
4.我们可以使用筛选几个重要糖尿病致病特征,然后组合创建为一个简短的问题,以准确预测某人是否可能患有糖尿病或是否有糖尿病的高风险。

传统集成树算法虽然比决策树性能更优,但性能仍有改进空间。

型采用新一代对称树算法,有效降低过度拟合,提高模型预测速度和预测能力。

糖尿病预测模型性能优秀,ROC大于0.84。

通过描述性统计,我们观察匹马印第安糖尿病数据集变量直方图:BMI,血压,血糖三个变量呈现明显正态分布。

所有变量数据缺失率为0,是良好科研建模数据集。

变量相关性热力图显示:血糖,BMI,年龄与糖尿病有高度相关性。

通过数据挖掘,我们得到匹马印第安数据集中变量重要性排序。

模型启示录1
血糖-控制含糖量高的食品摄入,例如白糖,奶茶,糖果,零食。

模型启示录2
BMI-控制体重,适当锻炼

人工智能让生活更美好!

AI机器学习建模Pima印第安人糖尿病数据集-论文
版权声明:文章来自公众号(python生物信息学),未经许可,不得抄袭。遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。

