
- 1Axure的基本_axure 取整
- 2文件读写中的inputStream和outputStream_asinputstream
- 3【Nas/群晖/服务器】FRP内网穿透实现外网访问_nas frp
- 4Springboot项目以war包形式发布到tomcat流程及问题_tomcat springboot war包
- 5zabbix5.0 监控linux服务器tcp端口状态_zabbix监控tcp连接数模板下载
- 6微信小程序需要ajax吗,在微信小程序中封装自己的ajax
- 7机器学习入门(七)神经网络--代价函数、前向反向传播算法及问题_有关机器学习代价函数的问答题?
- 8kali系统下载_kali下载
- 9最全的Docker-compose应用部署!快收藏!_docker compose solr
- 10网络安全/信息安全(黑客技术)自学笔记
【YOLOV8实例分割——详细记录环境配置、自定义数据处理到模型训练与部署】_import json import os import argparse from tqdm im
赞
踩
前言
Ultralytics YOLOv8是一种前沿的、最先进的(SOTA)模型,它在前代YOLO版本的成功基础上进行了进一步的创新,引入了全新的特性和改进,以进一步提升性能和灵活性。作为一个高速、精准且易于操作的设计,YOLOv8在广泛的领域中,包括目标检测与跟踪、实例分割、图像分类以及姿势估计等任务中,都表现出色。
实例分割在物体检测的基础上迈出了更进一步的步伐,它不仅可以识别图像中的单个物体,还能够精确地将这些物体从图像的其他部分中分割出来。
目标识别:
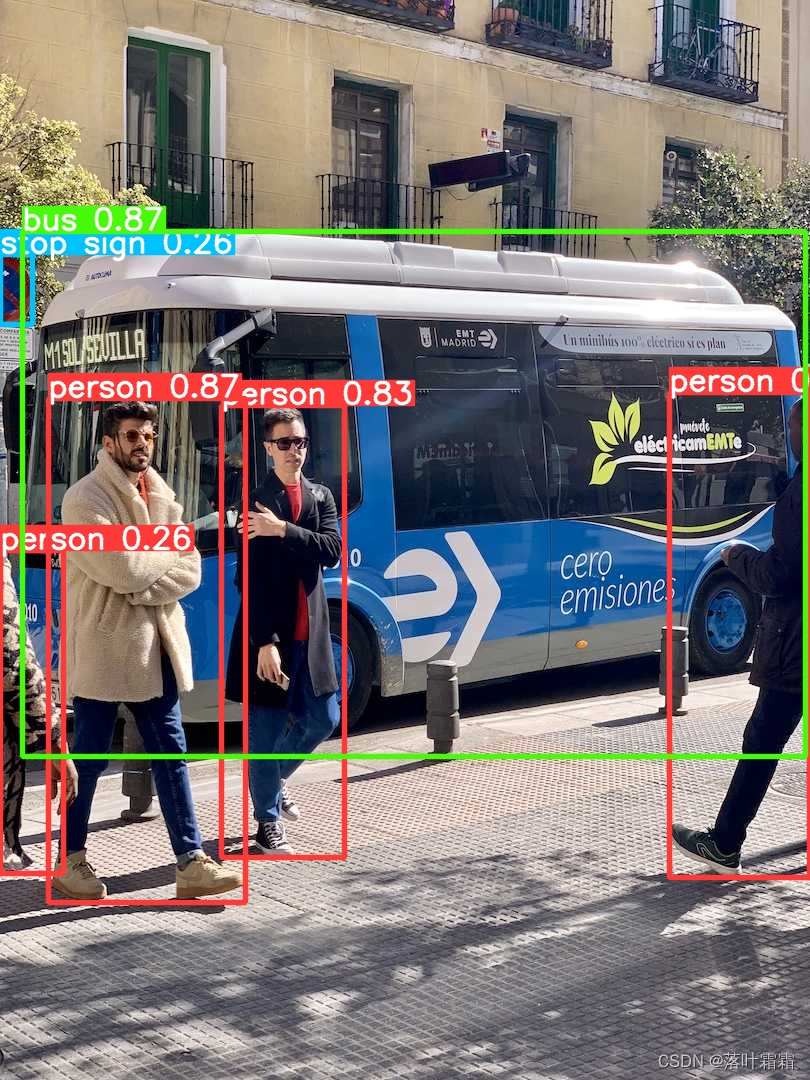
实例分割模型的输出是一组mask(或轮廓),这些遮罩清晰地勾勒出图像中的每个对象,同时还提供了每个对象的类别标签和置信度分数。当需要了解物体的准确形状时,实例分割变得非常有用,因为这不仅仅是关于物体位置的信息。
实例分割:
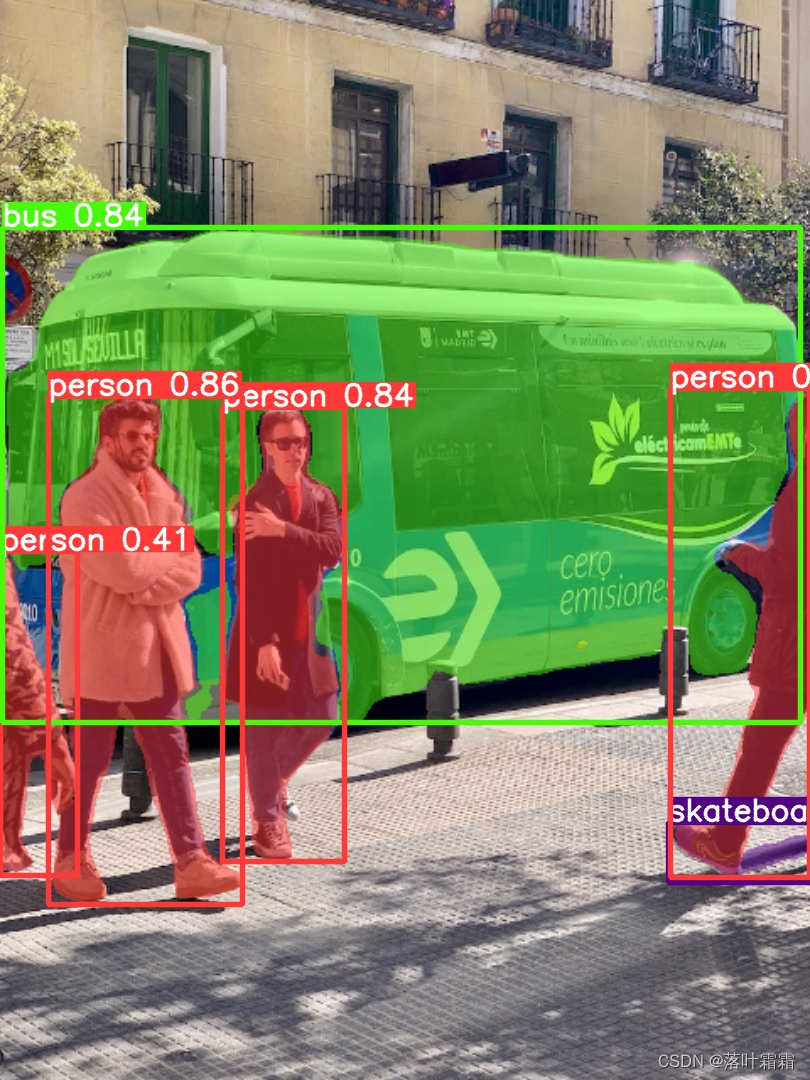
一、环境安装
1.直接安装
yolov8有两种安装方式,一种可直接安装U神的库,为了方便管理,还是在conda里面安装:
conda create -n yolov8 python=3.8
activate ylolv8
pip install ultralytics
- 1
- 2
- 3
2.源码安装
源码安装时,要单独安装torch,要不然训练的时候,有可能用不了GPU,我的环境是cuda 11.7。
#新建虚拟环境
conda create -n yolov8 python=3.8
#激活
conda activate yolov8
#安装torch,
conda install pytorch==2.0.0 torchvision==0.15.0 torchaudio==2.0.0 pytorch-cuda=11.7 -c pytorch -c nvidia
#下载源码
git clone https://github.com/ultralytics/ultralytics.git
cd ultralytics
#将requirements.txt中torch torchbision 注释掉,下载其他包
pip install -r requirements.txt
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
3.验证
安装完成之后,验证是否安装成功。
yolo task=segment mode=predict model=yolov8s-seg.pt source='1.jpg' show=True
- 1

4.安装错误
1.OMP: Error #15: Initializing libomp.dylib, but found libiomp5.dylib already initialize
如果在训练时出现这个错误,要么就降低numpy的版本,要么就是python的版本太高,降到3.9以下就可以了。
二、数据处理
1.数据集标注
标注工具是使用LabelMe进行标注,LabelMe允许用户在图像中绘制边界框、多边形、线条和点等来标注不同类型的对象或特征。也可以标注标注类别,用户可以定义不同的标注类别,使其适应不同的项目需求。每个类别都可以有自己的名称和颜色。
这里标注了湖面的区域,用来做目标入侵检测。

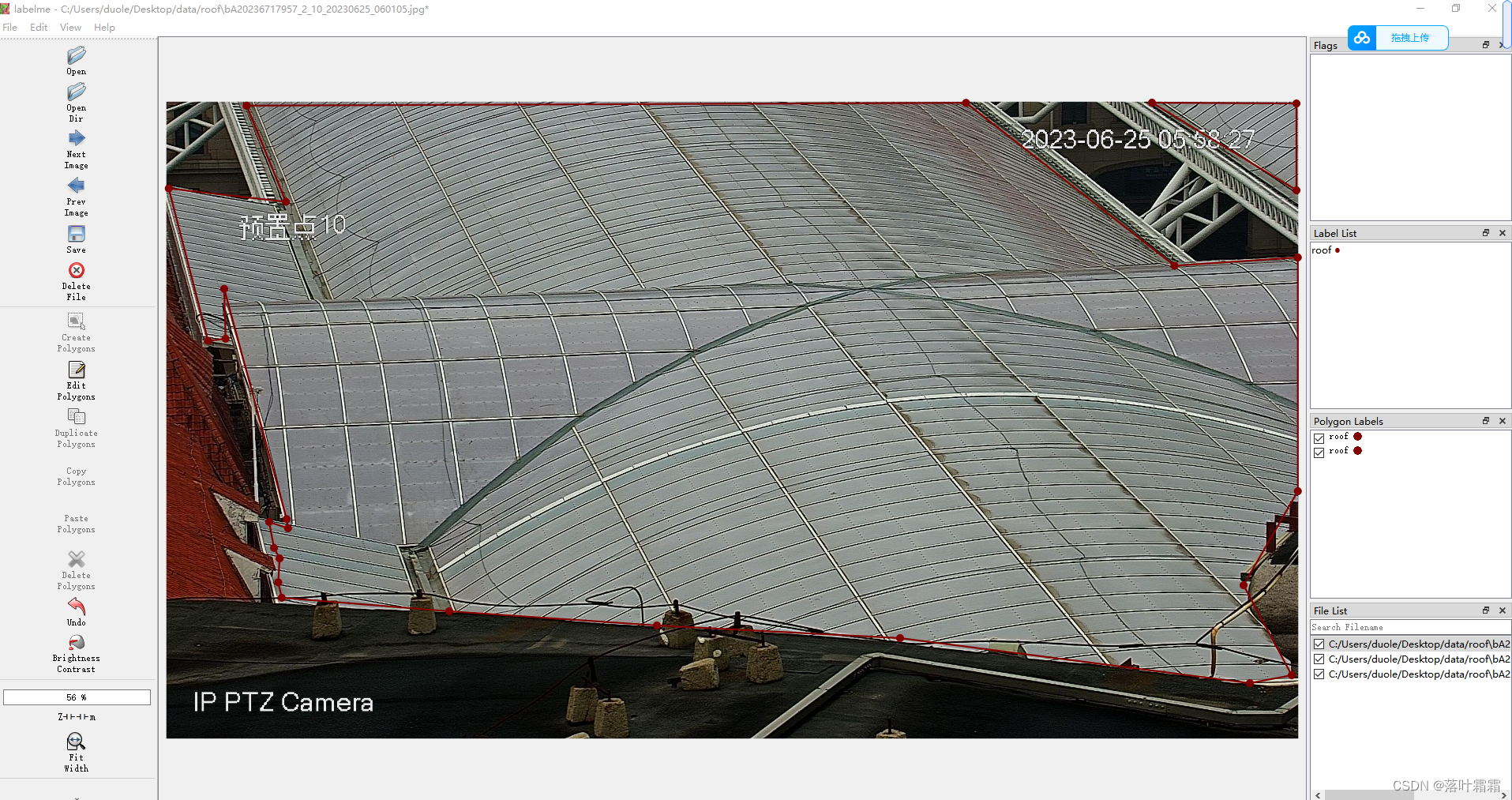
标注出来的数据格式是json如下:
在这里插入图片描述
2.数据集转换
标注完数据之后,在工程目录下创建一个dataset目录,dataset目录下包含有images、json_labels、labels三个目录,images存放数据集的所有的图像,json_labels目录下存放labelme标注出来的所有json标签,labels为空目录。
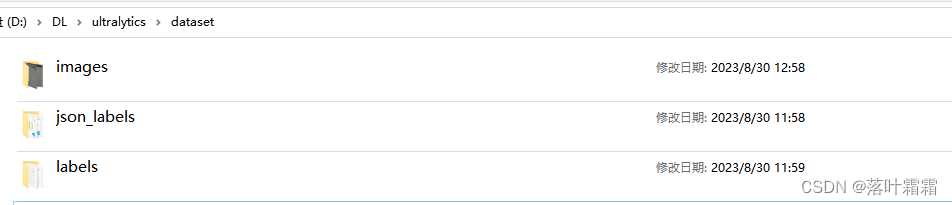
在当前目录下创建json2txt.py文件
# -*- coding: utf-8 -*- import json import os import argparse from tqdm import tqdm import glob import cv2 import numpy as np def convert_label_json(json_dir, save_dir, classes): json_paths = os.listdir(json_dir) classes = classes.split(',') for json_path in tqdm(json_paths): # for json_path in json_paths: path = os.path.join(json_dir, json_path) # print(path) with open(path, 'r') as load_f: print(load_f) json_dict = json.load(load_f, ) h, w = json_dict['imageHeight'], json_dict['imageWidth'] # save txt path txt_path = os.path.join(save_dir, json_path.replace('json', 'txt')) txt_file = open(txt_path, 'w') for shape_dict in json_dict['shapes']: label = shape_dict['label'] label_index = classes.index(label) points = shape_dict['points'] points_nor_list = [] for point in points: points_nor_list.append(point[0] / w) points_nor_list.append(point[1] / h) points_nor_list = list(map(lambda x: str(x), points_nor_list)) points_nor_str = ' '.join(points_nor_list) label_str = str(label_index) + ' ' + points_nor_str + '\n' txt_file.writelines(label_str) if __name__ == "__main__": parser = argparse.ArgumentParser(description='json convert to txt params') parser.add_argument('--json-dir', type=str, default='dataset/json_labels', help='json path dir') parser.add_argument('--save-dir', type=str, default='dataset/labels', help='txt save dir') parser.add_argument('--classes', type=str, default='surface', help='classes') args = parser.parse_args() json_dir = args.json_dir save_dir = args.save_dir classes = args.classes convert_label_json(json_dir, save_dir, classes)

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
运行json2txt.py之后,在labels里面生成txt标签文件,格式如下:
0 0.0019379844961240355 0.411190053285968 0.034496124031007755 0.41222272708496843 0.06705426356589148 0.411190053285968 0.08565891472868217 0.4163534222809699 0.1290697674418605 0.4235821388739725 0.17790697674418607 0.42771283406997396 0.23527131782945737 0.42771283406997396 0.34147286821705425 0.42771283406997396 0.3724806201550388 0.42151679127597175 0.37868217054263564 0.44113759345697884 0.42054263565891475 0.44630096245198064 0.9972868217054264 0.5227188235780081 0.9972868217054264 0.9946507497211781 0.0019379844961240355 0.9946507497211781
- 1
转换之后,一定要使用代码验证所转的数据是否正确:
def check_labels(txt_labels, images_dir): txt_files = glob.glob(txt_labels + "/*.txt") for txt_file in txt_files: filename = os.path.splitext(os.path.basename(txt_file))[0] pic_path = images_dir + filename + ".jpg" img = cv2.imread(pic_path) height, width, _ = img.shape file_handle = open(txt_file) cnt_info = file_handle.readlines() new_cnt_info = [line_str.replace("\n", "").split(" ") for line_str in cnt_info] color_map = {"0": (0, 255, 255)} for new_info in new_cnt_info: print(new_info) s = [] for i in range(1, len(new_info), 2): b = [float(tmp) for tmp in new_info[i:i + 2]] s.append([int(b[0] * width), int(b[1] * height)]) cv2.polylines(img, [np.array(s, np.int32)], True, color_map.get(new_info[0])) cv2.namedWindow('img2', 0) cv2.imshow('img2', img) cv2.waitKey()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
调用函数,显示转换后的效果:
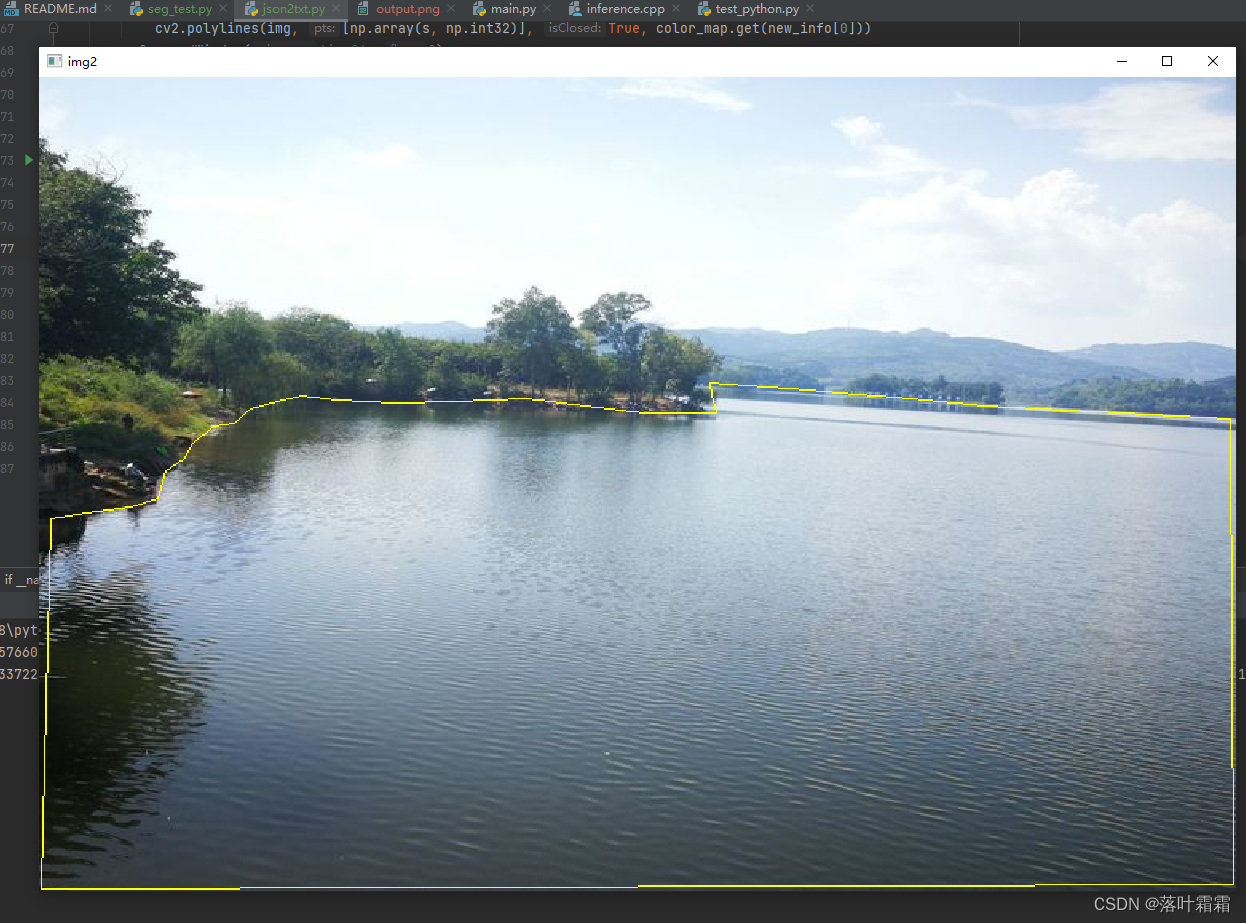
3.数据集分割
一般数据集划分为训练集和验证集是在开发深度学习模型时的常见做法。这种划分有助于评估模型的性能并进行超参数调整,以便提高模型的泛化能力。通常,常见的训练集和验证集的划分比例是9:1或者8:2,其中训练集占大部分,验证集占较小部分。
关训练集和验证集划分的指导原则:
数据量考虑: 数据集的大小是选择划分比例的一个关键因素。如果数据集较小,可能希望将更大的比例分配给训练集,以确保模型有足够的数据来学习。
数据的随机性: 确保在划分数据集时要随机混洗数据,以防止数据集中的任何特定模式或顺序影响模型的性能评估。
代表性: 确保训练集和验证集都代表了整个数据集的不同方面,以避免在验证模型性能时出现偏差。
交叉验证: 对于较小的数据集,您可以考虑使用交叉验证,将数据划分为多个折(folds),并在每次训练中使用不同的折作为验证集,从而更全面地评估模型性能。
超参数调整: 验证集通常用于调整模型的超参数,例如学习率、正则化强度等,以获得更好的性能。
不要在验证集上过拟合: 避免在验证集上进行过多的超参数调整或模型选择,以免模型在验证集上产生过拟合。
划分数据集的目的是确保模型在未见过的数据上具有良好的泛化能力。选择适当的训练集和验证集比例以及遵循上述指导原则将有助于提高深度学习项目的成功率。
数据集分割spilit_dataset.py代码:
# -*- coding:utf-8 -* import os import random import os import shutil def data_split(full_list, ratio): n_total = len(full_list) offset = int(n_total * ratio) if n_total == 0 or offset < 1: return [], full_list random.shuffle(full_list) sublist_1 = full_list[:offset] sublist_2 = full_list[offset:] return sublist_1, sublist_2 train_p="dataset/train" val_p="dataset/val" imgs_p="images" labels_p="labels" #创建训练集 if not os.path.exists(train_p):#指定要创建的目录 os.mkdir(train_p) tp1=os.path.join(train_p,imgs_p) tp2=os.path.join(train_p,labels_p) print(tp1,tp2) if not os.path.exists(tp1):#指定要创建的目录 os.mkdir(tp1) if not os.path.exists(tp2): # 指定要创建的目录 os.mkdir(tp2) #创建测试集文件夹 if not os.path.exists(val_p):#指定要创建的目录 os.mkdir(val_p) vp1=os.path.join(val_p,imgs_p) vp2=os.path.join(val_p,labels_p) print(vp1,vp2) if not os.path.exists(vp1):#指定要创建的目录 os.mkdir(vp1) if not os.path.exists(vp2): # 指定要创建的目录 os.mkdir(vp2) #数据集路径 images_dir="D:/DL/ultralytics/dataset/images" labels_dir="D:/DL/ultralytics/dataset/labels" #划分数据集,设置数据集数量占比 proportion_ = 0.9 #训练集占比 total_file = os.listdir(images_dir) num = len(total_file) # 统计所有的标注文件 list_=[] for i in range(0,num): list_.append(i) list1,list2=data_split(list_,proportion_) for i in range(0,num): file=total_file[i] print(i,' - ',total_file[i]) name=file.split('.')[0] if i in list1: jpg_1 = os.path.join(images_dir, file) jpg_2 = os.path.join(train_p, imgs_p, file) txt_1 = os.path.join(labels_dir, name + '.txt') txt_2 = os.path.join(train_p, labels_p, name + '.txt') if os.path.exists(txt_1) and os.path.exists(jpg_1): shutil.copyfile(jpg_1, jpg_2) shutil.copyfile(txt_1, txt_2) elif os.path.exists(txt_1): print(txt_1) else: print(jpg_1) elif i in list2: jpg_1 = os.path.join(images_dir, file) jpg_2 = os.path.join(val_p, imgs_p, file) txt_1 = os.path.join(labels_dir, name + '.txt') txt_2 = os.path.join(val_p, labels_p, name + '.txt') shutil.copyfile(jpg_1, jpg_2) shutil.copyfile(txt_1, txt_2) print("数据集划分完成: 总数量:",num," 训练集数量:",len(list1)," 验证集数量:",len(list2))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
运行之后,在dataset下面多出train和val两个目录:
三、模型训练
1.数据文件
在ultralytics/cfg/datasets目录下复制一份coc128-seg.yaml复制ultralytics目录,重新命名成water-seg.yaml。
然后抒文件内容改成自己的数据路径:
# Ultralytics YOLO 声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/2023面试高手/article/detail/122449Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

