
- 1完整指南:如何用Python进行数据挖掘和分析,规避并利用深度回撤?_python量化分析:私募方向+数据挖掘
- 2简单3步升级USB Type-C设备,240W(48V 5A)PD Sink HUSB238A强势推出,电子产品快速充电或升级为USB PD QC快充解决方案:HUSB238诱骗线材和转接头_48v转usb
- 350个javaweb毕设项目选题分享【源码+论文】(三)_javaweb期末项目选题
- 4python中64编码和解码方式_64位解码
- 5【随手记录】Llama Tutorial 大语言模型实践 手把手系列带实践源码_llama系列模型实践
- 6android 解析转义字符,Android常见XML转义字符(总结)
- 7cdsn入门篇
- 8matlab编写的流体计算和传热_matlab项目合作
- 9Python跳动的爱心_python爱心代码跳动
- 10Android Studio App开发之循环试图RecyclerView,布局管理器LayoutManager、动态更新循环视图讲解及实战(附源码)_app:layoutmanager
算法沉淀——BFS 解决最短路问题(leetcode真题剖析)
赞
踩

BFS(广度优先搜索)是解决最短路径问题的一种常见算法。在这种情况下,我们通常使用BFS来查找从一个起始点到目标点的最短路径。
具体步骤如下:
- 初始化: 从起始点开始,将其放入队列中,并标记为已访问。
- BFS遍历: 不断从队列中取出顶点,然后探索与该顶点相邻且未被访问的顶点。对于每个相邻顶点,将其标记为已访问,并将其加入队列。这样,每一轮
BFS都会探索到当前距离起始点的步数更多的顶点。 - 重复步骤2: 重复这个过程,直到找到目标点或者队列为空。
- 路径重建(可选): 如果需要找到实际的路径而不仅仅是路径的长度,通常在
BFS的过程中维护一个记录每个顶点是由哪个顶点发现的信息,然后通过回溯从目标点追溯到起始点,重建路径。
BFS的优势在于它保证首次到达目标点的路径就是最短路径,因为在BFS的遍历过程中,我们首次访问一个顶点时,它是离起始点最近的未访问顶点之一。
这种算法广泛应用于图的最短路径问题,例如在无权图中寻找最短路径,或者在有权图中,权值为1的情况下寻找最少步数的路径。
01.迷宫中离入口最近的出口
题目链接:https://leetcode.cn/problems/nearest-exit-from-entrance-in-maze/
给你一个 m x n 的迷宫矩阵 maze (下标从 0 开始),矩阵中有空格子(用 '.' 表示)和墙(用 '+' 表示)。同时给你迷宫的入口 entrance ,用 entrance = [entrancerow, entrancecol] 表示你一开始所在格子的行和列。
每一步操作,你可以往 上,下,左 或者 右 移动一个格子。你不能进入墙所在的格子,你也不能离开迷宫。你的目标是找到离 entrance 最近 的出口。出口 的含义是 maze 边界 上的 空格子。entrance 格子 不算 出口。
请你返回从 entrance 到最近出口的最短路径的 步数 ,如果不存在这样的路径,请你返回 -1 。
示例 1:
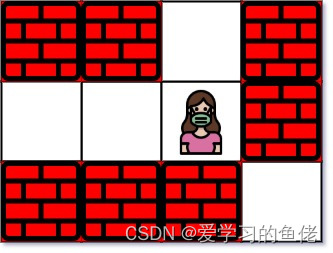
输入:maze = [["+","+",".","+"],[".",".",".","+"],["+","+","+","."]], entrance = [1,2]
输出:1
解释:总共有 3 个出口,分别位于 (1,0),(0,2) 和 (2,3) 。
一开始,你在入口格子 (1,2) 处。
- 你可以往左移动 2 步到达 (1,0) 。
- 你可以往上移动 1 步到达 (0,2) 。
从入口处没法到达 (2,3) 。
所以,最近的出口是 (0,2) ,距离为 1 步。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
示例 2:

输入:maze = [["+","+","+"],[".",".","."],["+","+","+"]], entrance = [1,0]
输出:2
解释:迷宫中只有 1 个出口,在 (1,2) 处。
(1,0) 不算出口,因为它是入口格子。
初始时,你在入口与格子 (1,0) 处。
- 你可以往右移动 2 步到达 (1,2) 处。
所以,最近的出口为 (1,2) ,距离为 2 步。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
示例 3:

输入:maze = [[".","+"]], entrance = [0,0]
输出:-1
解释:这个迷宫中没有出口。
- 1
- 2
- 3
提示:
maze.length == mmaze[i].length == n1 <= m, n <= 100maze[i][j]要么是'.',要么是'+'。entrance.length == 20 <= entrancerow < m0 <= entrancecol < nentrance一定是空格子。
思路
这是属于图论中边路权值为1的情况,利用层序遍历来解决迷宫问题是最经典的做法。我们可以从起点开始层序遍历,并且在遍历的过程中记录当前遍历的层数。这样就能在找到出口的时候,得到起点到出口的最短距离。
代码
class Solution { const int dx[4]={0,0,1,-1}; const int dy[4]={-1,1,0,0}; public: int nearestExit(vector<vector<char>>& maze, vector<int>& entrance) { queue<pair<int,int>> q; int m=maze.size(),n=maze[0].size(); int visit[m][n]; memset(visit,0,sizeof visit); int step=0; q.push({entrance[0],entrance[1]}); visit[entrance[0]][entrance[1]]=1; while(!q.empty()){ step++; int sz=q.size(); for(int i=0;i<sz;++i){ auto [a,b]=q.front(); q.pop(); for(int k=0;k<4;++k){ int x=a+dx[k],y=b+dy[k]; if(x>=0&&x<m&&y>=0&&y<n&&maze[x][y]=='.'&&!visit[x][y]){ if(x==0||x==m-1||y==0||y==n-1) return step; q.push({x,y}); visit[x][y]=1; } } } } return -1; } };

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 定义了常量数组
dx和dy表示上下左右四个方向。 - 使用
BFS进行迷宫遍历。 - 使用队列
q存储当前需要遍历的点,使用数组visit记录是否访问过。 - 将入口点入队,并标记为已访问。
- 在每一步中,从队列中取出当前层次的所有点,并尝试在四个方向上扩展。
- 如果扩展到边界,说明找到了最近的出口,返回步数。
- 如果队列为空仍未找到,说明无法找到出口,返回 -1。
02.最小基因变化
题目链接:https://leetcode.cn/problems/minimum-genetic-mutation/
基因序列可以表示为一条由 8 个字符组成的字符串,其中每个字符都是 'A'、'C'、'G' 和 'T' 之一。
假设我们需要调查从基因序列 start 变为 end 所发生的基因变化。一次基因变化就意味着这个基因序列中的一个字符发生了变化。
- 例如,
"AACCGGTT" --> "AACCGGTA"就是一次基因变化。
另有一个基因库 bank 记录了所有有效的基因变化,只有基因库中的基因才是有效的基因序列。(变化后的基因必须位于基因库 bank 中)
给你两个基因序列 start 和 end ,以及一个基因库 bank ,请你找出并返回能够使 start 变化为 end 所需的最少变化次数。如果无法完成此基因变化,返回 -1 。
注意:起始基因序列 start 默认是有效的,但是它并不一定会出现在基因库中。
示例 1:
输入:start = "AACCGGTT", end = "AACCGGTA", bank = ["AACCGGTA"]
输出:1
- 1
- 2
示例 2:
输入:start = "AACCGGTT", end = "AAACGGTA", bank = ["AACCGGTA","AACCGCTA","AAACGGTA"]
输出:2
- 1
- 2
示例 3:
输入:start = "AAAAACCC", end = "AACCCCCC", bank = ["AAAACCCC","AAACCCCC","AACCCCCC"]
输出:3
- 1
- 2
提示:
start.length == 8end.length == 80 <= bank.length <= 10bank[i].length == 8start、end和bank[i]仅由字符['A', 'C', 'G', 'T']组成
思路
其实这也可以直接转化成边路权值为1的图论问题。具体思路是:
- 使用哈希集合
hash存储基因库,便于快速查询某个基因是否合法。 - 使用广度优先搜索(
BFS),从起始基因开始,不断变异基因,直到找到目标基因为止。 - 在每一步中,对当前基因的每个位置尝试变异成可能的字符,如果变异后的基因是合法的且未被访问过,就加入队列中,并标记为已访问。
- 如果队列为空仍未找到目标基因,返回-1,表示无法变异到目标基因。
- 如果找到目标基因,返回步数
代码
class Solution { public: int minMutation(string startGene, string endGene, vector<string>& bank) { unordered_set<string> vis; // 用于记录已经访问过的基因序列 unordered_set<string> hash(bank.begin(), bank.end()); // 将基因库放入哈希集合中,方便查询是否是合法基因 if (startGene == endGene) return 0; // 如果起始基因和目标基因相同,不需要变异,返回步数为0 if (!hash.count(endGene)) return -1; // 如果目标基因不在基因库中,无法变异到目标基因,返回-1 string change = "ACGT"; // 可能的基因变异字符 queue<string> q; q.push(startGene); vis.insert(startGene); int ret = 0; while (!q.empty()) { ret++; int sz = q.size(); while (sz--) { string t = q.front(); q.pop(); for (int i = 0; i < 8; ++i) { string tmp = t; for (int j = 0; j < 4; ++j) { tmp[i] = change[j]; // 尝试将当前位置的基因变异为可能的字符 if (hash.count(tmp) && !vis.count(tmp)) { // 如果变异后的基因是合法的且未被访问过 if (tmp == endGene) return ret; // 如果变异后的基因与目标基因相同,返回步数 q.push(tmp); vis.insert(tmp); // 标记为已访问 } } } } } return -1; // 如果队列为空仍未找到目标基因,说明无法变异到目标基因,返回-1 } };
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
03.单词接龙
题目链接:https://leetcode.cn/problems/word-ladder/
字典 wordList 中从单词 beginWord 和 endWord 的 转换序列 是一个按下述规格形成的序列 beginWord -> s1 -> s2 -> ... -> sk:
- 每一对相邻的单词只差一个字母。
- 对于
1 <= i <= k时,每个si都在wordList中。注意,beginWord不需要在wordList中。 sk == endWord
给你两个单词 beginWord 和 endWord 和一个字典 wordList ,返回 从 beginWord 到 endWord 的 最短转换序列 中的 单词数目 。如果不存在这样的转换序列,返回 0 。
示例 1:
输入:beginWord = "hit", endWord = "cog", wordList = ["hot","dot","dog","lot","log","cog"]
输出:5
解释:一个最短转换序列是 "hit" -> "hot" -> "dot" -> "dog" -> "cog", 返回它的长度 5。
- 1
- 2
- 3
示例 2:
输入:beginWord = "hit", endWord = "cog", wordList = ["hot","dot","dog","lot","log"]
输出:0
解释:endWord "cog" 不在字典中,所以无法进行转换。
- 1
- 2
- 3
提示:
1 <= beginWord.length <= 10endWord.length == beginWord.length1 <= wordList.length <= 5000wordList[i].length == beginWord.lengthbeginWord、endWord和wordList[i]由小写英文字母组成beginWord != endWordwordList中的所有字符串 互不相同
思路
其实这道困难题和上面的题思路基本一致,只不过变化范围扩大到了26个小写字母,还有返回值的计算。
- 使用哈希集合
hash存储单词列表,便于快速查询某个单词是否合法。 - 使用广度优先搜索(
BFS),从起始单词开始,不断替换单词的每个位置的字符,直到找到目标单词为止。 - 在每一步中,对当前单词的每个位置尝试替换成可能的字符,如果替换后的单词是合法的且未被访问过,就加入队列中,并标记为已访问。
- 如果队列为空仍未找到目标单词,返回0,表示无法接龙到目标单词。
- 如果找到目标单词,返回步数。
代码
class Solution { public: int ladderLength(string beginWord, string endWord, vector<string>& wordList) { unordered_set<string> vis; // 用于记录已经访问过的单词 unordered_set<string> hash(wordList.begin(), wordList.end()); // 将单词列表放入哈希集合中,方便查询是否是合法单词 if (beginWord == endWord) return 1; // 如果起始单词和目标单词相同,不需要接龙,返回步数为1 if (!hash.count(endWord)) return 0; // 如果目标单词不在单词列表中,无法接龙到目标单词,返回0 int ret = 1; queue<string> q; q.push(beginWord); vis.insert(beginWord); while (!q.empty()) { ret++; int sz = q.size(); while (sz--) { string t = q.front(); q.pop(); for (int i = 0; i < t.size(); ++i) { string tmp = t; for (char c = 'a'; c <= 'z'; ++c) { tmp[i] = c; // 尝试将当前位置的字符替换为可能的字符 if (hash.count(tmp) && !vis.count(tmp)) { // 如果替换后的单词是合法的且未被访问过 if (tmp == endWord) return ret; // 如果替换后的单词与目标单词相同,返回步数 q.push(tmp); vis.insert(tmp); // 标记为已访问 } } } } } return 0; // 如果队列为空仍未找到目标单词,说明无法接龙到目标单词,返回0 } };
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
04.为高尔夫比赛砍树
题目链接:https://leetcode.cn/problems/cut-off-trees-for-golf-event/
你被请来给一个要举办高尔夫比赛的树林砍树。树林由一个 m x n 的矩阵表示, 在这个矩阵中:
0表示障碍,无法触碰1表示地面,可以行走比 1 大的数表示有树的单元格,可以行走,数值表示树的高度
每一步,你都可以向上、下、左、右四个方向之一移动一个单位,如果你站的地方有一棵树,那么你可以决定是否要砍倒它。
你需要按照树的高度从低向高砍掉所有的树,每砍过一颗树,该单元格的值变为 1(即变为地面)。
你将从 (0, 0) 点开始工作,返回你砍完所有树需要走的最小步数。 如果你无法砍完所有的树,返回 -1 。
可以保证的是,没有两棵树的高度是相同的,并且你至少需要砍倒一棵树。
示例 1:
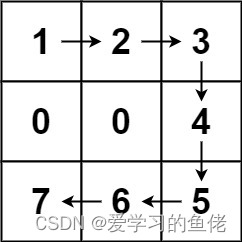
输入:forest = [[1,2,3],[0,0,4],[7,6,5]]
输出:6
解释:沿着上面的路径,你可以用 6 步,按从最矮到最高的顺序砍掉这些树。
- 1
- 2
- 3
示例 2:
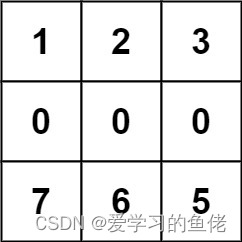
输入:forest = [[1,2,3],[0,0,0],[7,6,5]]
输出:-1
解释:由于中间一行被障碍阻塞,无法访问最下面一行中的树。
- 1
- 2
- 3
示例 3:
输入:forest = [[2,3,4],[0,0,5],[8,7,6]]
输出:6
解释:可以按与示例 1 相同的路径来砍掉所有的树。
(0,0) 位置的树,可以直接砍去,不用算步数。
- 1
- 2
- 3
- 4
提示:
m == forest.lengthn == forest[i].length1 <= m, n <= 500 <= forest[i][j] <= 109
思路
这里和之前的题不一样的地方是,我们每次都要找到最矮的树依次砍完所有的数,所以我们要针对从小到大每颗数的相对位置进行BFS遍历计算步数。
- 遍历整个矩形森林,将树木的位置加入
trees数组中。 - 根据树木的高度进行排序。
- 遍历排好序的树木数组,使用广度优先搜索(
BFS)计算从当前位置(bx, by)到目标位置(a, b)的步数。 - 如果无法到达目标位置,返回 -1。
- 累加步数,并更新起始位置
(bx, by)。 - 最终返回累加的步数作为结果。
代码
class Solution { const int dx[4] = {0, 0, 1, -1}; const int dy[4] = {-1, 1, 0, 0}; int m, n; int vis[51][51]; int bfs(vector<vector<int>>& forest, int bx, int by, int ex, int ey) { if (bx == ex && by == ey) return 0; // 如果起始位置和目标位置相同,步数为0 queue<pair<int, int>> q; memset(vis, 0, sizeof vis); q.push({bx, by}); vis[bx][by] = 1; int step = 0; while (!q.empty()) { step++; int sz = q.size(); while (sz--) { auto [a, b] = q.front(); q.pop(); for (int i = 0; i < 4; ++i) { int x = a + dx[i], y = b + dy[i]; if (x >= 0 && x < m && y >= 0 && y < n && forest[x][y] && !vis[x][y]) { if (x == ex && y == ey) return step; // 如果到达目标位置,返回步数 q.push({x, y}); vis[x][y] = 1; // 标记为已访问 } } } } return -1; // 如果未能到达目标位置,返回-1表示无法到达 } public: int cutOffTree(vector<vector<int>>& forest) { m = forest.size(), n = forest[0].size(); vector<pair<int, int>> trees; // 遍历整个矩形森林,将树木的位置加入trees数组中 for (int i = 0; i < m; i++) { for (int j = 0; j < n; j++) { if (forest[i][j] > 1) trees.push_back({i, j}); } } // 根据树木的高度进行排序 sort(trees.begin(), trees.end(), [&](const pair<int, int>& p1, const pair<int, int>& p2) { return forest[p1.first][p1.second] < forest[p2.first][p2.second]; }); int bx = 0, by = 0; // 起始位置为(0, 0) int ret = 0; // 遍历排好序的树木数组 for (auto& [a, b] : trees) { // 使用BFS计算从当前位置到目标位置的步数 int step = bfs(forest, bx, by, a, b); if (step == -1) return -1; // 如果无法到达目标位置,返回-1 ret += step; // 累加步数 bx = a, by = b; // 更新起始位置 } return ret; } };
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65

