- 1翻译:Practical Hidden Voice Attacks against Speech and Speaker Recognition Systems_speech over the air
- 2Springboot+Dubbo+Nacos实现RPC调用_dubbo rpc + nacos
- 3vscode网页版的正确打开方式(建立tunnel-p2p连接)
- 4聊聊前后端分离接口规范
- 5Vivado SDK报错Error while launching program: Memory write error at 0x100000. AP transaction timeout.
- 62024国际生物发酵展畅想未来-势拓伺服科技
- 7南京邮电大学操作系统实验三:虚拟内存页面置换算法_3、页面置换算法 (1)使用数组存储一组页面请求,页面请求的数量要50个以上,访问的
- 8【概率论】斗地主中出现炸弹的几率
- 9如何打造一个可躺赚的网盘项目,每天只需要2小时_网上躺赚项目
- 10osg qt5.15 osg3.6.3 osgEarth3.1 编译爬山
GPT模型系列_gpt mask
赞
踩
1、Mask Multi-head Attentiion
Mask Multi-head Attentiion,应用在tTransformer的decoder中,为了避免预测时能够看见未来的信息,运用到了mask机制
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-3krfitxt-1658062021318)(H:\baidu\NLP8\笔记\笔记\研修\image\image-20220717201645411.png)]](https://img-blog.csdnimg.cn/d703cd96c5434232be535b51829e59f0.png)
如上图所示,与RNN 的预测方式不同RNN的循环结构对于建模语言模型有着先天的优势,可以用当前时间步的隐隐状态去预测未来下一时刻的token,但是对于运用sel-attention机制的decoder来说没这样做不行,(为了预测下一个token,你需要需要知道下一个token是啥,这明显是个悖论。)。因此使用mask机制,仔细来说就是,让模型每次预测时候们看不见为了时候的token,比如用有y1预测x2,然后用y2预测x3。 所以GPT系列模型就是使用transf的decoder这样一个架构,去训练一个单向语言模型。
说到这里,会联想到一种训练方式 : Teacher Forcing
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-W2bHzk0k-1658062021319)(H:\baidu\NLP8\笔记\笔记\研修\image\image-20220717202548951.png)]
GPT就是采用这种Teacher Forcing 的方式去训练,按道理来说,标准的语言模型的训练需要将上一个时刻预测的词作为下一时刻的输入,但是这样的训练方式,太慢,复杂度变成了O(n),采用teacher forcing 的方式去训练,虽然模型丧失了一定的纠错能力,但是训练变快。时间复杂度为O(1),并且从实践来看,这样的训练方式,结果并没有太差。
2、Generative Pre-Traning (GPT)
GPT就是一个单向的预训练语言模型,用的Transformer的decoder,一句话就将GPT讲完了。

3、GPT2
GPT的缺点是,还是采用两种范式,即预训练和微调。GPT2主打不需要微调 ,论文里称Zero shot,但是有点像prompt
反正就与GPT相比更大的参数更大的数据集。
GPT-2能做这么大有几点细节有:
1、使用的BPE编码
2、将layer norm 放在 掩码自注意力的前边 即 pre-norm 使得网络的层数可以更深。
3、使用了top-k的采样方式
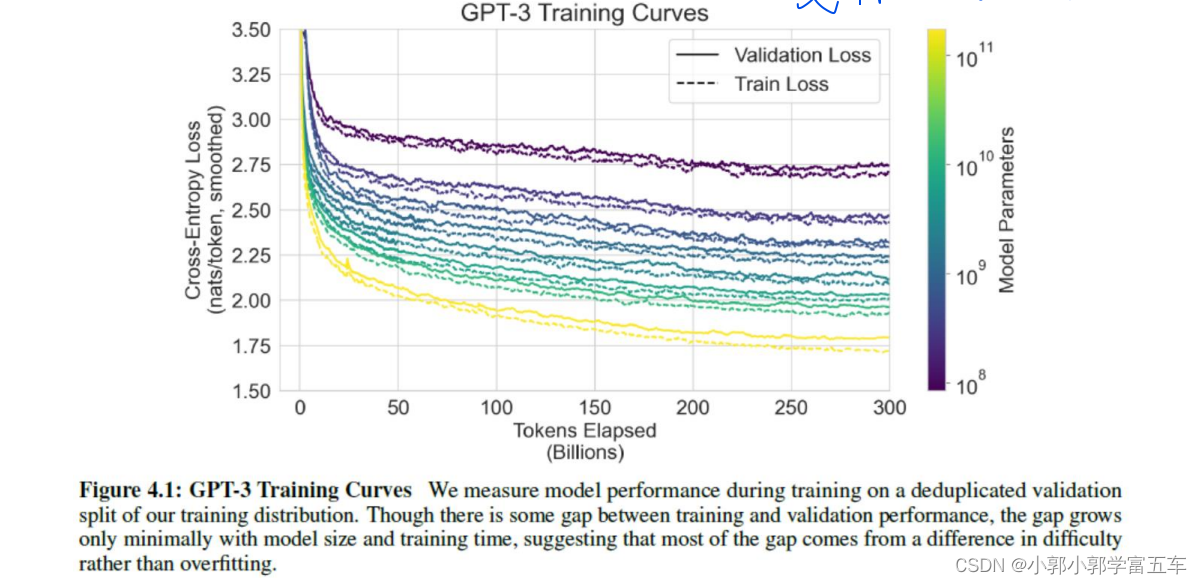
4、GPT3
更大的模型。更大的数据集,证明了一点,模型很大确实很管用,而且即使这么大了,从训练的Loss曲线来看,还没有停止下降。