
- 1金融统计分析与挖掘实战8.3-8.4_基于总体规模与投资效率指标的综合评价法python
- 2云服务器做深度学习推荐+autoDL云服务器进行深度学习教程_autodl 飞浆
- 3阿里云---阿里云服务器ECS开放8080端口_阿里云服务器开放8080端口
- 4如何把要想保存的文章转为 Markdown 格式
- 5ElasticSearch高可用安装部署(Linux)_elasticsearch高可用部署
- 6开源软件许可证知识产权问题_开源软件许可的“后台”和“前台”知识产权。
- 7Linux自学笔记——Centos系统安装
- 8开源中国众包平台的个人空间 工作日志 正文 关于你对软件众包的误解,你真的错了。_开源众包操作手册
- 9【golang】25、图片操作
- 10认识Node.js和基础三大模块_urfs
数据库连接池HikariCP
赞
踩
HikariCP
现在已经有很多公司在使用HikariCP了,HikariCP还成为了SpringBoot默认的连接池,伴随着SpringBoot和微服务,HikariCP 必将迎来广泛的普及。
下面带大家从源码角度分析一下HikariCP为什么能够被Spring Boot 青睐,文章目录如下:
 目录
目录
零、类图和流程图
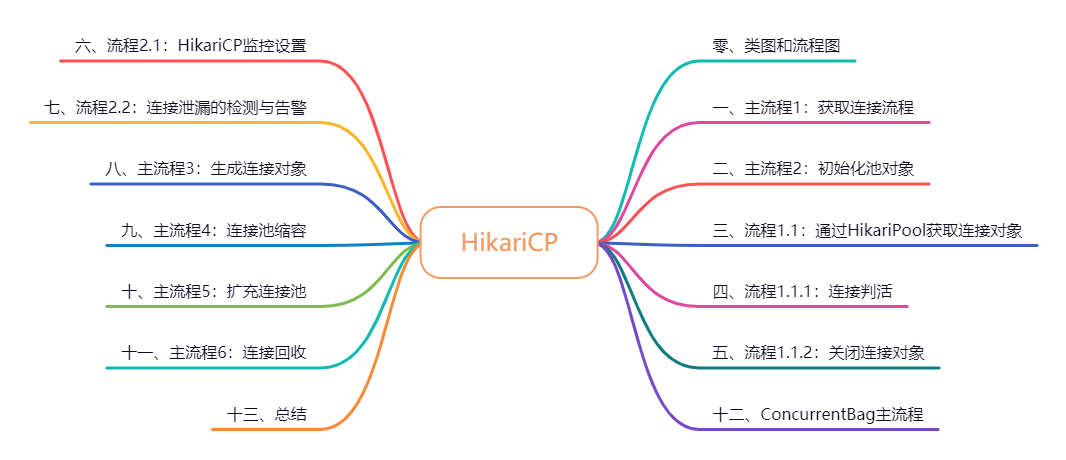
开始前先来了解下HikariCP获取一个连接时类间的交互流程,方便下面详细流程的阅读。
获取连接时的类间交互:
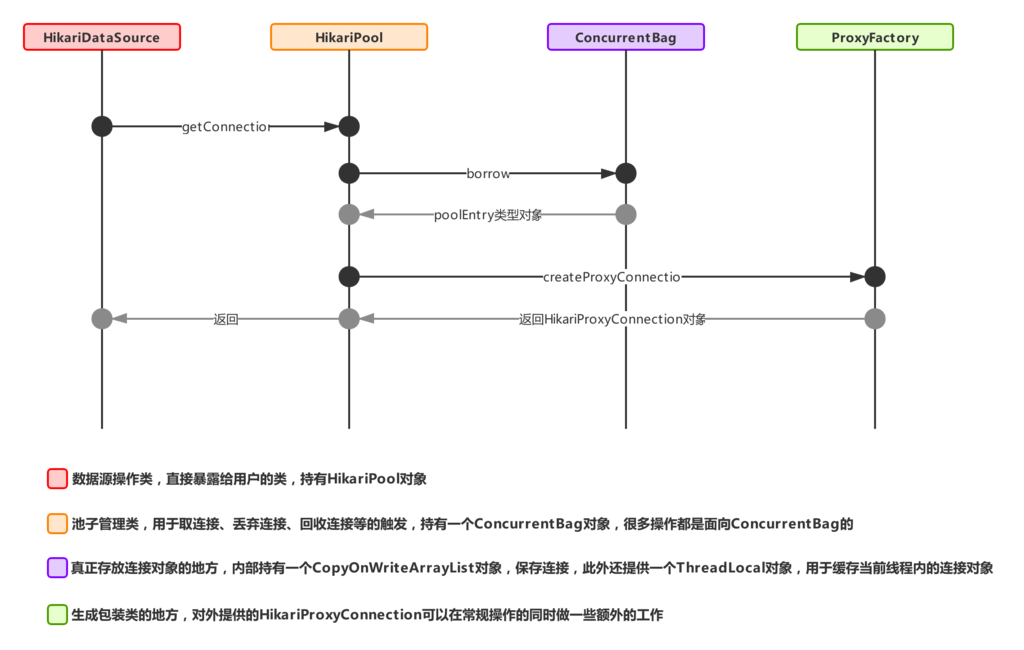 图1
图1
一、主流程1:获取连接流程
HikariCP获取连接时的入口是HikariDataSource里的getConnection方法,现在来看下该方法的具体流程:
 主流程1
主流程1
上述为HikariCP获取连接时的流程图,由图1可知,每个datasource对象里都会持有一个HikariPool对象,记为pool,初始化后的datasource对象pool是空的,所以第一次getConnection的时候会进行实例化pool属性(参考主流程1),初始化的时候需要将当前datasource里的config属性传过去,用于pool的初始化,最终标记sealed,然后根据pool对象调用getConnection方法(参考流程1.1),获取成功后返回连接对象。
二、主流程2:初始化池对象
 主流程2
主流程2
该流程用于初始化整个连接池,这个流程会给连接池内所有的属性做初始化的工作,其中比较主要的几个流程上图已经指出,简单概括一下:
- 利用
config初始化各种连接池属性,并且产生一个用于生产物理连接的数据源DriverDataSource - 初始化存放连接对象的核心类
connectionBag - 初始化一个延时任务线程池类型的对象
houseKeepingExecutorService,用于后续执行一些延时/定时类任务(比如连接泄漏检查延时任务,参考流程2.2以及主流程4,除此之外maxLifeTime后主动回收关闭连接也是交由该对象来执行的,这个过程可以参考主流程3) - 预热连接池,HikariCP会在该流程的
checkFailFast里初始化好一个连接对象放进池子内,当然触发该流程得保证initializationTimeout > 0时(默认值1),这个配置属性表示留给预热操作的时间(默认值1在预热失败时不会发生重试)。与Druid通过initialSize控制预热连接对象数不一样的是,HikariCP仅预热进池一个连接对象。 - 初始化一个线程池对象
addConnectionExecutor,用于后续扩充连接对象 - 初始化一个线程池对象
closeConnectionExecutor,用于关闭一些连接对象,怎么触发关闭任务呢?可以参考流程1.1.2
三、流程1.1:通过HikariPool获取连接对象
 流程1.1
流程1.1
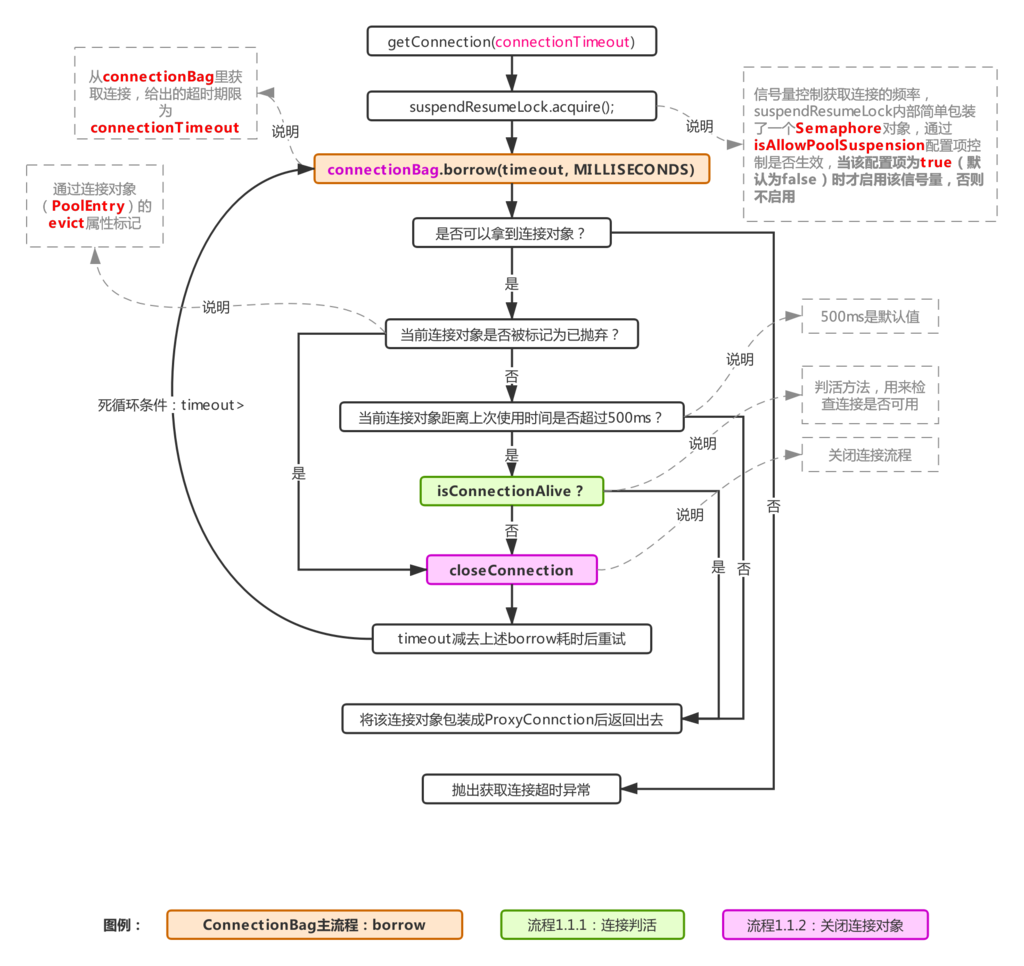
从最开始的结构图可知,每个HikariPool里都维护一个ConcurrentBag对象,用于存放连接对象,由上图可以看到,实际上HikariPool的getConnection就是从ConcurrentBag里获取连接的(调用其borrow方法获得,对应ConnectionBag主流程),在长连接检查这块,与之前说的Druid不同,这里的长连接判活检查在连接对象没有被标记为“已丢弃”时,只要距离上次使用超过500ms每次取出都会进行检查(500ms是默认值,可通过配置com.zaxxer.hikari.aliveBypassWindowMs的系统参数来控制),emmmm,也就是说HikariCP对长连接的活性检查很频繁,但是其并发性能依旧优于Druid,说明频繁的长连接检查并不是导致连接池性能高低的关键所在。
这个其实是由于HikariCP的无锁实现,在高并发时对CPU的负载没有其他连接池那么高而产生的并发性能差异,后面会说HikariCP的具体做法,即使是Druid,在获取连接、生成连接、归还连接时都进行了锁控制,因为通过上篇解析Druid的文章可以知道,Druid里的连接池资源是多线程共享的,不可避免的会有锁竞争,有锁竞争意味着线程状态的变化会很频繁,线程状态变化频繁意味着CPU上下文切换也将会很频繁。
回到流程1.1,如果拿到的连接为空,直接报错,不为空则进行相应的检查,如果检查通过,则包装成ConnectionProxy对象返回给业务方,不通过则调用closeConnection方法关闭连接(对应流程1.1.2,该流程会触发ConcurrentBag的remove方法丢弃该连接,然后把实际的驱动连接交给closeConnectionExecutor线程池,异步关闭驱动连接)。
四、流程1.1.1:连接判活
 流程1.1.1
流程1.1.1
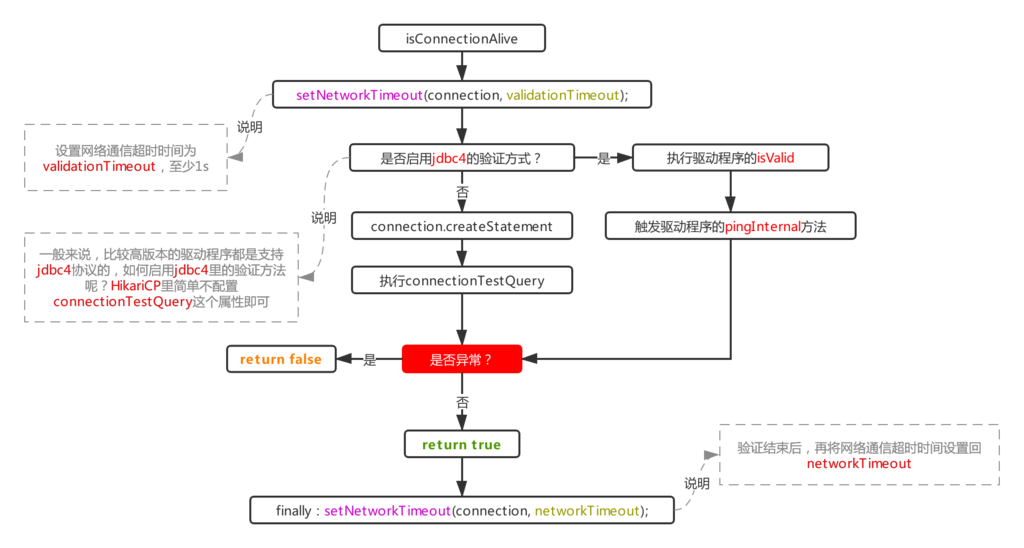
承接上面的流程1.1里的判活流程,来看下判活是如何做的,首先说验证方法(注意这里该方法接受的这个connection对象不是poolEntry,而是poolEntry持有的实际驱动的连接对象),在之前介绍Druid的时候就知道,Druid是根据驱动程序里是否存在ping方法来判断是否启用ping的方式判断连接是否存活,但是到了HikariCP则更加简单粗暴,仅根据是否配置了connectionTestQuery觉定是否启用ping:
this.isUseJdbc4Validation = config.getConnectionTestQuery() == null;
- 1
所以一般驱动如果不是特别低的版本,不建议配置该项,否则便会走createStatement+excute的方式,相比ping简单发送心跳数据,这种方式显然更低效。
此外,这里在刚进来还会通过驱动的连接对象重新给它设置一遍networkTimeout的值,使之变成validationTimeout,表示一次验证的超时时间,为啥这里要重新设置这个属性呢?因为在使用ping方法校验时,是没办法通过类似statement那样可以setQueryTimeout的,所以只能由网络通信的超时时间来控制,这个时间可以通过jdbc的连接参数socketTimeout来控制:
jdbc:mysql://127.0.0.1:3306/xxx?socketTimeout=250
- 1
这个值最终会被赋值给HikariCP的networkTimeout字段,这就是为什么最后那一步使用这个字段来还原驱动连接超时属性的原因;说到这里,最后那里为啥要再次还原呢?这就很容易理解了,因为验证结束了,连接对象还存活的情况下,它的networkTimeout的值这时仍然等于validationTimeout(不合预期),显然在拿出去用之前,需要恢复成本来的值,也就是HikariCP里的networkTimeout属性。
五、流程1.1.2:关闭连接对象
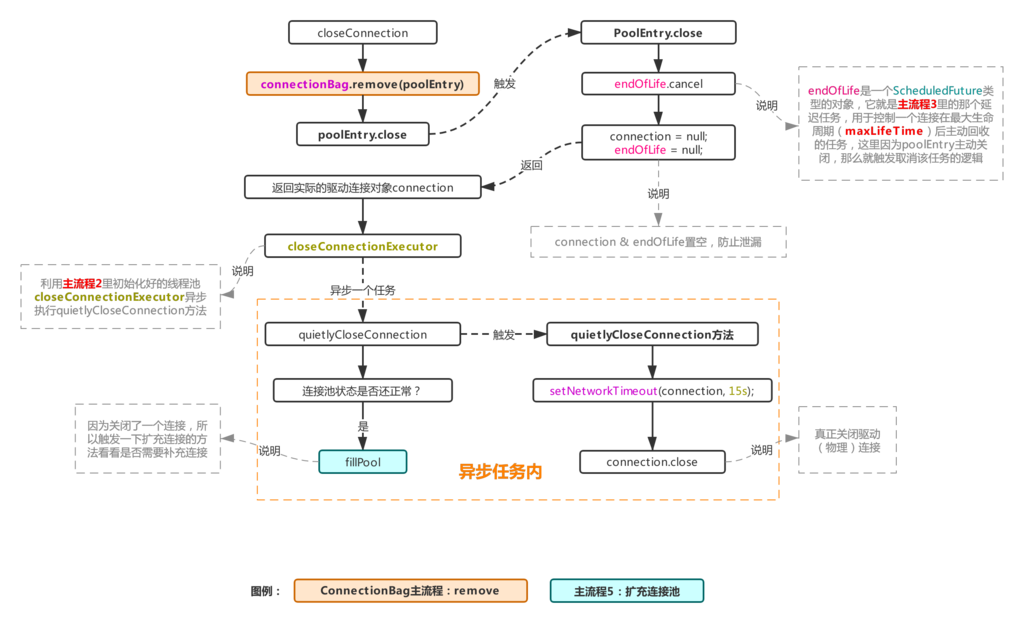 流程1.1.2
流程1.1.2
这个流程简单来说就是把流程1.1.1中验证不通过的死连接,主动关闭的一个流程,首先会把这个连接对象从ConnectionBag里移除,然后把实际的物理连接交给一个线程池去异步执行,这个线程池就是在主流程2里初始化池的时候初始化的线程池closeConnectionExecutor,然后异步任务内开始实际的关连接操作,因为主动关闭了一个连接相当于少了一个连接,所以还会触发一次扩充连接池(参考主流程5)操作。
六、流程2.1:HikariCP监控设置
不同于Druid那样监控指标那么多,HikariCP会把我们非常关心的几项指标暴露给我们,比如当前连接池内闲置连接数、总连接数、一个连接被用了多久归还、创建一个物理连接花费多久等,HikariCP的连接池的监控我们这一节专门详细的分解一下,首先找到HikariCP下面的metrics文件夹,这下面放置了一些规范实现的监控接口等,还有一些现成的实现(比如HikariCP自带对prometheus、micrometer、dropwizard的支持,不太了解后面两个,prometheus下文直接称为普罗米修斯):
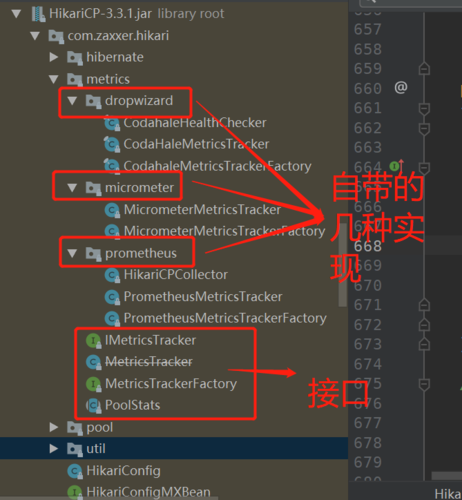 图2
图2
下面,来着重看下接口的定义:
//这个接口的实现主要负责收集一些动作的耗时 public interface IMetricsTracker extends AutoCloseable { //这个方法触发点在创建实际的物理连接时(主流程3),用于记录一个实际的物理连接创建所耗费的时间 default void recordConnectionCreatedMillis(long connectionCreatedMillis) {} //这个方法触发点在getConnection时(主流程1),用于记录获取一个连接时实际的耗时 default void recordConnectionAcquiredNanos(final long elapsedAcquiredNanos) {} //这个方法触发点在回收连接时(主流程6),用于记录一个连接从被获取到被回收时所消耗的时间 default void recordConnectionUsageMillis(final long elapsedBorrowedMillis) {} //这个方法触发点也在getConnection时(主流程1),用于记录获取连接超时的次数,每发生一次获取连接超时,就会触发一次该方法的调用 default void recordConnectionTimeout() {} @Override default void close() {} }

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
触发点都了解清楚后,再来看看MetricsTrackerFactory的接口定义:
//用于创建IMetricsTracker实例,并且按需记录PoolStats对象里的属性(这个对象里的属性就是类似连接池当前闲置连接数之类的线程池状态类指标)
public interface MetricsTrackerFactory
{
//返回一个IMetricsTracker对象,并且把PoolStats传了过去
IMetricsTracker create(String poolName, PoolStats poolStats);
}
- 1
- 2
- 3
- 4
- 5
- 6
上面的接口用法见注释,针对新出现的PoolStats类,我们来看看它做了什么:
public abstract class PoolStats { private final AtomicLong reloadAt; //触发下次刷新的时间(时间戳) private final long timeoutMs; //刷新下面的各项属性值的频率,默认1s,无法改变 // 总连接数 protected volatile int totalConnections; // 闲置连接数 protected volatile int idleConnections; // 活动连接数 protected volatile int activeConnections; // 由于无法获取到可用连接而阻塞的业务线程数 protected volatile int pendingThreads; // 最大连接数 protected volatile int maxConnections; // 最小连接数 protected volatile int minConnections; public PoolStats(final long timeoutMs) { this.timeoutMs = timeoutMs; this.reloadAt = new AtomicLong(); } //这里以获取最大连接数为例,其他的跟这个差不多 public int getMaxConnections() { if (shouldLoad()) { //是否应该刷新 update(); //刷新属性值,注意这个update的实现在HikariPool里,因为这些属性值的直接或间接来源都是HikariPool } return maxConnections; } protected abstract void update(); //实现在↑上面已经说了 private boolean shouldLoad() { //按照更新频率来决定是否刷新属性值 for (; ; ) { final long now = currentTime(); final long reloadTime = reloadAt.get(); if (reloadTime > now) { return false; } else if (reloadAt.compareAndSet(reloadTime, plusMillis(now, timeoutMs))) { return true; } } } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
实际上这里就是这些属性获取和触发刷新的地方,那么这个对象是在哪里被生成并且丢给MetricsTrackerFactory的create方法的呢?这就是本节所需要讲述的要点:主流程2里的设置监控器的流程,来看看那里发生了什么事吧:
//监控器设置方法(此方法在HikariPool中,metricsTracker属性就是HikariPool用来触发IMetricsTracker里方法调用的) public void setMetricsTrackerFactory(MetricsTrackerFactory metricsTrackerFactory) { if (metricsTrackerFactory != null) { //MetricsTrackerDelegate是包装类,是HikariPool的一个静态内部类,是实际持有IMetricsTracker对象的类,也是实际触发IMetricsTracker里方法调用的类 //这里首先会触发MetricsTrackerFactory类的create方法拿到IMetricsTracker对象,然后利用getPoolStats初始化PoolStat对象,然后也一并传给MetricsTrackerFactory this.metricsTracker = new MetricsTrackerDelegate(metricsTrackerFactory.create(config.getPoolName(), getPoolStats())); } else { //不启用监控,直接等于一个没有实现方法的空类 this.metricsTracker = new NopMetricsTrackerDelegate(); } } private PoolStats getPoolStats() { //初始化PoolStats对象,并且规定1s触发一次属性值刷新的update方法 return new PoolStats(SECONDS.toMillis(1)) { @Override protected void update() { //实现了PoolStat的update方法,刷新各个属性的值 this.pendingThreads = HikariPool.this.getThreadsAwaitingConnection(); this.idleConnections = HikariPool.this.getIdleConnections(); this.totalConnections = HikariPool.this.getTotalConnections(); this.activeConnections = HikariPool.this.getActiveConnections(); this.maxConnections = config.getMaximumPoolSize(); this.minConnections = config.getMinimumIdle(); } }; }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
到这里HikariCP的监控器就算是注册进去了,所以要想实现自己的监控器拿到上面的指标,要经过如下步骤:
- 新建一个类实现
IMetricsTracker接口,我们这里将该类记为IMetricsTrackerImpl - 新建一个类实现
MetricsTrackerFactory接口,我们这里将该类记为MetricsTrackerFactoryImpl,并且将上面的IMetricsTrackerImpl在其create方法内实例化 - 将
MetricsTrackerFactoryImpl实例化后调用HikariPool的setMetricsTrackerFactory方法注册到Hikari连接池。
上面没有提到PoolStats里的属性怎么监控,这里来说下,由于create方法是调用一次就没了,create方法只是接收了PoolStats对象的实例,如果不处理,那么随着create调用的结束,这个实例针对监控模块来说就失去持有了,所以这里如果想要拿到PoolStats里的属性,就需要开启一个守护线程,让其持有PoolStats对象实例,并且定时获取其内部属性值,然后push给监控系统,如果是普罗米修斯等使用pull方式获取监控数据的监控系统,可以效仿HikariCP原生普罗米修斯监控的实现,自定义一个Collector对象来接收PoolStats实例,这样普罗米修斯就可以定期拉取了,比如HikariCP根据普罗米修斯监控系统自己定义的MetricsTrackerFactory实现(对应图2里的PrometheusMetricsTrackerFactory类):
@Override
public IMetricsTracker create(String poolName, PoolStats poolStats) {
getCollector().add(poolName, poolStats); //将接收到的PoolStats对象直接交给Collector,这样普罗米修斯服务端每触发一次采集接口的调用,PoolStats都会跟着执行一遍内部属性获取流程
return new PrometheusMetricsTracker(poolName, this.collectorRegistry); //返回IMetricsTracker接口的实现类
}
//自定义的Collector
private HikariCPCollector getCollector() {
if (collector == null) {
//注册到普罗米修斯收集中心
collector = new HikariCPCollector().register(this.collectorRegistry);
}
return collector;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
通过上面的解释可以知道在HikariCP中如何自定义一个自己的监控器,以及相比Druid的监控,有什么区别。 工作中很多时候都是需要自定义的,我司虽然也是用的普罗米修斯监控,但是因为HikariCP原生的普罗米修斯收集器里面对监控指标的命名并不符合我司的规范,所以就自定义了一个,有类似问题的不妨也试一试。
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

