
- 1[WebSocket]之上层协议STOMP_stompclient.connect
- 2iphone/ipad 连接smb服务器,实现局域网内文件共享_ipad smb
- 3嵌入式软件开发工程师就业发展前景怎么样?
- 4openwrt 处理间歇性无法上网(DNS故障)问题_openwrt 间歇性断网
- 5vue3+element plus使用修改element的主题色问题_element-plus用了node-sass
- 6Epic版JustCause4(正当防卫4)0xc000007b错误解决方法_epic 0xc000007b
- 7变废为宝,用旧电脑自己DIY组建 NAS 服务器
- 8windows下内网穿透之frp使用_frp在2003系统上可以运行吗
- 9Centos7下搭建dhcp服务_centos7 yum dcphd
- 10PIDNet: A Real-time Semantic Segmentation Network Inspired by PID Controllers翻译
云服务器做深度学习推荐+autoDL云服务器进行深度学习教程_autodl 飞浆
赞
踩
目录
笔者用云服务做深度学习项目,只是偶尔才会用到它。所以我就想找一款按量收费性价比较高的云服务器,故笔者使用autodl云服务器,云服务器地址为:AutoDL-品质GPU租用平台-租GPU就上AutoDL 笔者经过多次筛选,显卡种类多,对于自掏腰包的学生来说,性价比是真不错。
主流云服务器
笔者最近需要跑深度学习模型训练,在网上看了诸多云服务信息,市场上现存在云服务器有:autoDL云、恒源云、阿里云、腾讯云、华为云、天翼云、矩池云、谷歌云、百度云(飞浆paddle)、硅云、MistGPU、微软云等云服务器。下面进行分别阐述:
autoDL云:价格比较亲民,笔者对比这么多家,性价比是真的高,对于学生党全部9.5折。它上传数据快,方便,支持vscode,pycharm等在线编译代码。传输方式有:公网网盘、autodl网盘、jupyterlab、filezilla和xshell软件支持。

恒源云:笔者选了很久后,主要是价格上比autoDL云贵几毛钱。其它方面都是很不错。
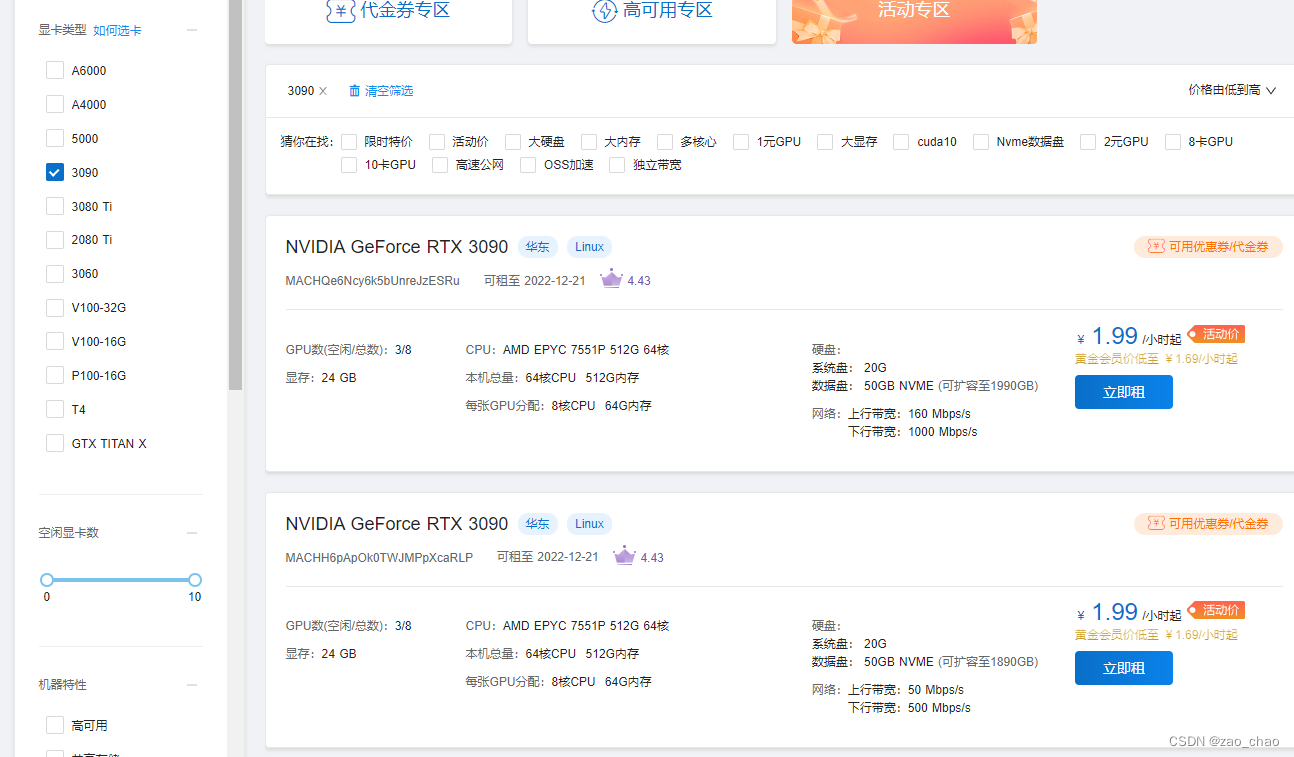
阿里云:市场比较大,国内外都有服务器,GPU架构并行运算能力较强。但是价格比较贵
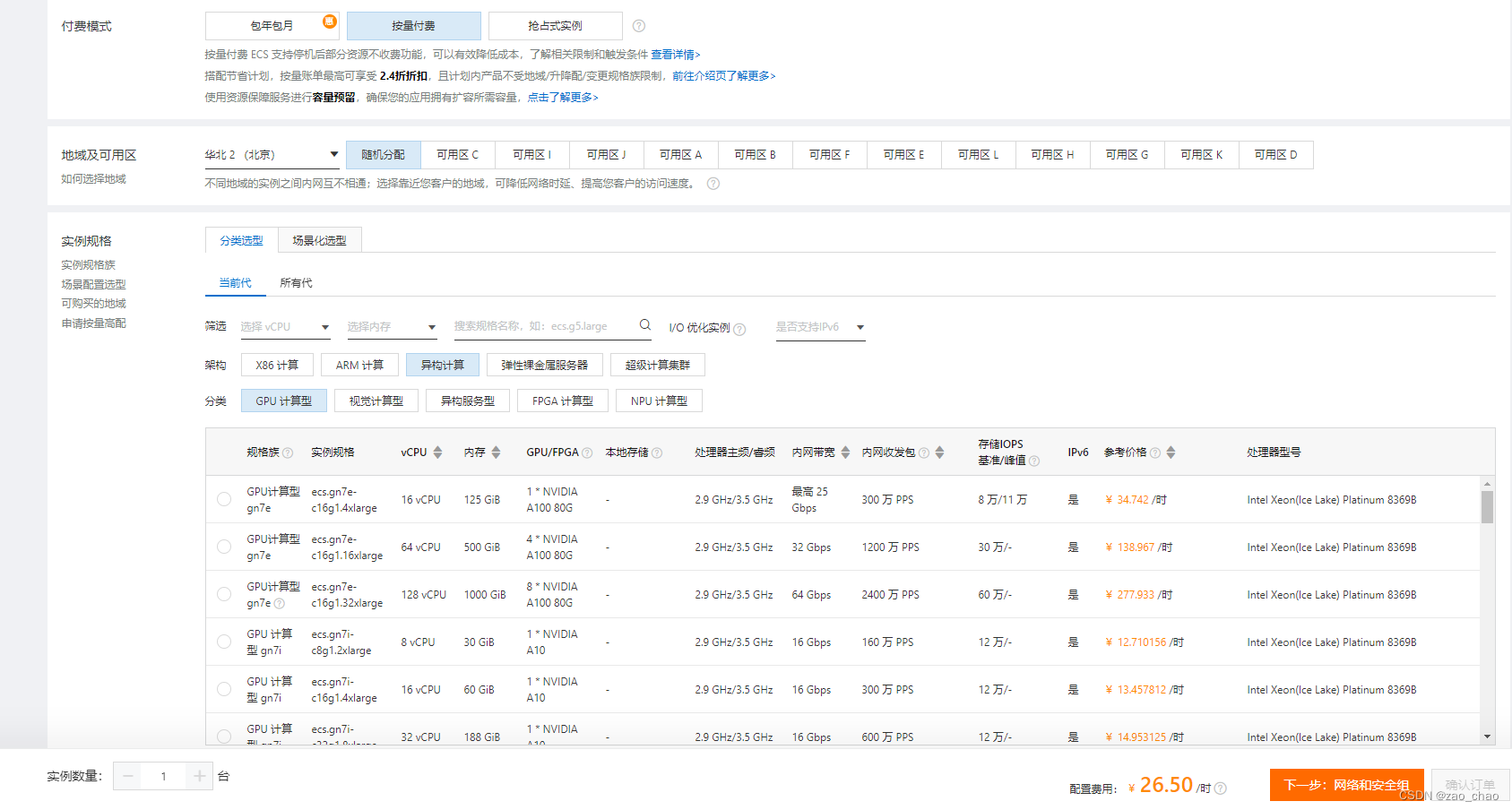
腾讯云:
市场占有率高, 他的计费方式是竞价计费,价格随时都是浮动的,价高者拥有该服务器的使用权。

华为云:笔者不知为啥,因为注册华为账号一直都不成功。所以未查看到其价格形式和其它信息,读者可以自行了解。
天翼云:价格比较贵

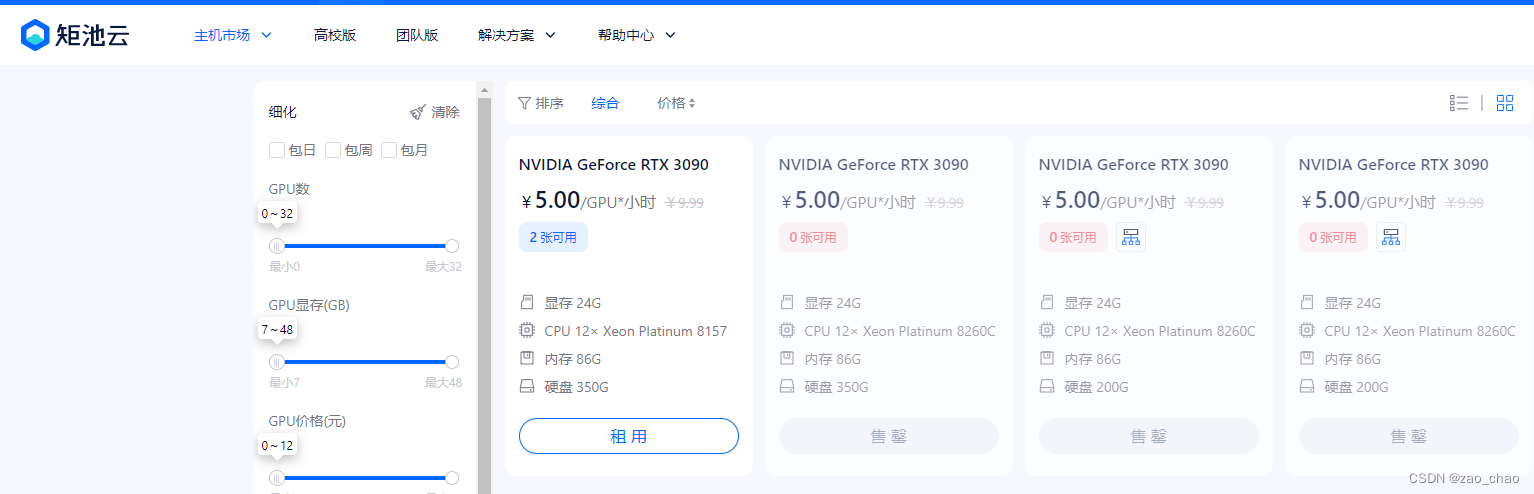
矩池云:矩池云因为和诸多高校合作,故价格也贵。
谷歌云和微软云:因为服务器都在国外,上传/下载数据太慢,中途断掉,又得重新开始,虽然也有免费使用时长,但断线就很恼火。
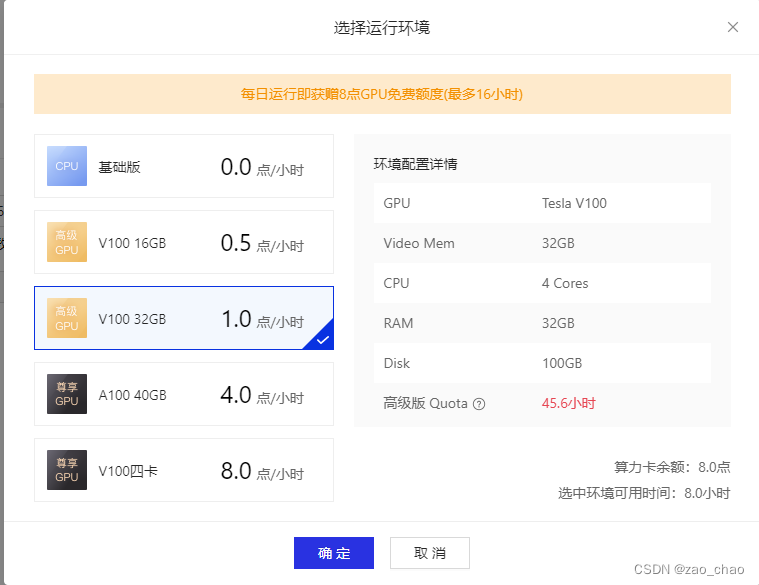
百度云(飞浆paddle):百度云每天可以赠送算力卡(每天免费领取8点算力卡),也有免费基础版本的,但它有其专门的框架(paddle框架)。笔者是使用不习惯。
autoDL云服务器进行深度学习教程
1、购买autoDL云服务器
云服务器地址为:AutoDL-品质GPU租用平台-租GPU就上AutoDL ,进去注册账号后,进入算力市场,选择区域,服务器离你所在距离越近,传输速率越高。先选择区域,在选择你所需要的显卡型号,在选择云服务器,你可以根据云服务器的不同规格来选择你所需的服务器,当然价格也是有所不同。
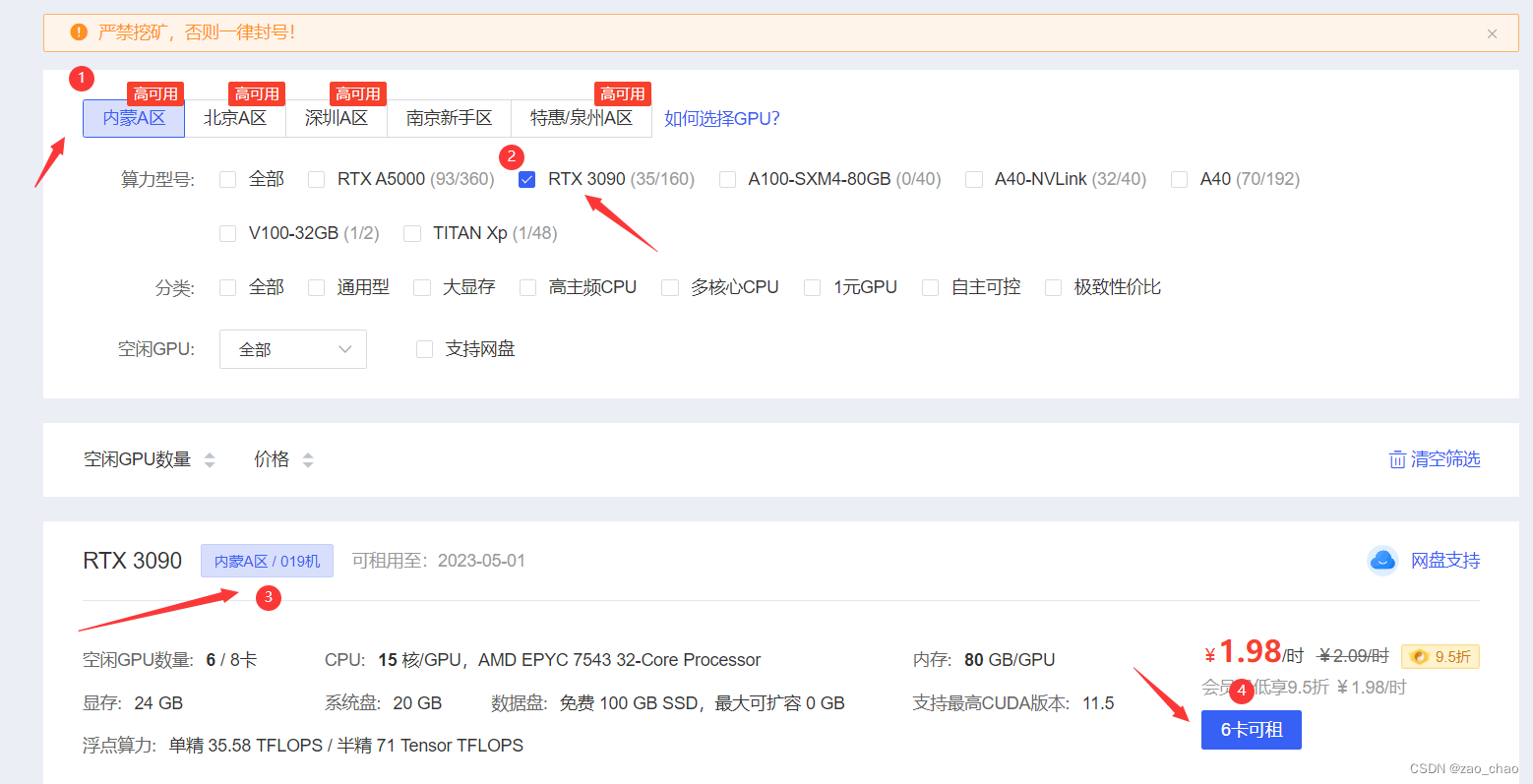
根据自己所需,选择其中GPU显卡数量,首次租用云服务器,选择平台镜像,服务器会自动安装pytorch所需要的环境配置。当你运行过自己的项目后,并保存为镜像后,你就可以用你自己的镜像。笔者第一次用的平台镜像为:pytorch1.11.0+python3.8+cuda11.3 版本,服务器运行系统均为Linux Ubuntu。而且该系统比较好的是他已经自带安装了miniaconda,很多常用的依赖库已经安装好了。

创建案例后,进入控制台,如图10所示。
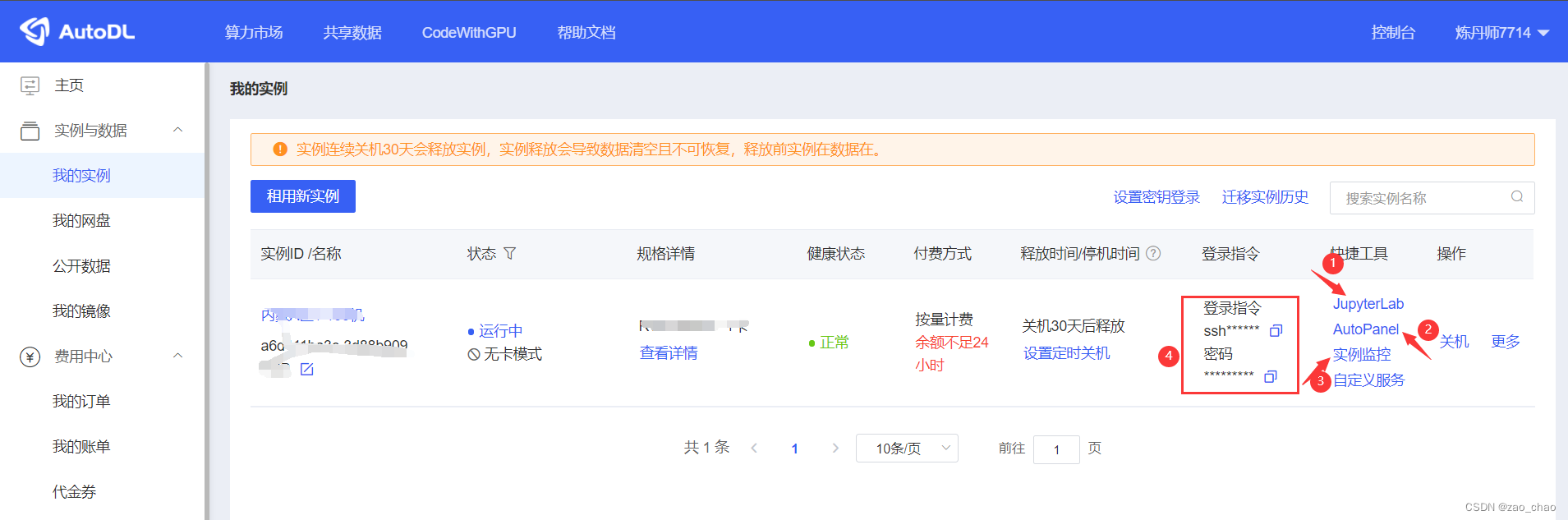
图10
2、向服务器上传项目数据
方式1:首先进入图10中1(JupyterLab)位置,在如下界面中点击上传数据。

- 公网网盘,直接使用阿里云盘、百度网盘上传下载数据,强烈推荐
- AutoDL网盘 上传数据,优点简单而且不用开实例,缺点是网页不支持上传文件夹
- JupyterLab上传,和网盘类似,优点简单,但是只支持文件不支持文件夹
- scp命令支持文件和文件夹上传下载,由于是命令行执行,上手难度稍高
- FileZilla软件支持文件和文件夹,拖拉拽即可上传下载,推荐使用
- XShell软件支持管理SSH连接,而且集成了xftp,支持拖拉拽上传下载文件夹/文件,推荐使用
3、解压服务器上的项目数据
方式1:
由于安装的zip、rar包等都只能解压或压缩某一种压缩包,这里提供一个小工具,支持解压格式:.tar, .zip, .rar, .7z,支持压缩/打包格式:.zip,.tar
- # 下载安装工具
- curl -L -o /usr/bin/arc http://autodl-public.ks3-cn-beijing.ksyun.com/tool/arc && chmod +x /usr/bin/arc
-
- # 压缩/打包
- arc compress xxx.zip path/to/directory
-
- # 解压
- arc decompress xxx.zip
- 或者解压到指定目录
- arc decompress xxx.zip path/to/directory
有个别zip的压缩包使用上边的命令以及unzip命令都不能解压时,先检查文件大小,如果文件大小和源文件一样,那么尝试下面的命令解压:
- apt-get update && apt-get install -y fastjar
- jar xvf xxx.zip
方式2:
命令:zip、unzip、tar
zip和unzip分别正对与zip的压缩包压缩和解压,tar是Linux另外一种更通用的压缩解压工具
- # zip和unzip。如果没有zip请使用apt-get update && apt-get install -y zip安装
- user@seeta:/tmp/$ zip -r dir.zip test_directory/ # 将test_directory文件夹压缩为dir.zip文件
- user@seeta:/tmp/$ unzip dir.zip # 将dir.zip文件解压
-
- # tar. 以下参数c代表压缩,x表示解压,z代表压缩/解压为gz格式的压缩包
- user@seeta:/tmp/$ tar czf dir.tar.gz test_directory/ # 将test_directory文件夹压缩为dir.tar.gz文件
- user@seeta:/tmp/$ tar xzf dir.tar.gz # 将dir.tar.gz文件解压
-
- # tar还可以用于压缩和解压其他格式的压缩文件,比如bz2
- user@seeta:/tmp/$ tar cjf dir.tar.bz2 test_directory/ # 将test_directory文件夹压缩为dir.tar.bz2文件
- user@seeta:/tmp/$ tar xjf dir.tar.bz2 # 将dir.tar.bz2文件解压
4、终端训练
方式一:在打开的JupyterLab页面中打开终端来执行(笔者推荐使用)。只要jupyterlab不出现重启(几乎不会),jupyterlab的终端就会一直运行,无论是本地主机断网还是关机。

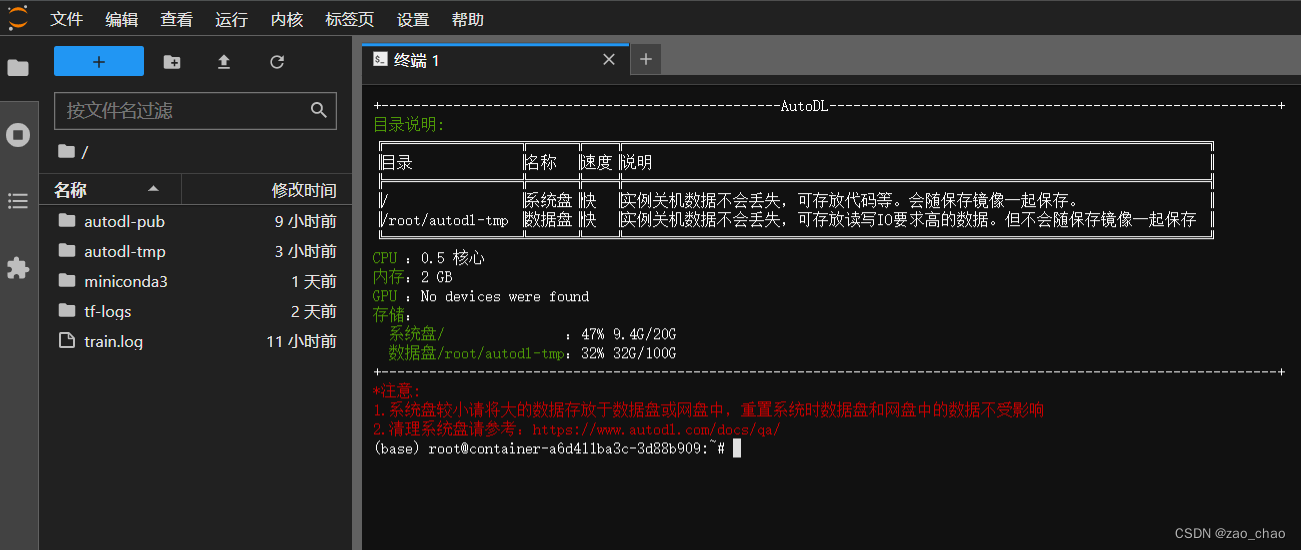
运行代码:python xxx.py或者执行某个文件夹下的代码文件:python+该执行文件的路径。
在使用JupyterLab长时间跑代码的过程中强烈建议对日志重定向,防止断网后中间的日志没有了。使用方法:
- # 日志重定向到train.log文件。即在你的命令后加上:> train.log 2>&1
- python xxx.py > train.log 2>&1
- # 实时查看日志
- tail -f train.log
方式二:如需使用其他IDE远程开发,请参考VSCode(推荐)和PyCharm (推荐调试代码使用)
4.1 远程IDE
当远程IDE进行代码运行时,需要采取守护进程,好保护程序在运行时,防止断网导致程序运行中断。 守护进程方法 。
4.2 代码执行结束自动关机
不确定自己的代码需要执行多久结束,希望执行完成后立马关机。这类场景可以通过shutdown命令来解决。
- # 假设您的程序原执行命令为
- python train.py
-
- # 那么可以在您的程序后跟上shutdown命令
- python train.py; shutdown # 用;拼接意味着前边的指令不管执行成功与否,都会执行shutdown命令
- python train.py && shutdown # 用&&拼接表示前边的命令执行成功后才会执行shutdown。请根据自己的需要选择
或者在您的Python代码中执行shutdown命令,例如:
- import os
-
- if __name__ == "__main__":
- # xxxxxx
- os.system("shutdown")
4.3 查看GPU信息
命令:nvidia-smi
- user@seeta:/tmp/test_directory$ nvidia-smi
- Mon Nov 8 11:55:26 2021
- +-----------------------------------------------------------------------------+
- | NVIDIA-SMI 440.82 Driver Version: 440.82 CUDA Version: 10.2 |
- |-------------------------------+----------------------+----------------------+
- | GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
- | Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
- |===============================+======================+======================|
- | 0 TITAN X (Pascal) Off | 00000000:01:00.0 On | N/A |
- | 31% 57C P0 66W / 250W | 408MiB / 12194MiB | 2% Default |
- +-------------------------------+----------------------+----------------------+
- | 1 TITAN X (Pascal) Off | 00000000:04:00.0 Off | N/A |
- | 93% 27C P8 11W / 250W | 2MiB / 12196MiB | 0% Default |
- +-------------------------------+----------------------+----------------------+
-
- +-----------------------------------------------------------------------------+
- | Processes: GPU Memory |
- | GPU PID Type Process name Usage |
- |=============================================================================|
- | 0 1450 G /usr/lib/xorg/Xorg 32MiB |
- | 0 2804 G /usr/lib/xorg/Xorg 351MiB |
- +-----------------------------------------------------------------------------+
- Memory-Usage # 内存的使用情况
- 408MiB / 12194MiB # 前者408MiB代表已使用的显存,后者12194MiB代表总现存
- GPU-Util # GPU的使用率
- 2% # 使用率百分比
如果需要不停的输出GPU占用信息,那么使用nvidia-smi -l 1每隔1秒输出一次,或使用watch -n 1 nvidia-smi也是同样的效果
4.4 查看进程的CPU和内存占用
方法1:命令:top
- Tasks: 11 total, 2 running, 9 sleeping, 0 stopped, 0 zombie
- %Cpu(s): 2.3 us, 1.3 sy, 0.0 ni, 96.3 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
- KiB Mem : 52801571+total, 45453059+free, 7807904 used, 65677196 buff/cache
- KiB Swap: 2074620 total, 2074620 free, 0 used. 51678192+avail Mem
- PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
- 2316 root 20 0 21.846g 1.796g 244664 R 101.4 0.4 0:05.56 python
- 58 root 20 0 372352 84804 15540 S 1.4 0.0 0:05.40 jupyter-lab
- 59 root 20 0 713796 11288 7668 S 1.4 0.0 0:01.31 proxy
- 2395 root 20 0 45920 3940 3444 R 1.4 0.0 0:00.01 top
- 1 root 20 0 25368 3724 3404 S 0.0 0.0 0:00.07 bash
- 48 root 20 0 55060 24328 9728 S 0.0 0.0 0:00.33 supervisord
- 60 root 20 0 72304 5872 5140 S 0.0 0.0 0:00.01 sshd
- 61 root 20 0 9756148 315032 156124 S 0.0 0.1 0:04.16 tensorboard
- 146 root 20 0 1582996 6964 5296 S 0.0 0.0 0:00.04 server
- 338 root 20 0 25824 4312 3800 S 0.0 0.0 0:00.18 bash
- 481 root 20 0 25824 4544 4040 S 0.0 0.0 0:00.18 bash
如果有高负载(CPU使用率高)的情况,那么一般进程都会排在最上边,根据进程名称可以进行确认。那么这个进程占用的CPU可以通过%CPU字段读取出来,内存更复杂一些,但是一般看RES字段就够了。比如上边第一个Python进程CPU的占用率是101.4%,内存使用大小是1.796g(Tips:如果内存显示的单位和上述不同,按e键切换)
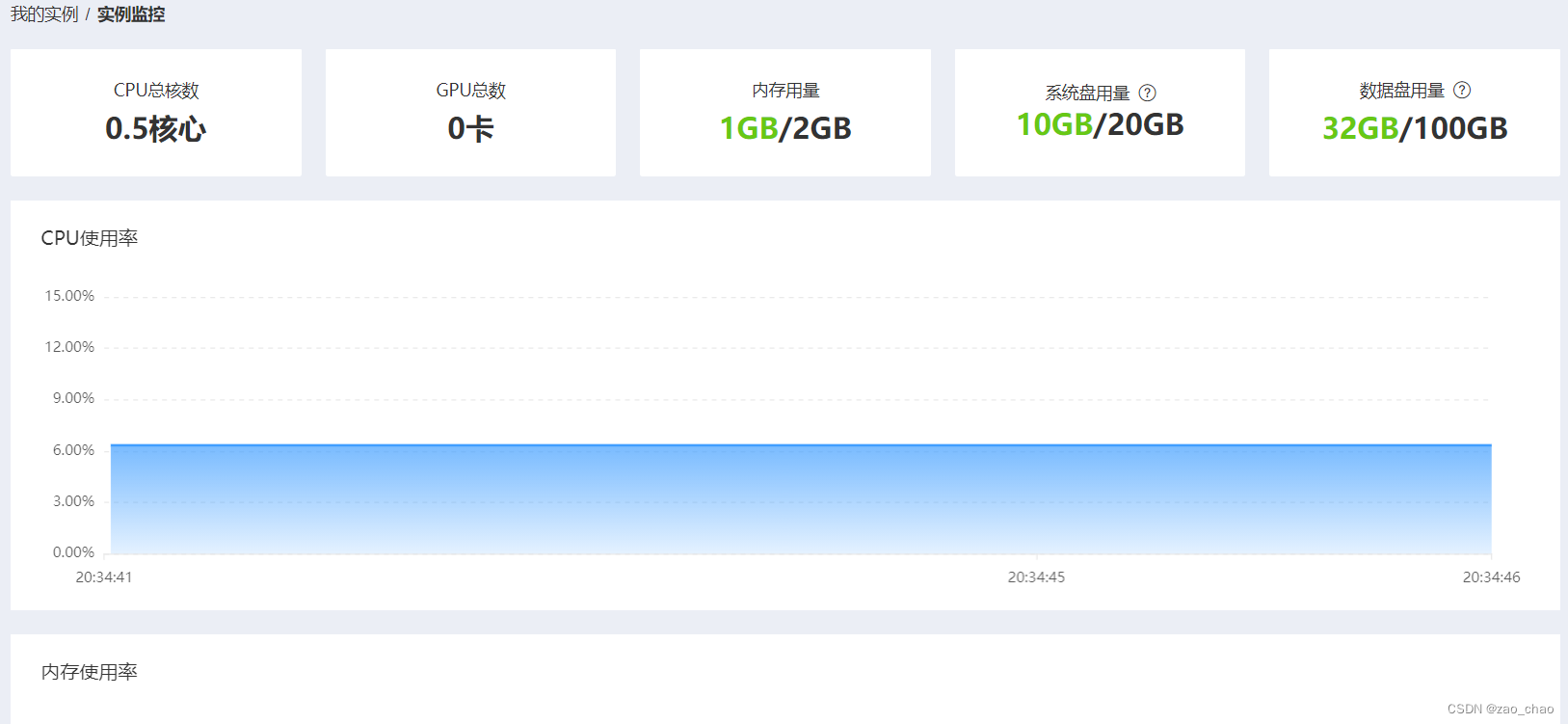
方法2: 使用平台提供的实例监控功能查看更为简便
4.5 提升GPU性能
如果发现训练速度明显很慢时,先排除是实例本身的问题,尝试调整网络结构或batch size把GPU压满,如测试脚本能正常压满GPU,请按照以下方式进行排查和调优。
检查NumPy
该项中招率非常高,所以优先检查。
NumPy会使用OpenBlas或MKL做计算加速。Intel的CPU支持MKL,AMD CPU仅支持OpenBlas。如果使用Intel的CPU,MKL会比OpenBlas有几倍的性能提升(部分矩阵计算),对最终的性能影响非常大。一般来说AMD CPU使用OpenBlas会比Intel的CPU使用OpenBlas更快,因此不用过份担心AMD CPU使用OpenBlas的性能差。
如果您在使用Intel CPU,先验证自己使用的NumPy是MKL还是OpenBlas版本。
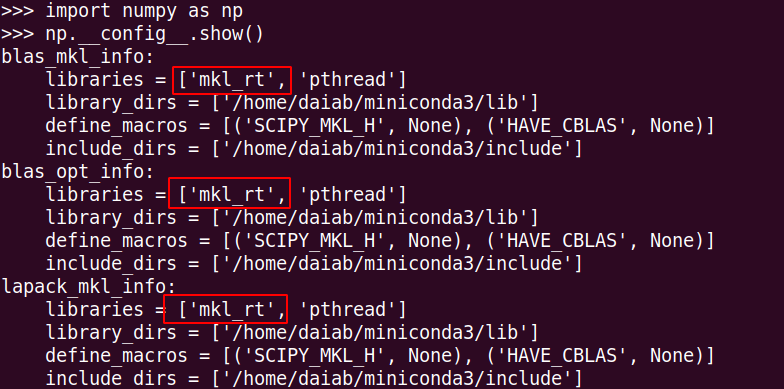
有以上mkl字样代表是MKL的版本。
在使用清华等国内的Conda源时,安装NumPy时默认会使用OpenBlas的加速方案,您使用conda install numpy安装时会发现如下OpenBlas相关的包:

所以为了安装MKL的NumPy,解决方法如下:
- # 第一步:卸载当前的NumPy
- pip uninstall numpy (如果是conda安装的, conda uninstal numpy)
- # 第二步:删除国内的Conda源
- echo "" > /root/.condarc
- # 第三步:重新安装NumPy
- conda install numpy
如果以上步骤正确,那么在install numpy时将会看到:

重装NumPy以后再次执行您的程序,查看是否性能有提升。如果不是NumPy的原因,请继续看下文:瓶颈分析
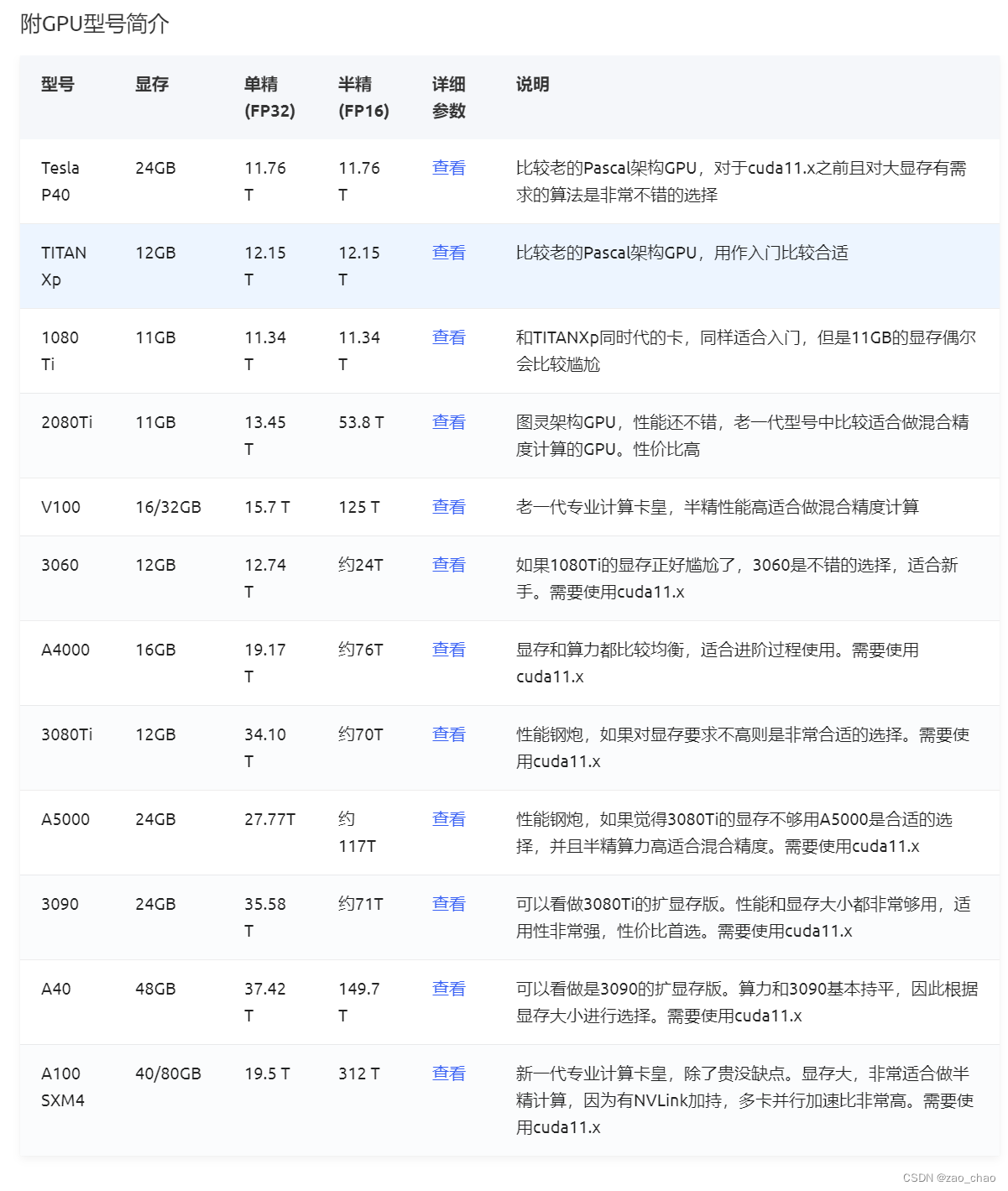
5、GPU选型
可以参考GPU选型 模型。
- 一、在pom.xml文件中添加Jedis的依赖
[详细] 赞
踩

