
- 1记一次google cloud platform云服务器sshd服务挂掉如何恢复_hashcloud怎么挂了
- 2python毕业设计作品基于django框架 图片分享平台毕设成品(6)开题答辩PPT_图片分享平台ppt
- 3操作系统——虚拟存储器(页面置换算法)_虚拟存储管理最佳置换算法
- 4Python-matplotlib画图(学习笔记)_import matplotlib.pyplot as pltimport numpy as npd
- 5Scapy的基本操作_scapy使用教程
- 6腾讯云服务器部署幻兽帕鲁联机服务器详细教程_腾讯服务器怎么登录帕鲁
- 7真实机下 ubuntu 18.04 安装anaconda+cuDNN+pytorch以及其版本选择(亲测非常实用)_anaconda哪个版本适合ubuntu18.04
- 8ZYNQ7000 uboot实现两级引导及加载FPGA程序_zynq下uboot
- 9使用Node.js和Web3.js实现链接MetaMask钱包并批量创建钱包并且批量发送代币_如何批量注册web3钱包
- 10夜莺(Flashcat)V6监控(三):categraf(All-in-on)采集器详解和告警自愈功能详解
sql server 全文检索 使用_sqlserver全文检索
赞
踩
目前项目中的日志查询 功能 由于长年累月的写入,目前已经达到千万级,对日志进行like 查询,速度可想而知。
此处只讨论 在数据库的优化。
当时 想到两个方案,一个是分区,一个 是全文检索。
分区的话,如果跨区,速度也会很慢,并且对区粒度的划分也得考虑,并且既然使用 like ‘%XX%’,必然不会走索引。
所以 选择 sqlserver 的full-text search 功能,该功能类似一个轻量级搜索引擎。
实现步骤:
1. 首先安装sqlserver时,必须选择安装FULL-Text search功能
2. 创建全文目录,如图,右键 创建即可,
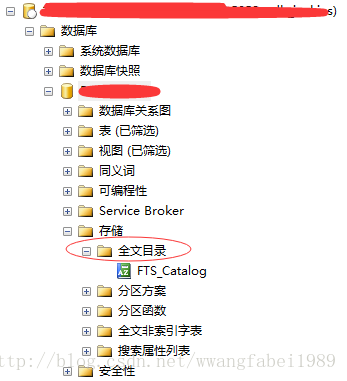
3. 在对应的表或者视图上 定义全文索引:注意 表或者视图 必须存在唯一索引,且视图不能包含union,且每个表或者视图,只能有一个全文索引,步骤:选中 表或者视图 --右键--定义全文索引--下一步,直到 选择索引 界面,如果存在全文索引,则系统默认选中,否则,会提示 无有效索引。
4. 选择索引列 ,第3步ok后,点击 下一步 ,选择需要建立全文检索的列,并选择 断字符语言(就类似切词,搜索引擎嘛)
5. 第4步ok后,下面就是 设置 索引填充规则了,上面都有说明,自己 实际 操作 看一下就行了,然后 下一步,直到 定义填充计划 这个页面,这个干什么的呢。 就是 说 我可以 定义一个job定时进行填充以及填充方式(不能每次都完全填充吧,可以是 增量填充或者基于更改的填充,),next.大功告成。
6 修改 查询 sql : cl like '%xxx%' 改为 contains(cl,'xxx')即可,也可使用 freetext. 剩余 的自己 google吧
知乎: https://zhuanlan.zhihu.com/albertwang
微信公众号:AI-Research-Studio

下面是赞赏码



