
- 1vue3 集成 Element-Plus之全局导入/按需导入_unplugin-element-plus
- 218. 四数之和 - 力扣(LeetCode)
- 3Python 3.11 终于发布了,性能大提升!
- 4matplotlib高级教程之形状与路径——patches和path_matplotlib.patches
- 5本地运行LlaMA 2的简易指南_llama2本地运行
- 6基础——SPI与QSPI的异同,QSPI的具体协议是什么,QSPI有什么用_qspi和spi接口的区别
- 73D建模与处理软件简介
- 8Vue三种3D动态词云实现
- 9Linux搭建Hyperledger Fabric区块链框架 - Hyperledger Fabric模型概念_hyperledger fabric数据上链
- 10初识 Nodejs (附带案例)_nodejs 实例
Ten years of pedestrian Detection-论文整理_ethz和tud
赞
踩
最近正在研究行人检测,学习了一篇2014年发表在ECCV上的一篇综述性的文章,是对行人检测过去十年的一个回顾,从dataset,main approaches的角度分析了近10年的40多篇论文提出的方法,发现有三种方法(DPM变体,Deep networks,Decision forests)都取得了相似的最好结果,并总结了feature,additional data以及context information等对于detection quality的影响。
1、Introduction
行人检测主要的方法有:Viola&Jones variants,HOG+SVM rigid templates, deformable part detectors (DPM), and convolutional neural networks(ConvNets) 。
2、Datasets
主要的datasets有6个:INRIA, ETH, TUD-Brussels, Daimler(Daimler stereo), Caltech-USA, KITTI。
2.1 INRIA数据库
http://pascal.inrialpes.fr/data/human/
介绍:该数据库是“HOG+SVM”的作者Dalal创建的,该数据库是目前使用最多的静态行人检测数据库,提供原始图片及相应的标注文件。训练集有正样本614张(包含2416个行人),负样本1218张;测试集有正样本288张(包含1126个行人),负样本453张。图片中人体大部分为站立姿势且高度大于100个象素,部分标注可能不正确。图片主要来源于GRAZ-01、个人照片及google,因此图片的清晰度较高。在XP操作系统下部分训练或者测试图片无法看清楚,但可用OpenCV正常读取和显示。
更新:2005
2.2 ETHZ行人数据库
Robust Multi-Person Tracking from Mobile Platforms
https://data.vision.ee.ethz.ch/cvl/aess/dataset/
Ess等构建了基于双目视觉的行人数据库用于多人的行人检测与跟踪研究。该数据库采用一对车载的AVT Marlins F033C摄像头进行拍摄,分辨率为640×480,帧率13-14fps,给出标定信息和行人标注信息,深度信息采用置信度传播方法获取。
更新:2010
2.3 TUD行人数据库
介绍:TUD行人数据库为评估运动信息在行人检测中的作用,提供图像对以便计算光流信息。训练集的正样本为1092对图像(图片大小为720×576,包含1776个行人);负样本为192对非行人图像(手持摄像机85对,车载摄像机107对);另外还提供26对车载摄像机拍摄的图像(包含183个行人)作为附加训练集。测试集有508对图像(图像对的时间间隔为1秒,分辨率为640×480),共有1326个行人。Andriluka等也构建了一个数据库用于验证他们提出的检测与跟踪相结合的行人检测技术。该数据集的训练集提供了行人的矩形框信息、分割掩膜及其各部位(脚、小腿、大腿、躯干和头部)的大小和位置信息。测试集为250张图片(包含311个完全可见的行人)用于测试检测器的性能,2个视频序列(TUD-Campus和TUD-Crossing)用于评估跟踪器的性能。
更新:2010
2.4 Daimler行人数据库
http://www.gavrila.net/Datasets/Daimler_Pedestrian_Benchmark_D/daimler_pedestrian_benchmark_d.html
该数据库采用车载摄像机获取,分为检测和分类两个数据集。检测数据集的训练样本集有正样本大小为18×36和48×96的图片各15560(3915×4)张,行人的最小高度为72个象素;负样本6744张(大小为640×480或360×288)。测试集为一段27分钟左右的视频(分辨率为640×480),共21790张图片,包含56492个行人。分类数据库有三个训练集和两个测试集,每个数据集有4800张行人图片,5000张非行人图片,大小均为18×36,另外还有3个辅助的非行人图片集,各1200张图片。
更新:2009?
2.5 Caltech Pedestrian Detection
http://www.vision.caltech.edu/Image_Datasets/CaltechPedestrians/
该数据库是目前规模较大的行人数据库,采用车载摄像头拍摄,约10个小时左右,视频的分辨率为640×480,30帧/秒。标注了约250,000帧(约137分钟),350000个矩形框,2300个行人,另外还对矩形框之间的时间对应关系及其遮挡的情况进行标注。数据集分为set00~set10,其中set00~set05为训练集,set06~set10为测试集(标注信息尚未公开)。性能评估方法有以下三种:(1)用外部数据进行训练,在set06~set10进行测试;(2)6-fold交叉验证,选择其中的5个做训练,另外一个做测试,调整参数,最后给出训练集上的性能;(3)用set00~set05训练,set06~set10做测试。由于测试集的标注信息没有公开,需要提交给Pitor Dollar。结果提交方法为每30帧做一个测试,将结果保存在txt文档中(文件的命名方式为I00029.txt I00059.txt ……),每个txt文件中的每行表示检测到一个行人,格式为“[left, top,width, height, score]”。如果没有检测到任何行人,则txt文档为空。该数据库还提供了相应的Matlab工具包,包括视频标注信息的读取、画ROC(Receiver Operatingcharacteristic Curve)曲线图和非极大值抑制等工具。
更新:2014
2.6 KITTI Vision Benchmark
http://www.cvlibs.net/datasets/kitti/index.php
KITTI是德国卡尔斯鲁厄理工学院和芝加哥丰田技术研究所联合创办的一个算法评测平台,旨在评测对象(机动车、非机动车、行人等)检测、目标跟踪等计算机视觉技术在车载环境下的性能,为机动车辅助驾驶应用做技术评估与技术储备。
2.7 小结
http://www.cvpapers.com/datasets.html
绝大多数的数据集都可以在上面网址中找到。
INRIA最旧图像也最少,不过好处是它拥有比较丰富的背景环境(如城市,沙滩,山地等),所以被使用的比较多。
ETH和TUD-Brussels是中等大小的视频数据集,Daimler缺乏彩色信息,Daimler stereo, ETH, and KITTI 提供立体信息。除了INRIA之外的数据集都是从视频中获取的,因此可以使用光流作为additional cue。
现在用的最多的数据集是Caltech-USA和KITTI,二者都是比较大且具有挑战性的。Caltech-USA有大量的方法使用因而比较起来比较方便,而KITTI的数据集更加丰富一些但是用的。这篇文章主要是以Caltech数据集作为标准,以INRIA和KITTI作为辅助。
3 Main approaches to improve pedestrian detection
首先介绍了近十年的主要发展:
2003, VJ detector.
2005, HOG detector.
2008, DPM.
2009, Caltech dataset, 评价方法FPPW->FPPI.
然后比较了40种左右方法的missing rate,给出了图表。
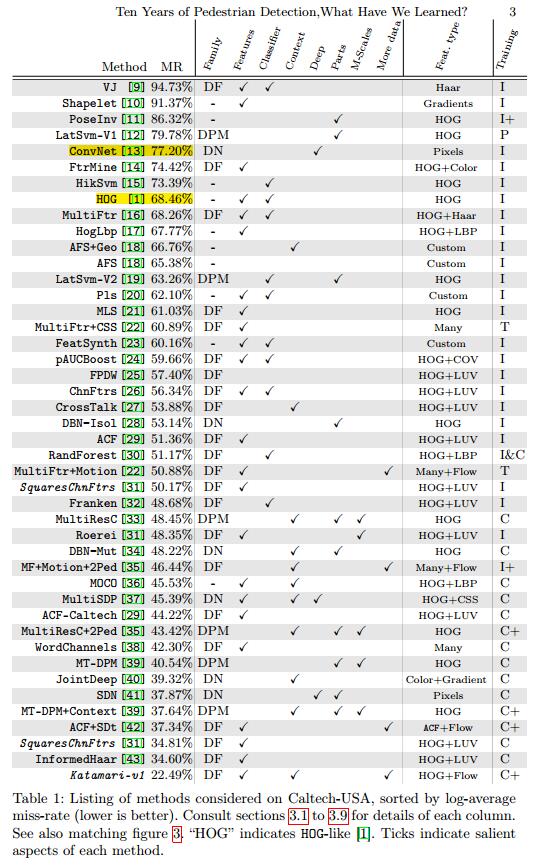
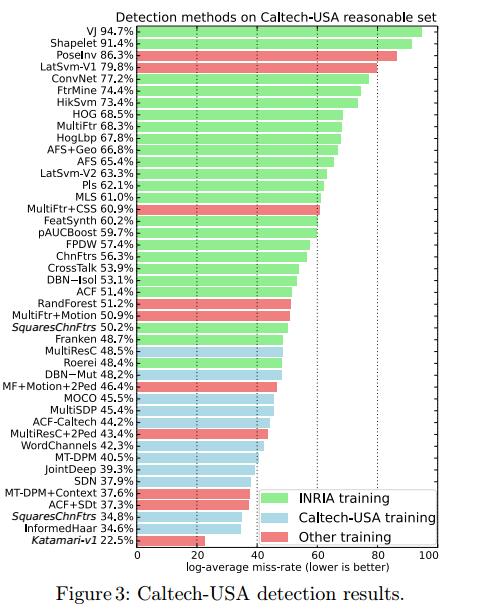
3.1 Training data
很显然,上图3显示了训练数据的大小比较明显的影响了结果的好坏。红色部分使用的训练集也是由Caltech数据集扩展而来。
3.2 Solution families
表1的40多种方法,大体可以分为3类:DPM变体,DN和DF。这三种方法都大体达到了state of art 。
3.3 Better classifiers
HOG+SVM 和 HikSvm 这些古老的方法,在当时的评价方法(FPPW)下,表现很好,但是却在FPPI下性能比较差。MultiFtrs 方法说明Adaboost以及线性SVM在给定足够多feature的条件下是可以达到同样的检测效果的。
并没有经验性的证据表明非线性核比线性核的性能更好。也没有证据表明某种分类器是最适合做行人检测的。
3.4 Additional data
使用额外的数据可以取得有效的提高,但是像立体和光流等线索都没有被完全利用起来。现在,基于单眼的方法已经达到了有额外信息方法的水平了。
3.5 Exploiting Context
环境信息也可以给行人检测带来提升,尽管不如额外数据和深度结构那样明显。
3.6 Deformable Parts
DPM detector就是为了做pedestrian detection而被提出来的。这种方法及其变体都很流行,尽管检测结果都很不错,但是却并不突出。越来越多的仅仅使用单个部件的方法都超越了DPM,这样就让我们产生了疑问:究竟有没有必要使用多个部件,即使是在有遮挡的情况下?这个问题目前也是没有明确答案的。
3.7 Multi-scale models
多尺度(多分辨率)的模型提供了一个对于已有检测子的更简洁和一般化的延伸。尽管有所提升,但对于最终的结果提升相当小。
3.8 Deep Architecture
随着数据量的增加和计算能力的增强,在计算机视觉领域(包括行人检测方面)使用深度网络(尤其是CNN)变得流行。
ConvNet结构混合了监督的和无监督的训练来搭建卷积神经网络,在INRIA,ETH,TUD-Brussels上得到了一般的结果,但在Caltech集上却失败了。这是从像素层面直接获取特征的方法。
而另一些结构(DBN, JointDeep, SDN)将part model和遮挡结合起来 都放进了深度结构,但它并不是从原始像素点之中去发现特征,而是从使用了边缘和色彩特征,或者将网络权重初始化时设置对边缘敏感的滤波器。值得注意的是,目前还没有人事先在ImageNet上预训练过。
虽然没有证据显示神经网络适合进行行人检测,但是很多性能良好的模型都使用了这种结构,不过其性能也只是和DPM和DF差不多,优势并不明显。
3.9 Better features
在改进行人检测的工作中,做的最多的就是增加或者多样化输入图像的特征。通过更多的和更高维度的特征,分类的任务似乎是变简单了,结果也有了改进。很多种类的特征已经被发现:边缘信息,颜色信息,纹理信息,局部形状信息,协方差特征,还有其他等等。越来越多的特征已被证明可以系统性的改善性能。
很多decision forest 方法采用10个feature channel,有些则采用了多达上百个feature channel。尽管增加channel可以提升性能,但目前表现最好的方法都是采取10个channel的:6个梯度方向,1个梯度幅值,3个颜色通道,叫做 HOG+LUV.
过去十年,特征的提升是检测效果提升的动力,显然,接下来的日子里,提升特征效果将依然是主流。这些提升都是在大量的实验和错误下累积起来的。接下来的研究将集中在为什么这些特征这么好以及如何设计更好的特征上。
4 Experiments
基于上面的分析,可以得出检测效果的提升主要集中在3个方面:better features,additional data 和context information。所以我们做实验来研究他们之间的互补性。
在3.2 中给出的3中主要方法里,我们选择了 Integral Channels Features 框架(DF方法)来做实验,因为这种方法表现突出且训练较快。
4.1 Reviewing the effect of features
所有方法都是在INRIA上训练,在Caltech上测试。如图5所示
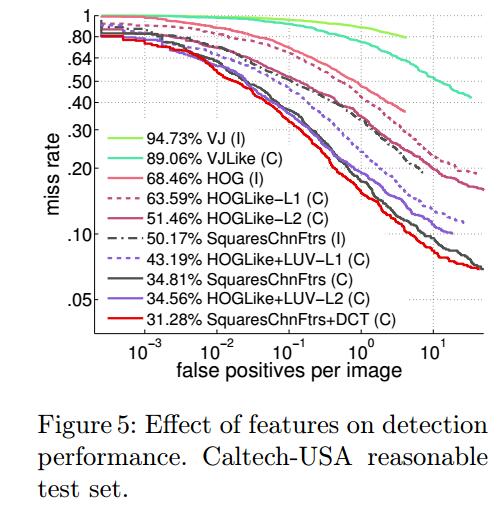
第一批实验都是复现那些具有里程碑式的方法,如 VJ , HOG+linear SVM , and ChnFtrs 。
从VJ以来,性能的提升多半可以归功于采用了更好的特征,梯度方向和颜色信息等。即使是在已有特征基础上加入的一点点微调也能产生显著的提升(如SquaresChnFtrs 加入DCT变换)。
4.2 Complementarity of approaches
接下来,作者又做了大量实验来研究better features(HOG+LUV+DCT), additional data (via optical flow), and context (via person-to-person interactions)之间的互补性。
在上文SquaresChnFtrs+DCT 的基础上,作者用和 ACF+SDt 中同样的方法将光流信息编码,同时用+2Ped 中的re-weighting技巧把环境信息加入。这种 SquaresChnFtrs+DCT+SDt+2Ped 的方法被称为Katamari-v1。
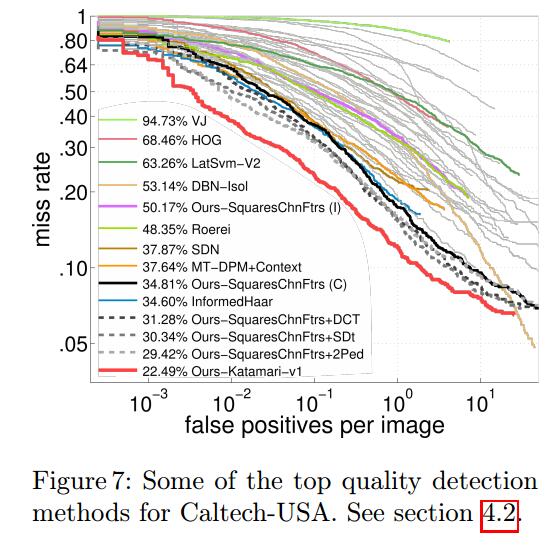
如图7 所示,Katamari-v1 方法达到了在Caltech上的最好结果,图7还显示了其他方法所获得最好效果。
结论:实验证明——通过加入额外的特征,光流,和环境信息是可以很大程度的互补的,获得了12%的提升。
4.3 How much model capacity is needed?
我们的目标是要从训练集到测试集推广,那么在研究模型泛化能力的时候,一个重要的问题就是,模型在训练集上的效果如何呢?
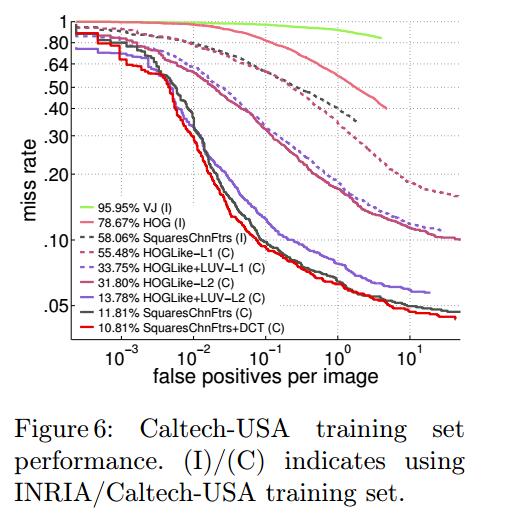
图6显示模型在训练集上的效果,不幸的是,这些方法都在训练集上就表现不佳,所以,目前还没有发现过拟合的问题。
所以,我们还是应该研究更有区分力的检测子来提升检测结果。这些更有区分力的检测子可以通过寻找更好的features和更复杂的分类器来实现。
4.4 Generalisation across datasets
对于真实世界应用来说,模型的泛化能力才是关键。
表2 展示了SquaresChnFtrs 用不同训练集训练时在Caltech上的表现(对于KITTI,评价指标是AUC,越高越好;对于其他数据集,评价指标是MR,越小越好)。
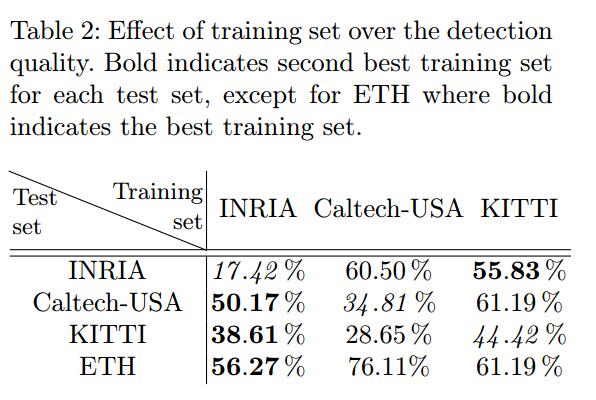
从表中可以看出,在Caltech和KITTI上训练,对于INRIA数据集的泛化性能很差。而反过来,INRIA确实对于Caltech和KITTI第二好的选择。这些结果表明,Caltech的行人相对更加单一的,而INRIA却因为它的多样性而更加有效。
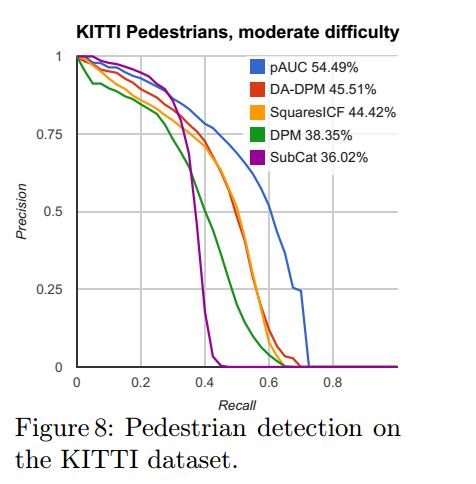
如图8,训练和测试如果都在KITTI上,SquaresChnFtrs (在KITTI上叫SquaresICF )比普通的DPM好,而且还和最好的DPM变体(DA-DPM )相当。目前在KITTI上表现最好的方法,pAUC 是ChnFtrs 的变体,只是它使用了250个特征通道而已。 这也和我们在3.9 和4.1 中的结论一致。
小结:尽管在一个训练集上训练之后再在另一个数据集上测试效果不一定好,但是排名大体还是基本一致的。也就是说,只要方法足够好,无论benchmark是什么都能得到好的结果。
5 Conclusion
做了这么多实验,发现这么多年在pedestrian detection上的进步基本上都得益于特征的提升,目前来看,这种趋势还将继续。
实验结果表明,better features ,optical flow ,context 是互补的。将它们结合起来,得到了在Caltech数据集上的最好模型。
尽管三种主要的方法——DPM,DF,DN——是基于完全不同的学习技巧的,它们的state of art 结果却是惊人相似的。
最后,未来的挑战将是更深层次的理解好的特征为什么好,这样才能设计出更好的特征!
参考文献
http://janhosang.com/pdfs/2014_eccvw_ten_years_of_pedestrian_detection_with_supplementary_material.pdf
http://blog.csdn.net/mduke/article/details/46582443

