
文章对很多方法在各方面进行对比分析,得出一些影响行人检测结果的因素。
方法很多,对方法本身的描述阐释的比较少。我也主要对结论进行翻译整理:
水平有限,难免错漏。
摘要:
目前的检测方法主要可分为三类,这三类的检测效果近似。
1. 引言:
行人检测是目标检测的典型实例。应用广泛。行人检测的问题定位明确,建立有基准和评价指标。因此行人检测可以作为探索不同目标检测方法的场所。目标检测的主要方法都在这里有使用,包括:Viola&Jones变体、HOG+SVM刚性模板、部件可变形探测器(DPM,也叫部位法)、卷积神经网络(ConvNets)。
本文的目的是:回顾过去十几年行人检测的进展(40+方法)、找出主要的创意、尝试量化哪一种创意对于最终的检测质量最有效力。在接下来的部分,我们回顾了现有的数据集(section 2)、对不同的方法进行了讨论(section 3)、通过实验重现/量化最近几年的进展(section 4)。虽然我们不是要介绍一个新的技术,但是通过现有的技术我们报道除了在Caltech-USA数据集上的最好检测结果。
2. 数据集:
过去已经出现了很多的行人检测公开数据集。INRIA, ETH, TUD-Brussels, Daimler(Daimler stereo), Caltech-USA和KITTI是最常用的。他们都有不同的特点,弱点和强项。
INRIA是最老的一种数据集,具有较少的图像。它的优势在于具有不同场景下(城市、海边、山区等)行人的高质量注释。所以它常用于做训练。ETH和TUD-Brussels是中等规模的视频数据集。Daimler没有被任何方法选择,因为缺少颜色通道。Daimler stereo、ETH和KITTI提供立体信息。除了INRIA,所有的数据集都通过视频获取,所以都可用光流方法作为附加。
目前,Caltech-USA和KITTI是行人检测的主要标准。二者都一样大,一样有挑战性。Caltech-USA的突出点是对于很多的方法都有用以评估;KITTI的突出点是测试集的多样性略好,但是使用的不是很频繁。INRIA, ETH (monocular), TUD-Brussels, Daimler (monocular), 和Caltech-USA 可以在一个统一的评估工具下使用。KITTI使用自己独立的未公开测试集的工具。
本文主要是用Caltech-USA数据集来比较不同方法,INRIA和KITTI其次。Caltech-USA和INRIA结果使用对数平均失误率(log-acerage miss-rate, MR, 值小为好)来评估;KITTI使用精确回忆曲线下的面积(area under the precision-recall curve,AUC,值高为好)来评估。
标准的价值:独立论文的方法通常只在某个数据集上以狭窄的视野达到了顶尖。有一个官方标准来收集各种方法的检测结果,极大的简化了作者将曲线放入的工作,并且为观察者提供了一个快速获取结果的方式。
3. 改善行人检测的主要方式
图3和表1一起定性和定量的展示了40+方法的比较,他们的结果都通过Caltech行人检测标准(2014)公布。

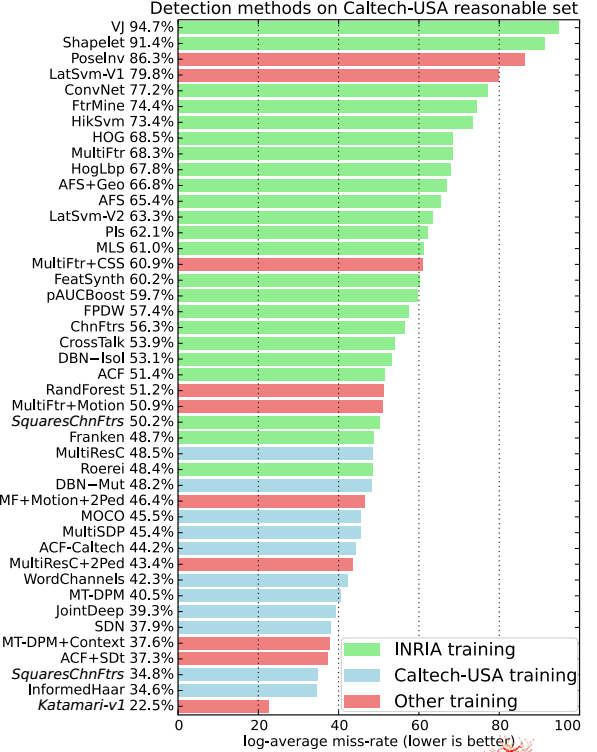
所有的方法都在Caltech标准下重新描述,而不是用该方法所独有的场景。
主要年代:VJ检测器,2003;HOG检测器,2005;DPM(LatSvm,HOG作为一个块),2008;......
3.1 训练数据
图3显示,检测性能的差异毫不奇怪的受控于训练数据的选择。
3.2 方案类型
总体上,40+方法可以分类为三中类型:DPM变体(MultiResC、MT-DMP,等)、深度网络(JoinDeep、ConvNet,等)、决策树(ChnFtrs、Roerei,等)。表中分别以DPM、DN和DF(Decision forests)标识。
仅凭原始数据就能促进决策树的生长,似乎特别适用于行人检测。在INRIA训练在Caltech测试,或者在Caltech训练,在Caltech测试都可以达到最佳性能。深度网络同样表现出很有趣的特性,并在检测质量上进展迅速。
结论:三种方法都在行人检测中达到了顶尖效果。
3.3 更好的分类器
自从HOG+SVM方法被踢出,线性和非线性内核都在考虑范围内。
近来,越来越多的检测器的部件单元都通过加入‘决策单元’进行优化。造成特征和分类器的边界区分不再清晰。
结论:没有结论性的经验证据表明非线性核比线性核更好,也不清楚是否一个特定的分类器(如SVM或者决策树)回避另外一个是适合用来做行人检测。
3.4 补充数据
一些方法在训练和测试中使用额外信息来改善检测结果。如:立体图像(stereo images)、光流(MultiFtr+Motion、ACF+SDt)、寻迹(tracking)、或其他场景数据(lidar、radar)。
结论:使用补充数据可以得到有效改善检测结果,尽管目前的数据集中立体和光流还没有完全采用。
3.5 利用上下文(exploiting context)
滑动窗口检测器可以通过窗内内容获得潜在的检测窗。利用上下文的策略包括:地平面约束(MultiResC、RandForest)、自动上下文(MOCO)、其他种类检测器(MT-DPM+Context)、人到人模式(DBN-Mnt、+2Ped、JointDeep)
结论:上下文提供了一定的改善,虽然改善的复读相比于补充数据(3.4)和深度结构(3.8)要低。
3.6 可变形部分
DPM检测是最初是用于行人检测的,并变得流形且发展了十几种变体。
对于行人检测的结果,有效但不显著。但有趣的是,在深度结构中对部件或部件的变体建模。
结论:除了遮挡问题外,对于行人检测,仍没有清楚的证据证明组件和部件的必要性。
3.7 多尺度模型
典型的检测中,高低分辨率的候选窗都被采样到同样大小,然后进行特征提取。目前发现,同时训练不同分辨率的模型可以提高性能1-2MR。
结论:多尺度模型提供了一个简单和通用的方法来扩展现有的分类器。尽管有改进,但对最终质量的贡献很小。
3.8 深度结构
大量的测试数据和增强的计算能力导致深度结构的成功。
ConvNet使用无监督和有监督混合的训练在INRIA上创建了一个卷积神经网络。该方法通过学习直接从原始像素值中提取特征。
结论:尽管有共同的描述,但是仍然没有清晰的证据证明深度网络善于学习特征。使用这类结构的成功方法大多数用这种结建模部件、遮挡和上下文中的高级方面。其检测结果和DPM、决策树同水平。
3.9 更好的特征
改善检测质量的最常见方法是增加或者多样化输入图像的计算特征。大量的特征类型已经被使用:边缘信息、颜色信息、纹理信息、局部形状信息、协方差信息、等。
结论:过去十年里,改善的特征一直是检测质量提高的持续驱动力,并将继续下去。下一步将是发展一个更好的方式理解是什么使得一个特征是好的、如何设计更好的特征。
4. 实验
基于前面部分的分析,有三个方面对于检测质量的影响最大:更好的特征、附加数据、上下文信息。
4.1 回顾特征的影响
结论:自从VJ,许多的进展可以通过使用更好的特征来解释。这些熟悉的特征的简单组合就能产生显著的改善。
4.2 方法的互补
结论:实验结果显示增加额外特征,流,上下文信息可以极大的补足,即便是使用的很强大的检测器。是否通过核心算法或者扩展系统内技术的差异性能获得更好的检测质量,值得观察。
4.3 需要多少模型容量
检测的主要任务是从训练集到测试集的概括。是否学习到的模型在训练集上就有很好的性能呢?
结论:我们的结果表明:研究如何增加探测器的区分能力,似乎就是改善探测质量。更好的区分能力可以来自于更多更好的特征或者更复杂的分类器。
4.4 数据集的概括能力
结论:检测器从一个数据集学习到的结果可能不能很好的转移到另一个数据集,数据集之间是同等地位的。这表明,可以从良好性能的方法中学习,而不要管数据集。
5 结论
实验表明行人检测过去十几年的绝大多数进展归功于特征的改善。证据表明这一结论将继续。尽管这些特征中的一些是通过学习得来,但是主要还是尝试和试错手工得到。
未来的主要挑战似乎是更深入的理解什么使得一个特征更好,然后可以设计出更好的特征。

