
- 1Leetcode: 合并两个有序链表(js)_@param {listnode} list1
- 2Python数据结构与算法-贪心算法(一)_贪心算法有n个非负整数,将其按照字符串拼接的方式拼接位一个整数,如何拼接可
- 3高效又稳定的ChatGPT大模型训练技巧总结,让训练事半功倍!_chatgpt 大模型训练
- 4python dataframe series 自定义排序规则_dataframe 按照key 排序
- 5HTML5入门 之下拉菜单_html5 下拉框
- 6快速从0-1完成聊天室开发——环信ChatroomUIKit功能详解
- 7阿里云——云存储:对象存储管理与安全
- 8MAC Homebrew 指令安装&卸载_==> the xcode command line tools will be installed
- 9在CentOS下安装NVIDIA显卡驱动。_centos 9 nvida xianka qudong
- 10【渝粤题库】陕西师范大学201301 《经济法学》作业(高起本、专升本)_下列哪项与消费者协会的法定职能不相称
有没有什么可以节省大量时间的 Deep Learning 效率神器?
赞
踩
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达有没有什么可以节省大量时间的 Deep Learning 效率神器?
欢迎留言讨论~
金瀛若愚
链接:https://www.zhihu.com/question/384519338/answer/2620482813
隆重安利Wandb+Hydra+Plotly 组合大法。这三个哥能让你的调参侠生涯如沐春风。
每个实验保存完整config + wandb远程追踪
还在给model取巨长的文件名来记录其超参吗?out了。wandb可以把config和结果曲线同步云端供横向评比和查看。同步云端的代码:
- def wandb_init(cfg: DictConfig):
- wandb.init(
- project='best paper',
- group=cfg.exp_group,
- name=cfg.exp_name,
- notes=cfg.exp_desc,
- save_code=True,
- config=OmegaConf.to_container(cfg, resolve=True)
- )
- OmegaConf.save(config=cfg, f=os.path.join(cfg.ckpt_dir, 'conf.yaml'))
这里的OmegaConf下面会讲到。想不起来某个实验的model存在哪了?看wandb的界面查找每个config值
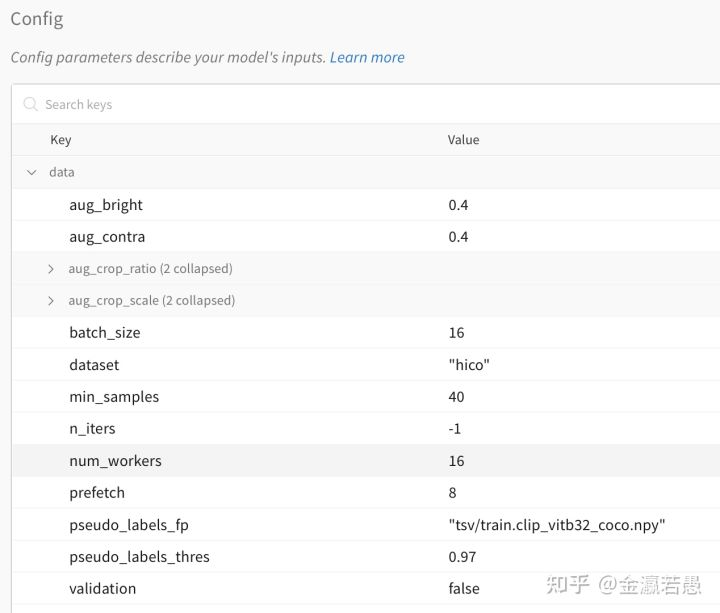
对应每个实验的curves
Hydra+OmegaConf配置管理
OmegaConf是Meta出的配置管理工具,可将yaml文件转成有对应变量名的Python的class或dict。支持默认值、合并和override、导出成yaml或json等,十分好用。你再也不用手写配置管理了。
比如:
- blob_root: /yjblob
- exp_name: best_paper_2
- ckpt_dir: ${.blob_root}/${.exp_name}/ckpt
- log_dir: ${.blob_root}/${.exp_name}/log
上面是config.yaml的片段,OmegaConf.resolve(cfg) 一句即可把blob_root 和exp_name 的值填进 ckpt_dir里。而普通的yaml是不支持变量的。
Hydra是Meta出的实验提交工具,支持在命令行里动态修改OmegaConf里面的数值。Hydra支持一个config里引用另一个config,于是你可以很容易的切换用db=mysql 还是db=postgresql :
- ├── conf
- │ ├── config.yaml
- │ ├── db
- │ │ ├── mysql.yaml
- │ │ └── postgresql.yaml
- │ └── __init__.py
- └── my_app.py
而且,这个OmegaConf的配置(DictConfig类型)可以转成Python的dict然后传给wandb,打通全场(见第一节的示例代码)。
Plotly导出可交互的曲线
Matplotlib不支持交互,生成的曲线无法还原每个点的值。Tensorboard和wandb的网页 支持交互,但不容易导出,而且其内置的precision-recall曲线等函数无法深度定制,只适合于画一些loss和lr曲线。Plotly就很强了。

当然也可以做定制化的precision-recall曲线。比如我希望看不同threshold下的precision, recall和false positive ratio,这样的定制化曲线wandb等并不支持,就可以用plotly
- df = DataFrame({
- 'thres': thresholds,
- 'prec': prec_data1,
- 'recl': recl_data1,
- 'fp': fp_data2
- })
- df = df.melt(id_vars=['thres'], value_vars=['prec', 'recl', 'fp'], var_name='curves')
- fig = px.line(df, x='thres', y='value', color='curves', markers=True)
- fig.update_xaxes(range=[0, 1])
- fig.update_yaxes(range=[0, 1])
- fig.update_traces(mode="markers+lines", hovertemplate=None)
- fig.update_layout(hovermode="x")
- fig.write_html(os.path.join(self.cfg.ckpt_dir, 'curves.html'), auto_play = False)
里面的hovermode指定移动鼠标时显示相同x值的不同y值:
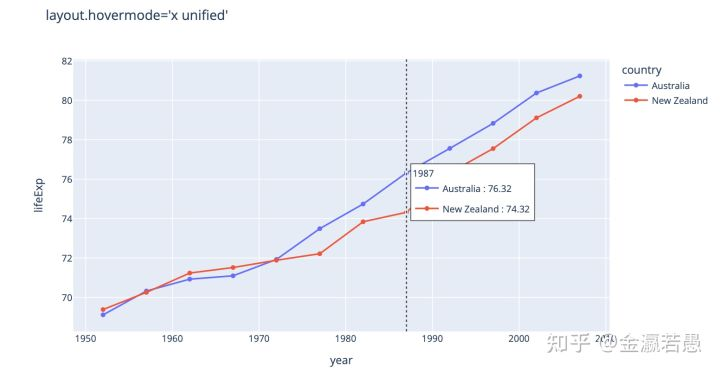 这还没完,wandb支持把plotly生成的可交互网页嵌入到wandb里
这还没完,wandb支持把plotly生成的可交互网页嵌入到wandb里
- import wandb
- import plotly.express as px
-
- # Initialize a new run
- run = wandb.init(project="log-plotly-fig-tables", name="plotly_html")
-
- # Create a table
- table = wandb.Table(columns = ["plotly_figure"])
-
- # Create path for Plotly figure
- path_to_plotly_html = "./plotly_figure.html"
-
- # Example Plotly figure
- fig = px.scatter(x = [0, 1, 2, 3, 4], y = [0, 1, 4, 9, 16])
-
- # Write Plotly figure to HTML
- fig.write_html(path_to_plotly_html, auto_play = False) # Setting auto_play to False prevents animated Plotly charts from playing in the table automatically
-
- # Add Plotly figure as HTML file into Table
- table.add_data(wandb.Html(path_to_plotly_html))
-
- # Log Table
- run.log({"test_table": table})
- wandb.finish()

以上便完成了Hydra+OmegaConf+wandb+plotly的打通。
使用远程GPU服务器/集群的一些技巧
如果要使用远程的服务器,常见问题在于远程debug、代码从本地同步到远程以及ssh断线重连问题。这些可以使用VS Code解决。
可以设置用得到的所有远程服务器,每个服务器配置好ssh,便于随时登录。下图的REMOTE EXPLORER里除了SSH Targets还有Containers,即可以直接ssh到服务器的docker container里。container的运行命令可以设置vs code自动完成。
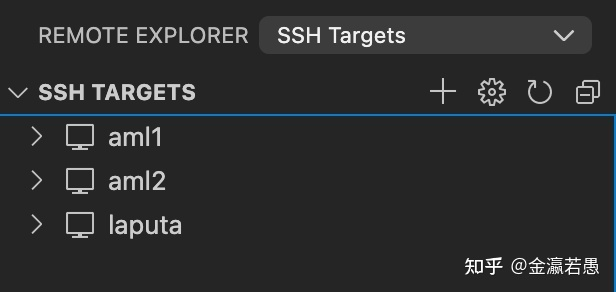
每个服务器都能从本地登录的git账户里clone代码。Clone之后下次可以直接远程打开这个repo
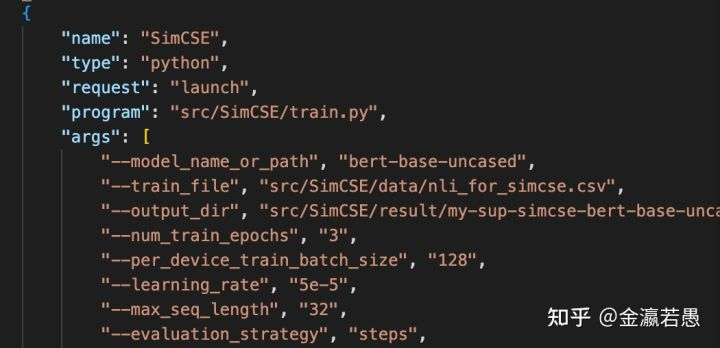
编辑Run and Debug设置(launch.json),可以预先设置training,testing等实验对应的命令行参数和环境变量,以后点对应的按钮就直接运行该实验。不用每次手动复制参数
在repo里开一个文件夹,加入gitignore。每次做可视化图片的时候,把图片存到这个文件夹,即可通过vscode远程看图,不需要每次ssh下载到本地。VS Code也支持内建ipynb文件来一边写一边运行。
邱锡鹏
链接:https://www.zhihu.com/question/384519338/answer/1181186086
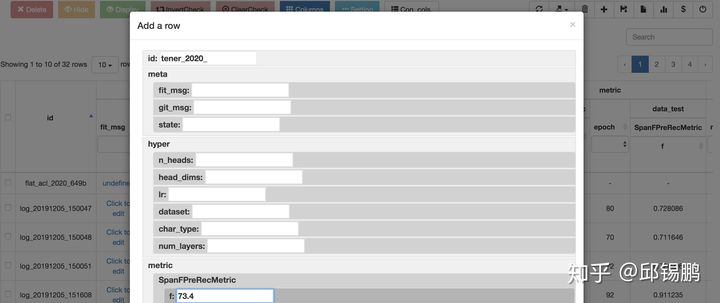
(1) Tabular显示实验结果,方便不同超参数之间的对比。以下一行是一次实验。
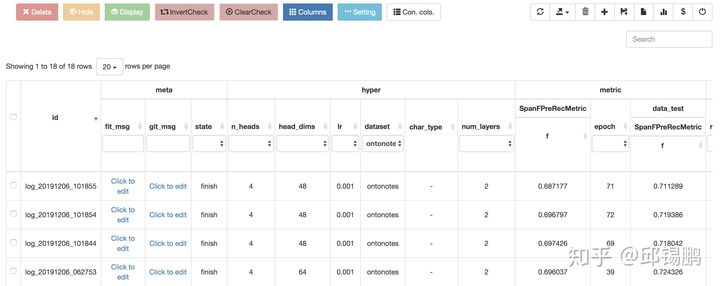 (1.1) 支持group操作,方便查看某种特定数据集或参数的性能
(1.1) 支持group操作,方便查看某种特定数据集或参数的性能
(1.2) 支持排序,谁是最强超参一目了然
(1.3) 支持column顺序、显示自定义,拯救强迫症
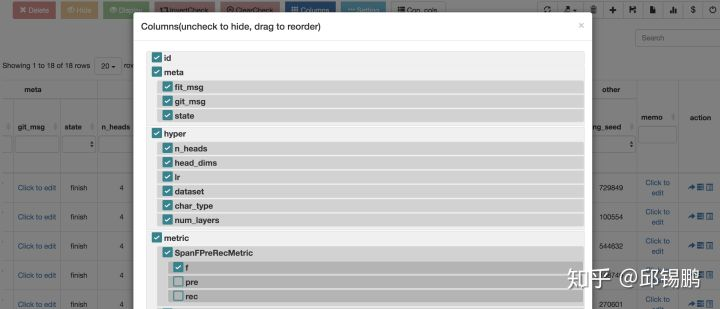 (1.4) 支持针对某条实验自定义备忘
(1.4) 支持针对某条实验自定义备忘
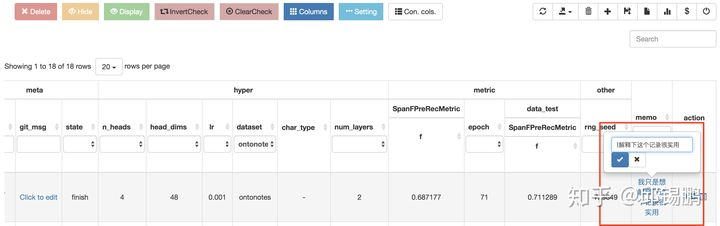 (1.5) 支持前端加入别人的实验performance,再也不用一边看paper一边check是否已经超过sota结果。
(1.5) 支持前端加入别人的实验performance,再也不用一边看paper一边check是否已经超过sota结果。
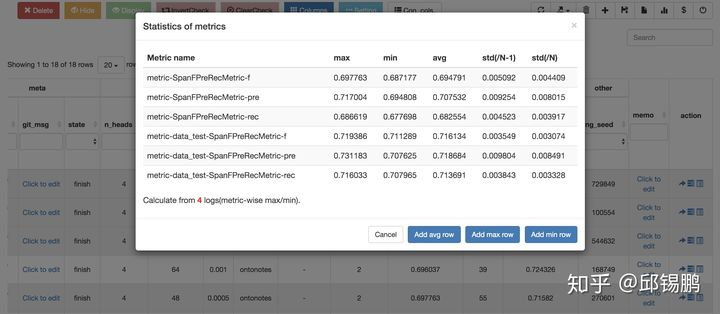
 (1.6) 支持计算平均值、标准差,还有比这个更实用的吗?
(1.6) 支持计算平均值、标准差,还有比这个更实用的吗?
 (1.7) 实验结果不理想?我们支持前端操作删除、隐藏记录
(1.7) 实验结果不理想?我们支持前端操作删除、隐藏记录
(1.8) 实在有分析需求,无法满足?我们支持导出excel、csv、txt、json等格式,总有一款适合你
(1.9) 还有什么比看到loss快速下降,evaluation快速上升更让人开心的事?
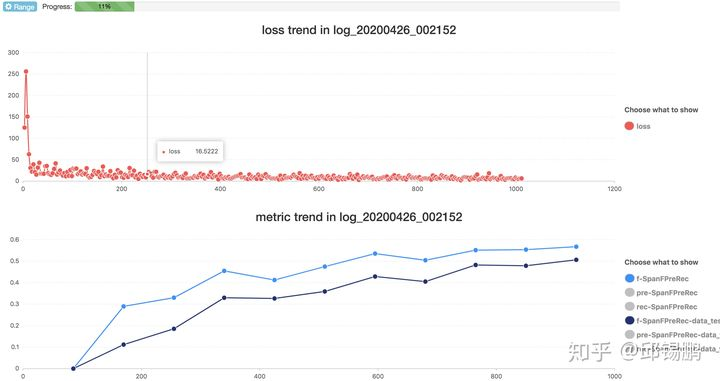
(2)想要复现实验结果,超参就够了????No, No, No. 作为一线炼丹师,我们深知调参过程有些神来之笔,例如加入Layer normalization带来的神奇效果并不能很容易体现在超参数中,所以fitlog支持在后台为你自动git commit代码(我们借助git进行代码管理,但与开发者自己管理的git不冲突,是并行的),需要回退到某次实验的代码,直接前端点击,回退,搞定。exactly复原结果不是梦(是的,我们甚至可以帮你管理随机数种子,但pytorch等深度学习框架的本身的随机性无法解决)。
(3) 茫茫的超参,哪个才是重要的?经过一夜的搜索,哪些参数搜索还不够?你可能需要这样的可视化。(每条线是一次实验,最左侧是dev上的性能)
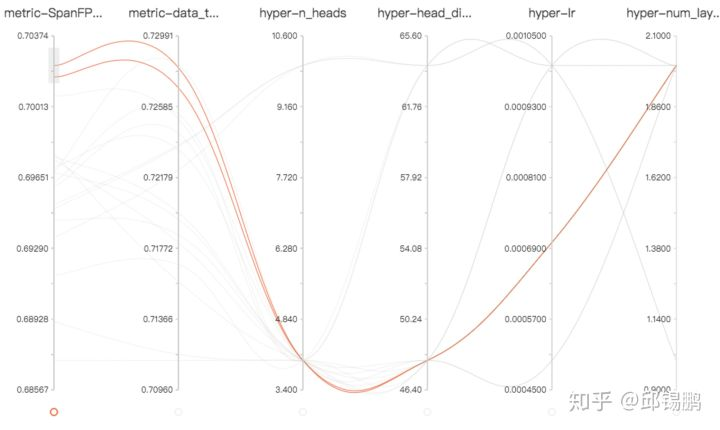 (4)fitlog是架构无关的,不管tensorflow还是pytorch都可以使用,不管是cv还是nlp也都支持。如果是NLP的任务,配合我们的fastNLP框架,只需要增加三五行代码便可以实现metric,loss的自动记录。
(4)fitlog是架构无关的,不管tensorflow还是pytorch都可以使用,不管是cv还是nlp也都支持。如果是NLP的任务,配合我们的fastNLP框架,只需要增加三五行代码便可以实现metric,loss的自动记录。
当然fitlog也不是十全十美的,对标其它的类似框架,我们为了轻量级,以下的东西目前没有支持
不支持保存model输出的图片,但是支持查看训练过程中的文本输出。
不支持除了loss与metric以外的曲线的展示。
Fing
链接:https://www.zhihu.com/question/384519338/answer/1160886439
视频详见上方链接
wandb,weights&bias,最近发现的一个神库。
深度学习实验结果保存与分析是最让我头疼的一件事情,每个实验要保存对应的log,training curve还有生成图片等等,光这些visualization就需要写很多重复的代码。跨设备的话还得把之前实验的记录都给拷到新设备去。
wandb这个库真是深得我心,只要几行代码就可以把每一次实验打包保存在云端,而且提供了自家的可视化接口,不用每次都自己写一个logger,也省掉了import matplotlib, tensorboard等一大堆重复堆积的代码块。
最关键的是,它是免费的:)
jpzLTIBaseline
链接:https://www.zhihu.com/question/384519338/answer/1196326124
关于实验管理,其他人的回答已经写得十分详细了。虽然我自己还是习惯直接Google Sheet然后在表格里的每一行记录【git commit hashcode】、【server name】、【pid】、【bash script to run exp】、【实验具体结果】、【notes】、【log position】、【ckpt position】,而且Google Sheet增加column以及合并格子用起来还是很flexible的。
这里我提一下其他方面的一些有助于提高效率的工具:
给自己的model起一个酷炫的缩写:http://acronymify.com/
现在越来越多的论文标题(尤其是Deep Learning方向)都是 [model缩写]: [正经论文题目] 的格式,而且一个朗朗上口的名字确实有助于记忆与传播。
写paper时候的用词搭配:https://linggle.com/
作为一个non-native speaker,写paper的时候词语搭配真是让人头秃。这个网站可以比较方便地找一些词语搭配。
手写/截图 转 LaTex公式:https://mathpix.com/
LaTex如果所有公式都要自己手打还是很痛苦的。(虽然很多时候一篇Deep Learning方向的paper公式数量只有十个左右(这还是在强行加上LSTM等被翻来覆去写烂的公式的情况下))
颜色搭配(色盲友好型):http://colorbrewer2.org/
这个网站不仅能很方便找到各种常用的 color schemes,而且都是 grayscale friendly and colorblind-friendly,对于paper里画图帮助比较大。
找前人paper的code:https://paperswithcode.com/
有的时候自己复现真是玄学,这个网站和搜索引擎 "[论文题目] site:http://github.com"配合使用即可。
文字转语音:https://cloud.google.com/text-to-speech
有的paper需要做一个video来介绍,对自己口语不是很有信心的话可以用G家的text2speech(这个领域Google应该是当之无愧的霸主),还能调节语速,非常贴心。
好消息!
小白学视觉知识星球
开始面向外开放啦
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

