
- 1gradle使用教程,小白一篇就够
- 2linux部署服务相关基础操作:磁盘挂载、jdk安装、docker安装、docker-compose环境安装、mysql、redis、jenkins等
- 3微信小程序的几种传值方式_微信小程序组件传值
- 4java实现猜数小游戏_java猜数字游戏: 输入开始和结束数字,由系统生成这两个数之间的一个随机数,之后
- 5因果推断对当下人工智能、机器学习的影响_ai 可信任因果推断
- 6前端解决刷新页面表单重复提交_前端js浏览器刷新会导致表单默认提交刷新前的
- 7如何确保电子商务安全交易_以实际在线交易为例,如何做好安全电子商务
- 8Android和HarmonyOS对比_android/harmonyos
- 9神经网络与深度学习简史_mozer (1987)
- 10Python数据分析-4_plt.bar(range(len(_x)), _y)
详细介绍NLP文本摘要_nlp 文本摘要
赞
踩
文本生成
文本生成(Text Generation):接收各种形式的文本信息作为输入,生成可读的文字表述。
文本摘要
文本摘要也是文本生成的应用,旨在将文本或文本集合转换为包含关键信息的简短摘要。摘要应该涵盖最重要的信息,同时要连贯无冗余,并在语法上可读。
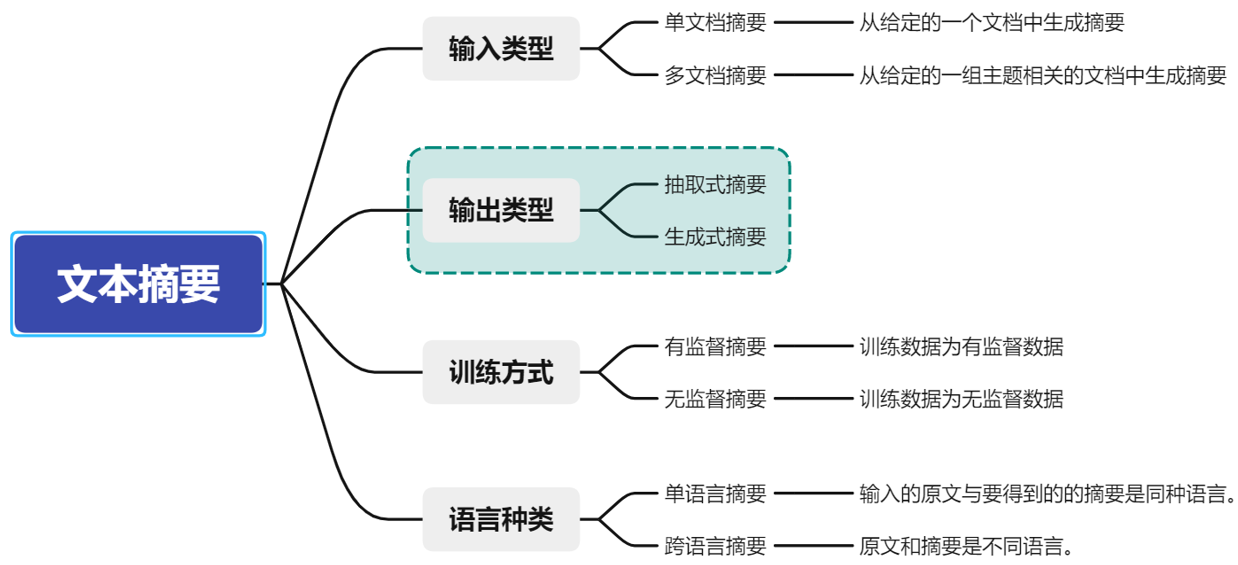
文本摘要的分类:
摘要质量的评价指标:
ROUGE(Recall-Oriented Understudy for Gisting Evaluation)分数,判断自动摘要和参考摘要的符合程度。其中最常用的是ROUGE-1、ROUGE-2和ROUGE-L。ROUGE-1和ROUGE-2的计算方式相同,即:

ROUGE-L即最长公共子序列(Longest Common Subsequence,LCS),计算如下:
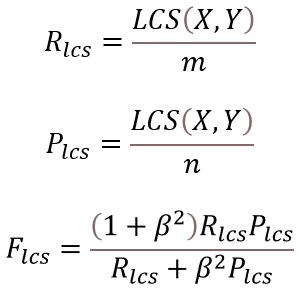
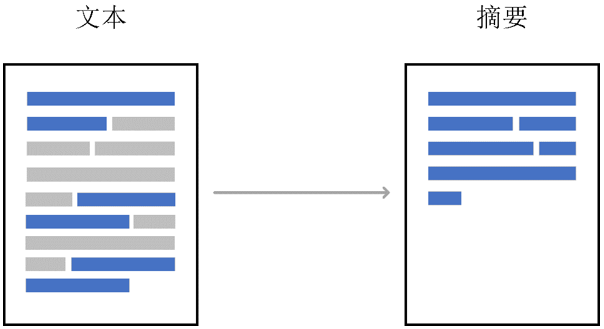
抽取式文本摘要
抽取式摘要(Extractive Summarization),从原文中选取关键词或句组成摘要,可以看作是一种序列标注问题,对原文中的每个句子(或字、词等单位)都做一个二分类,判断是否属于摘要,并组合起来作为摘要。
抽取式文本摘要方法
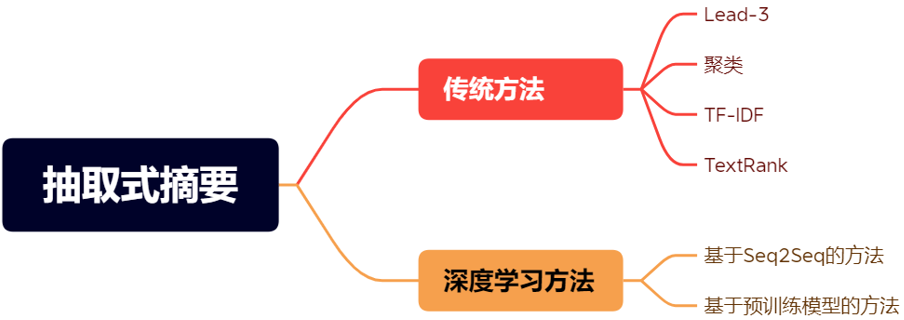
1.Lead-3方法:
抽取式摘要方法中,最简单的就是Lead-3方法:直接选取原文的前三句作为摘要。但因为许多语料会在文档开头就表明主题,因此Lead-3 方法虽然简单,但往往有着不错的表现。
2.基于聚类的方法:
通常情况下,文档中的相近的语句或段落会描述相近的内容,所以我们可以使用聚类完成摘要任务。例如可以通过余弦相似度的度量指标,将一篇文档中里的语义相近的句子聚到一簇,不同簇间往往表征着差别较大的语义。然后通过对簇内部的句子进行筛选,可以达到精简句子、提炼主题关键句的目的。
3.TF-IDF:
TF-IDF(term frequency–inverse document frequency)是一种用于信息检索与数据挖掘的常用技术,常用于挖掘文章中的关键词,算法简单而高效,常被工业用于最开始的文本数据清洗。
TF-IDF有两层意思,一层是"词频"(Term Frequency,缩写为TF),另一层是"逆文档频率"(Inverse Document Frequency,缩写为IDF)。词频即词出现的次数,一个词的词频越高,越可能作为句子的关键词。


但是在一篇文章中,两个相同词频的词未必有相同的重要性,因为有些词如“系统”、“算法”这种词在某个计算机相关语料库中可能本身就比较常见。这个时候就需要IDF,IDF会给常见的词较小的权重,它的大小与一个词的常见程度负相关。
当有TF(词频)和IDF(逆文档频率)后,将这两个量相乘,就能得到一个词的TF-IDF值。
TF-IDF文本摘要流程:
某个词在文章中的TF-IDF越大,那么一般而言这个词在这篇文章的重要性会越高,所以通过计算文章中各个词的TF-IDF,由大到小排序,排在最前面的几个词,就是该文章的关键词。包含关键词较多的句子,就可以作为摘要句。
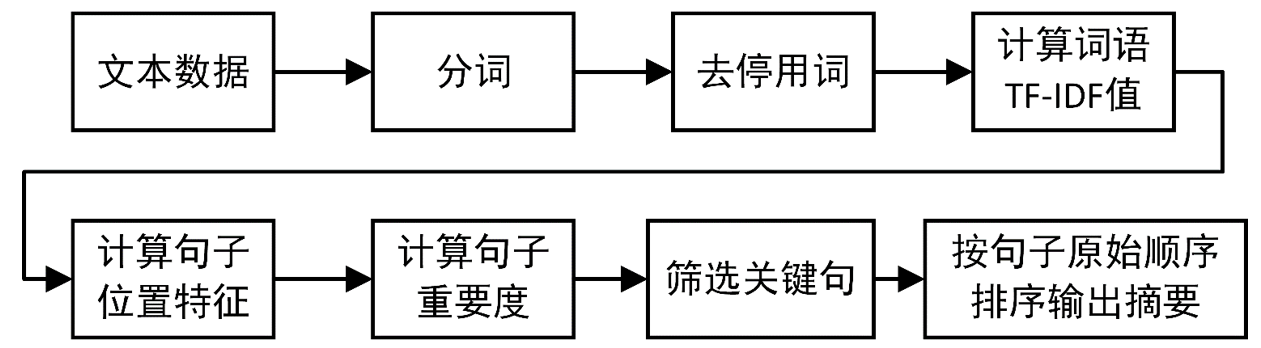
① 对于给定的文档进行分词、去停用词等数据预处理操作。保留如“名词”,“动词”,“形容词”等有实意的词语,最终得到n个候选关键词,即
“D=[”
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

