
- 1UniApp组件:常见的组件及其用法_uniapp uni组件
- 2报错:ERROR: Unable to resolve dependency for ':app@debug/compileClasspath': Could not resolve XX.XX
- 3NLPer福利!清华推出Prompt-tuning开源工具包,取代传统的微调fine-tuning_prompt tuning调优 训练语料
- 4chatgpt赋能python:Python中文文本预处理_中文预处理工具类python
- 5ubuntu| sudo apt-get update 更新失败, 没有 Release 文件 无法安全地用该源进行更新,所以默认禁用该源_没有 release 文件。 n: 无法安全地用该源进行更新,所以默认禁用该源。
- 6NLP比赛利器:DeBERTa系列模型介绍
- 7【循序渐进学Python】使用多种方法实现素数之和_python求一个数的所有因数之和
- 8你要的 Spark AI Summit 2020 PPT 我已经给你整理好了
- 9测试C#调用OpenCvSharp和IronOcr从摄像头中识别文字_c# ocrscanner
- 10【uniapp开发小程序】点击获取手机号(使用@getphonenumber)
22万字大模型面经整理+答案_chatglm3 的词表实现方法?
赞
踩
槽位对齐(slot alignment)
在text2sql任务中,槽位对齐(slot alignment)通常指的是将自然语言问题中的关键信息(槽位)与数据库中的列名或API调用中的参数进行匹配的过程。这个过程中,模型需要理解问题中的词汇,并将其映射到数据库或API的相应部分。
在多模态的text2sql任务中,比如涉及到图表类型选择、API参数对齐的任务,槽位对齐可能还需要考虑如何将文本信息与图表数据、API调用所需的参数进行有效对齐。这意味着模型不仅要理解自然语言,还要能够处理和理解图表中的信息,以及如何将它们转换为正确的查询或API调用。
例如,如果用户提出了一个关于特定数据集的问题,模型需要识别出相关的槽位(如时间范围、产品类别等),然后根据这些槽位选择合适的图表类型,并确保API调用的参数与这些槽位正确对应。
OOD
在机器学习和数据科学领域,"OOD"代表"Out-of-Distribution",即分布外。分布外(Out-of-Distribution, OOD)情况指的是模型在处理那些不属于其训练数据分布的数据时所面临的问题。简单来说,就是模型遇到了它在训练过程中没有见过的新情况或数据。
在Task Classification任务中,如果考虑了OOD情况,模型就需要能够识别出那些不属于预定义分类的任务,并可能需要采取某种策略来处理这些未知或未预见的情况。例如,如果一个模型被训练来识别适合用柱状图、折线图、饼图、散点图和地图展示的五种任务类型,那么任何不适用于这五种图表类型的任务都会被视为OOD。
在实际情况中,OOD检测对于确保模型的鲁棒性和可靠性非常重要,因为它帮助模型识别并妥善处理未知或异常数据,而不是错误地分类或处理。这对于自动化系统尤其重要,因为错误地处理OOD情况可能会导致不准确的决策或意外的行为。
“TPM"问题
在数据可视化模块中,"TPM"问题通常指的是"Too Powerful Models"(过于强大的模型)问题。这个概念是指在使用大型语言模型(Large Language Models, LLMs)进行数据分析和可视化时,可能会出现的以下两个主要问题:
- 过度拟合:大型语言模型具有很高的参数量和容量,能够捕捉到数据中的复杂模式和关系。然而,这可能导致模型在训练数据上过度拟合,即模型不仅学习了数据中的真实模式,还学习到了训练数据中的噪声和特定特征。当模型应用于新的或未见过的数据时,过度拟合的模型可能无法很好地泛化,导致不准确或误导性的可视化结果。
- 缺乏可解释性:大型语言模型通常被视为"黑箱"模型,因为它们的内部决策过程和特征提取机制很难解释和理解。这导致很难解释为什么模型会生成特定的可视化结果,以及这些结果是否可靠和可信。缺乏可解释性可能会阻碍用户对模型输出结果的信任和采用。
因此,在使用大型语言模型进行数据可视化时,需要谨慎处理TPM问题,确保模型能够泛化和提供可解释的结果。这可能涉及到适当的模型正则化、验证和测试,以及开发可解释性工具和技术来解释模型的决策过程。
消融实验(Ablation Study)
消融实验(Ablation Study)是一种实验设计方法,用于评估模型或系统中各个组成部分的重要性。在消融实验中,研究者会逐步移除或“消融”模型的一部分组件或功能,然后评估这些变化对模型性能的影响。通过比较不同版本的模型性能,研究者可以确定哪些组件或功能对于模型的表现至关重要,哪些则不那么重要。
消融实验可以是通过对prompt中的问题表示进行修改,比如去掉外键信息,然后观察模型性能的变化。例如,如果原始问题包含关于数据库中表之间关系的信息(外键信息),那么在消融实验中,研究者可能会移除这些关系信息,然后评估模型在执行text2sql任务时的性能。
通过这种实验,研究者可以了解外键信息对模型性能的影响,从而得出结论,外键信息对于生成准确的SQL查询是否重要。如果去掉外键信息后模型性能显著下降,那么可以认为这些信息对于任务来说是关键因素。反之,如果性能下降不明显,则可能表明模型对其他信息更为依赖。
消融实验是理解复杂模型和系统中各个部分作用的一种有效方法,它有助于提高模型的可解释性,并指导模型改进和优化。
Z-score算法
Z-score算法,也称为标准分数(standard score)算法,是一种统计学上的方法,用于描述一个数值相对于整个数据集的平均值的位置。Z-score衡量的是原始分数和平均值之间的标准差的倍数。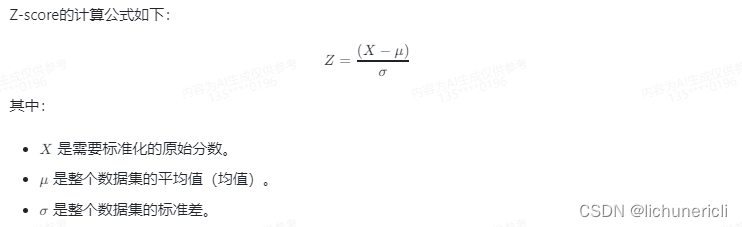
通过计算Z-score,我们可以了解一个数值相对于整个数据集是处于高于平均值还是低于平均值,以及相差了多少个标准差。Z-score的一个重要作用是将不同分布的数据转换为标准正态分布(均值为0,标准差为1的分布),这样便于比较和统计分析。
例如,如果一个学生的某门课程的Z-score是2,那么这意味着该学生的分数比平均值高出2个标准差。Z-score也可以是负数,表示分数低于平均值。Z-score的绝对值越大,表示该分数在数据集中的位置越偏离平均值。
涌现能力
大模型的涌现能力通常指的是在训练过程中,随着模型参数的增加,模型会逐渐展现出一些之前不具备的能力。这些能力可能是在模型训练初期无法预测的,但随着模型规模的扩大和训练数据的增加,这些能力逐渐显现出来。
在深度学习领域,涌现能力是一个重要的研究方向,它涉及到模型设计、训练方法、数据集等多个方面。涌现能力的出现,一方面表明了深度学习模型的强大潜力,另一方面也给模型的解释性和可控性带来了挑战。
例如,在自然语言处理领域,随着模型规模的增加,模型在语言理解、文本生成等方面的能力得到了显著提升。这些能力在一定程度上超出了模型设计者最初的预期,体现了大模型的涌现能力。
UMAP 统一流形近似和投影
UMAP(Uniform Manifold Approximation and Projection)是一种非线性的降维技术,它可以将高维数据映射到低维空间,同时尽可能保持数据原有的几何结构。UMAP 以流形学习的理论为基础,通过构建数据的局部邻域图,并在低维空间中寻找这些邻域的均匀表示,从而实现数据的降维。与传统的线性降维方法(如主成分分析PCA)相比,UMAP 能更好地捕捉数据的非线性结构。
UMAP 降维技术的步骤大致如下:
- 构建邻接图:首先,UMAP 会计算数据点之间的距离,并找出每个点的近邻点,构建一个基于这些近邻关系的图。
- 估计局部连通性:接着,UMAP 会估计这个图上每条边的权重,这反映了点之间的局部连通性。
- 优化嵌入:然后,UMAP 通过优化过程寻找一个低维空间中的数据表示,以保持原始高维空间中的这些局部连通性。这一步通常涉及到寻找一个低维空间中的点集,使得这些点之间的距离最小化,同时保持原始邻接图上的边权重。
- 输出降维结果:最后,UMAP 输出低维空间中的数据坐标,这些坐标即为降维后的嵌入。在 Python 中,可以使用 `umap-learn` 库来实现 UMAP 降维。
- import umap
- from sklearn.datasets import load_digits
-
- # 加载数据集
- digits = load_digits()
- data = digits.data
-
- # 创建 UMAP 模型并拟合数据
- umap_model = umap.UMAP(n_neighbors=5, min_dist=0.3, metric='correlation')
- embedding = umap_model.fit_transform(data)
-
- # embedding 即为降维后的数据
- print(embedding.shape) # 输出降维后的维度
在这段代码中,`n_neighbors` 参数指定了每个点在构建邻接图时考虑的近邻点数量,`min_dist` 参数影响了降维后点之间的最小距离,`metric` 参数定义了用于计算点之间距离的度量标准。根据具体的数据集和需求,这些参数可能需要调整以获得最佳的降维效果。
Reciprocal Rank Fusion 互惠排名融合
"Reciprocal Rank Fusion",是一种用于结合多个排名列表的方法,通常用于信息检索、推荐系统或机器学习中的多任务学习场景。这种方法的基本思想是,如果两个排名列表中的元素在彼此的列表中都有较高的排名,那么这些元素应该是相关的。因此,这种方法通过考虑一个列表中的元素在另一个列表中的排名来提高排名的质量和准确性。
在多任务学习场景中,不同的模型可能会针对不同的任务生成排名列表。例如,一个模型可能会针对用户查询推荐新闻文章,而另一个模型可能会推荐相关的产品。Reciprocal Rank Fusion可以帮助提高这些模型的整体性能,因为它考虑了不同任务之间的相关性。
Reciprocal Rank Fusion这种方法的具体实现通常涉及以下步骤:
- 生成排名列表:首先,每个模型都会针对其任务生成一个排名列表。这些列表通常是由一组候选项(如文档、产品、用户等)根据它们的任务相关性进行排序的。
- 计算排名分数:对于列表中的每一对元素,计算它们在另一个列表中的排名。例如,如果有一个新闻推荐列表和一个产品推荐列表,那么对于列表中的每一篇新闻和每一个产品,计算这篇新闻在产品列表中的排名,以及这个产品在新闻列表中的排名。
- 融合排名分数:将计算出的排名分数结合起来,以生成一个新的排名列表。这个过程可能涉及加权平均、取最大值或其他融合技术。
- 优化:最后,可能需要对融合后的排名列表进行优化,以确保它们更好地满足所有相关任务的需求。
Reciprocal Rank Fusion是一种强大的方法,因为它可以利用不同模型之间的相关性,从而提高整体性能。然而,它的实现可能需要仔细考虑如何计算排名分数,以及如何融合这些分数,以生成高质量的排名列表。
IR 信息检索
IR 是(Information Retrieval)的缩写,它是一门研究如何高效地存储、组织、搜索和提取信息的学科。在设计和实现一个 IR 系统时,需要考虑以下几个关键的组成部分:
- 数据采集:首先需要收集和组织相关的数据。这些数据可以是从各种来源获取的,如文本、图像、音频和视频等。
- 数据处理:对采集到的数据进行预处理,包括清洗、去重、分词、词干提取、词形还原等步骤,以便更好地组织和管理数据。
- 索引构建:将处理后的数据构建成索引,以便快速检索。索引是一种数据结构,它将文档映射到与之相关的关键词上。
- 查询处理:接收用户的查询请求,并对其进行解析和处理,以便有效地从索引中检索相关信息。
- 排名和排序:根据相关性对检索到的结果进行排名和排序,以便用户能够快速找到最相关的信息。
- 用户交互:提供用户界面,使用户能够提交查询、浏览和检索结果。
- 性能评估:使用各种评估指标(如准确率、召回率、F1 分数等)来评估 IR 系统的性能。
- 更新和维护:定期更新索引和数据,以保持 IR 系统的准确性和可靠性。
设计一个高效的 IR 系统需要综合考虑这些组成部分,并选择合适的算法和技术来实现它们。此外,还需要考虑用户的需求和行为,以确保 IR 系统能够提供有价值和相关的检索结果。
PCA 主成分分析
PCA 是(Principal Component Analysis)的缩写,它是一种统计方法,用于通过正交变换将一组可能相关的变量转换为一组线性不相关的变量,这组变量称为主成分。PCA的目标是找出数据中的主要趋势和模式,以便可以简化数据集,同时尽可能保留原始数据中的信息。
PCA的主要步骤如下:
- 数据标准化:首先对数据进行标准化处理,以确保每个变量具有相同的尺度。
- 计算协方差矩阵:计算标准化数据集的协方差矩阵,以了解不同变量之间的关系。
- 计算特征值和特征向量:对协方差矩阵进行特征分解,找出最大的特征值和对应的特征向量。这些特征值和特征向量代表了数据中的主要方向,即主成分。
- 选择主成分:根据特征值的大小,选择最重要的几个主成分。这些主成分能够解释数据中的大部分方差。
- 重构数据:使用选定的主成分重构数据,得到简化后的数据集。
PCA广泛应用于数据降维、特征提取和数据可视化等领域。通过PCA,可以去除数据中的噪声,识别出最重要的变量,从而简化模型和提高预测性能。然而,PCA也有一些局限性,例如它不考虑变量之间的非线性关系,且在处理类别数据时需要特别的处理。
t-SNE t-分布随机邻域嵌入
t-SNE(t-Distributed Stochastic Neighbor Embedding)是一种非线性降维技术,由Laurens van der Maaten和Geoffrey Hinton于2008年提出。t-SNE旨在将高维数据投影到低维空间,同时保持数据点在低维空间中的相似性结构,类似于它们在高维空间中的分布。
t-SNE的工作原理如下:
- 相似性度量:t-SNE使用高维空间中的相似性度量(如欧氏距离)来评估数据点之间的相似性。
- 概率分布:t-SNE将高维空间中的每个数据点映射到低维空间中的一个点,并且认为这个低维点周围的点在某种程度上保留了高维空间中该点的邻居分布。为了实现这一点,t-SNE首先为每个高维数据点构建一个概率分布,表示该点与其邻居点之间的关系。
- 目标分布:然后,t-SNE为低维空间中的每个点也构建一个概率分布,这个分布反映了低维空间中点与点之间的相似性。t-SNE的目标是使这两个概率分布尽可能相似。
- 梯度下降:为了达到这个目标,t-SNE使用梯度下降方法来调整低维空间中点的坐标,以便更好地反映高维空间中的相似性结构。
t-SNE的一个关键特点是它使用了t-分布来模拟高维空间中的相似性分布,这使得它能够在非线性空间中捕捉到数据的局部结构。t-SNE通常用于可视化高维数据,但它也可以用于数据挖掘和机器学习中的特征提取。
t-SNE的一个主要缺点是计算成本较高,因为它需要计算和优化大量的概率分布和梯度。此外,t-SNE的结果可能对初始化敏感,且不保证找到全局最优解。尽管如此,t-SNE仍然是数据可视化和理解高维数据结构的一个非常有用的工具。
一、基础篇
1. 目前主流的开源模型体系有哪些?
- Transformer体系:由Google提出的Transformer模型及其变体,如BERT、GPT等。
- PyTorch Lightning:一个基于PyTorch的轻量级深度学习框架,用于快速原型设计和实验。
- TensorFlow Model Garden:TensorFlow官方提供的一系列预训练模型和模型架构。
- Hugging Face Transformers:一个流行的开源库,提供了大量预训练模型和工具,用于NLP任务。
2. prefix LM 和 causal LM 区别是什么?
- prefix LM(前缀语言模型):在输入序列的开头添加一个可学习的任务相关的前缀,然后使用这个前缀和输入序列一起生成输出。这种方法可以引导模型生成适应特定任务的输出。
- causal LM(因果语言模型):也称为自回归语言模型,它根据之前生成的 token 预测下一个 token。在生成文本时,模型只能根据已经生成的部分生成后续部分,不能访问未来的信息。
3. 涌现能力是啥原因?
涌现能力(Emergent Ability)是指模型在训练过程中突然表现出的新的、之前未曾预料到的能力。这种现象通常发生在大型模型中,原因是大型模型具有更高的表示能力和更多的参数,可以更好地捕捉数据中的模式和关联。随着模型规模的增加,它们能够自动学习到更复杂、更抽象的概念和规律,从而展现出涌现能力。
4. 大模型LLM的架构介绍?
大模型LLM(Large Language Models)通常采用基于Transformer的架构。Transformer模型由多个编码器或解码器层组成,每个层包含多头自注意力机制和前馈神经网络。这些层可以并行处理输入序列中的所有位置,捕获长距离依赖关系。大模型通常具有数十亿甚至数千亿个参数,可以处理大量的文本数据,并在各种NLP任务中表现出色。
前馈神经网络(Feedforward Neural Network)是一种最基础的神经网络类型,它的信息流动是单向的,从输入层经过一个或多个隐藏层,最终到达输出层。在前馈神经网络中,神经元之间的连接不会形成闭环,这意味着信号在前向传播过程中不会回溯。
前馈神经网络的基本组成单元是神经元,每个神经元都会对输入信号进行加权求和,然后通过一个激活函数产生输出。激活函数通常是非线性的,它决定了神经元的输出是否应该被激活,从而允许网络学习复杂和非线性的函数。
前馈神经网络在模式识别、函数逼近、分类、回归等多个领域都有应用。例如,在图像识别任务中,网络的输入层节点可能对应于图像的像素值,而输出层节点可能代表不同类别的概率分布。
训练前馈神经网络通常涉及反向传播(Backpropagation)算法,这是一种有效的学习算法,通过计算输出层的误差,并将这些误差信号沿网络反向传播,以调整连接权重。通过多次迭代这个过程,网络可以逐渐学习如何减少输出误差,从而实现对输入数据的正确分类或回归。
在设计和训练前馈神经网络时,需要考虑多个因素,包括网络的层数、每层的神经元数目、激活函数的选择、学习速率、正则化策略等,这些都对网络的性能有重要影响。
5. 你比较关注哪些主流的开源大模型?
- GPT系列:由OpenAI开发的生成式预训练模型,如GPT-3。
- BERT系列:由Google开发的转换式预训练模型,如BERT、RoBERTa等。
- T5系列:由Google开发的基于Transformer的编码器-解码器模型,如T5、mT5等。
6. 目前大模型模型结构都有哪些?
- Transformer:基于自注意力机制的模型,包括编码器、解码器和编码器-解码器结构。
- GPT系列:基于自注意力机制的生成式预训练模型,采用解码器结构。
- BERT系列:基于自注意力机制的转换式预训练模型,采用编码器结构。
- T5系列:基于Transformer的编码器-解码器模型。
7. prefix LM 和 causal LM、encoder-decoder 区别及各自有什么优缺点?
- prefix LM:通过在输入序列前添加可学习的任务相关前缀,引导模型生成适应特定任务的输出。优点是可以减少对预训练模型参数的修改,降低过拟合风险;缺点是可能受到前缀表示长度的限制,无法充分捕捉任务相关的信息。
- causal LM:根据之前生成的 token 预测下一个 token,可以生成连贯的文本。优点是可以生成灵活的文本,适应各种生成任务;缺点是无法访问未来的信息,可能生成不一致或有误的内容。
- encoder-decoder:由编码器和解码器组成,编码器将输入序列编码为固定长度的向量,解码器根据编码器的输出生成输出序列。优点是可以处理输入和输出序列不同长度的任务,如机器翻译;缺点是模型结构较为复杂,训练和推理计算量较大。
8. 模型幻觉是什么?业内解决方案是什么?
模型幻觉是指模型在生成文本时产生的不准确、无关或虚构的信息。这通常发生在模型在缺乏足够信息的情况下进行推理或生成时。业内的解决方案包括:
- 使用更多的数据和更高质量的训练数据来提高模型的泛化和准确性。
- 引入外部知识源,如知识库或事实检查工具,以提供额外的信息和支持。
- 强化模型的推理能力和逻辑推理,使其能够更好地处理复杂问题和避免幻觉。
9. 大模型的Tokenizer的实现方法及原理?
大模型的Tokenizer通常使用字节对编码(Byte-Pair Encoding,BPE)算法。BPE算法通过迭代地将最频繁出现的字节对合并成新的符号,来构建一个词汇表。在训练过程中,模型会学习这些符号的嵌入表示。Tokenizer将输入文本分割成符号序列,然后将其转换为模型可以处理的数字表示。这种方法可以有效地处理大量文本数据,并减少词汇表的规模。
10. ChatGLM3 的词表实现方法?
ChatGLM3使用了一种改进的词表实现方法。它首先使用字节对编码(BPE)算法构建一个基本的词表,然后在训练过程中通过不断更新词表来引入新的词汇。具体来说,ChatGLM3在训练过程中会根据输入数据动态地合并出现频率较高的字节对,从而形成新的词汇。这样可以有效地处理大量文本数据,并减少词汇表的规模。同时,ChatGLM3还使用了一种特殊的词表分割方法,将词表分为多个片段,并在训练过程中逐步更新这些片段,以提高模型的泛化能力和适应性。
11. GPT3、LLAMA、ChatGLM 的Layer Normalization 的区别是什么?各自的优缺点是什么?
- GPT3:采用了Post-Layer Normalization(后标准化)的结构,即先进行自注意力或前馈神经网络的计算,然后进行Layer Normalization。这种结构有助于稳定训练过程,提高模型性能。
- LLAMA:采用了Pre-Layer Normalization(前标准化)的结构,即先进行Layer Normalization,然后进行自注意力或前馈神经网络的计算。这种结构有助于提高模型的泛化能力和鲁棒性。
- ChatGLM:采用了Post-Layer Normalization的结构,类似于GPT3。这种结构可以提高模型的性能和稳定性。
12. 大模型常用的激活函数有哪些?
- ReLU(Rectified Linear Unit):一种简单的激活函数,可以解决梯度消失问题,加快训练速度。
- GeLU(Gaussian Error Linear Unit):一种改进的ReLU函数,可以提供更好的性能和泛化能力。
- Swish:一种自门控激活函数,可以提供非线性变换,并具有平滑和非单调的特性。
13. Multi-query Attention 与 Grouped-query Attention 是否了解?区别是什么?
Multi-query Attention和Grouped-query Attention是两种不同的注意力机制变种,用于改进和扩展传统的自注意力机制。
- Multi-query Attention:在Multi-query Attention中,每个查询可以与多个键值对进行交互,从而捕捉更多的上下文信息。这种机制可以提高模型的表达能力和性能,特别是在处理长序列或复杂关系时。
- Grouped-query Attention:在Grouped-query Attention中,查询被分成多个组,每个组内的查询与对应的键值对进行交互。这种机制可以减少计算复杂度,提高效率,同时仍然保持较好的性能。
14. 多模态大模型是否有接触?落地案例?
多模态大模型是指可以处理和理解多种模态数据(如文本、图像、声音等)的模型。落地案例,例如:
- OpenAI的DALL-E和GPT-3:DALL-E是一个可以生成图像的模型,而GPT-3可以处理和理解文本。两者结合可以实现基于文本描述生成图像的功能。
- Google的Multimodal Transformer:这是一个可以同时处理文本和图像的模型,用于各种多模态任务,如图像字幕生成、视觉问答等。
二、大模型(LLMs)进阶
1. llama 输入句子长度理论上可以无限长吗?
LLaMA(Large Language Model Adaptation)模型的输入句子长度受到硬件资源和模型设计的限制。理论上,如果硬件资源足够,模型可以处理非常长的输入句子。然而,实际上,由于内存和处理能力的限制,输入句子长度通常是有限制的。在实际应用中,开发者会根据具体需求和硬件配置来确定合适的输入句子长度。
2. 什么是 LLMs 复读机问题?
LLMs 复读机问题是指在某些情况下,大型语言模型在生成文本时会重复之前已经生成的内容,导致生成的文本缺乏多样性和创造性。
3. 为什么会出现 LLMs 复读机问题?
LLMs 复读机问题可能由多种因素引起,包括模型训练数据中的重复模式、模型在处理长序列时的注意力机制失效、或者模型在生成文本时对过去信息的过度依赖等。
4. 如何缓解 LLMs 复读机问题?
- 数据增强:通过增加训练数据的多样性和复杂性,减少重复模式的出现。
- 模型改进:改进模型的结构和注意力机制,使其更好地处理长序列和避免过度依赖过去信息。
- 生成策略:在生成文本时采用多样化的策略,如抽样生成或引入随机性,以增加生成文本的多样性。
5. LLMs 复读机问题
6. llama 系列问题
7. 什么情况用Bert模型,什么情况用LLaMA、ChatGLM类大模型?
BERT 模型通常用于需要理解文本深层语义的任务,如文本分类、命名实体识别等。LLaMA 和 ChatGLM 类大模型则适用于需要生成文本或进行更复杂语言理解的任务,如对话系统、文本生成等。选择哪种模型取决于任务的需求和可用资源。
8. 各个专业领域是否需要各自的大模型来服务?
不同的专业领域需要特定的大模型来更好地服务。专业领域的大模型可以针对特定领域的语言和知识进行优化,提供更准确和相关的回答和生成文本。
9. 如何让大模型处理更长的文本?
- 使用模型架构,如Transformer,它可以有效地处理长序列。
- 使用内存机制,如外部记忆或缓存,来存储和检索长文本中的信息。
- 使用分块方法,将长文本分割成更小的部分,然后分别处理这些部分。
10. 大模型参数微调、训练、推理
11. 如果想要在某个模型基础上做全参数微调,究竟需要多少显存?
全参数微调(Full Fine-Tuning)通常需要大量的显存,因为这种方法涉及到更新模型的所有参数。显存的需求取决于模型的规模、批量大小、以及使用的硬件。例如,对于大型模型如GPT-3,可能需要多个GPU甚至TPU来分配显存,每个GPU或TPU可能需要几十GB的显存。在实际操作中,需要进行试错法来确定合适的批量大小和硬件配置。
12. 为什么SFT之后感觉LLM傻了?
指令微调(SFT,Supervised Fine-Tuning)之后感觉LLM“傻了”,可能是因为微调过程中出现了一些问题,例如过拟合、数据质量不佳、或者微调的强度不够。过拟合可能导致模型在训练数据上表现良好,但在未见过的数据上表现不佳。数据质量不佳可能导致模型学到了错误的模式或偏见。微调强度不够可能导致模型没有充分适应新的任务。
13. SFT 指令微调数据如何构建?
- 收集或生成与特定任务相关的指令和数据对,其中指令是描述任务或要求的文本,数据是对应的输入输出示例。
- 清洗和预处理数据,以确保数据的质量和一致性。
- 根据任务需求,对数据进行增强,如使用数据增强技术生成更多的训练样本。
- 将数据格式化为模型训练所需的格式,例如,对于语言模型,通常需要将文本转化为模型可以理解的数字编码。
14. 领域模型Continue PreTrain数据选取?
领域模型继续预训练(Continue Pre-Training)的数据选取应该基于领域内的文本特点和应用需求。通常,需要选取大量、高质量、多样化的领域文本数据。数据可以来自专业文献、行业报告、在线论坛、新闻文章等。数据选取时应该注意避免偏见和不平衡,确保数据能够全面地代表领域内的知识和语言使用。
15. 领域数据训练后,通用能力往往会有所下降,如何缓解模型遗忘通用能力?
- 多任务学习:在训练过程中同时包含领域内和通用的任务,使模型能够同时学习领域特定的和通用的知识。
- 控制微调强度:通过调整微调的学习率或训练轮数来控制模型对领域数据的适应程度。
- 定期回炉:在领域数据训练后,定期使用通用数据进行回炉训练,以保持模型的通用能力。
16. 领域模型Continue PreTrain ,如何让模型在预训练过程中就学习到更多的知识?
- 数据增强:使用数据增强技术如回译、掩码语言模型等来生成更多的训练样本。
- 知识注入:将领域特定的知识以文本、结构化数据或知识图谱的形式注入到预训练过程中。
- 多模态学习:如果适用,可以使用多模态数据(如文本和图像)进行预训练,以丰富模型的知识表示。
17. 进行SFT操作的时候,基座模型选用Chat还是Base?
在进行指令微调(SFT)操作时,选择基座模型(Chat或Base)取决于具体任务的需求和模型的性能。通常,如果任务需要生成对话或交互式响应,可以选择对话优化的模型(Chat)。如果任务更注重理解和生成文本的能力,可以选择基础模型(Base)。在实际应用中,可能需要根据实验结果和模型性能来选择最合适的基座模型。
18. 领域模型微调 指令&数据输入格式要求?
领域模型微调的指令和数据输入格式要求取决于所使用的模型和框架。一般来说,指令应该是清晰、具体的,能够指导模型完成特定的任务。数据输入格式通常需要与模型的输入接口相匹配,例如,对于文本模型,数据通常需要是字符串格式,并且可能需要经过特定的预处理,如分词、编码等。
19. 领域模型微调 领域评测集构建?
构建领域模型微调的领域评测集时,应该确保评测集能够全面、准确地反映领域内的任务需求和性能指标。通常,需要从领域内的真实数据中收集或生成评测样本,并确保样本的多样性和代表性。此外,可以根据任务需求设计定制的评价指标,以评估模型在领域内的性能。
20. 领域模型词表扩增是不是有必要的?
领域模型词表扩增通常是有必要的,尤其是当领域内有大量的专业术语或特定词汇时。词表扩增可以帮助模型更好地理解和生成领域内的文本,提高模型的领域适应性。然而,词表扩增也需要谨慎进行,以避免引入过多的噪音或不相关的词汇。
21. 如何训练自己的大模型?
- 选择合适的预训练目标和任务:确定模型将学习哪些通用的语言知识,以及针对哪些特定任务进行优化。
- 收集和准备数据:收集大量、多样化的数据,包括通用数据和特定领域的数据,进行清洗和预处理。
- 选择模型架构:选择一个适合的模型架构,如Transformer,并确定模型的规模和层数。
- 定义训练流程:设置训练参数,如学习率、批量大小、训练轮数等,并选择合适的优化器和损失函数。
- 训练模型:使用准备好的数据和训练流程开始训练模型,监控训练过程中的性能和资源使用。
- 评估和调优:在训练过程中定期评估模型的性能,并根据需要调整训练参数和模型架构。
- 微调和优化:在模型达到一定的性能后,进行微调以适应特定的应用场景和任务需求。
22. 训练中文大模型有啥经验?
- 使用大量高质量的中文数据,包括文本、对话、新闻、社交媒体帖子等。
- 考虑语言的特点,如词序、语法结构、多义性等,并设计相应的预训练任务。
- 使用适合中文的语言模型架构,如BERT或GPT,并进行适当的调整以优化性能。
- 考虑中文的特殊字符和标点,确保模型能够正确处理这些字符。
- 进行多任务学习,同时训练多个相关任务,以提高模型的泛化能力。
23. 指令微调的好处?
- 提高模型在特定任务上的性能,使其能够更好地理解和执行指令。
- 通过指令和示例数据的结合,使模型能够学习到更具体、更实用的知识。
- 减少了模型对大规模标注数据的依赖,通过少量的指令和示例数据就能进行有效的微调。
- 可以通过不同的指令和示例数据组合,快速适应不同的任务和应用场景。
24. 预训练和微调哪个阶段注入知识的?
在预训练阶段,模型通过大量的无监督数据学习通用的语言知识和模式。在微调阶段,模型通过与特定任务相关的监督数据学习特定领域的知识和任务特定的模式。因此,知识注入主要发生在微调阶段。
25. 想让模型学习某个领域或行业的知识,是应该预训练还是应该微调?
为了让模型学习某个领域或行业的知识,通常建议先进行预训练,以学习通用的语言知识和模式。预训练可以帮助模型建立强大的语言表示,并提高模型的泛化能力。然后,可以通过微调来注入特定领域或行业的知识,使模型能够更好地适应特定的任务和应用场景。
26. 多轮对话任务如何微调模型?
- 收集多轮对话数据,包括用户查询、系统回复、以及可能的中间交互。
- 对数据进行预处理,如分词、编码等,使其适合模型输入格式。
- 设计多轮对话的微调目标,如序列到序列学习、生成式对话等。
- 微调模型,使其能够生成连贯、自然的对话回复,并考虑到对话上下文和用户意图。
27. 微调后的模型出现能力劣化,灾难性遗忘是怎么回事?
微调后的模型出现能力劣化,灾难性遗忘可能是因为模型在微调过程中学习到了过多的特定任务的知识,而忽略了通用的语言知识。这可能导致模型在训练数据上表现良好,但在未见过的数据上表现不佳。为了解决这个问题,可以采取一些措施,如多任务学习、控制微调强度、定期使用通用数据进行回炉训练等。
28. 微调模型需要多大显存?
微调模型需要的显存取决于模型的规模、任务复杂度、数据量等因素。一般来说,微调模型需要的显存通常比预训练模型少,因为微调涉及到更新的参数较少。然而,具体需要的显存仍然需要根据实际情况进行评估和调整。
29. 大模型LLM进行SFT操作的时候在学习什么?
- 特定领域的语言模式和知识,包括专业术语、行业特定用语等。
- 针对特定任务的生成策略和响应模式。
- 对话上下文中的连贯性和逻辑性,对于多轮对话任务尤其重要。
- 指令理解和执行能力,使模型能够更准确地理解和执行用户的指令。
30. 预训练和SFT操作有什么不同?
预训练和SFT操作的主要区别在于目标和数据集。预训练通常是在大规模的无标签数据集上进行的,目的是让模型学习到通用的语言表示和模式。这个过程不需要人工标注数据,而是通过模型自己从数据中学习。SFT则是在有标签的数据集上进行的,目的是让模型适应特定的任务或领域。这个过程需要人工标注数据,以确保模型能够学习到正确的任务特定的模式和知识。
31. 样本量规模增大,训练出现OOM错,怎么解决?
当样本量规模增大时,训练出现OOM(Out of Memory)错误可能是由于显存不足导致的。为了解决这个问题,可以尝试以下方法:
- 增加训练设备的显存,如使用更高性能的GPU或增加GPU数量。
- 调整批量大小,减少每次训练时处理的样本数量。
- 使用模型并行或数据并行技术,将模型或数据分片到多个设备上进行训练。
- 使用动态批处理,根据可用显存动态调整批量大小。
32. 大模型LLM进行SFT 如何对样本进行优化?
- 数据增强:通过对原始数据进行转换,如文本回译、添加噪声等,生成更多的训练样本。
- 样本选择:选择与特定任务最相关的样本进行训练,以提高训练效率和性能。
- 样本权重:根据样本的难易程度或重要性为样本分配不同的权重,以优化训练过程。
- 平衡采样:在训练过程中,确保每个类别或子任务都有足够的样本被训练到。
33. 模型参数迭代实验步骤?
模型参数迭代实验是指在训练过程中,对模型的参数进行迭代调整和优化,以提高模型的性能。这通常涉及以下步骤:
- 选择一组初始参数。
- 在训练过程中,定期评估模型的性能。
- 根据评估结果,调整模型的参数,如学习率、批量大小、正则化参数等。
- 重复评估和调整参数,直到模型的性能达到预期的目标。
34. 为什么需要进行参选微调?参数微调的原因有哪些?
参数微调是指只对模型的一部分参数进行更新,以适应特定的任务或领域。进行参数微调的原因包括:
- 提高计算效率:参数微调通常比全量微调需要更少的计算资源,因为只有部分参数需要更新。
- 减少过拟合风险:只更新与特定任务相关的参数,可以减少模型对训练数据的过度依赖,降低过拟合的风险。
- 提高泛化能力:参数微调可以使模型在保持通用语言能力的同时,适应特定的任务需求。
35. 模型参数微调的方式有那些?你最常用哪些方法?
- 权重共享:在模型中,将部分参数设置为共享,这些参数同时用于多个任务或领域。
- 参数掩码:在模型中,将部分参数设置为不可训练,这些参数保持预训练时的值不变。
- 参数分解:将大型的参数矩阵分解为多个小型矩阵,只更新其中的部分矩阵。
- 参数共享微调:在模型中,将部分参数设置为共享,这些参数用于多个相关任务。
36. prompt tuning 和 prefix tuning 在微调上的区别是什么?
Prompt Tuning和Prefix Tuning都是参数高效的微调方法,它们通过在模型输入中添加特定的提示或前缀来引导模型生成适应特定任务的输出。区别在于:
- Prompt Tuning:在输入序列的末尾添加可学习的提示,提示可以是几个单词或短语,用于指导模型生成特定的输出。
- Prefix Tuning:在输入序列的开头添加可学习的连续前缀表示,前缀表示包含了任务特定的信息,用于引导模型生成适应特定任务的输出。
37. LLaMA-adapter 如何实现稳定训练?
LLaMA-adapter 是一种参数高效的微调方法,它通过在预训练模型的每个Transformer层中添加小型适配器模块来实现特定任务的适应。为了实现稳定训练,可以采取以下措施:
- 适配器初始化:使用预训练模型的参数作为适配器模块的初始化,以保持模型的稳定性。
- 适配器正则化:使用正则化技术,如权重衰减或dropout,来减少适配器模块的过拟合风险。
- 逐步学习:逐步调整适配器模块的参数,避免参数更新的幅度过大。
- 适配器优化:选择合适的优化器和训练策略,如使用较小的学习率、较长的训练周期等,以实现稳定的训练过程。
38. LoRA 原理与使用技巧有那些?
LoRA(Low-Rank Adaptation)是一种参数高效的微调方法,它通过引入低秩分解来减少需要更新的参数数量。LoRA的工作原理是将预训练模型的注意力矩阵或前馈网络矩阵分解为两个低秩矩阵的乘积,其中这两个低秩矩阵被视为可学习的任务特定参数。
使用LoRA的技巧包括:
- 适配器初始化:使用预训练模型的参数作为LoRA适配器模块的初始化,以保持模型的稳定性。
- 低秩分解:选择合适的低秩分解方法,如奇异值分解(SVD)或随机矩阵分解,以实现低秩分解。
- 逐步学习:逐步调整LoRA适配器模块的参数,避免参数更新的幅度过大。
- 适配器正则化:使用正则化技术,如权重衰减或dropout,来减少LoRA适配器模块的过拟合风险。
39. LoRA 微调优点是什么?
- 参数高效:LoRA只更新少量的低秩矩阵,相比全量微调,可以显著减少需要更新的参数数量。
- 计算效率:由于只更新少量的低秩矩阵,LoRA可以减少计算资源的需求,提高训练和推理的效率。
- 模型稳定性:LoRA适配器模块可以保持预训练模型的稳定性,减少过拟合风险。
- 性能提升:LoRA微调可以在不牺牲太多性能的情况下实现参数高效的微调。
40. AdaLoRA 的思路是怎么样的?
AdaLoRA是一种自适应的LoRA方法,它可以根据任务的需求和模型的性能动态调整LoRA适配器模块的参数。AdaLoRA的思路是:
- 初始化LoRA适配器模块的参数,使用预训练模型的参数作为初始化。
- 在训练过程中,根据模型的性能和任务需求,动态调整LoRA适配器模块的参数。
- 通过调整LoRA适配器模块的参数,使模型能够更好地适应特定的任务需求。
41. LoRA 权重合入chatglm模型的方法?
- 在chatGLM模型的每个Transformer层中添加LoRA适配器模块。
- 使用预训练模型的参数作为LoRA适配器模块的初始化。
- 在训练过程中,更新LoRA适配器模块的参数,以适应特定的任务需求。
- 保持预训练模型的参数不变,避免对预训练模型产生负面影响。
42. P-tuning 讲一下?与 P-tuning v2 区别在哪里?优点与缺点?
P-tuning是一种参数高效的微调方法,它通过在模型输入中添加可学习的连续前缀来引导模型生成适应特定任务的输出。P-tuning v2是P-tuning的改进版本,它使用了更多的连续前缀表示来引导模型生成适应特定任务的输出。
P-tuning与P-tuning v2的区别在于:
- P-tuning:在输入序列的开头添加一个可学习的连续前缀,前缀的长度较短。
- P-tuning v2:在输入序列的开头添加多个可学习的连续前缀,前缀的长度较长。
P-tuning的优点是参数高效,计算资源需求较低,可以快速实现模型微调。P-tuning的缺点是可能受到前缀表示长度的限制,无法充分捕捉任务相关的信息。P-tuning v2通过使用更多的连续前缀,可以更充分地捕捉任务相关的信息,但可能需要更多的计算资源来更新多个前缀的参数。
43. 为什么SFT之后感觉LLM傻了?
SFT(Supervised Fine-Tuning)之后感觉LLM(Large Language Model)"傻了",可能是因为微调过程中出现了以下问题:
- 过拟合:模型可能过度适应训练数据,导致在新数据上的泛化能力下降。
- 数据质量:如果训练数据质量不高,模型可能学到了错误的模式或偏见。
- 微调强度:微调的强度可能不够,导致模型没有充分适应新的任务。在这种情况下,模型可能没有学习到足够的特定领域的知识,因此在执行相关任务时表现不佳。
44. 垂直领域数据训练后,通用能力往往会有所下降,如何缓解模型遗忘通用能力?
- 多任务学习:在训练过程中同时包含通用任务和领域特定任务,使模型能够同时学习通用和特定领域的知识。
- 控制微调强度:通过调整学习率、正则化参数等,控制模型对领域数据的适应程度。
- 定期回炉:在领域数据训练后,定期使用通用数据进行回炉训练,以保持模型的通用能力。
- 知识蒸馏:使用一个预训练的通用模型来指导领域模型,帮助模型保持通用知识。
45. 进行SFT操作的时候,基座模型选用Chat还是Base?
在进行SFT(Supervised Fine-Tuning)操作时,选择基座模型(Chat或Base)取决于具体任务的需求和模型的性能。通常,如果任务需要生成对话或交互式响应,可以选择对话优化的模型(Chat)。如果任务更注重理解和生成文本的能力,可以选择基础模型(Base)。在实际应用中,可能需要根据实验结果和模型性能来选择最合适的基座模型。
46. 领域模型词表扩增是不是有必要的?
领域模型词表扩增通常是有必要的,尤其是当领域内有大量的专业术语或特定词汇时。词表扩增可以帮助模型更好地理解和生成领域内的文本,提高模型的领域适应性。然而,词表扩增也需要谨慎进行,以避免引入过多的噪音或不相关的词汇。
47. 训练中文大模型的经验和方法?
- 使用大量高质量的中文数据,包括文本、对话、新闻、社交媒体帖子等。
- 考虑语言的特点,如词序、语法结构、多义性等,并设计相应的预训练任务。
- 使用适合中文的语言模型架构,如BERT或GPT,并进行适当的调整以优化性能。
- 考虑中文的特殊字符和标点,确保模型能够正确处理这些字符。
- 进行多任务学习,同时训练多个相关任务,以提高模型的泛化能力。
48. 模型微调用的什么模型?模型参数是多少?微调模型需要多大显存?
模型微调使用的模型和模型参数取决于具体任务的需求和可用资源。模型可以是任何预训练的语言模型,如BERT、GPT、LLaMA等,参数数量可以从几千万到数十亿不等。微调模型需要的显存取决于模型的规模、任务复杂度、数据量等因素。一般来说,微调模型需要的显存通常比预训练模型少,因为微调涉及到更新的参数较少。然而,具体需要的显存仍然需要根据实际情况进行评估和调整。
49. 预训练和SFT操作有什么不同?
预训练和SFT操作的主要区别在于目标和数据集。预训练通常是在大规模的无标签数据集上进行的,目的是让模型学习到通用的语言表示和模式。这个过程不需要人工标注数据,而是通过模型自己从数据中学习。SFT则是在有标签的数据集上进行的,目的是让模型适应特定的任务或领域。这个过程需要人工标注数据,以确保模型能够学习到正确的任务特定的模式和知识。
50. 训练一个通用大模型的流程有那些?
- 数据收集:收集大量的、多样化的、无标签的文本数据。
- 数据预处理:对收集的数据进行清洗、分词、编码等预处理步骤。
- 模型设计:选择合适的模型架构,如Transformer,并确定模型的规模和层数。
- 预训练目标:设计预训练任务,如语言建模、掩码语言模型、句子对齐等。
- 训练模型:使用预训练数据集和预训练目标开始训练模型。
- 评估性能:在预训练过程中定期评估模型的性能,并根据需要调整训练参数。
- 微调和优化:在预训练完成后,使用有标签的数据集进行微调,以适应特定的任务或领域。
51. DDO 与 DPO 的区别是什么?
DDO(Dual Data Objectives)和DPO(Dual Prompt Objectives)是两种不同的训练策略,用于提高大型语言模型的性能。
- DDO:在训练过程中,同时优化两个数据集的目标,一个是通用数据集,另一个是特定领域数据集。这样可以让模型同时学习通用知识和特定领域的知识,提高模型的泛化能力和领域适应性。
- DPO:在训练过程中,同时使用两个提示(prompt),一个是通用提示,另一个是特定领域提示。这样可以让模型在执行任务时,同时利用通用知识和特定领域的知识,提高模型在特定任务上的性能。
52. 是否接触过 embeding 模型的微调方法?
嵌入模型微调通常涉及调整模型中的嵌入层,以适应特定的任务或领域。这可能包括:
- 初始化:使用特定领域的数据来初始化嵌入层,以便更好地捕捉领域特定的信息。
- 调整:通过训练或优化嵌入层的参数,使其能够适应特定任务或领域的需求。
- 知识注入:将领域特定的知识以向量的形式注入到嵌入层中,以增强模型对领域知识的理解和应用。
53. 有哪些省内存的大语言模型训练/微调/推理方法?
- 模型剪枝:通过移除模型中的冗余结构和参数,减少模型的内存占用。
- 知识蒸馏:使用一个大型教师模型来指导一个小型学生模型,使学生模型能够学习到教师模型的知识,同时减少内存占用。
- 量化:将模型的权重和激活从浮点数转换为低精度整数,减少模型的内存占用和计算需求。
- 模型并行:将大型模型分割到多个设备上进行训练和推理,减少单个设备的内存需求。
- 数据并行:将训练数据分割到多个设备上,每个设备训练模型的一个副本,减少单个设备的内存需求。
- 动态批处理:根据可用内存动态调整批量大小,以适应内存限制。
54. 大模型(LLMs)评测有那些方法?如何衡量大模型的效果?
大模型(LLMs)的评测方法通常包括:
- 准确性:评估模型在特定任务上的预测准确性。
- 泛化能力:评估模型在未见过的数据上的表现。
- 计算效率:评估模型训练和推理的速度和资源需求。
- 安全性:评估模型在对抗性输入下的稳定性和鲁棒性。
- 多样性和创造性:评估模型生成文本的多样性和创造性。
- 人类评估:通过人工评估来衡量模型的性能,特别是在对话和生成任务中。
衡量大模型效果的方法包括:
- 自动评估指标:使用如BLEU、ROUGE、METEOR等自动评估指标来衡量模型的语言生成和理解能力。
- 任务特定的指标:使用任务特定的指标来衡量模型在特定任务上的性能,如准确率、F1分数等。
- 用户反馈:收集用户对模型生成内容的反馈,以评估模型的实际应用效果。
55. 如何解决三个阶段的训练(SFT->RM->PPO)过程较长,更新迭代较慢问题?
- 减少训练数据量:如果训练数据量过大,可以考虑减少数据量,以加快训练速度。
- 优化训练流程:优化训练流程,如使用更高效的训练算法、调整训练参数等,以加快训练速度。
- 并行训练:使用多GPU或多服务器并行训练模型,以加快训练速度。
- 提前停止:在训练过程中,如果模型性能不再提高,可以提前停止训练,以节省时间。
- 知识蒸馏:使用一个大型教师模型来指导一个小型学生模型,使学生模型能够快速学习到教师模型的知识。
56. 模型训练的数据集问题:一般数据集哪里找?
- 公开数据集:许多研究机构和组织会发布公开数据集,如IMDb、Wikipedia、Common Crawl等。
- 特定领域数据集:针对特定领域的数据集,如医疗、金融、法律等,通常需要从相关的专业文献、报告、论坛等渠道获取。
- 合成数据:通过自动化或半自动化方法生成数据,如文本合成、数据增强等。
- 用户生成数据:通过众包、调查、游戏等方式收集用户生成的数据。
- 商业数据:从商业公司或服务中获取数据,通常需要遵守相关的数据使用协议和隐私政策。
57. 为什么需要进行模型量化及原理?
模型量化是将模型中的权重和激活从高精度浮点数转换为低精度整数(如INT8、INT4、FP16等)的过程,目的是减少模型的大小、提高计算效率并降低内存需求。模型量化的原理在于,低精度数值格式可以提供足够的精度来保持模型性能,同时显著减少数值的位数,从而减少存储和计算资源的使用。
58. 大模型词表扩充的方法及工具?
大模型词表扩充的方法包括:
- 新增词汇:手动添加领域特定的术语和词汇到词表中。
- 数据驱动:通过分析大量文本数据自动识别和添加高频出现的词汇。
- 词汇映射:将特定领域的词汇映射到现有的词表中,或者创建新的词汇条目。
工具方面,一些流行的词表管理工具和库包括:
- Hugging Face Transformers:提供了一个预训练模型和词表管理的接口。
- SentencePiece:一个用于构建词汇表的工具,支持BPE和其他子词分割方法。
- Moses:一个开源的自然语言处理工具,包括用于词表构建和分词的工具。
59. 大模型应用框架及其功能?
大模型应用框架提供了一组工具和库,用于构建、训练和部署大型语言模型。这些框架通常包括以下功能:
- 模型加载和保存:支持加载预训练模型和保存微调后的模型。
- 数据处理:提供数据预处理、分词、编码等工具。
- 模型训练:支持模型训练、评估和调试。
- 模型部署:支持将模型部署到不同的环境和平台,如服务器、移动设备等。
- API接口:提供模型预测的API接口,方便集成到其他应用中。
一些流行的大模型应用框架包括:
- Hugging Face Transformers:一个流行的NLP研究工具,提供了大量预训练模型和工具。
- PyTorch:一个开源的深度学习框架,支持大型语言模型的训练和部署。
- TensorFlow:另一个流行的深度学习框架,也支持大型语言模型的训练和部署。
60. 搭建大模型应用遇到过那些问题?如何解决的?
搭建大模型应用时可能会遇到以下问题:
- 资源限制:计算资源不足,如显存不足、计算时间受限等。
- 模型稳定性:模型在训练或部署过程中出现不稳定的行为。
- 数据质量:训练数据质量不高,导致模型性能不佳。
- 模型部署:将模型部署到生产环境中的技术挑战。
解决这些问题的方法可能包括:
- 资源优化:使用更高效的训练算法、调整训练参数、使用模型并行或数据并行技术。
- 模型调试:使用调试工具和技术来分析模型行为,找出问题的根源。
- 数据处理:进行数据清洗、增强和预处理,以提高数据质量。
- 部署策略:选择合适的部署策略,如使用模型压缩技术、优化模型结构等。
61. 如何提升大模型的检索效果?
- 优化索引:使用更高效的索引结构,如倒排索引、BM25等。
- 特征工程:提取和利用有效的特征,如文本向量、词频等。
- 模型选择:选择合适的检索模型,如基于向量的相似度计算、基于排序的模型等。
- 训练策略:使用训练策略,如多任务学习、知识蒸馏等,来提高模型的性能。
- 评估指标:使用更准确的评估指标,如MAP、NDCG等,来衡量检索效果。
62. 是否了解上下文压缩方法?
上下文压缩是一种减少模型参数数量和计算复杂度的技术,同时尽量保持模型的性能。这种方法通常涉及:
- 模型剪枝:移除模型中的冗余结构和参数。
- 知识蒸馏:使用一个大型教师模型来指导一个小型学生模型,使学生模型能够学习到教师模型的知识。
- 权重共享:在模型中,将部分参数设置为共享,这些参数同时用于多个任务或领域。
- 低秩分解:将大型参数矩阵分解为多个小型矩阵,只更新其中的部分矩阵。
63. 如何实现窗口上下文检索?
窗口上下文检索是一种在给定文本片段的上下文中检索相关信息的方法。实现窗口上下文检索通常涉及以下步骤:
- 文本分块:将长文本分割成多个较小的文本块,这些文本块被称为窗口。
- 索引构建:为每个文本块构建索引,以便快速检索相关信息。
- 查询处理:将查询文本与索引中的文本块进行匹配,找到与查询最相关的文本块。
- 上下文检索:在找到的相关文本块中,检索与查询相关的信息。这可能涉及到计算文本块与查询的相似度,并根据相似度排序文本块。
- 结果生成:根据检索结果生成答案或摘要。
64. 开源的 RAG 框架有哪些,你比较了解?
RAG(Retrieval-Augmented Generation)是一种结合了检索和生成的框架,用于提高大型语言模型生成文本的质量和相关性。开源的RAG框架包括:
- Hugging Face's RAG:一个结合了检索增强生成的开源框架,支持多种任务,如文本生成、摘要等。
- Google's Retrieval-Augmented Generator(RAG)TensorFlow实现:一个基于TensorFlow的RAG实现,用于支持大规模的文本生成任务。
- Microsoft's RAG:一个结合了检索和生成的框架,用于支持多轮对话和知识密集型任务。
65. 大模型应用框架 LangChain 和 LlamaIndex 各自的优势有那些?
LangChain和LlamaIndex是大模型应用框架,它们提供了构建、训练和部署大型语言模型的工具和库。这些框架的优势包括:
- 易用性:提供了一组易于使用的工具和库,简化了大模型应用的开发和部署过程。
- 灵活性:支持多种模型架构和任务,能够适应不同的应用场景和需求。
- 高效性:提供了高效的训练和推理算法,减少了计算资源的需求。
- 集成性:与其他工具和框架具有良好的集成,如数据处理、模型评估等。
- 社区支持:拥有活跃的社区,提供了大量的教程、文档和讨论,帮助用户解决问题和提高技能。
66. 向量库有那些?各自优点与区别?
- TensorFlow:一个开源的深度学习框架,提供了向量操作和计算的支持。
- PyTorch:另一个流行的深度学习框架,也提供了向量操作和计算的支持。
- NumPy:一个用于数值计算的Python库,提供了向量操作和矩阵运算的支持。
- SciPy:基于NumPy的Python库,提供了用于科学计算的向量操作和函数。
这些向量库的优点包括:
- 高效性:提供了高效的向量操作和矩阵运算,能够快速处理大规模数据。
- 灵活性:支持多种数据类型和操作,能够适应不同的应用场景和需求。
- 社区支持:拥有活跃的社区,提供了大量的教程、文档和讨论,帮助用户解决问题和提高技能。
区别在于它们的设计哲学、API接口和使用场景。例如,TensorFlow和PyTorch都是深度学习框架,提供了全面的神经网络构建和训练功能,而NumPy和SciPy更专注于数值计算和科学计算。
66-1. 向量数据库有那些?各自优点与区别?
向量数据库是一种数据库,专门设计用于存储和查询向量数据,常用于机器学习和数据科学领域。向量数据库可以高效地处理高维空间数据的相似性搜索,这在图像识别、文本搜索、推荐系统等应用中非常重要。以下是一些流行的向量数据库及其优缺点:
1. Milvus
- 优点:Milvus 是一个开源的向量数据库,支持多种类型的向量索引,如IVF、HNSW、Flat等。它提供了可扩展的架构,可以处理大量数据,并支持云原生部署。
- 缺点:由于是较新的项目,社区和文档可能不如一些老牌数据库成熟。
2. Faiss
- 优点:Faiss 是由Facebook AI团队开发的高效相似性搜索和密集向量聚类库。它提供了多种向量索引算法,性能极高。
- 缺点:作为一个库而不是完整的数据库系统,Faiss 不提供完整的数据管理功能,需要用户自己集成到应用中。
3. Vespa
- 优点:Vespa 是由Yahoo开发的一个高性能分布式数据存储和查询系统,支持向量相似性搜索和实时数据摄入。
- 缺点:Vespa 的配置和使用相对复杂,可能需要较深的系统知识。
4. Pinecone
- 优点:Pinecone 是一个托管的向量数据库服务,易于设置和使用,提供了强大的相似性搜索功能。
- 缺点:作为一个商业服务,Pinecone的成本可能比开源解决方案要高。
5. Weaviate
- 优点:Weaviate 是一个开源的向量搜索引擎,支持多种数据类型,包括文本、图像和向量,并提供了易于使用的REST API。
- 缺点:相对于其他一些解决方案,Weaviate 可能还不够成熟,社区较小。
67. 使用外部知识数据库时需要对文档进行分块,如何科学的设置文档块的大小?
- 查询需求:根据查询的需求和上下文长度来确定文档块的大小。
- 检索效率:较小的文档块可以提高检索效率,但过小的块可能导致信息的碎片化。
- 存储和计算资源:考虑存储和计算资源的需求,确定文档块的大小以平衡效率和资源使用。
- 用户体验:确保文档块的大小适合用户的阅读和理解需求。
一种科学的方法是进行实验和评估,通过比较不同文档块大小对检索效果、效率和用户体验的影响,来确定最佳的分块大小。
68. LLMs 受到上下文长度的限制,如果检索到的文档带有太多噪声,该如何解决这样的问题?
- 上下文修剪:使用摘要或摘要生成技术来提取文档的关键部分,减少噪声。
- 知识蒸馏:使用一个大型教师模型来指导一个小型学生模型,使学生模型能够学习到教师模型的知识,从而提高模型的鲁棒性。
- 过滤和去噪:使用文本过滤和去噪技术,如文本清洗、去重、去除无关信息等,来减少噪声。
- 强化学习:通过强化学习训练模型,使其能够自动识别和忽略噪声信息,专注于相关和有用的信息。
- 数据增强:通过对原始数据进行转换,如文本回译(将文本翻译成另一种语言再翻译回来)、添加噪声等,生成更多的训练样本,从而提高模型对噪声的鲁棒性。
知识蒸馏是一种模型压缩技术,其中一个大型的、表现良好的模型(教师模型)被用来训练一个小型的模型(学生模型)。这个过程涉及到将教师模型的知识转移到学生模型中,通常通过模仿教师模型的输出或中间层的表示。学生模型因此能够学习到如何处理噪声,同时保持较小的模型大小,这有助于在有限的上下文长度内工作。
69. RAG(检索增强生成)对于大模型来说,有什么好处?
- 提高生成质量:通过结合检索到的相关信息,RAG可以帮助大型语言模型生成更准确、更相关和更高质量的文本。
- 增强上下文关联性:检索到的信息可以为模型提供更多的上下文信息,使生成的文本更加符合上下文语境。
- 提高模型鲁棒性:通过结合检索到的信息,模型可以更好地处理不完整或噪声的输入,提高模型的鲁棒性。
- 减少训练数据需求:RAG可以通过检索相关信息来增强模型的知识,从而减少对大规模标注数据的依赖。
- 提高模型泛化能力:RAG可以帮助模型学习到更广泛的知识,提高模型的泛化能力,使其能够更好地适应不同的任务和领域。
70. Self-attention的公式及参数量?为什么用多头?为什么要除以根号d?
Self-attention 模型在对当前位置的信息进行编码时,会过度的将注意力集中于自身的位置,因此作者提出了通过多头注意力机制来解决这一问题。同时,使用多头注意力机制还能够给予注意力层的输出包含有不同子空间中的编码表示信息,从而增强模型的表达能力。
这是因为点积的数量级增长很大,因此将 softmax 函数推向了梯度极小的区域。
Self-attention(自注意力)机制是Transformer模型的核心组成部分,它允许模型在处理序列数据时,为序列中的每个元素(如词或标记)分配不同的注意力权重,从而捕捉序列内的依赖关系。
Self-attention的基本公式如下:
1. **计算Query(Q)、Key(K)和Value(V)**:
这些矩阵是通过将输入序列的嵌入(或隐藏状态)与三个不同的权重矩阵(Wq、Wk、Wv)相乘得到的。这三个权重矩阵是模型需要学习的参数。
- Q = X * Wq
- K = X * Wk
- V = X * Wv
其中,X是输入序列的嵌入矩阵,维度为NXD ,N是序列长度,D是嵌入维度。
2. **计算注意力得分**:
使用Query和Key计算注意力得分,这反映了序列中每个元素对其他元素的重要性。
- 得分 = Q * K^T
3. **应用softmax函数**:
将得分通过softmax函数转换为概率分布,确保所有注意力权重的总和为1。
- 概率分布 = softmax(得分 / √D)
4. **计算加权的Value**:
将Value与softmax得到的概率分布相乘,得到加权后的Value,这是考虑了序列中其他元素的上下文信息的新表示。
- 加权Value = 概率分布 * V
5. **输出**:
将加权Value相加,得到最终的输出,这是序列中每个元素的上下文表示。
- 输出 = 加权Value之和
参数量的计算:
- 每个权重矩阵(Wq、Wk、Wv)的参数量为DXD ,因此总共有3个权重矩阵,参数量为3XD2 。
为什么用多头(Multi-Head)注意力:
- 多头注意力允许模型在不同的表示子空间中学习信息,这样可以让模型同时关注不同的信息维度。每个头学习到的信息可以独立地编码输入序列的不同方面,然后将这些信息综合起来,得到更丰富的表示。
为什么要除以根号D:
- 将得分除以根号D(得分归一化)可以防止内积过大导致softmax函数梯度变得非常小,这有助于数值稳定性,使得学习过程更加稳定。此外,它还可以看作是一种缩放因子,帮助模型在不同维度上保持一致的性能。
三、大模型(LLMs)LangChain
1. 什么是 LangChain?
LangChain 是一个用于构建和运行大型语言模型应用的开源框架。它提供了一套工具和组件,帮助开发者将大型语言模型(如 GPT-3)与其他工具和API结合,以完成更复杂的任务。
2. LangChain 包含哪些核心概念?
- Components: 可重用的模块,例如API调用、数据库查询等。
- Chains: 将多个Components链接在一起以完成特定任务的流程。
- Prompt Templates: 用于指导语言模型生成输出的文本模板。
- Output Parsers: 解析语言模型输出的工具。
- Indexes and Retrievers: 用于存储和检索信息的索引和数据检索器。
- Agents and Toolkits: 提供特定领域功能的代理和工具集。
3. 什么是 LangChain Agent?
LangChain Agent是一种可以执行一系列操作以完成复杂任务的程序。它可以根据给定的输入和上下文,选择合适的工具和策略来生成响应或执行操作。
4. 如何使用 LangChain?
- 定义Components:创建或集成各种API和工具。
- 构建Chains:将Components组合成完成特定任务的流程。
- 设置Prompt Templates:定义用于指导语言模型的文本模板。
- 配置Output Parsers:解析和提取语言模型的输出。
- 部署和运行:将构建的应用部署到服务器或云平台,并进行测试和优化。
5. LangChain 支持哪些功能?
- 集成和调用外部API。
- 查询和操作数据库。
- 文本生成和编辑。
- 信息检索和问答。
- 多步骤任务执行和决策。
6. 什么是 LangChain model?
LangChain model指的是在LangChain框架中使用的大型语言模型,如GPT-3或类似的模型。这些模型通常用于生成文本、回答问题或执行特定的语言任务。
7. LangChain 包含哪些特点?
- 开源和可扩展:易于集成和扩展新功能。
- 模块化和可重用:Components和Chains可以重用和组合。
- 灵活和可定制:可以自定义Prompt Templates和Output Parsers。
- 支持多种语言模型:可以集成和使用不同的语言模型。
8. LangChain 如何使用?
- 定义Components:创建或集成各种API和工具。
- 构建Chains:将Components组合成完成特定任务的流程。
- 设置Prompt Templates:定义用于指导语言模型的文本模板。
- 配置Output Parsers:解析和提取语言模型的输出。
- 部署和运行:将构建的应用部署到服务器或云平台,并进行测试和优化。
9. LangChain 存在哪些问题及方法方案?
- 低效的令牌使用问题:可以通过优化Prompt Templates和减少不必要的API调用来解决。
- 文档的问题:可以通过改进文档和提供更多的示例来帮助开发者理解和使用LangChain。
- 太多概念容易混淆:可以通过提供更清晰的解释和更直观的API设计来解决。
- 行为不一致并且隐藏细节问题:可以通过提供更一致和透明的API和行为来解决。
- 缺乏标准的可互操作数据类型问题:可以通过定义和使用标准的数据格式和协议来解决。
低效的令牌使用问题:
- 在语言模型应用中,令牌是模型处理文本的单位,通常与成本挂钩。如果Prompt Templates设计不当或API调用频繁,可能会导致令牌的浪费,增加成本。
- 解决方案:优化Prompt Templates,确保它们尽可能高效地传达信息,减少冗余。同时,减少不必要的API调用,例如通过批量处理数据或合并多个请求。
文档的问题:
- 如果LangChain的文档不清晰或不完整,开发者可能难以理解如何使用框架,或者可能无法充分利用其功能。
- 解决方案:改进文档的质量,提供详细的API参考、教程和最佳实践指南。增加更多的示例代码和应用场景,帮助开发者更快地上手。
太多概念容易混淆:
- LangChain可能引入了许多新的概念和抽象,对于新用户来说,这可能难以理解和区分。
- 解决方案:提供清晰的解释和定义,使用户能够理解每个概念的目的和作用。设计更直观的API,使其易于理解和使用。
行为不一致并且隐藏细节问题:
- 如果API的行为不一致,开发者可能难以预测其结果,这会导致错误和混淆。隐藏细节可能会让开发者难以调试和优化他们的应用。
- 解决方案:确保API的行为一致,并提供清晰的错误消息和文档。避免隐藏太多细节,而是提供适当的抽象级别,同时允许高级用户访问底层实现。
缺乏标准的可互操作数据类型问题:
- 如果LangChain没有定义和使用标准的数据格式和协议,那么在不同的系统和服务之间进行数据交换可能会很困难。
- 解决方案:定义和使用标准的数据格式(如JSON、CSV)和协议(如REST、gRPC),以确保不同组件和服务之间的互操作性。
10. LangChain 替代方案?
LangChain的替代方案包括其他用于构建和运行大型语言模型应用的开源框架,例如Hugging Face的Transformers库、OpenAI的GPT-3 API等。
11. LangChain 中 Components and Chains 是什么?
Components是可重用的模块,例如API调用、数据库查询等。Chains是将多个Components链接在一起以完成特定任务的流程。
12. LangChain 中 Prompt Templates and Values 是什么?
Prompt Templates是用于指导语言模型生成输出的文本模板。Values是填充Prompt Templates中的变量的实际值。
13. LangChain 中 Example Selectors 是什么?
Example Selectors是从一组示例中选择一个或多个示例的工具。它们可以用于提供上下文或示例,以帮助语言模型生成更准确的输出。
- 上下文关联:当模型需要根据特定的上下文或场景生成回答时,Example Selectors可以帮助选择与当前上下文最相关的示例。
- 数据过滤:在处理大量数据时,Example Selectors可以根据特定的标准和条件过滤数据,以便模型仅处理最相关的信息。
- 个性化回答:Example Selectors可以根据用户的需求和偏好选择示例,从而生成更加个性化的回答。
14. LangChain 中 Output Parsers 是什么?
Output Parsers是解析和提取语言模型输出的工具。它们可以将语言模型的输出转换为更结构化和有用的形式。
15. LangChain 中 Indexes and Retrievers 是什么?
Indexes and Retrievers是用于存储和检索信息的索引和数据检索器。它们可以用于提供上下文或从大量数据中检索相关信息。
16. LangChain 中 Chat Message History 是什么?
Chat Message History是存储和跟踪聊天消息历史的工具。它可以用于维护对话的上下文,以便在多轮对话中提供连贯的响应。
17. LangChain 中 Agents and Toolkits 是什么?
Agents and Toolkits是提供特定领域功能的代理和工具集。Agents是一系列可以执行的操作,而Toolkits则是为这些操作提供接口和实现的工具集合。
18. LangChain 如何调用 LLMs 生成回复?
LangChain通过定义好的Prompt Templates向LLMs发送指令,LLMs根据这些指令生成文本回复。LangChain还可以使用Output Parsers来解析和格式化LLMs的输出。
19. LangChain 如何修改提示模板?
在LangChain中,可以通过修改Prompt Templates的文本内容或变量来定制提示。
20. LangChain 如何链接多个组件处理一个特定的下游任务?
LangChain通过构建Chains来链接多个Components。每个Component执行一个特定的任务,然后将输出传递给链中的下一个Component,直到完成整个任务。
21. LangChain 如何Embedding & vector store?
LangChain可以使用嵌入函数将文本数据转换为向量,并将这些向量存储在向量存储库中。这样做的目的是为了能够高效地检索和查询文本数据。
四、大模型分布式训练
1. 大模型进行训练,用的是什么框架?
- TensorFlow是一个由Google开发的开源机器学习框架,它提供了强大的分布式训练功能。TensorFlow支持数据并行、模型并行和分布式策略等多种分布式训练方法。
- PyTorch是一个由Facebook的AI研究团队开发的流行的开源机器学习库。它提供了分布式包(torch.distributed),支持分布式训练,并且可以通过使用torch.nn.parallel.DistributedDataParallel(DDP)或torch.nn.DataParallel来实现数据并行。
- Horovod是由Uber开源的分布式训练框架,它基于MPI(Message Passing Interface)并提供了一种简单的方法来并行化TensorFlow、Keras、PyTorch和Apache MXNet等框架的训练。Horovod特别适合于大规模的深度学习模型训练。
- Ray是一个开源的分布式框架,用于构建和运行分布式应用程序。Ray提供了Ray Tune(用于超参数调优)和Ray Serve(用于模型服务),并且可以与TensorFlow、PyTorch和MXNet等深度学习库集成。
- Hugging Face的Accelerate库是为了简化PyTorch模型的分布式训练而设计的。它提供了一个简单的API来启动分布式训练,并支持使用单个或多个GPU以及TPU。
- DeepSpeed是微软开发的一个开源库,用于加速PyTorch模型的训练。它提供了各种优化技术,如ZeRO(Zero Redundancy Optimizer)和模型并行性,以支持大规模模型的训练。
2. 业内常用的分布式AI框架?
- Horovod:由Uber开发,基于MPI的分布式训练框架。
- Ray:用于构建和运行分布式应用程序的开放源代码框架。
- DeepSpeed:由微软开发,用于加速深度学习训练的库,它提供了数据并行、张量并行和模型并行等多种并行策略。
- FairScale:由Facebook开发,提供了类似于DeepSpeed的功能。
3. 数据并行、张量并行、流水线并行的原理及区别?
- 数据并行:在数据并行中,模型的不同副本在不同的设备上运行,每个设备处理输入数据的不同部分。每个设备独立地进行前向传播和反向传播,但参数更新是同步的。数据并行的主要优点是简单且易于实现。
- 张量并行:在张量并行中,模型的单个层或参数被切分成多个部分,每个部分在不同的设备上运行。张量并行通常用于训练非常大型的模型,因为它可以减少每个设备的内存需求。
- 流水线并行:在流水线并行中,模型的不同层被放置在不同的设备上,每个设备负责模型的一部分。输入数据在设备之间按顺序流动,每个设备完成自己的计算后将数据传递给下一个设备。流水线并行可以减少每个设备的内存需求,并提高训练速度。
4. 推理优化技术 Flash Attention 的作用是什么?
Flash Attention是一种用于加速自然语言处理模型中自注意力机制的推理过程的优化技术。它通过减少计算量和内存需求,使得在有限的资源下能够处理更长的序列。Flash Attention使用了一种有效的矩阵乘法算法,可以在不牺牲准确性的情况下提高推理速度。
5. 推理优化技术 Paged Attention 的作用是什么?
Paged Attention是一种用于处理长序列的优化技术。它将注意力矩阵分页,使得只有当前页的注意力分数被计算和存储,从而大大减少了内存需求。这种方法可以在不增加计算成本的情况下处理比内存容量更大的序列。
Flash Attention 是一种高效的注意力机制实现,旨在提高大规模模型训练的速度和内存效率。它通过减少GPU内存使用和增加计算吞吐量来实现这一点。
Flash Attention 利用 GPU 上的特定优化,如共享张量核心和高效的内存使用,以减少内存占用并提高计算速度。这种方法特别适用于具有长序列和大型模型参数的场景,例如自然语言处理和推荐系统。
Paged Attention 是一种用于处理超长序列的注意力机制。在标准的注意力机制中,序列的长度受到GPU内存的限制。
Paged Attention 通过将序列分割成多个较小的部分(页面)来克服这个问题,只将当前需要计算的部分加载到内存中。这种方法允许模型处理比单个GPU内存更大的序列,同时保持较高的计算效率。Paged Attention 对于需要处理极长序列的应用场景(例如长文档处理、音频处理等)非常有用。
6. CPU-offload,ZeRO-offload 了解?
- CPU-offload:在深度学习训练中,将一些计算或数据从GPU转移到CPU上,以减轻GPU的负担。这通常用于减少GPU内存使用,提高GPU利用率。
- ZeRO-offload:是DeepSpeed中的一种优化技术,它将模型的参数、梯度和优化器状态分散存储在CPU内存或NVMe存储中,从而减少GPU内存的使用。ZeRO-offload是ZeRO(零冗余优化器)策略的一部分,旨在提高训练大规模模型的能力。
7. ZeRO,零冗余优化器的三个阶段?
- ZeRO-Stage 1:将优化器状态分割到不同设备上,减少内存占用。
- ZeRO-Stage 2:除了优化器状态,还将模型参数分割到不同设备上。
- ZeRO-Stage 3:将梯度和优化器状态也分割到不同设备上,实现最大的内存节省。
8. 混合精度训练的优点是什么?可能带来什么问题?
- 优点:混合精度训练使用不同精度(例如,FP16和FP32)的数字来执行计算,可以提高训练速度,减少内存使用,并可能减少能源消耗。它利用了现代GPU对FP16运算的支持,同时使用FP32进行关键的计算,以保持准确性。
- 可能的问题:混合精度训练可能会导致数值不稳定,特别是在模型梯度非常小或非常大时。此外,它可能需要额外的校准步骤来确保FP16计算的准确性。
9. Megatron-DeepSpeed 方法?
Megatron-DeepSpeed是结合了Megatron-LM和DeepSpeed的技术,用于训练超大型语言模型。它利用了Megatron-LM的模型并行技术和DeepSpeed的数据并行和优化器技术,以实现高效的训练。
10. Megatron-LM 方法?
Megatron-LM是一种由NVIDIA开发的用于训练大规模语言模型的模型并行技术。它通过将模型的不同部分分布在多个GPU上,以及使用张量并行和流水线并行等技术,来减少每个GPU的内存需求,并提高训练速度。Megatron-LM已经成功训练了数十亿参数的语言模型。
11. DeepSpeed 方法?
DeepSpeed 是一个开源的库,由微软开发,用于加速大规模模型训练。DeepSpeed 通过多种技术实现了这一点,包括:
- 数据并行:通过在不同的 GPU 上分配不同的数据批次,来并行处理数据,从而加速训练过程。
- 模型并行:通过在不同的 GPU 上分配模型的各个部分,来并行处理模型,从而可以训练更大的模型。
- 管道并行:通过将模型的不同层分配到不同的 GPU 上,并在这些 GPU 之间创建数据流管道,来进一步加速训练过程。
- 优化器并行:通过将模型的参数分为多个部分,并在不同的 GPU 上并行计算每个部分的梯度更新,来加速优化器步骤。
- 零冗余优化器(ZeRO):通过将模型的参数、梯度和优化器状态分割存储在多个 GPU 上,并消除冗余存储,来减少内存使用并提高训练效率。
五、大模型(LLMs)推理
1. 为什么大模型推理时显存涨的那么多还一直占着?
- 模型大小:大模型本身具有更多的参数和计算需求,这直接导致了显存的增加。
- 推理过程中的激活和梯度:在推理时,模型的前向传播会产生激活,这些激活需要存储在显存中,尤其是在执行动态计算或需要中间结果的情况下。
- 优化器状态:即使是在推理模式下,某些框架可能会默认加载优化器状态,这也会占用显存空间。
- 内存泄漏:有时代码中的内存泄漏会导致显存一直被占用,而不是在推理完成后释放。
要解决显存占用问题,可以采用的技术包括使用内存分析工具来检测泄漏,优化模型结构,或者使用如TensorFlow的内存管理功能来显式释放不再需要的内存。
2. 大模型在GPU和CPU上推理速度如何?
大模型在GPU上的推理速度通常远快于CPU,因为GPU专门为并行计算设计,具有更多的计算核心和更高的浮点运算能力。例如,NVIDIA的GPU使用CUDA核心,可以同时处理多个任务,这使得它们在执行深度学习推理时非常高效。
CPU虽然也可以执行深度学习推理任务,但由于其核心数量和浮点运算能力通常不及GPU,因此速度会慢得多。然而,CPU在处理单线程任务时可能更高效,且在某些特定场景下,如边缘计算设备上,CPU可能是唯一可用的计算资源。
3. 推理速度上,int8和fp16比起来怎么样?
INT8(8位整数)和FP16(16位浮点数)都是低精度格式,用于减少模型的大小和提高推理速度。INT8提供更高的压缩比,可以显著减少模型的内存占用和带宽需求,但由于量化过程中的信息损失,可能会对模型的准确性产生一定影响。FP16提供比INT8更高的精度,通常对模型的准确性影响较小,但相比INT16或FP32,它的速度和内存效率仍然有所提高。
在实际应用中,INT8和FP16的推理速度取决于具体的模型和硬件。一般来说,INT8可能会提供更高的吞吐量,但FP16可能会提供更好的延迟和准确性。例如,NVIDIA的Tensor Cores支持FP16和INT8运算,可以显著提高这两种格式的推理性能。
4. 大模型有推理能力吗?
大模型(LLMs)具有推理能力。推理能力不仅限于回答事实性问题,还包括理解复杂语境、生成连贯文本、执行文本分类、翻译等任务。例如,GPT-3是一个大模型,它能够生成文章、故事、诗歌,甚至编写代码。
5. 大模型生成时的参数怎么设置?
大模型生成时的参数设置取决于具体的任务和模型。一些常见的参数包括:
- 温度(Temperature):控制生成的文本的随机性。较低的温度值将导致生成更保守的文本,而较高的温度值将导致更多样化的文本。
- Top-k采样:仅从概率最高的k个词中采样,以减少生成文本的随机性。
- Top-p采样:从累积概率超过p的词中进行采样,这有助于生成更相关的文本。
- 最大生成长度:指定生成文本的最大长度。
例如,使用GPT-3生成文本时,可以设置温度为0.7,top-k为50,最大生成长度为100个词。
6. 有哪些省内存的大语言模型训练/微调/推理方法?
- 模型并行:将模型的不同部分分布在多个设备上。
- 张量切片:将模型的权重和激活分割成较小的块。
- 混合精度训练:使用FP16和INT8精度进行训练和推理。
- 优化器状态分割:如ZeRO技术,将优化器状态分割到不同设备上。
- 梯度累积:通过累积多个批次的梯度来减少每个批次的内存需求。
在机器学习中,优化器状态是指在训练模型时优化器所维护的关于模型参数更新的额外信息。这些信息对于执行梯度下降算法的变体(如Adam、RMSprop、SGD等)至关重要,因为它们帮助优化器更有效地调整模型参数。
优化器状态通常包括以下几个关键组件:
- 梯度:在反向传播过程中计算的权重参数的梯度,指示了损失函数相对于每个参数的斜率。
- 动量:某些优化器(如SGD with Momentum、Adam等)会使用动量来平滑参数更新,这可以帮助优化器在相关方向上加速学习,并减少震荡。
- 平方梯度:某些优化器(如RMSprop、Adam)会保存每个参数梯度的平方的移动平均,这有助于调整学习率并稳定训练过程。
- 学习率:优化器可能会根据训练的进度或某些其他信号调整每个参数的学习率。
- 其他统计量:某些优化器可能会使用其他统计量,如Adam优化器会维护梯度的一阶和二阶矩的估计。
优化器状态对于实现高效的参数更新至关重要。在训练过程中,优化器会根据这些状态信息来计算每个迭代步骤中参数的更新量。在分布式训练设置中,如DeepSpeed中的ZeRO优化器,优化器状态的管理变得尤为重要,因为它们需要跨多个GPU或节点高效地分配和同步。
7. 如何让大模型输出合规化?
- 过滤不当内容:使用内容过滤器来识别和过滤掉不当的语言或敏感内容。
- 指导性提示:提供明确的提示,指导模型生成符合特定标准和偏好的输出。
- 后处理:对模型的输出进行后处理,例如使用语法检查器和修正工具来提高文本的质量。
- 强化学习:使用强化学习来训练模型,使其偏好生成符合特定标准的输出。
8. 应用模式变更
应用模式变更是指在部署模型时,根据实际应用的需求和环境,对模型的配置、部署策略或使用方式进行调整。例如,一个在云端运行的模型可能需要调整其资源分配以适应不同的负载,或者在边缘设备上运行的模型可能需要减少其内存和计算需求以适应有限的资源。
应用模式变更可能包括:
- 资源调整:根据需求增加或减少用于运行模型的计算资源。
- 模型压缩:使用模型压缩技术如剪枝、量化来减少模型大小。
- 动态部署:根据负载动态地扩展或缩小模型服务的实例数量。
- 缓存策略:实施缓存机制来存储常用查询的响应,减少重复计算的次数。
- 性能优化:对模型进行性能分析,并优化其运行效率,例如通过批处理输入数据来提高吞吐量。
举例来说,如果一个大型语言模型在云平台上运行,当用户查询量增加时,可以通过增加服务器的数量或使用更高效的硬件来扩展其能力。相反,如果模型需要在嵌入式设备上运行,可能需要将模型压缩到更小的尺寸,并优化其运行时的内存使用,以确保模型可以在资源有限的设备上顺利运行。
在实际操作中,应用模式变更通常需要综合考虑模型的性能、成本、可扩展性和业务需求,以找到最佳的平衡点。
1. 前缀微调(Prefix-Tuning)
前缀微调是一种针对预训练模型的微调方法,通过在模型输入前添加特定任务相关的连续前缀表示,从而引导模型生成适应特定任务的输出。在微调过程中,只更新前缀表示的参数,而预训练模型的参数保持不变。
微调方法:首先,为每个任务设计一个可学习的前缀表示。然后,将这个前缀表示与输入序列进行拼接,输入到预训练模型中。最后,通过优化前缀表示的参数,使得模型能够生成适应特定任务的输出。
优点:前缀微调可以减少对预训练模型参数的修改,降低过拟合风险;同时,由于只更新前缀表示的参数,因此计算资源需求较低。
缺点:可能受到前缀表示长度的限制,无法充分捕捉任务相关的信息;此外,对于不同任务,可能需要设计不同的前缀表示,增加了人工成本。
2. 指令微调(Instruction Tuning)
指令微调是一种针对预训练模型的微调方法,通过在训练数据中添加指令来指导模型完成特定任务。在微调过程中,模型需要学习如何根据指令生成适应特定任务的输出。
微调方法:首先,在训练数据中添加包含任务描述的指令。然后,将这些指令与输入序列进行拼接,输入到预训练模型中。最后,通过优化模型参数,使得模型能够根据指令生成适应特定任务的输出。
优点:指令微调可以提高模型在遵循指令方面的能力,从而提高模型在特定任务上的性能。
缺点:可能需要对训练数据进行修改,增加了数据预处理的工作量;此外,对于不同任务,可能需要设计不同的指令,增加了人工成本。
3. p-tuning
p-tuning是一种针对预训练模型的微调方法,通过在模型输入前添加可学习的连续表示,从而引导模型生成适应特定任务的输出。在微调过程中,只更新这些连续表示的参数,而预训练模型的参数保持不变。
微调方法:首先,为每个任务设计一个可学习的连续表示。然后,将这个连续表示与输入序列进行拼接,输入到预训练模型中。最后,通过优化连续表示的参数,使得模型能够生成适应特定任务的输出。
优点:p-tuning可以减少对预训练模型参数的修改,降低过拟合风险;同时,由于只更新连续表示的参数,因此计算资源需求较低。
缺点:可能受到连续表示长度的限制,无法充分捕捉任务相关的信息;此外,对于不同任务,可能需要设计不同的连续表示,增加了人工成本。
4. p-tuning V2
p-tuning V2是p-tuning的改进版本,通过使用更多的连续表示来引导模型生成适应特定任务的输出。在微调过程中,只更新这些连续表示的参数,而预训练模型的参数保持不变。
微调方法:首先,为每个任务设计多个可学习的连续表示。然后,将这些连续表示与输入序列进行拼接,输入到预训练模型中。最后,通过优化连续表示的参数,使得模型能够生成适应特定任务的输出。
优点:p-tuning V2可以进一步减少对预训练模型参数的修改,降低过拟合风险;同时,由于使用了更多的连续表示,可以更充分地捕捉任务相关的信息。
缺点:可能需要更多的计算资源来更新多个连续表示的参数;此外,对于不同任务,可能需要设计不同的连续表示,增加了人工成本。
5. 参数高效微调(Parameter-Efficient Fine-Tuning,PEFT)
参数高效微调是一种针对预训练模型的微调方法,通过仅更新模型参数的一小部分来实现特定任务的适应。在微调过程中,大部分预训练模型的参数保持不变,只更新与特定任务相关的参数。
微调方法:首先,确定与特定任务相关的模型参数。然后,在微调过程中,只更新这些特定参数,而其他参数保持不变。
优点:参数高效微调可以减少计算资源的需求,降低过拟合风险;同时,由于只更新部分参数,因此可以更快地实现模型微调。
缺点:可能无法充分利用预训练模型的特征表示能力;此外,对于不同任务,可能需要确定不同的特定参数,增加了人工成本。
6. prompt微调
prompt微调是一种针对预训练模型的微调方法,通过设计特定的提示(prompt)来引导模型生成适应特定任务的输出。在微调过程中,模型需要学习如何根据提示生成适应特定任务的输出。
微调方法:首先,为每个任务设计一个特定的提示。然后,将这个提示与输入序列进行拼接,输入到预训练模型中。最后,通过优化模型参数,使得模型能够根据提示生成适应特定任务的输出。
优点:prompt微调可以提高模型在遵循提示方面的能力,从而提高模型在特定任务上的性能。
缺点:可能需要对训练数据进行修改,增加了数据预处理的工作量;
7. 领域模型微调(Domain Adaptation)
领域模型微调是一种针对预训练模型的微调方法,用于适应特定领域的任务。当预训练模型需要在特定领域(如医学、法律等)进行应用时,领域模型微调可以通过在领域特定的数据集上对模型进行微调,以适应该领域的特点。
微调方法:首先,准备一个包含领域特定数据的训练集。然后,在这个训练集上对预训练模型进行微调,更新模型的参数以更好地适应领域特定的语言和任务需求。
优点:领域模型微调可以使模型更好地适应特定领域的语言和任务需求,提高在领域内的性能。
缺点:可能需要大量的领域特定数据进行微调,而且微调后的模型可能只在特定领域有效,泛化能力可能减弱。
8. 适配器微调(Adapter-tuning)
适配器微调是一种参数高效的微调方法,它通过在预训练模型的每个Transformer层中添加小型适配器模块,来引入任务特定的参数。
微调方法:首先,在预训练模型的每个Transformer层中添加一对适配器模块,通常由两个全连接层组成。然后,在微调过程中,只更新这些适配器模块的参数,而预训练模型的原始参数保持不变。
优点:适配器微调不需要更新大量的模型参数,因此计算资源需求较低,训练速度较快。同时,适配器模块可以轻松地添加到预训练模型中,不会影响模型的原始性能。
缺点:适配器微调可能无法达到与全量微调相同的性能水平,因为适配器模块的参数量远小于整个模型。此外,适配器模块可能会引入额外的计算开销。
9. LoRA (Low-Rank Adaptation)
LoRA是一种参数高效的微调方法,它通过引入低秩分解来减少需要更新的参数数量。在LoRA中,预训练模型的注意力矩阵或前馈网络矩阵被分解为两个低秩矩阵的乘积,其中这两个低秩矩阵被视为可学习的任务特定参数。
微调方法:首先,将预训练模型的注意力矩阵或前馈网络矩阵分解为两个低秩矩阵。然后,在微调过程中,只更新这两个低秩矩阵的参数,而预训练模型的原始参数保持不变。
优点:LoRA可以显著减少需要更新的参数数量,从而减少计算资源的需求,并加快训练速度。同时,LoRA可以在不牺牲太多性能的情况下实现参数高效的微调。
缺点:LoRA的性能可能略低于全量微调,尤其是在处理非常复杂的任务时。此外,LoRA需要对预训练模型进行一定的修改,以实现矩阵的分解和参数的更新。
10. 全量微调(Full Fine-Tuning)
全量微调是一种传统的微调方法,它涉及更新预训练模型的所有参数以适应特定任务。
微调方法:首先,准备一个包含任务特定数据的训练集。然后,在这个训练集上对预训练模型的参数进行更新,包括Transformer层的权重和输出层的权重。
优点:全量微调通常能够达到最佳的性能,因为它允许模型完全适应特定任务的数据分布。
缺点:全量微调需要大量的计算资源,尤其是在处理大型预训练模型时。此外,全量微调可能会导致过拟合,尤其是在训练数据有限的情况下。
大模型基础
-
主流的开源大模型有哪些?
- GPT-3:由 OpenAI 开发,GPT-3 是一个巨大的自回归语言模型,拥有1750亿个参数。它可以生成文本、回答问题、翻译文本等。
- GPT-Neo:由 EleutherAI 开发,GPT-Neo 是一个开源的、基于 GPT 架构的语言模型,拥有数十亿到百亿级的参数。
- GPT-J:也是由 EleutherAI 开发的,GPT-J 是一个拥有 60亿参数的开源语言模型。
- PaLM (Pathways Language Model):由谷歌开发,PaLM 是一个大型语言模型,拥有5400亿个参数,用于处理自然语言处理任务。
- LaMDA:也是由谷歌开发,LaMDA 是一个对话应用程序的语言模型,旨在生成安全、有事实依据的响应。
- ERNIE 3.0:由百度开发,ERNIE 3.0 是一个大型预训练语言模型,用于处理自然语言处理任务。
- ChatGLM:由智谱 AI 公司开发,ChatGLM 是一个大型语言模型,用于处理自然语言处理任务。
- OPT (Open Pre-trained Transformer):由斯坦福大学和 Meta AI 开发,OPT 是一个大型语言模型,拥有1750亿个参数。
-
目前大模型模型结构有哪些?
目前大型模型的结构主要基于 Transformer 架构,这是因为 Transformer 能够有效地处理长距离依赖关系,并且在并行计算方面具有优势。以下是一些常见的大模型结构:
1. **Transformer**:原始的 Transformer 架构是由 Vaswani 等人在 2017 年提出的,它包含自注意力机制和前馈神经网络。这种结构已经被广泛应用在语言模型、机器翻译、文本生成等任务中。
2. **BERT (Bidirectional Encoder Representations from Transformers)**:BERT 是一种双向 Transformer 结构,它在预训练阶段使用掩码语言建模和下一句预测任务来学习语言表示。BERT 及其变体(如 RoBERTa、ALBERT)在多种自然语言处理任务中取得了突破性的性能。
3. **GPT (Generative Pre-trained Transformer)**:GPT 是一种自回归 Transformer 结构,它在预训练阶段使用传统的语言建模任务来学习语言表示。GPT 及其变体(如 GPT-2、GPT-3)在文本生成和零样本学习等任务中表现出色。
4. **T5 (Text-to-Text Transfer Transformer)**:T5 是一种基于 Transformer 的统一框架,它将所有自然语言处理任务都转化为文本到文本的格式。T5 及其变体(如 mT5、ByT5)在多种语言和任务中表现良好。
5. **XLNet**:XLNet 是一种基于自回归语言建模和双向 Transformer 的模型,它使用排列语言建模目标来捕捉上下文信息。XLNet 在多项自然语言处理任务中取得了出色的性能。
6. **Switch Transformer**:Switch Transformer 是一种使用稀疏注意力机制的 Transformer 结构,它通过将注意力集中在最重要的部分来减少计算复杂度。Switch Transformer 在处理超大型模型时非常有效。
7. **指令微调(Instruction Tuning)模型**:这类模型在预训练后通过指令微调来适应特定的任务或领域。例如,Flan-T5 和 FLAN 是在多种任务和指令上进行了微调的模型,它们在遵循指令和少样本学习方面表现良好。
这些模型结构在不同的应用场景中可能会有所变化,例如通过调整层数、隐藏单元数量、注意力头的数量等来适应不同的需求和资源限制。随着研究的进展,还可能出现新的模型结构和改进方法。
-
Prefix LM 和 causal LM、encoder-decoder 的区别及各自有什么优缺点?
Prefix LM、causal LM(也称为自回归LM)和encoder-decoder是三种不同的语言模型架构,它们在结构、训练方式和应用场景上有所区别。下面是它们的区别及各自的优缺点:
1. **Prefix LM**:
- Prefix LM是一种语言模型架构,它在每个时间步都考虑之前生成的所有文本作为上下文。这意味着模型在生成下一个词时可以使用到目前为止生成的整个序列的信息。
- **优点**:
- 能够利用更长的上下文信息,生成更连贯、上下文相关的文本。
- 在某些任务上,如文本续写或问答,能够提供更准确的回答。
- **缺点**:
- 计算成本较高,因为每个时间步都需要处理整个上下文。
- 可能更容易产生重复的文本。
2. **Causal LM(自回归LM)**:
- Causal LM是一种语言模型架构,它在生成文本时只考虑之前生成的词,而不是整个上下文。这意味着模型在生成下一个词时只能使用之前生成的词的信息。
- **优点**:
- 计算效率较高,因为每个时间步只需要处理之前生成的词。
- 在生成自然语言文本方面表现良好,如对话、文章等。
- **缺点**:
- 可能无法充分利用长距离的上下文信息。
- 在需要长距离上下文信息的任务上,性能可能不如Prefix LM。
3. **Encoder-Decoder**:
- Encoder-Decoder是一种包含编码器和解码器的模型结构,编码器处理输入数据,而解码器生成输出。这种结构常用于机器翻译、文本摘要等任务。
- **优点**:
- 能够处理更复杂的输入输出关系,如机器翻译中的源语言和目标语言。
- 可以通过编码器和解码器的设计来引入额外的约束或先验知识。
- **缺点**:
- 训练和推理速度通常较慢,因为需要分别处理编码器和解码器。
- 模型复杂度较高,需要更多的参数和计算资源。
总的来说,选择哪种架构取决于具体的应用场景和任务需求。例如,如果需要生成连贯的对话或文章,自回归LM可能是一个好选择;如果需要处理复杂的输入输出关系,如机器翻译,则可能需要使用Encoder-Decoder结构。
-
模型幻觉是什么?业内解决方案是什么?
模型幻觉(Model Hallucination)是指模型在生成文本或做出预测时产生的不准确、虚构或误导性的信息。这种现象通常发生在大型语言模型中,尤其是当模型基于不完整或模糊的信息进行推理时。模型幻觉可能是由于模型在训练数据中学习到的模式不准确,或者是因为模型过于自信地推广了有限的上下文信息。
### 解决方案:
1. **数据清洗和增强**:
- 确保训练数据的质量和多样性,减少错误信息的暴露。
- 使用数据增强技术,如回译(back-translation)、文本简化等,以提高模型的泛化能力。
2. **知识蒸馏**:
- 将大型模型的知识蒸馏到较小的模型中,同时尽量保留其性能,以减少模型的复杂性,从而可能减少幻觉。
3. **外部知识库**:
- 集成外部知识库或事实数据库,使模型在生成文本时能够引用准确的事实信息。
4. **事实检查和验证**:
- 在模型输出后,使用事实检查机制来验证其准确性。
- 开发专门的验证模型或工具,用于检测和纠正幻觉。
5. **改进模型架构**:
- 设计更复杂的模型架构,如多模态模型,以提高模型对上下文的理解能力。
- 引入注意力机制或其他机制来提高模型对关键信息的关注。
6. **模型微调**:
- 对模型进行特定领域的微调,以适应特定任务或领域的需求。
7. **用户交互**:
- 设计用户界面,允许用户与模型互动,提供反馈,从而帮助模型改进其输出。
8. **透明度和可解释性**:
- 提高模型决策的透明度和可解释性,使用户能够理解模型的推理过程。
9. **合规性和伦理**:
- 遵守相关的合规性和伦理标准,确保模型的输出不违反法律法规或伦理准则。
10. **持续监控和更新**:
- 持续监控模型的性能和输出,定期更新模型以反映新的数据和知识。
这些解决方案通常需要结合使用,以有效地减少模型幻觉。随着技术的发展,还可能出现新的技术和方法来进一步解决这个问题。
-
大模型的 Tokenizer 的实现方法及原理?
Tokenizer 是自然语言处理中的一个关键组件,它负责将原始文本转换为模型能够理解的数字表示(如词嵌入)。在大模型中,Tokenizer 的实现通常采用以下几种方法:
1. **字节对编码(Byte Pair Encoding,BPE)**:
- BPE 是一种基于字符的分割方法,它通过迭代地合并最常见的字节对来创建一个词汇表。这种方法可以有效地处理未知词汇和稀有词汇,同时减少词汇表的大小。
- BPE 的原理是首先将文本分割成单个字符,然后统计字符对的出现频率,并按照频率从高到低的顺序合并字符对。这个过程一直重复,直到达到预定的词汇表大小或合并次数。
2. **WordPiece**:
- WordPiece 是一种类似的基于频率的分割方法,它将文本分割成子词单元。WordPiece 不同于 BPE 的地方在于它可能会将单个字符作为子词的一部分进行合并。
- WordPiece 的原理是从单个字符开始,然后寻找能够最大化语料库中单词覆盖率的词块进行合并。
3. **Unigram Language Model**:
- Unigram Language Model 是一种基于概率的分割方法,它使用一个语言模型来评估不同的子词分割方式,并选择最可能的分割。
- 这种方法的原理是训练一个语言模型来预测单词的下一个字符,然后使用这个模型来找到最佳的子词边界。
4. **SentencePiece**:
- SentencePiece 是一种将句子作为单元进行编码的方法,它将整个句子编码为一个连续的整数序列,而不需要空格或分隔符。
- SentencePiece 的原理是将文本分割成句子片段,然后使用 BPE 或 Unigram LM 等方法来创建一个词汇表,最后将句子片段编码为整数序列。
在大模型中,Tokenizer 的选择和实现对于模型的性能和效率至关重要。一个良好的 Tokenizer 应该能够处理多种语言的复杂性,包括未知词汇、稀有词汇和成语等。此外,Tokenizer 还应该能够处理不同的文本输入,如长文本、短文本和噪声文本。
-
ChatGLM3 的词表实现方法?
ChatGLM3 是一个大型的自然语言处理模型,它使用了一种称为“词嵌入”(word embeddings)的技术来将文本数据转化为模型可以理解和处理的数值形式。在词嵌入中,每个单词都被分配一个唯一的向量,这个向量捕捉了单词的语义信息。
词表(vocabulary)是实现词嵌入的关键组成部分。词表是一个包含所有可能单词的列表,每个单词在列表中都有一个唯一的索引。模型使用这个索引来查找每个单词对应的向量。
以下是 ChatGLM3 的词表实现方法的一般步骤:
- 数据预处理:首先,需要对原始文本数据进行预处理,包括分词、去除停用词、文本清洗等。分词是将文本切分成单个单词或词组的过程,这是构建词表的基础。
- 构建词表:从预处理后的文本数据中,提取所有唯一的单词,并按照一定的顺序(如字母顺序)构建词表。词表中的每个单词都有一个唯一的索引。
- 生成词嵌入矩阵:根据词表的大小,生成一个词嵌入矩阵。矩阵的每一行都对应词表中的一个单词,表示该单词的词嵌入向量。这些向量可以通过无监督学习方法(如 Word2Vec、GloVe 等)从大量文本数据中学习得到。
- 文本编码:在模型训练或推理时,将输入的文本数据转换为词表中的索引序列。这通常通过查找每个单词在词表中的索引来实现。然后,将这些索引转换为对应的词嵌入向量,作为模型的输入。
需要注意的是,由于 ChatGLM3 是一个大型模型,其词表可能包含数十万甚至上百万个单词。因此,对于不在词表中的单词(即未知词),模型通常会采用一些特殊的处理方法,如将其映射到一个特定的“未知词”标记,或者使用某种策略来生成这些词的词嵌入向量。
此外,为了提高模型的性能和效率,词嵌入矩阵通常会采用一些优化策略,如量化、压缩等。这些策略可以在减少模型存储和计算需求的同时,保持模型的性能。
-
GPT3、LLAMA、Chatglm 的Layer Normalization的区别是什么?各自的优缺点是什么?
GPT-3、LLAMA 和 ChatGLM 是不同公司开发的大型语言模型,它们在 Layer Normalization 的实现上可能会有所不同。Layer Normalization 是一种在深度学习模型中常用的归一化技术,旨在稳定模型的训练过程。下面是它们在 Layer Normalization 方面的可能区别以及各自的优缺点:
1. **GPT-3**:
- GPT-3 是由 OpenAI 开发的,它使用了 Post-Layer Normalization 技术。
- **优点**:Post-Layer Normalization 可以提高模型训练的稳定性,尤其是在处理深层网络时。
- **缺点**:可能会增加计算复杂度,因为归一化是在每个层的激活函数之后进行的。
2. **LLAMA**:
- LLAMA 是由 Meta AI 开发的,关于其 Layer Normalization 的具体实现细节不太清楚,但通常大型模型会采用类似于 GPT-3 的 Layer Normalization 技术。
- **优点**:如果 LLAMA 采用 Post-Layer Normalization,那么它也可能享受到训练稳定性的提升。
- **缺点**:同样可能会面临计算复杂度增加的问题。
3. **ChatGLM**:
- ChatGLM 是由智谱 AI 公司开发的,关于其 Layer Normalization 的具体实现细节也不太清楚。不过,考虑到它是针对中文语言特点进行优化的模型,它可能会采用一些特定的技术来提高处理中文文本的效率。
- **优点**:如果 ChatGLM 对 Layer Normalization 进行了优化,那么它可能会在处理中文文本时表现得更好。
- **缺点**:特定的优化可能会限制模型在其他语言或任务上的泛化能力。
总的来说,Layer Normalization 在这些大型语言模型中起着关键作用,有助于提高训练稳定性和模型性能。不同的实现方法可能会在计算复杂度、训练稳定性以及模型泛化能力方面有所不同。具体的选择取决于模型的特定需求和设计目标。
-
大模型常用的激活函数有那些?
1. **ReLU (Rectified Linear Unit)**:
- 公式:f(x) = max(0, x)
- 优点:计算简单,收敛速度快,解决了梯度消失问题。
- 缺点:可能导致“死神经元”现象,即神经元输出恒为0。
2. **Leaky ReLU**:
- 公式:f(x) = max(0.01x, x)
- 优点:解决了ReLU中“死神经元”的问题,允许较小的负值激活。
- 缺点:需要额外调整泄漏系数。
3. **ELU (Exponential Linear Unit)**:
- 公式:f(x) = { x, if x > 0; α(exp(x) - 1), otherwise }
- 优点:具有ReLU的优点,同时能够减少梯度消失问题,提供负值激活。
- 缺点:计算复杂度稍高,需要调整超参数α。
4. **Swish**:
- 公式:f(x) = x * sigmoid(x)
- 优点:无上界有下界,平滑,减少了梯度消失问题。
- 缺点:计算稍微复杂,因为包含sigmoid函数。
5. **GeLU (Gaussian Error Linear Unit)**:
- 公式:f(x) = x * Φ(x),其中Φ(x)是高斯分布的累积分布函数。
- 优点:在Transformer模型中表现良好,能够提高模型性能。
- 缺点:计算比ReLU和Swish复杂。
6. **SELU (Scaled Exponential Linear Unit)**:
- 公式:f(x) = λ { x, if x > 0; α(exp(x) - 1), otherwise }
- 优点:自归一化(self-normalizing),有助于稳定训练。
- 缺点:需要调整超参数λ和α。
7. **Softmax**:
- 公式:f(xi) = exp(xi) / sum(exp(xj)) for all j
- 优点:常用于多分类问题的输出层,输出概率分布。
- 缺点:只适用于输出层,不适用于隐藏层。
-
Multi-query Attention 与 Grouped-query Attention 是什么?区别是什么?
Multi-query Attention 和 Grouped-query Attention 是注意力机制(Attention Mechanism)的两种不同变种,它们在处理输入数据时有所不同。下面是它们的区别:
1. **Multi-query Attention**:
- Multi-query Attention 是一种注意力机制,其中每个注意力头可以关注输入数据的不同部分。这意味着每个头可以独立地学习不同的表示,从而提高模型的表达能力。
- 在 Multi-query Attention 中,每个头通常有不同的权重矩阵,使得每个头可以关注不同的特征或模式。
- **优点**:提高了模型的表达能力,允许模型同时关注多个不同的方面。
- **缺点**:可能会增加计算复杂度,因为需要对每个头分别计算注意力权重。
2. **Grouped-query Attention**:
- Grouped-query Attention 是一种注意力机制的变种,其中多个头被分组,每组头关注输入数据的不同部分。这种方法的目的是提高计算效率,通过减少注意力头的数量来减少计算复杂度。
- 在 Grouped-query Attention 中,每组头共享相同的查询(query)权重矩阵,这意味着它们关注的是输入数据的相同部分,但可能有不同的关键信息。
- **优点**:减少了计算复杂度,特别是在处理大型模型或大量数据时。
- **缺点**:可能降低了模型的表达能力,因为减少了头的数量和多样性。
总的来说,Multi-query Attention 和 Grouped-query Attention 是两种不同的注意力机制变种,它们在模型的表达能力和计算效率之间做出了不同的权衡。具体的选择取决于特定任务的需求和可用的计算资源。
-
多模态大模型有哪些?
多模态大模型是指能够处理和理解多种不同模态数据(如文本、图像、声音等)的模型。这些模型通常具有更复杂的架构,能够将不同模态的数据转换为统一的表示,从而在多种任务上表现出色。以下是一些多模态大模型的落地案例:
1. **OpenAI的DALL-E和CLIP**:
- DALL-E是一个能够根据文本描述生成图像的多模态模型。
- CLIP是一个能够将图像和文本关联起来的多模态模型,用于图像分类和检索。
2. **谷歌的PaLM**:
- PaLM是一个大型多模态模型,能够处理文本、图像和声音等多种模态的数据。
3. **百度的ERNIE-ViL**:
- ERNIE-ViL是一个多模态预训练模型,它能够同时理解文本和图像内容,用于视觉问答等任务。
这些多模态大模型在多种应用场景中展现了强大的能力,例如图像生成、图像分类、视觉问答等。它们的出现标志着人工智能领域向更广泛的应用和更高的智能化水平迈进。
大模型参数微调、训练、推理
-
为什么需要进行参选微调?参数微调的优点有哪些?
参数微调(Fine-tuning)是深度学习中的一个重要概念,特别是在自然语言处理和计算机视觉等领域。它涉及使用一个已经在大规模数据集上训练好的模型,然后在一个特定的任务上进一步训练这个模型,以便使其能够更好地解决这个特定的问题。下面是参数微调的一些优点:
1. **节省计算资源**:使用预训练模型可以节省大量的计算资源。预训练模型通常在大规模的数据集上进行了数周甚至数月的训练,如果从头开始训练一个模型,将需要同样多的时间和资源。
2. **提高性能**:预训练模型已经学到了大量关于语言或图像的一般性知识。通过在特定任务上进行微调,可以利用这些知识,通常能获得比从头开始训练更好的性能。
3. **减少过拟合风险**:对于许多特定任务,由于数据量有限,从头开始训练模型容易导致过拟合。预训练模型已经在大规模数据上学习,因此过拟合的风险较小。
4. **适应性强**:预训练模型通常能够快速适应新的任务,尤其是在与预训练任务相似的任务上。
5. **便于迁移学习**:通过微调,可以将一个模型的知识迁移到相关的任务上,这对于那些数据稀疏或者标注困难的领域尤其有用。
6. **时间效率**:微调通常只需要相对较少的时间,就可以达到令人满意的性能,这对于快速开发和部署模型非常有帮助。
参数微调是一个强大的工具,使得深度学习模型能够更加灵活和有效地应用于各种实际问题。
-
模型参数微调的方式有哪些?
模型参数微调(Fine-tuning)是深度学习中的一个重要技术,它允许我们利用在大型数据集上预训练的模型,并在特定任务或领域上进行调整以获得更好的性能。微调的方式通常有以下几种:
1. **特征提取微调**:在这种方式中,我们冻结预训练模型的绝大部分层,只微调顶部的几层或输出层。这是因为预训练模型学习到的特征在多个领域都是通用的,而顶部的层更特定于原始任务的细节。
2. **全模型微调**:与特征提取微调相反,全模型微调会调整模型的所有层。这种方法在目标数据集较大,且与预训练数据集相似时效果较好。
3. **差异学习率微调**:这种方法中,模型的不同层会有不同的学习率。通常,接近输入的层会有更低的学习率,而接近输出的层会有更高的学习率。这样可以保持模型在早期学习到的通用特征,同时允许模型针对特定任务调整其输出层。
4. **渐进式微调**:在这种技术中,首先只微调模型的顶部层,然后逐渐解冻更多的层,并调整这些层的参数。
5. **迁移学习微调**:在迁移学习中,模型在一个任务上微调后,其学到的知识被用来提高在另一个相关任务上的性能。
-
prompt tuning 和 prefix tuning 在微调上的区别是什么?
Prompt Tuning 和 Prefix Tuning 是两种针对预训练语言模型(如 GPT-3)的微调方法,它们旨在通过最小的参数调整来改善模型在特定任务上的性能。这两种方法的主要区别在于它们调整模型的方式。
**Prompt Tuning:**
Prompt Tuning 的核心思想是将下游任务重新构造为语言模型的任务,即生成任务。在 Prompt Tuning 中,模型被用来预测一系列固定的 "prompt" tokens,这些 tokens 被设计用来引导模型生成正确的输出。只有这些 prompt tokens 的参数会被更新,而预训练模型的其余部分保持不变。这种方法大大减少了需要调整的参数数量,从而降低了过拟合的风险,并使得在较小的数据集上进行微调成为可能。
**Prefix Tuning:**
Prefix Tuning 与 Prompt Tuning 类似,也是通过添加额外的 tokens 来引导模型生成正确的输出。但是,与 Prompt Tuning 不同的是,Prefix Tuning 不只是更新这些额外的 tokens,而是引入了一个可训练的连续性 "prefix" 状态,这个状态会被输入到每一层的 Transformer 自注意力模块中。这个 prefix 状态可以看作是模型的一种提示,它指导模型如何处理随后的输入。由于 prefix 状态与模型的其余部分是分离的,因此 Prefix Tuning 同样可以减少需要调整的参数数量。
**区别总结:**
- **参数更新**:Prompt Tuning 只更新 prompt tokens 的参数,而 Prefix Tuning 更新的是一个连续性的 prefix 状态。
- **参数数量**:Prompt Tuning 通常需要更新的参数更少,因为它只关注于少量的 prompt tokens。Prefix Tuning 可能需要更多的参数,取决于 prefix 状态的设计。
- **适用性**:两种方法都适用于小型数据集,但 Prefix Tuning 可能更灵活,因为它可以为每一层引入不同的 prefix 状态,而 Prompt Tuning 通常只在输入层添加 prompt tokens。
- **效果**:实验表明,Prefix Tuning 在某些任务上可能比 Prompt Tuning 更有效,尤其是在需要更深层次提示的任务上。
总的来说,Prompt Tuning 和 Prefix Tuning 都是为了减少微调时需要更新的参数数量,从而在小数据集上也能获得良好的性能。它们的主要区别在于如何构造和更新这些提示信息。
-
LLaMA-adapter 如何实现稳定训练?
LLaMA-adapter 是一种用于语言模型的微调方法,旨在通过引入少量的参数来提高模型在特定任务上的性能,同时保持预训练模型的参数大部分不变。这种方法有助于减少在少量数据上进行微调时可能出现的过拟合问题。
为了实现稳定训练,LLaMA-adapter 采用了以下策略:
1. **参数效率**:LLaMA-adapter 引入了一个小型适配器模块,该模块包含相对较少的参数。这些适配器模块被插入到预训练模型的 Transformer 层之间,使得模型可以在不大幅改变原始预训练参数的情况下适应新任务。
2. **梯度裁剪**:在训练过程中,梯度裁剪可以帮助控制模型参数的更新幅度,防止梯度爆炸,从而提高训练的稳定性。
3. **学习率调度**:使用适当的学习率调度策略,如预热(warm-up)和衰减(decay),可以帮助模型在训练初期稳定地调整参数,并在训练后期精细调整。
4. **正则化**:应用正则化技术,如权重衰减(weight decay)或dropout,可以减少模型复杂度,避免过拟合,并提高泛化能力。
5. **适配器冻结**:在训练过程中,可以先将预训练模型的参数冻结,只训练适配器模块。一旦适配器模块开始收敛,可以逐步解冻部分预训练模型的层,进行联合训练。
6. **数据增强**:使用数据增强技术,如词替换、回译等,可以增加训练数据的多样性,提高模型对变化的适应性。
7. **多任务学习**:在多任务学习的设置中,模型同时学习多个相关任务,这可以帮助模型捕获更通用的特征,提高其在单个任务上的性能。
8. **评估和早停**:在训练过程中定期评估模型在验证集上的性能,并根据验证损失或指标实现早停,以防止过拟合。
通过上述策略,LLaMA-adapter 旨在实现稳定且高效的训练,使得预训练模型能够在保持大部分参数不变的情况下,快速适应新的任务。这种方法特别适合于数据稀缺的场景,因为它减少了微调时对大量标注数据的依赖。
-
LoRA 原理与使用技巧有哪些?
LoRA微调(LoRA Tuning)是一种用于自然语言处理(NLP)任务的模型微调方法,特别是针对大型语言模型(LLMs)的微调。这种方法由Hugging Face的研究人员在2022年提出,旨在通过引入低秩适配(Low-Rank Adaptation)来提高大型语言模型的微调效率和性能。
### LoRA微调原理:
1. **低秩适配**:LoRA微调的核心思想是假设模型参数的更新可以被分解为一个低秩的矩阵和一个稀疏的向量。这样,就可以只更新这个低秩的矩阵,从而减少需要更新的参数数量。
2. **稀疏性**:在LoRA微调中,稀疏性是指只更新模型参数中的一小部分,这些部分对模型性能的提升最为关键。
3. **LoRA适配器**:LoRA微调引入了LoRA适配器,这是一种特殊的神经网络结构,用于学习低秩的参数更新矩阵。适配器通常包含两个全连接层,其中一个用于生成低秩矩阵,另一个用于生成稀疏向量。
### 使用技巧:
1. **适配器配置**:LoRA微调的关键是适配器的配置。适配器的数量、隐藏层大小和激活函数的选择都会影响微调的效果。需要根据具体的任务和模型进行调整。
2. **稀疏性控制**:LoRA微调允许通过控制稀疏性来平衡计算效率和性能。增加稀疏性可以减少需要更新的参数数量,从而提高计算效率,但可能会降低性能。
3. **正则化**:由于LoRA微调引入了额外的参数,可能需要使用正则化技术来防止过拟合。常用的正则化技术包括Dropout、权重衰减等。
4. **学习率调整**:LoRA微调可能需要调整学习率,以适应其特有的参数更新方式。可以使用较小的学习率,或者使用学习率调度策略。
5. **集成学习**:LoRA微调可以与其他微调方法结合使用,例如知识蒸馏、模型集成等,以进一步提高性能。
总的来说,LoRA微调是一种有效的模型微调方法,尤其适用于大型语言模型的微调。通过合理的配置和使用技巧,可以提高微调的效率和性能。
-
LoRA 微调优点是什么?
LoRA (Low-Rank Adaptation) 是一种用于微调预训练模型的高效方法,其主要优点包括:
1. **参数效率**:LoRA 通过引入额外的低秩矩阵来调整预训练模型的注意力层和前馈网络层,而不是直接更新原始模型的参数。这些低秩矩阵的参数数量远小于原始模型,因此可以显著减少需要训练的参数数量。
2. **减少过拟合**:由于只更新少量的参数,LoRA 可以减少在小型数据集上微调时出现的过拟合问题。这意味着模型可以在只有少量标注数据的情况下仍然保持良好的泛化能力。
3. **训练速度**:由于需要更新的参数较少,LoRA 的训练速度通常比传统的全模型微调要快。这有助于节省计算资源,并允许研究人员和工程师更快地迭代模型。
4. **易于部署**:LoRA 微调后的模型可以很容易地与原始预训练模型结合,部署时只需替换或添加少量的参数,而不需要重新部署整个模型。
5. **灵活性**:LoRA 可以灵活地应用于不同类型的预训练模型,包括 Transformer 架构的模型。它还可以轻松地与多任务学习和其他微调方法结合使用。
6. **可解释性**:LoRA 的低秩分解可以提供一定的可解释性,因为它可以被视为对原始权重矩阵的分解,其中低秩矩阵捕捉了主要的适应变化。
7. **内存效率**:由于只需要存储和更新少量的额外参数,LoRA 相比于全模型微调具有更高的内存效率。
总之,LoRA 微调方法提供了一种在保持预训练模型大部分参数不变的情况下,高效、稳定地适应新任务的途径。这种方法特别适合于资源受限的环境,如有限的标注数据、计算能力和存储资源。
-
AdaLoRA 的思路是怎么样的?
AdaLoRA(Adaptive Low-Rank Approximation)是一种优化技术,其思路在于通过自适应的低秩近似来改进深度学习模型。其核心思想是在训练过程中,根据每个参数的重要程度自动为其分配可微调参数的预算。这样,AdaLoRA能够在减少计算复杂度和内存消耗的同时,保持模型的性能。
具体来说,AdaLoRA采用奇异值分解(SVD)的形式进行参数化增量更新。SVD是一种矩阵分解技术,可以将一个矩阵分解为三个矩阵的乘积,其中一个矩阵是对角矩阵,对角线上的元素称为奇异值。在AdaLoRA中,通过对增量更新进行SVD分解,可以高效裁剪不重要更新中的奇异值,从而降低增量过程中的资源消耗。
此外,AdaLoRA还通过优化低秩近似的秩选择策略,进一步提高了算法的性能。它根据参数的重要性动态调整秩的大小,使得模型在训练过程中能够更好地适应数据的变化。
总的来说,AdaLoRA的思路是通过自适应的低秩近似和优化的秩选择策略,降低深度学习模型的计算复杂度和内存消耗,同时保持模型的性能。这种方法可以应用于各种深度学习模型,如卷积神经网络(CNN)、循环神经网络(RNN)等,有助于提高模型的训练效率和性能。
-
LoRA 权重合入chatglm模型的方法?
要将 LoRA 微调的权重合入 ChatGLM 模型,你需要遵循以下步骤:
1. **理解 ChatGLM 模型结构**:首先,你需要了解 ChatGLM 模型的架构,包括其层的类型、参数名称和连接方式。这可以通过查看模型的配置文件或源代码来实现。
2. **获取 LoRA 微调权重**:在进行 LoRA 微调后,你会得到一组新的权重,这些权重通常包括注意力层的 query、key 和 value 权重,以及前馈网络层的权重。这些权重应该是低秩分解后的结果。
3. **修改模型配置**:根据 LoRA 微调的权重,你可能需要修改 ChatGLM 模型的配置文件,以确保模型能够正确加载和使用这些权重。这可能包括添加新的层或修改现有层的参数。
4. **更新模型权重**:将 LoRA 微调得到的权重合并到 ChatGLM 模型中。这可能涉及到将低秩矩阵与原始权重矩阵相乘,然后将结果赋值给相应的模型参数。
5. **保存和加载模型**:在合并了 LoRA 微调权重后,保存更新后的模型,并确保模型可以正确加载。你可能需要编写自定义的加载逻辑来处理 LoRA 微调权重的特殊格式。
6. **测试模型性能**:在合并了 LoRA 微调权重后,你应该在验证集上测试模型的性能,以确保合并过程没有引入错误,并且模型仍然能够很好地执行任务。
请注意,这个过程可能需要你具备一定的编程技能,以及对 ChatGLM 模型和 LoRA 微调方法的深入理解。如果你不熟悉这些概念,你可能需要寻求一个有经验的开发者或研究人员的帮助。
-
P-tuning 与 P-tuning v2 区别在哪里?优点与缺点?
P-tuning是一种用于自然语言处理(NLP)任务的参数微调方法,特别是在处理Few-Shot学习场景时,即训练数据非常有限的情况下。P-tuning是由微软研究院的研究人员在2020年提出的,旨在通过引入一系列可学习的上下文参数(Prompt Tokens)来改善预训练语言模型(如GPT)的适应性。
### P-tuning的原理:
P-tuning的核心思想是将下游任务的输入转化为预训练模型能够处理的自然语言提示(Prompt)。这些提示通常是一些模板化的句子,其中包含了任务的具体信息和一些可学习的参数(Prompt Tokens)。通过微调这些Prompt Tokens,模型能够更好地理解任务并给出正确的输出。
### P-tuning v2:
P-tuning v2是P-tuning的改进版本,由同一研究团队在2021年提出。P-tuning v2在原版的基础上做了一些优化,以提高模型在Few-Shot学习场景下的性能。
#### P-tuning v2的改进:
1. **连续提示**:P-tuning v2使用连续的向量作为提示,而不是离散的Prompt Tokens。这些向量是通过一个小型的神经网络生成的,使得提示更加灵活和丰富。
2. **参数效率**:由于使用了连续的向量,P-tuning v2通常需要更少的参数来达到与P-tuning相似或更好的性能。
3. **更好的泛化能力**:连续提示可以更好地捕捉到任务之间的关联性,从而提高模型在未见过的任务上的泛化能力。
### 优点:
- **灵活性**:P-tuning和P-tuning v2都提供了灵活的提示机制,使预训练模型能够适应不同的任务。
- **性能提升**:在Few-Shot场景下,这两种方法都能显著提高模型的性能。
- **减少对大量标注数据的依赖**:通过精心设计的提示,可以在没有大量标注数据的情况下训练模型。
### 缺点:
- **提示设计**:提示的设计对性能有很大影响,需要专业知识来设计有效的提示。
- **计算成本**:虽然P-tuning v2在参数效率上有所改进,但生成连续提示的额外神经网络可能会增加计算成本。
- **模型复杂性**:引入额外的可学习参数可能会增加模型的复杂性,使得训练和调试更加困难。
总的来说,P-tuning和P-tuning v2都是针对Few-Shot学习场景的有力工具,它们通过改进预训练模型的适应性来提高其在有限数据上的性能。P-tuning v2在P-tuning的基础上进一步提高了参数效率和泛化能力,但同时也带来了一些额外的计算成本和模型复杂性。
-
为什么SFT之后感觉LLM表现变差?
在进行了监督微调(Supervised Fine-Tuning,SFT)之后,如果感觉大型语言模型(Large Language Models,LLMs)的表现变差,可能是由以下几个原因造成的:
1. **过拟合**:SFT通常是在一个比预训练数据集小得多的特定任务数据集上进行的。这可能会导致模型过拟合,即模型学会了特定数据集的细节,而失去了泛化到新数据或不同任务的能力。过拟合的模型在训练数据上表现良好,但在未见过的数据上表现不佳。
2. **数据质量**:SFT的效果很大程度上取决于微调时使用的数据质量。如果微调数据包含错误、噪声或不相关的信息,模型可能会学习这些不良模式,从而导致性能下降。
3. **数据分布偏移**:如果微调数据与模型预训练时使用的数据分布不一致,模型可能难以适应新的分布。这种分布偏移会导致模型在新数据上的性能下降。
4. **灾难性遗忘**:在SFT过程中,模型可能会“忘记”在预训练阶段学到的知识,尤其是当微调数据量较小或与预训练任务差异很大时。这种现象被称为灾难性遗忘。
5. **微调策略不当**:微调策略,包括学习率、批次大小、训练轮数等,都需要根据具体任务和数据集进行调整。如果微调策略选择不当,可能会导致模型性能下降。
6. **模型复杂性**:对于非常复杂的模型,微调可能需要更多的数据和更精细的调整策略。如果这些条件没有得到满足,模型可能会出现性能下降的情况。
为了解决这些问题,可以尝试以下方法:
- **使用更多的数据**:增加微调数据量可以帮助模型更好地泛化。
- **数据增强**:通过数据增强技术,如回译、同义词替换等,可以增加数据的多样性。
- **正则化技术**:应用正则化,如权重衰减、dropout等,可以减少过拟合。
- **学习率调度**:使用适当的学习率调度策略,如预热和衰减,可以帮助模型更好地收敛。
- **微调策略调整**:根据任务和数据集的特点调整微调策略。
- **模型集成**:使用多个模型的集成可能有助于提高性能。
总之,SFT之后模型性能下降可能是由于多种因素造成的。理解这些因素并采取相应的措施可以帮助改善模型的表现。
-
垂直领域数据训练后,通用能力往往会有所下降,如何缓解模型遗忘通用能力?
在垂直领域数据上训练模型后,确实可能会出现模型在通用领域的能力下降的现象,这被称为“灾难性遗忘”(catastrophic forgetting)。为了缓解这一问题,可以采取以下几种策略:
1. **连续学习(Continual Learning)**:
- **弹性权重共享(Elastic Weight Consolidation, EWC)**:通过在模型更新时施加惩罚,保留对旧任务重要的权重。
- **经验重放(Experience Replay)**:存储旧任务的样本并在学习新任务时重放,以保持模型对旧任务的能力。
- **梯度裁剪(Gradient Clipping)**:限制梯度的大小,以减少对旧任务参数的影响。
2. **多任务学习(Multi-Task Learning)**:
- 同时训练模型在多个任务上表现良好,这样模型可以学习到不同任务之间的通用特征。
3. **参数隔离(Parameter Isolation)**:
- 为不同任务或领域分配不同的模型参数,确保在一个领域上的更新不会影响到其他领域。
4. **动态扩展(Dynamic Expansion)**:
- 随着新任务的加入,动态增加模型的容量,以容纳新的知识和保持旧知识。
5. **任务特定适配器(Task-Specific Adapters)**:
- 在预训练模型的顶部添加小的适配器模块,这些适配器专门为新任务学习,而不改变预训练模型的参数。
6. **提示引导(Prompt Tuning)**:
- 使用提示工程来引导模型在新任务上的表现,同时保持其通用能力。
7. **知识蒸馏(Knowledge Distillation)**:
- 将大型模型的知识蒸馏到一个小型模型中,这样小型模型可以保留大型模型的大部分能力。
8. **周期性复习(Periodic Review)**:
- 定期在通用数据上对模型进行微调,以刷新其通用知识。
9. **领域自适应(Domain Adaptation)**:
- 使用领域自适应技术,如对抗性训练,使模型能够在新领域上泛化,同时保留在源领域上学到的知识。
10. **元学习(Meta-Learning)**:
- 通过元学习训练模型,使其能够快速适应新任务,同时保持对旧任务的知识。
选择哪种策略取决于具体的应用场景、可用的数据和资源。在实际应用中,可能需要组合多种策略以达到最佳效果。
-
进行SFT操作的时候,基座模型选用Chat还是Base?
在进行监督微调(Supervised Fine-Tuning,SFT)操作时,选择基座模型(backbone model)的版本(如 Chat 或 Base)取决于多个因素,包括你的具体任务需求、可用资源、以及对模型性能的期望。以下是一些选择基座模型时可能考虑的因素:
1. **性能需求**:如果任务需要更高的语言理解能力和生成质量,通常选择更大、更先进的模型版本(如 Chat)。这些模型通常在更多的数据上进行了预训练,并可能包含了一些额外的训练技巧或架构改进。
2. **计算资源**:较大的模型需要更多的计算资源进行微调。如果你的计算资源有限,选择一个较小的 Base 版本可能更合适。这将减少训练时间和成本,同时也可能减少过拟合的风险。
3. **数据量**:如果你的微调数据集较小,使用一个较小的 Base 模型可能更合适,因为较大的模型可能会在小型数据集上过拟合。
4. **泛化能力**:在某些情况下,较小的 Base 模型可能具有更好的泛化能力,尤其是在预训练数据和微调数据之间存在较大分布偏移时。
5. **应用场景**:考虑你的应用场景。如果模型将在对生成质量要求不高的场景中使用,如聊天机器人或简单的文本分类任务,Base 模型可能就足够了。如果应用场景要求更高的语言理解能力和创造性,如撰写文章或生成代码,则可能需要 Chat 版本。
6. **成本和预算**:较大的模型可能需要更高的运行成本,包括计算资源和能源消耗。如果你的预算有限,这可能会影响你的选择。
在实际操作中,你可能需要根据上述因素进行权衡,并可能需要通过实验来确定哪个版本的模型在你的特定任务上表现最佳。通常,从 Base 版本开始进行初步实验是一个不错的选择,因为它的资源需求较低。如果你发现 Base 版本无法满足你的性能需求,再考虑升级到 Chat 版本。
-
领域模型词表扩增是不是有必要?
领域模型词表扩增是一个根据特定应用场景需求来决定的过程。在某些情况下,扩增词表是有必要的,而在其他情况下则可能不是必需的。以下是一些考虑因素:
### 需要进行词表扩增的情况:
1. **领域特定词汇**:如果模型需要处理特定领域的文本,如医学、法律或工程等专业领域,其中包含大量的专业术语和缩写,那么扩增词表以确保模型能够理解这些术语是有益的。
2. **新词或流行词汇**:随着时间的推移,新的词汇和流行词汇会不断出现。对于需要处理最新数据的模型,更新词表以包含这些新词是必要的。
3. **多语言或方言**:对于需要处理多种语言或方言的模型,扩增词表以包含不同语言和方言的词汇是重要的。
4. **提高准确性**:在某些情况下,扩增词表可以提高模型的准确性,尤其是在处理那些具有大量未知词汇的文本时。
### 不需要进行词表扩增的情况:
1. **通用模型**:如果模型是为了处理通用的日常语言而设计的,且已经包含了足够丰富的词汇量,那么扩增词表可能不是必要的。
2. **资源限制**:扩增词表可能会增加模型的复杂性和资源需求,如内存和处理时间。如果资源有限,可能需要权衡是否扩增词表。
3. **数据分布**:如果训练数据和实际应用场景中的数据分布相似,且已经包含了所有必要的词汇,那么扩增词表可能不是必需的。
### 词表扩增的方法:
如果决定扩增词表,可以采用以下方法:
- **基于频率的筛选**:根据领域数据中的词汇频率,选择出现频率较高的词汇加入词表。
- **专业词典和术语库**:利用专业词典和术语库来扩增词表,确保覆盖领域内的专业术语。
- **用户反馈**:根据用户的反馈和实际应用中的错误来识别缺失的词汇,并动态地更新词表。
总之,是否进行领域模型词表扩增取决于模型的应用场景和需求。在做出决定时,需要权衡模型的性能、资源限制和实际应用中的数据分布。
-
训练中文大模型的经验和方法
训练中文大型模型需要大量的数据、计算资源和精细的工程实践。以下是一些训练中文大型模型的经验和方法:
1. **数据收集与处理**:
- **数据质量**:确保训练数据的质量。低质量或错误的数据可能会导致模型学习不良模式。
- **数据多样性**:使用来自不同来源、不同风格和不同主题的数据,以提高模型的泛化能力。
- **数据清洗**:去除噪声、重复和无关的内容,以及可能的敏感信息。
- **数据平衡**:确保数据在不同类别或任务上平衡,以避免模型偏向某一类别。
2. **模型选择**:
- **预训练模型**:可以选择一个已经在大量中文数据上预训练的模型作为起点,如BERT、GPT等。
- **模型架构**:根据任务需求选择合适的模型架构,如Transformer、RNN等。
3. **训练策略**:
- **学习率调度**:使用适当的学习率调度策略,如预热、衰减等,以帮助模型稳定收敛。
- **正则化**:应用正则化技术,如权重衰减、dropout等,以减少过拟合。
- **梯度裁剪**:对于非常深的模型,梯度裁剪有助于稳定训练过程。
- **批量大小**:根据GPU内存和模型大小选择合适的批量大小。
4. **评估与调试**:
- **监控训练指标**:定期评估模型在验证集上的性能,以便及时发现潜在的过拟合或其他问题。
- **错误分析**:分析模型在验证集上的错误,以指导后续的训练和调整。
5. **资源管理**:
- **分布式训练**:使用分布式训练技术,如数据并行、模型并行等,以加快训练速度和处理大型模型。
- **硬件选择**:根据模型大小和预算选择合适的硬件,如GPU或TPU。
6. **微调与适应**:
- **任务特定微调**:在特定任务上对模型进行微调,以提高其在特定领域的性能。
- **迁移学习**:利用在相关任务上预训练的模型,通过迁移学习来提高模型在新任务上的性能。
7. **合规性与伦理**:
- **数据合规性**:确保训练数据的使用符合相关法律法规和伦理标准。
- **模型输出控制**:采取措施确保模型输出不会产生有害或不适当的内容。
训练中文大型模型是一个复杂的过程,需要跨学科的知识和技能。在实践中,可能需要多次实验和调整,以找到最佳的训练策略和模型配置。此外,随着技术的发展,新的训练技术和方法也在不断涌现,因此保持对新技术的关注和学习也是提高模型性能的关键。
-
模型微调用的什么模型?模型参数是多少?微调模型需要多大显存?
模型微调通常是指在预训练模型的基础上,使用特定领域的数据对模型进行进一步的训练,以适应特定的任务或领域。微调使用的模型类型和参数数量取决于多种因素,包括预训练模型的选择、目标任务的需求、可用的计算资源等。
### 常用的预训练模型:
1. **BERT (Bidirectional Encoder Representations from Transformers)**:Google开发的预训练模型,有多种尺寸,如BERT-Base有1.1亿参数,BERT-Large有3.4亿参数。
2. **RoBERTa (A Robustly Optimized BERT Pretraining Approach)**:Facebook开发的BERT变体,也有多种尺寸,如RoBERTa-Base有1.35亿参数,RoBERTa-Large有3.5亿参数。
3. **GPT (Generative Pretrained Transformer)**:OpenAI开发的生成型预训练模型,GPT-3是其第三代,有1750亿参数。
4. **XLNet (Generalized Autoregressive Pretraining for Language Understanding)**:CMU和Google开发的模型,XLNet-Large有2.25亿参数。
5. **ALBERT (A Lite BERT)**:Google开发的轻量级BERT变体,ALBERT-xxlarge有12亿参数。
### 微调模型需要的显存:
显存需求取决于以下几个因素:
1. **模型大小**:更大的模型需要更多的显存来存储模型参数和中间激活。
2. **批量大小(Batch Size)**:批量大小决定了每次迭代中处理的样本数量,批量越大,显存需求越高。
3. **序列长度(Sequence Length)**:输入序列越长,显存需求也越高。
4. **显存优化技术**:如梯度累积、混合精度训练等可以减少显存使用。
例如,微调一个BERT-Base模型,如果使用批量大小为32,序列长度为128,那么在单精度浮点数(FP32)下,大约需要4-6GB的显存。如果是BERT-Large模型,同样的设置可能需要12-16GB的显存。这些估计值是大致数字,实际显存需求可能会根据具体的实现细节和深度学习框架有所不同。
为了确保微调过程顺利进行,建议使用具有足够显存的显卡,并根据实际情况调整批量大小和序列长度,或者采用显存优化技术来降低显存需求。
-
预训练和SFT操作有什么不同?
预训练(Pre-training)和监督微调(Supervised Fine-Tuning,SFT)是深度学习模型训练中的两个不同阶段,它们在目标、数据使用和训练方法上有所区别:
1. **目标**:
- **预训练**:预训练的目的是让模型学习到通用的语言特征和知识,以便在后续的任务中能够快速适应。预训练通常在大规模、多样化的语料库上进行,如维基百科、书籍、新闻文章等。
- **SFT**:监督微调的目标是针对特定的任务或领域,对预训练模型进行进一步的训练,使其能够更好地解决这些具体的问题。SFT通常在特定任务的有标签数据集上进行。
2. **数据使用**:
- **预训练**:使用的是无标签或弱标签的数据,模型通过自监督学习任务(如语言建模、掩码语言建模、下一句预测等)来学习语言规律。
- **SFT**:使用的是与特定任务相关的有标签数据,模型通过有监督的学习来优化针对该任务的性能。
3. **训练方法**:
- **预训练**:模型从随机初始化开始,通过大量的数据学习语言的深层表示。这个阶段的训练通常需要大量的计算资源和时间。
- **SFT**:模型基于预训练的权重进行微调,只需要调整模型的部分参数,通常在较小的数据集上进行训练。这个阶段的训练计算成本较低,时间也相对较短。
4. **模型调整**:
- **预训练**:模型可能会经历多个阶段的预训练,每个阶段都可能会调整模型结构或训练目标。
- **SFT**:在微调阶段,模型的架构通常保持不变,但最后一层或几层的输出层会根据任务的特定需求进行调整,如分类任务的输出层神经元数量会与类别数相匹配。
总结来说,预训练是让模型学习通用知识的过程,而SFT是在特定任务上对模型进行定制化的过程。预训练提供了模型泛化的基础,而SFT则优化了模型在特定任务上的性能。在实际应用中,这两个阶段通常是相互补充的,预训练模型通过SFT来适应各种下游任务。
-
训练一个通用大模型的流程有哪些?
训练一个通用大模型(如BERT、GPT等)是一个复杂的过程,涉及到大量的数据预处理、模型设计、训练、评估和调优。以下是训练通用大模型的一般流程:
1. **需求分析**:
- 确定模型的目标应用场景和性能指标。
- 分析所需的计算资源和预计的训练时间。
2. **数据收集**:
- 收集大量的文本数据,这些数据通常来自互联网,包括书籍、文章、网页等。
- 确保数据多样性和质量,避免偏见和版权问题。
3. **数据预处理**:
- 清洗数据:去除噪声、错误和不相关的信息。
- 分词:将文本分割成单词、子词或字符。
- 标记化:将文本转换为模型可以理解的数字表示形式。
- 数据增强:通过诸如词替换、句子重组等方法增加数据的多样性。
4. **模型设计**:
- 选择合适的模型架构,如Transformer。
- 确定模型的超参数,如层数、隐藏单元数、注意力头的数量等。
5. **预训练**:
- 使用无监督或自监督学习方法对模型进行预训练。
- 选择预训练任务,如掩码语言模型(MLM)、下一句预测(NSP)等。
- 在大型计算集群上训练模型,这可能需要几天到几周的时间。
6. **模型评估**:
- 在预训练完成后,使用一组标准的评估任务来评估模型的性能。
- 评估指标可能包括语言理解、文本生成、句子分类等。
7. **微调**:
- 使用特定领域的标注数据对模型进行微调,以适应特定的任务。
- 微调可能涉及到调整模型的部分层或添加新的输出层。
8. **模型调优**:
- 根据微调的结果调整超参数和训练策略。
- 使用交叉验证、网格搜索等方法找到最佳的超参数组合。
9. **模型部署**:
- 将训练好的模型部署到生产环境中。
- 实现模型的推理接口,以便在实际应用中使用。
10. **监控和维护**:
- 监控模型的性能和稳定性。
- 定期使用新数据对模型进行再训练或微调,以保持模型的时效性。
训练通用大模型是一个迭代的过程,可能需要多次调整和优化才能达到满意的性能。此外,由于训练大模型需要大量的计算资源,因此通常需要使用分布式训练和高效的计算技术来加速训练过程。
-
DDO 与 DPO 的区别是什么?
DDO 和 DPO 是两个不同的概念,分别代表数据驱动运营(Data-Driven Operations)和数据保护官(Data Protection Officer)。
**数据驱动运营(DDO)**:
数据驱动运营是一种管理实践,它依赖于数据分析来指导业务决策和运营流程。在这种模式下,组织使用数据来优化流程、提高效率、降低成本、增强客户体验和增加收入。数据驱动运营通常涉及以下几个方面:
- 数据收集:从各种来源收集相关数据。
- 数据分析:使用统计分析、数据挖掘和机器学习技术来分析数据。
- 决策支持:基于数据分析的结果来做出更明智的决策。
- 执行与优化:根据数据分析的洞察来执行操作并不断优化流程。
**数据保护官(DPO)**:
数据保护官是欧盟通用数据保护条例(GDPR)引入的一个角色,主要负责确保组织在处理个人数据时遵守相关的数据保护法规。DPO的职责包括:
- 监督和指导组织的数据保护合规工作。
- 为组织提供关于数据保护法律和政策的专业建议。
- 管理个人数据泄露的响应和通知过程。
- 作为监管机构和数据主体之间的联络点。
总结来说,DDO关注的是如何利用数据来改善业务运营和决策,而DPO则是一个法律合规角色,负责确保组织在处理个人数据时遵守相关的数据保护法规。两者都与数据相关,但关注的焦点和应用领域不同。
-
embeding 模型的微调方法
嵌入模型(embedding models)的微调是自然语言处理(NLP)和推荐系统等领域的常见做法。嵌入模型通常用于将单词、句子、文档或其他类型的数据映射到高维空间中的低维向量,其中相似的实体在向量空间中彼此靠近。
嵌入模型的微调方法通常包括以下步骤:
1. **预训练嵌入**:
- 使用大规模语料库通过无监督学习(如Word2Vec、GloVe)或预训练模型(如BERT)来训练嵌入。
2. **初始化模型**:
- 使用预训练的嵌入作为模型的一部分来初始化,例如,将单词嵌入作为神经网络的第一层。
3. **冻结嵌入**:
- 在微调过程的初期,可能选择冻结嵌入层,让模型的其他部分适应特定任务。
- 这有助于避免在训练数据较少时过拟合,并利用预训练嵌入的通用性。
4. **部分微调**:
- 在某些情况下,可以选择只微调嵌入层的一部分,而不是所有的嵌入。
- 这可以通过设置不同的学习率或在某些嵌入上应用更小的权重更新来实现。
5. **完全微调**:
- 如果有足够的训练数据和计算资源,可以选择微调所有的嵌入,包括预训练的嵌入。
- 这允许模型调整嵌入以更好地适应特定任务。
6. **动态更新**:
- 对于一些在线学习场景,模型可能会动态地更新嵌入,以反映新的数据和趋势。
7. **评估和迭代**:
- 定期评估模型的性能,并根据需要调整微调策略。
- 可能需要多次迭代来找到最佳的微调方法。
微调嵌入模型的关键是找到预训练嵌入的通用性和特定任务数据之间的平衡。微调的目的是调整嵌入,使其在特定任务上表现更好,同时保留其在通用语言理解方面的优势。
-
有哪些节省内存的大语言模型训练/微调/推理方法?
在处理大型语言模型时,内存使用是一个重要的考虑因素。以下是一些减少内存使用的方法,这些方法可以应用于模型的训练、微调和推理阶段:
1. **模型剪枝**:
- **权重剪枝**:去除模型中不重要的权重,减少模型的参数数量。
- **注意力头剪枝**:在 Transformer 模型中,剪除一些注意力头。
2. **知识蒸馏**:
- 将一个大型模型(教师模型)的知识蒸馏到一个较小的模型(学生模型)中,从而减少内存占用。
3. **参数共享**:
- 在模型的不同部分之间共享参数,减少总体参数数量。
4. **低秩分解**:
- 使用低秩分解技术来减少参数的数量,例如 LoRA 微调方法。
5. **量化**:
- 将模型的权重和激活从浮点数转换为低比特宽度的整数,减少内存使用并可能加速推理。
6. **使用高效的模型架构**:
- 选择内存效率更高的模型架构,如 Longformer 或 Reformer,它们设计了特定的机制来减少注意力机制的内存和计算成本。
7. **层叠式训练**:
- 先训练模型的一部分,然后冻结这些参数,再训练其他部分。
8. **梯度检查点**:
- 在训练过程中,通过重新计算而非存储中间激活来节省内存。
9. **使用分布式训练**:
- 通过将模型分布在多个设备上,可以减少单个设备上的内存压力。
10. **动态推理**:
- 在推理时,根据输入动态调整模型的计算,例如,只处理输入文本的相关部分。
11. **优化数据加载和批处理**:
- 在训练时,优化数据加载和批处理过程,减少内存峰值。
12. **使用更高效的库和工具**:
- 使用为内存效率设计的深度学习库和工具,如 PyTorch 的内存优化功能。
13. **模型架构搜索(NAS)**:
- 使用自动化的方法来搜索内存效率更高的模型架构。
这些方法可以单独使用,也可以组合使用,以达到更好的内存优化效果。在实际应用中,选择哪种方法取决于具体的需求、资源和任务目标。
-
大模型(LLMs)评测有那些方法?如何衡量大模型的效果?
大模型(Large Language Models,LLMs)的评测通常涉及多个维度,包括模型的性能、泛化能力、鲁棒性、效率以及伦理和安全性等方面。以下是一些常用的评测方法和衡量效果的方式:
1. **性能指标**:
- **准确率**:对于分类任务,衡量模型正确分类的比例。
- **损失函数**:使用交叉熵损失、均方误差等来衡量模型输出与真实值之间的差距。
- **困惑度(Perplexity)**:衡量模型对语言数据的建模能力,通常用于语言模型。
2. **泛化能力**:
- **零样本学习(Zero-shot learning)**:评估模型在不提供特定任务样本的情况下处理新任务的能力。
- **少样本学习(Few-shot learning)**:评估模型在只提供少量样本的情况下学习新任务的能力。
- **跨领域泛化**:评估模型在不同领域数据上的表现。
3. **鲁棒性**:
- **对抗性测试**:评估模型对输入数据微小扰动的抵抗力。
- **稳健性**:评估模型在处理噪声数据、错误数据或异常值时的性能。
4. **效率指标**:
- **计算成本**:评估模型训练和推理所需的计算资源。
- **参数效率**:衡量模型性能与参数数量之间的关系。
- **推理速度**:评估模型处理单个样本的速度。
5. **伦理和安全性**:
- **偏见和公平性**:评估模型输出是否存在性别、种族、文化等偏见。
- **隐私保护**:评估模型在处理敏感数据时的隐私保护措施。
- **可解释性和透明度**:评估模型的决策过程是否可解释和透明。
6. **人类评估**:
- **人工评审**:使用人类评估者来评估模型的输出质量。
- **用户研究**:通过用户实验来评估模型在实际应用中的表现。
7. **标准和基准测试**:
- **GLUE (General Language Understanding Evaluation)**:一套用于评估自然语言理解能力的基准测试。
- **SuperGLUE (Super General Language Understanding Evaluation)**:GLUE的升级版,包含更具挑战性的任务。
- **SQuAD (Stanford Question Answering Dataset)**:用于评估机器阅读理解和问答能力的基准。
8. **特定任务评估**:
- **文本生成**:使用评价指标如BLEU、ROUGE、METEOR等来衡量生成文本的质量。
- **机器翻译**:使用评价指标如BLEU、TER (Translation Edit Rate)等来评估翻译质量。
衡量大模型的效果通常需要综合使用上述多种方法,并根据具体的应用场景和任务需求来选择合适的评价指标。此外,随着大模型的发展,新的评测方法和标准也在不断出现,以适应模型的进步和应用的多样化。
-
如何解决三个阶段的训练(SFT->RM->PPO)过程较长,更新迭代较慢问题?
三个阶段的训练流程——监督微调(Supervised Fine-Tuning,SFT)、奖励建模(Reward Modeling,RM)和近端策略优化(Proximal Policy Optimization,PPO)——是一个典型的强化学习(RL)任务流程,其中每个阶段都有其特定的目的和挑战。如果你发现这个过程较长,更新迭代较慢,可以考虑以下策略来加速训练:
1. **并行处理**:
- 在多个环境中并行运行模型,收集更多的数据用于训练。
- 使用并行计算资源,如GPU或TPU集群,来加速模型的训练和推理。
2. **批量训练**:
- 增加训练批次的大小,以利用现代GPU的并行处理能力。
3. **高效模型架构**:
- 使用内存和计算效率更高的模型架构,如Transformer的变体Longformer或Reformer。
4. **迁移学习和微调**:
- 使用预训练的模型作为起点,而不是从头开始训练,可以节省时间。
- 在新数据上微调模型,而不是完全重新训练。
5. **早期停止**:
- 实施早期停止策略,当模型性能不再显著提升时停止训练。
6. **周期性训练**:
- 定期对模型进行训练,而不是连续不断地训练,可以将训练时间分散到多个时间段。
7. **动态调整学习率**:
- 使用自适应学习率调整策略,如学习率衰减或循环学习率,以加速收敛。
8. **模型剪枝和量化**:
- 剪枝和量化模型可以减少模型的大小和计算需求,从而加速训练和推理。
9. **使用高效的优化器**:
- 选择合适的优化器,如AdamW或Adamax,它们可能比传统的SGD更快地收敛。
10. **数据预处理和增强**:
- 在训练前对数据进行预处理和增强,以提高模型的泛化能力和训练效率。
11. **分布式训练**:
- 使用分布式训练框架,如Ray或PyTorch Distributed,来同时训练多个模型或并行处理数据。
12. **选择性更新**:
- 只更新模型的一部分,而不是整个模型,可以减少每次迭代的计算量。
13. **使用预定义的任务和模板**:
- 对于特定的RL任务,使用预定义的任务和模板可以减少设计新任务所需的时间。
通过上述策略,你可以优化三个阶段的训练流程,减少每个阶段的训练时间,从而加快模型的更新和迭代速度。在实际应用中,可能需要根据具体的任务需求和可用资源,组合使用多种策略来达到最佳的训练效果。
-
模型训练的数据集问题:一般数据集哪里找?
获取模型训练数据集的途径有很多,具体取决于数据集的类型和应用领域。以下是一些常见的数据集来源:
1. **公共数据集**:
- **政府机构和学术机构**:许多政府机构和学术机构会公开大量的数据集,例如美国国家标准与技术研究院(NIST)、欧盟的开放数据门户等。
- **开放数据平台**:如Kaggle、Google Dataset Search、UCI Machine Learning Repository、AWS Public Dataset Program等提供各种领域的开放数据集。
2. **专业领域数据集**:
- **科研论文**:科研论文中经常包含数据集的描述和链接,尤其是那些发表在顶级会议和期刊上的论文。
- **专业社区和论坛**:如GitHub、ResearchGate等,研究人员和从业者会分享他们的数据和代码。
3. **社交媒体和网络爬虫**:
- **社交媒体平台**:如Twitter、Facebook等提供API接口,可以用于获取公共数据。
- **网络爬虫**:可以使用爬虫工具如Scrapy、BeautifulSoup等,从网站上爬取数据。
4. **商业数据集**:
- **数据交易平台**:如Acxiom、Experian等提供商业数据。
- **API服务**:如Twitter API、YouTube API等,提供丰富的数据资源。
5. **合作伙伴和私有数据**:
- **企业内部数据**:企业可能拥有自己的数据集,可以用于训练模型。
- **合作伙伴数据**:与其他公司或组织合作,共同开发数据集。
6. **数据竞赛和挑战**:
- **Kaggle、Drivendata等平台**:举办各种数据科学和机器学习竞赛,提供数据集供参赛者使用。
7. **开源项目**:
- **GitHub**:许多开源项目会附带数据集,或者提供获取数据集的指南。
在选择数据集时,需要考虑数据的质量、大小、多样性、覆盖范围、标注情况以及使用许可等因素。此外,还需要确保数据的使用符合相关的法律法规和伦理标准。对于特定的研究领域或应用场景,可能还需要对数据集进行进一步的预处理和清洗以满足模型训练的需求。
-
为什么需要进行模型量化及原理?
模型量化是一种将模型的权重和/或激活从浮点数(通常是32位或16位浮点数)转换为低比特宽度的整数(如8位、4位或2位整数)的技术。这种转换可以显著减少模型的内存占用和计算成本,同时在保持可接受性能的情况下,提高模型的推理速度。以下是一些进行模型量化的原因和基本原理:
### 为什么要进行模型量化?
1. **减少内存占用**:
- 量化可以减少模型的大小,因为整数占用的空间比浮点数少。这对于需要在内存受限的设备上部署模型非常有用。
2. **提高推理速度**:
- 整数运算通常比浮点运算快,尤其是在没有专门浮点运算单元的硬件上。量化后的模型可以在更短的时间内完成推理。
3. **降低功耗**:
- 低比特宽度的整数运算通常需要更少的能量,这使得量化模型在移动设备上更加节能。
4. **硬件优化**:
- 一些硬件平台(如ASIC、FPGA)针对整数运算进行了优化,量化可以使模型更好地利用这些平台的性能。
### 模型量化的原理
模型量化基于以下原理:
1. **数值范围限定**:
- 通过将浮点数的范围映射到整数范围,例如将[-1, 1]区间映射到[-128, 127](对于8位量化)。
2. **量化级别**:
- 量化级别定义了可表示的值的数量。例如,8位量化有256个不同的值,而16位量化有65536个不同的值。
3. **量化粒度**:
- 量化粒度是两个可表示值之间的差值。在8位量化中,量化粒度是1/256。
4. **量化误差**:
- 量化引入了量化误差,因为浮点数被近似为最接近的整数。量化误差的管理是量化过程中的关键。
5. **校准**:
- 在量化之前,通常需要进行校准步骤,以确定最佳的量化参数,如缩放因子和零点偏移。
6. **对称与非对称量化**:
- 对称量化将零点设置在量化范围的中间,而非对称量化允许零点不在中间,这可以提供更好的数值表示。
模型量化可以在训练后或训练过程中进行。后训练量化(Post-Training Quantization,PTQ)是在模型训练完成后进行的,而量化感知训练(Quantization-Aware Training,QAT)是在训练过程中结合量化操作进行的,以优化模型的量化性能。
总之,模型量化是一种有效的技术,可以在不显著牺牲性能的情况下,减少模型的内存占用和推理延迟,使其更适合在资源受限的环境中部署。
-
大模型词表扩充的方法及工具?
大模型的词表扩充是一个重要的步骤,尤其是在处理特定领域的文本或新词、流行词时。以下是一些常用的方法和工具:
### 方法:
1. **频率筛选**:
- 从大量文本中统计单词的频率,选择出现频率较高的单词加入词表。
2. **专业词典和术语库**:
- 利用专业领域的词典和术语库,将专业术语添加到词表中。
3. **用户反馈和错误分析**:
- 根据用户的反馈和模型在实际应用中的错误,识别缺失的词汇并更新词表。
4. **在线词表和语料库**:
- 利用在线词表和语料库,如WordNet、HowNet等,来扩充词表。
5. **子词和字符分割**:
- 对于未知单词,可以将其分解为子词或字符,以便模型能够处理。
### 工具:
1. **Hugging Face Transformers**:
- Hugging Face的Transformers库提供了词表扩充的功能,可以通过简单的API调用实现。
2. **spaCy**:
- spaCy是一个自然语言处理库,它提供了自定义词表的工具,可以方便地添加新词。
3. **NLTK (Natural Language Toolkit)**:
- NLTK是一个自然语言处理平台,提供了丰富的文本处理功能,包括词表扩充。
4. **gensim**:
- gensim是一个用于主题建模和词向量处理的Python库,它可以用来扩充词表。
5. **Vocabulary Builder**:
- 一些专门的词汇构建工具,可以帮助从文本中提取和分析词汇,用于词表扩充。
6. **自定义脚本**:
- 编写自定义的Python脚本,使用正则表达式、文本处理库(如re、BeautifulSoup)等来识别和提取新词。
在实际操作中,词表扩充通常需要结合多种方法和工具,以实现最佳的扩充效果。同时,需要注意词表的大小和模型的能力,过大的词表可能会导致模型效率降低。
大模型应用框架
-
什么是 LangChain?
LangChain 是一个开源的框架,旨在帮助开发者和企业构建、部署和运行基于语言模型的应用程序。它提供了一套工具和接口,用于轻松地整合大型语言模型(如 GPT-3、ChatGPT、LLaMA 等)和其他数据源(如数据库、API、文档等),以创建复杂的、交互式的语言应用。
LangChain 的主要特点包括:
1. **模型集成**:LangChain 支持多种语言模型的集成,包括 OpenAI 的 GPT-3、Hugging Face 的模型、以及自定义模型。
2. **工具集成**:LangChain 可以与各种工具和数据库集成,使得语言模型能够利用外部信息来生成更准确和有用的回答。
3. **链式思考**:LangChain 支持链式思考,即模型可以分步执行任务,每次只处理一部分信息,然后将结果传递给下一步,这在处理复杂任务时非常有用。
4. **内存管理**:LangChain 提供了内存管理功能,允许模型在对话中保持上下文记忆,这对于保持对话的一致性和连贯性至关重要。
5. **可扩展性**:LangChain 设计为可扩展的,开发者可以根据需要添加自定义功能或集成其他系统。
6. **易于部署**:LangChain 提供了简单的部署选项,支持在本地、云服务器或容器化环境中运行模型应用程序。
7. **开源社区**:作为一个开源项目,LangChain 拥有一个活跃的社区,提供大量的教程、示例和文档,以帮助开发者快速上手和使用。
LangChain 适用于各种应用场景,如聊天机器人、客户支持、数据分析、内容创作等,它简化了构建基于语言模型的应用程序的过程,使得开发者能够更加专注于应用的功能和用户体验。
-
什么是 LangChain Agent?
LangChain Agent是一个开源的框架,旨在将大型语言模型(如 GPT-3、GPT-4 等)与各种工具和API连接起来,以执行更复杂的任务。LangChain Agent通过自然语言与用户交互,并能够使用工具来获取信息、进行计算或执行其他操作,从而更好地理解用户的请求并给出更准确的回答。
LangChain Agent的核心思想是将语言模型作为决策者(agent),使用外部工具来增强其能力。例如,如果用户询问某个数据点的信息,LangChain Agent可以调用相应的API来获取数据,而不是仅依靠语言模型本身的知识。
LangChain Agent的主要特点包括:
1. **工具集成**:可以轻松地将各种工具和API集成到语言模型中,使其能够利用这些工具来执行任务。
2. **自然语言处理**:与用户的交互完全通过自然语言进行,用户无需了解任何特定的命令或查询格式。
3. **灵活性和可扩展性**:用户可以根据需要添加或自定义工具,以适应不同的应用场景。
4. **上下文保持**:LangChain Agent能够在对话中保持上下文,这意味着它可以记住之前的交互并在此基础上进行后续的操作。
5. **开源和社区支持**:作为一个开源项目,LangChain Agent拥有一个活跃的社区,用户可以共享和贡献新的工具、模型和改进。
总的来说,LangChain Agent是一个强大的框架,它将大型语言模型与外部工具和API结合起来,使其能够执行更复杂的任务,并为用户提供更丰富和准确的信息。
-
什么是 LangChain model?
"LangChain model" 可能是指在使用 LangChain 框架时所使用的语言模型。
LangChain 是一个开源框架,用于构建和运行基于语言模型的应用程序。在这个框架中,你可以使用各种语言模型,如 OpenAI 的 GPT-3、GPT-3.5、GPT-4,或者 Hugging Face 的transformers库中的模型。这些模型可以是预训练的模型,也可以是经过特定任务微调的模型。
在 LangChain 中,你可以将语言模型与其他工具和数据库集成,以创建能够执行复杂任务的应用程序。例如,你可以使用语言模型来分析文本数据,然后使用其他工具来根据分析结果执行特定操作。
总之,"LangChain model" 可能指的是在 LangChain 框架中使用的大型语言模型,用于处理和生成文本数据。这些模型可以是开源的,也可以是商业的,具体取决于你的应用需求和资源。
-
除了 LangChain 外的其他框架?
除了LangChain,还有其他几个框架和平台也致力于将大型语言模型(LLMs)与外部工具和API结合起来,以提高模型的实用性和执行复杂任务的能力。以下是一些其他著名的框架:
1. **AgentGPT**:
- AgentGPT是一个开源项目,它允许用户创建自主的AI代理,这些代理可以使用互联网上的工具和资源来执行任务。AgentGPT利用GPT-3.5模型来生成自然语言指令,并使用这些指令与工具交互。
2. **OpenAI Gym**:
- OpenAI Gym是一个用于开发和比较强化学习算法的工具包。它提供了多种环境,其中一些环境可以与语言模型结合使用,以训练模型在特定任务中的行为。
3. **AutoGPT**:
- AutoGPT是一个实验性的开源项目,它旨在创建一个具有高级推理能力的自主AI代理。AutoGPT使用GPT-4模型来规划、执行和评估行动,以实现特定的目标。
4. **Hex**:
- Hex是一个由DeepMind开发的语言模型指令微调框架,它允许模型通过自然语言与外部工具交互。Hex使用强化学习来训练模型,使其能够有效地使用工具来解决复杂问题。
5. **Toolformer**:
- Toolformer是一种新型的语言模型架构,它集成了对工具的使用。Toolformer在模型内部直接嵌入工具,使模型能够自主地决定何时使用哪些工具来辅助回答问题。
这些框架和平台各有特点,但它们都共享一个目标:通过将语言模型与外部工具和API结合使用,提高模型的实用性和执行复杂任务的能力。用户可以根据具体的需求和偏好选择合适的框架。
-
基于LangChain 搭建大模型应用的经验
LangChain 是一个开源的框架,用于构建和运行基于语言模型的应用程序。以下是一些基于 LangChain 搭建大模型应用的经验和建议:
1. **选择合适的模型**:
- 根据你的应用需求选择合适的大型语言模型。你可以选择预训练的模型,如 GPT-3、GPT-3.5 或 GPT-4,或者使用 Hugging Face 的transformers库中的模型。
- 考虑微调模型以适应特定任务,以提高模型在特定领域的性能。
2. **安装和配置 LangChain**:
- 确保你的开发环境已经安装了 LangChain 所需的依赖库和工具。
- 根据你的需求配置 LangChain 的参数,如模型路径、输入输出格式等。
3. **集成外部工具和数据库**:
- 利用 LangChain 的集成能力,将语言模型与其他工具和数据库连接起来。这可以提供额外的数据和功能,以增强语言模型的应用。
- 例如,你可以将语言模型与知识图谱、数据库或 API 集成,以获取更多相关信息并生成更准确和有用的回答。
4. **实现链式思考**:
- 利用 LangChain 的链式思考功能,使语言模型能够分步执行任务,每次只处理一部分信息,然后将结果传递给下一步。这有助于处理复杂任务,并保持对话的一致性和连贯性。
5. **优化性能**:
- 考虑使用模型量化、剪枝等技术来优化语言模型的性能。这可以减少模型的内存占用和计算成本,提高推理速度。
- 使用高效的编程语言和框架,如 Python 和 PyTorch,来加速模型的开发和部署。
6. **测试和评估**:
- 在开发过程中,定期测试和评估语言模型的性能。这有助于发现潜在的问题并改进模型的表现。
- 考虑使用自动化测试工具和性能监控工具来确保模型的稳定性和可靠性。
7. **部署和维护**:
- 使用适当的部署策略,如容器化、微服务架构等,将语言模型应用程序部署到生产环境。
- 定期维护和更新语言模型,以适应新的需求和数据变化。
请注意,基于 LangChain 搭建大模型应用的具体步骤和经验可能会因应用需求和环境的不同而有所差异。建议参考 LangChain 的官方文档和社区资源,以获取更多具体的指导和示例。
-
搭建大模型应用遇到过的问题和解决方法
在搭建大模型应用时,可能会遇到各种问题和挑战。以下是一些常见的问题以及可能的解决方案:
1. **计算资源限制**:
- **问题**:大型模型需要大量的计算资源,如 GPU 或 TPU。如果资源有限,训练和推理可能会非常缓慢。
- **解决方案**:使用分布式训练和推理,将任务分配给多个设备;使用云服务提供商的计算资源;采用模型剪枝、量化等技术减小模型大小。
2. **模型优化困难**:
- **问题**:大型模型的结构和参数复杂,优化起来比较困难。
- **解决方案**:使用模型压缩技术,如知识蒸馏、低秩分解等,来简化模型;采用量化感知训练(QAT)来优化模型的量化性能。
3. **数据不足**:
- **问题**:训练大型模型通常需要大量的数据,但数据可能难以获取或标注。
- **解决方案**:使用迁移学习,利用预训练模型在大规模数据集上学到的知识;使用数据增强技术,如回译、同义词替换等,来增加数据多样性。
4. **模型泛化能力差**:
- **问题**:模型可能对训练数据过度拟合,导致泛化能力差。
- **解决方案**:增加训练数据量,提高数据多样性;应用正则化技术,如权重衰减、dropout等;使用交叉验证等技术来评估模型泛化能力。
5. **模型更新迭代慢**:
- **问题**:大型模型的训练和评估可能非常耗时,导致更新迭代速度慢。
- **解决方案**:使用高效的训练策略,如批处理大小调整、学习率调度等;实施早期停止策略,避免不必要的迭代。
6. **部署和维护复杂**:
- **问题**:大型模型在部署和维护时可能面临各种挑战,如资源管理、性能监控等。
- **解决方案**:采用容器化技术,如 Docker,来简化部署和维护;使用自动化工具来监控模型性能和资源使用情况。
7. **模型安全性和可解释性**:
- **问题**:大型模型可能产生不安全或不合理的输出,同时其内部运作可能难以解释。
- **解决方案**:实施模型监控和审计策略,确保输出符合预期;使用可解释性技术,如注意力机制可视化等,来分析模型决策过程。
在解决这些问题的过程中,通常需要跨学科的知识和技能,包括数据科学、软件工程和机器学习等。此外,与团队合作、持续学习和关注行业最佳实践也是成功搭建大型模型应用的关键。
-
如何提升大模型的检索效果?
提升大模型在检索任务中的效果可以通过以下几个方面进行:
1. **优化模型架构**:
- **问题**:模型的架构可能不适合所有类型的检索任务。
- **解决方案**:选择或设计适合特定检索任务的模型架构,如基于Transformer的模型,它们在处理序列数据时表现出色。
2. **改进检索策略**:
- **问题**:简单的匹配或排序算法可能不足以处理复杂的检索任务。
- **解决方案**:采用更先进的检索策略,如向量检索(如BERT-based models)、基于语义的检索等。
3. **优化查询和文档表示**:
- **问题**:查询和文档的表示可能不足以捕捉其语义内容。
- **解决方案**:使用预训练语言模型或其他NLP技术来增强查询和文档的表示。
4. **引入外部知识**:
- **问题**:模型可能无法从有限的训练数据中学习到足够的信息。
- **解决方案**:使用外部知识源,如知识图谱、外部数据库或API,来增强模型的背景知识。
5. **多模态检索**:
- **问题**:如果检索任务涉及多种类型的数据(如文本、图像、视频等)。
- **解决方案**:采用多模态检索方法,将不同类型的数据融合在一起,以提高检索效果。
6. **训练和评估**:
- **问题**:模型的训练和评估可能不充分,导致其在实际应用中表现不佳。
- **解决方案**:使用大规模、多样化的数据集进行训练,确保模型能够处理各种查询和文档;实施严格的评估策略,确保模型的性能在各种情况下都能保持稳定。
7. **调整超参数和训练策略**:
- **问题**:超参数和训练策略的选择可能影响模型的性能。
- **解决方案**:尝试不同的超参数设置和训练策略,如学习率、批次大小、正则化技术等,以找到最佳的配置。
8. **模型压缩和加速**:
- **问题**:大型模型可能需要大量的计算资源,导致训练和推理速度慢。
- **解决方案**:采用模型压缩和加速技术,如知识蒸馏、模型剪枝、量化等,以减小模型大小并提高推理速度。
9. **用户反馈和迭代**:
- **问题**:模型可能无法满足所有用户的需求。
- **解决方案**:收集用户反馈,并根据反馈进行模型的迭代和优化。
10. **遵守伦理和合规性**:
- **问题**:模型的应用可能涉及敏感数据或不当行为。
- **解决方案**:确保模型的应用符合相关的伦理和合规性要求,如数据隐私保护、公平性和透明度等。
提升大模型在检索任务中的效果需要综合考虑多个因素,并根据具体任务的需求进行调整。通过不断实验和优化,可以提高模型的性能,并使其更好地满足实际应用的需求。
-
上下文压缩方法
上下文压缩方法是自然语言处理和机器学习领域中用于处理长序列的一种技术。在处理非常长的文本或者对话时,由于模型输入长度的限制,我们不能将整个上下文都作为输入。上下文压缩方法就是为了解决这个问题,它可以在不损失重要信息的情况下,将长序列压缩成更短的形式。以下是一些常见的上下文压缩方法:
1. **滑动窗口**:
- 选择一个固定大小的窗口,只将窗口内的文本作为输入。当处理新的文本时,窗口在文本上滑动,以便包含最新的信息和一部分历史信息。
2. **注意力机制**:
- 使用注意力机制来赋予不同部分的文本不同的权重,这样模型可以更多地关注对当前任务重要的部分,而不仅仅是最近的输入。
3. **关键信息提取**:
- 通过提取摘要、关键词或关键句子来压缩文本。这可以手动完成,也可以使用自动摘要或关键词提取算法。
4. **稀疏注意力**:
- 稀疏注意力机制只关注输入序列中的一小部分,例如,只关注包含重要信息的单词或短语。
5. **记忆网络**:
- 记忆网络使用外部记忆单元来存储长期信息,模型可以根据需要从这些记忆中检索信息。
6. **经验回放**:
- 在训练过程中,存储一些重要的历史信息,并在后续的训练步骤中回放这些信息,以帮助模型学习长期依赖。
7. **序列建模**:
- 使用序列建模技术,如循环神经网络(RNNs)或长短期记忆网络(LSTMs),来处理长序列。这些模型设计用来捕捉序列中的长期依赖关系。
8. **transformer**:
- Transformer模型使用自注意力机制来同时处理序列中的所有部分,这使得模型能够学习到序列中的长期依赖关系。
在实际应用中,选择哪种上下文压缩方法取决于具体任务的需求、可用的计算资源以及模型的容量。通常需要根据实际情况进行实验和调整,以找到最佳的压缩方法。
-
如何实现窗口上下文检索?
窗口上下文检索(Window Context Retrieval)是一种在处理序列数据时考虑局部上下文信息的检索方法。在自然语言处理(NLP)中,这通常涉及到在序列中滑动窗口来捕获每个查询附近的文本片段,以便更好地理解查询的语境。以下是一些实现窗口上下文检索的方法:
1. **定义窗口大小**:
- 确定窗口的大小,即查询左右两侧的文本数量。这个大小可以根据具体任务的需求和数据特性来调整。
2. **数据预处理**:
- 将原始文本数据分割成较小的片段或句子。
- 确保每个文本片段都有一个唯一的标识符,以便在检索过程中能够快速定位。
3. **构建索引**:
- 使用倒排索引或向量数据库等技术来存储和索引文本片段。
- 确保索引能够快速检索到与查询最相关的文本片段。
4. **查询处理**:
- 对于每个查询,滑动窗口来提取窗口内的文本片段。
- 将查询和窗口内的文本片段一起输入到检索模型中,例如基于 Transformer 的模型。
5. **模型训练和优化**:
- 训练一个模型,使其能够根据查询和窗口上下文来评估文本片段的相关性。
- 使用交叉熵损失或其他适当的损失函数来优化模型,使其能够准确地评估文本片段与查询的相关性。
6. **检索和排名**:
- 使用训练好的模型对窗口内的文本片段进行评分。
- 根据评分对文本片段进行排序,并返回最相关的片段。
7. **后处理**:
- 根据实际应用的需求,对返回的文本片段进行后处理,如文本摘要、答案抽取等。
8. **评估和调整**:
- 评估模型的性能,确保其能够准确地检索到与查询最相关的文本片段。
- 根据评估结果调整窗口大小、模型参数等,以优化检索效果。
实现窗口上下文检索的关键在于如何有效地捕获和利用局部上下文信息。通过结合适当的模型架构和训练策略,可以提高模型在处理序列数据时的检索效果。此外,考虑到实际应用的需求,可能还需要对返回的文本片段进行后处理,以生成更准确和有用的结果。
-
开源的 RAG 框架有哪些?
RAG(Retrieval-Augmented Generation)框架是一种结合了检索和生成技术的自然语言处理框架,旨在提高生成任务的质量和多样性。以下是一些开源的RAG框架:
- RAG-Token-Level:这是一个基于Transformer的RAG模型,它在生成每个token时都会从外部知识源中检索相关信息。该模型在多个生成任务上取得了显著的性能提升。
- RAG-Sequence-Level:与RAG-Token-Level不同,该模型在生成整个序列后才进行检索,以获取与生成内容相关的额外信息。这种方法可以更好地利用外部知识源来提高生成质量。
- Dense Retrieval with Generative Language Modeling:这是一个结合了密集检索和生成式语言建模的RAG框架。它使用密集向量表示来检索相关信息,并将这些信息与生成模型相结合,以提高生成任务的质量和多样性。
这些开源的RAG框架为研究人员和开发者提供了强大的工具,可以方便地结合检索和生成技术来改进自然语言处理任务的性能。请注意,这些框架可能需要特定的数据预处理和后处理步骤,以及适当的训练和调整才能获得最佳性能。
-
大模型应用框架 LangChain 和 LlamaIndex 各的优势有哪些?
LangChain 和 LlamaIndex 是两个不同的开源项目,它们都旨在简化大型语言模型(LLM)的应用和部署。以下是它们各自的优势:
### LangChain
LangChain 是一个开源的框架,它提供了一套工具和接口,用于轻松地整合大型语言模型和其他数据源,以创建复杂的、交互式的语言应用。LangChain 的优势包括:
1. **链式思考**:LangChain 支持链式思考,即模型可以分步执行任务,每次只处理一部分信息,然后将结果传递给下一步。这有助于处理复杂任务,并保持对话的一致性和连贯性。
2. **工具集成**:LangChain 可以与各种工具和数据库集成,使得语言模型能够利用外部信息来生成更准确和有用的回答。
3. **内存管理**:LangChain 提供了内存管理功能,允许模型在对话中保持上下文记忆,这对于保持对话的一致性和连贯性至关重要。
4. **可扩展性**:LangChain 设计为可扩展的,开发者可以根据需要添加自定义功能或集成其他系统。
5. **易于部署**:LangChain 提供了简单的部署选项,支持在本地、云服务器或容器化环境中运行模型应用程序。
### LlamaIndex
LlamaIndex 是一个开源的搜索引擎,专门为大型语言模型设计,用于高效地检索和推荐与用户查询最相关的文本片段。LlamaIndex 的优势包括:
1. **高效的检索**:LlamaIndex 使用高效的索引和检索算法,使得用户能够快速找到与查询最相关的文本片段。
2. **支持多模态**:LlamaIndex 支持多模态数据,包括文本、图像、音频等,使其能够处理复杂的查询和数据。
3. **可扩展性**:LlamaIndex 设计为可扩展的,支持大规模的数据集和模型。
4. **灵活的模型集成**:LlamaIndex 可以轻松地与各种大型语言模型集成,包括 OpenAI 的 GPT-3、Hugging Face 的模型等。
5. **易于部署**:LlamaIndex 提供了简单的部署选项,支持在本地、云服务器或容器化环境中运行。
总的来说,LangChain 和 LlamaIndex 都是优秀的开源项目,它们各自的优势可以帮助开发者更轻松地构建和部署基于大型语言模型的应用程序。选择哪个项目取决于具体的应用需求和开发环境。
-
向量库有哪些?各自优点与区别?
向量库是用于存储和查询向量数据的数据库,广泛应用于机器学习、深度学习、自然语言处理等领域。以下是一些常见的向量库及其优点和区别:
- Annoy:Annoy是一个基于近似最近邻搜索的库,使用随机投影森林算法来构建索引。它的优点是查询速度快,支持高维度的向量数据,并且可以处理大规模的数据集。缺点是精度相对较低,适用于对查询速度要求较高但对精度要求不是特别严格的场景。
- FAISS:FAISS是Facebook AI Similarity Search的缩写,是一个高效的相似度搜索和聚类库。它支持大规模的向量搜索,提供了多种索引方法和搜索算法,可以根据实际需求进行选择和调整。FAISS的优点是查询速度快,精度高,支持多种数据类型和距离度量方式。缺点是对于非常大的数据集,构建索引的时间和内存开销可能会比较大。
- Milvus:Milvus是一个开源的向量数据库,支持大规模的向量存储和高效查询。它提供了多种索引方法和查询算法,支持多种数据类型和距离度量方式,可以满足不同场景的需求。Milvus的优点是易于使用,提供了丰富的API和工具,支持分布式部署和高可用性。缺点是相对于商业产品来说,功能和性能可能有所限制。
- Qdrant:Qdrant是一个基于PostgreSQL的向量搜索引擎,提供了全文搜索和近似搜索功能。它支持多种向量数据类型和距离度量方式,支持分布式部署和扩展。Qdrant的优点是易于集成和使用,可以与现有的数据库和应用程序无缝对接。缺点是相对于其他向量库来说,其性能可能不是最优的。
这些向量库各有优缺点,适用于不同的场景和需求。在选择向量库时,需要根据实际的需求和场景来评估和选择最合适的库。
-
使用外部知识数据库时需要对文档进行分块,如何科学的设置文档块的大小?
在使用外部知识数据库时,对文档进行分块是一个常见的操作,因为这样可以提高检索效率并使模型能够更好地处理和理解文档内容。科学地设置文档块的大小需要考虑以下因素:
1. **模型能力**:
- 考虑所使用的模型的处理能力。例如,基于 Transformer 的模型可以处理较长的序列,因此可以设置较大的块大小。
2. **检索任务**:
- 分析检索任务的需求。如果任务需要细致的理解和分析文档的每个部分,可能需要较小的块大小。
3. **数据特性**:
- 考虑文档的数据特性,如文本的长度、主题分布、结构化程度等。如果文档长度不一,可能需要动态调整块大小。
4. **性能与效率**:
- 在保证模型性能的前提下,考虑系统的响应时间和处理效率。较大的块可能会减少I/O操作,但可能会增加内存占用和处理时间。
5. **用户交互**:
- 如果应用需要实时用户交互,考虑用户等待的时间和体验。较小的块可能会提供更快的响应,但可能会导致更多的查询和处理。
6. **查询类型**:
- 分析用户查询的类型和复杂性。对于复杂的查询,可能需要更细粒度的文档块来提供准确的答案。
7. **实验与评估**:
- 通过实验和评估来确定最佳的块大小。可以尝试不同的块大小,并测量它们对检索性能的影响。
8. **资源限制**:
- 考虑系统的资源限制,如内存、存储和计算能力。这些限制可能会影响块大小的选择。
9. **上下文保留**:
- 确保块大小设置能够保留足够的上下文信息,以便模型能够理解文档的整体结构和内容。
在实际应用中,没有一个固定的规则来确定文档块的大小,因为它取决于具体的应用场景和需求。通常,需要通过实验和迭代来找到一个平衡点,既能够满足性能要求,又不会牺牲过多的准确性或用户体验。
-
LLMs 受到上下文长度的限制,如果检索到的文档带有太多噪声,该如何解决这样的问题?
大型语言模型(LLMs)如GPT-3确实存在上下文长度的限制,这意味着它们在处理非常长的文本或文档时可能会遇到性能下降的问题。此外,如果文档中包含大量噪声或不相关信息,可能会影响模型的理解和生成质量。以下是一些解决这类问题的方法:
1. **数据预处理**:
- 在将文档输入模型之前,进行数据预处理,如去除噪声、标准化格式、分词等,以减少噪声对模型的影响。
2. **摘要生成**:
- 使用文档摘要工具或方法(如抽象摘要、提取摘要等)来减少文档的长度,只保留关键信息。
3. **上下文压缩**:
- 使用上下文压缩方法,如注意力机制或关键信息提取,来聚焦于文档中的重要部分,忽略噪声或不相关的信息。
4. **多步处理**:
- 将长文档分成多个部分,逐步处理每个部分,然后将结果合并。这可以减少单个输入的大小,并允许模型更有效地处理信息。
5. **模型集成**:
- 使用多个模型或模型版本来处理文档的不同部分,每个模型专注于不同的上下文或任务。
6. **强化学习**:
- 利用强化学习训练模型,使其能够识别并忽略噪声和不相关的信息,专注于文档的核心内容。
7. **模型优化**:
- 调整模型的架构和训练策略,以提高其处理长文档和噪声数据的能力。
8. **反馈机制**:
- 引入用户反馈机制,让用户指出文档中的噪声或不相关信息,然后使用这些反馈来训练和改进模型。
9. **领域特定知识**:
- 结合领域特定的知识库或工具,帮助模型更好地理解文档的上下文和噪声。
10. **限制上下文长度**:
- 显式地限制输入给模型的上下文长度,只包含文档中最相关的部分。
通过上述方法,可以有效地减轻文档长度限制和噪声数据对大型语言模型的影响,提高模型在实际应用中的性能和可靠性。
-
RAG(检索增强生成)对于大模型来说,有什么好处?
RAG(Retrieval-Augmented Generation)是一种结合了检索和生成的技术,它在大模型中的应用带来了多方面的好处:
1. **增强生成质量**:
- 通过检索相关信息并将其集成到生成过程中,RAG 可以提高生成的内容的相关性和准确性。这有助于生成更加丰富、多样和有用的回答。
2. **减轻记忆负担**:
- 大模型通常需要处理大量的信息和知识。RAG 通过检索机制来获取所需信息,而不是要求模型记住所有信息,从而减轻了模型的记忆负担。
3. **提高效率**:
- RAG 可以减少模型在生成过程中需要执行的计算量,因为它利用了检索到的信息而不是从头开始生成所有内容。这有助于提高模型的效率和速度。
4. **增强泛化能力**:
- 通过结合检索到的外部信息,RAG 可以帮助模型更好地泛化到新的数据和任务,因为它可以利用更多的背景知识来生成回答。
5. **改善可解释性**:
- RAG 的检索机制提供了更多的可解释性,因为它可以明确地展示模型是如何利用外部信息来生成回答的。
6. **支持多模态应用**:
- RAG 可以与多模态数据和外部知识源集成,从而支持更复杂和多样化的应用,如生成图像、视频或音频内容。
7. **灵活性**:
- RAG 提供了一种灵活的框架,可以轻松地与其他技术和工具集成,如知识图谱、数据库或API。
总之,RAG 对于大模型来说是一种强大的技术,它可以提高模型的生成质量、效率和泛化能力,同时减轻模型的记忆负担。通过结合检索和生成,RAG 可以帮助模型更好地适应各种复杂任务和应用场景。
大模型分布式训练
-
大模型进行训练,用的是什么框架?
常用的大型模型训练框架:
1. **TensorFlow**:由 Google 开发,是一个开源的软件库,用于数据流编程,广泛用于各种机器学习和深度学习任务。TensorFlow 支持广泛的硬件,包括 CPU、GPU 和 TPU。
2. **PyTorch**:由 Facebook 的 AI 研究团队开发,是一个开源的机器学习库,广泛用于应用如计算机视觉和自然语言处理等领域的深度学习。PyTorch 以其动态计算图和易用性而闻名。
3. **Apache MXNet**:由 Apache 软件基金会支持,是一个开源的深度学习框架,支持灵活的编程模型和高效的计算。MXNet 支持多种编程语言,如 Python、Scala 和 R。
4. **Keras**:是一个高层神经网络 API,它能够以 TensorFlow、CNTK 或 Theano 为后端运行。Keras 以其简洁的 API 和易用性而受到许多研究者和开发者的喜爱。
5. **PaddlePaddle**:由百度开发,是一个开源的深度学习平台,支持丰富的神经网络模型和易于上手的 API。PaddlePaddle 支持多种硬件,包括 CPU、GPU 和 AI 加速卡。
6. **MindSpore**:由华为推出,是一个开源的深度学习计算框架,旨在提供全场景 AI 解决方案。MindSpore 支持端到端的开发流程,并支持在多种设备上进行训练和推理。
选择哪个框架取决于具体的应用需求、团队的熟悉程度以及社区和生态系统支持等因素。每个框架都有其独特的优势和特点,因此在选择时应考虑这些因素。
-
业内常用的分布式AI框架
在人工智能领域,随着模型和数据集的规模不断扩大,分布式训练和推理变得日益重要。分布式AI框架能够利用多台机器的计算资源来加速模型的训练和部署过程。以下是一些业内常用的分布式AI框架:
1. **TensorFlow**:
- TensorFlow是由Google开发的一个开源机器学习框架,它支持分布式训练和推理。TensorFlow的Eager Execution模式简化了模型的训练过程,而其Keras API则提供了一个高层神经网络API,使得构建和训练模型更加直观。
2. **PyTorch**:
- PyTorch是由Facebook的人工智能研究团队开发的一个开源机器学习库,它提供了两个主要的API:TorchScript和Torch动态运行时。PyTorch支持动态计算图,使得调试更加直观,同时也支持分布式训练。
3. **Apache MXNet**:
- Apache MXNet是一个开源的深度学习框架,它提供了灵活的编程模型,支持灵活的设备配置和数据并行。MXNet可以轻松地与多种编程语言集成,包括Python、Scala和R。
4. **Microsoft Cognitive Toolkit (CNTK)**:
- CNTK是Microsoft开发的一个开源深度学习工具包,它提供了广泛的训练算法和优化器。CNTK支持灵活的分布式训练模型,包括数据并行、模型并行和流水线并行。
5. **Ray**:
- Ray是一个开源的分布式AI框架,由UC Berkeley开发。Ray提供了一个简洁的API来构建和训练分布式模型,同时支持超参数调整和模型并行。Ray还集成了多个流行的机器学习库,如TensorFlow和PyTorch。
6. **Horovod**:
- Horovod是Intel开发的一个开源的分布式深度学习训练框架,它可以在多个机器上运行TensorFlow、Keras和PyTorch模型。Horovod支持多种深度学习框架,并且可以与现有的分布式文件系统如HDFS和云存储服务如Amazon S3无缝集成。
这些框架各有特点,适用于不同的应用场景和需求。选择合适的框架通常取决于具体的任务、团队的技术栈偏好以及可用的计算资源等因素。随着技术的发展,新的分布式AI框架也在不断涌现,为研究人员和开发者提供更多的选择和可能性。
-
数据并行、张量并行、流水线并行的原理及区别?
数据并行、张量并行和流水线并行是深度学习模型训练中常用的并行化技术,它们可以提高训练效率和加速模型收敛。下面简要介绍它们的原理和区别:
1. **数据并行**:
- **原理**:数据并行是指将一个大的数据集分割成多个子集,每个子集分配给一个设备(如 GPU 或 CPU)进行处理。每个设备独立地训练一个模型副本,然后将所有设备的模型副本聚合以更新全局模型参数。
- **优势**:可以充分利用多个设备的计算资源,提高训练吞吐。
- **局限**:需要足够的数据来填充每个设备,且每个设备上的模型结构必须完全相同。
2. **张量并行**:
- **原理**:张量并行是将一个大的张量(tensor)分割成多个子张量,每个子张量分配给不同的设备。每个设备上的模型操作只在其本地子张量上进行,然后通过 all-reduce 操作将结果聚合到全局。
- **优势**:可以处理比数据并行更大的模型和数据集,因为每个设备只需要处理张量的一部分。
- **局限**:需要仔细设计网络结构以适应张量分割,这可能会增加模型的复杂性。
3. **流水线并行**:
- **原理**:流水线并行是将一个训练迭代的过程拆分成多个阶段,每个阶段分配给不同的设备。每个设备处理一个阶段,然后将结果传递给下一个设备。整个过程就像流水线一样,每个设备处理一个连续的部分。
- **优势**:可以进一步扩展训练规模,特别是当每个阶段可以独立处理时。
- **局限**:需要确保数据在流水线中的流动不会导致延迟或瓶颈。
**区别**:
- **数据并行**侧重于数据集的分割,每个设备处理数据集的一部分。
- **张量并行**侧重于张量的分割,每个设备处理张量的一部分。
- **流水线并行**侧重于训练过程的拆分,每个设备处理训练过程的一个连续阶段。
在实际应用中,可以根据具体的任务需求和硬件资源选择合适的并行化技术,或者将它们组合使用,以达到最佳的训练效果。
-
推理优化技术 Flash Attention 的作用是什么?
Flash Attention 是 Google 提出的一种新的注意力机制优化技术,它在 Transformer 模型的注意力模块中引入了速度和内存效率的提升。Transformer 模型在自然语言处理、计算机视觉等众多领域表现出色,但其注意力机制在处理长距离依赖时会消耗大量的计算资源和内存。Flash Attention 的主要作用是解决这些问题,提高模型的处理速度和效率。
Flash Attention 的主要优化点包括:
1. **块划分**:将输入序列划分为固定大小的块,而不是像传统的注意力机制那样处理整个序列。这种划分减少了需要同时考虑的序列长度,从而降低了计算和内存的需求。
2. **稀疏注意力**:在计算注意力权重时,Flash Attention 只关注序列中的一些关键点,而不是计算所有点之间的注意力。这进一步减少了计算量和内存使用。
3. **位掩码**:Flash Attention 使用位掩码来确定哪些位置的元素应该被考虑,哪些位置应该被忽略。这有助于减少不必要的计算和内存访问。
通过这些优化,Flash Attention 能够在不牺牲太多性能的情况下,显著提高 Transformer 模型的推理速度和效率。这对于处理大规模数据集或在资源受限的环境中部署 Transformer 模型具有重要意义。
-
推理优化技术 Paged Attention 的作用是什么?
推理优化技术Paged Attention的主要作用是对kv cache所占空间的分页管理,是一种典型的以内存空间换计算开销的手段。具体来说,通过有效地管理Attention模块中的Key和Value的Cache,Paged Attention能够重新定义大模型(LLM)的推理服务,从而提高其吞吐量。例如,在vLLM(一个开源的大模型推理加速框架)中,通过应用Paged Attention技术,其吞吐量比HuggingFace Transformers高出了24倍,而无需更改任何模型架构。因此,Paged Attention技术对于优化大模型的推理效率具有重要的作用。
-
CPU-offload,ZeRO-offload 了解?
CPU-offload 和 ZeRO-offload 是针对大型语言模型(LLMs)训练时的一种优化技术,旨在减少对昂贵的 GPU 资源的依赖,并将一些计算任务卸载到 CPU 上。
1. **CPU-offload**:
- CPU-offload 技术允许模型的一部分计算在 CPU 上进行,而不是全部在 GPU 上。这通常涉及到将模型的某些层或某些操作(如矩阵乘法)从 GPU 转移到 CPU。
- 这种方法可以提高训练吞吐,因为它允许 GPU 同时处理多个任务,而 CPU 可以处理那些对 GPU 来说计算量较小或者内存占用较小的任务。
- CPU-offload 通常需要模型架构的支持,以及相应的数据传输机制,以确保 GPU 和 CPU 之间的数据同步。
2. **ZeRO-offload**:
- ZeRO(Zero Redundancy Optimizer)是一种优化技术,它通过将模型的参数和梯度分解成更小的部分,使得这些部分可以分散在不同的设备上进行处理。
- ZeRO-offload 进一步发展了 ZeRO 的概念,通过将模型的一部分参数和梯度卸载到 CPU 或专门的硬件设备上,以减少 GPU 内存的使用。
- 这样做可以使得更大的模型能够在单个 GPU 上进行训练,或者在多 GPU 环境中减少对大量 GPU 内存的需求。
这两种技术都是针对大型模型的训练效率和资源利用进行的优化。它们可以提高训练吞吐,降低成本,并使得在资源受限的环境中训练更大的模型成为可能。然而,这些技术也需要仔细的实现和调优,以确保不会对模型的性能产生负面影响。
-
ZeRO,零冗余优化器 的三个阶段?
ZeRO(Zero Redundancy Optimizer)是一种针对大型神经网络模型训练的优化器,由 DeepMind 开发。ZeRO 的目标是减少模型训练中的内存冗余,允许模型在具有有限内存的设备上进行训练。ZeRO 通过将模型参数和梯度压缩成稀疏格式来实现这一点,从而减少内存占用。ZeRO 的三个阶段如下:
1. **ZeRO-1**:
- **原理**:在 ZeRO-1 阶段,ZeRO 开始对模型的参数进行稀疏化。具体来说,它将参数张量分解成更小的块(chunks),并只保留这些块的梯度。
- **优势**:这一阶段减少了单个 GPU 上的内存占用,但仍然需要存储完整的模型参数。
2. **ZeRO-2**:
- **原理**:在 ZeRO-2 阶段,ZeRO 进一步对模型参数进行稀疏化。除了将参数张量分解成块,ZeRO-2 还允许每个块的参数在不同的 GPU 上进行存储。
- **优势**:这一阶段显著减少了每个 GPU 的内存占用,并允许模型在更大规模的分布式训练环境中运行。
3. **ZeRO-3**:
- **原理**:ZeRO-3 是 ZeRO 技术的最终阶段,它进一步扩展了 ZeRO-2 的概念,允许模型参数的梯度完全分布在多个 GPU 上。
- **优势**:这一阶段进一步减少了每个 GPU 的内存占用,并允许训练更大规模的模型。
ZeRO 的主要优点是它能够显著减少训练大型神经网络模型所需的内存,从而使得这些模型可以在具有有限内存的设备上进行训练。通过使用 ZeRO,研究人员和开发者可以训练更大规模的模型,探索更深层次的模型结构,以期提高模型的性能和准确性。
-
混合精度训练的优点是什么?可能带来什么问题?
混合精度训练是一种使用不同精度的浮点数来加速深度学习模型训练的方法。在混合精度训练中,通常会同时使用低精度(如float16)和高精度(如float32)的数值。以下是混合精度训练的一些优点和可能的问题:
### 优点:
1. **加速训练**:使用float16代替float32可以显著减少模型的内存占用和计算量,因为float16占用的空间是float32的一半,计算速度通常也更快。
2. **提高能效**:由于float16计算速度快且内存占用少,因此在相同时间内可以处理更多的数据,或者在相同计算资源下处理更大的模型,从而提高能效。
3. **硬件友好**:一些硬件(如Tensor Cores on NVIDIA GPUs)专门优化了float16的计算,因此在支持这些硬件的系统中,混合精度训练可以进一步加速训练过程。
4. **减少内存溢出风险**:在处理非常大或非常深的模型时,混合精度训练可以减少因内存不足导致的溢出问题。
### 可能的问题:
1. **精度损失**:使用低精度数值会引入一定的数值误差,这可能会影响模型的训练质量和最终性能。
2. **稳定性问题**:在某些情况下,混合精度训练可能会导致模型的训练不稳定,如梯度消失或爆炸。
3. **算法调整**:为了保证模型性能,可能需要对算法进行调整,如修改学习率或采用额外的技术(如梯度缩放)来补偿精度损失。
4. **兼容性问题**:并非所有的深度学习框架和算法都支持混合精度训练,因此在某些情况下可能需要对代码进行修改或调整。
总的来说,混合精度训练是一个有效的技术,可以在不影响模型性能的情况下提高训练效率。然而,使用混合精度训练也需要权衡其可能带来的精度损失和稳定性问题,并可能需要对现有算法和代码进行调整。在实际应用中,通常需要进行实验来确定最佳的混合精度配置。
-
Megatron-DeepSpeed 方法?
Megatron-DeepSpeed 是一种结合了 Megatron 和 DeepSpeed 技术的训练方法,旨在训练超大规模的模型。这种方法通常用于处理最先进的自然语言处理任务,如语言建模、机器翻译等。以下是 Megatron-DeepSpeed 的一些关键特点和组件:
1. **模型并行**:
- Megatron-DeepSpeed 利用模型并行技术,将大型模型分割到多个 GPU 或 TPU 上。通过将模型划分为多个部分,每个部分可以独立地在其对应的设备上进行处理。
2. **梯度累积**:
- 为了提高训练吞吐,Megatron-DeepSpeed 采用梯度累积技术。这意味着多个梯度更新周期在单个设备上累积,然后一次性应用到模型参数上。
3. **ZeRO 压缩**:
- 为了减少内存占用,Megatron-DeepSpeed 采用 Zero Redundancy Optimizer (ZeRO) 技术。通过将模型参数和梯度压缩成稀疏格式,可以减少每个设备的内存占用。
4. **混合精度训练**:
- 为了提高训练吞吐和模型性能,Megatron-DeepSpeed 采用混合精度训练技术。这意味着使用较低的浮点数精度(如 16 位浮点数)进行训练,以减少内存占用和提高计算效率。
5. **DeepSpeed 组件**:
- DeepSpeed 是一组优化器和训练技术,旨在提高大规模模型的训练效率。Megatron-DeepSpeed 结合了 DeepSpeed 的某些组件,如 ZERO、Layer-wise Learning Rate Scheduler (LLR) 等,以进一步提高训练效率。
通过结合这些技术和组件,Megatron-DeepSpeed 允许训练超大规模的模型,如 GPT-3、T5 等。这种方法的关键优势在于它能够减少内存占用,提高训练吞吐,从而使得训练更大规模的模型成为可能。然而,Megatron-DeepSpeed 的实现和配置相对复杂,需要一定的技术背景和经验。
-
Megatron-LM 方法
Megatron-LM 是由 NVIDIA 开发的一种用于训练超大规模语言模型的方法,它主要解决了在训练超大规模语言模型时遇到的两个主要问题:梯度消失和内存限制。Megatron-LM 通过以下几种主要技术来优化训练过程:
1. **模型并行**:
- Megatron-LM 利用模型并行性,将一个大型模型划分到多个 GPU 上进行并行处理。这种方法可以显著减少单个 GPU 上的计算量和内存需求。
2. **流水线并行**:
- 流水线并行是一种将模型训练过程划分成多个阶段,每个阶段由不同的 GPU 处理的方法。这种方法可以进一步减少每个 GPU 上的计算量和内存需求。
3. **梯度缩放**:
- 为了处理梯度消失问题,Megatron-LM 采用梯度缩放技术,通过放大小梯度来保持模型的训练稳定性。
4. **低精度训练**:
- Megatron-LM 还使用低精度(如 float16)来减少模型的内存占用和计算量,进一步提高训练效率。
通过这些技术,Megatron-LM 能够有效地训练超大规模的语言模型,例如 GPT-3。这种方法对于推动自然语言处理领域的发展具有重要意义,使得更多的研究人员和开发者能够利用大规模语言模型来解决更复杂的自然语言处理问题。
需要注意的是,Megatron-LM 需要特定的硬件和软件环境,如支持多 GPU 训练的硬件和相应的深度学习框架。此外,这种方法可能需要专业的知识和经验来正确地实现和调优。
其他技术
-
GPU服务器用的那些?
常见 GPU 服务器配置的概览,这些配置通常用于深度学习、机器学习和高性能计算任务。
在选择 GPU 服务器时,以下是一些常见的配置选项:
1. **GPU 类型**:
- **NVIDIA GPU**:NVIDIA 的 GPU 广泛应用于深度学习和其他高性能计算任务。常见的 GPU 型号包括 Tesla、Quadro、Titan 和 GeForce RTX 系列。
- **AMD GPU**:AMD 的 Radeon Pro 和 Radeon Instinct 系列也是深度学习任务的选择之一。
2. **GPU 数量**:
- 单 GPU 服务器:适合个人使用或小型计算任务。
- 多 GPU 服务器:适合需要更高计算能力的大型项目和深度学习训练,可以是双 GPU、四 GPU 或更多。
3. **内存**:
- 内存大小通常根据服务器中 GPU 的数量和类型来决定。一般建议至少 16GB 内存,对于大型模型和复杂任务,可能需要 32GB 或更多。
4. **CPU**:
- 高性能的 CPU,如 Intel Xeon 或 AMD EPYC 系列,通常用于支持多 GPU 服务器上的计算任务。
5. **存储**:
- SSD 存储提供快速的读写速度,适合 I/O 密集型任务。
- NVMe SSD 提供更高的速度,适合需要快速访问大量数据的应用。
6. **网络**:
- 高带宽和低延迟的网络接口对于分布式训练和数据传输非常重要。
7. **散热和电源**:
- 强大的散热系统和高效率的电源是支持多 GPU 服务器的关键。
8. **机箱和扩展性**:
- 根据需求选择合适的机箱,确保有足够的空间和扩展性来支持多 GPU 和其他硬件。
在选择 GPU 服务器时,重要的是要考虑你的具体需求,包括预算、性能需求、特定任务的资源需求等。此外,选择一个有良好支持和服务记录的供应商也很重要。如果你有特定的任务或应用需求,建议咨询专业的 IT 顾问或服务器供应商,以获得更具体的建议和配置方案。
-
国产GPU服务器
国产GPU服务器市场正在迅速发展,尽管目前国内GPU企业相对于国际大厂而言规模较小,但它们正在通过技术创新和市场需求的增长逐渐崭露头角。在国内市场中,有几款值得关注的国产GPU产品:
1. **凌久微** - GP201:这是一款采用统一渲染架构的自主高性能GPU,能够满足显控、科学计算及人工智能等应用需求。凌久微电子主要从事GPU/SOC芯片产品设计研发,其自研的图形处理器(GPU)已广泛应用于商用计算机、国家信息安全和高可靠性电子设备等领域。
2. **壁仞科技** - BR100:壁仞科技推出的BR100系列通用GPU芯片,基于原创芯片架构研发,采用7nm制程工艺,具有极高的算力,单芯片峰值算力达到PFLOPS级别,这标志着中国通用GPU芯片进入“每秒千万亿次计算”的新时代。
3. **沐曦** - 7nm GPU:沐曦的国产高性能AI推理GPU芯片设计研发,主要用于AI推理场景,适用于人工智能、自动驾驶、工业和制造自动化、智慧城市、自然语言处理、边缘计算等领域。
4. **芯动力** - RPP-R8:芯动力专注于国产化GP-GPU芯片的设计与开发,其RPP-R8芯片是一款为并行计算设计的高端通用异构芯片,专注于并行计算领域,具有高计算密度和低功耗的特点。
这些产品展示了中国在GPU领域的进步和潜力,尽管国产GPU在市场上仍然面临挑战,但它们的发展对于提高国内在AI和高性能计算领域的自主能力具有重要意义
为什么会出现 LLMs 复读机问题?
LLMs 复读机问题(LLMs Parroting Problem)是指大型语言模型(LLMs)在生成文本时可能出现的重复或重复先前输入内容的现象。出现LLMs复读机问题可能有以下几个原因:
- 数据偏差:大型语言模型通常是通过预训练阶段使用大规模无标签数据进行训练的。如果训练数据中存在大量的重复文本或者某些特定的句子或短语出现频率较高,模型在生成文本时可能会倾向于复制这些常见的模式。
- 训练目标的限制:大型语言模型的训练通常是基于自监督学习的方法,通过预测下一个词或掩盖词来学习语言模型。这样的训练目标可能使得模型更倾向于生成与输入相似的文本,导致复读机问题的出现。
- 缺乏多样性的训练数据:虽然大型语言模型可以处理大规模的数据,但如果训练数据中缺乏多样性的语言表达和语境,模型可能无法学习到足够的多样性和创造性,导致复读机问题的出现。
- 模型结构和参数设置:大型语言模型的结构和参数设置也可能对复读机问题产生影响。例如,模型的注意力机制和生成策略可能导致模型更倾向于复制输入的文本。
如何缓解 LLMs 复读机问题?
为了缓解LLMs复读机问题,可以尝试以下方法:
- 多样性训练数据:在训练阶段,使用多样性的语料库来训练模型,避免数据偏差和重复文本的问题。这可以包括从不同领域、不同来源和不同风格的文本中获取数据。
- 引入噪声:在生成文本时,引入一些随机性或噪声,例如通过采样不同的词或短语,或者引入随机的变换操作,以增加生成文本的多样性。这可以通过在生成过程中对模型的输出进行采样或添加随机性来实现。
- 温度参数调整:温度参数是用来控制生成文本的多样性的一个参数。通过调整温度参数的值,可以控制生成文本的独创性和多样性。较高的温度值会增加随机性,从而减少复读机问题的出现。
- Beam搜索调整:在生成文本时,可以调整Beam搜索算法的参数。Beam搜索是一种常用的生成策略,它在生成过程中维护了一个候选序列的集合。通过调整Beam大小和搜索宽度,可以控制生成文本的多样性和创造性。
- 后处理和过滤:对生成的文本进行后处理和过滤,去除重复的句子或短语,以提高生成文本的质量和多样性。可以使用文本相似度计算方法或规则来检测和去除重复的文本。
- 人工干预和控制:对于关键任务或敏感场景,可以引入人工干预和控制机制,对生成的文本进行审查和筛选,确保生成结果的准确性和多样性。
需要注意的是,缓解LLMs复读机问题是一个复杂的任务,没有一种通用的解决方案。不同的方法可能适用于不同的场景和任务,需要根据具体情况进行选择和调整。此外,解决复读机问题还需要综合考虑数据、训练目标、模型架构和生成策略等多个因素,需要进一步的研究和实践来提高大型语言模型的生成文本多样性和创造性。
llama 输入句子长度理论上可以无限长吗?
理论上来说,LLMs(大型语言模型)可以处理任意长度的输入句子,但实际上存在一些限制和挑战。下面是一些相关的考虑因素:
- 计算资源:生成长句子需要更多的计算资源,包括内存和计算时间。由于LLMs通常是基于神经网络的模型,计算长句子可能会导致内存不足或计算时间过长的问题。
- 模型训练和推理:训练和推理长句子可能会面临一些挑战。在训练阶段,处理长句子可能会导致梯度消失或梯度爆炸的问题,影响模型的收敛性和训练效果。在推理阶段,生成长句子可能会增加模型的错误率和生成时间。
- 上下文建模:LLMs是基于上下文建模的模型,长句子的上下文可能会更加复杂和深层。模型需要能够捕捉长句子中的语义和语法结构,以生成准确和连贯的文本。
尽管存在这些挑战,研究人员和工程师们已经在不断努力改进和优化LLMs,以处理更长的句子。例如,可以采用分块的方式处理长句子,将其分成多个较短的片段进行处理。此外,还可以通过增加计算资源、优化模型结构和参数设置,以及使用更高效的推理算法来提高LLMs处理长句子的能力。
值得注意的是,实际应用中,长句子的处理可能还受到应用场景、任务需求和资源限制等因素的影响。因此,在使用LLMs处理长句子时,需要综合考虑这些因素,并根据具体情况进行选择和调整。
什么情况用Bert模型,什么情况用LLaMA、ChatGLM类大模型?
选择使用哪种大模型,如Bert、LLaMA或ChatGLM,取决于具体的应用场景和需求。下面是一些指导原则:
Bert模型:Bert是一种预训练的语言模型,适用于各种自然语言处理任务,如文本分类、命名实体识别、语义相似度计算等。如果你的任务是通用的文本处理任务,而不依赖于特定领域的知识或语言风格,Bert模型通常是一个不错的选择。Bert由一个Transformer编码器组成,更适合于NLU相关的任务。
LLaMA模型:LLaMA(Large Language Model Meta AI)包含从 7B 到 65B 的参数范围,训练使用多达14,000亿tokens语料,具有常识推理、问答、数学推理、代码生成、语言理解等能力。Bert由一个Transformer解码器组成。训练预料主要为以英语为主的拉丁语系,不包含中日韩文。所以适合于英文文本生成的任务。
ChatGLM模型:ChatGLM是一个面向对话生成的语言模型,适用于构建聊天机器人、智能客服等对话系统。如果你的应用场景需要模型能够生成连贯、流畅的对话回复,并且需要处理对话上下文、生成多轮对话等,ChatGLM模型可能是一个较好的选择。ChatGLM的架构为Prefix decoder,训练语料为中英双语,中英文比例为1:1。所以适合于中文和英文文本生成的任务。
在选择模型时,还需要考虑以下因素:
- 数据可用性:不同模型可能需要不同类型和规模的数据进行训练。确保你有足够的数据来训练和微调所选择的模型。
- 计算资源:大模型通常需要更多的计算资源和存储空间。确保你有足够的硬件资源来支持所选择的模型的训练和推理。
- 预训练和微调:大模型通常需要进行预训练和微调才能适应特定任务和领域。了解所选择模型的预训练和微调过程,并确保你有相应的数据和时间来完成这些步骤。
最佳选择取决于具体的应用需求和限制条件。在做出决策之前,建议先进行一些实验和评估,以确定哪种模型最适合你的应用场景。
各个专业领域是否需要各自的大模型来服务?
各个专业领域通常需要各自的大模型来服务,原因如下:
- 领域特定知识:不同领域拥有各自特定的知识和术语,需要针对该领域进行训练的大模型才能更好地理解和处理相关文本。例如,在医学领域,需要训练具有医学知识的大模型,以更准确地理解和生成医学文本。
- 语言风格和惯用语:各个领域通常有自己独特的语言风格和惯用语,这些特点对于模型的训练和生成都很重要。专门针对某个领域进行训练的大模型可以更好地掌握该领域的语言特点,生成更符合该领域要求的文本。
- 领域需求的差异:不同领域对于文本处理的需求也有所差异。例如,金融领域可能更关注数字和统计数据的处理,而法律领域可能更关注法律条款和案例的解析。因此,为了更好地满足不同领域的需求,需要专门针对各个领域进行训练的大模型。
- 数据稀缺性:某些领域的数据可能相对较少,无法充分训练通用的大模型。针对特定领域进行训练的大模型可以更好地利用该领域的数据,提高模型的性能和效果。
尽管需要各自的大模型来服务不同领域,但也可以共享一些通用的模型和技术。例如,通用的大模型可以用于处理通用的文本任务,而领域特定的模型可以在通用模型的基础上进行微调和定制,以适应特定领域的需求。这样可以在满足领域需求的同时,减少模型的重复训练和资源消耗。
如何让大模型处理更长的文本?
要让大模型处理更长的文本,可以考虑以下几个方法:
- 分块处理:将长文本分割成较短的片段,然后逐个片段输入模型进行处理。这样可以避免长文本对模型内存和计算资源的压力。在处理分块文本时,可以使用重叠的方式,即将相邻片段的一部分重叠,以保持上下文的连贯性。
- 层次建模:通过引入层次结构,将长文本划分为更小的单元。例如,可以将文本分为段落、句子或子句等层次,然后逐层输入模型进行处理。这样可以减少每个单元的长度,提高模型处理长文本的能力。
- 部分生成:如果只需要模型生成文本的一部分,而不是整个文本,可以只输入部分文本作为上下文,然后让模型生成所需的部分。例如,输入前一部分文本,让模型生成后续的内容。
- 注意力机制:注意力机制可以帮助模型关注输入中的重要部分,可以用于处理长文本时的上下文建模。通过引入注意力机制,模型可以更好地捕捉长文本中的关键信息。
- 模型结构优化:通过优化模型结构和参数设置,可以提高模型处理长文本的能力。例如,可以增加模型的层数或参数量,以增加模型的表达能力。还可以使用更高效的模型架构,如Transformer等,以提高长文本的处理效率。
需要注意的是,处理长文本时还需考虑计算资源和时间的限制。较长的文本可能需要更多的内存和计算时间,因此在实际应用中需要根据具体情况进行权衡和调整。
什么是涌现?为什么会出现涌现?
"大模型的涌现能力"这个概念可能是指大型神经网络模型在某些任务上表现出的出乎意料的能力,超出了人们的预期。出现的原因从结论上来看,是模型不够好,导致的原因主要是:
- 数据量的增加:随着互联网的发展和数字化信息的爆炸增长,可用于训练模型的数据量大大增加。更多的数据可以提供更丰富、更广泛的语言知识和语境,使得模型能够更好地理解和生成文本。
- 计算能力的提升:随着计算硬件的发展,特别是图形处理器(GPU)和专用的AI芯片(如TPU)的出现,计算能力大幅提升。这使得训练更大、更复杂的模型成为可能,从而提高了模型的性能和涌现能力。
- 模型架构的改进:近年来,一些新的模型架构被引入,如Transformer,它在处理序列数据上表现出色。这些新的架构通过引入自注意力机制等技术,使得模型能够更好地捕捉长距离的依赖关系和语言结构,提高了模型的表达能力和生成能力。
- 预训练和微调的方法:预训练和微调是一种有效的训练策略,可以在大规模无标签数据上进行预训练,然后在特定任务上进行微调。这种方法可以使模型从大规模数据中学习到更丰富的语言知识和语义理解,从而提高模型的涌现能力。
其实导致涌现出现的原因拆解开就是因为技术糅合导致的不可控。大模型的涌现能力是由数据量的增加、计算能力的提升、模型架构的改进以及预训练和微调等因素共同作用的结果。
大模型基本概念
1. 大模型:一般指1亿以上参数的模型,但是这个标准一直在升级,目前万亿参数以上的模型也有了。大语言模型(Large Language Model,LLM)是针对语言的大模型。
2. 175B、60B、540B等:这些一般指参数的个数,B是Billion/十亿的意思,175B是1750亿参数,这是ChatGPT大约的参数规模。
3. 强化学习:(Reinforcement Learning)一种机器学习的方法,通过从外部获得激励来校正学习方向从而获得一种自适应的学习能力。
4. 基于人工反馈的强化学习(RLHF):(Reinforcement Learning from Human Feedback)构建人类反馈数据集,训练一个激励模型,模仿人类偏好对结果打分,这是GPT-3后时代大语言模型越来越像人类对话核心技术。
5. 涌现:(Emergence)或称创发、突现、呈展、演生,是一种现象。许多小实体相互作用后产生了大实体,而这个大实体展现了组成它的小实体所不具有的特性。研究发现,模型规模达到一定阈值以上后,会在多步算术、大学考试、单词释义等场景的准确性显著提升,称为涌现。
6. 泛化:(Generalization)模型泛化是指一些模型可以应用(泛化)到其他场景,通常为采用迁移学习、微调等手段实现泛化。
7. 微调:(FineTuning)针对大量数据训练出来的预训练模型,后期采用业务相关数据进一步训练原先模型的相关部分,得到准确度更高的模型,或者更好的泛化。
8. 指令微调:(Instruction FineTuning),针对已经存在的预训练模型,给出额外的指令或者标注数据集来提升模型的性能。
9. 思维链:(Chain-of-Thought,CoT)。通过让大语言模型(LLM)将一个问题拆解为多个步骤,一步一步分析,逐步得出正确答案。需指出,针对复杂问题,LLM直接给出错误答案的概率比较高。思维链可以看成是一种指令微调。
Transformer架构以及在大型语言模型中的作用
Transformer架构是一种深度神经网络架构,于2017年由Vaswani等人在他们的论文“Attention is All You Need”中首次提出。自那以后,它已成为大型语言模型(如BERT和GPT)最常用的架构。
Transformer架构使用注意机制来解析输入序列,例如句子或段落,专门用于自然语言处理(NLP)应用。与传统的循环神经网络(RNN)不同,Transformer采用自注意力技术,使其能够同时关注输入序列的多个部分。
在大型语言模型中,Transformer架构用于创建输入文本的深层表示,然后可以用于各种NLP任务,如文本分类、命名实体识别和文本生成。这些模型在大量文本数据上进行了预训练,使它们能够学习数据中的模式和关系,然后可以进行特定的NLP任务的微调。
总的来说,Transformer架构通过提供强大而灵活的架构,彻底改变了NLP领域,特别适用于处理大量文本数据。在大型语言模型中的使用已经在各种NLP任务的性能上实现了显著的改进,并使从业者更容易将最先进的NLP模型集成到他们的项目中。
如何使用预训练模型来执行NLP任务?
假设您是一家金融科技初创公司的有经验的软件工程师:
在我之前的一个项目中,我利用预训练模型来提高我们的客户支持聊天机器人的准确性。该聊天机器人最初是在一小组客户咨询的小型数据集上训练的,但由于训练数据量有限,它在某些问题上表现不佳。
为了解决这个问题,我在公司更大的客户咨询数据集上对一个预训练的BERT模型进行了微调。这使模型能够学习数据中的特定模式和关系,从而显著提高了聊天机器人在测试集上的准确性。
除了提高聊天机器人的性能外,使用预训练模型还节省了大量时间和资源,与从零开始训练模型相比。这使我们能够迅速部署更新后的聊天机器人,提供更好的客户体验。
总的来说,预训练模型已经证明在我的NLP项目中是一个有价值的工具,提供高性能和资源节省,并我期待在将来的项目中继续使用它们。
解释微调以及它如何用于定制预训练模型以适应特定任务
微调是一种将预训练模型适应特定任务的过程。它涉及在特定任务的较小数据集上训练预训练模型,使模型能够学习任务特定的特征并适应任务的数据分布。
例如,像BERT或GPT-2这样的预训练语言模型可以针对特定的NLP任务,如情感分析或命名实体识别,进行微调。在这种情况下,微调过程涉及使用特定任务的标记示例的小型数据集来训练模型,通过更新模型参数来改善模型在任务上的性能。
微调过程可以通过使用反向传播和梯度下降等训练算法来更新模型的参数来完成,就像在任何其他机器学习任务中一样。然而,由于模型已经在大量文本数据上进行了预训练,它已经对语言有很强的理解,可以更快地学习任务特定的特征,而不需要从零开始训练模型。
微调具有几个优点。它允许将预训练模型适应特定任务和领域,提高模型在特定任务上的性能。与从头开始训练模型相比,它还节省时间和计算资源,因为预训练模型提供了性能的强大基线。
总的来说,微调是一种用于定制预训练模型以适应特定任务的强大技术,并已成为NLP项目中的常见实践。
将大型语言模型集成到生产系统的过程:
将大型语言模型集成到生产系统通常涉及多个步骤,包括对输入数据进行预处理、定义模型架构、训练模型以及在生产环境中部署模型。以下是该过程的高层概述:
1. 预处理输入数据:首先,需要对输入数据进行预处理,以确保可以输入模型。这可能包括数据清洗、将文本转换为数值表示以及将数据分为训练和测试集。
2. 定义模型架构:接下来,需要定义模型架构。这涉及选择一个预训练语言模型,如BERT或GPT-2,并对其进行微调以适应特定任务。模型架构可能还包括其他层和组件,如分类器,以执行所需的任务。
3. 训练模型:一旦模型架构被定义,下一步是在经过预处理的数据上训练模型。这涉及使用训练算法,如随机梯度下降,来更新模型参数,并提高模型在任务上的性能。
4. 评估模型:在模型经过训练后,评估模型在测试集上的性能非常重要。这可能包括计算指标,如准确度或F1分数,以评估模型的性能并确定需要改进的方面。
5. 部署模型:最后一步是在生产环境中部署模型。这可能涉及将经过训练的模型转换为可以部署在生产环境中的格式,如TensorFlow Serving或Flask,并将其集成到生产系统中。
6. 监控和维护:一旦模型被部署,监控其性能并根据需要进行更新非常重要。这可能涉及重新训练模型以适应新数据、更新模型架构以及解决在生产环境中出现的任何问题。
如何优化模型性能?
以下是一位金融科技初创公司有经验的软件工程师的虚构答案:
一个例子是针对用于识别欺诈交易的模型。该模型最初是在大量历史交易数据上进行训练的,但由于数据不平衡,其性能不佳。为了解决这个问题,我使用了过采样技术来平衡数据并提高模型的性能。
除了过采样,我还通过微调超参数来优化模型性能。这包括调整学习速率、批量大小和训练周期数等参数,以找到能够实现最佳性能的值的组合。
最后,我还尝试了不同的模型架构,包括决策树和随机森林,以确定最适合该任务的模型。通过比较不同模型的性能,我能够选择表现最佳的模型并将其集成到生产环境中。
总的来说,优化模型性能涉及数据预处理、调整超参数和模型选择的组合。在我的以前的项目中,我通过利用这些技术改进了欺诈检测模型的性能,为我们的客户提供了更准确的解决方案。
大型语言模型中的注意机制?以及是如何工作的?
注意机制是许多最先进的NLP模型的重要组成部分,包括基于Transformer的模型,如BERT和GPT。
注意机制的工作原理是允许模型在进行预测时有选择地关注输入序列的不同部分。这是通过计算每个输入序列元素的一组注意分数来实现的,这些分数表示每个元素对于给定任务的重要性。然后,这些注意分数用于加权输入元素,并生成加权和,作为模型下一层的输入。
在高层次上,注意机制允许模型根据手头的任务动态地调整其关注点。例如,在机器翻译任务中,注意机制可能在不同时间关注源句子中的不同单词,使模型能够有选择地关注生成翻译时的重要信息。
在实践中,注意机制是通过一组参数来实现的,称为注意权重,这些参数在训练过程中学习。这些注意权重用于计算注意分数并生成输入元素的加权和。注意权重可以看作是模型用于存储有关输入序列信息的一种记忆。
总的来说,注意机制在提高大型语言模型性能方面发挥了至关重要的作用,因为它允许模型有选择地关注输入序列的不同部分,并更好地捕捉元素之间的关系。
如何处理大型语言模型的计算需求?
处理大型语言模型的计算需求可能是一个挑战,尤其是在模型必须集成到生产环境中的实际应用中。以下是在项目中管理计算需求的一些策略:
- 硬件优化:大型语言模型需要大量的计算资源,如高端GPU或TPU。为了满足模型的需求,重要的是使用适当的硬
以下是将上述文本翻译成中文:
你如何处理大型语言模型的计算需求?
处理大型语言模型的计算需求可能是一个挑战,尤其是在模型必须集成到生产环境中的实际应用中。以下是在项目中管理计算需求的一些建议:
- 硬件优化:大型语言模型需要大量的计算资源,包括高端GPU或TPU。为了满足模型的需求,使用适当的硬件非常重要,无论是使用云端GPU还是投资于本地硬件。
- 模型修剪:模型修剪涉及移除模型的多余或不重要的组件,可以显著减少模型的计算需求而不损害性能。这可以通过权重修剪、结构修剪和激活修剪等技术来实现。
- 模型量化:量化涉及减少模型权重和激活的精度,可以显著减少模型的内存需求和计算需求。这可以通过量化感知训练或后训练量化等技术来实现。
- 模型蒸馏:模型蒸馏涉及训练一个较小的模型来模仿较大模型的行为。这可以显著减少模型的计算需求而不损害性能,因为较小的模型可以更高效地训练,并且可以在资源有限的环境中部署。
- 并行处理:并行处理涉及将模型的工作负载分布到多个GPU或处理器上,可以显著减少运行模型所需的时间。这可以通过数据并行处理、模型并行处理或管道并行处理等技术来实现。
通过使用这些策略的组合,可以有效地管理大型语言模型的计算需求,确保模型能够在实际应用中得以有效部署。
使用大型语言模型时遇到的挑战或限制
在NLP项目中使用大型语言模型可能会面临一些挑战和限制。一些常见的挑战包括:
- 计算需求:大型语言模型需要大量的计算资源,如高端GPU或TPU,这可能会在资源有限或需要实时应用的环境中造成部署困难。
- 内存需求:存储大型语言模型的参数需要大量内存,这使得在内存受限的环境中部署或对较小数据集进行微调变得具有挑战性。
- 解释性不足:大型语言模型通常被视为黑盒,难以理解其推理和决策,而这在某些应用中很重要。
- 过拟合:在小数据集上微调大型语言模型可能会导致过拟合,降低对新数据的准确性。
- 偏见:大型语言模型是在大量数据上训练的,这可能会引入模型的偏见。这可能在要求结果中保持中立和公平的应用中构成挑战。
- 道德关切:使用大型语言模型可能会对社会产生重大影响,因此必须考虑伦理问题。例如,通过语言模型生成假新闻或带有偏见的决策可能会带来负面后果。
NLP中生成模型和判别模型的区别
在NLP中,生成模型和判别模型是用于执行不同NLP任务的两个广泛类别的模型。
生成模型关注学习底层数据分布并从中生成新样本。它们建模输入和输出的联合概率分布,旨在最大化生成观察数据的可能性。在NLP中的一个生成模型示例是语言模型,其目标是基于先前的单词来预测序列中的下一个单词。
判别模型则关注学习输入-输出空间中正负示例之间的边界。它们建模给定输入情况下输出的条件概率分布,旨在最大化对新示例的分类准确性。在NLP中的一个判别模型示例是情感分析模型,其目标是根据文本内容将文本分类为积极、消极或中性。
总之,生成模型的目标是生成数据,而判别模型的目标是对数据进行分类。
对大模型基本原理和架构的理解
大型语言模型如GPT(Generative Pre-trained Transformer)系列是基于自注意力机制的深度学习模型,主要用于处理和生成人类语言。
基本原理
- 自然语言理解:模型通过对大量文本数据的预训练,学习到语言的统计规律,从而能够在不同的语言任务上表现出自然语言理解的能力。
- 迁移学习:GPT类模型首先在一个广泛的数据集上进行预训练,以掌握语言的通用表示,然后可以在特定任务上进行微调(fine-tuning),以适应特定的应用场景。
- 生成能力:这类模型不仅能够理解输入的文本,还能够生成连贯、相关的文本,使其在对话系统、文本生成、摘要等应用中非常有价值。
架构特点
- Transformer架构:GPT模型基于Transformer架构,该架构由编码器和解码器组成,但GPT仅使用了解码器部分。Transformer利用自注意力机制来捕获输入序列中不同位置之间的关系。
- 自注意力机制:允许模型在处理序列的每个元素时动态地聚焦于序列中的其他元素,这在理解上下文关系时尤其重要。
- 多层堆叠:GPT模型由多层Transformer解码器块堆叠而成,每层包括自注意力层和前馈神经网络,以及归一化层和残差连接,以帮助避免在训练深层网络时出现的梯度消失问题。
- 位置编码:
对于输入文本序列,首先通过输入层(InputEmbedding)将每个单词转换为其相对应的向量表示。序列中不再有任何信息能够提示模型单词之间的相对位置关系。在送入编码器端建模其上下文语义之前,一个非常重要的操作是在词嵌入中加入位置编码(PositionalEncoding)这一特征。
位置编码(Positional Encoding) 是在 Transformer 模型中引入的一种技术,用于为序列中的每个位置添加位置信息。由于 Transformer 模型没有使用循环神经网络或卷积神经网络,无法直接捕捉到序列中单词之间的相对位置关系。位置编码的目的是为了提供序列中单词的位置信息,以便模型能够更好地理解序列中单词之间的顺序关系。位置编码使用正弦和余弦函数生成。具体公式如下.

其中 pos 表示单词在序列中的位置(索引),i表示位置编码向量中对应的维度(索引),dmodel 表示位置编码的总维度(模型的隐藏单元数目)。
位置编码可以通过将其与词嵌入相加来获得最终的输入表示。这样做可以将位置信息与语义信息相结合,使模型能够更好地理解序列中单词之间的相对位置关系。
使用大模型以及优化模型的方法
项目中使用大模型的方法
在项目中使用大型模型通常遵循以下步骤:
(1)需求分析与确定目标
- 确定项目需求和业务目标,明确大模型需要解决的问题或提升的性能指标。
(2)数据收集与预处理
- 收集足够的、高质量的训练数据。
- 进行数据清洗,去除噪声和异常值,确保数据质量。
- 实施数据预处理,如标准化、归一化、编码分类变量等。
(3)模型选择
- 根据问题的特性选择合适的大模型框架,如BERT,GPT等。
- 评估是否需要自定义模型或使用预训练模型。
(4)功能实现
- 设计模型输入输出及其结构,例如确定神经网络层数、连接方式、激活函数等。
- 实现数据到模型的输入流程,如特征工程、embedding层的设计等。
(5)模型训练与验证
- 使用GPU或TPU等硬件加速训练过程。
- 应用诸如交叉验证等技术来评估模型的泛化能力。
- 监控训练过程中的关键指标,如损失函数值、准确率等。
(6)模型评估
- 在独立测试集上评估模型表现。
- 使用适当的评价指标,如精确度、召回率、F1分数、ROC-AUC等。
(7)模型部署
- 将训练好的模型部署到生产环境。
- 实现API接口供其他系统或用户调用模型。
- 确保模型在部署环境下的稳定性和可扩展性。
(8)监控与更新
- 持续监控模型的性能,以便及时发现退化情况。
- 定期使用新数据更新模型以维持其准确性和相关性。
微调大模型
微调大型语言模型(LLM)是一种自定义模型以适应特定任务或数据集的方法。以下是微调大型语言模型的典型步骤:
1. 明确微调目标
确定你希望通过微调模型达到什么目的,例如提高在特定领域数据上的表现、适应新的文本风格或术语、解决一个具体的问题。
2. 数据准备
- 数据收集:根据微调的目标,收集或创建一个与目标任务相关的数据集。
- 数据预处理:清洗数据、去除噪音、执行必要的文本规范化等。
- 数据分割:将数据分为训练集、验证集和测试集。
3. 选择基础模型
选择一个适合你任务的预训练语言模型作为起点。这可以是GPT-3、BERT、chatgml等。
4. 定义微调设置
- 微调超参数:设置学习率、批大小、epoch数等。
- 模型架构调整(可选):如果需要,可以对模型的架构进行修改,如增加层、改变激活函数等。
5. 微调环境准备
- 硬件准备:确保有足够的计算资源,通常需要使用GPU或TPU。
- 软件依赖:安装所有必要的库和框架,如PyTorch、TensorFlow等。
6. 微调过程
- 加载预训练模型:使用所选的框架加载预训练模型。
- 微调训练:在特定于任务的数据上训练模型,调整模型权重。
- 监控:在训练过程中监控性能指标,如损失函数值和验证集上的精度。
7. 模型评估
- 使用测试集来评估微调后模型的性能。
- 如果有必要,根据评估结果反复调整超参数并重新训练模型。
8. 应用与部署
- 将微调后的模型集成到下游应用中。
- 部署模型到生产环境。
9. 监测与维护
- 监控模型在实际使用中的表现。
- 根据需要进行维护和进一步微调。
注意事项
- 伦理与合规性: 在数据收集和使用模型时,确保遵守隐私、伦理和法律标准。
- 偏见和公平性: 检查和缓解可能在数据或模型中存在的任何偏见。
- 数据代表性: 确保数据集能够代表实际应用场景中的数据分布。
优化模型的方法
优化大型模型涉及多个方面,包括但不限于:
1.计算效率优化
1)模型剪枝(Model Pruning)
模型剪枝通过移除模型中不重要的参数或神经元来减少模型复杂性,可以提高推理速度,并在一定程度上减少过拟合。剪枝策略包括但不限于权重剪枝、单元剪枝和结构化剪枝。
2) 知识蒸馏(Knowledge Distillation)
知识蒸馏通常是指将一个大型、复杂的“教师”模型的知识转移到一个小型的“学生”模型中。这样做可以让小模型在保持较低计算成本的同时,尽可能地接近大模型的性能。
3) 量化(Quantization)
量化是一种将模型参数和激活函数从浮点数(例如32位float)转换为低位宽度的表示(例如8位整数)。这可以显著减少模型大小和加速推理过程,特别是对于部署在移动和边缘设备的场景。
4) 使用混合精度训练
2.软件级优化(Software level optimization)
- 混合精度训练:使用不同的数据类型(如16-bit半精度浮点数和32-bit单精度浮点数)进行计算,以平衡训练速度和模型表现(减少内存占用并加速训练)
- 并行计算和分布式训练:利用多GPU或多节点进行模型训练,有效降低训练时间。
- 高效的数据加载和预处理:优化数据管道,确保CPU/GPU资源的最大利用率。
3.数据加载优化(Data loading optimization)
使用多线程或异步I/O操作来加速数据加载和预处理
4. 架构搜索和设计(Architecture Search and Design)
- 神经架构搜索(NAS):自动寻找符合特定任务需求的最优模型架构。
- 模块化设计:通过组件化设计使得模型更容易扩展和修改。
- 轻量级模型结构:研发或应用如MobileNets, EfficientNets等轻量级但仍然强大的网络架构。
旋转位置编码及其优点
旋转位置编码(Rotation Position Encoding,RoPE)是一种用于为序列数据中的每个位置添加旋转位置信息的编码方法。RoPE的思路是通过引入旋转矩阵来表示位置之间的旋转关系,从而捕捉序列中位置之间的旋转模式。
传统的绝对位置编码和相对位置编码方法主要关注位置之间的线性关系,而忽略了位置之间的旋转关系。然而,在某些序列数据中,位置之间的旋转关系可能对于模型的理解和预测是重要的。例如,在一些自然语言处理任务中,单词之间的顺序可能会发生旋转,如句子重排或句子中的语法结构变化。
RoPE通过引入旋转矩阵来捕捉位置之间的旋转关系。具体而言,RoPE使用一个旋转矩阵,将每个位置的位置向量与旋转矩阵相乘,从而获得旋转后的位置向量。这样,模型可以根据旋转后的位置向量来识别和理解位置之间的旋转模式。
RoPE的优势在于它能够捕捉到序列数据中位置之间的旋转关系,从而提供了更丰富的位置信息。这对于一些需要考虑位置旋转的任务,如自然语言推理、自然语言生成等,尤为重要。RoPE的引入可以帮助模型更好地理解和建模序列数据中的旋转模式,从而提高模型的性能和泛化能力。
旋转位置编码(RoPE)是一种用于位置编码的改进方法,相比于传统的位置编码方式,RoPE具有以下优点:
解决位置编码的周期性问题:传统的位置编码方式(如Sinusoidal Position Encoding)存在一个固定的周期,当序列长度超过该周期时,位置编码会出现重复。这可能导致模型在处理长序列时失去对位置信息的准确理解。RoPE通过引入旋转操作,可以解决这个周期性问题,使得位置编码可以适应更长的序列。
更好地建模相对位置信息:传统的位置编码方式只考虑了绝对位置信息,即每个位置都有一个唯一的编码表示。然而,在某些任务中,相对位置信息对于理解序列的语义和结构非常重要。RoPE通过旋转操作,可以捕捉到相对位置信息,使得模型能够更好地建模序列中的局部关系。
更好的泛化能力:RoPE的旋转操作可以看作是对位置编码进行了一种数据增强操作,通过扩展位置编码的变化范围,可以提高模型的泛化能力。这对于处理不同长度的序列以及在测试时遇到未见过的序列长度非常有帮助。
总体而言,RoPE相比于传统的位置编码方式,在处理长序列、建模相对位置信息和提高泛化能力方面具有一定的优势。这些优点可以帮助模型更好地理解序列数据,并在各种自然语言处理任务中取得更好的性能。
损失函数和优化算法
在训练和优化大型人工智能模型时,根据不同的任务类型和建模策略,我们会选择相应的损失函数和优化算法。下面是一些常用损失函数和优化算法的分类总结:
损失函数
对于回归问题
- 均方误差损失(MSE):当预测输出是连续值且假设误差为正态分布时。
- 平均绝对误差(MAE):对异常值具有更高的鲁棒性。
- Huber损失:介于MSE和MAE之间,对异常值适度鲁棒。
- 对数余弦相似性损失:当想要比较两个向量之间的角度差异而不是数值差异时使用。
对于二分类问题
- 二元交叉熵损失:当目标变量为0或1时,衡量模型预测概率与实际标签的差异。
对于多分类问题
- 多类别交叉熵损失:当有多个类别且每个样本只属于一个类别时。
- 稀疏多类别交叉熵损失:类似于多类别交叉熵损失,但适用于类别标签以整数形式给出的情况。
特定领域的损失函数
- 结构化损失函数:如序列到序列模型中的编辑距离等,用于结构化输出空间。
- 对抗损失:在生成对抗网络(GANs)中,区分生成器和判别器的学习过程。
- 三重项损失(Triplet Loss):在度量学习和面部识别等任务中,目的是使得相似的样本靠近,不同的样本远离。
处理类不平衡的损失函数
- 焦点损失(Focal Loss):对难以分类的样本赋予更高的权重,广泛用于解决前景和背景类不平衡的目标检测问题。
优化算法
基本算法
- 随机梯度下降(SGD):最基础的优化方法,适用于大规模数据集。
带动量的算法
- SGD with Momentum:加速SGD并减小震荡,适用于需要克服局部极小值或鞍点的情况。
自适应学习率算法
- Adagrad:适合处理稀疏数据。
- RMSprop:解决了Adagrad学习率急剧下降的问题,适合处理非平稳目标。
- Adam:结合了momentum和RMSprop的优点,对于很多问题都提供了良好的默认配置。
- AdamW:在Adam的基础上加入L2正则化,通常带来更好的泛化性能。
- AdaDelta:改进版的RMSprop,无需手动设置学习率。
大规模训练中的优化算法
- LAMB (Layer-wise Adaptive Moments optimizer for Batch training):针对大批量数据开发,用于大模型和大规模分布式训练。
- LARS (Layer-wise Adaptive Rate Scaling):配合大批量数据进行有效的分布式训练
大规模的数据处理
在面对大规模数据处理的问题时,通常会遵循一个系统化的流程来确保数据是准确、可用和具有分析价值的。以下是处理步骤:
1. 数据清洗
在数据清洗阶段,首要任务是识别并纠正数据集中的错误和不一致性。
- 缺失值处理:根据数据的性质和缺失情况,可以采取多种策略,如删除含有缺失值的记录、填充缺失值(均值、中位数、众数、预测模型等)或者使用算法(例如K近邻)来估计缺失值。
- 异常值检测与处理:可使用统计测试(如IQR、Z-score)来识别异常值,并根据业务逻辑考虑是否需要修正或移除这些值。
- 数据格式标准化:确保所有数据遵循同一格式标准,比如日期时间格式、货币单位、文本编码等。
- 去重:移除数据中的重复记录,以避免在分析时产生偏差。
2. 数据预处理
- 数据转换:包括归一化(将数据缩放到一个小的特定范围)、标准化(基于数据的均值和标准差),以便模型更好地理解数据的结构。
- 数据编码:对分类数据进行编码,如独热编码(One-Hot Encoding)、标签编码(Label Encoding)或使用诸如Word Embedding对文本数据进行编码。
- 时间序列数据处理:如果处理时间序列数据,可能需要考虑数据平滑、趋势和季节性分解、差分等技术来使数据稳定。
- 数据划分:将数据集分为训练集、验证集和测试集,以便进行模型开发和评估。
3. 特征工程
- 特征选择:通过技术如相关性分析、卡方检验、互信息、递归特征消除(RFE)等方法,选择最有影响力的特征。
- 特征构造:结合业务知识和数据探索结果,构建新的特征,以更好地捕获数据中的模式。
- 特征转换:运用主成分分析(PCA)、因子分析、t-SNE等降维技术来减少特征空间,同时尽量保留原始数据的信息。
- 特征学习:利用深度学习方法自动学习特征表示,尤其在图像、音频和文本数据上效果显著。
4. 处理大规模数据集的特别考虑
- 分布式处理:使用如Apache Hadoop、Spark等
使用GPU来加速模型训练和推理
GPU加速计算是指使用图形处理单元(GPU)来加速运算密集型和并行度高的计算任务。GPU最初设计用于处理复杂的图形和图像处理算法,但它们的架构特别适合执行可以并行化的数学和工程计算任务。与传统的中央处理单元(CPU)相比,GPU有成百上千个较小、更专业的核心,这使得它们在处理多个并发操作方面非常有效。
GPU加速计算是通过将计算任务分配到多个GPU核心上并行处理来实现加速的。在模型的训练和推理过程中,通常使用GPU来加速矩阵乘法、卷积等计算密集型操作。通过将数据和模型权重从CPU内存复制到GPU内存中,并使用GPU加速库(如CUDA、cuDNN等)来进行计算,可以大大加快模型的训练和推理速度。
在深度学习和机器学习领域,模型训练和推理涉及到大量的矩阵和向量运算,这些运算可以被分解成小的、可以并行处理的任务。正因为这种计算性质,使用GPU通常会显著提升训练和推理过程的效率。如何使用GPU加速模型训练和推理的:
- 硬件选择:首先确保有访问权限的硬件资源包含支持CUDA(Compute Unified Device Architecture)的NVIDIA GPU,这是目前应用最广泛的平台进行GPU加速。
- 环境配置:安装相应的驱动程序、CUDA Toolkit以及深度学习框架(如TensorFlow、PyTorch等)的GPU版本。这些软件配合工作,能够让开发者通过简洁的API调用GPU进行计算。
- 模型设计时考虑并行性:在设计模型时,优化网络结构以便它能够利用GPU的并行处理能力。例如,选择合适的批处理大小(batch size),既不至于造成内存溢出,也要足够大以填满GPU的计算能力。
- 数据预处理:使用GPU加速数据预处理过程,如图像的缩放、归一化等操作。这可以通过深度学习框架的相关功能实现,如利用TensorFlow的
tf.dataAPI。 - 并行数据加载和增强:在训练时,并行地从磁盘加载数据并进行数据增强,以确保GPU在训练时始终保持充分利用,减少I/O操作导致的闲置时间。
- 优化计算图:使用深度学习框架的自动优化功能,它可以优化计算图,减少不必要的计算,合并可以合并的操作,以减少执行操作的次数。
- 精度调整:根据需要,使用混合精度训练(例如,结合FP32和FP16),这可以减少内存的使用,并可能进一步加速训练过程,尤其是在具备Tensor Cores的新型GPU上。
- 分布式训练:对于非常大的模型或数据集,可以使用多个GPU进行分布式训练,通过策略如模型并行化或数据并行化,在多个GPU间划分工作负载。
- 监控和调优:使用NVIDIA提供的工具,如NVIDIA Visual Profiler和NSight,监控GPU的使用情况,识别瓶颈,并进一步调优以提高效率。
通过这些方法,可以充分利用GPU强大的并行处理能力,大幅度提升模型训练和推理的速度。
模型部署和应用时的稳定性和性能
在大模型的部署和应用方面,以下是通常使用的工具和技术,以及如何确保模型的稳定性和性能:
工具和技术
1. 模型优化工具
- TensorRT:针对NVIDIA GPU优化的高性能深度学习推理(inference)引擎。
- ONNX (Open Neural Network Exchange):提供了一个开放格式来表示深度学习模型,并与ONNX Runtime配合,可以跨不同框架和硬件平台获得一致性的优化。
2. 服务化框架
- TensorFlow Serving、TorchServe:专为生产环境设计的系统,用于部署机器学习模型,支持模型版本控制、模型监测等高级功能。
- Triton Inference Server:支持多种框架、模型并发执行和动态批量处理的推理服务器。
3. 容器化技术
- Docker 和 Kubernetes:使用这些工具将模型封装成容器,便于快速部署、扩展和管理。
4. 云服务和自动化部署
- 利用 AWS Sagemaker、Azure ML、Google AI Platform 等云服务,它们提供了端到端的机器学习生命周期管理。
5. 自动扩缩容
- 结合使用负载均衡器和自动扩缩容策略,根据流量需求自动调整计算资源。
确保稳定性和性能
- 模型量化和简化:对模型进行量化(减少数值精度)和剪枝(移除冗余节点)来降低延时和内存占用,同时尽量保持模型性能。
- 压力测试和基准测试:使用工具如 Locust 或 JMeter 进行压力测试和基凌测试,确保系统在高负载下也能维持稳定运行。
- 持续集成和持续部署 (CI/CD):实施CI/CD流程,自动化模型的测试和部署流程,快速反馈问题并修复。
- 监控和日志:使用 Prometheus、Grafana、ELK stack (Elasticsearch, Logstash, Kibana) 等工具实时监控系统性能和收集日志,快速诊断和解决问题。
- 异常检测和自愈策略:实现异常检测机制和自愈策略,如当模型服务出现问题时自动重启服务或切换到备用实例。
- A/B 测试和金丝雀发布:在实际环境中,采用A/B测试和金丝雀发布策略逐渐更新模型,确保新版本的模型不会影响现有系统的稳定性。
- 资源隔离和优先级设置
资源隔离
资源隔离是指在硬件资源(如CPU、GPU、内存、存储等)使用上,确保不同模型或任务之间相互隔离,以免争用导致性能下降或服务中断。资源隔离可以通过以下方法实现:
1)虚拟化技术
- 使用虚拟机(VMs)或容器技术(如Docker)来隔离不同的应用。
- 为每个模型分配独立的计算资源,确保它们不会因为共享底层硬件而相互干扰。
2) 集群管理系统
- 使用Kubernetes等集群管理系统可以高效地处理容器化工作负载的调度与隔离。
- 可以设置资源配额和限制,避免单个任务占用过多资源。
3) 服务级别的隔离
- 在微服务架构中,每个服务可以运行在独立的资源环境中。
- 确保关键服务,如模型推理服务,获取必需的计算资源。
4) 网络隔离
- 网络流量控制和带宽限制也是确保稳定性的重要方面。
- 防止大量数据传输时对其他服务造成影响。
优先级设置
确保关键任务优先执行,非关键任务在资源紧张时可以暂缓或降级:
1) 优先级队列
- 利用作业队列管理请求,并根据预设优先级处理任务。
- 例如,可以给实时用户请求的模型推理任务更高的优先级,而对于离线批量处理任务则可以降低优先级。
2) 负载监控与动态调整
- 实时监控系统负载情况,当检测到资源压力时,自动降低低优先级任务的资源分配。
- 动态调整服务的规模(如自动扩展),以适应不断变化的负载。
3) 优先级感知的调度器
- 开发或使用支持优先级设置的调度器,确保系统按照既定优先级执行任务。
- 这些调度器可以根据任务的紧急程度和重要性来调整资源分配。
4) 服务质量(QoS)策略
- 通过定义不同服务级别协议(SLAs),明确各类任务对资源的需求。
- QoS策略可确保即使在高负载
选择预训练模型并进行微调
选择适合自己的基座模型(foundation model)需要考虑多种因素,包括你的应用领域、资源限制、可用技术和特定任务需求。以下是选择基座模型时可能需要考虑的情况:
应用领域
- 通用文本处理:如果需要进行文本生成、分类、摘要等通用语言任务,可以选用像GPT-3或BERT这样的大型通用语言模型。
- 专业领域(比如医疗或法律):在这种情况下,你可能需要一个已经针对特定领域预训练过的模型,例如BioBERT(医疗领域BERT变种)。
资源限制
- 计算资源丰富:如果有足够的计算资源,可以使用最先进的大型模型,如GPT-4或T5。
- 计算资源受限:在资源受限的情况下,可以选择DistilBERT、MobileBERT等小型化模型,它们旨在保持较好的性能同时减少资源消耗。
技术可用性
- 无需微调能力:如果不打算对模型进行微调,那么可以选择零售即用型API服务,如OpenAI提供的GPT-3.5 API。
- 需要微调能力:如果需要根据自己的数据集对模型进行微调,可能需要选择可以下载并自行训练的开源模型,比如http://huggingface.co提供的各类Transformer模型。
任务需求
- 文本生成:GPT-3.5是一个强大的文本生成模型,在创作故事、代码、文章等方面表现出色。
- 文本理解:BERT及其变体(比如RoBERTa、ALBERT等)在文本分类、问答任务和实体识别等方面表现优异。
举例说明:科研团队需要在生物医药领域进行文献挖掘
- 可以选择Domain-specific的模型,如BioBERT,该模型针对生物医学文献进行了预训练,能更好地理解相关术语和概念。
- 初创公司希望构建聊天机器人服务客户:
- 初期可能资源有限,可以选择使用DistilGPT或者轻量级的ALBERT,并结合Transfer Learning技术进行微调以满足特定任务需求。
- 大型企业希望分析客户反馈来进行情感分析:
- 可以直接使用预训练的BERT或其变种,并在具有大量客户反馈的数据上进行微调,以提高情感分类的准确度。
当然,这些仅是指导性意见。实际选择时,还需要综合考虑数据隐私、成本效益、模型的可解释性、稳定性等其他因素。
对NLP中些基本任务和方法的理解
自然语言处理(NLP)是人工智能领域的一个分支,它涉及到理解、解释和操作人类语言的各种任务。以下是对于NLP中一些基本任务和方法的深度解释:
1. 分词
分词是自然语言处理(Natural Language Processing,简称NLP)中的一项基础任务,其目标是将一个给定的文本字符串切分成若干个有意义的单元,这些单元通常指的是单词、词汇或者短语。在不同的语言中,分词的方式和难度各异。例如,在英语等使用空格作为自然分隔符的西方语言中,基本的分词可以相对简单地通过空格来实现。然而,在中文等没有明显词界分隔符的语言中,分词则更为复杂。
中文分词的挑战
- 无空格分隔:中文文本中词与词之间没有明显的分隔标志,如空格或者标点符号。
- 歧义和多义性:一个字符序列可能对应多种切分方式,且每一种切分方式都有合理的解释。
- 新词问题:语言是持续发展变化的,新词汇层出不穷,传统的基于词典的分词系统可能难以覆盖所有新词。
- 上下文相关性:依存于上下文,同样的字符序列可能在不同的语境下有不同的切分方式。
分词方法的分类
基于规则的分词
- 这种方法依赖预定义的词汇表和一系列切分规则。算法通过扫描文本,尝试匹配最长的词条或按照规则进行拆分。
基于统计的分词
- 统计模型通常通过大量已经分词的文本(语料库)学习词的边界。隐马尔可夫模型(HMM)和条件随机场(CRF)是两种典型的统计模型用于分词任务。
基于深度学习的分词
- 随着深度学习技术的发展,基于深度神经网络的分词方法已经成为主流。比如RNN、LSTM、GRU等循环神经网络及其变体,以及BERT、GPT这类预训练模型都被成功应用于分词任务中。
评估分词效果的指标
- 分词的效果通常通过准确率(Precision)、召回率(Recall)以及它们的调和平均——F1分数来衡量。
实际应用
分词在NLP领域有广泛的应用,如搜索引擎、情感分析等。
2. 词嵌入(Word Embeddings)
嵌入(Embedding)是一种将离散的符号或对象映射到连续向量空间中的技术。在自然语言处理中,嵌入常用于将文本中的单词或字符转换为向量表示,以便计算机可以更好地理解和处理文本数据。
嵌入的原理是通过学习将离散符号映射到连续向量空间中的映射函数。这个映射函数可以是一个神经网络模型,也可以是其他的统计模型。通过训练模型,使得相似的符号在嵌入空间中距离更近,不相似的符号距离更远。嵌入的目标是捕捉符号之间的语义和语法关系,以便计算机可以通过向量运算来理解和推理。
嵌入可以使用不同的数学公式进行解读,其中最常见的是 one-hot 编码和词嵌入。
1).0ne-hot 编码: 将每个符号表示为一个高维稀疏向量,向量的维度等于符号的总数。每个符号都对应向量中的一个维度,该维度上的值为 1,其他维度上的值为 0。例如,对于一个包含 4 个符号(A、B、C、D) 的词汇表,A可以表示为[1,0,0,0],B 可以表示为[0,1,0,0],以此类推
2). 词嵌入: 词嵌入是一种将单词或短语从词汇表映射到连续(实数值)向量空间中的嵌入技术。它通过训练模型来学习单词之间的语义关系。这些向量旨在捕获单词的语义含义,其中语义相似的单词具有相似的表示。
常见的词嵌入方法有 Word2Vec、GloVe 和 BERT 等。例如,可以使用 Word2Vec 模型将单词映射为 300 维的向量表示。
- 举例:
- Word2Vec:通过训练神经网络模型学习词汇的统计属性,生成密集的词向量。
- GloVe:利用全局单词-单词共现矩阵来预测单词之间的关系,并产生词向量。
- FastText:在Word2Vec的基础上增加了子词信息,使得它可以更好地处理罕见词或外来词。
词嵌入的核心优势在于它能够减少维度灾难,并允许机器学习算法高效地处理文本数据。
词嵌入背景
在深度学习兴起之前,传统的文本表示方法如one-hot编码,会遇到维度灾难和单词间关系无法表示的问题。比如,在one-hot编码中,每个单词都被表示为一个很长的向量,这个向量的维度等于词汇表的大小,其中只有一个位置的值是1,其余位置的值都是0。这种表示方法忽略了单词间的相似性,'king' 和 'queen' 虽然在语义上相近,但它们的one-hot向量却是正交的。
词嵌入原理
词嵌入的基本思想是将单词映射到一个连续的向量空间中,并且希望在这个空间中,语义或者功能相似的词彼此接近。这样的词向量通常是低维的,并且是稠密的,每个维度都是一个实数,相比于稀疏的one-hot向量,可以大大降低模型的复杂度。
词嵌入方法
- 基于计数的方法:如Latent Semantic Analysis(LSA),通过矩阵分解技术来找到词汇和文档之间的隐含关系。
- 预测模型:如Word2Vec(Skip-gram和CBOW),GloVe等。这些模型通常通过定义一个预测任务,例如给定上下文预测当前单词(或反之),通过优化这个任务来学习词向量。
词嵌入特点
- 分布式表示:每个维度不再代表某个具体的语义特征,而是多个特征的组合,信息分布在整个向量中。
- 语义相似性:在向量空间中,语义上相近的词汇通常在距离上也较为接近。
- 处理歧义:一些高级的词嵌入模型如ELMo、BERT可以生成上下文相关的词嵌入,进而能更好地处理词汇的多义性。
词嵌入应用
词嵌入广泛应用于各种NLP任务,如情感分析、机器翻译、命名实体识别等,它提供了一种强大的方式来表达文本数据,对于改善模型的表现至关重要。
3. 文本分类(Text Classification)
文本分类是指使用机器学习方法自动将给定的文本分派到一个或多个预定义的类别中。这是自然语言处理领域中的一项基本任务,广泛应用于垃圾邮件检测、情感分析、新闻分类、主题标签赋予等场景。
基础概念
- 文本: 在此上下文中,文本通常是指任何形式的书面语言表达,例如文章、社交媒体帖子、评论、电子邮件等。
- 分类: 是指识别文本所属的类别或类目的过程。
关键任务
- 特征提取: 将文本转换为模型可处理的数值形式,这涉及到从原始数据中提取出有用的信息作为特征。传统方法包括词袋(Bag-of-Words)、TF-IDF等。深度学习方法则通过嵌入层直接学习单词或短语的密集表示。
- 模型训练: 使用算法如朴素贝叶斯、逻辑回归、支持向量机(SVM)、随机森林或深度神经网络等对特征进行学习,并产生分类决策。
- 评估与优化: 通过精确度、召回率、F1分数等指标来评估模型性能,并根据实际需求对模型进行调整和优化。
方法论
文本分类的方法大致可以分为以下几种:
- 基于规则的方法: 利用特定的关键词或模式来识别文本的类别。其优点在于简单易行,但缺点是灵活性差,无法很好地应对复杂或变化的数据。
- 基于传统机器学习的方法: 这些方法依赖于手工设计的特征(如词频、TF-IDF)。朴素贝叶斯、SVM、决策树等算法在这一框架内广泛使用。
- 基于深度学习的方法: 利用卷积神经网络(CNN)、循环神经网络(RNN)、长短期记忆网络(LSTM)和Attention机制或它们的组合来进行特征提取和分类。近年来,Transformer模型及其变体(如BERT、GPT等)由于其出色的表现已成为该领域的主流。
应用场景
文本分类技术被广泛应用于多种业务场景,包括:
- 情感分析: 分析用户评论或产品评价中的情感倾向。
- 垃圾邮件检测: 自动识别并过滤掉垃圾邮件。
- 话题识别: 对文章或文档进行主题分类。
- 意图识别: 在对话系统中判断用户的询问意图。
挑战
- 类别不平衡: 在某些数据集中,一些类别的样本可能远多于其他类别,导致模型偏向于多数类。
- 多标签分类: 一个文本可能属于多个类别,这给分类任务带来了额外的复杂性。
- 文本长度和噪声: 文本长度可能会影响分类效果,而且文本中的噪声(错别字、俚语等)也可能干扰模型的判断。
- 语言和文化差异: 跨语言或跨文化的文本分类需要模型能够理解和适应不同的语言表达和文化背景。
4. 命名实体识别(Named Entity Recognition,NER)
命名实体识别是自然语言处理(NLP)领域中的一项关键技术,旨在从文本中识别出具有特定意义的实体,并将这些实体划归到预定义的类别中。典型的实体类别包括人名、组织名、地点名以及时间表达式等。
基本概念
- 实体: 在文本中可以代指某个具体或抽象事物的连续字符序列。
- 命名实体: 特指那些能够唯一标识个体(如人、组织或地点)的实体。比如,“OpenAI”指的是一个特定的组织。
- 识别: 是指通过算法自动检测文本中的实体,并进行分类的过程。
关键任务
- 实体边界识别: 确定一个实体的起始和结束位置。
- 实体分类: 将识别出的实体分配到适当的类别。
方法论
NER的方法大致可以分为以下几种:
- 基于规则的方法: 依赖手工编写的规则来识别实体。例如,利用正则表达式匹配特定模式的字符串作为时间或日期实体。
- 基于统计的方法: 利用机器学习算法学习特征与实体类别之间的关系。这包括支持向量机(SVM)、隐马尔可夫模型(HMM)、条件随机场(CRF)等传统机器学习方法。
- 基于深度学习的方法: 近年来,深度学习方法,尤其是循环神经网络(RNNs)、长短期记忆网络(LSTMs)和最近的变换器模型(如BERT、GPT等),因其在文本表示方面的强大能力而成为主流。这些模型能够自动提取复杂的特征并在大规模数据集上进行训练。
应用场景
命名实体识别在多种应用中都非常重要,比如信息提取、问答系统、知识图谱构建、内容推荐、舆情分析等。
挑战
- 跨领域泛化性: 不同领域(如金融、医疗)可能需要识别不同种类的实体,而且对实体精确性的要求各不相同。
- 上下文歧义: 相同的词汇在不同的上下文中可能代表不同的实体类型。
- 数据稀缺: 对于一些特定领域或语言,可能缺乏足够的标注数据进行模型的训练。
- 实体嵌套: 在某些情况下,一个实体内部可能包含另一个实体,这给实体边界的确定带来了困难。
总结
命名实体识别是提取文本信息,增强文本理解能力的基础。随着深度学习技术的不断进步,NER的准确率和效率都有了显著的提升,但仍然存在一些待解决的问题和挑战。在未来,希望能开发出更加鲁棒、泛化能力强,并且可以适应动态发展的实体类型的NER系统。
过拟合和欠拟合的防止
过拟合(Overfitting)
过拟合是指模型在训练数据上学到了太多的细节和噪声,以至于它在新的未见过的数据上表现不佳。具体来说,这意味着模型在训练集上的准确率很高,但是当应用到验证集或测试集上时,性能急剧下降。过拟合的主要原因是模型太复杂,学习能力过强,导致它捕捉到了训练样本中的特定特征,而这些特征并不具有普遍性。
防止过拟合的方法
- 数据增强:通过旋转、缩放、裁剪等方式对图像进行变换,或者在文本和语音数据上应用诸如同义词替换、音频伸缩等技术,从而扩大训练集,增加模型的泛化能力。
- 正则化:引入L1、L2正则化项或使用Elastic Net结合两者的优点,使得模型参数在优化过程中保持较小的值,防止模型过度依赖某些可能是噪声的特征。
- 交叉验证:使用K折交叉验证确保模型在不同的数据子集上都具有良好的性能。
- Dropout:在神经网络中随机丢弃一部分神经元,以增强网络的泛化能力。
- 早停法(Early Stopping):在训练过程中监视验证集的性能,当性能开始下降时停止训练。
- 模型简化:选择更简单的模型或减少网络层数和参数数量,避免创建过于复杂的模型。
欠拟合(Underfitting)
欠拟合指的是模型过于简单,不能在训练集上获得足够低的误差,因此无法捕捉数据中的基本规律,导致在训练集和测试集上都有不好的性能。欠拟合通常是由于模型复杂度不足,或者训练不充分所导致。
防止欠拟合的方法
- 增加模型复杂度:选择更复杂的模型,例如添加更多层次或神经元到神经网络中。
- 特征工程:寻找更好的特征集合,包括特征选择和特征构造,以增强模型的预测能力。
- 更多训练周期:增加训练次数直到模型在训练集上达到较低的误差。
- 减少正则化:如果使用了正则化,减少正则化参数可以让模型更自由地学习训练数据。
- 确保数据质量:检查数据是否干净、完整,且没有错误,因为低质量数据会影响模型性能。
在面对大规模数据时,需要特别注意模型的选择和训练策略。大规模数据集可能会带来计算资源上的挑战,并且可能需要分布式训练或模型压缩技术。同时,也要确保数据的质量和多样性,避免由于数据偏差而导致的过拟合问题。
简要描述下列概念在大语言模型中的作用
- Transformer 架构
- Attention 机制
- 预训练与微调
- 过拟合和欠拟合
Transformer 架构
Transformer是一种基于自注意力机制的深度学习模型,它在论文“Attention Is All You Need”中首次提出。与此前流行的循环神经网络(RNN)和长短期记忆网络(LSTM)相比,具有并行处理能力强和能够捕捉长距离依赖的优势。
Transformer在NLP领域的大多数任务中,如语言模型、机器翻译、文本摘要等,都取得了明显的性能提升。核心组件包括:
- 自注意力(Self-Attention)机制:使模型能够在序列的不同位置之间建立直接的依赖关系,无论它们在序列中的距离有多远,从而更好地捕捉远距离依赖。
- 多头注意力(Multi-Head Attention):并行地学习序列中不同位置的信息,使模型可以从多个子空间中同时提取不同的特征,增强模型的学习能力。
- 位置编码(Positional Encoding):由于Transformer模型缺乏循环结构,无法自然地利用序列顺序信息,位置编码通过添加到输入中来为每个元素提供位置信号。
- 编码器-解码器(Encoder-Decoder)架构:编码器负责处理输入序列,解码器用于生成输出序列。在编码器和解码器中都有多个相同的层叠结构,每个层中都有自注意力和全连接网络。
Transformer在大语言模型中的作用
Transformer架构通过其创新性的设计,在大型语言模型中提供了高效的并行计算、强大的上下文捕捉能力以及灵活的架构选择,在大型语言模型中,Transformer架构已经成为一个范式,其主要作用有:
- 提升并行化能力:由于Transformer不依赖于序列中的先前状态,模型在训练时能够高效地利用硬件架构,尤其是GPU,来进行大规模并行计算,这大幅度提高了训练效率。
- 强化长距离依赖捕捉能力:自注意力机制能够直接捕获序列中任意两点之间的关系,对于理解和生成长文本尤为重要,使得大语言模型能够更好地理解复杂的上下文和语义信息。
- 提供灵活的架构选择:Transformer的编码器和解码器模块可以根据任务需要灵活组合。例如,BERT模型只使用了编码器部分来理解文本,而GPT系列模型则使用解码器以自回归方式生成文本。
- 改善上下文表达能力:利用多头注意力机制,模型能够综合理解和表达不同层面的上下文信息,从而捕捉语言中的多样性和复杂性。
Attention 机制
- Attention 机制是一种用于提高序列模型性能的技术,它使模型能够动态地聚焦于序列中不同部分的信息。其核心原理是根据输入序列的每个元素与当前目标的相关性(即attention score)来加权输入序列的表示。这些权重决定了在生成输出时应该给予每个输入元素多少注意力。
- 该机制通常涉及三个关键组成部分:查询向量(Query, Q)、键向量(Key, K)和值向量(Value, V)。通过计算Q与各个K之间的相似度来生成权重(即attention scores),然后这些权重用于加权V,以输出加权的和,这反映了输入的不同部分的一种综合表示。在多头注意力(multi-head attention)的情况下,这个过程会多次同时进行,每次使用不同的Q,K,V权重,能够允许模型在不同的表示子空间中捕捉到输入的不同方面的信息。
- 具体地,Q,K,V是通过对同一个输入向量进行不同的线性变换(即乘以训练中学习的权重矩阵)得到的,这允许模型采用每个输入的不同表示形式来执行不同的任务。
Attention 机制在大语言模型中的作用
- 大语言模型中,Attention 机制能够使得模型高效处理长距离上下文信息,这意味着每个单词或词元可以与前文中的任意单词直接相互作用,无论它们在序列中的距离有多远。由于这种能力,Attention 机制在捕捉文本的上下文关系、语法结构和意义层次方面表现非常出色。
- Attention 机制有效地增强了模型的表示能力,能够学习更细致、复杂的语言规则和模式。它也是实现并行化处理的关键,因为不同的attention权重可以独立计算,大大提高了训练效率。
- 训练期间,Attention 机制能够让信息在网络不同层之间流动,这使得模型能够逐渐在更高层次上抽象和理解语言。在预测时,模型能够考虑到与当前预测最相关的上下文,从而生成更准确、连贯的文本。
预训练
1. 简要描述预训练
- 预训练(pre-training)是大语言模型如GPT (Generative Pre-trained Transformer)等的发展过程中的一项关键技术。它涉及在巨大的文本语料库上训练一个语言模型,而不需要特定的任务标签。预训练的目标是让模型学习到语言的通用表征,包括词汇、语法、句法结构和部分语义知识。预训练通常使用非监督或自监督的学习任务,如掩码语言模型(在BERT中)或是下一个单词预测(在GPT中),通过这些任务模型捕捉到语言的统计规律。
- 预训练的模型通常包含数以亿计的参数,它们能够从文本中提取复杂的特征并建立长距离依赖关系。对于Transformer架构而言,预训练同样包含学习自注意力(self-attention)机制的权重,这使得模型能够在处理每个词时考虑到句子中的所有其他词。
2. 预训练在大语言模型中的作用
预训练在大语言模型中的作用是多方面的:
- 基础语言理解:预训练帮助模型学会理解语言的基本结构和语义,构建起一种对自然语言普遍特性的表征(Representation)。这种表征能够捕捉词汇、语法、句法和语义等多方面的信息,使模型能够对不同的语言输入进行有效的理解和处理。通过这种普遍性的表征,模型能够在后续的下游任务中更好地适应和迁移学习到的知识。
- 知识融合:在从广泛的语料中学习时,模型可以吸收丰富的常识、事实知识和领域信息,这为后续特定任务提供了有力支撑。
- 迁移学习:通过预训练获得的语言表征可以迁移到不同的下游任务,通过微调(fine-tuning)使得模型在小规模标记数据上表现优异。
- 效率和经济性:预训练一次,多次利用的模式减少了对大量标记数据的需求,相比从零开始训练模型更加高效且成本效益更高。
- 模型泛化:预训练使得模型在看到新任务或新数据时能够更好地泛化,因为它已经在预训练阶段学习到了语言的广泛模式和结构。
微调
1. 简要描述微调(Fine-Tuning)
微调(Fine-Tuning)是对大型预训练语言模型训练过程的第二阶段,目的是调整和优化模型的参数以适应特定的下游任务和数据分布,以提高模型的表现。在这个过程中,模型已经在海量数据集上进行了预训练,通过这个预训练,模型已经学会了语言的基本结构和模式;也就是说,模型已经具备广泛的语言理解和生成的能力。继预训练之后,微调会针对具体任务对模型进行专门的调整,典型的微调任务包括文本分类、情感分析、问题回答等。
微调在广泛的预训练阶段之后,此时模型已经掌握了语言的基本语法、句法和一般知识。微调通常涉及以下几个步骤:
- 选择一个或多个具体的下游任务,如文本分类、命名实体识别、情感分析等。
- 准备相关任务的标注数据集,这个数据集一般相较于预训练数据集较小,但更为专业或专门化。
- 使用这个专门的数据集来继续训练模型,调整模型参数。训练的过程中会使用如交叉熵损失函数等具体的优化目标。
大模型的微调分成两种:
- 针对全量的参数--全量微调FFT(Full Fine Tuning)。
- 只针对部分的参数进行训练PEFT(Parameter-Efficient Fine Tuning)。
【业界常用的PEFT方案:Prompt Tuning、Prefix Tuning、LoRA、QLoRA】
2. 微调(Fine-Tuning)在大语言模型中的作用
微调在大语言模型中的核心作用是为了使通用预训练模型适应特定的应用或任务。在预训练阶段,模型学习了大量的语言知识和通用能力,但通常缺少对任务特定场景的优化。具体来说,微调的主要作用包括:
- 模型个性化:通过微调,模型可以学习到特定领域的词汇、术语及其语义,例如,医疗、法律或金融等领域的专业术语。
- 性能提升:在特定任务上继续训练能提高模型的精确度和召回率,减少不相关的一般性知识对预测的干扰。
- 快速适应新任务:通过微调大型模型能够迅速适应新环境或任务,这比重头训练一个新模型要经济和高效。
- 使用少量数据就能取得较好的效果:由于通用基础已经在预训练过程中建立,微调使模型能在相对较少的标注数据上就实现较高的性能。
过拟合和欠拟合
1. 过拟合(Overfitting)
- 模型在训练数据上表现出色,但在新的、未见过的数据上性能差。
- 原因通常是模型复杂度过高,学习到了训练数据中的噪声和特定特征。
2. 欠拟合(Underfitting)
- 模型在训练数据上表现不佳,通常也会在测试数据上表现不佳。
- 原因是模型过于简单,不能捕捉数据中的基本结构。
3. 作用于大语言模型
- 过拟合会降低模型在实际应用中的泛化能力。
- 欠拟合则表明模型没有足够的能力理解数据。
- 适当的模型复杂度、数据正则化和其他技术(如早停)是保证模型性能的关键。
解释BERT模型中的MLM和NSP的工作原理
BERT(Bidirectional Encoder Representations from Transformers)模型的结构、预训练任务以及微调(Fine-tuning)阶段:
输入表示,BERT模型的输入表示是通过以下三种类型的嵌入组合而成的:
- Token Embeddings:词向量嵌入,表示输入序列中的每个单词或标记。
- Segment Embeddings:区分对话或文本中的不同片段(例如,两个句子的起始和结束位置)。
- Position Embeddings:表示单词在序列中的位置信息。
预训练任务,BERT的预训练包括两个主要任务:
Masked Language Model (MLM):
- 输入序列的处理:
- 随机选择15%的token。
- 80%的选中token被替换成
[MASK]标记(即[CLS])。- 10%的选中token被替换成随机token。
- 剩余10%的选中token保持不变。
- 构建预测目标,即原始选中的token。
- Transformer的自注意力机制:
- 利用周围未掩盖的token来理解上下文。
- 整合来自双向上下文的信息。
- 预测及优化:
- 输出选中token的概率分布。
- 与预测目标(即token的真实值)进行比较。
- 使用交叉熵损失函数优化模型参数。
Next Sentence Prediction (NSP):
- 输入序列的构建:
- 拼接两个句子A和B。
- 有50%的概率B是A的下一句,另外50%则随机选择。
- 构建分类目标,即句子是否连续(IsNext)或非连续(NotNext)。
- Transformer的自注意力机制:
- 理解两个句子之间的关联。
- 学习表示句子关系的嵌入。
- 预测及优化:
- 输出句子关系的分类结果。
- 与分类目标进行比较。
- 使用交叉熵损失函数优化模型参数。
Fine-tuning阶段(下游任务适配)
- 调整模型输出与任务对应:
- 根据具体任务调整BERT模型的输出层。
- 继续优化模型参数:
- 微调模型参数以适应具体任务,例如文本分类、命名实体识别等。
通过上述结构化的预训练和微调过程,BERT模型能够在多种自然语言处理任务中取得显著的效果。
Masked Language Model (MLM)
1. 输入序列的处理
- 随机选择输入序列中的15%的token进行遮蔽。
- 这些选中的token会有80%的概率被[MASK]替换,10%的概率被随机token替换,另外10%的概率保持不变。
- 构建预测目标:选择这些token的原始形态。
2. Transformer的自注意力机制
- 利用周围未被掩盖的token来理解每个[MASK]位置的上下文信息。
- 通过自注意力机制,模型可以综合左右两侧的上下文信息来预测[MASK]位置的token。
3. 预测及优化
- 模型输出每个[MASK]位置的token概率分布。
- 将预测结果与真实token值(标签)进行比较。
- 使用交叉熵损失函数进行优化。
Next Sentence Prediction (NSP)
1. 输入序列的构建
- 输入由两个句子A和B构成,它们被拼接在一起,模型需要预测B是否自然地跟随A。
- 在预训练的数据准备阶段,B有50%的概率是A的实际下一句,另外50%的概率是从语料库中随机挑选的句子。
- 设置分类目标:如果B是A的下一句,则标记为IsNext,否则标记为NotNext。
2. Transformer的自注意力机制
- 通过自注意力机制,BERT可以整合两个句子的信息,以衡量其相互间的逻辑和连贯性。
- 模型学习并理解句子关系,得到两个句子间关系的表示。
3. 预测及优化
- 模型输出一个二分类结果,预测句子B是否是句子A的下一句。
- 将预测结果与真实分类标签进行比较。
- 使用交叉熵损失函数对模型参数进行优化。
通过这两种预训练任务,BERT不仅能够理解单词和句子的内部结构,还能理解它们之间的关系。这些能力在完成Fine-tuning阶段时,使得BERT在各种NLP下游任务,如问答、情感分析、文本摘要等方面,都有出色的表现。
描述 GPT 和 BERT 模型架构的主要区别及其优缺点
GPT和BERT是自然语言处理领域的两个重要的预训练语言模型,它们有着不同的架构和优缺点。以下是对两者的详细比较:
GPT
1. 架构
- 采用基于Transformer的解码器架构。
- 使用无监督学习的方式进行预训练。
- 从左到右依次生成文本。
2. 优点
- 生成能力:由于其单向性的架构,GPT特别擅长文本生成任务。
- 细粒度上下文理解:在生成文本时,GPT能够连贯地从前到后保持上下文信息。
- 直接Fine-tuning:GPT可以直接在下游任务上进行Fine-tuning。
3. 缺点
- 缺乏双向上下文:由于其单向的架构,GPT不能像BERT那样在预训练阶段捕获双向上下文信息。
- 生成时可能偏离主题,因为模型只能利用之前的上下文。
BERT
1. 架构
- 采用基于Transformer的编码器架构。
- 对输入文本中的随机单词进行遮蔽,然后预测这些单词。
- 使用Masked Language Model和Next Sentence Prediction的预训练任务。
2. 优点
- 双向上下文理解:BERT通过其Masked Language Model (MLM) 从整个句子两端同时获取上下文,能够更好地理解每个单词的意义。
- 适用性强:由于其深层次的双向理解,BERT在诸多NLP任务(如问答系统、情感分析等)上表现出色。
3. 缺点
- 有限的文本生成能力:BERT不像GPT那样适用于文本生成任务,因为它是为在已存在的上下文中填空(即预测Masked tokens)设计的。
- 预训练计算成本较高:由于其双向特性和对输入的重复注意力计算,BERT在预训练阶段通常需要更多计算资源。
让大模型处理更长的文本
在处理更长文本的问题上,由于Transformer架构本身的限制,长序列数据处理是稍微有挑战性的。这主要是因为Transformer模型的自注意力机制拥有O(n^2)的时间和空间复杂性,这里的n是序列的长度。为了应对这一挑战,在实践中,我们可以采用以下策略来优化处理长文本的能力:
策略
1. 优化自注意力机制
- Longformer:采用全局注意力到关键token和滑动窗口实现局部注意力。
- BigBird:类似于Longformer,通过稀疏注意力机制和随机全局注意力点增强处理长序列的能力。
- Reformer:使用Locality-Sensitive Hashing(LSH)来减少计算需求,便于处理长序列。
2. 修改模型架构
- Transformer-XL:通过相对位置编码和记忆机制允许模型利用之前的隐藏状态信息,有效地处理长文本。
- Adaptive Attention Span:缩小注意力窗口的大小来减少参数的数量,适用于文本中各个部分。
3. 采用分块策略
- 对输入序列进行分块处理,并在模型中嵌入一种机制来维持区块间的联系(如使用额外的代表性token和结合状态信息)。
4. 压缩表示
- 预处理步骤中使用文本压缩,如通过抽取和提炼来减少文本长度。
- 模型内无损压缩技巧,例如通过使用卷积或递归下采样来简化输入序列。
5. 层次化注意力
- 实施多层次的自注意力机制,首先在局部区块内进行注意力计算,然后在更高层次上处理区块间的关系。
实现细节
在实现上述策略时,以下的细节需要考虑:
- 计算和存储资源:评估模型的可扩展性需要的资源,优化内存管理同时保证效率和效果。
- 分块策略:确保分块过程不会损失重要的上下文信息,设计有效的跨区块上下文融合机制。
- 模型泛化能力:在优化长文本处理的同时,保持模型在短文本处理的性能。
- 训练与推理速度:采用的优化策略不应严重影响整体训练和推理的速度。
- 兼容性和迁移学习:确保新的长序列处理方法能够和现有模型架构以及先进的预训练方法相兼容。
结合这些策略和细节,在设计和实现大型模型处理长文本的能力时,我们可以有效地平衡性能和效率,以达到实际应用需求。
Zeroshot和Fewshot具体做法的区别
在面对Zero-shot(零样本学习)和Few-shot(小样本学习)学习问题时,两者的主要差异在于训练阶段可用的数据类型和数量。以下是两种方法的具体做法区别的详细分析:
Zero-shot Learning
在Zero-shot学习中,模型在没有看见任何类别特定样本的情况下对新类别进行推理。Zero-shot学习的关键之处在于将知识从已知类别泛化到未知类别。
1. 知识转移的关键
- 语义知识表达:使用属性、类别描述或者词嵌入来建立类别与特征之间的联系。
- 类别标签空间:将看见和未看见的类别映射到共享标签空间,如Word2Vec嵌入空间。
2. 模型设计
- 构建推断机制:设计模型能够基于现有知识结构化地推断未知类别。
- 充分利用训练数据:即便不直接从目标类别中学习,也要最大化从其他附加信息中学习。
Few-shot Learning
与零样本学习相对,Few-shot学习提供了少量的目标类别样本来指导学习过程。
1. 训练方法
- 数据增强:为了避免过拟合,采用诸如旋转、剪切、噪声添加等技巧增加样本多样性。
- Meta-learning:通过设计任务学习模型学习学习过程,即“学会学习”。
2. 模型设计
- 匹配网络:使用记忆增强组件和注意力机制来找到小样本和查询样本间的关系。
- 基于模型的适应性:利用如神经过程(Neural Processes)等模型快速适应新类别
零样本与小样本的做法对比
1. 数据使用
- Zero-shot:不使用任何目标类别样本。需利用类别描述或其他辅助信息。
- Few-shot:使用少量目标类别样本进行微调或元学习。
2. 训练策略
- Zero-shot:侧重于推广和抽象层次的泛化能力。
- Few-shot:集中在如何从极少的数据中快速学习。
3. 泛化能力
- Zero-shot:需在知识桥接未见类别上有强大的泛化能力。
- Few-shot:侧重于从少量信息中迅速概括并泛化。
4. 评估方法
- Zero-shot:在完全未见过的类别上评估。
- Few-shot:使用n-way k-shot设置进行评估,其中n是类别数,k是每类样本数。
为什么transformer要用Layer Norm为什么不用BN
当讨论Transformers模型相对于批量归一化(Batch Normalization, BN)而选择层归一化(Layer Normalization, LN)的原因时,可以从几个核心角度来分析和说明这一设计决策。
1. 计算特性
批量归一化(BN)
- 依赖于批次大小:BN依赖于一个批次中的所有数据,计算每个特征的均值和方差。
- 迷你批次效应:小批量大小可能会导致估计的准确性下降,这在小批量情况下尤为显著。
- 序列长度变化影响:在NLP任务中,序列长度通常是可变的,这会增加BN在处理不同序列长度时的复杂性。
层归一化(LN)
- 独立于批次大小:LN对每个样本独立计算统计值,因此其性能不会因批次大小而变化。
- 计算稳定性:由于它独立于其他样本,LN提供了更稳定的行为,尤其是对于小批量的情况。
2. 归一化方向
批量归一化(BN)
- 跨样本:BN对同一特征的所有样本进行归一化,可能导致批次间的差异被平滑掉,对模型学习个体样本特性是不利的。
层归一化(LN)
- 跨特征:LN在单个样本内部对所有特征进行归一化,保持了批次间样本的独立性。
3. 适应性
批量归一化(BN)
- 对RNN不友好:RNN及其变体(常用于处理序列数据)在不同时间步处理不同的数据,BN因其跨批次特性并不适用。
层归一化(LN)
- 适合序列模型:对于Transformers和RNN这类序列模型,LN在保持序列内部依赖性的同时提供了较好的归一化效果。
4. 实例一致
批量归一化(BN)
- - 对实例差异不敏感:BN对所有输入样本执行相同的归一化操作,不管它们的内部特征如何。
层归一化(LN)
- -维护实例差异性:LN通过在每个样本的所有特征上执行归一化,保持了实例之间的差异性。
结构总结
计算特性
- BN:依赖批次大小
- LN:独立于批次大小
归一化方向
- BN:纵向归一化(横跨样本)
- LN:横向归一化(内部特征)
适应性
- BN:适合固定长度输入和大批量处理
- LN:适合序列模型和变长输入
实例一致性
- BN:可能会减弱样本间差异
- LN:保持样本间差异
Transformer为什么要用三个不一样的QKV?

- 注意力层:使用多头注意力(Multi-HeadAttention)机制整合上下文语义,它使得序列中任意两个单词之间的依赖关系可以直接被建模而不基于传统的循环结构,从而更好地解决文本的长程依赖。
- 位置感知前馈层(Position-wiseFFN):通过全连接层对输入文本序列中的每个单词表示进行更复杂的变换。
- 残差连接:Add部分。它是一条分别作用在上述两个子层当中的直连通路,被用于连接它们的输入与输出。从而使得信息流动更加高效,有利于模型的优化。
- 层归一化:对应图中的Norm部分。作用于上述两个子层的输出表示序列中,对表示序列进行层归一化操作,同样起到稳定优化的作用。
Multi-Head Attention
Multi-Head Attention,是由多个Self-Attention组成的,以捕获单词之间多种维度上的相关系数 attention score。左图是Self-Attention,右图是Multi-Head Attention,如下所示:

自注意力(Self-Attention)机制自然成了Transformer模型核心组件之一。该机制通过计算序列中各个元素之间的关系来捕捉序列的内部结构。在自注意力中,将输入序列线性变换生成三个矩阵:查询(Query, Q)、键(Key, K)和值(Value, V)是为了实现这一机制并优化其性能。
【self-Attention 接收的是输入(单词的表示向量组成的矩阵) 或者上一个 Encoder block 的输出。在计算的时候需要用到矩阵Q(查询),K(键值),V(值)】
***为什么Transformer需要进行Multi-head Attention,即多头注意力机制?
假如翻译一个句子,比如“The animal didn’t cross the street because it was too tired”,我们会想知道“it”指的是哪个词,这时模型的“多头”注意机制会起到作用。
它给出了注意力层的多个“表示子空间”(representation subspaces)。
可以类比CNN中同时使用多个滤波器的作用,直观上讲,多头的注意力有助于网络捕捉到更丰富的特征/信息。
Transformer的多头注意力借鉴了CNN中同一卷积层内使用多个卷积核的思想,原文中使用了 8 个 scaled dot-product attention (缩放的点积注意力),在同一 multi-head attention 层中,输入均为 KQV ,同时进行注意力的计算,彼此之前参数不共享,最终将结果拼接起来,这样可以允许模型在不同的表示子空间里学习到相关的信息,在此之前的 A Structured Self-attentive Sentence Embedding 也有着类似的思想。
简而言之,就是希望每个注意力头,只关注最终输出序列中一个子空间,互相独立。其核心思想在于,抽取到更加丰富的特征信息。不过,Multi-Head 的多个头并不一定就如我们所期望的那样去关注不同方面的信息。在 EMNLP 2018 的 Multi-Head Attention with Disagreement Regularization一文中采用正则化手段来保证每个头关注不同的子空间。
Self-Attention
Transformer模型中的注意力机制利用三个不同的负载矩阵:查询(Query, Q)、键(Key, K)和值(Value, V)是为了以灵活、高效的方式捕捉序列内部的依赖关系。这种设计背后的原理可以从以下几个方面来深入理解:
分解为不同Q, K, V的目的(简要回答版):
1). 提升表达能力:通过使用不同的参数矩阵将输入变换为Q, K, V,模型能够学习到更加丰富和多样的表示,每个表示捕捉输入数据的不同方面。这些不同的表示可以被解释为不同的抽象概念,比如“寻找什么”(Q)、“在什么上寻找”(K)、和“当找到之后要怎么处理”(V)。
2). 泛化能力:对Q, K, V的不同处理方式允许注意力机制学习在不同上下文中复用相似的模式(例如,无论语境如何,“问题”和“答案”的概念可能是类似的)。这样的设计引入了一种泛化,允许模型更好地适应新的、未见过的数据。
分解为不同Q, K, V的目的(详细回答版):
1). 提高泛化能力
更灵活的权重分配:在计算注意力权重时,Q 和 K 的线性变换产物进行点积操作,决定了每个元素给到其他元素的关注程度。不同的Q和K表示允许模型动态调整注意力权重,从而更好地适应数据中的模式和变化。
适应序列本质特征:注意力得分(即softmax(QKᵀ/√d_k))反映了输入序列各部分之间的相对相关性。通过调整Q、K的学习过程,Transformer可以更好地捕捉长距离依赖和复杂的序列关系,这对于处理自然语言等顺序相关性强的数据非常重要。
泛化关系模式:通过独立的参数矩阵进行线性变换,可以让模型学习到从数据中抽象和泛化出更加复杂的关系模式,而不仅仅是简单的匹配和复制。
2). 增强模型的表达能力:
定制化的信息抽取:V代表了要提取的信息,通过关联Q和K计算得出的权重,可以从V中提取更为丰富且相关的上下文信息。这样一来,模型不是简单地对原始输入进行编码,而是能够根据不同的情况提取不同的信息,这对于提高模型对输入数据的理解至关重要。
提供角色分离:在自注意力机制中,Q、K、V承担不同的角色。Q代表需要检索信息的部分,K代表被检索的部分,V则代表实际回传的信息内容。这种分离使得模型可以分开处理检索和传递信息的角色,增加模型的灵活性和表达能力。
增加复杂性:使用不同的变换矩阵,可以使得Q、K、V在高维空间有着不同的表示,强化了模型捕捉多样化关系的能力,例如,长距离依赖、语义关系等。
具体机制
具体来说,注意力机制通过对每个输入单元的Q与所有输入单元的K进行比较,并应用softmax函数来确定每个单元的V将如何被加权。计算注意力权重时使用的softmax函数,确保了即使在不同序列长度和复杂性的情况下,注意力分数也会被规范化(normalized),这样模型的泛化能力就会被提升。
Self-attention的公式为

其中,根号d_k是缩放因子(通常是K的维度开平方根),用于调整点积的大小,预防过大的点积导致softmax函数进入梯度很小的区域,影响训练效率。
总结一下:通过将输入序列分别映射到Q, K, V三种表示,Transformer不仅增强了模型的表达能力,还在注意力权重计算中引入泛化的可能性,使模型能够有效处理各种序列数据,并且对于自然语言的多样性和复杂性有着更强的适应性。这也是Transformer模型在自然语言处理任务中取得如此卓越表现的关键因素之一。
为了便于更好的理解Transformer的自注意力机制,现以图文的形式简要介绍一下计算自注意力的步骤:
计算自注意力的第一步就是从每个编码器的输入向量(每个单词的词向量)中生成三个向量。也就是说对于每个单词,我们创造一个查询向量、一个键向量和一个值向量。
第一步是计算查询矩阵、键矩阵和值矩阵。为此,我们将将输入句子的词嵌入装进矩阵X中,将其乘以我们训练的权重矩阵(WQ,WK,WV)。

x矩阵中的每一行对应于输入句子中的一个单词。

计算自注意力的第二步是计算得分。

第三步和第四步是将分数除以8(8是论文中使用的键向量的维数64的平方根,这会让梯度更稳定。这里也可以使用其它值,8只是默认值),然后通过softmax传递结果。softmax的作用是使所有单词的分数归一化,得到的分数都是正值且和为1。

这个softmax分数决定了每个单词对编码当下位置(“Thinking”)的贡献。显然,已经在这个位置上的单词将获得最高的softmax分数,但有时关注另一个与当前单词相关的单词也会有帮助。
第五步是将每个值向量乘以softmax分数(这是为了准备之后将它们求和)。这里的直觉是希望关注语义上相关的单词,并弱化不相关的单词(例如,让它们乘以0.001这样的小数)。
第六步是对加权值向量求和(译注:自注意力的另一种解释就是在编码某个单词时,就是将所有单词的表示(值向量)进行加权求和,而权重是通过该词的表示(键向量)与被编码词表示(查询向量)的点积并通过softmax得到),然后即得到自注意力层在该位置的输出。

这样自自注意力的计算就完成了。得到的向量就可以传给前馈神经网络。
我们可以将步骤2到步骤6合并为一个公式来计算自注意力层的输出。

为什么需要提示学习?
提示学习是一种在自然语言处理任务中引入人类编写的提示或示例来辅助模型生成更准确和有意义的输出的技术。以下是一些使用提示学习的原因:
-
解决模糊性:在某些任务中,输入可能存在歧义或模糊性,通过提供明确的提示,可以帮助模型更好地理解任务的要求,避免产生错误或不确定的输出。
-
控制生成:在生成式任务中,使用提示可以指导模型生成特定类型的输出。例如,在生成新闻标题的任务中,通过提示指定标题的主题或风格,可以使模型生成更符合要求的标题。
-
纠正偏见:在自然语言处理中,模型可能受到社会偏见的影响,通过在提示中明确要求模型避免偏见,可以帮助减少模型输出中的偏见。
-
增加一致性:通过在多个样本中使用相同的提示,可以确保模型生成的输出在不同输入上具有一致性。这对于任务如翻译或摘要生成等涉及多个输入的任务尤为重要。
总的来说,提示学习可以提供额外的信息和指导,帮助模型更好地理解任务和生成准确、有意义的输出。
什么是提示学习?
提示学习是一种在机器学习中使用人类编写的提示或示例来辅助模型进行学习和推理的技术。在自然语言处理任务中,提示通常是一段文字或问题,用于指导模型生成或理解特定的输出。
提示学习可以用于各种自然语言处理任务,包括文本分类、命名实体识别、情感分析、机器翻译等。在这些任务中,模型需要根据输入的文本来进行预测或生成输出。通过提供明确的提示,可以引导模型关注特定的信息或完成特定的任务。提示可以采用不同的形式,例如:
-
完整的句子或问题:提供完整的句子或问题,要求模型根据输入生成相应的回答或输出。
-
部分句子或关键词:提供部分句子或关键词,要求模型根据提示进行补充或扩展。
-
条件约束:提供条件约束,要求模型生成满足这些条件的输出。
通过提示学习,可以改善模型的性能,提高其准确性和鲁棒性。同时,提示学习也可以用于控制模型的生成,纠正偏见以及提供一致性的输出。
提示学习有什么优点?
提示学习是一种在自然语言处理任务中使用人工设计的提示或指导来辅助模型生成输出的方法。它具有以下几个优点:
-
控制生成输出:通过给定合适的提示,可以更好地控制模型生成的输出。提示可以引导模型关注特定的信息、执行特定的任务或生成特定的风格。这种控制使得模型更加可控,能够满足特定的需求。
-
提高生成质量:通过合理设计和使用提示,可以帮助模型生成更准确、更流畅、更有逻辑性的输出。提示提供了一种引导模型生成的方式,可以避免一些常见的错误和无意义的输出,从而提高生成质量。
-
解决数据稀缺问题:在某些任务中,训练数据可能非常稀缺,难以覆盖所有可能的输入和输出。通过使用提示,可以将模型的知识和经验引导到特定领域或任务中,从而提供更好的性能。这种方式可以在数据稀缺的情况下,利用有限的数据进行更有效的训练和生成。
-
提供可解释性:提示作为人工设计的输入,可以提供对模型生成输出的解释和理解。通过分析和调整提示,可以更好地理解模型在生成过程中的决策和行为,从而提高模型的可解释性。
-
简化训练过程:在某些任务中,模型的训练可能非常困难和耗时。通过使用提示,可以简化训练过程,减少模型的训练时间和计算资源的消耗。提示可以提供额外的信息和约束,帮助模型更快地收敛和学习。
需要注意的是,提示学习也存在一些挑战和限制,如如何设计合适的提示、如何平衡提示和自由生成等。因此,在使用提示学习时,需要根据具体任务和需求进行设计和调整,以获得最佳的效果。
提示学习有哪些方法?
提示学习有多种方法和技术,以下是一些常见的方法:
-
文本前缀(Text Prefix):在输入文本的开头添加一个人工设计的前缀作为提示。这个前缀可以是一个问题、一个指令、一个关键词等,用来引导模型生成相关的输出。例如,在文本生成任务中,可以在输入文本前添加一个问题,要求模型回答该问题。
-
控制标记(Control Tokens):在输入文本中使用特定的控制标记来指示模型生成特定的内容。这些控制标记可以是特殊的标记或标签,用来指定生成的风格、主题、任务等。例如,对于文本生成任务,可以使用不同的控制标记来指示生成正面或负面情感的文本。
-
问题模板(Question Templates):设计一系列问题模板,用于引导模型生成回答问题的文本。这些问题模板可以覆盖不同类型的问题,包括事实性问题、推理问题、主观性问题等。模型可以根据问题模板生成对应的回答。
-
策略优化(Policy Optimization):通过设计一个策略网络,引导模型在生成过程中做出合适的决策。策略网络可以根据当前的输入和上下文,选择合适的动作或生成方式。这种方法可以用于生成对话系统、机器翻译等任务。
-
知识引导(Knowledge Guided):利用外部的知识源来辅助模型生成输出。这些知识源可以是知识图谱、数据库、文档等,模型可以根据这些知识源进行查询、检索和引用。这样可以提供更准确、更丰富的信息来指导模型生成。
这些方法可以单独使用,也可以组合使用,根据具体任务和需求进行选择和调整。在实际应用中,需要根据数据集、模型架构和任务目标等因素来确定最适合的提示学习方法。同时,也需要进行实验和调整,以获得最佳的性能和效果。
前缀微调(Prefix-tuning)
为什么需要前缀微调?
前缀微调(Prefix-tuning)是一种在提示学习中使用的技术,它通过微调(fine-tuning)预训练语言模型来适应特定的生成任务。前缀微调之所以需要,是因为传统的预训练语言模型在生成任务中存在一些问题和限制,包括以下几个方面:
-
缺乏控制:传统的预训练语言模型通常是通过无监督学习从大规模文本数据中学习得到的,生成时缺乏对输出的控制。这导致模型往往会生成一些无意义、不准确或不符合要求的内容。
-
缺乏指导:传统的预训练语言模型在生成任务中缺乏指导,无法根据特定的任务要求生成相关的内容。例如,在问答任务中,模型需要根据给定的问题生成准确的答案,但预训练语言模型无法直接实现这一点。
-
数据偏差:预训练语言模型通常是从大规模的通用数据中训练得到的,而特定的生成任务往往需要针对特定领域或任务的数据。由于数据的偏差,预训练语言模型在特定任务上的性能可能会受到限制。
-
预训练语言模型:首先,使用大规模的无监督数据对语言模型进行预训练。这个预训练过程通常是通过自回归(autoregressive)的方式进行,模型根据前面的文本生成下一个词或字符。
前缀微调通过在输入文本的开头添加一个人工设计的前缀,将任务要求或指导信息引入到生成过程中,从而解决了上述问题。通过给定合适的前缀,可以控制模型生成的内容,指导模型关注特定的信息,并使生成结果更加准确和符合要求。前缀微调提供了一种简单有效的方法,可以在生成任务中引入人类设计的指导信息,提高模型的生成质量和可控性。
前缀微调思路是什么?
前缀微调(Prefix-tuning)的思路是在预训练语言模型的基础上,通过微调的方式引入任务相关的指导信息,从而提高模型在特定生成任务上的性能和可控性。以下是前缀微调的一般思路:
-
设计前缀:针对特定的生成任务,设计一个合适的前缀,作为输入文本的开头。前缀可以是一个问题、一个指令、一个关键词等,用来引导模型生成相关的输出。前缀应该包含任务的要求、指导或关键信息,以帮助模型生成符合任务要求的内容。
-
微调预训练模型:使用带有前缀的任务数据对预训练语言模型进行微调。微调的目标是让模型在特定任务上更好地生成符合要求的内容。微调的过程中,可以使用任务相关的损失函数来指导模型的学习,以最大程度地提高生成结果的质量和准确性。
-
生成输出:在实际应用中,使用微调后的模型来生成输出。将任务相关的输入文本(包含前缀)输入到模型中,模型根据前缀和上下文生成相应的输出。通过前缀的设计和微调过程,模型能够更好地理解任务要求,并生成符合要求的内容。
前缀微调通过在预训练语言模型的基础上引入任务相关的指导信息,使模型更加适应特定的生成任务。这种方法不仅提高了生成结果的质量和准确性,还增加了对生成过程的可控性,使模型能够更好地满足任务的需求。
前缀微调的优点是什么?
前缀微调(Prefix-tuning)具有以下几个优点:
-
可控性:通过设计合适的前缀,可以引导模型生成特定类型的内容,使生成结果更加符合任务要求。前缀提供了对生成过程的控制,使得模型能够根据任务需求生成相关的内容,从而提高生成结果的准确性和质量。
-
灵活性:前缀微调是一种通用的方法,可以适用于各种生成任务,包括文本摘要、问答、对话生成等。只需针对具体任务设计合适的前缀即可,无需重新训练整个模型,提高了模型的灵活性和可扩展性。
-
数据效率:相比于从零开始训练一个生成模型,前缀微调利用了预训练语言模型的知识,可以在相对较少的任务数据上进行微调,从而节省了大量的训练时间和资源。这对于数据稀缺的任务或领域来说尤为重要。
-
提高生成效果:通过引入任务相关的前缀,前缀微调可以帮助模型更好地理解任务要求,生成更准确、更相关的内容。相比于传统的预训练语言模型,前缀微调在特定任务上往往能够取得更好的性能。
-
可解释性:前缀微调中的前缀可以包含任务的要求、指导或关键信息,这使得模型生成的结果更加可解释。通过分析前缀和生成结果之间的关系,可以更好地理解模型在任务中的决策过程,从而更好地调试和优化模型。
综上所述,前缀微调通过引入任务相关的前缀,提高了生成模型的可控性、灵活性和生成效果,同时还具备数据效率和可解释性的优势。这使得前缀微调成为一种有效的方法,用于提升生成任务的性能和可控性。
前缀微调的缺点是什么?
尽管前缀微调(Prefix-tuning)具有很多优点,但也存在一些缺点:
-
前缀设计的挑战:前缀的设计需要考虑到任务的要求、指导或关键信息,以便正确引导模型生成相关内容。设计一个合适的前缀可能需要领域知识和人工调整,这可能会增加任务的复杂性和工作量。
-
任务依赖性:前缀微调是一种针对特定任务的方法,模型的性能和生成效果高度依赖于任务数据和前缀的设计。如果任务数据不足或前缀设计不合理,可能会导致模型性能下降或生成结果不符合预期。
-
预训练偏差:预训练语言模型的偏差可能会在前缀微调中得以保留或放大。如果预训练模型在某些方面存在偏差或不准确性,前缀微调可能无法完全纠正这些问题,导致生成结果仍然存在偏差。
-
对任务数据的依赖:前缀微调需要特定任务的数据用于微调预训练模型,如果任务数据不充分或不代表性,可能无法充分发挥前缀微调的优势。此外,前缀微调可能对不同任务需要单独进行微调,这可能需要更多的任务数据和人力资源。
-
可解释性的限制:虽然前缀微调可以增加生成结果的可解释性,但模型的内部决策过程仍然是黑盒的。模型在生成过程中的具体决策和推理过程可能难以解释,这可能限制了对模型行为的深入理解和调试。
综上所述,前缀微调虽然有很多优点,但也存在一些挑战和限制。在实际应用中,需要仔细考虑前缀设计、任务数据和模型的偏差等因素,以充分发挥前缀微调的优势并解决其潜在的缺点。
指示微调(Prompt-tuning)
为什么需要指示微调?
指示微调(Prompt-tuning)是一种用于生成任务的微调方法,它的出现主要是为了解决前缀微调(Prefix-tuning)中前缀设计的挑战和限制。以下是需要指示微调的几个原因:
-
前缀设计的复杂性:前缀微调需要设计合适的前缀来引导模型生成相关内容。然而,前缀的设计可能需要领域知识和人工调整,这增加了任务的复杂性和工作量。指示微调通过使用简洁的指示语句来替代复杂的前缀设计,简化了任务的准备过程。
-
指导信息的一致性:前缀微调中的前缀需要包含任务的要求、指导或关键信息。然而,前缀的设计可能存在主观性和不确定性,导致模型生成结果的一致性较差。指示微调通过使用明确和一致的指示语句来提供指导信息,可以更好地控制模型生成的结果,提高一致性和可控性。
-
任务的多样性和灵活性:前缀微调中的前缀是针对特定任务设计的,对于不同的任务需要单独进行微调。这对于多样的任务和领域来说可能需要更多的任务数据和人力资源。指示微调通过使用通用的指示语句,可以适用于各种生成任务,提高了任务的灵活性和可扩展性。
-
模型的可解释性:指示微调中的指示语句可以提供对模型生成结果的解释和指导。通过分析指示语句和生成结果之间的关系,可以更好地理解模型在任务中的决策过程,从而更好地调试和优化模型。
综上所述,指示微调通过使用简洁的指示语句替代复杂的前缀设计,提供明确和一致的指导信息,增加任务的灵活性和可解释性。这使得指示微调成为一种有用的方法,用于生成任务的微调,尤其适用于多样的任务和领域。
指示微调思路是什么?
指示微调(Prompt-tuning)的思路是通过微调预训练模型,并使用简洁的指示语句来指导模型生成相关内容。以下是指示微调的基本思路:
-
预训练模型:首先,使用大规模的无监督预训练任务(如语言模型、掩码语言模型等)来训练一个通用的语言模型。这个预训练模型能够学习到丰富的语言知识和语义表示。
-
指示语句的设计:为了指导模型生成相关内容,需要设计简洁明确的指示语句。指示语句应该包含任务的要求、指导或关键信息,以引导模型生成符合任务要求的结果。指示语句可以是一个完整的句子、一个问题、一个关键词等,具体的设计取决于任务的需求。
-
微调过程:在微调阶段,将预训练模型与任务数据相结合,使用指示语句来微调模型。微调的目标是通过优化模型参数,使得模型能够根据指示语句生成符合任务要求的结果。微调可以使用监督学习的方法,通过最小化任务数据的损失函数来更新模型参数。
-
模型生成:经过微调后,模型可以根据给定的指示语句来生成相关内容。模型会利用预训练的语言知识和微调的任务导向来生成符合指示的结果。生成的结果可以是一个句子、一段文字、一张图片等,具体取决于任务类型。
通过指示微调,可以在预训练模型的基础上,使用简洁明确的指示语句来指导模型生成相关内容。这种方法简化了任务的准备过程,提高了任务的灵活性和可控性,并增加了模型生成结果的一致性和可解释性。
指示微调优点是什么?
指示微调(Prompt-tuning)具有以下几个优点:
-
灵活性和可扩展性:指示微调使用通用的指示语句来指导模型生成任务相关内容,而不需要针对每个任务设计特定的前缀。这使得指示微调更加灵活和可扩展,可以适用于各种不同的生成任务和领域。
-
简化任务准备:相比于前缀微调,指示微调减少了任务准备的复杂性。前缀设计可能需要领域知识和人工调整,而指示语句通常更简洁明确,减少了任务准备的时间和工作量。
-
一致性和可控性:指示微调使用明确的指示语句来指导模型生成结果,提高了生成结果的一致性和可控性。指示语句可以提供任务的要求、指导或关键信息,使得模型生成的结果更加符合任务需求。
-
可解释性:指示微调中的指示语句可以提供对模型生成结果的解释和指导。通过分析指示语句和生成结果之间的关系,可以更好地理解模型在任务中的决策过程,从而更好地调试和优化模型。
-
效果提升:指示微调通过使用指示语句来引导模型生成任务相关内容,可以提高生成结果的质量和准确性。指示语句可以提供更明确的任务要求和指导信息,帮助模型更好地理解任务,并生成更符合要求的结果。
综上所述,指示微调具有灵活性和可扩展性、简化任务准备、一致性和可控性、可解释性以及效果提升等优点。这使得指示微调成为一种有用的方法,用于生成任务的微调。
指示微调缺点是什么?
指示微调(Prompt-tuning)也存在一些缺点,包括以下几点:
-
依赖于设计良好的指示语句:指示微调的效果很大程度上依赖于设计良好的指示语句。如果指示语句不够明确、不够准确或不够全面,可能导致模型生成的结果不符合任务要求。因此,需要投入一定的时间和精力来设计和优化指示语句。
-
对任务理解的依赖:指示微调要求模型能够准确理解指示语句中的任务要求和指导信息。如果模型对任务理解存在偏差或困惑,可能会导致生成结果的不准确或不符合预期。这需要在微调过程中充分训练和调整模型,以提高任务理解的准确性。
-
对大规模数据的依赖:指示微调通常需要大规模的任务数据来进行微调训练。这可能对于某些任务和领域来说是一个挑战,因为获取大规模的高质量任务数据可能是困难的。缺乏足够的任务数据可能会限制指示微调的效果和泛化能力。
-
可能导致过度指导:指示微调中使用的指示语句可能会过度指导模型生成结果,导致生成内容过于机械化或缺乏创造性。过度指导可能会限制模型的多样性和创新性,使得生成结果缺乏多样性和惊喜性。
-
难以处理复杂任务:对于一些复杂的任务,简单的指示语句可能无法提供足够的信息来指导模型生成复杂的结果。这可能需要设计更复杂的指示语句或采用其他更复杂的方法来解决任务。
综上所述,指示微调虽然具有一些优点,但也存在一些缺点。需要在设计指示语句、任务理解、数据获取和处理复杂任务等方面进行充分考虑和优化,以克服这些缺点并提高指示微调的效果。
指示微调与 Prefix-tuning 区别是什么?
指示微调(Prompt-tuning)和前缀微调(Prefix-tuning)是两种不同的方法,用于指导生成模型生成任务相关内容的技术。它们之间的区别包括以下几个方面:
-
输入形式:指示微调使用通用的指示语句来指导模型生成结果,这些指示语句通常作为输入的一部分。而前缀微调则在输入文本前添加一个特定的前缀,用于指导模型生成结果。
-
灵活性:指示微调更加灵活和可扩展,可以适用于各种不同的生成任务和领域。指示语句可以根据任务的要求和指导进行设计,而不需要针对每个任务设计特定的前缀。前缀微调则需要为每个任务设计特定的前缀,这可能需要领域知识和人工调整。
-
任务准备:前缀微调可能需要更多的任务准备工作,包括设计和调整前缀,以及对前缀的领域知识和语法规则的理解。而指示微调的任务准备相对简化,指示语句通常更简洁明确,减少了任务准备的时间和工作量。
-
一致性和可控性:指示微调使用明确的指示语句来指导模型生成结果,提高了生成结果的一致性和可控性。指示语句可以提供任务的要求、指导或关键信息,使得模型生成的结果更加符合任务需求。前缀微调的一致性和可控性取决于前缀的设计和使用方式。
-
可解释性:指示微调中的指示语句可以提供对模型生成结果的解释和指导。通过分析指示语句和生成结果之间的关系,可以更好地理解模型在任务中的决策过程,从而更好地调试和优化模型。前缀微调的解释性相对较弱,前缀通常只是作为生成结果的一部分,不提供明确的解释和指导。
综上所述,指示微调和前缀微调在输入形式、灵活性、任务准备、一致性和可控性以及可解释性等方面存在差异。选择哪种方法取决于具体的任务需求和实际应用场景。
指示微调与 fine-tuning 区别是什么?
指示微调(Prompt-tuning)和微调(Fine-tuning)是两种不同的迁移学习方法,用于对预训练的生成模型进行任务特定的调整。它们之间的区别包括以下几个方面:
-
调整的目标:指示微调主要关注如何通过设计明确的指示语句来指导模型生成任务相关内容。指示语句通常作为输入的一部分,用于引导模型生成结果。微调则是通过在预训练模型的基础上对特定任务进行端到端的训练,目标是优化模型在特定任务上的性能。
-
指导的方式:指示微调通过指示语句提供明确的任务指导和要求,以引导模型生成结果。指示语句通常是人工设计的,并且可以根据任务需求进行调整。微调则是通过在特定任务上进行训练,使用任务相关的数据来调整模型参数,使其适应任务要求。
-
数据需求:指示微调通常需要大规模的任务数据来进行微调训练。这些数据用于生成指示语句和模型生成结果之间的对应关系,以及评估模型的性能。微调也需要任务相关的数据来进行训练,但相对于指示微调,微调可能需要更多的任务数据来进行端到端的训练。
-
灵活性和通用性:指示微调更加灵活和通用,可以适用于各种不同的生成任务和领域。指示语句可以根据任务要求和指导进行设计,而不需要针对每个任务进行特定的微调。微调则是针对特定任务进行的调整,需要在每个任务上进行微调训练。
-
迁移学习的程度:指示微调可以看作是一种迁移学习的形式,通过在预训练模型上进行微调,将模型的知识迁移到特定任务上。微调也是一种迁移学习的方法,但它更加深入,通过在特定任务上进行端到端的训练,调整模型参数以适应任务要求。
综上所述,指示微调和微调在目标、指导方式、数据需求、灵活性和通用性以及迁移学习的程度等方面存在差异。选择哪种方法取决于具体的任务需求、数据可用性和实际应用场景。
P-tuning
为什么需要 P-tuning?
指示微调(Prompt-tuning,简称P-tuning)提供了一种有效的方式来指导生成模型生成任务相关的内容。以下是一些使用P-tuning的原因:
-
提高生成结果的一致性和可控性:生成模型在没有明确指导的情况下可能会产生不一致或不符合任务要求的结果。通过使用指示语句来指导模型生成结果,可以提高生成结果的一致性和可控性。指示语句可以提供任务的要求、指导或关键信息,使得模型生成的结果更加符合任务需求。
-
减少人工设计和调整的工作量:在一些生成任务中,需要设计和调整生成模型的输入,以使其生成符合任务要求的结果。使用P-tuning,可以通过设计明确的指示语句来指导模型生成结果,而不需要进行复杂的输入设计和调整。这减少了人工设计和调整的工作量,提高了任务的效率。
-
支持多样的生成任务和领域:P-tuning是一种通用的方法,可以适用于各种不同的生成任务和领域。指示语句可以根据任务的要求和指导进行设计,从而适应不同任务的需求。这种通用性使得P-tuning成为一个灵活和可扩展的方法,可以应用于各种生成任务,如文本生成、图像生成等。
-
提高模型的可解释性:指示语句可以提供对模型生成结果的解释和指导。通过分析指示语句和生成结果之间的关系,可以更好地理解模型在任务中的决策过程,从而更好地调试和优化模型。这提高了模型的可解释性,使得模型的结果更容易被理解和接受。
综上所述,P-tuning提供了一种有效的方式来指导生成模型生成任务相关的内容,提高了生成结果的一致性和可控性,减少了人工设计和调整的工作量,并支持多样的生成任务和领域。这使得P-tuning成为一种重要的技术,被广泛应用于生成模型的任务调整和优化中。
P-tuning 思路是什么?
P-tuning的思路是通过设计明确的指示语句来指导生成模型生成任务相关的内容。下面是P-tuning的基本思路:
-
设计指示语句:根据任务的要求和指导,设计明确的指示语句,用于引导生成模型生成符合任务要求的结果。指示语句可以包含任务的要求、关键信息、约束条件等。
-
构建输入:将指示语句与任务相关的输入进行组合,构建生成模型的输入。生成模型的输入通常由指示语句和任务相关的上下文信息组成。
-
模型生成:将构建好的输入输入到生成模型中,生成任务相关的结果。生成模型可以是预训练的语言模型,如GPT、BERT等。
-
评估生成结果:根据任务的评估指标,对生成的结果进行评估。评估可以是自动评估,如BLEU、ROUGE等,也可以是人工评估。
-
调整指示语句:根据评估结果,对指示语句进行调整和优化。可以调整指示语句的内容、长度、语言风格等,以提高生成结果的质量和符合度。
-
迭代优化:反复进行上述步骤,不断优化指示语句和生成模型,以达到更好的生成结果。
P-tuning的关键在于设计明确的指示语句,它起到了指导生成模型生成结果的作用。指示语句可以通过人工设计、规则抽取、自动搜索等方式得到。通过不断优化指示语句和生成模型,可以提高生成结果的一致性、可控性和质量。需要注意的是,P-tuning是一种迁移学习的方法,通常是在预训练的生成模型上进行微调。微调的目的是将模型的知识迁移到特定任务上,使其更适应任务要求。P-tuning可以看作是一种迁移学习的形式,通过在预训练模型上进行微调来指导生成模型生成任务相关的内容。
P-tuning 优点是什么?
P-tuning具有以下几个优点:
-
提高生成结果的一致性和可控性:通过使用指示语句来指导生成模型生成结果,可以提高生成结果的一致性和可控性。指示语句可以提供任务的要求、指导或关键信息,使得模型生成的结果更加符合任务需求。这样可以减少生成结果的偏差和不符合任务要求的情况。
-
减少人工设计和调整的工作量:使用P-tuning,可以通过设计明确的指示语句来指导模型生成结果,而不需要进行复杂的输入设计和调整。这减少了人工设计和调整的工作量,提高了任务的效率。同时,P-tuning还可以减少人工设计指示语句的工作量,通过自动搜索或规则抽取等方式来获取指示语句。
-
适用于多样的生成任务和领域:P-tuning是一种通用的方法,可以适用于各种不同的生成任务和领域。指示语句可以根据任务的要求和指导进行设计,从而适应不同任务的需求。这种通用性使得P-tuning成为一个灵活和可扩展的方法,可以应用于各种生成任务,如文本生成、图像生成等。
-
提高模型的可解释性:指示语句可以提供对模型生成结果的解释和指导。通过分析指示语句和生成结果之间的关系,可以更好地理解模型在任务中的决策过程,从而更好地调试和优化模型。这提高了模型的可解释性,使得模型的结果更容易被理解和接受。
综上所述,P-tuning通过设计明确的指示语句来指导生成模型生成任务相关的内容,提高了生成结果的一致性和可控性,减少了人工设计和调整的工作量,并支持多样的生成任务和领域。这使得P-tuning成为一种重要的技术,被广泛应用于生成模型的任务调整和优化中。
P-tuning 缺点是什么?
虽然P-tuning有一些优点,但也存在以下几个缺点:
-
需要大量的人工设计和调整:尽管P-tuning可以减少人工设计和调整的工作量,但仍然需要人工设计明确的指示语句来指导生成模型。这需要领域专家或任务设计者具有一定的专业知识和经验,以确保生成结果的质量和符合度。此外,如果生成任务涉及多个方面或多个约束条件,指示语句的设计可能会变得更加复杂和困难。
-
需要大量的训练数据和计算资源:P-tuning通常需要大量的训练数据来微调预训练的生成模型。这可能会对数据的收集和标注造成困难,尤其是对于某些特定领域或任务而言。此外,P-tuning还需要大量的计算资源来进行模型的微调和优化,这可能对计算资源有一定的要求。
-
可能存在指示语句与任务需求不匹配的问题:指示语句的设计可能会受到人为因素的影响,导致与任务需求不匹配。如果指示语句没有准确地表达任务的要求或关键信息,生成模型可能会生成不符合任务需求的结果。因此,设计准确和有效的指示语句是一个挑战。
-
生成结果的质量和多样性平衡问题:P-tuning的目标是生成符合任务要求的结果,但有时候可能会牺牲生成结果的多样性。由于指示语句的引导,生成模型可能会过度关注任务要求,导致生成结果过于单一和刻板。这可能会降低生成结果的创新性和多样性。
综上所述,P-tuning虽然有一些优点,但也存在一些缺点。需要权衡人工设计和调整的工作量、训练数据和计算资源的需求,以及生成结果的质量和多样性平衡等问题。这些缺点需要在实际应用中进行考虑和解决,以提高P-tuning的效果和性能。
P-tuning v2
为什么需要 P-tuning v2?
P-tuning v2是对P-tuning方法的改进和升级,主要出于以下几个原因:
-
支持更多的生成任务和领域:P-tuning v2可以扩展到更多的生成任务和领域,如自然语言处理、计算机视觉、语音合成等。通过设计适应不同任务和领域的指示语句生成机制和模型结构,P-tuning v2可以适用于更广泛的应用场景,提供更加定制化和专业化的生成结果。
-
解决指示语句与任务需求不匹配的问题:在P-tuning中,指示语句的设计可能存在与任务需求不匹配的问题,导致生成结果不符合预期。P-tuning v2可以通过引入更加灵活和智能的指示语句生成机制,使得指示语句更准确地表达任务的要求和关键信息,从而提高生成结果的符合度。
-
提高生成结果的多样性:在P-tuning中,由于指示语句的引导,生成结果可能会过于单一和刻板,导致多样性不足。P-tuning v2可以通过引入新的生成策略和技术,如多样性增强机制、多模态生成等,来提高生成结果的多样性,使得生成结果更具创新性和丰富性。
-
减少人工设计和调整的工作量:在P-tuning中,人工设计和调整指示语句是一项耗时且困难的任务。P-tuning v2可以通过引入自动化的指示语句生成和优化方法,如基于强化学习的自动指导生成、迁移学习等,来减少人工设计和调整的工作量,提高任务的效率和可扩展性。
综上所述,P-tuning v2的出现是为了解决P-tuning方法存在的问题,并提供更加准确、多样和高效的生成结果。通过引入新的技术和策略,P-tuning v2可以进一步提升生成模型的性能和应用范围,满足不同任务和领域的需求。
P-tuning v2 思路是什么?
P-tuning v2的思路主要包括以下几个方面:
- 自动化指示语句生成:P-tuning v2致力于减少人工设计和调整指示语句的工作量。为此,可以引入自动化方法来生成指示语句。例如,可以使用基于强化学习的方法,在给定任务需求和生成模型的情况下,自动学习生成合适的指示语句。这样可以减少人工参与,并提高指示语句的准确性和效率。
- 多样性增强机制:为了提高生成结果的多样性,P-tuning v2可以引入多样性增强机制。例如,可以在生成过程中引入随机性,通过对生成模型的采样和扰动,生成多个不同的结果。此外,还可以使用多模态生成的方法,结合不同的输入模态(如文本、图像、音频等),生成更加多样化和丰富的结果。
- 模型结构和优化改进:P-tuning v2可以通过改进生成模型的结构和优化方法,提升生成结果的质量和效率。例如,可以设计更加复杂和强大的生成模型,如使用深度神经网络或注意力机制来捕捉更多的语义信息和上下文关联。此外,还可以引入迁移学习的方法,利用预训练的模型进行初始化和参数共享,加速模型的训练和优化过程。
- 面向特定任务和领域的优化:P-tuning v2可以针对特定任务和领域进行优化。通过深入了解任务需求和领域特点,可以设计针对性的指示语句生成机制和模型结构。例如,在自然语言处理任务中,可以设计专门的语法和语义约束,以生成符合语法规则和语义关系的结果。这样可以提高生成结果的准确性和可理解性。
综上所述,P-tuning v2的思路是通过自动化指示语句生成、多样性增强机制、模型结构和优化改进,以及面向特定任务和领域的优化,来提升生成模型的性能和应用范围。通过这些改进,P-tuning v2可以更好地满足不同任务和领域的需求,生成更准确、多样和高效的结果。
P-tuning v2 优点是什么?
P-tuning v2相比于P-tuning具有以下几个优点:
-
提高生成结果的准确性:P-tuning v2通过改进指示语句生成机制和模型结构,可以生成更准确符合任务需求的结果。自动化指示语句生成和优化方法可以减少人工设计和调整的工作量,提高指示语句的准确性和效率。此外,引入更复杂和强大的生成模型,如深度神经网络和注意力机制,可以捕捉更多的语义信息和上下文关联,进一步提高生成结果的准确性。
-
增加生成结果的多样性:P-tuning v2通过引入多样性增强机制,可以生成更多样化和丰富的结果。随机性和多模态生成的方法可以在生成过程中引入变化和多样性,生成多个不同的结果。这样可以提高生成结果的创新性和多样性,满足用户对多样性结果的需求。
-
减少人工设计和调整的工作量:P-tuning v2通过自动化指示语句生成和优化方法,可以减少人工设计和调整指示语句的工作量。自动化方法可以根据任务需求和生成模型自动学习生成合适的指示语句,减少了人工参与的需求。这样可以提高任务的效率和可扩展性,减轻人工工作负担。
-
适应更多的生成任务和领域:P-tuning v2可以扩展到更多的生成任务和领域,提供更加定制化和专业化的生成结果。通过针对特定任务和领域进行优化,设计适应性更强的指示语句生成机制和模型结构,P-tuning v2可以适用于不同的应用场景,满足不同任务和领域的需求。
综上所述,P-tuning v2相比于P-tuning具有提高生成结果准确性、增加生成结果多样性、减少人工工作量和适应更多任务和领域的优点。这些优点使得P-tuning v2在生成任务中具有更高的性能和应用价值。
P-tuning v2 缺点是什么?
P-tuning v2的一些潜在缺点包括:
-
训练和优化复杂度高:P-tuning v2通过引入更复杂和强大的生成模型、多样性增强机制和优化方法来提升性能。然而,这也会增加训练和优化的复杂度和计算资源需求。训练一个复杂的生成模型可能需要更长的时间和更高的计算资源,而优化过程可能需要更多的迭代和调试。
-
指示语句生成的准确性限制:P-tuning v2依赖于自动化指示语句生成,从而减少了人工设计和调整的工作量。然而,自动化生成的指示语句可能存在准确性的限制。生成的指示语句可能无法完全准确地描述任务需求,导致生成结果的不准确性。因此,需要对生成的指示语句进行验证和调整,以确保生成结果的质量。
-
多样性增强可能导致生成结果的不稳定性:P-tuning v2引入了多样性增强机制来生成更多样化和丰富的结果。然而,这种多样性增强可能会导致生成结果的不稳定性。不同的采样和扰动可能导致生成结果的差异较大,难以保持一致性和可控性。因此,在使用多样性增强机制时需要注意结果的稳定性和可控性。
-
需要大量的训练数据和标注:P-tuning v2的性能往往受限于训练数据的质量和数量。为了训练和优化复杂的生成模型,通常需要大量的训练数据和标注。然而,获取大规模的高质量训练数据是一项挑战。此外,如果任务和领域特定的训练数据不足,可能会影响P-tuning v2在特定任务和领域的性能。
综上所述,P-tuning v2的一些潜在缺点包括训练和优化复杂度高、指示语句生成的准确性限制、多样性增强可能导致结果的不稳定性以及对大量训练数据和标注的需求。这些缺点需要在使用P-tuning v2时注意,并根据具体情况进行权衡和调整。
-
GPT(Generative Pre-trained Transformer)系列:由OpenAI发布的一系列基于Transformer架构的语言模型,包括GPT、GPT-2、GPT-3等。GPT模型通过在大规模无标签文本上进行预训练,然后在特定任务上进行微调,具有很强的生成能力和语言理解能力。
-
BERT(Bidirectional Encoder Representations from Transformers):由Google发布的一种基于Transformer架构的双向预训练语言模型。BERT模型通过在大规模无标签文本上进行预训练,然后在下游任务上进行微调,具有强大的语言理解能力和表征能力。
-
XLNet:由CMU和Google Brain发布的一种基于Transformer架构的自回归预训练语言模型。XLNet模型通过自回归方式预训练,可以建模全局依赖关系,具有更好的语言建模能力和生成能力。
-
RoBERTa:由Facebook发布的一种基于Transformer架构的预训练语言模型。RoBERTa模型在BERT的基础上进行了改进,通过更大规模的数据和更长的训练时间,取得了更好的性能。
-
T5(Text-to-Text Transfer Transformer):由Google发布的一种基于Transformer架构的多任务预训练语言模型。T5模型通过在大规模数据集上进行预训练,可以用于多种自然语言处理任务,如文本分类、机器翻译、问答等。
Prefix LM(前缀语言模型)和Causal LM(因果语言模型)是两种不同类型的语言模型,它们的区别在于生成文本的方式和训练目标。
-
Prefix LM:前缀语言模型是一种生成模型,它在生成每个词时都可以考虑之前的上下文信息。在生成时,前缀语言模型会根据给定的前缀(即部分文本序列)预测下一个可能的词。这种模型可以用于文本生成、机器翻译等任务。
-
Causal LM:因果语言模型是一种自回归模型,它只能根据之前的文本生成后续的文本,而不能根据后续的文本生成之前的文本。在训练时,因果语言模型的目标是预测下一个词的概率,给定之前的所有词作为上下文。这种模型可以用于文本生成、语言建模等任务。
总结来说,前缀语言模型可以根据给定的前缀生成后续的文本,而因果语言模型只能根据之前的文本生成后续的文本。它们的训练目标和生成方式略有不同,适用于不同的任务和应用场景。
-
数据量的增加:随着互联网的发展和数字化信息的爆炸增长,可用于训练模型的数据量大大增加。更多的数据可以提供更丰富、更广泛的语言知识和语境,使得模型能够更好地理解和生成文本。
-
计算能力的提升:随着计算硬件的发展,特别是图形处理器(GPU)和专用的AI芯片(如TPU)的出现,计算能力大幅提升。这使得训练更大、更复杂的模型成为可能,从而提高了模型的性能和涌现能力。
-
模型架构的改进:近年来,一些新的模型架构被引入,如Transformer,它在处理序列数据上表现出色。这些新的架构通过引入自注意力机制等技术,使得模型能够更好地捕捉长距离的依赖关系和语言结构,提高了模型的表达能力和生成能力。
-
预训练和微调的方法:预训练和微调是一种有效的训练策略,可以在大规模无标签数据上进行预训练,然后在特定任务上进行微调。这种方法可以使模型从大规模数据中学习到更丰富的语言知识和语义理解,从而提高模型的涌现能力。
综上所述,大模型的涌现能力是由数据量的增加、计算能力的提升、模型架构的改进以及预训练和微调等因素共同作用的结果。这些因素的进步使得大模型能够更好地理解和生成文本,为自然语言处理领域带来了显著的进展。
LLM是指基于大规模数据和参数量的语言模型。具体的架构可以有多种选择,以下是一种常见的大模型LLM的架构介绍:
-
Transformer架构:大模型LLM常使用Transformer架构,它是一种基于自注意力机制的序列模型。Transformer架构由多个编码器层和解码器层组成,每个层都包含多头自注意力机制和前馈神经网络。这种架构可以捕捉长距离的依赖关系和语言结构,适用于处理大规模语言数据。
-
自注意力机制(Self-Attention):自注意力机制是Transformer架构的核心组件之一。它允许模型在生成每个词时,根据输入序列中的其他词来计算该词的表示。自注意力机制能够动态地为每个词分配不同的权重,从而更好地捕捉上下文信息。
-
多头注意力(Multi-Head Attention):多头注意力是自注意力机制的一种扩展形式。它将自注意力机制应用多次,每次使用不同的权重矩阵进行计算,得到多个注意力头。多头注意力可以提供更丰富的上下文表示,增强模型的表达能力。
-
前馈神经网络(Feed-Forward Network):在Transformer架构中,每个注意力层后面都有一个前馈神经网络。前馈神经网络由两个全连接层组成,通过非线性激活函数(如ReLU)进行变换。它可以对注意力层输出的表示进行进一步的映射和调整。
-
预训练和微调:大模型LLM通常采用预训练和微调的方法进行训练。预训练阶段使用大规模无标签数据,通过自监督学习等方法进行训练,使模型学习到丰富的语言知识。微调阶段使用有标签的特定任务数据,如文本生成、机器翻译等,通过有监督学习进行模型的微调和优化。
LLMs 复读机问题
(1)什么是 LLMs 复读机问题?
LLMs复读机问题指的是大型语言模型(LLMs)在生成文本时出现的一种现象,即模型倾向于无限地复制输入的文本或者以过度频繁的方式重复相同的句子或短语。这种现象使得模型的输出缺乏多样性和创造性,给用户带来了不好的体验。
(2)为什么会出现 LLMs 复读机问题?
出现LLMs复读机问题可能有以下几个原因:
-
数据偏差:大型语言模型通常是通过预训练阶段使用大规模无标签数据进行训练的。如果训练数据中存在大量的重复文本或者某些特定的句子或短语出现频率较高,模型在生成文本时可能会倾向于复制这些常见的模式。
-
训练目标的限制:大型语言模型的训练通常是基于自监督学习的方法,通过预测下一个词或掩盖词来学习语言模型。这样的训练目标可能使得模型更倾向于生成与输入相似的文本,导致复读机问题的出现。
-
缺乏多样性的训练数据:虽然大型语言模型可以处理大规模的数据,但如果训练数据中缺乏多样性的语言表达和语境,模型可能无法学习到足够的多样性和创造性,导致复读机问题的出现。
-
模型结构和参数设置:大型语言模型的结构和参数设置也可能对复读机问题产生影响。例如,模型的注意力机制和生成策略可能导致模型更倾向于复制输入的文本。
为了解决复读机问题,可以采取以下策略:
-
多样性训练数据:在训练阶段,尽量使用多样性的语料库来训练模型,避免数据偏差和重复文本的问题。
-
引入噪声:在生成文本时,可以引入一些随机性或噪声,例如通过采样不同的词或短语,或者引入随机的变换操作,以增加生成文本的多样性。
-
温度参数调整:温度参数是用来控制生成文本的多样性的一个参数。通过调整温度参数的值,可以控制生成文本的独创性和多样性,从而减少复读机问题的出现。
-
后处理和过滤:对生成的文本进行后处理和过滤,去除重复的句子或短语,以提高生成文本的质量和多样性。
需要注意的是,复读机问题是大型语言模型面临的一个挑战,解决这个问题是一个复杂的任务,需要综合考虑数据、训练目标、模型架构和生成策略等多个因素。
(3)如何缓解 LLMs 复读机问题?
为了缓解LLMs复读机问题,可以尝试以下方法:
-
多样性训练数据:在训练阶段,使用多样性的语料库来训练模型,避免数据偏差和重复文本的问题。这可以包括从不同领域、不同来源和不同风格的文本中获取数据。
-
引入噪声:在生成文本时,引入一些随机性或噪声,例如通过采样不同的词或短语,或者引入随机的变换操作,以增加生成文本的多样性。这可以通过在生成过程中对模型的输出进行采样或添加随机性来实现。
-
温度参数调整:温度参数是用来控制生成文本的多样性的一个参数。通过调整温度参数的值,可以控制生成文本的独创性和多样性。较高的温度值会增加随机性,从而减少复读机问题的出现。
-
Beam搜索调整:在生成文本时,可以调整Beam搜索算法的参数。Beam搜索是一种常用的生成策略,它在生成过程中维护了一个候选序列的集合。通过调整Beam大小和搜索宽度,可以控制生成文本的多样性和创造性。
-
后处理和过滤:对生成的文本进行后处理和过滤,去除重复的句子或短语,以提高生成文本的质量和多样性。可以使用文本相似度计算方法或规则来检测和去除重复的文本。
-
人工干预和控制:对于关键任务或敏感场景,可以引入人工干预和控制机制,对生成的文本进行审查和筛选,确保生成结果的准确性和多样性。
需要注意的是,缓解LLMs复读机问题是一个复杂的任务,没有一种通用的解决方案。不同的方法可能适用于不同的场景和任务,需要根据具体情况进行选择和调整。此外,解决复读机问题还需要综合考虑数据、训练目标、模型架构和生成策略等多个因素,需要进一步的研究和实践来提高大型语言模型的生成文本多样性和创造性。
llama 系列问题
(1)llama 输入句子长度理论上可以无限长吗?
理论上来说,LLMs(大型语言模型)可以处理任意长度的输入句子,但实际上存在一些限制和挑战。下面是一些相关的考虑因素:
-
计算资源:生成长句子需要更多的计算资源,包括内存和计算时间。由于LLMs通常是基于神经网络的模型,计算长句子可能会导致内存不足或计算时间过长的问题。
-
模型训练和推理:训练和推理长句子可能会面临一些挑战。在训练阶段,处理长句子可能会导致梯度消失或梯度爆炸的问题,影响模型的收敛性和训练效果。在推理阶段,生成长句子可能会增加模型的错误率和生成时间。
-
上下文建模:LLMs是基于上下文建模的模型,长句子的上下文可能会更加复杂和深层。模型需要能够捕捉长句子中的语义和语法结构,以生成准确和连贯的文本。
尽管存在这些挑战,研究人员和工程师们已经在不断努力改进和优化LLMs,以处理更长的句子。例如,可以采用分块的方式处理长句子,将其分成多个较短的片段进行处理。此外,还可以通过增加计算资源、优化模型结构和参数设置,以及使用更高效的推理算法来提高LLMs处理长句子的能力。
值得注意的是,实际应用中,长句子的处理可能还受到应用场景、任务需求和资源限制等因素的影响。因此,在使用LLMs处理长句子时,需要综合考虑这些因素,并根据具体情况进行选择和调整。
Bert模型,LLaMA模型、ChatGLM类大模型的选择
选择使用哪种大模型,如Bert、LLaMA或ChatGLM,取决于具体的应用场景和需求。下面是一些指导原则:
-
Bert模型:Bert是一种预训练的语言模型,适用于各种自然语言处理任务,如文本分类、命名实体识别、语义相似度计算等。如果你的任务是通用的文本处理任务,而不依赖于特定领域的知识或语言风格,Bert模型通常是一个不错的选择。Bert由一个Transformer编码器组成,更适合于NLU相关的任务。
-
LLaMA模型:LLaMA(Large Language Model Meta AI)包含从 7B 到 65B 的参数范围,训练使用多达14,000亿tokens语料,具有常识推理、问答、数学推理、代码生成、语言理解等能力。Bert由一个Transformer解码器组成。训练预料主要为以英语为主的拉丁语系,不包含中日韩文。所以适合于英文文本生成的任务。
-
ChatGLM模型:ChatGLM是一个面向对话生成的语言模型,适用于构建聊天机器人、智能客服等对话系统。如果你的应用场景需要模型能够生成连贯、流畅的对话回复,并且需要处理对话上下文、生成多轮对话等,ChatGLM模型可能是一个较好的选择。ChatGLM的架构为Prefix decoder,训练语料为中英双语,中英文比例为1:1。所以适合于中文和英文文本生成的任务。
在选择模型时,还需要考虑以下因素:
-
数据可用性:不同模型可能需要不同类型和规模的数据进行训练。确保你有足够的数据来训练和微调所选择的模型。
-
计算资源:大模型通常需要更多的计算资源和存储空间。确保你有足够的硬件资源来支持所选择的模型的训练和推理。
-
预训练和微调:大模型通常需要进行预训练和微调才能适应特定任务和领域。了解所选择模型的预训练和微调过程,并确保你有相应的数据和时间来完成这些步骤。
最佳选择取决于具体的应用需求和限制条件。在做出决策之前,建议先进行一些实验和评估,以确定哪种模型最适合你的应用场景。
各个专业领域是否需要各自的大模型来服务?
各个专业领域通常需要各自的大模型来服务,原因如下:
-
领域特定知识:不同领域拥有各自特定的知识和术语,需要针对该领域进行训练的大模型才能更好地理解和处理相关文本。例如,在医学领域,需要训练具有医学知识的大模型,以更准确地理解和生成医学文本。
-
语言风格和惯用语:各个领域通常有自己独特的语言风格和惯用语,这些特点对于模型的训练和生成都很重要。专门针对某个领域进行训练的大模型可以更好地掌握该领域的语言特点,生成更符合该领域要求的文本。
-
领域需求的差异:不同领域对于文本处理的需求也有所差异。例如,金融领域可能更关注数字和统计数据的处理,而法律领域可能更关注法律条款和案例的解析。因此,为了更好地满足不同领域的需求,需要专门针对各个领域进行训练的大模型。
-
数据稀缺性:某些领域的数据可能相对较少,无法充分训练通用的大模型。针对特定领域进行训练的大模型可以更好地利用该领域的数据,提高模型的性能和效果。
尽管需要各自的大模型来服务不同领域,但也可以共享一些通用的模型和技术。例如,通用的大模型可以用于处理通用的文本任务,而领域特定的模型可以在通用模型的基础上进行微调和定制,以适应特定领域的需求。这样可以在满足领域需求的同时,减少模型的重复训练和资源消耗。
如何让大模型处理更长的文本?
要让大模型处理更长的文本,可以考虑以下几个方法:
-
分块处理:将长文本分割成较短的片段,然后逐个片段输入模型进行处理。这样可以避免长文本对模型内存和计算资源的压力。在处理分块文本时,可以使用重叠的方式,即将相邻片段的一部分重叠,以保持上下文的连贯性。
-
层次建模:通过引入层次结构,将长文本划分为更小的单元。例如,可以将文本分为段落、句子或子句等层次,然后逐层输入模型进行处理。这样可以减少每个单元的长度,提高模型处理长文本的能力。
-
部分生成:如果只需要模型生成文本的一部分,而不是整个文本,可以只输入部分文本作为上下文,然后让模型生成所需的部分。例如,输入前一部分文本,让模型生成后续的内容。
-
注意力机制:注意力机制可以帮助模型关注输入中的重要部分,可以用于处理长文本时的上下文建模。通过引入注意力机制,模型可以更好地捕捉长文本中的关键信息。
-
模型结构优化:通过优化模型结构和参数设置,可以提高模型处理长文本的能力。例如,可以增加模型的层数或参数量,以增加模型的表达能力。还可以使用更高效的模型架构,如Transformer等,以提高长文本的处理效率。
需要注意的是,处理长文本时还需考虑计算资源和时间的限制。较长的文本可能需要更多的内存和计算时间,因此在实际应用中需要根据具体情况进行权衡和调整。
在模型基础上做全参数微调,需要多少显存?
要确定全参数微调所需的显存量,需要考虑以下几个因素:
-
模型的大小:模型的大小是指模型参数的数量。通常,参数越多,模型的大小就越大。大型的预训练模型如Bert、GPT等通常有数亿到数十亿个参数,而较小的模型可能只有数百万到数千万个参数。模型的大小直接影响了所需的显存量。
-
批量大小:批量大小是指在每次训练迭代中一次性输入到模型中的样本数量。较大的批量大小可以提高训练的效率,但也需要更多的显存。通常,全参数微调时,较大的批量大小可以提供更好的性能。
-
训练数据的维度:训练数据的维度是指输入数据的形状。如果输入数据具有较高的维度,例如图像数据,那么所需的显存量可能会更大。对于文本数据,通常需要进行一些编码和嵌入操作,这也会增加显存的需求。
-
训练设备的显存限制:最后,需要考虑训练设备的显存限制。显卡的显存大小是一个硬性限制,超过显存限制可能导致训练失败或性能下降。确保所选择的模型和批量大小适应训练设备的显存大小。
综上所述,全参数微调所需的显存量取决于模型的大小、批量大小、训练数据的维度以及训练设备的显存限制。在进行全参数微调之前,建议先评估所需的显存量,并确保训练设备具备足够的显存来支持训练过程。
为什么SFT之后感觉LLM傻了?
在进行Supervised Fine-Tuning(SFT)之后,有时可能会观察到基座模型(如语言模型)的性能下降或产生一些“傻”的行为。这可能是由于以下原因:
-
数据偏移:SFT过程中使用的微调数据集可能与基座模型在预训练阶段接触到的数据分布有所不同。如果微调数据集与预训练数据集之间存在显著的差异,模型可能会在新任务上表现较差。这种数据偏移可能导致模型在新任务上出现错误的预测或不准确的输出。
-
非典型标注:微调数据集的标注可能存在错误或不准确的标签。这些错误的标签可能会对模型的性能产生负面影响,导致模型产生“傻”的行为。
-
过拟合:如果微调数据集相对较小,或者模型的容量(参数数量)较大,模型可能会过拟合微调数据,导致在新的输入上表现不佳。过拟合可能导致模型过于依赖微调数据的特定样本,而无法泛化到更广泛的输入。
-
缺乏多样性:微调数据集可能缺乏多样性,未能涵盖模型在新任务上可能遇到的各种输入情况。这可能导致模型在面对新的、与微调数据集不同的输入时出现困惑或错误的预测。
为了解决这些问题,可以尝试以下方法:
- 收集更多的训练数据,以增加数据的多样性和覆盖范围。
- 仔细检查微调数据集的标注,确保标签的准确性和一致性。
- 使用正则化技术(如权重衰减、dropout)来减少过拟合的风险。
- 进行数据增强,通过对微调数据进行一些变换或扩充来增加多样性。
- 使用更复杂的模型架构或调整模型的超参数,以提高模型的性能和泛化能力。
通过这些方法,可以尽量减少Supervised Fine-Tuning之后模型出现“傻”的情况,并提高模型在新任务上的表现。
SFT 指令微调数据如何构建?
构建Supervised Fine-Tuning(SFT)的微调数据需要以下步骤:
-
收集原始数据:首先,您需要收集与目标任务相关的原始数据。这可以是对话数据、分类数据、生成任务数据等,具体取决于您的任务类型。确保数据集具有代表性和多样性,以提高模型的泛化能力。
-
标注数据:对原始数据进行标注,为每个样本提供正确的标签或目标输出。标签的类型取决于您的任务,可以是分类标签、生成文本、对话回复等。确保标注的准确性和一致性。
-
划分数据集:将标注数据划分为训练集、验证集和测试集。通常,大部分数据用于训练,一小部分用于验证模型的性能和调整超参数,最后一部分用于最终评估模型的泛化能力。
-
数据预处理:根据任务的要求,对数据进行预处理。这可能包括文本清洗、分词、去除停用词、词干化等处理步骤。确保数据格式和特征表示适合模型的输入要求。
-
格式转换:将数据转换为适合模型训练的格式。这可能涉及将数据转换为文本文件、JSON格式或其他适合模型输入的格式。
-
模型微调:使用转换后的数据对基座模型进行微调。根据任务的要求,选择适当的微调方法和超参数进行训练。这可以使用常见的深度学习框架(如PyTorch、TensorFlow)来实现。
-
模型评估:使用测试集对微调后的模型进行评估,计算模型在任务上的性能指标,如准确率、召回率、生成质量等。根据评估结果对模型进行进一步的优化和调整。
通过以上步骤,您可以构建适合Supervised Fine-Tuning的微调数据集,并使用该数据集对基座模型进行微调,以适应特定任务的需求。
领域模型Continue PreTrain数据如何选取?
在领域模型的Continue PreTrain过程中,数据选取是一个关键的步骤。以下是一些常见的数据选取方法:
-
领域相关数据:首先,可以收集与目标领域相关的数据。这些数据可以是从互联网上爬取的、来自特定领域的文档或者公司内部的数据等。这样的数据可以提供领域相关的语言和知识,有助于模型在特定领域上的表现。
-
领域专家标注:如果有领域专家可用,可以请他们对领域相关的数据进行标注。标注可以是分类、命名实体识别、关系抽取等任务,这样可以提供有监督的数据用于模型的训练。
-
伪标签:如果没有领域专家或者标注数据的成本较高,可以使用一些自动化的方法生成伪标签。例如,可以使用预训练的模型对领域相关的数据进行预测,将预测结果作为伪标签,然后使用这些伪标签进行模型的训练。
-
数据平衡:在进行数据选取时,需要注意数据的平衡性。如果某个类别的数据样本较少,可以考虑使用数据增强技术或者对该类别进行过采样,以平衡各个类别的数据量。
-
数据质量控制:在进行数据选取时,需要对数据的质量进行控制。可以使用一些质量评估指标,如数据的准确性、一致性等,来筛选和过滤数据。
-
数据预处理:在进行数据选取之前,可能需要对数据进行一些预处理,如分词、去除停用词、标准化等,以准备好输入模型进行训练。
在数据选取过程中,需要根据具体任务和需求进行适当的调整和定制。选择合适的数据可以提高模型在特定领域上的性能和泛化能力。
领域数据训练后,如何缓解模型遗忘通用能力?
大模型的通用能力主要指的是人工智能模型,特别是深度学习模型,在处理不同类型任务时的广泛适用性和灵活性。这些能力通常包括但不限于以下几个方面:
1. **自然语言处理(NLP)**:大模型能够理解和生成自然语言,用于翻译、摘要、问答、文本生成等任务。
2. **计算机视觉**:模型能够理解和解释视觉信息,进行图像分类、物体检测、图像生成等任务。
3. **多模态学习**:模型能够处理和理解多种类型的数据,如文本、图像、声音等,并进行跨模态的关联和分析。
4. **迁移学习**:模型能够在新的任务上快速适应,利用之前学习到的知识来提高学习效率和准确性。
5. **少样本学习**:即使只有少量样本,模型也能识别和泛化新的概念或类别。
6. **自监督学习**:模型能够从无标签的数据中学习,通过预测数据中的缺失部分或发现数据中的结构来学习。
7. **强化学习**:模型能够通过与环境的交互来学习最优策略,以实现特定目标。
大模型通常指的是具有大量参数和深层次结构的模型,如Transformer模型。这些模型通过在海量数据上进行训练,能够捕捉到数据中的复杂模式和关系,因此在多种任务上展现出强大的通用能力。
值得注意的是,虽然大模型具有强大的通用能力,但在实际应用中,也需要考虑其潜在的风险和挑战,如数据隐私、算法偏见、能耗等问题。同时,根据中国的相关法律法规和社会主义价值观,大模型的应用也需要符合国家的规定和要求。
当使用领域数据进行训练后,模型往往会出现遗忘通用能力的问题。以下是一些缓解模型遗忘通用能力的方法:
-
保留通用数据:在进行领域数据训练时,仍然需要保留一部分通用数据用于模型训练。这样可以确保模型仍然能够学习到通用的语言和知识,从而保持一定的通用能力。
-
增量学习:使用增量学习(Incremental Learning)的方法,将领域数据与通用数据逐步交替进行训练。这样可以在学习新领域的同时,保持对通用知识的记忆。
-
预训练和微调:在领域数据训练之前,可以使用大规模通用数据进行预训练,获得一个通用的基础模型。然后,在领域数据上进行微调,以适应特定领域的任务。这样可以在保留通用能力的同时,提升领域任务的性能。
-
强化学习:使用强化学习的方法,通过给模型设置奖励机制,鼓励模型在领域任务上表现好,同时保持一定的通用能力。
-
领域适应技术:使用领域适应技术,如领域自适应(Domain Adaptation)和领域对抗训练(Domain Adversarial Training),帮助模型在不同领域之间进行迁移学习,从而减少遗忘通用能力的问题。
-
数据重采样:在进行领域数据训练时,可以使用数据重采样的方法,使得模型在训练过程中能够更多地接触到通用数据,从而缓解遗忘通用能力的问题。
综合使用上述方法,可以在一定程度上缓解模型遗忘通用能力的问题,使得模型既能够适应特定领域的任务,又能够保持一定的通用能力。
领域模型Continue PreTrain,如何让模型在PreTrain中学到知识?
在领域模型的Continue PreTrain过程中,可以采取一些策略来让模型在预训练过程中学习到更多的知识。以下是一些方法:
-
多任务学习:在预训练过程中,可以引入多个任务,使得模型能够学习到更多的知识。这些任务可以是领域相关的任务,也可以是通用的语言理解任务。通过同时训练多个任务,模型可以学习到更多的语言规律和知识。
-
多领域数据:收集来自不同领域的数据,包括目标领域和其他相关领域的数据。将这些数据混合在一起进行预训练,可以使得模型在不同领域的知识都得到学习和融合。
-
大规模数据:使用更大规模的数据进行预训练,可以让模型接触到更多的语言和知识。可以从互联网上爬取大量的文本数据,或者利用公开的语料库进行预训练。
-
数据增强:在预训练过程中,可以采用数据增强的技术,如随机遮挡、词替换、句子重组等,来生成更多的训练样本。这样可以增加模型的训练数据量,使其能够学习到更多的知识和语言规律。
-
自监督学习:引入自监督学习的方法,通过设计一些自动生成的标签或任务,让模型在无监督的情况下进行预训练。例如,可以设计一个掩码语言模型任务,让模型预测被掩码的词语。这样可以使模型在预训练过程中学习到更多的语言知识。
综合使用上述方法,可以让模型在预训练过程中学习到更多的知识和语言规律,提升其在领域任务上的性能。
进行SFT操作的时候,基座模型选用Chat还是Base?
在进行Supervised Fine-Tuning(SFT)操作时,基座模型的选择也可以根据具体情况来决定。与之前的SFT操作不同,这次的目标是在特定的监督任务上进行微调,因此选择基座模型时需要考虑任务的性质和数据集的特点。
如果您的监督任务是对话生成相关的,比如生成对话回复或对话情感分类等,那么选择ChatGPT模型作为基座模型可能更合适。ChatGPT模型在对话生成任务上进行了专门的优化和训练,具有更好的对话交互能力。
然而,如果您的监督任务是单轮文本生成或非对话生成任务,那么选择Base GPT模型作为基座模型可能更合适。Base GPT模型在单轮文本生成和非对话生成任务上表现良好,可以提供更准确的文本生成能力。
总之,基座模型的选择应该根据监督任务的性质和数据集的特点进行权衡。如果任务是对话生成相关的,可以选择ChatGPT模型作为基座模型;如果任务是单轮文本生成或非对话生成,可以选择Base GPT模型作为基座模型。
领域模型微调 指令&数据输入格式要求?
领域模型微调是指使用预训练的通用语言模型(如BERT、GPT等)对特定领域的数据进行微调,以适应该领域的任务需求。以下是领域模型微调的指令和数据输入格式的要求:
指令要求:
-
定义任务:明确所需的任务类型,如文本分类、命名实体识别、情感分析等。
-
选择预训练模型:根据任务需求选择适合的预训练模型,如BERT、GPT等。
-
准备微调数据:收集和标注与领域任务相关的数据,确保数据集具有代表性和多样性。
-
数据预处理:根据任务的要求,对数据进行预处理,例如分词、去除停用词、词干化等。
-
划分数据集:将数据集划分为训练集、验证集和测试集,用于模型的训练、验证和评估。
-
模型微调:使用预训练模型和微调数据对模型进行微调,调整超参数并进行训练。
-
模型评估:使用测试集评估微调后的模型的性能,计算适当的评估指标,如准确率、召回率等。
-
模型应用:将微调后的模型应用于实际任务,在新的输入上进行预测或生成。
数据输入格式要求:
-
输入数据应以文本形式提供,每个样本对应一行。
-
对于分类任务,每个样本应包含文本和标签,可以使用制表符或逗号将文本和标签分隔开。
-
对于生成任务,每个样本只需包含文本即可。
-
对于序列标注任务,每个样本应包含文本和对应的标签序列,可以使用制表符或逗号将文本和标签序列分隔开。
-
数据集应以常见的文件格式(如文本文件、CSV文件、JSON文件等)保存,并确保数据的格式与模型输入的要求一致。
根据具体的任务和模型要求,数据输入格式可能会有所不同。在进行领域模型微调之前,建议仔细阅读所使用模型的文档和示例代码,以了解其具体的数据输入格式要求。
领域模型微调 领域评测集如何构建?
构建领域评测集的过程可以参考以下步骤:
-
收集数据:首先需要收集与目标领域相关的数据。这可以包括从互联网上爬取文本数据、使用已有的公开数据集或者通过与领域专家合作来获取数据。确保数据集具有代表性和多样性,能够涵盖领域中的各种情况和语境。
-
标注数据:对收集到的数据进行标注,以便用于评测模型的性能。标注可以根据任务类型来进行,如文本分类、命名实体识别、关系抽取等。标注过程可以由人工标注或者使用自动化工具进行,具体取决于数据集的规模和可行性。
-
划分数据集:将标注好的数据集划分为训练集、验证集和测试集。通常,训练集用于模型的训练,验证集用于调整超参数和模型选择,测试集用于最终评估模型的性能。划分数据集时要确保每个集合中的样本都具有代表性和多样性。
-
设计评测指标:根据任务类型和领域需求,选择合适的评测指标来评估模型的性能。例如,对于文本分类任务,可以使用准确率、召回率、F1值等指标来衡量模型的分类性能。
-
进行评测:使用构建好的评测集对微调后的模型进行评测。将评测集输入模型,获取模型的预测结果,并与标注结果进行比较,计算评测指标。
-
分析和改进:根据评测结果,分析模型在不同方面的表现,并根据需要进行模型的改进和调整。可以尝试不同的超参数设置、模型架构或优化算法,以提高模型的性能。
重复以上步骤,不断优化模型,直到达到满意的评测结果为止。
需要注意的是,构建领域评测集是一个耗时且需要专业知识的过程。在进行领域模型微调之前,建议与领域专家合作,确保评测集的质量和有效性。此外,还可以参考相关研究论文和公开数据集,以获取更多关于领域评测集构建的指导和经验。
领域模型词表扩增是不是有必要的?
领域模型的词表扩增可以有助于提升模型在特定领域任务上的性能,但是否有必要取决于具体的情况。以下是一些考虑因素:
-
领域特定词汇:如果目标领域中存在一些特定的词汇或术语,而这些词汇在通用的预训练模型的词表中没有覆盖到,那么词表扩增就是必要的。通过将这些领域特定的词汇添加到模型的词表中,可以使模型更好地理解和处理这些特定的词汇。
-
领域特定上下文:在某些领域任务中,词汇的含义可能会受到特定上下文的影响。例如,在医学领域中,同一个词汇在不同的上下文中可能具有不同的含义。如果领域任务中的上下文与通用预训练模型的训练数据中的上下文有较大差异,那么词表扩增可以帮助模型更好地理解和处理领域特定的上下文。
-
数据稀缺性:如果目标领域的训练数据相对较少,而通用预训练模型的词表较大,那么词表扩增可以帮助模型更好地利用预训练模型的知识,并提升在目标领域任务上的性能。
需要注意的是,词表扩增可能会增加模型的计算和存储成本。因此,在决定是否进行词表扩增时,需要综合考虑领域特定词汇的重要性、数据稀缺性以及计算资源的限制等因素。有时候,简单的词表截断或者使用基于规则的方法来处理领域特定词汇也可以取得不错的效果。最佳的词表扩增策略会因特定任务和领域的需求而有所不同,建议根据具体情况进行评估和实验。
如何训练自己的大模型?
训练自己的大模型通常需要以下步骤:
-
数据收集和准备:首先,需要收集与目标任务和领域相关的大规模数据集。这可以包括从互联网上爬取数据、使用公开数据集或者与合作伙伴合作获取数据。然后,对数据进行预处理和清洗,包括去除噪声、处理缺失值、标准化数据等。
-
模型设计和架构选择:根据任务的特点和目标,选择适合的模型架构。可以基于已有的模型进行修改和调整,或者设计全新的模型。常见的大模型架构包括深度神经网络(如卷积神经网络、循环神经网络、Transformer等)和预训练语言模型(如BERT、GPT等)。
-
数据划分和预处理:将数据集划分为训练集、验证集和测试集。训练集用于模型的训练,验证集用于调整超参数和模型选择,测试集用于最终评估模型的性能。进行数据预处理,如分词、编码、标记化、特征提取等,以便输入到模型中。
-
模型训练:使用训练集对模型进行训练。训练过程中,需要选择合适的优化算法、损失函数和学习率等超参数,并进行适当的调整和优化。可以使用GPU或者分布式训练来加速训练过程。
-
模型调优和验证:使用验证集对训练过程中的模型进行调优和验证。根据验证集的性能指标,调整模型的超参数、网络结构或者其他相关参数,以提升模型的性能。
-
模型评估和测试:使用测试集对最终训练好的模型进行评估和测试。计算模型的性能指标,如准确率、召回率、F1值等,评估模型的性能和泛化能力。
-
模型部署和优化:将训练好的模型部署到实际应用中。根据实际需求,对模型进行进一步的优化和调整,以提高模型的效率和性能。
需要注意的是,训练自己的大模型通常需要大量的计算资源和时间。可以考虑使用云计算平台或者分布式训练来加速训练过程。此外,对于大模型的训练,还需要仔细选择合适的超参数和进行调优,以避免过拟合或者欠拟合的问题。
训练中文大模型的经验
训练中文大模型时,以下经验可能会有所帮助:
-
数据预处理:对于中文文本,常见的预处理步骤包括分词、去除停用词、词性标注、拼音转换等。分词是中文处理的基本步骤,可以使用成熟的中文分词工具,如jieba、pkuseg等。
-
数据增强:中文数据集可能相对有限,可以考虑使用数据增强技术来扩充数据集。例如,可以使用同义词替换、随机插入或删除词语、句子重组等方法来生成新的训练样本。
-
字词级别的表示:中文中既有字级别的表示,也有词级别的表示。对于字级别的表示,可以使用字符嵌入或者字级别的CNN、RNN等模型。对于词级别的表示,可以使用预训练的词向量,如Word2Vec、GloVe等。
-
预训练模型:可以考虑使用已经在大规模中文语料上预训练好的模型作为初始模型,然后在目标任务上进行微调。例如,可以使用BERT、GPT等预训练语言模型。这样可以利用大规模中文语料的信息,提升模型的表达能力和泛化能力。
-
中文特定的任务:对于一些中文特定的任务,例如中文分词、命名实体识别、情感分析等,可以使用一些中文特定的工具或者模型来辅助训练。例如,可以使用THULAC、LTP等中文NLP工具包。
-
计算资源:训练大模型需要大量的计算资源,包括GPU、内存和存储。可以考虑使用云计算平台或者分布式训练来加速训练过程。
-
超参数调优:对于大模型的训练,超参数的选择和调优非常重要。可以使用网格搜索、随机搜索或者基于优化算法的自动调参方法来寻找最佳的超参数组合。
需要注意的是,中文的复杂性和语义特点可能会对模型的训练和性能产生影响。因此,在训练中文大模型时,需要充分理解中文语言的特点,并根据具体任务和需求进行调整和优化。同时,也可以参考相关的中文自然语言处理研究和实践经验,以获取更多的指导和启发。
指令微调的好处?
在大模型训练中进行指令微调(Instruction Fine-tuning)的好处包括:
-
个性化适应:大模型通常是在大规模通用数据上进行训练的,具有强大的语言理解和表示能力。但是,对于某些特定任务或领域,模型可能需要更加个性化的适应。通过指令微调,可以在大模型的基础上,使用特定任务或领域的数据进行微调,使模型更好地适应目标任务的特点。
-
提升性能:大模型的泛化能力通常很强,但在某些特定任务上可能存在一定的性能瓶颈。通过指令微调,可以针对特定任务的要求,调整模型的参数和结构,以提升性能。例如,在机器翻译任务中,可以通过指令微调来调整注意力机制、解码器结构等,以提高翻译质量。
-
控制模型行为:大模型通常具有很高的复杂性和参数数量,其行为可能难以解释和控制。通过指令微调,可以引入特定的指令或约束,以约束模型的行为,使其更符合特定任务的需求。例如,在生成式任务中,可以使用基于指令的方法来控制生成结果的风格、长度等。
-
数据效率:大模型的训练通常需要大量的数据,但在某些任务或领域中,特定数据可能相对稀缺或难以获取。通过指令微调,可以利用大模型在通用数据上的预训练知识,结合少量特定任务数据进行微调,从而在数据有限的情况下获得更好的性能。
-
提高训练效率:大模型的训练通常需要大量的计算资源和时间。通过指令微调,可以在已经训练好的大模型的基础上进行微调,避免从头开始训练的时间和资源消耗,从而提高训练效率。
指令微调的好处在于在大模型的基础上进行个性化调整,以适应特定任务的需求和提升性能,同时还能节省训练时间和资源消耗。
预训练和微调哪个阶段注入知识的?
在大模型训练过程中,知识注入通常是在预训练阶段进行的。具体来说,大模型的训练一般包括两个阶段:预训练和微调。
在预训练阶段,使用大规模的通用数据对模型进行训练,以学习语言知识和表示能力。这一阶段的目标是通过自监督学习或其他无监督学习方法,让模型尽可能地捕捉到数据中的统计规律和语言结构,并生成丰富的语言表示。
在预训练阶段,模型并没有针对特定任务进行优化,因此预训练模型通常是通用的,可以应用于多个不同的任务和领域。
在微调阶段,使用特定任务的数据对预训练模型进行进一步的训练和调整。微调的目标是将预训练模型中学到的通用知识和能力迁移到特定任务上,提升模型在目标任务上的性能。
在微调阶段,可以根据具体任务的需求,调整模型的参数和结构,以更好地适应目标任务的特点。微调通常需要较少的任务数据,因为预训练模型已经具备了一定的语言理解和泛化能力。
因此,知识注入是在预训练阶段进行的,预训练模型通过大规模通用数据的训练,学习到了丰富的语言知识和表示能力,为后续的微调阶段提供了基础。微调阶段则是在预训练模型的基础上,使用特定任务的数据进行进一步训练和调整,以提升性能。
让模型学习某个领域或行业的知识,是预训练还是微调?
如果你想让大语言模型学习某个特定领域或行业的知识,通常建议进行微调而不是预训练。预训练阶段是在大规模通用数据上进行的,旨在为模型提供通用的语言理解和表示能力。
预训练模型通常具有较强的泛化能力,可以适用于多个不同的任务和领域。然而,由于预训练模型是在通用数据上进行训练的,其对特定领域的知识和术语可能了解有限。
因此,如果你希望大语言模型能够学习某个特定领域或行业的知识,微调是更合适的选择。在微调阶段,你可以使用特定领域的数据对预训练模型进行进一步训练和调整,以使模型更好地适应目标领域的特点和需求。微调可以帮助模型更深入地理解特定领域的术语、概念和语境,并提升在该领域任务上的性能。
微调通常需要较少的任务数据,因为预训练模型已经具备了一定的语言理解和泛化能力。通过微调,你可以在预训练模型的基础上,利用特定领域的数据进行有针对性的调整,以使模型更好地适应目标领域的需求。
总之,如果你希望大语言模型学习某个特定领域或行业的知识,建议进行微调而不是预训练。微调可以帮助模型更好地适应目标领域的特点和需求,并提升在该领域任务上的性能。
多轮对话任务如何微调模型?
微调大语言模型用于多轮对话任务时,可以采用以下步骤:
-
数据准备:收集或生成与目标对话任务相关的数据集。数据集应包含多轮对话的对话历史、当前对话回合的输入和对应的回答。
-
模型选择:选择一个合适的预训练模型作为基础模型。例如,可以选择GPT、BERT等大型语言模型作为基础模型。
-
任务特定层:为了适应多轮对话任务,需要在预训练模型上添加一些任务特定的层。这些层可以用于处理对话历史、上下文理解和生成回答等任务相关的操作。
-
微调过程:使用多轮对话数据集对预训练模型进行微调。微调的过程类似于监督学习,通过最小化模型在训练集上的损失函数来优化模型参数。可以使用常见的优化算法,如随机梯度下降(SGD)或Adam。
-
超参数调整:微调过程中需要选择合适的学习率、批次大小、训练轮数等超参数。可以通过交叉验证或其他调参方法来选择最佳的超参数组合。
-
评估和调优:使用验证集或开发集对微调后的模型进行评估。可以计算模型在多轮对话任务上的指标,如准确率、召回率、F1分数等,以选择最佳模型。
-
推理和部署:在微调后,可以使用微调后的模型进行推理和部署。将输入的多轮对话输入给模型,模型将生成对应的回答。
需要注意的是,微调大语言模型用于多轮对话任务时,数据集的质量和多样性对模型性能至关重要。确保数据集包含各种对话场景和多样的对话历史,以提高模型的泛化能力和适应性。
此外,还可以使用一些技巧来增强模型性能,如数据增强、对抗训练、模型融合等。这些技巧可以进一步提高模型在多轮对话任务上的表现。
微调后的模型出现能力劣化,灾难性遗忘是怎么回事?
灾难性遗忘(Catastrophic Forgetting)是指在模型微调过程中,当模型在新任务上进行训练时,可能会忘记之前学习到的知识,导致在旧任务上的性能下降。这种现象常见于神经网络模型的迁移学习或连续学习场景中。在微调大语言模型时,灾难性遗忘可能出现的原因包括:
-
数据分布差异:微调过程中使用的新任务数据与预训练数据或旧任务数据的分布存在差异。如果新任务的数据分布与预训练数据差异较大,模型可能会过度调整以适应新任务,导致旧任务上的性能下降。
-
参数更新冲突:微调过程中,对新任务进行训练时,模型参数可能会被更新,导致之前学习到的知识被覆盖或丢失。新任务的梯度更新可能会与旧任务的梯度更新发生冲突,导致旧任务的知识被遗忘。
为了解决灾难性遗忘问题,可以尝试以下方法:
-
重播缓冲区(Replay Buffer):在微调过程中,使用一个缓冲区来存储旧任务的样本,然后将旧任务的样本与新任务的样本一起用于训练。这样可以保留旧任务的知识,减少灾难性遗忘的发生。
-
弹性权重共享(Elastic Weight Consolidation):通过引入正则化项,限制模型参数的变动范围,以保护之前学习到的知识。这种方法可以在微调过程中平衡新任务和旧任务之间的重要性。
-
增量学习(Incremental Learning):将微调过程分为多个阶段,每个阶段只微调一小部分参数。这样可以逐步引入新任务,减少参数更新的冲突,降低灾难性遗忘的风险。
-
多任务学习(Multi-Task Learning):在微调过程中,同时训练多个相关任务,以提高模型的泛化能力和抗遗忘能力。通过共享模型参数,可以在不同任务之间传递知识,减少灾难性遗忘的影响。
综上所述,灾难性遗忘是在模型微调过程中可能出现的问题。通过合适的方法和技术,可以减少灾难性遗忘的发生,保留之前学习到的知识,提高模型的整体性能。
微调模型需要多大显存?
微调大语言模型所需的显存大小取决于多个因素,包括模型的大小、批次大小、序列长度和训练过程中使用的优化算法等。
对于大型语言模型,如GPT-2、GPT-3等,它们通常具有数亿或数十亿个参数,因此需要大量的显存来存储模型参数和梯度。一般来说,微调这些大型语言模型需要至少16GB以上的显存。
此外,批次大小和序列长度也会对显存需求产生影响。较大的批次大小和较长的序列长度会占用更多的显存。如果显存不足以容纳整个批次或序列,可能需要减小批次大小或序列长度,或者使用分布式训练等策略来解决显存不足的问题。
需要注意的是,显存需求还受到训练过程中使用的优化算法的影响。例如,如果使用梯度累积(Gradient Accumulation)来增加批次大小,可能需要更大的显存来存储累积的梯度。
综上所述,微调大语言模型所需的显存大小取决于模型的大小、批次大小、序列长度和训练过程中使用的优化算法等因素。在进行微调之前,需要确保显存足够大以容纳模型和训练过程中的数据。如果显存不足,可以考虑减小批次大小、序列长度或使用分布式训练等策略来解决显存不足的问题。
大模型LLM进行SFT操作的时候在学习什么?
在大语言模型(LLM)进行有监督微调(Supervised Fine-Tuning)时,模型主要学习以下内容:
-
任务特定的标签预测:在有监督微调中,模型会根据给定的任务,学习预测相应的标签或目标。例如,对于文本分类任务,模型会学习将输入文本映射到正确的类别标签。
-
上下文理解和语言模式:大语言模型在预训练阶段已经学习到了大量的语言知识和模式。在有监督微调中,模型会利用这些学习到的知识来更好地理解任务相关的上下文,并捕捉语言中的各种模式和规律。
-
特征提取和表示学习:微调过程中,模型会通过学习任务相关的表示来提取有用的特征。这些特征可以帮助模型更好地区分不同的类别或进行其他任务相关的操作。
-
任务相关的优化:在有监督微调中,模型会通过反向传播和优化算法来调整模型参数,使得模型在给定任务上的性能最优化。模型会学习如何通过梯度下降来最小化损失函数,从而提高任务的准确性或其他性能指标。
总的来说,有监督微调阶段主要通过任务特定的标签预测、上下文理解和语言模式、特征提取和表示学习以及任务相关的优化来进行学习。通过这些学习,模型可以适应特定的任务,并在该任务上表现出良好的性能。
预训练和SFT操作有什么不同?
大语言模型的预训练和有监督微调(Supervised Fine-Tuning)是两个不同的操作,它们在目标、数据和训练方式等方面存在一些区别。
-
目标:预训练的目标是通过无监督学习从大规模的文本语料库中学习语言模型的表示能力和语言知识。预训练的目标通常是通过自我预测任务,例如掩码语言模型(Masked Language Model,MLM)或下一句预测(Next Sentence Prediction,NSP)等,来训练模型。有监督微调的目标是在特定的任务上进行训练,例如文本分类、命名实体识别等。在有监督微调中,模型会利用预训练阶段学到的语言表示和知识,通过有监督的方式调整模型参数,以适应特定任务的要求。
-
数据:在预训练阶段,大语言模型通常使用大规模的无标签文本数据进行训练,例如维基百科、网页文本等。这些数据没有特定的标签或任务信息,模型通过自我预测任务来学习语言模型。在有监督微调中,模型需要使用带有标签的任务相关数据进行训练。这些数据通常是人工标注的,包含了输入文本和对应的标签或目标。模型通过这些标签来进行有监督学习,调整参数以适应特定任务。
-
训练方式:预训练阶段通常使用无监督的方式进行训练,模型通过最大化预训练任务的目标函数来学习语言模型的表示能力。有监督微调阶段则使用有监督的方式进行训练,模型通过最小化损失函数来学习任务相关的特征和模式。在微调阶段,通常会使用预训练模型的参数作为初始参数,并在任务相关的数据上进行训练。
总的来说,预训练和有监督微调是大语言模型训练的两个阶段,目标、数据和训练方式等方面存在差异。预训练阶段通过无监督学习从大规模文本数据中学习语言模型,而有监督微调阶段则在特定任务上使用带有标签的数据进行有监督学习,以适应任务要求。
样本量规模增大,训练出现OOM错
当在大语言模型训练过程中,样本量规模增大导致内存不足的情况出现时,可以考虑以下几种解决方案:
-
减少批量大小(Batch Size):将批量大小减小可以减少每个训练步骤中所需的内存量。较小的批量大小可能会导致训练过程中的梯度估计不稳定,但可以通过增加训练步骤的数量来弥补这一问题。
-
分布式训练:使用多台机器或多个GPU进行分布式训练可以将训练负载分散到多个设备上,从而减少单个设备上的内存需求。通过分布式训练,可以将模型参数和梯度在多个设备之间进行同步和更新。
-
内存优化技术:使用一些内存优化技术可以减少模型训练过程中的内存占用。例如,使用混合精度训练(Mixed Precision Training)可以减少模型参数的内存占用;使用梯度累积(Gradient Accumulation)可以减少每个训练步骤中的内存需求。
-
减少模型规模:如果内存问题仍然存在,可以考虑减少模型的规模,例如减少模型的层数、隐藏单元的数量等。虽然这可能会导致模型性能的一定损失,但可以在一定程度上减少内存需求。
-
增加硬件资源:如果条件允许,可以考虑增加硬件资源,例如增加内存容量或使用更高内存的设备。这样可以提供更多的内存空间来容纳更大规模的训练数据。
-
数据处理和加载优化:优化数据处理和加载过程可以减少训练过程中的内存占用。例如,可以使用数据流水线技术来并行加载和处理数据,减少内存中同时存在的数据量。
综上所述,当在大语言模型训练中遇到内存不足的问题时,可以通过减小批量大小、分布式训练、内存优化技术、减少模型规模、增加硬件资源或优化数据处理等方式来解决。具体的解决方案需要根据具体情况进行选择和调整。
大模型LLM进行SFT 如何对样本进行优化?
对于大语言模型进行有监督微调(Supervised Fine-Tuning)时,可以采用以下几种方式对样本进行优化:
-
数据清洗和预处理:对于有监督微调的任务,首先需要对样本数据进行清洗和预处理。这包括去除噪声、处理缺失值、进行标准化或归一化等操作,以确保数据的质量和一致性。
-
数据增强:通过数据增强技术可以扩充训练数据,增加样本的多样性和数量。例如,可以使用数据扩充方法如随机裁剪、旋转、翻转、加噪声等来生成新的训练样本,从而提高模型的泛化能力。
-
标签平衡:如果样本标签不平衡,即某些类别的样本数量远远多于其他类别,可以采取一些方法来平衡样本标签。例如,可以通过欠采样、过采样或生成合成样本等技术来平衡不同类别的样本数量。
-
样本选择:在有限的资源和时间下,可以选择一部分具有代表性的样本进行微调训练。可以根据任务的需求和数据分布的特点,选择一些关键样本或难样本进行训练,以提高模型在关键样本上的性能。
-
样本权重:对于一些重要的样本或困难样本,可以给予更高的权重,以便模型更加关注这些样本的学习。可以通过调整损失函数中样本的权重或采用加权采样的方式来实现。
-
样本组合和分割:根据任务的特点和数据的结构,可以将多个样本组合成一个样本,或将一个样本分割成多个子样本。这样可以扩展训练数据,提供更多的信息和多样性。
-
样本筛选和策略:根据任务需求,可以制定一些样本筛选和选择策略。例如,可以根据样本的置信度、难度、多样性等指标进行筛选和选择,以提高模型的性能和泛化能力。
总的来说,对大语言模型进行有监督微调时,可以通过数据清洗和预处理、数据增强、标签平衡、样本选择、样本权重、样本组合和分割、样本筛选和策略等方式对样本进行优化。这些优化方法可以提高训练样本的质量、多样性和数量,从而提升模型的性能和泛化能力。具体的优化策略需要根据任务需求和数据特点进行选择和调整。
模型参数迭代实验
模型参数迭代实验是指通过多次迭代更新模型参数,以逐步优化模型性能的过程。在实验中,可以尝试不同的参数更新策略、学习率调整方法、正则化技术等,以找到最佳的参数配置,从而达到更好的模型性能。
下面是一个基本的模型参数迭代实验过程:
-
设定初始参数:首先,需要设定初始的模型参数。可以通过随机初始化或使用预训练模型的参数作为初始值。
-
选择损失函数:根据任务的特点,选择适当的损失函数作为模型的优化目标。常见的损失函数包括均方误差(MSE)、交叉熵损失等。
-
选择优化算法:选择适当的优化算法来更新模型参数。常见的优化算法包括随机梯度下降(SGD)、Adam、Adagrad等。可以尝试不同的优化算法,比较它们在模型训练过程中的效果。
-
划分训练集和验证集:将样本数据划分为训练集和验证集。训练集用于模型参数的更新,验证集用于评估模型性能和调整超参数。
-
迭代更新参数:通过多次迭代更新模型参数来优化模型。每次迭代中,使用训练集的一批样本进行前向传播和反向传播,计算损失函数并更新参数。可以根据需要调整批量大小、学习率等超参数。
-
评估模型性能:在每次迭代的过程中,可以使用验证集评估模型的性能。可以计算准确率、精确率、召回率、F1值等指标,以及绘制学习曲线、混淆矩阵等来分析模型的性能。
-
调整超参数:根据验证集的评估结果,可以调整超参数,如学习率、正则化系数等,以进一步提升模型性能。可以使用网格搜索、随机搜索等方法来寻找最佳的超参数配置。
-
终止条件:可以设置终止条件,如达到最大迭代次数、模型性能不再提升等。当满足终止条件时,结束模型参数迭代实验。
通过模型参数迭代实验,可以逐步优化模型性能,找到最佳的参数配置。在实验过程中,需要注意过拟合和欠拟合等问题,并及时调整模型结构和正则化技术来解决。同时,要进行合理的实验设计和结果分析,以得到可靠的实验结论。
什么是 LangChain?
https://python.langchain.com/docs/get_started/introduction
LangChain 是一个基于语言模型的框架,用于构建聊天机器人、生成式问答(GQA)、摘要等功能。它的核心思想是将不同的组件“链”在一起,以创建更高级的语言模型应用。
LangChain 包含哪些核心概念?
- Models(模型):这是LangChain框架的核心,指的是各种语言模型,如GPT-3、BERT等,它们用于理解和生成文本。
- Prompts(提示):这是提供给模型的问题或指令,用于指导模型生成期望的输出。良好的提示设计对于获得高质量的输出至关重要。
- Indexes(索引):这部分指的是将大量数据组织起来,以便模型可以快速准确地检索信息。索引可以是自定义的,也可以是利用现有的工具和数据库。
- Memory(记忆):为了使模型能够在对话或任务中保持上下文连贯性,Memory组件允许模型存储和回忆先前的交互信息。
- Chains(链):Chain是模型执行的一系列步骤。通过将模型调用组织成链,可以执行更复杂的任务,如信息检索、问题解答等。
- Agents(代理):Agents是高级概念,它涉及模型自主地决定采取哪些行动来完成特定任务。这通常涉及到模型调用外部工具或API。
- 训练数据选择:用户可以使用示例选择器从大型训练数据集中筛选和选择特定的示例。当使用有限的计算资源或专注于数据集的特定子集时,这非常有用。
- 推理定制:在推理过程中,示例选择器可用于从数据集中检索特定示例。这允许用户根据特定的条件或标准生成响应或预测。
LangChain 中 Components and Chains 是什么?
https://python.langchain.com/docs/modules/chains/
组件和链是LangChain框架中的关键概念。
组件指的是构成LangChain框架的单个构建块或模块。这些组件可以包括语言模型、数据预处理器、响应生成器等其他功能。每个组件负责语言模型应用中的特定任务或功能。
另一方面,链是这些组件之间的连接或链接。它们定义了语言模型应用中数据和信息的流动。链允许一个组件的输出作为另一个组件的输入,从而能够创建更先进的语言模型。
总结来说,组件是LangChain框架内的单个模块或功能,而链则定义了这些组件之间的连接和数据流动。
以下是一个示例,说明LangChain中组件和链的概念:
- from langchain import Component, Chain
-
- # Define components
- preprocessor = Component("Preprocessor")
- language_model = Component("Language Model")
- response_generator = Component("Response Generator")
-
- # Define chains
- chain1 = Chain(preprocessor, language_model)
- chain2 = Chain(language_model, response_generator)
-
- # Execute chains
- input_data = "Hello, how are you?"
- processed_data = chain1.execute(input_data)
- response = chain2.execute(processed_data)
-
- print(response)

在上面的示例中,我们有三个组件:预处理器、语言模型和响应生成器。我们创建了两个链:chain1连接预处理器和语言模型,chain2连接语言模型和响应生成器。输入数据通过chain1进行预处理,然后通过chain2生成响应。
这是一个简化的示例,用于演示LangChain中组件和链的概念。在实际场景中,您会有更复杂的链,包含多个组件和数据转换。
LangChain 中 Prompt Templates and Values 是什么?
https://python.langchain.com/docs/modules/model_io/prompts/prompt_templates/
提示模板和值是LangChain框架中的关键概念。
提示模板指的是预先定义的结构或格式,用于指导语言模型提示的生成。这些模板通过指定所需的输入和输出格式,提供了一种一致和标准化的构建提示的方法。提示模板可以包括占位符或变量,这些占位符或变量稍后会被具体的值填充。
另一方面,值是用于填充提示模板中的占位符或变量的具体数据或信息。这些值可以是动态生成的,也可以从外部来源检索。它们为语言模型提供必要的上下文或输入,以生成所需的输出。
以下是一个示例,说明LangChain中提示模板和值的概念:
- from langchain import PromptTemplate, Value
-
- # Define prompt template
- template = PromptTemplate("What is the capital of {country}?")
-
- # Define values
- country_value = Value("country", "France")
-
- # Generate prompt
- prompt = template.generate_prompt(values=[country_value])
-
- print(prompt)
在上面的示例中,我们有一个提示模板,用于询问一个国家的首都。该模板包括一个占位符{country},它将被实际的国家值填充。我们定义了一个值对象country_value,其名称为"country",值为"France"。然后,我们通过将值对象传递给模板的generate_prompt方法来生成提示。
生成的提示将是"What is the capital of France?"。
提示模板和值允许在LangChain框架中灵活和动态地生成提示。它们使根据特定要求或场景定制和适应提示成为可能。
LangChain 中 Example Selectors 是什么?
https://python.langchain.com/docs/modules/model_io/prompts/example_selectors/
示例选择器是LangChain框架中的一个功能,它允许用户指定并从数据集中检索特定的示例或数据点。这些选择器通过选择符合特定标准或条件的特定示例,帮助定制训练或推理过程。
示例选择器可以用于各种场景,以下是一个示例,说明LangChain中示例选择器的概念:
- from langchain import ExampleSelector
-
- # Define an example selector
- selector = ExampleSelector(condition="label=='positive'")
-
- # Retrieve examples based on the selector
- selected_examples = selector.select_examples(dataset)
-
- # Use the selected examples for training or inference
- for example in selected_examples:
- # Perform training or inference on the selected example
- ...
在上面的示例中,我们定义了一个示例选择器,其条件是选择标签等于"positive"的示例。然后我们使用这个选择器从数据集中检索选定的示例。这些选定的示例可以用于训练或推理目的。
示例选择器为定制LangChain框架中使用的数据提供了一种灵活的方式。它们允许用户专注于数据的特定子集,或应用特定标准来选择符合他们要求的示例。
LangChain 中 Output Parsers 是什么?
https://python.langchain.com/docs/modules/model_io/output_parsers/
输出解析器是LangChain框架中的一个功能,它允许用户自动检测并解析语言模型生成的输出。这些解析器设计用来处理不同类型的输出,例如字符串、列表、字典甚至Pydantic模型。
输出解析器提供了一种方便的方式来处理和操作语言模型的输出,无需手动解析或转换。它们帮助从输出中提取相关信息,并使得进一步的加工或分析成为可能。
以下是一个示例,说明LangChain中输出解析器的概念:
- # Define an output parser
- parser = OutputParser()
-
- # Apply the output parser to a function
- @llm_prompt(output_parser=parser)
- def generate_response(input_text):
- # Generate response using the language model
- response = language_model.generate(input_text)
- return response
-
- # Generate a response
- input_text = "Hello, how are you?"
- response = generate_response(input_text)
-
- # Parse the output
- parsed_output = parser.parse_output(response)
-
- # Process the parsed output
- processed_output = process_output(parsed_output)
-
- print(processed_output)
在上面的示例中,我们定义了一个输出解析器,并使用`llm_prompt`装饰器将其应用于`generate_response`函数。输出解析器自动检测输出的类型并提供解析后的输出。然后我们可以根据需要进一步处理或分析解析后的输出。
输出解析器在LangChain框架中提供了一种灵活且高效的方式来处理语言模型的输出。它们简化了输出的后处理,并使得与其他组件或系统的无缝集成成为可能。
LangChain 中 Indexes and Retrievers 是什么?
https://python.langchain.com/docs/modules/data_connection/retrievers/
https://python.langchain.com/docs/modules/data_connection/indexing
索引和检索器是Langchain框架中的组件。
索引用于存储和组织数据,以便高效检索。Langchain支持多种类型的文档索引,例如InMemoryExactNNIndex、HnswDocumentIndex、WeaviateDocumentIndex、ElasticDocIndex和QdrantDocumentIndex。每种索引都有自己的特点,适用于不同的用例。例如,InMemoryExactNNIndex适用于可以存储在内存中的小数据集,而HnswDocumentIndex轻量级,适用于中小型数据集。
另一方面,检索器用于根据给定的查询从索引中检索相关文档。Langchain提供了不同类型的检索器,如MetalRetriever和DocArrayRetriever。MetalRetriever与Metal平台一起使用,用于语义搜索和检索,而DocArrayRetriever与DocArray工具一起使用,用于管理多模态数据。
总的来说,索引和检索器是Langchain中用于高效数据存储和检索的基本组件。
LangChain 中 Chat Message History 是什么?
https://python.langchain.com/docs/modules/memory/chat_messages/
Chat Message History 是 Langchain 框架中的一个组件,用于存储和管理聊天消息的历史记录。它可以跟踪和保存用户和AI之间的对话,以便在需要时进行检索和分析。
Langchain 提供了不同的 Chat Message History 实现,包括 StreamlitChatMessageHistory、CassandraChatMessageHistory 和 MongoDBChatMessageHistory。
- StreamlitChatMessageHistory:用于在 Streamlit 应用程序中存储和使用聊天消息历史记录。它使用 Streamlit 会话状态来存储消息,并可以与 ConversationBufferMemory 和链或代理一起使用。
- CassandraChatMessageHistory:使用 Apache Cassandra 数据库存储聊天消息历史记录。Cassandra 是一种高度可扩展和高可用的 NoSQL 数据库,适用于存储大量数据。
- MongoDBChatMessageHistory:使用 MongoDB 数据库存储聊天消息历史记录。MongoDB 是一种面向文档的 NoSQL 数据库,使用类似 JSON 的文档进行存储。
您可以根据自己的需求选择适合的 Chat Message History 实现,并将其集成到 Langchain 框架中,以便记录和管理聊天消息的历史记录。
请注意,Chat Message History 的具体用法和实现细节可以参考 Langchain 的官方文档和示例代码。
LangChain 中 Agents and Toolkits 是什么?
https://python.langchain.com/docs/modules/agents/
https://python.langchain.com/docs/modules/agents/toolkits/
在LangChain中,代理(Agents)和工具包(Toolkits)是用于创建和管理对话代理的组件。
代理负责根据对话的当前状态确定下一步行动。可以使用不同的方法创建代理,例如OpenAI函数调用、计划执行代理(Plan-and-execute Agent)、Baby AGI和Auto GPT。这些方法为构建代理提供了不同级别的定制和功能。
另一方面,工具包是代理可以用来执行特定任务或动作的工具集合。工具是接受输入并产生输出的函数或方法。它们可以是自定义构建的,也可以是预定义的,涵盖了广泛的功能性,如语言处理、数据操作和外部API集成。
通过结合代理和工具包,开发人员可以创建强大的对话代理,这些代理能够理解用户输入,生成适当的响应,并根据给定的上下文执行各种任务。
以下是如何使用LangChain创建代理的示例:
- from langchain.chat_models import ChatOpenAI
- from langchain.agents import tool
-
- # Load the language model
- llm = ChatOpenAI(temperature=0)
-
- # Define a custom tool
- @tool
- def get_word_length(word: str) -> int:
- """Returns the length of a word."""
- return len(word)
-
- # Create the agent
- agent = {
- "input": lambda x: x["input"],
- "agent_scratchpad": lambda x: format_to_openai_functions(x['intermediate_steps'])
- } | prompt | llm_with_tools | OpenAIFunctionsAgentOutputParser()
-
- # Invoke the agent
- output = agent.invoke({
- "input": "how many letters in the word educa?",
- "intermediate_steps": []
- })
-
- # Print the result
- print(output.return_values["output"])
这是一个基本的示例,LangChain提供了更多的功能和特性来构建和定制代理和工具包。您可以通过查阅LangChain的文档来获取更多细节和示例。
什么是 LangChain Agent?
https://python.langchain.com/docs/modules/agents/
LangChain Agent 是 LangChain 框架中的一个组件,用于创建和管理对话代理。代理是根据当前对话状态确定下一步操作的组件。LangChain 提供了多种创建代理的方法,包括 OpenAI Function Calling、Plan-and-execute Agent、Baby AGI 和 Auto GPT 等。这些方法提供了不同级别的自定义和功能,用于构建代理。
代理可以使用工具包执行特定的任务或操作。工具包是代理使用的一组工具,用于执行特定的功能,如语言处理、数据操作和外部 API 集成。工具可以是自定义构建的,也可以是预定义的,涵盖了广泛的功能。
通过结合代理和工具包,开发人员可以创建强大的对话代理,能够理解用户输入,生成适当的回复,并根据给定的上下文执行各种任务。
以下是使用 LangChain 创建代理的示例代码:
- from langchain.chat_models import ChatOpenAI
- from langchain.agents import tool
-
- # 加载语言模型
- llm = ChatOpenAI(temperature=0)
-
- # 定义自定义工具
- @tool
- def get_word_length(word: str) -> int:
- """返回单词的长度。"""
- return len(word)
-
- # 创建代理
- agent = {
- "input": lambda x: x["input"],
- "agent_scratchpad": lambda x: format_to_openai_functions(x['intermediate_steps'])
- } | prompt | llm_with_tools | OpenAIFunctionsAgentOutputParser()
-
- # 调用代理
- output = agent.invoke({
- "input": "单词 educa 中有多少个字母?",
- "intermediate_steps": []
- })
-
- # 打印结果
- print(output.return_values["output"])
这只是一个基本示例,LangChain 中还有更多功能和功能可用于构建和自定义代理和工具包。您可以参考 LangChain 文档以获取更多详细信息和示例。
如何使用 LangChain?
https://python.langchain.com/docs/get_started/quickstart
要使用LangChain,您首先需要在platform.langchain.com上注册以获取API密钥。一旦您有了API密钥,就可以安装Python库并编写一个简单的Python脚本来调用LangChain API。以下是一些入门的示例代码:
- import langchain
-
- api_key = "YOUR_API_KEY"
-
- langchain.set_key(api_key)
-
- response = langchain.ask("What is the capital of France?")
-
- print(response.response)
这段代码将问题"What is the capital of France?"发送到LangChain API,并打印出响应。您可以通过提供max_tokens、temperature等参数来自定义请求。LangChain Python库文档中有更多关于可用选项的详细信息。
LangChain 支持哪些功能?
LangChain支持以下功能:
-
编写帖子的短标题:使用
write_me_short_post函数可以生成关于特定主题、平台和受众的短标题。该函数的参数包括topic(主题)、platform(平台,默认为Twitter)和audience(受众,默认为开发人员)。生成的标题应该在15个单词以内。 -
模拟对话:使用
simulate_conversation函数可以模拟对话,包括系统消息、用户消息和助手消息。对话可以根据角色(如助手、用户、系统)进行交互,并可以包含历史记录。这对于训练聊天模型非常有用。 -
可选部分:可以在提示中定义可选部分,只有在所有参数都不为空时才会渲染该部分。这可以通过在提示中使用
{? ... ?}语法来实现。 -
输出解析器:
llm_prompt装饰器可以自动检测输出类型,并提供相应的解析器。支持的输出类型包括字符串、列表、字典和Pydantic模型。
以上是LangChain支持的一些功能。您可以根据具体的需求使用这些功能来创建生产就绪的聊天应用程序。
什么是 LangChain model?
LangChain model 是一个基于语言模型的框架,用于构建聊天机器人、生成式问答(GQA)、摘要等功能。LangChain 的核心思想是可以将不同的组件“链”在一起,以创建更高级的语言模型应用。
LangChain model是一种基于大型语言模型(LLM)的模型。它是LangChain框架的核心组件之一,用于构建基于语言模型的应用程序。LangChain模型可以用于聊天机器人、生成式问答、摘要等多种应用。它提供了一种标准的接口,使开发人员能够使用LLM来处理自然语言处理任务。LangChain模型的目标是简化开发过程,使开发人员能够更轻松地构建强大的语言模型应用程序。
LangChain 包含哪些特点?
LangChain 包含以下特点:
- 编写自定义的LangChain提示和链式代码的语法糖
- 使用IDE内置的支持进行提示、类型检查和弹出文档,以快速查看函数的提示和参数
- 利用LangChain生态系统的全部功能
- 添加对可选参数的支持
- 通过将参数绑定到一个类来轻松共享参数
- 支持传递内存和回调函数
- 简化的流式处理
- 定义聊天消息提示
- 可选部分
- 输出解析器
- 支持更复杂的数据结构
LangChain 如何调用 LLMs 生成回复?
要调用LLMs生成回复,您可以使用LangChain框架提供的LLMChain类。LLMChain类是LangChain的一个组件,用于与语言模型进行交互并生成回复。以下是一个示例代码片段,展示了如何使用LLMChain类调用LLMs生成回复:
- from langchain.llms import OpenAI
- from langchain.chains import LLMChain
-
- llm = OpenAI(temperature=0.9) # 创建LLM实例
- prompt = "用户的问题" # 设置用户的问题
-
- # 创建LLMChain实例
- chain = LLMChain(llm=llm, prompt=prompt)
-
- # 调用LLMs生成回复
- response = chain.generate()
-
- print(response) # 打印生成的回复
在上面的代码中,我们首先创建了一个LLM实例,然后设置了用户的问题作为LLMChain的prompt。接下来,我们调用LLMChain的generate方法来生成回复。最后,我们打印生成的回复。
请注意,您可以根据需要自定义LLM的参数,例如温度(temperature)、最大令牌数(max_tokens)等。LangChain文档中有关于LLMChain类和LLM参数的更多详细信息。
LangChain 如何修改 提示模板?
要修改LangChain的提示模板,您可以使用LangChain框架提供的ChatPromptTemplate类。ChatPromptTemplate类允许您创建自定义的聊天消息提示,并根据需要进行修改。以下是一个示例代码片段,展示了如何使用ChatPromptTemplate类修改提示模板:
- from langchain.prompts import ChatPromptTemplate
-
- # 创建一个空的ChatPromptTemplate实例
- template = ChatPromptTemplate()
-
- # 添加聊天消息提示
- template.add_message("system", "You are a helpful AI bot.")
- template.add_message("human", "Hello, how are you doing?")
- template.add_message("ai", "I'm doing well, thanks!")
- template.add_message("human", "What is your name?")
-
- # 修改提示模板
- template.set_message_content(0, "You are a helpful AI assistant.")
- template.set_message_content(3, "What is your name? Please tell me.")
-
- # 格式化聊天消息
- messages = template.format_messages()
-
- print(messages)
在上面的代码中,我们首先创建了一个空的ChatPromptTemplate实例。然后,我们使用add_message方法添加了聊天消息提示。接下来,我们使用set_message_content方法修 改了第一个和最后一个聊天消息的内容。最后,我们使用format_messages方法格式化聊天消息,并打印出来。请注意,您可以根据需要添加、删除和修改聊天消息提示。ChatPromptTemplate类提供了多种方法来操作提示模板。更多详细信息和示例代码可以在LangChain文档中找到。
LangChain 如何链接多个组件处理一个特定的下游任务?
要链接多个组件处理一个特定的下游任务,您可以使用LangChain框架提供的Chain类。Chain类允许您将多个组件连接在一起,以便按顺序处理任务。以下是一个示例代码片段,展示了如何使用Chain类链接多个组件处理下游任务:
- from langchain.chains import Chain
- from langchain.components import Component1, Component2, Component3
-
- # 创建组件实例
- component1 = Component1()
- component2 = Component2()
- component3 = Component3()
-
- # 创建Chain实例并添加组件
- chain = Chain()
- chain.add_component(component1)
- chain.add_component(component2)
- chain.add_component(component3)
-
- # 处理下游任务
- output = chain.process_downstream_task()
-
- print(output)
在上面的代码中,我们首先创建了多个组件的实例,例如Component1、Component2和Component3。然后,我们创建了一个Chain实例,并使用add_component方法将这些组件添加到链中。最后,我们调用process_downstream_task方法来处理下游任务,并打印输出结果。
请注意,您可以根据需要添加、删除和修改组件。Chain类提供了多种方法来操作链。更多详细信息和示例代码可以在LangChain文档中找到。
LangChain 如何Embedding & vector store?
要在LangChain中进行嵌入和向量存储,您可以使用LangChain框架提供的Embedding和VectorStore类。Embedding类用于将文本嵌入到向量空间中,而VectorStore类用于存储和检索嵌入向量。以下是一个示例代码片段,展示了如何在LangChain中进行嵌入和向量存储:
- from langchain.embeddings import Embedding
- from langchain.vectorstore import VectorStore
-
- # 创建Embedding实例
- embedding = Embedding()
-
- # 将文本嵌入到向量空间中
- embedding.embed("Hello, world!")
-
- # 创建VectorStore实例
- vector_store = VectorStore()
-
- # 存储嵌入向量
- vector_store.store("hello", embedding.get_embedding())
-
- # 检索嵌入向量
- vector = vector_store.retrieve("hello")
-
- print(vector)
在上面的代码中,我们首先创建了一个Embedding实例,并使用embed方法将文本嵌入到向量空间中。然后,我们创建了一个VectorStore实例,并使用store方法将嵌入向量存储到向量存储中。最后,我们使用retrieve方法检索嵌入向量,并打印出来。
请注意,您可以根据需要添加、删除和修改嵌入向量。Embedding类和VectorStore类提供了多种方法来操作嵌入和向量存储。更多详细信息和示例代码可以在LangChain文档中找到。
LangChain 存在哪些问题及方法方案?
- LangChain 低效的令牌使用问题
LangChain的token使用是高效的。LangChain使用了一种称为"token-based"的方法来处理文本输入和输出。这种方法将文本分解为小的单元,称为"tokens",并对它们进行处理。相比于传统的字符或词语级别的处理,使用tokens可以更高效地处理文本。
LangChain还提供了一些参数,如max_tokens和temperature,可以用来控制生成回复的长度和多样性。通过调整这些参数,开发人员可以根据自己的需求来平衡生成回复的效率和质量。
总的来说,LangChain的token使用是高效的,并且开发人员可以通过调整参数来控制生成回复的效果。
- LangChain 文档的问题
为了解决这个问题,LangChain的维护者可以提供更加清晰和结构化的文档,包括详细的教程、示例和组件之间的交互说明。此外,建立一个活跃的社区论坛,让用户可以互相帮助解答疑问,也是很有帮助的。
- LangChain 太多概念容易混淆,过多的“辅助”函数问题
对辅助函数进行分类和模块化,提供清晰的API文档和使用指南,可以帮助用户更快地找到他们需要的函数,并理解如何使用它们。
- LangChain 行为不一致并且隐藏细节问题
确保框架的一致性和透明性是至关重要的。这可以通过严格的测试和持续集成流程来实现。同时,提供详细的错误信息和日志记录功能,可以帮助开发人员更好地理解系统的状态和行为。
- LangChain 缺乏标准的可互操作数据类型问题
LangChain提供了一种标准的接口,使开发人员能够使用大型语言模型(LLM)处理自然语言处理任务。虽然LangChain支持更复杂的数据结构,但它目前缺乏标准的可互操作数据类型。这意味着LangChain在处理数据时可能需要进行一些额外的处理和转换。开发人员可以根据自己的需求使用LangChain提供的功能和工具来处理和操作数据。
LangChain 替代方案?
LangChain是一个独特的框架,目前没有直接的替代方案。它提供了一种简化开发过程的方式,使开发人员能够更轻松地构建基于语言模型的应用程序。LangChain的特点包括编写自定义的LangChain提示和链式代码的语法糖、使用IDE内置的支持进行提示和类型检查、支持可选参数和共享参数等。虽然可能有其他类似的框架可用,但LangChain在其特定领域内提供了独特的功能和优势。
LLMs 存在模型幻觉问题,如何处理?
大语言模型的模型幻觉问题是指其可能生成看似合理但实际上不准确或不符合事实的内容。这是由于大语言模型在训练过程中接触到的数据源的偏差、噪声或错误所导致的。处理大语言模型的模型幻觉问题需要采取一些方法和策略,以下是一些建议:
-
数据清洗和预处理:在训练大语言模型之前,对数据进行仔细的清洗和预处理是至关重要的。删除不准确、噪声或有偏差的数据可以减少模型幻觉问题的出现。
-
多样化训练数据:为了减少模型对特定数据源的依赖和偏好,可以尽量使用多样化的训练数据。包括来自不同领域、不同来源和不同观点的数据,以获得更全面的语言理解。
-
引入多样性的生成策略:在生成文本时,可以采用多样性的生成策略来减少模型的倾向性和幻觉问题。例如,使用温度参数来调整生成的多样性,或者使用抽样和束搜索等不同的生成方法。
-
人工审核和后处理:对生成的文本进行人工审核和后处理是一种常用的方法。通过人工的干预和修正,可以纠正模型幻觉问题,并确保生成的内容准确和可靠。
-
引入外部知识和约束:为了提高生成文本的准确性,可以引入外部知识和约束。例如,结合知识图谱、实体识别或逻辑推理等技术,将先验知识和约束融入到生成过程中。
这些方法可以帮助减少大语言模型的模型幻觉问题,但并不能完全消除。因此,在使用大语言模型时,仍然需要谨慎评估生成结果的准确性和可靠性,并结合人工的审核和后处理来确保生成内容的质量。
基于LLM+向量库的文档对话 思路是怎么样?
基于大语言模型和向量库的文档对话可以通过以下实现思路:
-
数据预处理:首先,需要对文档数据进行预处理。这包括分词、去除停用词、词干化等步骤,以准备文档数据用于后续的向量化和建模。
-
文档向量化:使用向量库的方法,将每个文档表示为一个向量。常见的向量化方法包括TF-IDF、Word2Vec、Doc2Vec等。这些方法可以将文档转换为数值向量,以便计算文档之间的相似度或进行聚类分析。
-
大语言模型训练:使用大语言模型,如GPT、BERT等,对文档数据进行训练。这样可以使模型学习到文档之间的语义关系和上下文信息。
-
文档检索:当用户提供一个查询文本时,首先对查询文本进行向量化,然后计算查询向量与文档向量之间的相似度。可以使用余弦相似度或其他相似度度量方法来衡量它们之间的相似程度。根据相似度排序,返回与查询文本最相关的文档。
-
文档推荐:除了简单的文档检索,还可以使用大语言模型生成推荐文档。通过输入用户的查询文本,使用大语言模型生成与查询相关的文本片段或摘要,并根据这些生成的文本片段推荐相关的文档。
-
对话交互:在文档对话系统中,用户可以提供多个查询文本,并根据系统的回复进行进一步的对话交互。可以使用大语言模型生成系统的回复,并根据用户的反馈进行迭代和改进。
通过以上实现思路,可以构建一个基于大语言模型和向量库的文档对话系统,使用户能够方便地进行文档检索、推荐和对话交互。具体的实现细节和技术选择会根据具体的应用场景和需求来确定。
基于LLM+向量库的文档对话 核心技术是什么?
基于大语言模型和向量库的文档对话的核心技术包括以下几个方面:
-
大语言模型:大语言模型是指能够理解和生成人类语言的深度学习模型,如GPT、BERT等。这些模型通过在大规模文本数据上进行预训练,学习到语言的语义和上下文信息。在文档对话系统中,大语言模型可以用于生成回复、推荐相关文档等任务。
-
文档向量化:文档向量化是将文档表示为数值向量的过程。这可以使用向量库技术,如TF-IDF、Word2Vec、Doc2Vec等。文档向量化的目的是将文档转换为计算机可以处理的数值形式,以便计算文档之间的相似度或进行其他文本分析任务。
-
相似度计算:相似度计算是文档对话系统中的重要技术。通过计算查询文本向量与文档向量之间的相似度,可以实现文档的检索和推荐。常见的相似度计算方法包括余弦相似度、欧氏距离等。
-
对话生成:对话生成是指根据用户的查询文本生成系统的回复或推荐文档。这可以使用大语言模型来生成自然语言的回复。生成的回复可以基于查询文本的语义和上下文信息,以提供准确和有意义的回复。
-
对话交互:对话交互是指用户和系统之间的交互过程。用户可以提供查询文本,系统根据查询文本生成回复,用户再根据回复提供进一步的查询或反馈。对话交互可以通过迭代和反馈来改进系统的回复和推荐。
这些技术共同构成了基于大语言模型和向量库的文档对话系统的核心。通过结合这些技术,可以实现文档的检索、推荐和对话交互,提供更智能和个性化的文档服务。
基于LLM+向量库的文档对话 prompt 模板 如何构建?
构建基于大语言模型和向量库的文档对话的prompt模板可以考虑以下几个方面:
-
查询类型:首先确定用户可能的查询类型,例如问题查询、主题查询、摘要查询等。针对不同的查询类型,可以构建相应的prompt模板。例如,对于问题查询,可以使用"我有一个关于XXX的问题"作为模板;对于主题查询,可以使用"我想了解关于XXX的信息"作为模板。
-
查询内容:根据文档的特点和领域知识,确定用户可能会查询的内容。例如,对于新闻文档,查询内容可以包括新闻标题、关键词、时间范围等;对于学术论文,查询内容可以包括作者、论文标题、摘要等。根据查询内容,可以构建相应的prompt模板。例如,对于查询新闻标题的情况,可以使用"请问有关于XXX的新闻吗?"作为模板。
-
上下文信息:考虑上下文信息对于查询的影响。用户之前的查询或系统的回复可能会影响当前的查询。可以将上下文信息加入到prompt模板中,以便更好地理解用户的意图。例如,对于上一轮的回复是关于某个主题的,可以使用"我还有关于上次谈到的XXX的问题"作为模板。
-
可变参数:考虑到用户的查询可能有不同的变化,可以在prompt模板中留出一些可变的参数,以便根据具体查询进行替换。例如,可以使用"我想了解关于XXX的信息"作为模板,其中的XXX可以根据用户的查询进行替换。
通过这些方面的考虑,可以构建多个不同的prompt模板,以满足不同类型和内容的查询需求。在实际应用中,可以根据具体的场景和数据进行调整和优化,以提供更准确和有针对性的查询模板。
痛点1:文档切分粒度不好把控,噪声太多,语义信息丢失
在基于大语言模型和向量库的文档对话中,确实需要在文档切分的粒度上进行权衡。如果切分得太细,可能会引入较多的噪声;如果切分得太粗,可能会丢失一些重要的语义信息。以下是一些解决方案:
-
预处理和过滤:在进行文档切分之前,可以进行一些预处理和过滤操作,以减少噪声的影响。例如,可以去除文档中的停用词、标点符号、特殊字符等,以及进行拼写纠错和词形还原等操作。这样可以降低噪声的存在,提高文档切分的质量。
-
主题建模:可以使用主题建模技术,如LDA(Latent Dirichlet Allocation)等,对文档进行主题抽取。通过识别文档的主题,可以帮助确定文档切分的粒度。例如,将同一主题下的文档划分为一个切分单元,以保留更多的语义信息。
-
上下文信息:在进行文档切分时,考虑上下文信息对于语义的影响。例如,将与上一文档相关联的文档划分为一个切分单元,以保留上下文的连贯性和语义关联。这样可以更好地捕捉文档之间的语义信息。
-
动态切分:可以采用动态切分的方式,根据用户的查询和需要,实时生成切分单元。例如,根据用户的关键词或查询意图,动态生成包含相关信息的切分单元,以减少噪声和提高语义的准确性。
-
实验和优化:在实际应用中,可以进行一系列的实验和优化,通过不断调整和评估文档切分的效果。可以尝试不同的切分粒度,评估其噪声和语义信息的平衡。通过实验和优化,逐步找到合适的文档切分策略。
综上所述,解决文档切分粒度的问题需要综合考虑预处理、主题建模、上下文信息、动态切分等多个因素,并通过实验和优化来找到最佳的平衡点,以保留足够的语义信息同时减少噪声的影响。
痛点2:在基于垂直领域 表现不佳
如果在垂直领域中,基于LLM(Language Model + Retrieval)和向量库的文档对话表现不佳,可以考虑以下方法来改进:
-
针对垂直领域进行领域特定训练:LLM模型是基于大规模通用语料库进行训练的,可能无法充分捕捉垂直领域的特点和术语。可以使用领域特定的语料库对LLM模型进行微调或重新训练,以提高在垂直领域的表现。
-
增加领域知识:在向量库中,可以添加垂直领域的专业知识,如领域术语、实体名词等。这样可以提高向量库中文档的表示能力,使其更适应垂直领域的对话需求。
-
优化检索算法:在使用向量库进行文档检索时,可以尝试不同的检索算法和相似度计算方法。常用的算法包括余弦相似度、BM25等。通过调整参数和算法选择,可以提高检索的准确性和相关性。
-
数据增强和样本平衡:在训练LLM模型时,可以增加垂直领域的样本数据,以增加模型对垂直领域的理解和表达能力。同时,要注意样本的平衡,确保训练数据中包含各个垂直领域的典型对话场景,避免偏向某个特定领域。
-
引入外部知识库:在垂直领域的对话中,可以结合外部的领域知识库,如专业词典、行业标准等,来提供更准确的答案和解决方案。通过与外部知识库的结合,可以弥补LLM模型和向量库在垂直领域中的不足。
-
收集用户反馈和迭代优化:通过收集用户的反馈信息,了解用户对对话系统的需求和期望,并根据反馈进行迭代优化。持续改进和优化是提高垂直领域对话效果的关键。
总之,通过领域特定训练、增加领域知识、优化检索算法、数据增强和样本平衡、引入外部知识库以及收集用户反馈和迭代优化等方法,可以改进基于LLM和向量库的文档对话在垂直领域中的表现。这些方法可以根据具体情况灵活应用,以提高对话系统的准确性和适应性。
痛点3:langchain 内置 问答分句效果不佳问题
如果您在使用Langchain内置的问答分句功能时发现效果不佳,可以尝试以下方法来改善:
-
调整输入:检查输入的文本是否符合预期的格式和结构。确保输入的句子和段落之间有明确的分隔符,如句号、问号或换行符。如果输入的文本结构不清晰,可能会导致分句效果不佳。
-
引入标点符号:在文本中适当地引入标点符号,如句号、问号或感叹号,以帮助模型更好地理解句子的边界。标点符号可以提供明确的分句信号,有助于改善分句的准确性。
-
使用自定义规则:针对特定的文本类型或语言,可以使用自定义规则来分句。例如,可以编写正则表达式或使用特定的分句库来处理特定的分句需求。这样可以更好地适应特定的语言和文本结构。
-
结合其他工具:除了Langchain内置的问答分句功能,还可以结合其他分句工具或库来处理文本。例如,NLTK、spaCy等自然语言处理工具包中提供了强大的分句功能,可以与Langchain一起使用,以获得更好的分句效果。
-
使用上下文信息:如果上下文信息可用,可以利用上下文信息来辅助分句。例如,可以根据上下文中的语境和语义信息来判断句子的边界,从而提高分句的准确性。
-
收集反馈和调整模型:如果您发现Langchain内置的问答分句功能在特定场景下效果不佳,可以收集用户反馈,并根据反馈进行模型调整和改进。通过不断优化模型,可以逐渐改善分句效果。
总之,通过调整输入、引入标点符号、使用自定义规则、结合其他工具、使用上下文信息以及收集反馈和调整模型等方法,可以改善Langchain内置的问答分句效果。这些方法可以根据具体情况灵活使用,以提高分句的准确性和效果。
痛点4:如何尽可能召回与query相关的Document 问题
要尽可能召回与query相关的Document,可以采取以下方法:
-
建立索引:将Document集合建立索引,以便能够快速检索和匹配相关的Document。可以使用搜索引擎或专业的信息检索工具,如Elasticsearch、Solr等。
-
关键词匹配:通过对query和Document中的关键词进行匹配,筛选出包含相关关键词的Document。可以使用TF-IDF、BM25等算法来计算关键词的重要性和匹配程度。
-
向量化表示:将query和Document转化为向量表示,通过计算它们之间的相似度来判断相关性。可以使用词嵌入模型(如Word2Vec、GloVe)或深度学习模型(如BERT、ELMo)来获取向量表示。
-
上下文建模:考虑上下文信息,如query的前后文、Document的上下文等,以更准确地判断相关性。可以使用上下文编码器或注意力机制来捕捉上下文信息。
-
扩展查询:根据query的特点,进行查询扩展,引入相关的同义词、近义词、词根变化等,以扩大相关Document的召回范围。
-
语义匹配:使用语义匹配模型,如Siamese网络、BERT等,来计算query和Document之间的语义相似度,以更准确地判断相关性。
-
实时反馈:利用用户的反馈信息,如点击、收藏、评分等,来优化召回结果。通过监控用户行为,不断调整和优化召回算法,提升相关Document的召回率。
-
多模态信息利用:如果有可用的多模态信息,如图像、视频等,可以将其整合到召回模型中,以提供更丰富、准确的相关Document。通过多模态信息的利用,可以增强召回模型的表达能力和准确性。
总之,通过建立索引、关键词匹配、向量化表示、上下文建模、查询扩展、语义匹配、实时反馈和多模态信息利用等方法,可以尽可能召回与query相关的Document。这些方法可以单独使用,也可以结合起来,以提高召回的准确性和覆盖率。
痛点5:如何让LLM基于query和context得到高质量的response
要让LLM基于query和context得到高质量的response,可以采取以下方法:
-
数据准备:准备大量高质量的训练数据,包括query、context和对应的高质量response。确保数据的多样性和覆盖性,以提供更好的训练样本。
-
模型架构:选择合适的模型架构,如Transformer等,以便提取query和context中的重要信息,并生成相应的高质量response。确保模型具有足够的容量和复杂性,以适应各种复杂的查询和上下文。
-
微调和优化:使用预训练的模型作为起点,通过在特定任务上进行微调和优化,使模型能够更好地理解query和context,并生成更准确、连贯的response。可以使用基于强化学习的方法,如强化对抗学习,来进一步提高模型的表现。
-
上下文建模:在LLM中,上下文对于生成高质量的response非常重要。确保模型能够准确地理解和利用上下文信息,以生成与之相关的response。可以使用一些技术,如注意力机制和上下文编码器,来帮助模型更好地建模上下文。
-
评估和反馈:定期评估模型的性能,使用一些评估指标,如BLEU、ROUGE等,来衡量生成的response的质量。根据评估结果,及时调整和改进模型的训练策略和参数设置。同时,收集用户反馈和意见,以便进一步改进模型的性能。
-
多模态信息利用:如果有可用的多模态信息,如图像、视频等,可以将其整合到LLM中,以提供更丰富、准确的response。利用多模态信息可以增强模型的理解能力和表达能力,从而生成更高质量的response。
-
引入外部知识和资源:为了提高LLM的质量,可以引入外部知识和资源,如知识图谱、预训练的语言模型等。利用这些资源可以帮助模型更好地理解和回答query,从而生成更高质量的response。
总之,通过合适的数据准备、模型架构选择、微调和优化、上下文建模、评估和反馈、多模态信息利用以及引入外部知识和资源等方法,可以帮助LLM基于query和context得到高质量的response。
什么是微调?如何进行微调?
微调(Fine-tuning)是一种迁移学习的技术,用于在一个已经预训练好的模型基础上,通过进一步训练来适应特定的任务或数据集。微调可以在具有相似特征的任务之间共享知识,从而加快训练速度并提高模型性能。以下是一般的微调步骤:
-
选择预训练模型:选择一个在大规模数据集上预训练好的模型,如ImageNet上的预训练的卷积神经网络(如ResNet、VGG等)。这些模型通常具有良好的特征提取能力。
-
冻结底层权重:将预训练模型的底层权重(通常是卷积层)固定住,不进行训练。这是因为底层权重通常学习到了通用的特征,可以被用于许多不同的任务。
-
替换顶层分类器:将预训练模型的顶层分类器(通常是全连接层)替换为适合特定任务的新的分类器。新的分类器的输出节点数量应该与任务的类别数相匹配。
-
解冻部分权重(可选):根据任务的复杂性和可用的训练数据量,可以选择解冻一些底层权重,以便更好地适应新的任务。这样可以允许底层权重进行微小的调整,以更好地适应新任务的特征。
-
进行训练:使用特定任务的训练数据集对新的分类器进行训练。可以使用较小的学习率进行训练,以避免对预训练模型的权重进行过大的更新。
-
评估和调整:在训练完成后,使用验证集或测试集评估模型的性能。根据评估结果,可以进行调整,如调整学习率、调整模型结构等。
微调的关键是在预训练模型的基础上进行训练,从而将模型的知识迁移到特定任务上。通过这种方式,可以在较少的数据和计算资源下,快速构建和训练高性能的模型。
为什么需要 PEFT?
PEFT(Performance Estimation and Modeling for Fine-Tuning)是一种用于微调任务的性能估计和建模方法。它的主要目的是帮助研究人员和从业者在微调过程中更好地理解和预测模型的性能,并进行更有效的模型选择和调优。以下是一些需要使用PEFT的情况:
-
模型选择:在微调之前,通常需要选择一个合适的预训练模型。PEFT可以帮助评估和比较不同预训练模型在特定任务上的性能,从而选择最适合的模型。
-
超参数调优:微调过程中可能涉及到一些超参数的选择,如学习率、批量大小等。PEFT可以帮助预估不同超参数设置下模型的性能,并指导超参数的调优。
-
计算资源规划:微调通常需要大量的计算资源,如显存、GPU时间等。PEFT可以帮助估计不同模型和数据集规模下的计算资源需求,以便更好地规划和分配资源。
-
模型压缩和加速:在一些场景下,需要将模型压缩或加速,以便在资源受限的设备上进行推理。PEFT可以帮助评估不同压缩和加速技术对模型性能的影响,并指导模型优化的方向。
PEFT通过模型的性能估计和建模,可以提供更准确的预测和指导,帮助研究人员和从业者更好地进行微调任务的设计和优化。
介绍一下 PEFT?
PEFT(Performance Estimation and Modeling for Fine-Tuning)是一种用于微调任务的性能估计和建模方法。它的目的是帮助研究人员和从业者在微调过程中更好地理解和预测模型的性能,并进行更有效的模型选择和调优。PEFT的主要思想是通过预测模型在微调任务上的性能,提供对不同模型和参数设置的性能估计。这样可以避免在大规模数据集上进行昂贵的微调实验,从而节省时间和计算资源。PEFT的关键步骤包括:
-
数据采样:从原始数据集中采样一小部分数据用于性能估计。这样可以减少计算开销,同时保持采样数据与原始数据集的分布一致性。
-
特征提取:使用预训练模型提取采样数据的特征表示。这些特征通常具有很好的表达能力,可以用于性能估计。
-
性能估计模型:基于采样数据的特征表示,建立一个性能估计模型。这个模型可以是简单的线性回归模型,也可以是更复杂的神经网络模型。
-
性能预测:使用性能估计模型对未知数据的性能进行预测。通过输入微调任务的特征表示,模型可以输出预测的性能指标,如准确率、F1分数等。
通过PEFT,研究人员和从业者可以在微调之前,通过预测模型的性能,选择最佳的预训练模型、超参数设置和资源规划策略。这样可以加速模型的开发和优化过程,提高微调任务的效率和性能。
PEFT 有什么优点?
PEFT具有以下几个优点:
-
节省时间和计算资源:传统的微调方法需要在大规模数据集上进行昂贵的实验,耗费大量时间和计算资源。而PEFT通过性能估计和建模,可以避免这些实验,节省时间和计算开销。
-
提供准确的性能预测:PEFT通过建立性能估计模型,可以对未知数据的性能进行预测。这样可以提供准确的性能指标,帮助研究人员和从业者更好地理解模型的性能。
-
辅助模型选择和调优:PEFT可以帮助选择最佳的预训练模型、超参数设置和资源规划策略。通过预测模型的性能,可以指导模型选择和调优的方向,提高微调任务的效率和性能。
-
可解释性和可扩展性:PEFT的性能估计模型可以是简单的线性回归模型,也可以是更复杂的神经网络模型。这使得PEFT具有很好的可解释性和可扩展性,可以适应不同的微调任务和数据集。
-
适用于资源受限的场景:在一些资源受限的场景下,如移动设备或边缘计算环境,无法进行大规模的微调实验。PEFT可以帮助估计模型在这些设备上的性能,并指导模型压缩和加速的方向。
综上所述,PEFT通过性能估计和建模,提供了一种高效、准确和可解释的方法,帮助研究人员和从业者进行微调任务的设计和优化。
微调方法批处理大小,模式大小,GPU显存速度关系?
微调方法的批处理大小、模型大小和GPU显存之间存在一定的关系,可以影响微调的速度和性能。下面是一些常见的情况:
-
批处理大小(Batch Size):批处理大小是指在每次迭代中同时处理的样本数量。较大的批处理大小可以提高GPU的利用率,加快训练速度,但可能会导致显存不足的问题。如果批处理大小过大,无法适应GPU显存的限制,可能需要减小批处理大小或使用分布式训练等方法来解决显存不足的问题。
-
模型大小(Model Size):模型大小指的是微调任务中使用的模型的参数量和内存占用。较大的模型通常需要更多的显存来存储参数和激活值,可能会导致显存不足的问题。在GPU显存有限的情况下,可以考虑使用轻量级模型或模型压缩等方法来减小模型大小,以适应显存限制。
-
GPU显存:GPU显存是指GPU设备上可用的内存大小。如果微调任务所需的显存超过了GPU显存的限制,会导致显存不足的问题。在这种情况下,可以采取一些策略来解决显存不足,例如减小批处理大小、减小模型大小、使用分布式训练、使用混合精度训练等。
总之,微调方法的批处理大小、模型大小和GPU显存之间存在相互影响的关系。需要根据具体的情况来选择合适的参数设置,以在保证性能的同时,充分利用GPU资源并避免显存不足的问题。
PEFT 和 全量微调区别?
PEFT(Performance Estimation for Fine-Tuning)和全量微调(Full Fine-Tuning)是两种不同的微调方法,它们在性能估计和实际微调过程中的数据使用上存在一些区别。
-
时间和计算开销:全量微调需要在完整数据集上进行训练和调优,耗费大量时间和计算资源。尤其是在大规模数据集和复杂模型的情况下,全量微调的时间和计算开销会更大。
-
数据使用:全量微调使用完整的微调数据集进行模型的训练和调优。这意味着需要在大规模数据集上进行昂贵的实验,耗费大量时间和计算资源。
-
性能预测准确性:全量微调通过在完整数据集上进行训练和调优,可以获得较为准确的性能指标。因为全量微调是在实际数据上进行的,所以能够更好地反映模型在真实场景中的性能。
而PEFT则通过性能估计和建模的方式,避免了在完整数据集上进行实验的过程,从而节省了时间和计算开销。PEFT使用一部分样本数据来训练性能估计模型,然后利用该模型对未知数据的性能进行预测。虽然PEFT的性能预测准确性可能不如全量微调,但可以提供一个相对准确的性能指标,帮助研究人员和从业者更好地理解模型的性能。
综上所述,PEFT和全量微调在数据使用、时间和计算开销以及性能预测准确性等方面存在一些区别。选择使用哪种方法应根据具体情况和需求来决定。
多种不同的高效微调方法对比
在高效微调方法中,有几种常见的方法可以比较,包括迁移学习、知识蒸馏和网络剪枝。下面是对这些方法的简要比较:
-
迁移学习(Transfer Learning):迁移学习是一种通过利用预训练模型的知识来加速微调的方法。它可以使用在大规模数据集上预训练的模型作为初始模型,并在目标任务上进行微调。迁移学习可以大大减少微调所需的训练时间和计算资源,并且通常能够达到较好的性能。
-
知识蒸馏(Knowledge Distillation):知识蒸馏是一种将大型复杂模型的知识转移到小型模型中的方法。它通过在预训练模型上进行推理,并使用其输出作为目标标签,来训练一个较小的模型。知识蒸馏可以在保持较小模型的高效性能的同时,获得接近于大型模型的性能。
-
网络剪枝(Network Pruning):网络剪枝是一种通过减少模型的参数和计算量来提高微调效率的方法。它通过对预训练模型进行剪枝,去除冗余和不必要的连接和参数,从而减少模型的大小和计算量。网络剪枝可以显著减少微调所需的训练时间和计算资源,并且通常能够保持较好的性能。
这些高效微调方法都有各自的特点和适用场景。迁移学习适用于目标任务与预训练任务相似的情况,可以快速获得较好的性能。知识蒸馏适用于需要在小型模型上进行微调的情况,可以在保持高效性能的同时减少模型大小。网络剪枝适用于需要进一步减少微调所需资源的情况,可以在保持较好性能的同时减少模型大小和计算量。
综上所述,选择适合的高效微调方法应根据具体任务需求和资源限制来决定。不同方法之间也可以结合使用,以进一步提高微调的效率和性能。
当前高效微调技术存在的一些问题
尽管高效微调技术在提高微调效率方面取得了一些进展,但仍然存在一些问题和挑战:
-
性能保持:一些高效微调技术可能在提高效率的同时,对模型性能产生一定的影响。例如,网络剪枝可能会削减模型的容量,导致性能下降。因此,在使用高效微调技术时需要权衡效率和性能之间的关系,并进行适当的调整和优化。
-
通用性:目前的高效微调技术通常是针对特定的模型架构和任务设计的,可能不具备通用性。这意味着对于不同的模型和任务,可能需要重新设计和实现相应的高效微调技术。因此,需要进一步研究和开发通用的高效微调技术,以适应不同场景和需求。
-
数据依赖性:一些高效微调技术可能对数据的分布和规模具有一定的依赖性。例如,迁移学习通常需要目标任务和预训练任务具有相似的数据分布。这可能限制了高效微调技术在一些特殊或小规模数据集上的应用。因此,需要进一步研究和改进高效微调技术,使其对数据的依赖性更加灵活和适应性更强。
-
可解释性:一些高效微调技术可能会引入一些黑盒操作,使得模型的解释和理解变得困难。例如,知识蒸馏可能会导致模型的输出不再直接对应于原始数据标签。这可能会影响模型的可解释性和可信度。因此,需要进一步研究和改进高效微调技术,以提高模型的可解释性和可理解性。
综上所述,当前高效微调技术在性能保持、通用性、数据依赖性和可解释性等方面仍然存在一些问题和挑战。随着研究的深入和技术的发展,相信这些问题将逐渐得到解决,并推动高效微调技术的进一步发展和应用。
高效微调技术最佳实践
以下是一些高效微调技术的最佳实践:
-
选择合适的预训练模型:预训练模型的选择对于高效微调至关重要。选择在大规模数据集上训练过的模型,例如ImageNet上的模型,可以获得更好的初始参数和特征表示。
-
冻结部分层:在微调过程中,可以选择冻结预训练模型的一部分层,只微调模型的一部分层。通常,较低层的特征提取层可以被冻结,只微调较高层的分类层。这样可以减少微调所需的训练时间和计算资源。
-
适当调整学习率:微调过程中,学习率的调整非常重要。通常,可以使用较小的学习率来微调模型的较高层,以避免过大的参数更新。同时,可以使用较大的学习率来微调模型的较低层,以更快地调整特征表示。
-
数据增强:数据增强是一种有效的方法,可以增加训练数据的多样性,提高模型的泛化能力。在微调过程中,可以使用各种数据增强技术,例如随机裁剪、翻转和旋转等,以增加训练数据的数量和多样性。
-
早停策略:在微调过程中,使用早停策略可以避免过拟合。可以监测验证集上的性能,并在性能不再提升时停止微调,以避免过多训练导致模型在验证集上的性能下降。
-
结合其他高效微调技术:可以结合多种高效微调技术来进一步提高微调的效率和性能。例如,可以使用知识蒸馏来将大型模型的知识转移到小型模型中,以减少模型的大小和计算量。
早停策略(Early Stopping)是一种用于防止过拟合的技术,即在训练过程中,当验证集上的性能不再提高时停止训练。
微调的早停策略结合了这两个概念。具体来说,它指的是在微调预训练模型时,通过监控验证集上的性能指标(如准确率、损失函数值等),在性能不再提升时及时停止训练。这样可以避免模型在训练数据上过度拟合,从而导致泛化能力下降。
早停策略通常需要设置一些参数,例如:
1. 验证集:用于监控模型性能的数据集。
2. 检查点:训练过程中检查模型性能的频率。
3. 停止准则:决定何时停止训练的规则,例如连续多次性能不再提升。
通过合理地运用早停策略,可以提高模型在未知数据上的表现,并减少训练时间。
综上所述,高效微调技术的最佳实践包括选择合适的预训练模型、冻结部分层、适当调整学习率、使用数据增强、使用早停策略以及结合其他高效微调技术。这些实践可以帮助提高微调的效率和性能,并在资源受限的情况下获得更好的结果。
PEFT 存在的问题
PEFT(Performance Estimation and Modeling for Fine-Tuning)是一种用于估计和建模微调过程中性能的方法。尽管PEFT在一些方面具有优势,但也存在一些问题和挑战:
-
精度限制:PEFT的性能估计是基于预训练模型和微调数据集的一些统计特征进行建模的。这种建模方法可能无法准确地捕捉到微调过程中的复杂性和不确定性。因此,PEFT的性能估计结果可能存在一定的误差和不确定性,无法完全准确地预测微调性能。
-
数据偏差:PEFT的性能估计和建模依赖于预训练模型和微调数据集的统计特征。如果这些特征与实际应用场景存在显著差异,PEFT的性能估计可能不准确。例如,如果微调数据集与目标任务的数据分布不一致,PEFT的性能估计可能会有较大的偏差。
-
模型依赖性:PEFT的性能估计和建模依赖于预训练模型的质量和性能。如果预训练模型本身存在一些问题,例如表示能力不足或训练偏差等,PEFT的性能估计可能会受到影响。因此,PEFT的性能估计结果可能在不同的预训练模型之间存在差异。
-
计算复杂性:PEFT的性能估计和建模可能需要大量的计算资源和时间。尤其是在大规模模型和数据集上,PEFT的计算复杂性可能会变得非常高。这可能限制了PEFT在实际应用中的可行性和可扩展性。
综上所述,尽管PEFT在性能估计和建模方面具有一定的优势,但仍然存在精度限制、数据偏差、模型依赖性和计算复杂性等问题。在使用PEFT时,需要注意这些问题,并进行适当的验证和调整,以确保性能估计的准确性和可靠性。
各种参数高效微调方法总结
当涉及到高效微调方法时,有几个关键的参数和技术可以考虑:
-
冻结层:在微调过程中,可以选择冻结预训练模型的一部分层,只微调模型的一部分层。通常,较低层的特征提取层可以被冻结,只微调较高层的分类层。这样可以减少微调所需的训练时间和计算资源。
-
学习率调整:微调过程中,学习率的调整非常重要。可以使用较小的学习率来微调模型的较高层,以避免过大的参数更新。同时,可以使用较大的学习率来微调模型的较低层,以更快地调整特征表示。
-
数据增强:数据增强是一种有效的方法,可以增加训练数据的多样性,提高模型的泛化能力。在微调过程中,可以使用各种数据增强技术,例如随机裁剪、翻转和旋转等,以增加训练数据的数量和多样性。
-
早停策略:在微调过程中,使用早停策略可以避免过拟合。可以监测验证集上的性能,并在性能不再提升时停止微调,以避免过多训练导致模型在验证集上的性能下降。
-
知识蒸馏:知识蒸馏是一种将大型模型的知识转移到小型模型中的方法,以减少模型的大小和计算量。通过将预训练模型的输出作为目标标签,可以在微调过程中使用知识蒸馏来提高小型模型的性能。
这些参数和技术可以根据具体的任务和数据集进行调整和应用。综合考虑这些方法,可以提高微调的效率和性能,并在资源受限的情况下获得更好的结果。
为什么需要适配器微调(Adapter-tuning)?
适配器微调(Adapter-tuning)是一种用于微调预训练模型的方法,它相比于传统的微调方法具有一些优势和应用场景。以下是一些需要适配器微调的情况:
-
保留预训练模型的知识:在传统的微调方法中,通常需要在微调过程中更新整个模型的参数。然而,对于某些任务和应用,我们可能希望保留预训练模型的知识,而只对特定任务进行微调。适配器微调可以实现这一目标,它只微调模型的适配器层,而不改变预训练模型的参数。
-
减少微调的计算量和时间:传统的微调方法需要更新整个模型的参数,这可能需要大量的计算资源和时间。适配器微调可以显著减少微调的计算量和时间,因为它只需要微调适配器层的参数,而不需要重新训练整个模型。
-
提高模型的可解释性和可复用性:适配器微调可以使模型更具可解释性和可复用性。通过在适配器层中添加任务特定的适配器,我们可以更好地理解模型在不同任务上的表现,并且可以将适配器用于其他类似的任务,从而提高模型的可复用性。
-
避免灾难性遗忘:在传统的微调方法中,微调过程可能会导致预训练模型在原任务上的性能下降,即灾难性遗忘。适配器微调通过只微调适配器层,可以避免对预训练模型的其他部分进行大幅度的更新,从而减少灾难性遗忘的风险。
总而言之,适配器微调是一种用于微调预训练模型的方法,它可以保留预训练模型的知识,减少计算量和时间,提高模型的可解释性和可复用性,并避免灾难性遗忘。这些优势使得适配器微调在某些任务和应用中成为一种有吸引力的选择。
适配器微调(Adapter-tuning)思路
适配器微调(Adapter-tuning)是一种用于微调预训练模型的方法,其思路可以概括如下:
-
预训练模型选择:首先,选择一个适合任务的预训练模型,例如BERT、GPT等。这些预训练模型在大规模数据上进行了训练,具有较强的语义表示能力。
-
适配器层添加:在选择的预训练模型中,为目标任务添加适配器层。适配器层是一个小型的任务特定层,通常由一个或多个全连接层组成。适配器层的目的是将预训练模型的表示转换为适合目标任务的表示。
-
冻结其他层:在适配器微调中,通常会冻结预训练模型的其他层,只微调适配器层的参数。这是因为预训练模型已经在大规模数据上进行了训练,其低层特征提取层已经具有较好的特征表示能力,不需要进行大幅度的更新。
-
学习率调整:在微调过程中,可以使用较小的学习率来微调适配器层的参数,以避免过大的参数更新。同时,可以使用较大的学习率来微调预训练模型的其他层,以更快地调整特征表示。
-
数据增强和训练:为了增加训练数据的多样性,可以使用各种数据增强技术,例如随机裁剪、翻转和旋转等。然后,使用目标任务的标注数据对适配器层进行训练。
-
验证和调优:在微调过程中,可以使用验证集来监测模型的性能,并根据性能表现进行调优。可以根据验证集上的性能选择最佳的模型参数和超参数。
适配器微调的思路是在预训练模型中添加适配器层,并只微调适配器层的参数,从而保留预训练模型的知识、减少计算量和时间,并提高模型的可解释性和可复用性。这种方法在许多自然语言处理和计算机视觉任务中都取得了良好的效果。
适配器微调(Adapter-tuning)特点是什么?
适配器微调(Adapter-tuning)具有以下特点:
-
保留预训练模型的知识:适配器微调只微调适配器层的参数,而不改变预训练模型的其他参数。这样可以保留预训练模型在大规模数据上学到的知识和特征表示能力。
-
减少微调的计算量和时间:相比于传统的微调方法,适配器微调只需要微调适配器层的参数,而不需要重新训练整个模型。这样可以大大减少微调的计算量和时间消耗。
-
提高模型的可解释性和可复用性:适配器微调在预训练模型中添加了适配器层,这些适配器层可以理解为任务特定的模块。通过适配器层,模型的性能在不同任务之间可以更好地解释和比较,并且适配器层可以用于其他类似的任务,提高模型的可复用性。
-
避免灾难性遗忘:传统的微调方法可能导致预训练模型在原任务上的性能下降,即灾难性遗忘。适配器微调只微调适配器层的参数,不对预训练模型的其他部分进行大幅度的更新,可以减少灾难性遗忘的风险。
-
灵活性和可扩展性:适配器微调可以在不同的预训练模型和任务中应用。适配器层的设计可以根据任务的特点进行调整,以适应不同的任务需求。这种灵活性和可扩展性使得适配器微调成为一种通用且高效的微调方法。
总而言之,适配器微调通过保留预训练模型的知识、减少计算量和时间、提高模型的可解释性和可复用性、避免灾难性遗忘以及具有灵活性和可扩展性等特点,成为一种有吸引力的微调方法。
AdapterFusion 思路是什么?
AdapterFusion是一种用于多任务学习的方法,其思路可以概括如下:
-
预训练模型选择:首先,选择一个适合多任务学习的预训练模型,例如BERT、GPT等。这些预训练模型在大规模数据上进行了训练,具有较强的语义表示能力。
-
适配器层添加:在选择的预训练模型中,为每个任务添加适配器层。适配器层是一个小型的任务特定层,通常由一个或多个全连接层组成。适配器层的目的是将预训练模型的表示转换为适合每个任务的表示。
-
适配器融合:在AdapterFusion中,适配器融合是关键步骤。适配器融合通过将不同任务的适配器层的输出进行融合,得到一个综合的表示。常见的融合方法包括简单的加权平均、注意力机制等。
-
冻结其他层:在AdapterFusion中,通常会冻结预训练模型的其他层,只微调适配器层的参数。这是因为预训练模型已经在大规模数据上进行了训练,其低层特征提取层已经具有较好的特征表示能力,不需要进行大幅度的更新。
-
学习率调整:在微调过程中,可以使用较小的学习率来微调适配器层的参数,以避免过大的参数更新。同时,可以使用较大的学习率来微调预训练模型的其他层,以更快地调整特征表示。
-
数据增强和训练:为了增加训练数据的多样性,可以使用各种数据增强技术,例如随机裁剪、翻转和旋转等。然后,使用多个任务的标注数据对适配器层进行训练。
-
验证和调优:在微调过程中,可以使用验证集来监测模型的性能,并根据性能表现进行调优。可以根据验证集上的性能选择最佳的模型参数和超参数。
AdapterFusion的思路是在预训练模型中为每个任务添加适配器层,并通过适配器融合将不同任务的表示进行融合,从而提高多任务学习的性能。这种方法可以充分利用预训练模型的知识,并通过适配器融合实现任务之间的信息共享和互补,从而提高模型的泛化能力和效果。
AdapterDrop 思路是什么?
AdapterDrop是一种用于适配器微调的方法,其思路可以概括如下:
-
适配器层添加:首先,在预训练模型中为每个任务添加适配器层。适配器层是一个小型的任务特定层,通常由一个或多个全连接层组成。适配器层的目的是将预训练模型的表示转换为适合每个任务的表示。
-
适配器层的随机丢弃:在AdapterDrop中,引入了适配器层的随机丢弃机制。具体而言,对于每个任务,在训练过程中以一定的概率随机丢弃该任务的适配器层。这样,模型在训练过程中会随机选择使用哪些任务的适配器层进行微调。
-
动态适配器选择:在每个训练样本上,通过随机丢弃适配器层,模型会自动选择使用哪些任务的适配器层进行微调。这种动态的适配器选择机制可以增加模型的鲁棒性和泛化能力,使得模型能够适应不同任务的变化和不确定性。
-
训练和微调:在训练过程中,使用多个任务的标注数据对适配器层进行训练。对于每个训练样本,根据随机丢弃的适配器层进行微调,并计算损失函数以更新模型的参数。
-
推断和预测:在推断和预测阶段,可以选择使用所有任务的适配器层进行预测,或者根据某种策略选择部分任务的适配器层进行预测。这样可以根据具体应用场景的需求进行灵活的任务选择和预测。
AdapterDrop的思路是通过适配器层的随机丢弃机制,实现动态的适配器选择和微调。这种方法可以增加模型的鲁棒性和泛化能力,使得模型能够适应不同任务的变化和不确定性。同时,通过随机丢弃适配器层,还可以减少模型的计算量和参数数量,提高模型的效率和可扩展性。
AdapterDrop 特点是什么?
AdapterDrop具有以下几个特点:
-
动态适配器选择:AdapterDrop引入了适配器层的随机丢弃机制,使得模型可以在训练过程中动态选择使用哪些任务的适配器层进行微调。这种动态适配器选择机制可以增加模型的鲁棒性和泛化能力,使得模型能够适应不同任务的变化和不确定性。
-
鲁棒性和泛化能力:通过随机丢弃适配器层,AdapterDrop可以让模型在训练过程中随机选择使用哪些任务的适配器层进行微调。这种随机性可以增加模型对于噪声和干扰的鲁棒性,并提高模型的泛化能力。
-
减少计算量和参数数量:通过随机丢弃适配器层,AdapterDrop可以减少模型的计算量和参数数量。在训练过程中,只有部分任务的适配器层被使用,其他任务的适配器层被丢弃,从而减少了模型的计算量和参数数量,提高了模型的效率和可扩展性。
-
灵活的任务选择和预测:在推断和预测阶段,可以根据具体的需求选择使用所有任务的适配器层进行预测,或者选择使用部分任务的适配器层进行预测。这种灵活的任务选择和预测机制可以根据具体应用场景的需求进行灵活调整,提高模型的适应性和可用性。
总之,AdapterDrop通过动态适配器选择、增加鲁棒性和泛化能力、减少计算量和参数数量以及灵活的任务选择和预测等特点,提供了一种有效的方法来进行适配器微调,进一步提高多任务学习的性能。
MAM Adapter 思路是什么?
MAM Adapter(Masked and Masked Adapter for Multi-task Learning)是一种用于多任务学习的适配器微调方法,其思路可以概括如下:
-
适配器层添加:首先,在预训练模型中为每个任务添加适配器层。适配器层是一个小型的任务特定层,通常由一个或多个全连接层组成。适配器层的目的是将预训练模型的表示转换为适合每个任务的表示。
-
掩码机制:在MAM Adapter中,引入了掩码机制来增强适配器层的表示能力。具体而言,对于每个任务,在训练过程中,随机选择一部分适配器层的神经元进行掩码操作,即将这些神经元的输出置为0。这样可以使得适配器层的表示更加丰富和多样化。
-
掩码预测:在训练过程中,除了对任务的预测进行优化外,还引入了掩码预测任务。具体而言,对于每个任务,在适配器层的输出上添加一个掩码预测层,用于预测哪些神经元应该被掩码。这样,模型在训练过程中不仅要优化任务的预测准确性,还要同时优化掩码预测任务的准确性。
-
联合训练:在训练过程中,使用多个任务的标注数据对适配器层和掩码预测层进行联合训练。通过最小化任务预测的损失和掩码预测的损失,来更新模型的参数。这样可以使得模型能够同时学习任务的表示和掩码的生成,进一步提高多任务学习的性能。
-
推断和预测:在推断和预测阶段,可以选择使用所有任务的适配器层进行预测,或者根据某种策略选择部分任务的适配器层进行预测。根据具体应用场景的需求,可以灵活选择适配器层进行预测,从而实现多任务学习的目标。
MAM Adapter的思路是通过引入掩码机制和掩码预测任务,增强适配器层的表示能力,并通过联合训练优化任务预测和掩码预测的准确性。这种方法可以提高适配器微调的性能,进一步增强多任务学习的效果。
MAM Adapter 特点是什么?
MAM Adapter具有以下几个特点:
-
掩码机制增强表示能力:MAM Adapter引入了掩码机制,通过随机掩码部分适配器层的神经元,从而增强适配器层的表示能力。这种掩码机制可以使得适配器层的表示更加丰富和多样化,有助于提高多任务学习的性能。
-
联合训练优化任务和掩码预测:MAM Adapter在训练过程中不仅优化任务的预测准确性,还同时优化掩码预测任务的准确性。通过最小化任务预测的损失和掩码预测的损失,来更新模型的参数。这样可以使得模型能够同时学习任务的表示和掩码的生成,进一步提高多任务学习的性能。
-
灵活的任务选择和预测:在推断和预测阶段,可以根据具体的需求选择使用所有任务的适配器层进行预测,或者选择使用部分任务的适配器层进行预测。这种灵活的任务选择和预测机制可以根据具体应用场景的需求进行灵活调整,提高模型的适应性和可用性。
-
提高多任务学习性能:MAM Adapter通过增强适配器层的表示能力和联合训练优化任务和掩码预测,可以提高多任务学习的性能。适配器层的表示能力增强了模型对任务的适应能力,而掩码预测任务的优化可以使得模型学习到更加鲁棒的表示。
总之,MAM Adapter通过掩码机制增强表示能力、联合训练优化任务和掩码预测、灵活的任务选择和预测等特点,提供了一种有效的方法来进行适配器微调,进一步提高多任务学习的性能。
什么是 LoRA?
LoRA(low-rank adaptation of large language models)是一种针对大型语言模型进行低秩适应的技术。大型语言模型通常具有数十亿个参数,这使得它们在计算和存储方面非常昂贵。低秩适应的目标是通过将语言模型的参数矩阵分解为低秩近似,来减少模型的复杂度和计算资源的需求。低秩适应的方法可以通过使用矩阵分解技术,如奇异值分解(Singular Value Decomposition,SVD)或特征值分解(Eigenvalue Decomposition),将语言模型的参数矩阵分解为较低秩的近似矩阵。通过这种方式,可以减少模型的参数量和计算复杂度,同时保留模型的关键特征和性能。低秩适应的技术可以用于加速大型语言模型的推理过程,减少模型的存储需求,并提高在资源受限环境下的模型效率。它是在大型语言模型优化和压缩领域的一个重要研究方向。
LoRA 的思路是什么?
LoRA(Low-Rank Adaptation)是一种用于大规模语言模型的低秩适应方法,旨在减少模型的计算和存储开销。它的核心思想是通过对模型参数矩阵进行低秩分解,以达到降低模型复杂度和提高效率的目的。具体而言,LoRA的思路可以分为以下几个步骤:
-
参数矩阵分解:LoRA通过对模型参数矩阵进行低秩分解,将其分解为两个或多个较小的矩阵的乘积。常用的矩阵分解方法包括奇异值分解(SVD)和特征值分解(Eigenvalue Decomposition)等。
-
低秩适应:在参数矩阵分解之后,我们可以选择保留较低秩的近似矩阵,而舍弃一些对模型性能影响较小的细微变化。这样可以减少模型的参数量和计算复杂度,同时保留模型的关键特征和性能。
-
重构模型:使用低秩适应后的近似矩阵重新构建语言模型,该模型具有较低的参数量和计算需求,但仍能保持相对较高的性能。
通过LoRA的低秩适应方法,我们可以在不显著损失模型性能的情况下,降低大型语言模型的复杂度和资源需求。这对于在计算资源受限的环境下部署和使用语言模型非常有帮助。
LoRA 的特点是什么?
LoRA(Low-Rank Adaptation)具有以下几个特点:
-
低秩适应:LoRA通过对大型语言模型的参数矩阵进行低秩分解,将其分解为较小的矩阵的乘积。这样可以减少模型的参数量和计算复杂度,提高模型的效率和速度。
-
保持关键特征:虽然低秩适应会舍弃一些对模型性能影响较小的细节,但它会尽量保留模型的关键特征。通过选择合适的低秩近似矩阵,可以最大限度地保持模型的性能。
-
减少存储需求:低秩适应可以显著减少大型语言模型的参数量,从而降低模型的存储需求。这对于在资源受限的设备上使用语言模型非常有益。
-
加速推理过程:由于低秩适应减少了模型的计算复杂度,因此可以加速模型的推理过程。这对于实时应用和大规模部署非常重要。
-
可扩展性:LoRA的低秩适应方法可以应用于各种大型语言模型,包括预训练的Transformer模型等。它是一种通用的技术,可以适应不同的模型架构和任务。
-
原始模型:首先,我们有一个大规模的语言模型,其参数矩阵往往非常庞大,包含数十亿个参数。
总之,LoRA通过低秩适应的方法,可以在减少存储需求和加速推理过程的同时,保持模型的关键特征和性能。这使得它成为在资源受限环境下使用大型语言模型的有效策略。
QLoRA 的思路是怎么样的?
QLoRA(Quantized Low-Rank Adaptation)是一种结合了量化和低秩适应的方法,用于进一步减少大规模语言模型的计算和存储开销。它的思路可以概括如下:
-
量化参数:首先,对大规模语言模型的参数进行量化。量化是一种将浮点数参数转换为固定位数的整数或更简单表示的方法。通过减少参数位数,可以显著减少模型的存储需求和计算复杂度。
-
参数矩阵分解:在量化参数之后,QLoRA使用低秩分解的方法对量化参数矩阵进行分解。低秩分解将参数矩阵分解为较小的矩阵的乘积,从而进一步减少模型的参数量和计算复杂度。
-
低秩适应:在参数矩阵分解之后,选择保留较低秩的近似矩阵,并舍弃一些对模型性能影响较小的细节。这样可以进一步减少模型的计算需求,同时保持模型的关键特征和性能。
-
重构模型:使用低秩适应后的近似矩阵和量化参数重新构建语言模型。这样得到的模型既具有较低的参数量和计算需求,又能保持相对较高的性能。
通过结合量化和低秩适应的思路,QLoRA能够进一步减少大型语言模型的计算和存储开销。它在资源受限的环境下,尤其是移动设备等场景中,具有重要的应用价值。
QLoRA 的特点是什么?
QLoRA(Quantized Low-Rank Adaptation)具有以下几个特点:
-
量化降低存储需求:通过将参数进行量化,将浮点数参数转换为固定位数的整数或更简单的表示,从而显著减少模型的存储需求。这对于在资源受限的设备上使用大型语言模型非常有益。
-
低秩适应减少计算复杂度:通过低秩适应的方法,将量化参数矩阵分解为较小的矩阵的乘积,进一步减少模型的参数量和计算复杂度。这可以加速模型的推理过程,提高模型的效率。
-
保持关键特征和性能:虽然量化和低秩适应会舍弃一些对模型性能影响较小的细节,但它们会尽量保留模型的关键特征和性能。通过选择合适的量化位数和低秩近似矩阵,可以最大限度地保持模型的性能。
-
可扩展性和通用性:QLoRA的量化和低秩适应方法可以应用于各种大型语言模型,包括预训练的Transformer模型等。它是一种通用的技术,可以适应不同的模型架构和任务。
-
综合优化:QLoRA综合考虑了量化和低秩适应的优势,通过量化降低存储需求,再通过低秩适应减少计算复杂度,从而实现了更高效的模型。这使得QLoRA成为在资源受限环境下使用大型语言模型的有效策略。
总之,QLoRA通过量化和低秩适应的方法,可以在减少存储需求和计算复杂度的同时,保持模型的关键特征和性能。它具有高效、通用和可扩展的特点,适用于各种大型语言模型的优化。
AdaLoRA 的思路是怎么样的?
AdaLoRA(Adaptive Low-Rank Adaptation)是一种自适应的低秩适应方法,用于进一步减少大规模语言模型的计算和存储开销。它的思路可以概括如下:
-
初始低秩适应:首先,对大规模语言模型的参数进行低秩适应。低秩适应是一种将参数矩阵分解为较小的矩阵的乘积的方法,从而减少模型的参数量和计算复杂度。初始低秩适应的目的是在不损失太多性能的情况下,尽可能地减少模型的计算需求。
-
评估性能和复杂度:在进行初始低秩适应之后,评估模型的性能和计算复杂度。性能可以通过模型在验证集上的准确率等指标来衡量,而计算复杂度可以通过模型的计算量来衡量。
-
自适应调整:根据评估的结果,如果模型的性能满足要求,那么适应低秩矩阵可以作为最终模型的参数。如果模型的性能不满足要求,那么可以考虑增加低秩适应的程度,即进一步减少参数量和计算复杂度。这个过程可以通过增加低秩适应的迭代次数或增加低秩矩阵的秩来实现。
-
重构模型:使用自适应调整后的低秩矩阵重新构建语言模型。这样得到的模型既具有较低的参数量和计算需求,又能保持相对较高的性能。
通过自适应的低秩适应方法,AdaLoRA能够根据模型的性能和计算需求进行灵活调整,从而进一步减少大型语言模型的计算和存储开销。它可以根据具体任务和资源限制,自动找到一个平衡点,使模型在性能和效率之间达到最佳的平衡。
LoRA 权重是否可以合入原模型?
LoRA权重可以合并到原模型中。在使用LoRA进行低秩适应时,原始模型的参数矩阵会被分解为较小的矩阵的乘积。这些较小的矩阵可以表示为低秩矩阵的形式,其中包含了原始模型的权重信息。合并LoRA权重到原模型的过程通常涉及将低秩矩阵重新组合成原始模型的参数矩阵。这可以通过矩阵乘法等操作来实现。
合并后的模型将包含原始模型的权重信息,同时也融入了低秩适应的优化,从而在减少计算和存储开销的同时保持模型性能。需要注意的是,合并LoRA权重到原模型时,可能会有一些微小的性能损失。这是因为低秩适应过程中对参数进行了量化和近似处理,可能会损失一些细节信息。然而,通过合适的低秩适应方法和参数设置,可以最小化这种性能损失,同时获得较高的效率和较低的资源开销。
ChatGLM-6B LoRA 后的权重多大?
无法提供ChatGLM-6B模型经过LoRA微调后的具体权重大小。这是因为权重的大小会受到多种因素的影响,包括模型的架构、微调的数据集、训练策略等。
LoRA 微调优点是什么?
LoRA微调具有以下几个优点:
-
保留原模型的知识:LoRA微调是在原模型的基础上进行的,因此可以保留原模型所学到的知识和表示能力。这意味着LoRA微调的模型可以继承原模型在大规模数据上训练得到的特征提取能力和语言模型知识,从而在微调任务上表现更好。
-
减少微调时间和资源开销:由于LoRA已经对原模型进行了低秩适应,减少了参数量和计算复杂度,因此LoRA微调所需的时间和资源开销相对较小。这对于大规模语言模型的微调任务来说是非常有益的,可以加快模型的训练和推理速度,降低资源消耗。
-
提高模型泛化能力:LoRA微调通过低秩适应,对原模型进行了一定程度的正则化。这种正则化可以帮助模型更好地泛化到新的任务和数据上,减少过拟合的风险。LoRA微调的模型通常具有更好的泛化能力,能够适应不同领域和任务的需求。
-
可扩展性和灵活性:LoRA微调方法的设计可以根据具体任务和资源限制进行调整和优化。可以通过调整低秩适应的程度、迭代次数和参数设置等来平衡性能和效率。这种灵活性使得LoRA微调适用于不同规模和需求的语言模型,具有较高的可扩展性。
综上所述,LoRA微调具有保留知识、减少资源开销、提高泛化能力和灵活性等优点,使得它成为大规模语言模型微调的一种有效方法。
LoRA 微调方法为什么能加速训练?
LoRA微调方法能够加速训练的原因主要有以下几点:
-
低秩适应减少了参数量:LoRA微调使用低秩适应方法对原模型的参数进行分解,将原始的参数矩阵分解为较小的矩阵的乘积形式。这样可以大幅度减少参数量,从而减少了模型的存储需求和计算复杂度。减少的参数量意味着更少的内存占用和更快的计算速度,从而加速了训练过程。
-
降低了计算复杂度:由于LoRA微调减少了参数量,每个参数的计算量也相应减少。在训练过程中,计算参数更新和梯度传播的时间会显著减少,从而加速了训练过程。特别是在大规模语言模型中,参数量巨大,计算复杂度很高,LoRA微调可以显著减少计算开销,提高训练效率。
-
加速收敛速度:LoRA微调通过低秩适应对原模型进行了正则化,使得模型更容易收敛到较好的解。低秩适应过程中的正则化可以帮助模型更好地利用数据进行训练,减少过拟合的风险。这样可以加快模型的收敛速度,从而加速训练过程。
-
提高了计算效率:LoRA微调方法通过低秩适应减少了模型的参数量和计算复杂度,从而提高了计算效率。这意味着在相同的计算资源下,LoRA微调可以处理更大规模的数据和更复杂的任务。同时,也可以利用较少的计算资源来训练模型,从而减少了时间和成本。
综上所述,LoRA微调方法通过减少参数量、降低计算复杂度、加速收敛速度和提高计算效率等方式,能够显著加速训练过程,特别适用于大规模语言模型的微调任务。
如何在已有 LoRA 模型上继续训练?
在已有LoRA模型上继续训练可以按照以下步骤进行:
-
加载已有的LoRA模型:首先,需要加载已经训练好的LoRA模型,包括原始模型的参数和低秩适应所得到的参数。可以使用相应的深度学习框架提供的函数或方法来加载模型。
-
准备微调数据集:根据需要进行微调的任务,准备相应的微调数据集。这些数据集可以是新的标注数据,也可以是从原始训练数据中选择的子集。确保微调数据集与原始训练数据集具有一定的相似性,以便模型能够更好地泛化到新的任务上。
-
设置微调参数:根据任务需求,设置微调的超参数,包括学习率、批大小、训练轮数等。这些参数可以根据经验或者通过实验进行调整。注意,由于LoRA已经对原模型进行了低秩适应,可能需要调整学习率等参数来适应新的微调任务。
-
定义微调目标函数:根据任务类型,定义微调的目标函数。这可以是分类任务的交叉熵损失函数,回归任务的均方误差损失函数等。根据具体任务需求,可以选择合适的损失函数。
-
进行微调训练:使用微调数据集和定义的目标函数,对已有的LoRA模型进行微调训练。根据设定的超参数进行迭代训练,通过反向传播和优化算法更新模型参数。可以使用批量梯度下降、随机梯度下降等优化算法来进行模型参数的更新。
-
评估和调整:在微调训练过程中,定期评估模型在验证集上的性能。根据评估结果,可以调整超参数、微调数据集等,以进一步优化模型的性能。
-
保存微调模型:在微调训练完成后,保存微调得到的模型参数。这样就可以在后续的推理任务中使用微调后的模型。
需要注意的是,在进行微调训练时,需要根据具体任务和数据集的特点进行调整和优化。可能需要尝试不同的超参数设置、微调数据集的选择等,以获得更好的微调效果
1 大模型怎么评测?
大语言模型的评测通常涉及以下几个方面:
-
语法和流畅度:评估模型生成的文本是否符合语法规则,并且是否流畅自然。这可以通过人工评估或自动评估指标如困惑度(perplexity)来衡量。
-
语义准确性:评估模型生成的文本是否准确传达了所需的含义,并且是否避免了歧义或模棱两可的表达。这需要通过人工评估来判断,通常需要领域专家的参与。
-
上下文一致性:评估模型在生成长篇文本时是否能够保持一致的上下文逻辑和连贯性。这需要通过人工评估来检查模型生成的文本是否与前文和后文相衔接。
-
信息准确性:评估模型生成的文本中所包含的信息是否准确和可靠。这可以通过人工评估或与已知信息进行对比来判断。
-
创造性和多样性:评估模型生成的文本是否具有创造性和多样性,是否能够提供不同的观点和表达方式。这需要通过人工评估来判断。
评测大语言模型是一个复杂的过程,需要结合人工评估和自动评估指标来进行综合评价。由于大语言模型的规模和复杂性,评测结果往往需要多个评估者的共识,并且需要考虑到评估者的主观因素和评估标准的一致性。
2 大模型的honest原则是如何实现的?
大语言模型的"honest"原则是指模型在生成文本时应该保持诚实和真实,不应该编造虚假信息或误导用户。实现"honest"原则可以通过以下几种方式:
-
数据训练:使用真实和可靠的数据进行模型的训练,确保模型学习到的知识和信息与真实世界相符。数据的来源和质量对于模型的"honest"性非常重要。
-
过滤和审查:在训练数据中,可以通过过滤和审查来排除不真实或不可靠的内容。这可以通过人工审核或自动筛选算法来实现,以确保训练数据的可信度。
-
监督和调整:对模型的生成结果进行监督和调整,及时发现和纠正可能的误导或虚假信息。这可以通过人工审核、用户反馈或者自动监测来实现。
-
透明度和解释性:提供模型生成文本的解释和可追溯性,使用户能够了解模型生成文本的依据和过程。这可以通过展示模型的输入数据、模型的结构和参数等方式来实现。
-
遵循道德和法律准则:确保模型的设计和使用符合道德和法律的准则,不违背伦理和法律规定。这需要在模型的开发和应用过程中考虑到社会和伦理的因素。
需要注意的是,尽管大语言模型可以尽力遵循"honest"原则,但由于其是基于训练数据进行生成,仍然存在可能生成不准确或误导性的文本。因此,用户在使用大语言模型生成的文本时,仍需保持批判性思维,并结合其他信息和验证渠道进行判断。
3 模型如何判断回答的知识是训练过的已知的知识?
大语言模型判断回答的知识是否为训练过的已知知识,通常可以通过以下几种方式来实现:
-
训练数据:在训练大语言模型时,可以使用包含已知知识的真实数据。这些数据可以来自于可靠的来源,如百科全书、学术文献等。通过训练模型时接触到这些知识,模型可以学习到一定的知识表示和模式。
-
监督学习:可以使用人工标注的数据来进行监督学习,将已知知识标注为正确答案。在训练模型时,通过最大化与标注答案的匹配程度,模型可以学习到回答问题的知识表示和模式。
-
开放域知识库:可以利用开放域知识库,如维基百科,作为额外的训练数据。通过将知识库中的信息与模型进行交互,模型可以学习到知识的表示和检索能力。
-
过滤和筛选:在训练数据中,可以通过过滤和筛选来排除不准确或不可靠的信息。这可以通过人工审核或自动筛选算法来实现,以提高模型对已知知识的准确性。
训练这种能力需要充分的训练数据和有效的训练方法。同时,还需要进行模型的评估和调优,以确保模型能够正确理解和回答已知的知识问题。此外,定期更新训练数据和模型,以跟进新的知识和信息,也是保持模型知识更新和准确性的重要步骤。
4 奖励模型需要和基础模型一致吗?
奖励模型和基础模型在训练过程中可以是一致的,也可以是不同的。这取决于你的任务需求和优化目标。如果你希望优化一个包含多个子任务的复杂任务,那么你可能需要为每个子任务定义一个奖励模型,然后将这些奖励模型整合到一个统一的奖励函数中。这样,你可以根据任务的具体情况调整每个子任务的权重,以实现更好的性能。
另一方面,如果你的任务是单任务的,那么你可能只需要一个基础模型和一个对应的奖励模型,这两个模型可以共享相同的参数。在这种情况下,你可以通过调整奖励模型的权重来控制任务的优化方向。总之,奖励模型和基础模型的一致性取决于你的任务需求和优化目标。在实践中,你可能需要尝试不同的模型结构和奖励函数,以找到最适合你任务的解决方案。
5 RLHF 在实践过程中存在哪些不足?
RLHF(Reinforcement Learning from Human Feedback)是一种通过人类反馈进行增强学习的方法,尽管具有一定的优势,但在实践过程中仍然存在以下几个不足之处:
-
人类反馈的代价高昂:获取高质量的人类反馈通常需要大量的人力和时间成本。人类专家需要花费时间来评估模型的行为并提供准确的反馈,这可能限制了RLHF方法的可扩展性和应用范围。
-
人类反馈的主观性:人类反馈往往是主观的,不同的专家可能会有不同的意见和判断。这可能导致模型在不同专家之间的反馈上存在差异,从而影响模型的训练和性能。
-
反馈延迟和稀疏性:获取人类反馈可能存在延迟和稀疏性的问题。人类专家不可能实时监控和评估模型的每一个动作,因此模型可能需要等待一段时间才能收到反馈,这可能会导致训练的效率和效果下降。
-
错误反馈的影响:人类反馈可能存在错误或误导性的情况,这可能会对模型的训练产生负面影响。如果模型在错误的反馈指导下进行训练,可能会导致模型产生错误的行为策略。
-
缺乏探索与利用的平衡:在RLHF中,人类反馈通常用于指导模型的行为,但可能会导致模型过于依赖人类反馈而缺乏探索的能力。这可能限制了模型发现新策略和优化性能的能力。
针对这些不足,研究人员正在探索改进RLHF方法,如设计更高效的人类反馈收集机制、开发更准确的反馈评估方法、结合自适应探索策略等,以提高RLHF方法的实用性和性能。
6 如何解决人工产生的偏好数据集成本较高,很难量产问题?
解决人工产生偏好数据集成本高、难以量产的问题,可以考虑以下几种方法:
-
引入模拟数据:使用模拟数据来代替或辅助人工产生的数据。模拟数据可以通过模拟环境或模型生成,以模拟人类用户的行为和反馈。这样可以降低数据收集的成本和难度,并且可以大规模生成数据。
-
主动学习:采用主动学习的方法来优化数据收集过程。主动学习是一种主动选择样本的方法,通过选择那些对模型训练最有帮助的样本进行标注,从而减少标注的工作量。可以使用一些算法,如不确定性采样、多样性采样等,来选择最有价值的样本进行人工标注。
-
在线学习:采用在线学习的方法进行模型训练。在线学习是一种增量学习的方法,可以在模型运行的同时进行训练和优化。这样可以利用实际用户的交互数据来不断改进模型,减少对人工标注数据的依赖。
-
众包和协作:利用众包平台或协作机制来收集人工产生的偏好数据。通过将任务分发给多个人参与,可以降低每个人的负担,并且可以通过众包平台的规模效应来提高数据收集的效率。
-
数据增强和迁移学习:通过数据增强技术,如数据合成、数据扩增等,来扩充有限的人工产生数据集。此外,可以利用迁移学习的方法,将从其他相关任务或领域收集的数据应用于当前任务,以减少对人工产生数据的需求。
综合运用上述方法,可以有效降低人工产生偏好数据的成本,提高数据的量产能力,并且保证数据的质量和多样性。
7 如何解决三个阶段的训练(SFT->RM->PPO)过程较长,更新迭代较慢问题?
要解决三个阶段训练过程较长、更新迭代较慢的问题,可以考虑以下几种方法:
-
并行化训练:利用多个计算资源进行并行化训练,可以加速整个训练过程。可以通过使用多个CPU核心或GPU来并行处理不同的训练任务,从而提高训练的效率和速度。
-
分布式训练:将训练任务分发到多台机器或多个节点上进行分布式训练。通过将模型和数据分布在多个节点上,并进行并行计算和通信,可以加快训练的速度和更新的迭代。
-
优化算法改进:针对每个阶段的训练过程,可以考虑改进优化算法来加速更新迭代。例如,在SFT(Supervised Fine-Tuning)阶段,可以使用更高效的优化算法,如自适应学习率方法(Adaptive Learning Rate)或者剪枝技术来减少模型参数;在RM(Reward Modeling)阶段,可以使用更快速的模型训练算法,如快速梯度法(Fast Gradient Method)等;在PPO(Proximal Policy Optimization)阶段,可以考虑使用更高效的采样和优化方法,如并行采样、多步采样等。
-
迁移学习和预训练:利用迁移学习和预训练技术,可以利用已有的模型或数据进行初始化或预训练,从而加速训练过程。通过将已有模型的参数或特征迁移到目标模型中,可以减少目标模型的训练时间和样本需求。
-
参数调优和超参数搜索:对于每个阶段的训练过程,可以进行参数调优和超参数搜索,以找到更好的参数设置和配置。通过系统地尝试不同的参数组合和算法设定,可以找到更快速和高效的训练方式。
综合运用上述方法,可以加速三个阶段训练过程,提高更新迭代的速度和效率,从而减少训练时间和资源消耗。
8 如何解决 PPO 的训练过程同时存在4个模型(2训练,2推理),对计算资源的要求较高问题?
要解决PPO训练过程中对计算资源要求较高的问题,可以考虑以下几种方法:
-
减少模型规模:通过减少模型的规模和参数量,可以降低对计算资源的需求。可以使用模型压缩技术、剪枝算法等方法来减少模型的参数数量,从而降低计算资源的使用量。
-
降低训练频率:可以降低PPO训练的频率,减少每个训练周期的次数。例如,可以增加每个训练周期的时间间隔,或者减少每个周期中的训练步数。这样可以减少训练过程中对计算资源的占用。
-
模型并行化:利用多个计算资源进行模型并行化训练,可以加速PPO的训练过程。可以将模型参数分布到多个GPU上,并进行并行计算和通信,以提高训练的效率和速度。
-
异步训练:采用异步训练的方式,可以在多个计算资源上同时进行PPO的训练。可以使用异步优化算法,如A3C(Asynchronous Advantage Actor-Critic)等,将训练任务分发到多个线程或进程中进行并行训练,从而提高训练的效率。
-
云计算和分布式训练:利用云计算平台或分布式系统进行PPO的训练,可以充分利用大规模计算资源。可以将训练任务分发到多个计算节点上进行分布式训练,以加速训练过程。
-
参数共享和模型缓存:对于有多个模型的情况,可以考虑共享部分参数或缓存已计算的模型输出。通过共享参数和缓存计算结果,可以减少重复计算和存储,从而降低对计算资源的要求。
综合运用上述方法,可以有效降低PPO训练过程中对计算资源的要求,提高训练的效率和速度。
1 如何给LLM注入领域知识?
给LLM(低层次模型,如BERT、GPT等)注入领域知识的方法有很多。以下是一些建议:
-
数据增强:在训练过程中,可以通过添加领域相关的数据来增强模型的训练数据。这可以包括从领域相关的文本中提取示例、对现有数据进行扩充或生成新的数据。
-
迁移学习:使用预训练的LLM模型作为基础,然后在特定领域的数据上进行微调。这样可以利用预训练模型学到的通用知识,同时使其适应新领域。
-
领域专家标注:与领域专家合作,对模型的输出进行监督式标注。这可以帮助模型学习到更准确的领域知识。
-
知识图谱:将领域知识表示为知识图谱,然后让LLM模型通过学习知识图谱中的实体和关系来理解领域知识。
-
规则和启发式方法:编写领域特定的规则和启发式方法,以指导模型的学习过程。这些方法可以是基于规则的、基于案例的或基于实例的。
-
模型融合:将多个LLM模型的预测结果结合起来,以提高模型在特定领域的性能。这可以通过投票、加权平均或其他集成方法来实现。
-
元学习:训练一个元模型,使其能够在少量领域特定数据上快速适应新领域。这可以通过在线学习、模型蒸馏或其他元学习方法来实现。
-
模型解释性:使用模型解释工具(如LIME、SHAP等)来理解模型在特定领域的预测原因,从而发现潜在的知识缺失并加以补充。
-
持续学习:在模型部署后,持续收集领域特定数据并更新模型,以保持其在新数据上的性能。
-
多任务学习:通过同时训练模型在多个相关任务上的表现,可以提高模型在特定领域的泛化能力。
2 如何想要快速体验各种模型?
如果想要快速体验各种大语言模型,可以考虑以下几种方法:
-
使用预训练模型:许多大语言模型已经在大规模数据上进行了预训练,并提供了预训练好的模型参数。可以直接使用这些预训练模型进行推理,以快速体验模型的性能。常见的预训练模型包括GPT、BERT、XLNet等。
-
使用开源实现:许多大语言模型的开源实现已经在GitHub等平台上公开发布。可以根据自己的需求选择合适的开源实现,并使用提供的示例代码进行快速体验。这些开源实现通常包含了模型的训练和推理代码,可以直接使用。
-
使用云平台:许多云平台(如Google Cloud、Microsoft Azure、Amazon Web Services等)提供了大语言模型的服务。可以使用这些云平台提供的API或SDK来快速体验各种大语言模型。这些云平台通常提供了简单易用的接口,可以直接调用模型进行推理。
-
使用在线演示:一些大语言模型的研究团队或公司提供了在线演示平台,可以在网页上直接体验模型的效果。通过输入文本或选择预定义的任务,可以快速查看模型的输出结果。这种方式可以快速了解模型的性能和功能。
无论使用哪种方法,都可以快速体验各种大语言模型的效果。可以根据自己的需求和时间限制选择合适的方法,并根据体验结果进一步选择和优化模型。
3 预训练数据 Token 重复是否影响模型性能?
预训练数据中的Token重复可以对模型性能产生一定的影响,具体影响取决于重复的程度和上下文。
-
学习重复模式:如果预训练数据中存在大量的Token重复,模型可能会学习到这些重复模式,并在生成或分类任务中出现类似的重复结果。这可能导致模型在处理新数据时表现较差,缺乏多样性和创造力。
-
上下文信息不足:重复的Token可能会导致上下文信息的缺失。模型在训练过程中需要通过上下文信息来理解词语的含义和语义关系。如果重复的Token导致上下文信息不足,模型可能会在处理复杂的语义任务时遇到困难。
-
训练速度和效率:预训练数据中的Token重复可能会导致训练速度变慢,并且可能需要更多的计算资源。重复的Token会增加计算量和参数数量,从而增加训练时间和资源消耗。
尽管存在以上影响,预训练数据中的一定程度的Token重复通常是不可避免的,并且在某些情况下可能对模型性能有积极的影响。例如,一些常见的词语或短语可能会在不同的上下文中重复出现,这有助于模型更好地理解它们的含义和语义关系。在实际应用中,需要根据具体任务和数据集的特点来评估预训练数据中的Token重复对模型性能的影响,并在需要的情况下采取相应的处理措施,如数据清洗、数据增强等。
1 什么是位置编码?
位置编码是一种用于在序列数据中为每个位置添加位置信息的技术。在自然语言处理中,位置编码通常用于处理文本序列。由于传统的神经网络无法直接捕捉输入序列中的位置信息,位置编码的引入可以帮助模型更好地理解和处理序列数据。
在Transformer模型中,位置编码通过为输入序列中的每个位置分配一个固定的向量来实现。这些向量会与输入序列中的词向量相加,以融合位置信息。位置编码的设计目的是使模型能够区分不同位置的输入。
在Transformer模型中,使用了一种特殊的位置编码方式,即正弦和余弦函数的组合。位置编码的公式如下:
PE(pos, 2i) = sin(pos / 10000^(2i/dmodel)) PE(pos, 2i+1) = cos(pos / 10000^(2i/dmodel))
其中,pos表示位置,i表示维度,dmodel表示Transformer模型的隐藏层的维度。通过使用不同频率的正弦和余弦函数,位置编码可以捕捉到不同位置之间的相对距离和顺序。位置编码的加入使得模型可以根据位置信息更好地理解输入序列,从而更好地处理序列数据的顺序和相关性。
2 什么是绝对位置编码?
绝对位置编码是一种用于为序列数据中的每个位置添加绝对位置信息的技术。在自然语言处理中,绝对位置编码常用于处理文本序列,特别是在使用Transformer模型进行序列建模的任务中。
在传统的Transformer模型中,位置编码使用了正弦和余弦函数的组合来表示相对位置信息,但它并没有提供绝对位置的信息。这意味着,如果将输入序列的位置进行重新排序或删除/添加元素,模型将无法正确地理解序列的新位置。为了解决这个问题,绝对位置编码被引入到Transformer模型中。
绝对位置编码通过为每个位置分配一个唯一的向量来表示绝对位置信息。这样,无论序列中的位置如何变化,模型都能够准确地识别和理解不同位置的输入。一种常用的绝对位置编码方法是使用可训练的位置嵌入层。在这种方法中,每个位置都被映射为一个固定长度的向量,该向量可以通过训练来学习。这样,模型可以根据位置嵌入层中的向量来识别和区分不同位置的输入。
绝对位置编码的引入使得模型能够更好地处理序列数据中的绝对位置信息,从而提高了模型对序列顺序和相关性的理解能力。这对于一些需要考虑绝对位置的任务,如机器翻译、文本生成等,尤为重要。
3 什么是相对位置编码?
相对位置编码是一种用于为序列数据中的每个位置添加相对位置信息的技术。在自然语言处理中,相对位置编码常用于处理文本序列,特别是在使用Transformer模型进行序列建模的任务中。
传统的Transformer模型使用了绝对位置编码来捕捉输入序列中的位置信息,但它并没有提供相对位置的信息。相对位置编码的目的是为了让模型能够更好地理解序列中不同位置之间的相对关系和顺序。
相对位置编码的一种常见方法是使用相对位置注意力机制。在这种方法中,模型通过计算不同位置之间的相对位置偏移量,并将这些偏移量作为注意力机制的输入,以便模型能够更好地关注不同位置之间的相对关系。相对位置编码的另一种方法是使用相对位置嵌入层。在这种方法中,每个位置都被映射为一个相对位置向量,该向量表示该位置与其他位置之间的相对位置关系。这样,模型可以根据相对位置嵌入层中的向量来识别和区分不同位置之间的相对关系。
相对位置编码的引入使得模型能够更好地处理序列数据中的相对位置信息,从而提高了模型对序列顺序和相关性的理解能力。这对于一些需要考虑相对位置的任务,如问答系统、命名实体识别等,尤为重要。
4 旋转位置编码 RoPE
4.1 旋转位置编码 RoPE 思路是什么?
旋转位置编码(Rotation Position Encoding,RoPE)是一种用于为序列数据中的每个位置添加旋转位置信息的编码方法。RoPE的思路是通过引入旋转矩阵来表示位置之间的旋转关系,从而捕捉序列中位置之间的旋转模式。
传统的绝对位置编码和相对位置编码方法主要关注位置之间的线性关系,而忽略了位置之间的旋转关系。然而,在某些序列数据中,位置之间的旋转关系可能对于模型的理解和预测是重要的。例如,在一些自然语言处理任务中,单词之间的顺序可能会发生旋转,如句子重排或句子中的语法结构变化。
RoPE通过引入旋转矩阵来捕捉位置之间的旋转关系。具体而言,RoPE使用一个旋转矩阵,将每个位置的位置向量与旋转矩阵相乘,从而获得旋转后的位置向量。这样,模型可以根据旋转后的位置向量来识别和理解位置之间的旋转模式。RoPE的优势在于它能够捕捉到序列数据中位置之间的旋转关系,从而提供了更丰富的位置信息。这对于一些需要考虑位置旋转的任务,如自然语言推理、自然语言生成等,尤为重要。RoPE的引入可以帮助模型更好地理解和建模序列数据中的旋转模式,从而提高模型的性能和泛化能力。
4.2 推导一下 旋转位置编码 RoPE ?
在RoPE中,位置编码是通过将每个位置的隐藏状态向量旋转一个角度来实现的。这个角度是由位置索引和维度索引共同决定的。旋转操作是在复数平面上进行的,因此,每个隐藏状态向量被视为一个复数。
旋转位置编码的基本思想是将位置信息编码为旋转角度,这样,不同位置的隐藏状态向量在复数平面上会有不同的旋转,从而保持了序列中的相对位置信息。
 通过这种方式,RoPE能够在不增加模型参数的情况下,将位置信息编码到Transformer模型中,从而提高模型处理序列数据的能力。
通过这种方式,RoPE能够在不增加模型参数的情况下,将位置信息编码到Transformer模型中,从而提高模型处理序列数据的能力。
4.3 旋转位置编码 RoPE 有什么优点?
旋转位置编码(RoPE)是一种用于位置编码的改进方法,相比于传统的位置编码方式,RoPE具有以下优点:
-
解决位置编码的周期性问题:传统的位置编码方式(如Sinusoidal Position Encoding)存在一个固定的周期,当序列长度超过该周期时,位置编码会出现重复。这可能导致模型在处理长序列时失去对位置信息的准确理解。RoPE通过引入旋转操作,可以解决这个周期性问题,使得位置编码可以适应更长的序列。
-
更好地建模相对位置信息:传统的位置编码方式只考虑了绝对位置信息,即每个位置都有一个唯一的编码表示。然而,在某些任务中,相对位置信息对于理解序列的语义和结构非常重要。RoPE通过旋转操作,可以捕捉到相对位置信息,使得模型能够更好地建模序列中的局部关系。
-
更好的泛化能力:RoPE的旋转操作可以看作是对位置编码进行了一种数据增强操作,通过扩展位置编码的变化范围,可以提高模型的泛化能力。这对于处理不同长度的序列以及在测试时遇到未见过的序列长度非常有帮助。
总体而言,RoPE相比于传统的位置编码方式,在处理长序列、建模相对位置信息和提高泛化能力方面具有一定的优势。这些优点可以帮助模型更好地理解序列数据,并在各种自然语言处理任务中取得更好的性能。
4.4 旋转位置编码 RoPE 被哪些 LLMs 应用?
旋转位置编码(RoPE, Rotary Position Embedding)是一种在大型语言模型(LLMs)中广泛应用的位置编码方法。它主要用于Transformer模型中,以提高模型处理序列数据的能力。RoPE的主要特点是它能够将相对位置信息集成到self-attention机制中,从而提升Transformer架构的性能。
RoPE被多个大型语言模型采用,其中包括LLaMA、GLM、Baichuan、ChatGLM和Qwen等。这些模型采用RoPE的主要原因之一是它具有良好的外推性,即模型能够有效地处理在训练时未遇到的长文本或对话。这种外推性对于大型语言模型来说非常重要,因为它们通常在较小的上下文长度中进行训练,而在实际应用中,可能需要处理超出训练长度的文本。
RoPE的工作原理是通过将每个位置的隐藏状态向量旋转一个角度来引入序列中的相对位置信息。这个角度是由位置索引和维度索引共同决定的。在数学上,RoPE通过对query和key向量进行旋转矩阵变换,使得变换后的向量带有位置信息,从而在attention矩阵上表征相对位置信息。由于这种方法是基于绝对位置编码实现的相对位置编码,因此它不需要操作Attention矩阵,有了应用到线性Attention的可能性。
总的来说,旋转位置编码RoPE因其有效性和灵活性,在大型语言模型中得到了广泛的应用,特别是在处理长文本或多轮对话等任务时表现出了良好的效果。
5 长度外推问题篇
5.1 什么是长度外推问题?
长度外推问题是指在机器学习和自然语言处理中,模型被要求在输入序列的长度超出其训练范围时进行预测或生成。这种情况下,模型需要推断或生成与其训练数据中的示例长度不同的序列。
长度外推问题通常是由于训练数据的限制或资源限制而引起的。例如,在语言模型中,模型可能只能训练到一定长度的句子,但在实际应用中,需要生成更长的句子。在这种情况下,模型需要学会推断和生成超出其训练数据长度范围的内容。
解决长度外推问题的方法包括使用合适的编码器和解码器架构,使用适当的位置编码方法(如RoPE),以及训练模型时使用更大的输入序列范围。此外,还可以使用基于生成模型的方法,如生成对抗网络(GAN),来生成更长的序列。长度外推问题是自然语言处理中一个重要的挑战,对于实现更强大的语言模型和生成模型具有重要意义。
5.2 长度外推问题的解决方法有哪些?
解决长度外推问题的方法主要包括以下几种:
-
使用适当的模型架构:选择能够处理不同长度序列的模型架构。例如,Transformer模型在处理长度变化的序列时表现出色,因为它使用自注意力机制来捕捉序列中的长距离依赖关系。
-
使用适当的位置编码方法:为了帮助模型理解序列中不同位置的信息,可以使用位置编码方法,如相对位置编码(RoPE)或绝对位置编码。这些编码方法可以帮助模型推断和生成超出其训练范围的序列。
-
增加训练数据范围:如果可能,可以增加训练数据的范围,包括更长的序列示例。这样可以让模型更好地学习如何处理超出其训练范围的序列。
-
使用生成模型:生成模型如生成对抗网络(GAN)可以用于生成更长的序列。GAN模型可以通过生成器网络生成超出训练数据范围的序列,并通过判别器网络进行评估和优化。
-
增加模型容量:增加模型的容量(如增加隐藏层的大小或增加模型的参数数量)可以提高模型处理长度外推问题的能力。更大的模型容量可以更好地捕捉序列中的复杂模式和依赖关系。
-
使用迭代方法:对于超出模型训练范围的序列,可以使用迭代方法进行外推。例如,可以通过多次迭代生成序列的一部分,并将生成的部分作为下一次迭代的输入,从而逐步生成完整的序列。
这些方法可以单独或组合使用来解决长度外推问题,具体的选择取决于具体的任务和数据。
6 ALiBi (Attention with Linear Biases)
6.1 ALiBi (Attention with Linear Biases) 思路是什么?
ALiBi(Attention with Linear Biases)是一种用于处理长度外推问题的方法,它通过引入线性偏置来改进自注意力机制(Self-Attention)。自注意力机制是一种用于捕捉序列中不同位置之间依赖关系的机制,它通过计算每个位置与其他位置的注意力权重来加权聚合信息。然而,自注意力机制在处理长度变化的序列时存在一些问题,例如在处理长序列时,注意力权重可能变得过于稀疏或集中,导致模型无法有效地捕捉长距离依赖关系。
ALiBi的思路是在自注意力机制中引入线性偏置,以增强模型对长距离依赖关系的建模能力。具体来说,ALiBi使用线性映射将输入序列转换为一个低维度的特征向量,然后通过计算特征向量之间的内积来计算注意力权重。这样做的好处是,线性映射可以将输入序列的信息压缩到一个更紧凑的表示中,从而减少模型对长距离依赖关系的建模难度。
ALiBi还引入了一个线性偏置向量,用于调整注意力权重的分布。通过调整偏置向量的值,可以控制注意力权重的稀疏性和集中性,从而更好地适应不同长度的序列。这种线性偏置的引入可以帮助模型更好地处理长度外推问题,提高模型在处理长序列时的性能。
总的来说,ALiBi通过引入线性偏置来改进自注意力机制,增强模型对长距离依赖关系的建模能力,从而提高模型在处理长度外推问题时的性能。
6.2 ALiBi (Attention with Linear Biases) 的偏置矩阵有什么作用?

在ALiBi中,偏置矩阵是一个用于调整注意力权重的矩阵。具体来说,偏置矩阵是一个形状为(L,L)的矩阵,其中L是输入序列的长度。矩阵中的每个元素都是一个偏置值,用于调整注意力权重的分布。偏置矩阵的作用是在计算注意力权重时引入一个额外的偏置项,从而调整注意力的分布。通过调整偏置矩阵的值,可以控制注意力权重的稀疏性和集中性,以更好地适应不同长度的序列。
具体来说,偏置矩阵通过与注意力权重矩阵相乘,对注意力权重进行调整。偏置矩阵中的每个元素与注意力权重矩阵中的对应元素相乘,可以增加或减小该位置的注意力权重。通过调整偏置矩阵的值,可以控制不同位置的注意力权重,使其更加稀疏或集中。偏置矩阵的引入可以帮助模型更好地处理长度外推问题。通过调整注意力权重的分布,模型可以更好地适应不同长度的序列,并更好地捕捉序列中的长距离依赖关系。偏置矩阵提供了一种灵活的方式来控制注意力权重的调整,从而提高模型在处理长度外推问题时的性能。
6.3 ALiBi (Attention with Linear Biases) 有什么优点?
ALiBi(Attention with Linear Biases)具有以下几个优点:
-
改善了自注意力机制的性能:ALiBi通过引入线性偏置来改进自注意力机制,增强了模型对长距离依赖关系的建模能力。这样可以更好地捕捉序列中的长距离依赖关系,提高模型的性能。
-
灵活性:ALiBi中的偏置矩阵提供了一种灵活的方式来调整注意力权重的分布。通过调整偏置矩阵的值,可以控制注意力权重的稀疏性和集中性,以更好地适应不同长度的序列。这种灵活性使得ALiBi能够适应不同的任务和数据特点。
-
减少参数数量:ALiBi使用线性映射将输入序列转换为一个低维度的特征向量,从而减少了模型的参数数量。这样可以降低模型的复杂度,减少计算和存储成本,并提高模型的效率。
-
通用性:ALiBi可以应用于各种长度外推问题,如序列预测、机器翻译等。它的思路和方法可以适用于不同领域和任务,具有一定的通用性。
综上所述,ALiBi通过改进自注意力机制,提供了一种灵活的方式来调整注意力权重的分布,减少参数数量,并具有一定的通用性。这些优点使得ALiBi在处理长度外推问题时具有较好的性能和适应性。
Byte-Pair Encoding(BPE) 如何构建词典?
Byte-Pair Encoding(BPE)是一种常用的无监督分词方法,用于将文本分解为子词或字符级别的单位。BPE的词典构建过程如下:
-
初始化词典:将每个字符视为一个初始的词。例如,对于输入文本"hello world",初始词典可以包含{'h', 'e', 'l', 'o', 'w', 'r', 'd'}。
-
统计词频:对于每个词,统计其在文本中的频率。例如,在"hello world"中,'h'出现1次,'e'出现1次,'l'出现3次,'o'出现2次,'w'出现1次,'r'出现1次,'d'出现1次。
-
合并频率最高的词对:在每次迭代中,选择频率最高的词对进行合并。合并的方式是将两个词连接起来,并用一个特殊的符号(如"_")分隔。例如,在初始词典中,选择频率最高的词对"l"和"l",将它们合并为"ll",更新词典为{'h', 'e', 'll', 'o', 'w', 'r', 'd'}。
-
更新词频:更新合并后的词频。对于合并的词,统计其在文本中的频率。例如,在"hello world"中,'h'出现1次,'e'出现1次,'ll'出现3次,'o'出现2次,'w'出现1次,'r'出现1次,'d'出现1次。
-
重复步骤3和4:重复步骤3和4,直到达到预设的词典大小或者满足其他停止条件。每次迭代都会合并频率最高的词对,并更新词频。
最终得到的词典即为BPE的词典。通过BPE算法,可以将文本分解为多个子词,其中一些子词可能是常见的词汇,而其他子词则是根据输入文本的特点生成的。这种方式可以更好地处理未登录词和稀有词,并提高模型对复杂词汇和短语的处理能力。
WordPiece 与 BPE 异同点是什么?
WordPiece和BPE(Byte-Pair Encoding)都是常用的无监督分词方法,它们有一些相似之处,但也存在一些差异。
-
分词目标:WordPiece和BPE都旨在将文本分解为子词或字符级别的单位,以便更好地处理未登录词和稀有词,提高模型对复杂词汇和短语的处理能力。
-
无监督学习:WordPiece和BPE都是无监督学习方法,不需要依赖外部的标注数据,而是通过分析输入文本自动构建词典。
-
拆分策略:WordPiece采用贪婪的自顶向下的拆分策略,将词汇表中的词分解为更小的子词。它使用最大似然估计来确定最佳的分割点,并通过词频来更新词典。BPE则采用自底向上的拆分策略,通过合并频率最高的词对来构建词典。它使用词频来选择合并的词对,并通过更新词频来更新词典。
-
分割粒度:WordPiece通常将词分解为更小的子词,例如将"running"分解为"run"和"##ning"。这些子词通常以"##"前缀表示它们是一个词的一部分。BPE则将词分解为更小的子词或字符级别的单位。它不使用特殊的前缀或后缀来表示子词。
-
处理未登录词:WordPiece和BPE在处理未登录词时有所不同。WordPiece通常将未登录词分解为更小的子词,以便模型可以更好地处理它们。而BPE则将未登录词作为单独的词处理,不进行进一步的拆分。
总体而言,WordPiece和BPE都是有效的分词方法,选择使用哪种方法取决于具体的任务需求和语料特点。
简单介绍一下 SentencePiece 思路?
SentencePiece是一种基于BPE算法的分词工具,旨在将文本分解为子词或字符级别的单位。与传统的BPE算法不同,SentencePiece引入了一种更灵活的训练方式,可以根据不同任务和语料库的需求进行自定义。SentencePiece的思路如下:
-
初始化词典:将每个字符视为一个初始的词。例如,对于输入文本"hello world",初始词典可以包含{'h', 'e', 'l', 'o', 'w', 'r', 'd'}。
-
统计词频:对于每个词,统计其在文本中的频率。例如,在"hello world"中,'h'出现1次,'e'出现1次,'l'出现3次,'o'出现2次,'w'出现1次,'r'出现1次,'d'出现1次。
-
合并频率最高的词对:在每次迭代中,选择频率最高的词对进行合并。合并的方式是将两个词连接起来,并用一个特殊的符号(如"_")分隔。例如,在初始词典中,选择频率最高的词对"l"和"l",将它们合并为"ll",更新词典为{'h', 'e', 'll', 'o', 'w', 'r', 'd'}。
-
更新词频:更新合并后的词频。对于合并的词,统计其在文本中的频率。例如,在"hello world"中,'h'出现1次,'e'出现1次,'ll'出现3次,'o'出现2次,'w'出现1次,'r'出现1次,'d'出现1次。
-
重复步骤3和4:重复步骤3和4,直到达到预设的词典大小或者满足其他停止条件。每次迭代都会合并频率最高的词对,并更新词频。
-
训练模型:根据得到的词典,训练一个分词模型。模型可以根据需求选择将文本分解为子词或字符级别的单位。
通过SentencePiece,可以根据不同任务和语料库的需求,自定义分词模型。它可以更好地处理未登录词和稀有词,提高模型对复杂词汇和短语的处理能力。同时,SentencePiece还支持多种语言和编码方式,可以广泛应用于自然语言处理任务中。
不同大模型 LLMs 的分词方式
大模型语言模型(Large Language Models,LLMs)通常采用不同的分词方式,这些方式可以根据任务和语料库的不同进行调整。以下是一些常见的大模型LLMs的分词方式的举例:
-
基于规则的分词:这种分词方式使用预定义的规则和模式来切分文本。例如,可以使用空格、标点符号或特定的字符来确定词语的边界。这种方法简单直接,但对于复杂的语言和文本结构可能不够准确。
-
基于统计的分词:这种分词方式使用统计模型来确定词语的边界。通常会使用大量的标注数据来训练模型,并根据词语的频率和上下文来进行切分。这种方法相对准确,但对于未见过的词语或特定领域的术语可能不够准确。
-
基于深度学习的分词:这种分词方式使用深度学习模型,如循环神经网络(RNN)或Transformer模型,来进行分词。这些模型可以学习文本的上下文信息,并根据语义和语法规则来进行切分。这种方法可以处理复杂的语言结构和未见过的词语,但需要大量的训练数据和计算资源。
-
基于预训练模型的分词:最近的研究表明,使用预训练的语言模型,如BERT、GPT等,可以在分词任务上取得很好的效果。这些模型在大规模的文本数据上进行预训练,并能够学习到丰富的语言表示。在具体的分词任务中,可以通过在预训练模型上进行微调来进行分词。这种方法具有较高的准确性和泛化能力。
-
基于词典的分词:这是最常见的分词方式之一,使用一个预先构建好的词典来将文本分解为单词。例如,BERT模型使用WordPiece分词器,将文本分解为词片段(subword units),并在词典中查找匹配的词片段。
-
基于字符的分词:这种方式将文本分解为单个字符或者字符级别的单位。例如,GPT模型使用字节对编码(Byte Pair Encoding,BPE)算法,将文本分解为字符或字符片段。
-
基于音节的分词:对于一些语言,特别是拼音文字系统,基于音节的分词方式更为常见。这种方式将文本分解为音节或音节级别的单位。例如,对于中文,可以使用基于音节的分词器将文本分解为音节。
-
基于规则的分词:有些语言具有明确的分词规则,可以根据这些规则将文本分解为单词。例如,日语中的分词可以基于汉字辞书或者语法规则进行。
-
基于统计的分词:这种方式使用统计模型来判断文本中的分词边界。例如,隐马尔可夫模型(Hidden Markov Model,HMM)可以通过训练来预测最可能的分词边界。
需要注意的是,不同的大模型LLMs可能在分词方式上有所差异,具体的实现和效果可能因模型的结构、训练数据和任务设置而有所不同。甚至在同一个模型中,可以根据任务和语料库的需求进行调整。这些分词方式的选择会对模型的性能和效果产生影响,因此需要根据具体情况进行选择和调整。
Layer Norm 的计算公式
Layer Norm(层归一化)是一种用于神经网络中的归一化技术,用于提高模型的训练效果和泛化能力。



RMS Norm 的计算公式


RMS Norm 的作用是通过计算输入 X 的均方根,将每个样本的特征进行归一化,使得特征在不同样本之间具有相似的尺度,有助于提高模型的训练效果和泛化能力。RMS Norm 通常用于优化器中,例如在 AdamW 优化器中,它被用作权重衰减的一种形式。
RMS Norm 相比于 Layer Norm 有什么特点?
RMS Norm(Root Mean Square Norm)和 Layer Norm 是两种常用的归一化方法,它们在实现上有一些不同之处。
-
计算方式:RMS Norm 是通过计算输入数据的平方均值的平方根来进行归一化,而 Layer Norm 是通过计算输入数据在每个样本中的平均值和方差来进行归一化。
-
归一化范围:RMS Norm 是对整个输入数据进行归一化,而 Layer Norm 是对每个样本进行归一化。
-
归一化位置:RMS Norm 通常应用于循环神经网络(RNN)中的隐藏状态,而 Layer Norm 通常应用于卷积神经网络(CNN)或全连接层中。
-
归一化效果:RMS Norm 在处理长序列数据时可能会出现梯度消失或梯度爆炸的问题,而 Layer Norm 能够更好地处理这些问题。
综上所述,RMS Norm 和 Layer Norm 在计算方式、归一化范围、归一化位置和归一化效果等方面存在一些差异,适用于不同的神经网络结构和任务。选择哪种归一化方法应根据具体情况进行评估和选择。
Deep Norm 思路
Deep Norm 是一种基于归一化的深度学习模型优化方法,其思路是通过在深度神经网络中引入多层归一化操作,以改善模型的训练和泛化性能。
Deep Norm 的主要思想是在网络的每一层之间插入归一化层,以减小输入数据的分布差异,从而加速收敛并提高模型的泛化能力。与传统的批归一化(Batch Normalization)不同,Deep Norm 在每一层都进行归一化,而不是仅在特定层进行。
Deep Norm 的具体步骤如下:
-
输入数据:将输入数据传递给网络的第一层。
-
归一化层:在网络的每一层之间插入归一化层。归一化层的作用是将每层的输入数据进行归一化,使其均值为0,方差为1。这可以减小数据的分布差异,有助于提高模型的稳定性和泛化性能。
-
激活函数:在归一化层之后应用激活函数,以引入非线性变换。
-
下一层:将经过归一化和激活函数处理的数据传递给网络的下一层。
通过在每一层引入归一化操作,Deep Norm 可以有效地解决深度神经网络中的梯度消失和梯度爆炸问题,并提高模型的收敛速度和泛化性能。此外,Deep Norm 还可以减少对学习率的敏感性,使得模型更容易优化。
需要注意的是,Deep Norm 需要在训练过程中对每一层的均值和方差进行估计,可以使用滑动平均等方法来更新归一化层的参数。在测试阶段,可以使用训练阶段估计的均值和方差进行归一化。
总而言之,Deep Norm 是一种通过在深度神经网络中引入多层归一化操作来优化模型的方法,可以改善模型的训练和泛化性能。
Deep Norm 代码实现
Deep Norm 的代码实现可以基于 PyTorch 框架来完成。以下是一个简单的 Deep Norm 的代码示例:
- import torch
- import torch.nn as nn
-
- class DeepNorm(nn.Module):
- def __init__(self, input_dim, hidden_dims, output_dim):
- super(DeepNorm, self).__init__()
-
- self.layers = nn.ModuleList()
- self.norm_layers = nn.ModuleList()
-
- # 添加隐藏层和归一化层
- for i, hidden_dim in enumerate(hidden_dims):
- self.layers.append(nn.Linear(input_dim, hidden_dim))
- self.norm_layers.append(nn.LayerNorm(hidden_dim))
- input_dim = hidden_dim
-
- # 添加输出层
- self.output_layer = nn.Linear(input_dim, output_dim)
-
- def forward(self, x):
- for layer, norm_layer in zip(self.layers, self.norm_layers):
- x = layer(x)
- x = norm_layer(x)
- x = torch.relu(x)
-
- x = self.output_layer(x)
- return x
-
- # 创建一个 DeepNorm 模型实例
- input_dim = 100
- hidden_dims = [64, 32]
- output_dim = 10
- model = DeepNorm(input_dim, hidden_dims, output_dim)
-
- # 使用模型进行训练和预测
- input_data = torch.randn(32, input_dim)
- output = model(input_data)
在这个示例中,我们定义了一个 DeepNorm 类,其中包含了多个隐藏层和归一化层。在 forward 方法中,我们依次对输入数据进行线性变换、归一化和激活函数处理,并通过输出层得到最终的预测结果。
需要注意的是,在实际使用中,可以根据具体任务的需求来调整模型的结构和参数设置。此外,还可以使用其他归一化方法,如 Layer Norm 或 Batch Norm,根据实际情况进行选择和实现。
Deep Norm 有什么优点?
Deep Norm 有以下几个优点:
-
改善梯度传播:Deep Norm 在每一层都引入了归一化操作,可以有效地解决深度神经网络中的梯度消失和梯度爆炸问题。通过减小输入数据的分布差异,Deep Norm 可以使得梯度更加稳定,并加速模型的收敛速度。
-
提高泛化能力:Deep Norm 的归一化操作有助于提高模型的泛化能力。归一化可以减小数据的分布差异,使得模型更容易学习到数据的共性特征,从而提高模型对未见数据的预测能力。
-
减少对学习率的敏感性:Deep Norm 的归一化操作可以减少对学习率的敏感性。通过将输入数据归一化到相同的尺度,Deep Norm 可以使得模型的训练更加稳定,减少了对学习率的调整需求。
-
网络结构更简洁:Deep Norm 可以将归一化操作嵌入到网络的每一层中,而不需要额外的归一化层。这使得网络结构更加简洁,减少了模型参数的数量,降低了计算和存储成本。
-
提高模型的可解释性:Deep Norm 的归一化操作可以使得模型的输出具有更好的可解释性。通过将输入数据归一化到均值为0,方差为1的范围内,Deep Norm 可以使得模型输出的数值更易于理解和解释。
综上所述,Deep Norm 通过引入多层归一化操作,可以改善梯度传播、提高泛化能力、减少对学习率的敏感性,同时还能简化网络结构和提高模型的可解释性。这些优点使得 Deep Norm 成为一种有效的深度学习模型优化方法。
Layer normalization 在 LLMs 中的不同位置有什么区别?
在大语言模型(Large Language Models)中,Layer Norm(层归一化)可以应用在不同位置,包括输入层、输出层和中间隐藏层。这些位置的归一化有一些区别:
-
输入层归一化:在输入层应用 Layer Norm 可以将输入的特征进行归一化,使得输入数据的分布更加稳定。这有助于减少不同样本之间的分布差异,提高模型的泛化能力。
-
输出层归一化:在输出层应用 Layer Norm 可以将输出结果进行归一化,使得输出结果的分布更加稳定。这有助于减小输出结果的方差,提高模型的稳定性和预测准确性。
-
中间隐藏层归一化:在中间隐藏层应用 Layer Norm 可以在每个隐藏层之间进行归一化操作,有助于解决深度神经网络中的梯度消失和梯度爆炸问题。通过减小输入数据的分布差异,Layer Norm 可以使得梯度更加稳定,并加速模型的收敛速度。
总的来说,Layer Norm 在大语言模型中的不同位置应用可以解决不同的问题。输入层归一化可以提高模型的泛化能力,输出层归一化可以提高模型的稳定性和预测准确性,而中间隐藏层归一化可以改善梯度传播,加速模型的收敛速度。具体应用 Layer Norm 的位置需要根据具体任务和模型的需求进行选择。
LLMs 各模型分别用了哪种 Layer normalization?
不同的大语言模型(LLMs)可能会使用不同的层归一化方法,以下是一些常见的层归一化方法在大语言模型中的应用:
-
BERT(Bidirectional Encoder Representations from Transformers):BERT使用的是Transformer中的层归一化方法,即在每个Transformer编码层中应用Layer Normalization。
-
GPT(Generative Pre-trained Transformer):GPT系列模型通常使用的是GPT-Norm,它是一种变种的层归一化方法。GPT-Norm在每个Transformer解码层的每个子层(自注意力、前馈神经网络)之后应用Layer Normalization。
-
XLNet:XLNet使用的是两种不同的层归一化方法,即Token-wise层归一化和Segment-wise层归一化。Token-wise层归一化是在每个Transformer编码层中应用Layer Normalization,而Segment-wise层归一化是在每个Transformer解码层的自注意力机制之后应用Layer Normalization。
-
RoBERTa:RoBERTa是对BERT模型的改进,它也使用的是Transformer中的层归一化方法,即在每个Transformer编码层中应用Layer Normalization。
需要注意的是,虽然这些大语言模型使用了不同的层归一化方法,但它们的目的都是为了提高模型的训练效果和泛化能力。具体选择哪种层归一化方法取决于模型的设计和任务的需求。
FFN块 计算公式
在Transformer模型中,FFN(Feed-Forward Network)块通常指的是在编码器(Encoder)和解码器(Decoder)中的一个全连接前馈网络子结构。FFN块位于自注意力层(Self-Attention Layer)之后,用于对自注意力层的输出进行进一步的加工处理。FFN块的作用是引入非线性,允许模型学习更复杂的特征表示。
一个标准的FFN块通常包含两个全连接层(也称为线性层),中间有一个激活函数。第一个全连接层通常有较大的隐藏层尺寸,用于对输入进行维度扩展;第二个全连接层则将维度还原回与输入相同的尺寸。


GeLU 计算公式
GeLU(Gaussian Error Linear Unit)是一种激活函数,常用于神经网络中的非线性变换。它在Transformer模型中广泛应用于FFN(Feed-Forward Network)块。下面是GeLU的计算公式:
假设输入是一个标量 x,GeLU的计算公式如下:
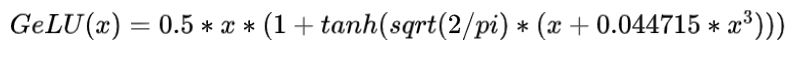
其中,tanh() 是双曲正切函数,sqrt() 是平方根函数,pi 是圆周率。
GeLU函数的特点是在接近零的区域表现得类似于线性函数,而在远离零的区域则表现出非线性的特性。相比于其他常用的激活函数(如ReLU),GeLU函数在某些情况下能够提供更好的性能和更快的收敛速度。
需要注意的是,GeLU函数的计算复杂度较高,可能会增加模型的计算开销。因此,在实际应用中,也可以根据具体情况选择其他的激活函数来代替GeLU函数。
Swish 计算公式
Swish是一种激活函数,它在深度学习中常用于神经网络的非线性变换。Swish函数的计算公式如下:
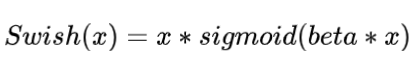
其中,sigmoid() 是Sigmoid函数,x 是输入,beta 是一个可调节的超参数。
Swish函数的特点是在接近零的区域表现得类似于线性函数,而在远离零的区域则表现出非线性的特性。相比于其他常用的激活函数(如ReLU、tanh等),Swish函数在某些情况下能够提供更好的性能和更快的收敛速度。
Swish函数的设计灵感来自于自动搜索算法,它通过引入一个可调节的超参数来增加非线性程度。当beta为0时,Swish函数退化为线性函数;当beta趋近于无穷大时,Swish函数趋近于ReLU函数。
需要注意的是,Swish函数相对于其他激活函数来说计算开销较大,因为它需要进行Sigmoid运算。因此,在实际应用中,也可以根据具体情况选择其他的激活函数来代替Swish函数。
使用 GLU 线性门控单元的 FFN 块计算公式
使用GLU(Gated Linear Unit)线性门控单元的FFN(Feed-Forward Network)块是Transformer模型中常用的结构之一。它通过引入门控机制来增强模型的非线性能力。下面是使用GLU线性门控单元的FFN块的计算公式:
假设输入是一个向量 x,GLU线性门控单元的计算公式如下:
![]()
(1)其中,sigmoid() 是Sigmoid函数, 是一个可学习的权重矩阵。
在公式(1)中,首先将输入向量 x 通过一个全连接层(线性变换)得到一个与 x 维度相同的向量,然后将该向量通过Sigmoid函数进行激活。这个Sigmoid函数的输出称为门控向量,用来控制输入向量 x 的元素是否被激活。最后,将门控向量与输入向量 x 逐元素相乘,得到最终的输出向量。
GLU线性门控单元的特点是能够对输入向量进行选择性地激活,从而增强模型的表达能力。它在Transformer模型的编码器和解码器中广泛应用,用于对输入向量进行非线性变换和特征提取。
需要注意的是,GLU线性门控单元的计算复杂度较高,可能会增加模型的计算开销。因此,在实际应用中,也可以根据具体情况选择其他的非线性变换方式来代替GLU线性门控单元。
使用 GeLU 的 GLU 块计算公式
使用GeLU作为激活函数的GLU块的计算公式如下:
其中,GeLU() 是Gaussian Error Linear Unit的激活函数,W_1 是一个可学习的权重矩阵。
在公式(1)中,首先将输入向量 x 通过一个全连接层(线性变换)得到一个与 x 维度相同的向量,然后将该向量作为输入传递给GeLU激活函数进行非线性变换。最后,将GeLU激活函数的输出与输入向量 x 逐元素相乘,得到最终的输出向量。
GeLU激活函数的计算公式如下:
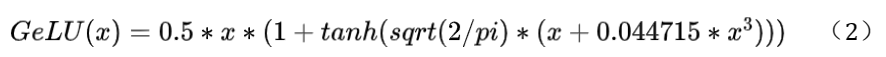
其中,tanh() 是双曲正切函数,sqrt() 是平方根函数,pi 是圆周率。
在公式(2)中,GeLU函数首先对输入向量 x 进行一个非线性变换,然后通过一系列的数学运算得到最终的输出值。
使用GeLU作为GLU块的激活函数可以增强模型的非线性能力,并在某些情况下提供更好的性能和更快的收敛速度。这种结构常用于Transformer模型中的编码器和解码器,用于对输入向量进行非线性变换和特征提取。
需要注意的是,GLU块和GeLU激活函数是两个不同的概念,它们在计算公式和应用场景上有所区别。在实际应用中,可以根据具体情况选择合适的激活函数来代替GeLU或GLU。
使用 Swish 的 GLU 块计算公式
使用Swish作为激活函数的GLU块的计算公式如下:
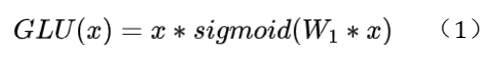
其中,sigmoid() 是Sigmoid函数,W_1 是一个可学习的权重矩阵。
在公式(1)中,首先将输入向量 x 通过一个全连接层(线性变换)得到一个与 x 维度相同的向量,然后将该向量通过Sigmoid函数进行激活。这个Sigmoid函数的输出称为门控向量,用来控制输入向量 x 的元素是否被激活。最后,将门控向量与输入向量 x 逐元素相乘,得到最终的输出向量。
Swish激活函数的计算公式如下:
![]()
其中,sigmoid() 是Sigmoid函数,beta 是一个可学习的参数。
在公式(2)中,Swish函数首先对输入向量 x 进行一个非线性变换,然后通过Sigmoid函数进行激活,并将该激活结果与输入向量 x 逐元素相乘,得到最终的输出值。
使用Swish作为GLU块的激活函数可以增强模型的非线性能力,并在某些情况下提供更好的性能和更快的收敛速度。GLU块常用于Transformer模型中的编码器和解码器,用于对输入向量进行非线性变换和特征提取。
需要注意的是,GLU块和Swish激活函数是两个不同的概念,它们在计算公式和应用场景上有所区别。在实际应用中,可以根据具体情况选择合适的激活函数来代替Swish或GLU。
1 为什么大模型推理时显存涨的那么多还一直占着?
大语言模型进行推理时,显存涨得很多且一直占着显存不释放的原因主要有以下几点:
-
模型参数占用显存:大语言模型通常具有巨大的参数量,这些参数需要存储在显存中以供推理使用。因此,在推理过程中,模型参数会占用相当大的显存空间。
-
输入数据占用显存:进行推理时,需要将输入数据加载到显存中。对于大语言模型而言,输入数据通常也会占用较大的显存空间,尤其是对于较长的文本输入。
-
中间计算结果占用显存:在推理过程中,模型会进行一系列的计算操作,生成中间结果。这些中间结果也需要存储在显存中,以便后续计算使用。对于大语言模型而言,中间计算结果可能会占用较多的显存空间。
-
内存管理策略:某些深度学习框架在推理时采用了一种延迟释放显存的策略,即显存不会立即释放,而是保留一段时间以备后续使用。这种策略可以减少显存的分配和释放频率,提高推理效率,但也会导致显存一直占用的现象。
需要注意的是,显存的占用情况可能会受到硬件设备、深度学习框架和模型实现的影响。不同的环境和设置可能会导致显存占用的差异。如果显存占用过多导致资源不足或性能下降,可以考虑调整模型的批量大小、优化显存分配策略或使用更高性能的硬件设备来解决问题。
2 大模型在gpu和cpu上推理速度如何?
大语言模型在GPU和CPU上进行推理的速度存在显著差异。一般情况下,GPU在进行深度学习推理任务时具有更高的计算性能,因此大语言模型在GPU上的推理速度通常会比在CPU上更快。以下是GPU和CPU在大语言模型推理速度方面的一些特点:
-
GPU推理速度快:GPU具有大量的并行计算单元,可以同时处理多个计算任务。对于大语言模型而言,GPU可以更高效地执行矩阵运算和神经网络计算,从而加速推理过程。
-
CPU推理速度相对较慢:相较于GPU,CPU的计算能力较弱,主要用于通用计算任务。虽然CPU也可以执行大语言模型的推理任务,但由于计算能力有限,推理速度通常会较慢。
-
使用GPU加速推理:为了充分利用GPU的计算能力,通常会使用深度学习框架提供的GPU加速功能,如CUDA或OpenCL。这些加速库可以将计算任务分配给GPU并利用其并行计算能力,从而加快大语言模型的推理速度。
需要注意的是,推理速度还受到模型大小、输入数据大小、计算操作的复杂度以及硬件设备的性能等因素的影响。因此,具体的推理速度会因具体情况而异。一般来说,使用GPU进行大语言模型的推理可以获得更快的速度。
3 推理速度上,int8和fp16比起来怎么样?
在大语言模型的推理速度上,使用INT8(8位整数量化)和FP16(半精度浮点数)相对于FP32(单精度浮点数)可以带来一定的加速效果。这是因为INT8和FP16的数据类型在表示数据时所需的内存和计算资源较少,从而可以加快推理速度。
具体来说,INT8在相同的内存空间下可以存储更多的数据,从而可以在相同的计算资源下进行更多的并行计算。这可以提高每秒推理操作数(Operations Per Second,OPS)的数量,加速推理速度。FP16在相对较小的数据范围内进行计算,因此在相同的计算资源下可以执行更多的计算操作。
虽然FP16的精度相对较低,但对于某些应用场景,如图像处理和语音识别等,FP16的精度已经足够满足需求。需要注意的是,INT8和FP16的加速效果可能会受到硬件设备的支持程度和具体实现的影响。某些硬件设备可能对INT8和FP16有更好的优化支持,从而进一步提高推理速度。综上所述,使用INT8和FP16数据类型可以在大语言模型的推理过程中提高推理速度,但需要根据具体场景和硬件设备的支持情况进行评估和选择。
4 大模型有推理能力吗?
大语言模型具备推理能力。推理是指在训练阶段之后,使用已经训练好的模型对新的输入数据进行预测、生成或分类等任务。
大语言模型可以通过输入一段文本或问题,然后生成相应的回答或补全文本。大语言模型通常基于循环神经网络(RNN)或变种(如长短时记忆网络LSTM或门控循环单元GRU)等结构构建,通过学习大量的文本数据,模型可以捕捉到语言的规律和模式。这使得大语言模型能够对输入的文本进行理解和推理,生成合理的回答或补全。
例如,GPT(Generative Pre-trained Transformer)模型是一种大型的预训练语言模型,它通过预训练的方式学习大规模的文本数据,然后可以在推理阶段生成连贯、合理的文本。这种模型可以用于自然语言处理任务,如文本生成、机器翻译、对话系统等。需要注意的是,大语言模型的推理能力是基于其训练数据的统计规律和模式,因此在面对新颖、复杂或特殊的输入时,可能会出现推理错误或生成不准确的结果。此外,大语言模型的推理能力也受到模型的大小、训练数据的质量和数量、推理算法等因素的影响。
5 大模型生成时的参数怎么设置?
在大语言模型进行推理时,参数设置通常包括以下几个方面:
-
模型选择:选择适合推理任务的模型,如循环神经网络(RNN)、长短时记忆网络(LSTM)、门控循环单元(GRU)或变种的Transformer等。不同的模型在推理任务上可能有不同的效果。
-
模型加载:加载预训练好的模型参数,这些参数可以是在大规模文本数据上进行预训练得到的。预训练模型的选择应根据任务和数据集的特点来确定。
-
推理算法:选择合适的推理算法,如贪婪搜索、束搜索(beam search)或采样方法等。贪婪搜索只考虑当前最有可能的输出,束搜索会考虑多个候选输出,采样方法会根据概率分布进行随机采样。
-
温度参数:在生成文本时,可以通过调整温度参数来控制生成的文本的多样性。较高的温度会增加生成文本的随机性和多样性,而较低的温度会使生成文本更加确定和一致。
-
推理长度:确定生成文本的长度限制,可以设置生成的最大长度或生成的最小长度等。
-
其他参数:根据具体任务和需求,可能还需要设置其他参数,如生成的起始文本、生成的批次大小等。
以上参数设置需要根据具体任务和数据集的特点进行调整和优化。通常情况下,可以通过实验和调参来找到最佳的参数组合,以获得较好的推理效果。同时,还可以通过人工评估和自动评估指标来评估生成文本的质量和准确性,进一步优化参数设置。
6 省内存的大语言模型训练/微调/推理方法
以下是一些常见的方法:
-
参数共享(Parameter Sharing):通过共享模型中的参数,可以减少内存占用。例如,可以在不同的位置共享相同的嵌入层或注意力机制。
-
梯度累积(Gradient Accumulation):在训练过程中,将多个小批次的梯度累积起来,然后进行一次参数更新。这样可以减少每个小批次的内存需求,特别适用于GPU内存较小的情况。
-
梯度裁剪(Gradient Clipping):通过限制梯度的大小,可以避免梯度爆炸的问题,从而减少内存使用。
-
分布式训练(Distributed Training):将训练过程分布到多台机器或多个设备上,可以减少单个设备的内存占用。分布式训练还可以加速训练过程。
-
量化(Quantization):将模型参数从高精度表示(如FP32)转换为低精度表示(如INT8或FP16),可以减少内存占用。量化方法可以通过减少参数位数或使用整数表示来实现。
-
剪枝(Pruning):通过去除冗余或不重要的模型参数,可以减少模型的内存占用。剪枝方法可以根据参数的重要性进行选择,从而保持模型性能的同时减少内存需求。
-
蒸馏(Knowledge Distillation):使用较小的模型(教师模型)来指导训练较大的模型(学生模型),可以从教师模型中提取知识,减少内存占用。
-
分块处理(Chunking):将输入数据或模型分成较小的块进行处理,可以减少内存需求。例如,在推理过程中,可以将较长的输入序列分成多个较短的子序列进行处理。
这些方法可以结合使用,根据具体场景和需求进行选择和调整。同时,不同的方法可能对不同的模型和任务有不同的效果,因此需要进行实验和评估。
7 如何让大模型输出合规化?
要让大模型输出合规化,可以采取以下方法:
-
数据清理和预处理:在进行模型训练之前,对输入数据进行清理和预处理,以确保数据符合合规要求。这可能包括去除敏感信息、匿名化处理、数据脱敏等操作。
-
引入合规性约束:在模型训练过程中,可以引入合规性约束,以确保模型输出符合法律和道德要求。例如,可以在训练过程中使用合规性指标或损失函数来约束模型的输出。
-
限制模型访问权限:对于一些特定的应用场景,可以通过限制模型的访问权限来确保输出的合规性。只允许授权用户或特定角色访问模型,以保护敏感信息和确保合规性。
-
解释模型决策过程:为了满足合规性要求,可以对模型的决策过程进行解释和解释。通过提供透明的解释,可以使用户或相关方了解模型是如何做出决策的,并评估决策的合规性。
-
审查和验证模型:在模型训练和部署之前,进行审查和验证以确保模型的输出符合合规要求。这可能涉及到法律专业人士、伦理专家或相关领域的专业人士的参与。
-
监控和更新模型:持续监控模型的输出,并根据合规要求进行必要的更新和调整。及时发现和解决合规性问题,确保模型的输出一直保持合规。
-
合规培训和教育:为使用模型的人员提供合规培训和教育,使其了解合规要求,并正确使用模型以确保合规性。
需要注意的是,合规性要求因特定领域、应用和地区而异,因此在实施上述方法时,需要根据具体情况进行调整和定制。同时,合规性是一个动态的过程,需要与法律、伦理和社会要求的变化保持同步。
8 应用模式变更
大语言模型的应用模式变更可以包括以下几个方面:
-
任务定制化:将大语言模型应用于特定的任务或领域,通过对模型进行微调或迁移学习,使其适应特定的应用场景。例如,将大语言模型用于自动文本摘要、机器翻译、对话系统等任务。
-
个性化交互:将大语言模型应用于个性化交互,通过对用户输入进行理解和生成相应的回复,实现更自然、智能的对话体验。这可以应用于智能助手、在线客服、社交媒体等场景。
-
内容生成与创作:利用大语言模型的生成能力,将其应用于内容生成和创作领域。例如,自动生成新闻报道、创意文案、诗歌等内容,提供创作灵感和辅助创作过程。
-
情感分析与情绪识别:通过大语言模型对文本进行情感分析和情绪识别,帮助企业或个人了解用户的情感需求和反馈,以改善产品、服务和用户体验。
-
知识图谱构建:利用大语言模型的文本理解能力,将其应用于知识图谱的构建和更新。通过对海量文本进行分析和提取,生成结构化的知识表示,为知识图谱的建设提供支持。
-
法律和合规应用:大语言模型可以用于法律和合规领域,例如自动生成法律文件、合同条款、隐私政策等内容,辅助法律专业人士的工作。
-
教育和培训应用:将大语言模型应用于教育和培训领域,例如智能辅导系统、在线学习平台等,为学生提供个性化的学习辅助和教学资源。
-
创新应用场景:探索和创造全新的应用场景,结合大语言模型的能力和创新思维,开拓新的商业模式和服务方式。例如,结合增强现实技术,实现智能导览和语音交互;结合虚拟现实技术,创建沉浸式的交互体验等。应用模式变更需要充分考虑数据安全、用户隐私、道德和法律等因素,确保在合规和可持续发展的前提下进行应用创新。同时,与领域专家和用户进行密切合作,不断优化和改进应用模式,以满足用户需求和市场竞争。

