
- 1基于深度学习、机器学习,神经网络,OpenCV,图像处理,卷积神经网络计算机毕业设计题目大全_基于神经网络的毕设题目
- 2使用python计算RMSR、MRE和R方、MAE_python实现rmse
- 3关于QWidget里的Widget::paintEvent (QPaintEvent * event)显示图片的问题(即qpainter.drawPixmap)_widget中paintevent无效
- 420240326 每日AI必读资讯_gatekeep ai 网址
- 5微信小程序的N种页面跳转方式(2024最新)_微信小程序页面跳转
- 6YOLOv8-seg 分割代码详解(一)Predict
- 7MATLAB 线性拟合直线示例 + MATLAB线性拟合中文文档(决定系数R^2公式与解释 与 带惩罚项的修改R^2)_matlab拟合直线
- 8爬虫实战——中国天气网数据_爬取天气预报的目的
- 9paddleocr的基本使用_paddleocr zlibwapi.dll
- 10word2vec原理详解及实战_word2vec原理与实战详解(一)
TUM提出TrackFormer:基于Transformers的多目标跟踪
赞
踩
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达论文是学术研究的精华和未来发展的明灯。小白决心每天为大家带来经典或者最新论文的解读和分享,旨在帮助各位读者快速了解论文内容。个人能力有限,理解难免出现偏差,建议对文章内容感兴趣的读者,一定要下载原文,了解具体内容。

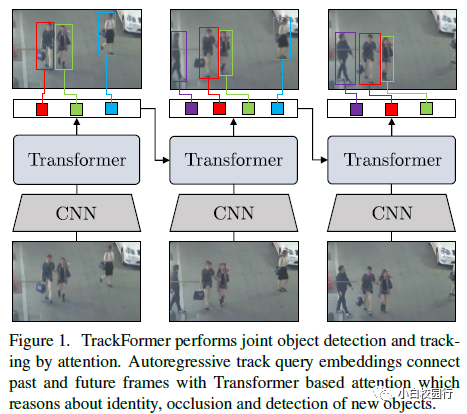
TrackFormer通过注意进行联合目标检测和跟踪。自回归跟踪查询嵌入将过去和未来的帧与基于变压器的注意连接起来,这将导致身份、遮挡和新对象的检测。
摘要
作者提出了一种基于编码器-解码器转换器结构的端到端多目标跟踪和分割模型TrackFormer。作者的方法引入了跟踪查询嵌入,通过视频序列利用一个自回归的方式跟踪对象。新的轨迹是由DETR对象检测器产生的,并且随着时间的推移嵌入相应对象的位置。Transformers解码器在帧之间调整跟踪查询嵌入,从而跟随目标位置的变化。TrackFormer在一个新的注意跟踪范式中实现了帧之间的无缝数据关联,通过自我和编码器-解码器注意机制,同时推理位置、遮挡和对象身份。TrackFormer产生在多目标跟踪(MOT17)和分割(MOTS20)任务上的最先进的性能状态。作者希望作者的检测和跟踪的统一方式将促进未来多目标跟踪和视频理解的研究。
代码将会于近期公布
本文主要工作
在经验评估中,作者将TrackFormer应用到MOT17基准,在那里它达到了最优的性能。此外,作者展示了作者的模型输出分割蒙版的灵活性,并展示了多目标跟踪和分割(MOTS20)挑战的最新成果。
综上所述,作者做出了以下贡献:
一个基于Transformers的统一的检测(或分割)和多目标跟踪方法,实现了一个新的跟踪-注意范式的跟踪单独与注意关联。
新概念的自回归轨迹查询嵌入对象的空间位置,并随时间跟踪它。
在两个具有挑战性的多目标跟踪基准(MOT17和MOTS20)的最先进的结果。
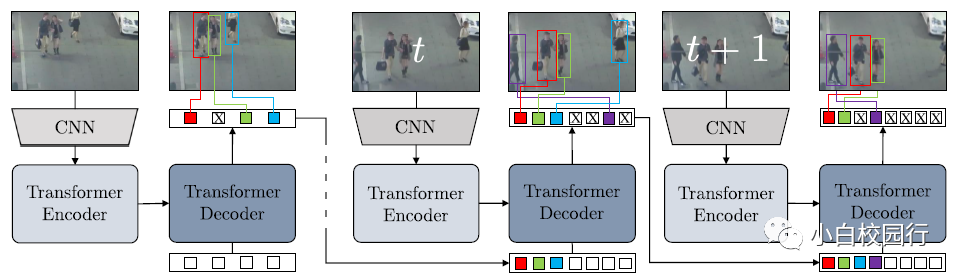
TrackFormer通过自回归处理视频实现联合检测和多目标跟踪。该体系结构以检测器为基础,由用于图像特征提取的CNN、用于图像特征编码的Transformers 编码器和Transformers解码器组成,Transformers解码器应用自关注和编译码器的注意力,产生带有包围框和类信息的输出嵌入。在帧t = 0时,解码器将Nobject对象查询(白色)转换为输出嵌入或初始化新的轨迹查询或预测背景类(交叉)。在随后的帧中,解码器处理Nobject + Ntrack查询的联合集合,以跟踪或删除(蓝色)现有的轨道以及初始化新的轨道(紫色)。
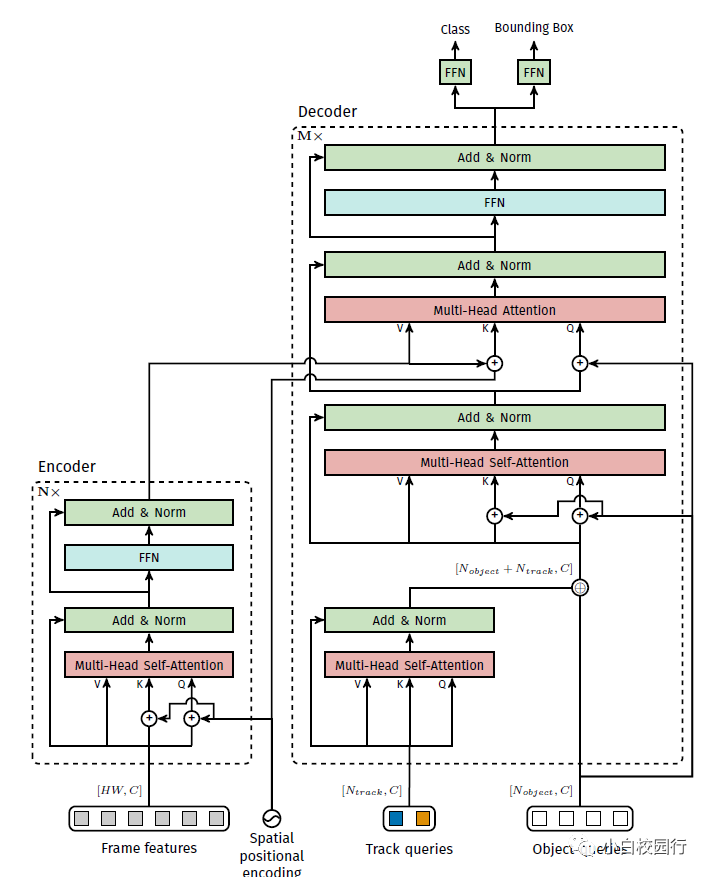
TrackFormer编码器-解码器架构。作者用方括号表示张量的维数
验证实验
作者在两个mochallenge基准上展示了TrackFormer的跟踪结果,即MOT17和MOTS20。此外,作者在消融研究中验证了个人的贡献。
TrackFormer遵循CNN特征提取和Transformers编码器-解码器架构。前者是通过ResNet101骨干实现的,编码器和解码器都应用了6层单独的特征宽度256。每个注意层应用8个注意头的多自我注意。作者不使用主干的DC5(扩张型conv5)版本,因为这将导致与最后剩余阶段的较大分辨率相关的大量内存需求。然而,作者希望DC5或任何其他更重的骨干,或更高的分辨率,能够进一步改善结果,并将其留给未来的工作。

在选定的MOTS20测试序列上,作者将TrackFormer分割结果与流行的Track R-CNN进行比较。通过像素掩模精度的差异,可以清楚地看出TrackFormer在MOTSA方面的优势
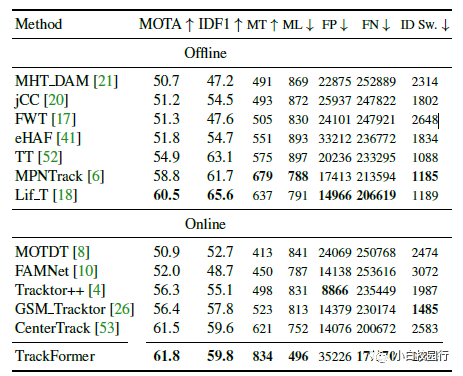
在MOT17测试集上评估的现代多目标跟踪方法的比较。作者报告了数据集提供的三组公共检测以及在线和离线方法之间的平均结果。在所有的跟踪方法中,TrackFormer在MOTA方面取得了最先进的结果。箭头指示低或高的最优度量值。
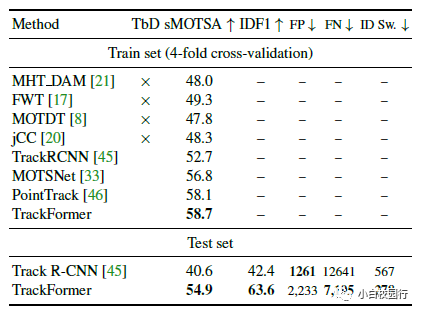
在MOTS20训练集和测试集上评价现代多目标跟踪和分割方法的比较。TbD所指出的方法最初是通过检测进行跟踪,没有分割。因此,他们在SDP公共检测上进行评估,并预测带有附加口罩的R-CNN,在MOTS20上进行微调。TrackFormer在motssa和IDF1两套上实现了最先进的结果。
结论
作者提出了一种新的基于Transformers的检测和多目标跟踪的端到端统一方法。作者的TrackFormer体系结构引入了跟踪查询嵌入,它以自回归的方式在一个序列上跟踪对象。Transformers编码器-解码器体系结构将每个轨道查询转换为其相应对象的变化位置。TrackFormer associates只通过注意力操作进行跟踪,不依赖任何额外的匹配、图形优化、运动或外观建模。作者的方法实现了多目标跟踪和分割的最先进的结果。作者希望这种新的注意力跟踪模式将促进未来在视频检测和跟踪方面的工作。
论文下载:https://arxiv.org/pdf/2101.02702.pdf
每日坚持论文分享不易,如果喜欢我们的内容,希望可以推荐或者转发给周围的同学。
好消息!
小白学视觉知识星球
开始面向外开放啦
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

